With the advent of generative AI and machine learning, new opportunities for enhancement became available for different industries and processes. During re:Invent 2023, we launched AWS HealthScribe, a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation. In addition to AWS HealthScribe, we also launched Amazon Q Business, a generative AI-powered assistant that can perform functions such as answer questions, provide summaries, generate content, and securely complete tasks based on data and information that are in your enterprise systems.
AWS HealthScribe combines speech recognition and generative AI trained specifically for healthcare documentation to accelerate clinical documentation and enhance the consultation experience.
Key features of AWS HealthScribe include:
- Rich consultation transcripts with word-level timestamps.
- Speaker role identification (clinician or patient).
- Transcript segmentation into relevant sections such as subjective, objective, assessment, and plan.
- Summarized clinical notes for sections such as chief complaint, history of present illness, assessment, and plan.
- Evidence mapping that references the original transcript for each sentence in the AI-generated notes.
- Extraction of structured medical terms for entries such as conditions, medications, and treatments.
AWS HealthScribe provides a suite of AI-powered features to streamline clinical documentation while maintaining security and privacy. It doesn’t retain audio or output text, and users have control over data storage with encryption in transit and at rest.
With Amazon Q Business, we provide a new generative AI-powered assistant designed specifically for business and workplace use cases. It can be customized and integrated with an organization’s data, systems, and repositories. Amazon Q allows users to have conversations, help solve problems, generate content, gain insights, and take actions through its AI capabilities. Amazon Q offers user-based pricing plans tailored to how the product is used. It can adapt interactions based on individual user identities, roles, and permissions within the organization. Importantly, AWS never uses customer content from Amazon Q to train its underlying AI models, making sure that company information remains private and secure.
In this blog post, we’ll show you how AWS HealthScribe and Amazon Q Business together analyze patient consultations to provide summaries and trends from clinician conversations, simplifying documentation workflows. This automation and use of machine learning from clinician-patient interactions with Amazon HealthScribe and Amazon Q can help improve patient outcomes by enhancing communication, leading to more personalized care for patients and increased efficiency for clinicians.
Benefits and use cases
Gaining insight from patient-clinician interactions alongside a chatbot can help in a variety of ways such as:
- Enhanced communication: In analyzing consultations, clinicians using AWS HealthScribe can more readily identify patterns and trends in large patient datasets, which can help improve communication between clinicians and patients. An example would be a clinician understanding common trends in their patient’s symptoms that they can then consider for new consultations.
- Personalized care: Using machine learning, clinicians can tailor their care to individual patients by analyzing the specific needs and concerns of each patient. This can lead to more personalized and effective care.
- Streamlined workflows: Clinicians can use machine learning to help streamline their workflows by automating tasks such as appointment scheduling and consultation summarization. This can give clinicians more time to focus on providing high-quality care to their patients. An example would be using clinician summaries together with agentic workflows to perform these tasks on a routine basis.
Architecture diagram

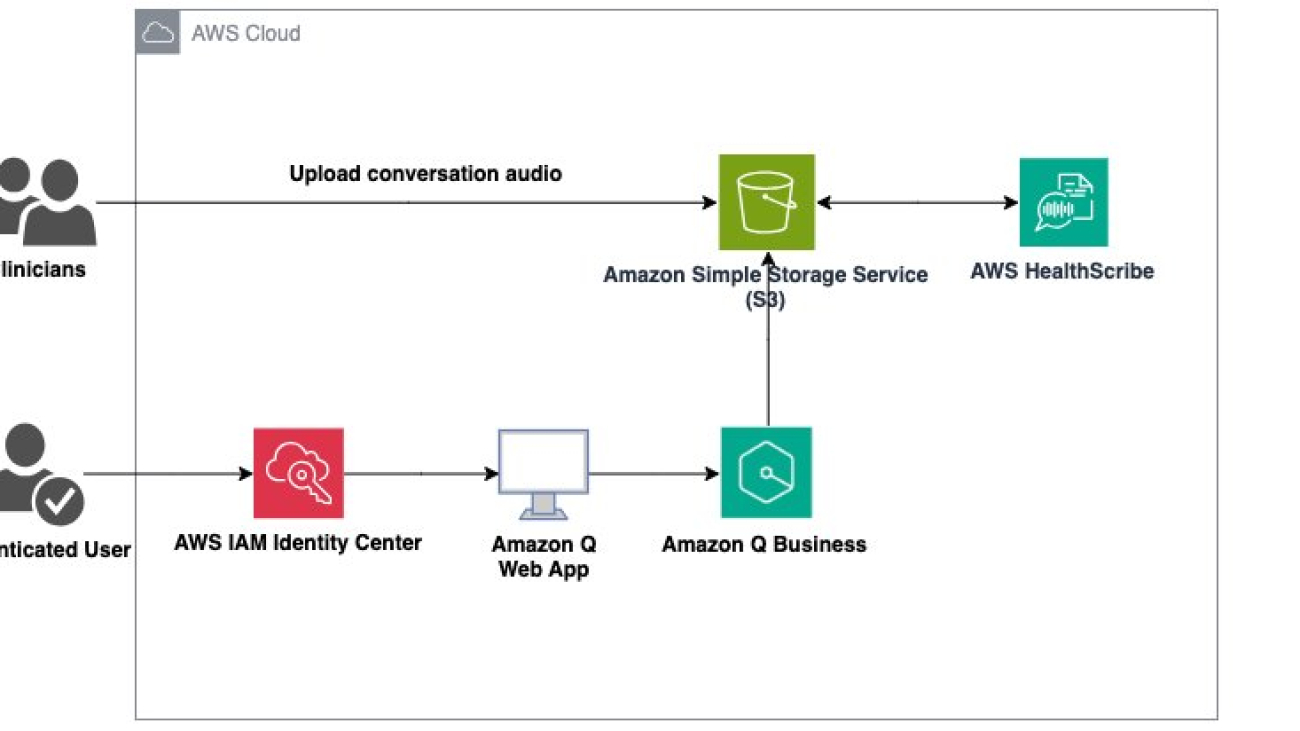
In the architecture diagram we present for this demo, two user workflows are shown. To kickoff the process, a clinician uploads the recording of a consultation to Amazon Simple Storage Service (Amazon S3). This audio file is then ingested by AWS HealthScribe and used to analyze consultation conversations. AWS HealthScribe will then output two files which are also stored on Amazon S3. In the second workflow, an authenticated user logs in via AWS IAM Identity Center to an Amazon Q web front end hosted by Amazon Q Business. In this scenario, Amazon Q Business is given the output Amazon S3 bucket as the data source for use in its web app.
Prerequisites
- AWS IAM Identity Center will be used as the SAML 2.0-compliant identity provider (IdP). You’ll need to enable an IAM Identity Center instance. Under this instance, be sure to provision a user with a valid email address because this will be the user you will use to sign in to Amazon Q Business. For more details, see Configure user access with the default IAM Identity Center directory.
- Amazon Simple Storage Service (Amazon S3) buckets that will be the input and output buckets for the clinician-patient conversations and AWS HealthScribe.
Implementation
To start using AWS HealthScribe you must first start a transcription job that takes a source audio file and outputs summary and transcription JSON files with the analyzed conversation. You’ll then connect these output files to Amazon Q.
Creating the AWS HealthScribe job
- In the AWS HealthScribe console, choose Transcription jobs in the navigation pane, and then choose Create job to get started.

- Enter a name for the job—in this example, we use
FatigueConsult—and select the S3 bucket where the audio file of the clinician-patient conversation is stored.
- Next, use the S3 URI search field to find and point the transcription job to the Amazon S3 bucket you want the output files to be saved to. Maintain the default options for audio settings, customization, and content removal.

- Create a new AWS Identity and Access Management (IAM) role for AWS HealthScribe to use for access to the S3 input and output buckets by choosing Create an IAM role. In our example, we entered
HealthScribeRoleas the Role name. To complete the job creation, choose Create job.
- This will take a few minutes to finish. When it’s complete, you will see the status change from In Progress to Complete and can inspect the results by selecting the job name.
 AWS HealthScribe will create two files: a word-for-word transcript of the conversation with the suffix
AWS HealthScribe will create two files: a word-for-word transcript of the conversation with the suffix /transcript.jsonand a summary of the conversation with the suffix/summary.json. This summary uses the underlying power of generative AI to highlight key topics in the conversation, extract medical terminology, and more.

In this workflow, AWS HealthScribe analyzes the patient-clinician conversation audio to:
- Transcribe the consultation
- Identify speaker roles (for example, clinician and patient)
- Segment the transcript (for example, small talk, visit flow management, assessment, and treatment plan)
- Extract medical terms (for example, medication name and medical condition name)
- Summarize notes for key sections of the clinical document (for example, history of present illness and treatment plan)
- Create evidence mapping (linking every sentence in the AI-generated note with corresponding transcript dialogues).
Connecting an AWS HealthScribe job to Amazon Q
To use Amazon Q with the summarized notes and transcripts from AWS HealthScribe, we need to first create an Amazon Q business application and set the data source as the S3 bucket where the output files were stored in the HealthScribe jobs workflow. This will allow Amazon Q to index the files and give users the ability to ask questions of the data.
- In the Amazon Q Business console, choose Get Started, then choose Create Application.
- Enter a name for your application and select Create and use a new service-linked role (SLR).

- Choose Create when you’re ready to select a data source.
- In the Add data source pane select Amazon S3.

- To configure the S3 bucket with Amazon Q, enter a name for the data source. In our example we use
my-s3-bucket.
- Next, locate the S3 bucket with the JSON outputs from HealthScribe using the Browse S3 button. Select Full sync for the sync mode and select a cadence of your preference. Once you complete these steps, Amazon Q Business will run a full sync of the objects in your S3 bucket and be ready for use.

- In the main applications dashboard, navigate to the URL under Web experience URL. This is how you will access the Amazon Q web front end to interact with the assistant.

After a user signs in to the web experience, they can start asking questions directly in the chat box as shown in the sample frontend that follows.
Sample frontend workflow
With the AWS HealthScribe results integrated into Amazon Q Business, users can go to the web experience to gain insights from their patient conversations. For example, you can use Q to determine information such as trends in patient symptoms, checking which medications patients are taking and so on as shown in the following figures.
The workflow starts with a question and answer about issues patients had, as shown in the following figure.  In the example above, a clinician is asking what the symptoms were of patients who complained of stomach pain. Q responds with common symptoms, like bloating and bowel problems, from the data it has access to. The answers generated cite the source files from Amazon S3 that led to its summary and can be inspected by choosing Sources.
In the example above, a clinician is asking what the symptoms were of patients who complained of stomach pain. Q responds with common symptoms, like bloating and bowel problems, from the data it has access to. The answers generated cite the source files from Amazon S3 that led to its summary and can be inspected by choosing Sources.
In the following example, a clinician asks what medications patients with knee pain are taking. Using our sample data of various consultations for knee pain, Q tells us patients are taking over the counter ibuprofen, but that it is not often providing patients relief.
This application can also help clinicians understand common trends in their patient data, such as asking what the common symptoms are for patients with chest pain.
 In the final example for this post, a clinician asks Q if there are common symptoms for patients complaining of knee and elbow pain. Q responds that both sets of patients describe their pain being exacerbated by movement, but that it cannot conclusively point to any common symptoms across both consultation types. In this case Amazon Q is correctly using source data to prevent a hallucination from occurring.
In the final example for this post, a clinician asks Q if there are common symptoms for patients complaining of knee and elbow pain. Q responds that both sets of patients describe their pain being exacerbated by movement, but that it cannot conclusively point to any common symptoms across both consultation types. In this case Amazon Q is correctly using source data to prevent a hallucination from occurring.
Considerations
The UI for Amazon Q has limited customization. At the time of writing this post, the Amazon Q frontend cannot be embedded in other tools. Supported customization of the web experience includes the addition of a title and subtitle, adding a welcome message, and displaying sample prompts. For updates on web experience customizations, see Customizing an Amazon Q Business web experience. If this kind of customization is critical to your application and business needs, you can explore custom large language model chatbot designs using Amazon Bedrock or Amazon SageMaker.
AWS HealthScribe uses conversational and generative AI to transcribe patient-clinician conversations and generate clinical notes. The results produced by AWS HealthScribe are probabilistic and might not always be accurate because of various factors, including audio quality, background noise, speaker clarity, the complexity of medical terminology, and context-specific language nuances. AWS HealthScribe is designed to be used in an assistive role for clinicians and medical scribes rather than as a substitute for their clinical expertise. As such, AWS HealthScribe output should not be employed to fully automate clinical documentation workflows, but rather to provide additional assistance to clinicians or medical scribes in their documentation process. Please ensure that your application provides the workflow for reviewing the clinical notes produced by AWS HealthScribe and establishes expectation of the need for human review before finalizing clinical notes.
Amazon Q Business uses machine learning models that generate predictions based on patterns in data, and generate insights and recommendations from your content. Outputs are probabilistic and should be evaluated for accuracy as appropriate for your use case, including by employing human review of the output. You and your users are responsible for all decisions made, advice given, actions taken, and failures to take action based on your use of these features.
This proof-of-concept can be extrapolated to create a patient-facing application as well, with the notion that a patient can review their own conversations with physicians and be given access to their medical records and consultation notes in a way that makes it easy for them to ask questions of the trends and data for their own medical history.
AWS HealthScribe is only available for English-US language at this time in the US East (N. Virginia) Region. Amazon Q Business is only available in US East (N. Virginia) and US West (Oregon).
Clean up
To ensure that you don’t continue to accrue charges from this solution, you must complete the following clean-up steps.
AWS HealthScribe
Navigate to the AWS HealthScribe the console and choose Transcription jobs. Select whichever HealthScribe jobs you want to clean up and choose Delete at the top right corner of the console page.
Amazon S3
To clean up your Amazon S3 resources, navigate to the Amazon S3 console and choose the buckets that you used or created while going through this post. To empty the buckets, follow the instructions for Emptying a bucket. After you empty the bucket, you delete the entire bucket.
Amazon Q Business
To delete your Amazon Q Business application, follow the instructions on Managing Amazon Q Business applications.
Conclusion
In this post, we discussed how you can use AWS HealthScribe with Amazon Q Business to create a chatbot to quickly gain insights into patient clinician conversations. To learn more, reach out to your AWS account team or check out the links that follow.
About the Authors
 Laura Salinas is a Startup Solution Architect supporting customers whose core business involves machine learning. She is passionate about guiding her customers on their cloud journey and finding solutions that help them innovate. Outside of work she loves boxing, watching the latest movie at the theater and playing competitive dodgeball.
Laura Salinas is a Startup Solution Architect supporting customers whose core business involves machine learning. She is passionate about guiding her customers on their cloud journey and finding solutions that help them innovate. Outside of work she loves boxing, watching the latest movie at the theater and playing competitive dodgeball.
 Tiffany Chen is a Solutions Architect on the CSC team at AWS. She has supported AWS customers with their deployment workloads and currently works with Enterprise customers to build well-architected and cost-optimized solutions. In her spare time, she enjoys traveling, gardening, baking, and watching basketball.
Tiffany Chen is a Solutions Architect on the CSC team at AWS. She has supported AWS customers with their deployment workloads and currently works with Enterprise customers to build well-architected and cost-optimized solutions. In her spare time, she enjoys traveling, gardening, baking, and watching basketball.
 Art Tuazon is a Partner Solutions Architect focused on enabling AWS Partners through technical best practices and is passionate about helping customers build on AWS. In her free time, she enjoys running and cooking.
Art Tuazon is a Partner Solutions Architect focused on enabling AWS Partners through technical best practices and is passionate about helping customers build on AWS. In her free time, she enjoys running and cooking.
 Winnie Chen is a Solutions Architect currently on the CSC team at AWS supporting greenfield customers. She supports customers of all industries as well as sizes such as enterprise and small to medium businesses. She has helped customers migrate and build their infrastructure on AWS. In her free time, she enjoys traveling and spending time outdoors through activities like hiking, biking and rock climbing.
Winnie Chen is a Solutions Architect currently on the CSC team at AWS supporting greenfield customers. She supports customers of all industries as well as sizes such as enterprise and small to medium businesses. She has helped customers migrate and build their infrastructure on AWS. In her free time, she enjoys traveling and spending time outdoors through activities like hiking, biking and rock climbing.












 Irene Arroyo Delgado is an AI/ML and GenAI Specialist Solutions Architect at AWS. She focuses on bringing out the potential of generative AI for each use case and productionizing ML workloads, to achieve customers’ desired business outcomes by automating end-to-end ML lifecycles. In her free time, Irene enjoys traveling and hiking.
Irene Arroyo Delgado is an AI/ML and GenAI Specialist Solutions Architect at AWS. She focuses on bringing out the potential of generative AI for each use case and productionizing ML workloads, to achieve customers’ desired business outcomes by automating end-to-end ML lifecycles. In her free time, Irene enjoys traveling and hiking. Itziar Molina Fernandez is an AI/ML Consultant in the AWS Professional Services team. In her role, she works with customers building large-scale machine learning platforms and generative AI use cases on AWS. In her free time, she enjoys exploring new places.
Itziar Molina Fernandez is an AI/ML Consultant in the AWS Professional Services team. In her role, she works with customers building large-scale machine learning platforms and generative AI use cases on AWS. In her free time, she enjoys exploring new places. Matteo Amadei is a Data Scientist Consultant in the AWS Professional Services team. He uses his expertise in artificial intelligence and advanced analytics to extract valuable insights and drive meaningful business outcomes for customers. He has worked on a wide range of projects spanning NLP, computer vision, and generative AI. He also has experience with building end-to-end MLOps pipelines to productionize analytical models. In his free time, Matteo enjoys traveling and reading.
Matteo Amadei is a Data Scientist Consultant in the AWS Professional Services team. He uses his expertise in artificial intelligence and advanced analytics to extract valuable insights and drive meaningful business outcomes for customers. He has worked on a wide range of projects spanning NLP, computer vision, and generative AI. He also has experience with building end-to-end MLOps pipelines to productionize analytical models. In his free time, Matteo enjoys traveling and reading. Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.


 Yash Yamsanwar is a Machine Learning Architect at Amazon Web Services (AWS). He is responsible for designing high-performance, scalable machine learning infrastructure that optimizes the full lifecycle of machine learning models, from training to deployment. Yash collaborates closely with ML research teams to push the boundaries of what is possible with LLMs and other cutting-edge machine learning technologies.
Yash Yamsanwar is a Machine Learning Architect at Amazon Web Services (AWS). He is responsible for designing high-performance, scalable machine learning infrastructure that optimizes the full lifecycle of machine learning models, from training to deployment. Yash collaborates closely with ML research teams to push the boundaries of what is possible with LLMs and other cutting-edge machine learning technologies. Sawyer Hirt is a Solutions Architect at AWS, specializing in AI/ML and cloud architectures, with a passion for helping businesses leverage cutting-edge technologies to overcome complex challenges. His expertise lies in designing and optimizing ML workflows, enhancing system performance, and making advanced AI solutions more accessible and cost-effective, with a particular focus on Generative AI. Outside of work, Sawyer enjoys traveling, spending time with family, and staying current with the latest developments in cloud computing and artificial intelligence.
Sawyer Hirt is a Solutions Architect at AWS, specializing in AI/ML and cloud architectures, with a passion for helping businesses leverage cutting-edge technologies to overcome complex challenges. His expertise lies in designing and optimizing ML workflows, enhancing system performance, and making advanced AI solutions more accessible and cost-effective, with a particular focus on Generative AI. Outside of work, Sawyer enjoys traveling, spending time with family, and staying current with the latest developments in cloud computing and artificial intelligence.
 NotebookLM is piloting a way for teams to collaborate, and introducing a new way to customize Audio Overviews.
NotebookLM is piloting a way for teams to collaborate, and introducing a new way to customize Audio Overviews.





 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN) 
 A study published by Google Cloud and Harris Poll sheds light on healthcare’s administrative burden, and how AI can help.
A study published by Google Cloud and Harris Poll sheds light on healthcare’s administrative burden, and how AI can help.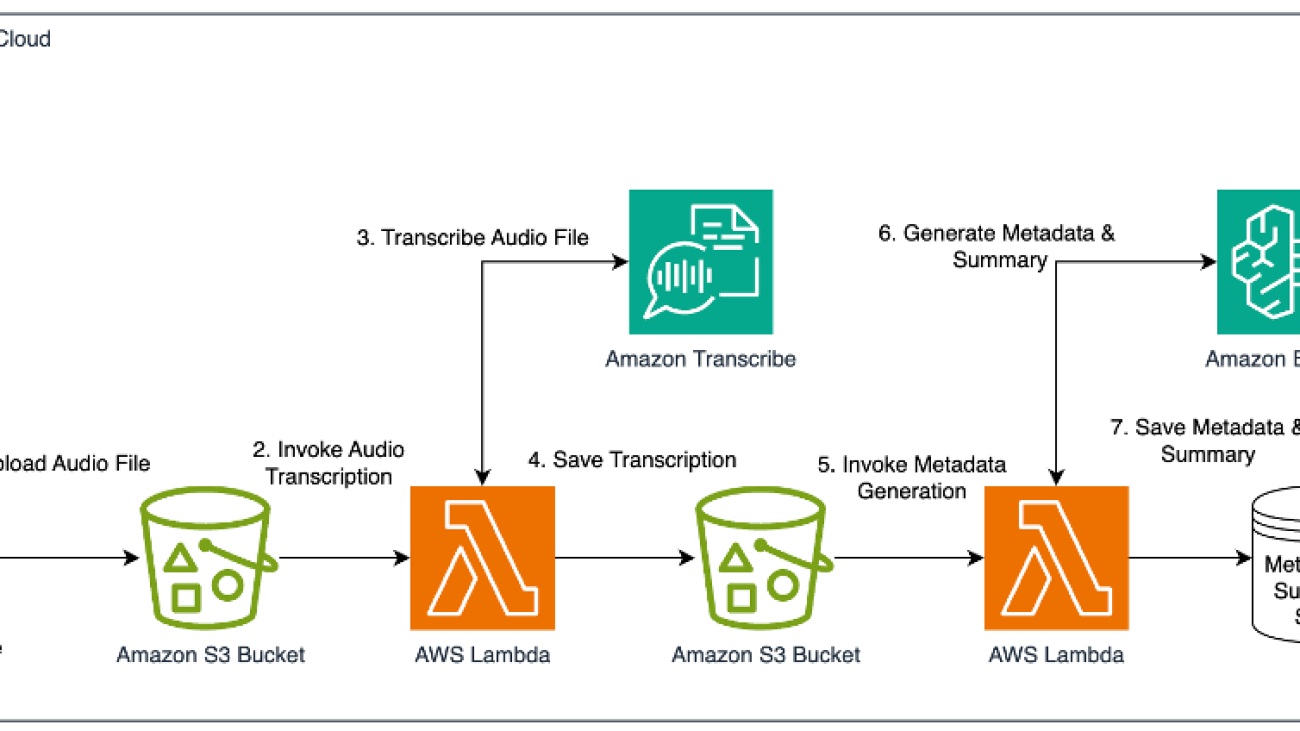

 Lucas Desard is GenAI Engineer at DPG Media. He helps DPG Media integrate generative AI efficiently and meaningfully into various company processes.
Lucas Desard is GenAI Engineer at DPG Media. He helps DPG Media integrate generative AI efficiently and meaningfully into various company processes. Tom Lauwers is a machine learning engineer on the video personalization team for DPG Media. He builds and architects the recommendation systems for DPG Media’s long-form video platforms, supporting brands like VTM GO, Streamz, and RTL play.
Tom Lauwers is a machine learning engineer on the video personalization team for DPG Media. He builds and architects the recommendation systems for DPG Media’s long-form video platforms, supporting brands like VTM GO, Streamz, and RTL play. Sam Landuydt is the Area Manager Recommendation & Search at DPG Media. As the manager of the team, he guides ML and software engineers in building recommendation systems and generative AI solutions for the company.
Sam Landuydt is the Area Manager Recommendation & Search at DPG Media. As the manager of the team, he guides ML and software engineers in building recommendation systems and generative AI solutions for the company. Irina Radu is a Prototyping Engagement Manager, part of AWS EMEA Prototyping and Cloud Engineering. She helps customers get the most out of the latest tech, innovate faster, and think bigger.
Irina Radu is a Prototyping Engagement Manager, part of AWS EMEA Prototyping and Cloud Engineering. She helps customers get the most out of the latest tech, innovate faster, and think bigger. Fernanda Machado, AWS Prototyping Architect, helps customers bring ideas to life and use the latest best practices for modern applications.
Fernanda Machado, AWS Prototyping Architect, helps customers bring ideas to life and use the latest best practices for modern applications. Andrew Shved, Senior AWS Prototyping Architect, helps customers build business solutions that use innovations in modern applications, big data, and AI.
Andrew Shved, Senior AWS Prototyping Architect, helps customers build business solutions that use innovations in modern applications, big data, and AI.