Amazon SageMaker Ground Truth is a powerful data labeling service offered by AWS that provides a comprehensive and scalable platform for labeling various types of data, including text, images, videos, and 3D point clouds, using a diverse workforce of human annotators. In addition to traditional custom-tailored deep learning models, SageMaker Ground Truth also supports generative AI use cases, enabling the generation of high-quality training data for artificial intelligence and machine learning (AI/ML) models. SageMaker Ground Truth includes a self-serve option and an AWS managed option known as SageMaker Ground Truth Plus. In this post, we focus on getting started with SageMaker Ground Truth Plus by creating a project and sharing your data that requires labeling.
Overview of solution
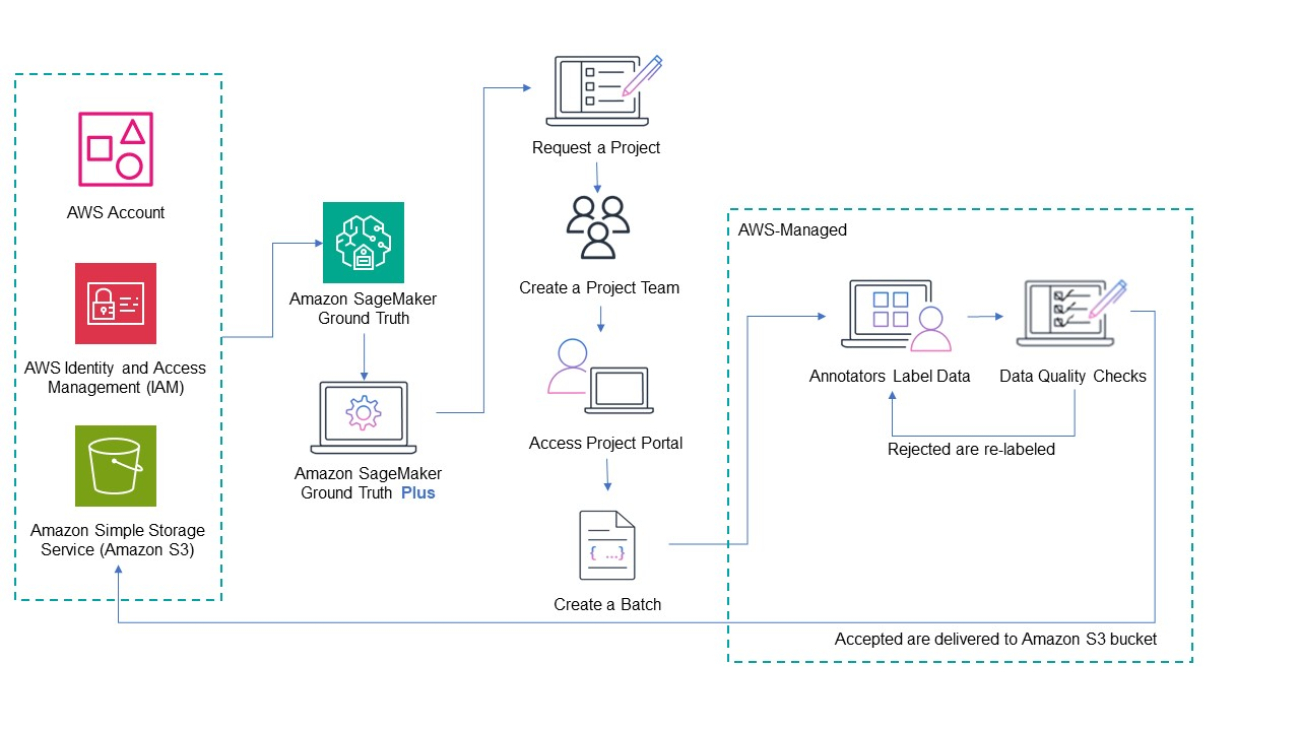
First, you fill out a consultation form on the Get Started with Amazon SageMaker Ground Truth page or, if you already have an AWS account, you submit a request project form on the SageMaker Ground Truth Plus console. An AWS expert contacts you to review your specific data labeling requirements. You can share any specific requirements such as subject matter expertise, language expertise, or geographic location of labelers. If you submitted a consultation form, you submit a request project form on the SageMaker Ground Truth Plus console and it will be approved without any further discussion. If you submitted a project request, then your project status changes from Review in progress to Request approved.
Next, you create your project team, which includes people that are collaborating with you on the project. Each team member receives an invitation to join your project. Now, you upload the data that requires labeling to an Amazon Simple Storage Solution (Amazon S3) bucket. To add that data to your project, go to your project portal and create a batch and include the S3 bucket URL. Every project consists of one or more batches. Each batch is made up of data objects to be labeled.
Now, the SageMaker Ground Truth Plus team takes over and sources annotators based on your specific data labeling needs, trains them on your labeling requirements, and creates a UI for them to label your data. After the labeled data passes internal quality checks, it is delivered back to an S3 bucket for you to use for training your ML models.
The following diagram illustrates the solution architecture.

Using the steps outlined in this post, you’ll be able to quickly get set up for your data labeling project. This includes requesting a new project, setting up a project team, and creating a batch, which includes the data objects you needed labeled.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account.
- The URI of the S3 bucket where your data is stored. The bucket should be in the US East (N. Virginia) AWS Region.
- An AWS Identity and Access Management (IAM) user. If you’re the owner of your AWS account, then you have administrator access and can skip this step. If your AWS account is part of an AWS organization, then you can ask your AWS administrator to grant your IAM user the required permissions. The following identity-based policy specifies the minimum permissions required for your IAM user to perform all the steps in this post (provide the name of the S3 bucket where your data is stored:
Request a project
Complete the following steps to request a project:
- On the SageMaker console, under Ground Truth in the navigation pane, choose Plus.

- Choose Request project.

- For Business email address, enter a valid email.
- For Project name, enter a descriptive name with no spaces or special characters.
- For Task type, choose the option that best describes the type of data you need labeled.
- For Contains PII, only turn on if your data contains personally identifiable information (PII).
- For IAM role, the role you choose grants SageMaker Ground Truth Plus permissions to access your data in Amazon S3 and perform a labeling job. You can use any of the following options to specify the IAM role:
- Choose Create an IAM role (recommended), which provides access to the S3 buckets you specify and automatically attaches the required permissions and trust policy to the role.
- Enter a custom IAM role ARN.
- Choose an existing role.
If you don’t have permissions to create an IAM role, you may ask your AWS administrator to create the role for you. When using an existing role or a custom IAM role ARN, the IAM role should have the following permissions policy and trust policy.
The following code is the permissions policy:
The following code is the trust policy:
- Choose Request project.

Under Ground Truth in the navigation pane, you can choose Plus to see your project listed in the Projects section with the status Review in progress.

An AWS representative will contact you within 72 hours to review your project requirements. When this review is complete, your project status will change from Review in progress to Request approved.
Create project team
SageMaker Ground Truth uses Amazon Cognito to manage the members of your workforce and work teams. Amazon Cognito is a service that you use to create identities for your workers. Complete the following steps to create a project team:
- On the SageMaker console, under Ground Truth in the navigation pane, choose Plus.
- Choose the Create project team.

The remaining steps depend on whether you create a new user group or import an existing group.
Option 1: Create a new Amazon Cognito user group
If you don’t want to import members from an existing Amazon Cognito user group in your account, or you don’t have any Amazon Cognito user groups in your account, you can use this option.
- When creating your project team, select Create a new Amazon Cognito user group.
- For Amazon Cognito user group name, enter a descriptive name with no spaces.
- For Email addresses, enter up to 50 addresses. Use a comma between addresses.
- Choose Preview invitation to see the email that is sent to the email addresses you provided.
- Choose Create project team.

Under Ground Truth in the navigation pane, choose Plus to see your project team listed in the Project team section. The email addresses you added are included in the Members section.

Option 2: Import existing Amazon Cognito user groups
If you have an existing Amazon Cognito user group in your account from which you want to import members, you can use this option.
- When creating your project team, select Import existing Amazon Cognito user groups.
- For Select existing Amazon Cognito user groups, choose the user group from which you want to import members.
- Choose Create project team.

Under Ground Truth in the navigation pane, choose Plus to see your project team listed in the Project team section. The email addresses you added are included in the Members section.
Access the project portal and Create Batch
You can use the project portal to create batches containing your unlabeled input data and track the status of your previously created batches in a project. To access the project portal, make sure that you have created at least one project and at least one project team with one verified member.
- On the SageMaker console, under Ground Truth in the navigation pane, choose Plus.
- Choose Open project portal.

- Log in to the project portal using your project team’s user credentials created in the previous step.

A list of all your projects is displayed on the project portal.

- Choose a project to open its details page.
- In the Batches section, choose Create batch.

- Enter the batch name, batch description, S3 location for input datasets, and S3 location for output datasets.
- Choose Submit.

To create a batch successfully, make sure you meet the following criteria:
- Your S3 bucket is in the US East (N. Virginia) Region.
- The maximum size for each file is no more than 2 GB.
- The maximum number of files in a batch is 10,000.
- The total size of a batch is less than 100 GB.
- Your submitted batch is listed in the Batches section with the status Request submitted. When the data transfer is complete, the status changes to Data received.

Next, the SageMaker Ground Truth Plus team sets up data labeling workflows, which changes the batch status to In progress. Annotators label the data, and you complete your data quality check by accepting or rejecting the labeled data. Rejected objects go back to annotators to re-label. Accepted objects are delivered to an S3 bucket for you to use for training your ML models.
Conclusion
SageMaker Ground Truth Plus provides a seamless solution for building high-quality training datasets for your ML models. By using AWS managed expert labelers and automating the data labeling workflow, SageMaker Ground Truth Plus eliminates the overhead of building and managing your own labeling workforce. With its user-friendly interface and integrated tools, you can submit your data, specify labeling requirements, and monitor the progress of your projects with ease. As you receive accurately labeled data, you can confidently train your models, maintaining optimal performance and accuracy. Streamline your ML projects and focus on building innovative solutions with the power of SageMaker Ground Truth Plus.
To learn more, see Use Amazon SageMaker Ground Truth Plus to Label Data.
About the Authors
 Joydeep Saha is a System Development Engineer at AWS with expertise in designing and implementing solutions to deliver business outcomes for customers. His current focus revolves around building cloud-native end-to-end data labeling solutions, empowering customers to unlock the full potential of their data and drive success through accurate and reliable machine learning models.
Joydeep Saha is a System Development Engineer at AWS with expertise in designing and implementing solutions to deliver business outcomes for customers. His current focus revolves around building cloud-native end-to-end data labeling solutions, empowering customers to unlock the full potential of their data and drive success through accurate and reliable machine learning models.
 Ami Dani is a Senior Technical Program Manager at AWS focusing on AI/ML services. During her career, she has focused on delivering transformative software development projects for the federal government and large companies in industries as diverse as advertising, entertainment, and finance. Ami has experience driving business growth, implementing innovative training programs, and successfully managing complex, high-impact projects.
Ami Dani is a Senior Technical Program Manager at AWS focusing on AI/ML services. During her career, she has focused on delivering transformative software development projects for the federal government and large companies in industries as diverse as advertising, entertainment, and finance. Ami has experience driving business growth, implementing innovative training programs, and successfully managing complex, high-impact projects.
 Google Shopping uses AI to help you find more relevant products, discover personalized options and find the lowest prices.
Google Shopping uses AI to help you find more relevant products, discover personalized options and find the lowest prices.
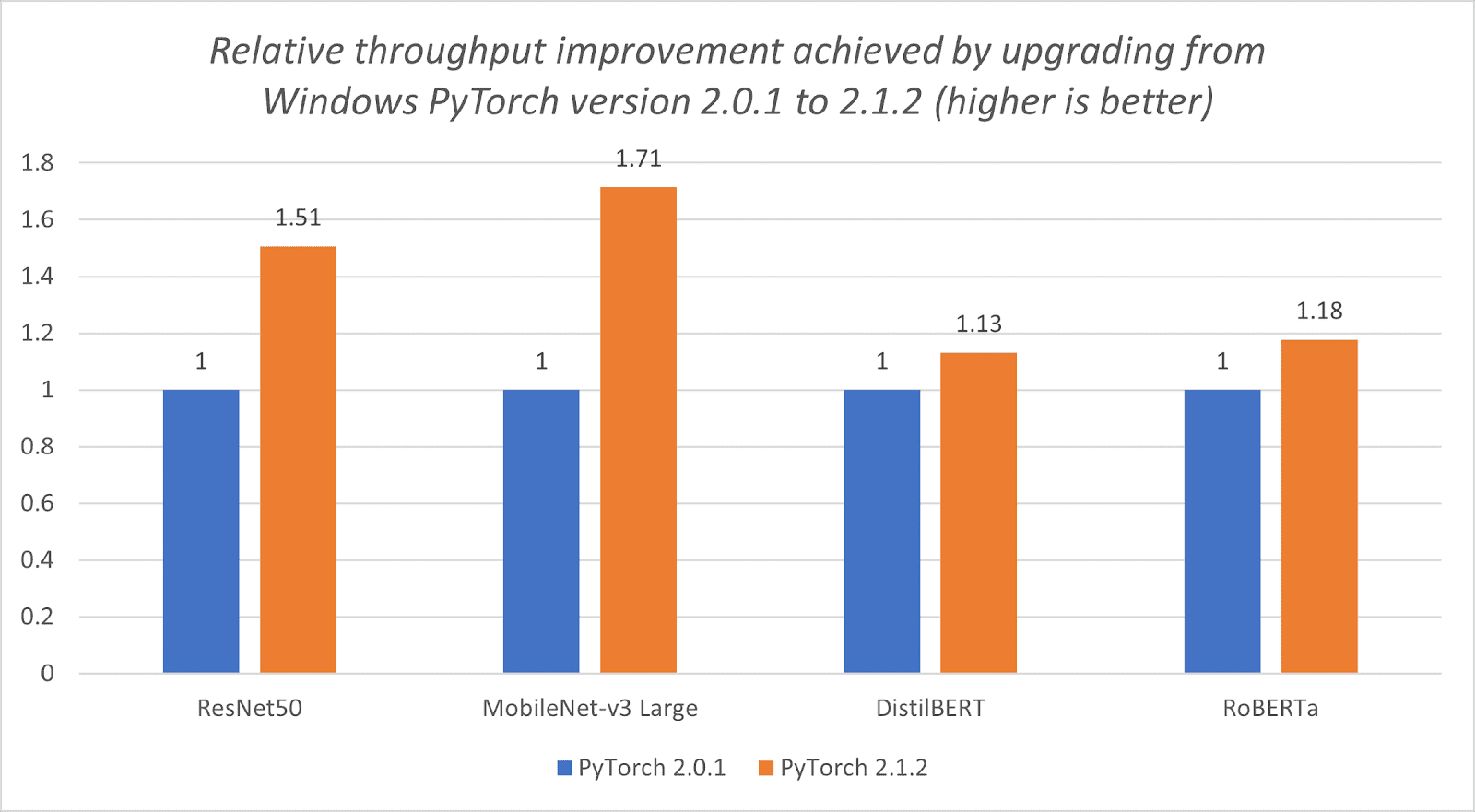
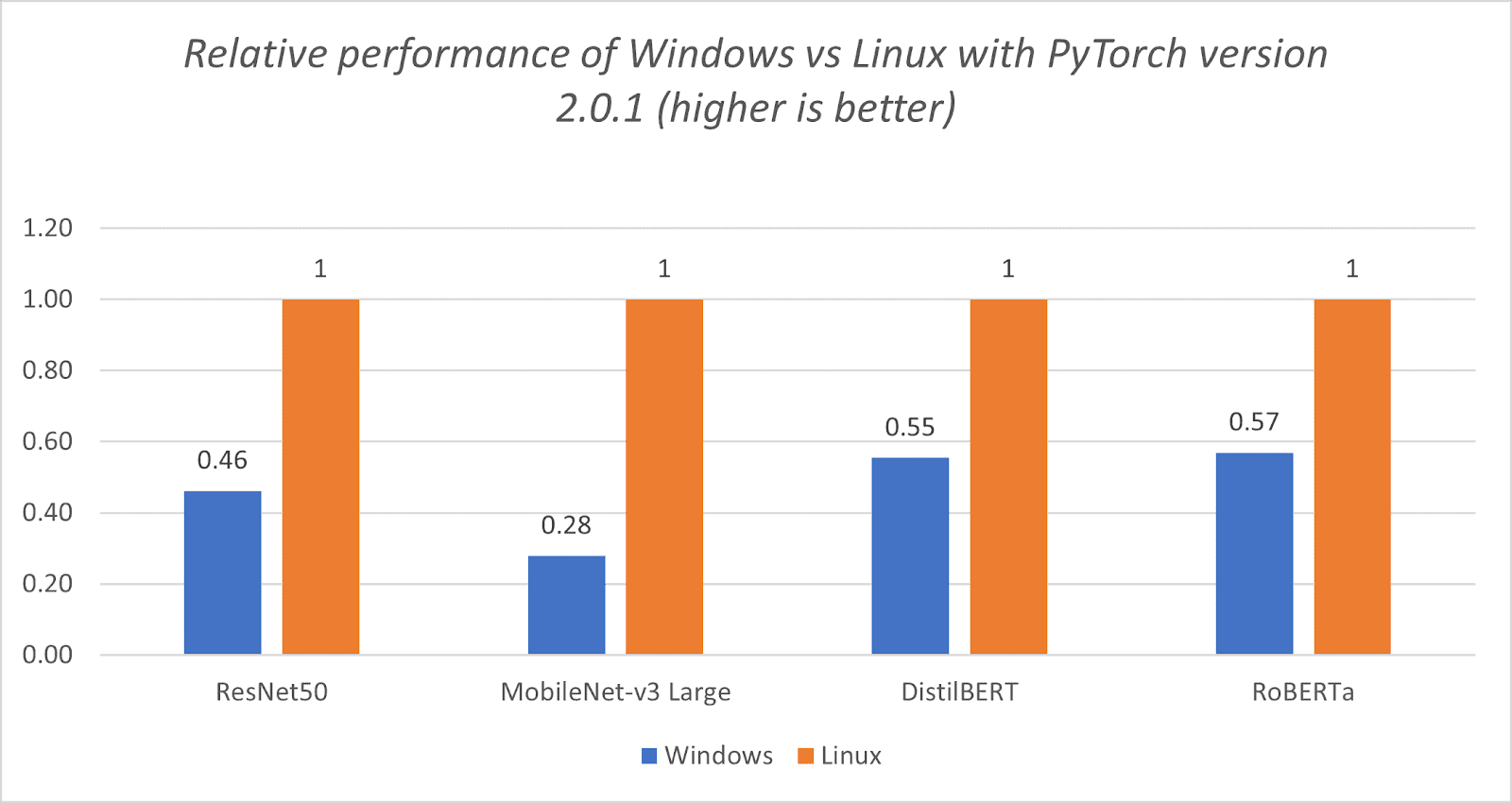
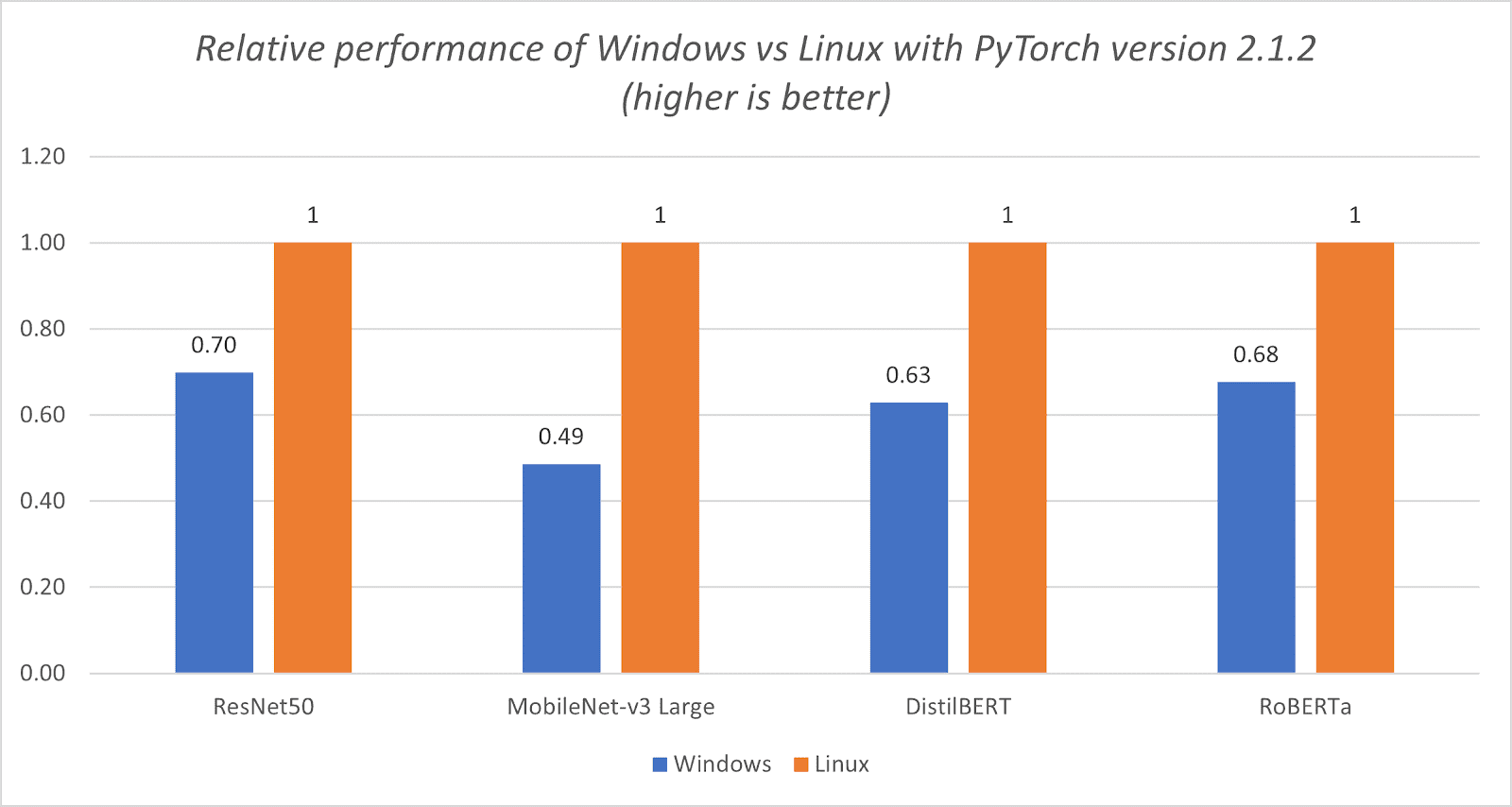
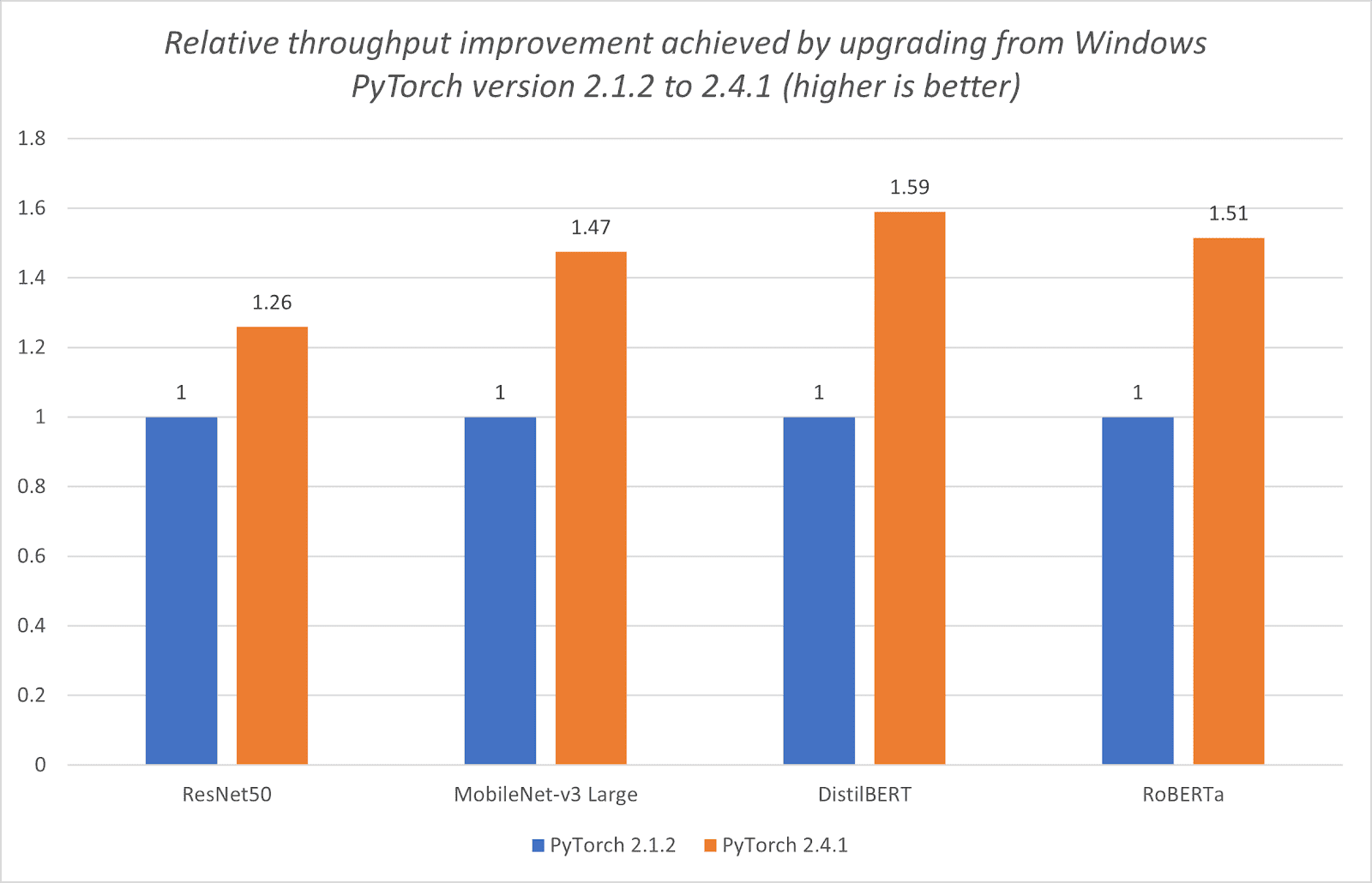

 Here’s a breakdown of on-device processing and how we’re working to make your devices better with local AI features.
Here’s a breakdown of on-device processing and how we’re working to make your devices better with local AI features.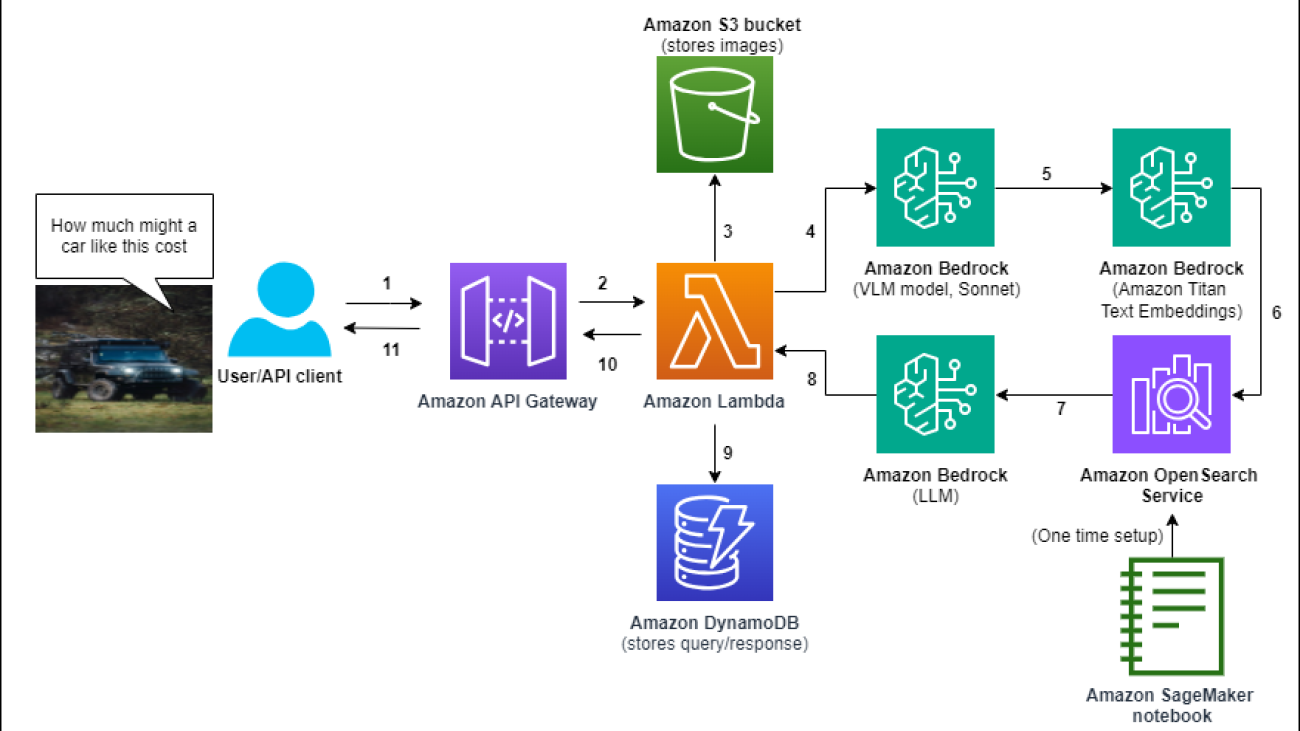














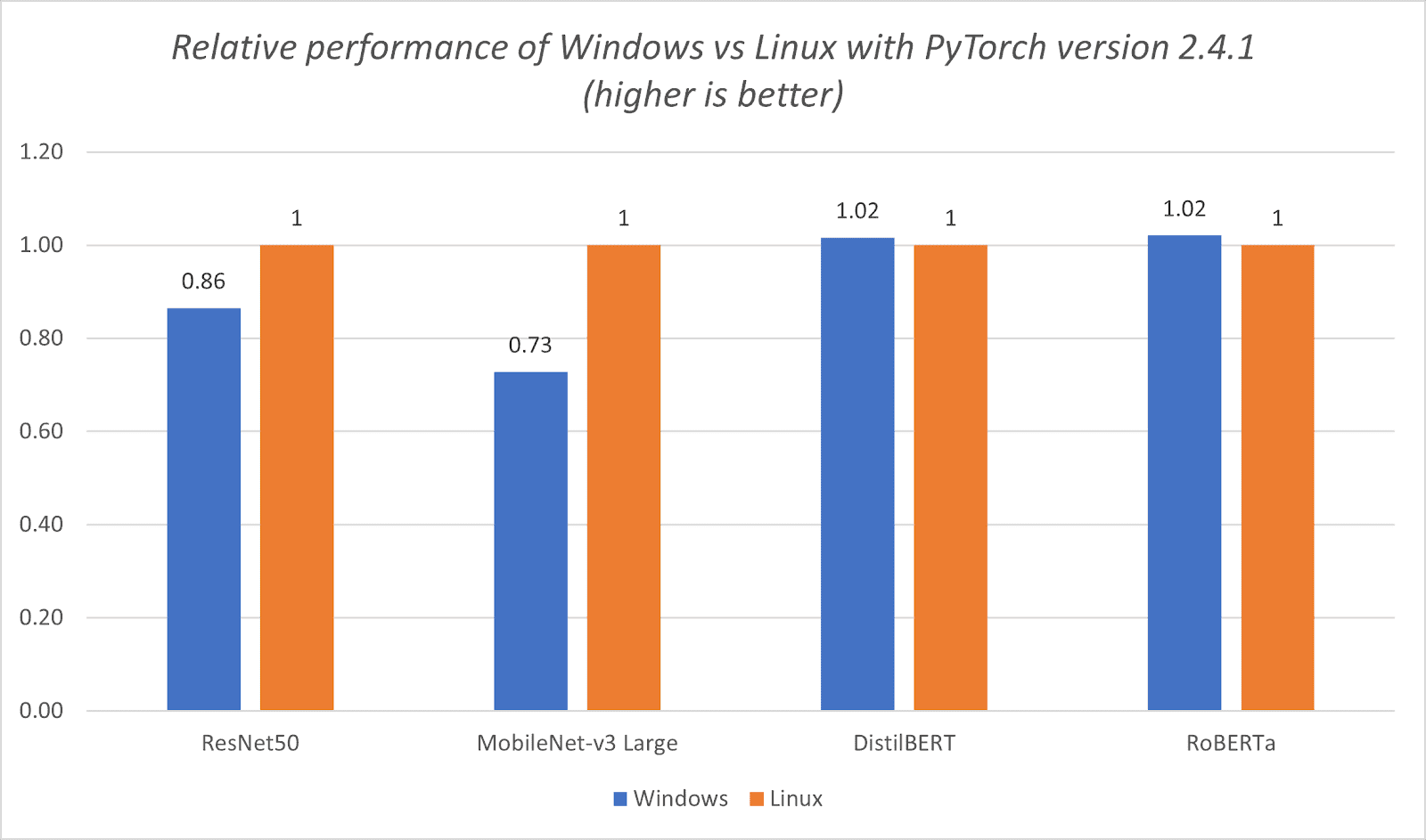
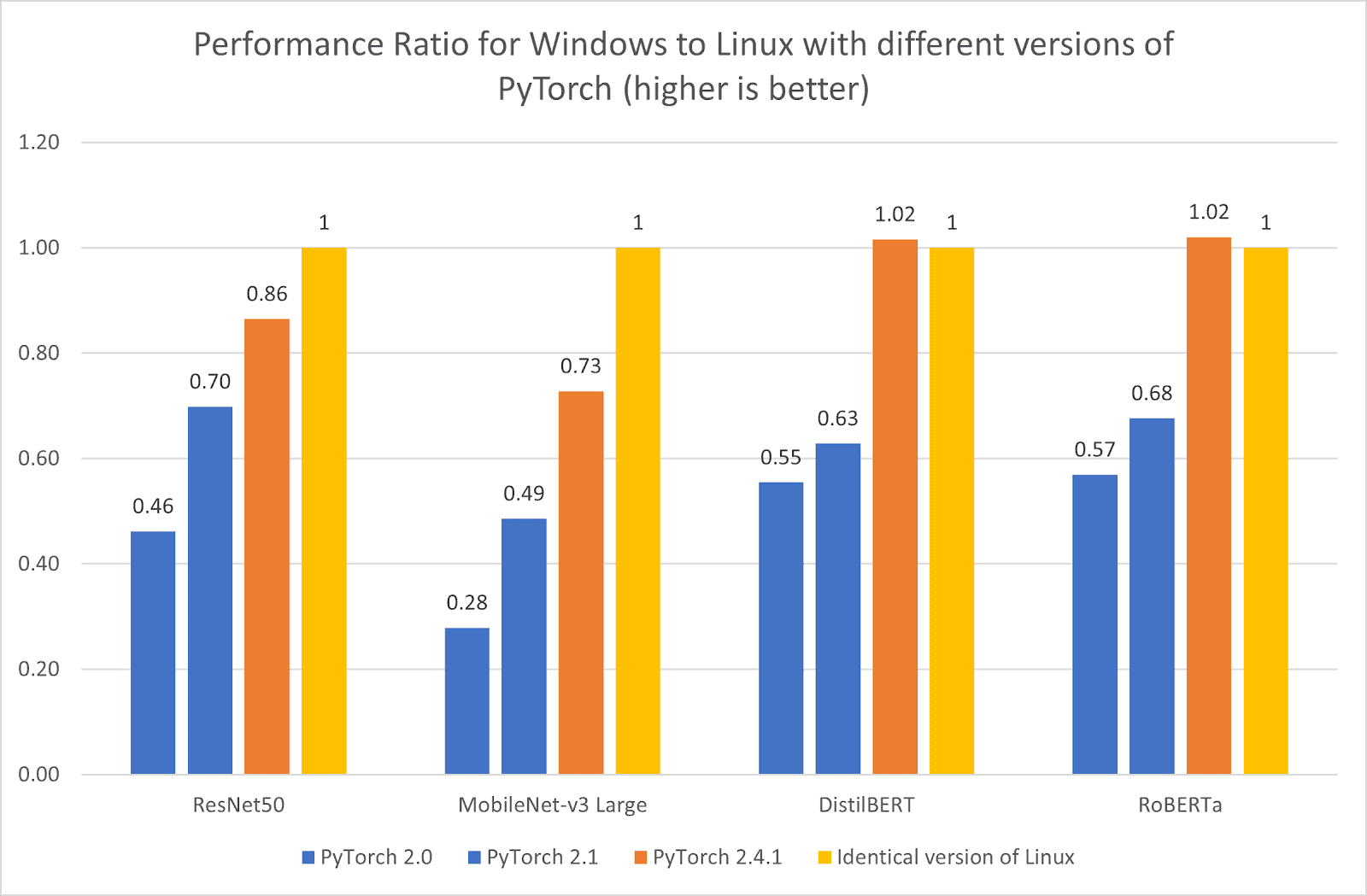
 Emmett Goodman is an Applied Scientist at the Amazon Generative AI Innovation Center. He specializes in computer vision and language modeling, with applications in healthcare, energy, and education. Emmett holds a PhD in Chemical Engineering from Stanford University, where he also completed a postdoctoral fellowship focused on computer vision and healthcare.
Emmett Goodman is an Applied Scientist at the Amazon Generative AI Innovation Center. He specializes in computer vision and language modeling, with applications in healthcare, energy, and education. Emmett holds a PhD in Chemical Engineering from Stanford University, where he also completed a postdoctoral fellowship focused on computer vision and healthcare. Negin Sokhandan is a Principle Applied Scientist at the AWS Generative AI Innovation Center, where she works on building generative AI solutions for AWS strategic customers. Her research background is statistical inference, computer vision, and multimodal systems.
Negin Sokhandan is a Principle Applied Scientist at the AWS Generative AI Innovation Center, where she works on building generative AI solutions for AWS strategic customers. Her research background is statistical inference, computer vision, and multimodal systems. Yanxiang Yu is an Applied Scientist at the Amazon Generative AI Innovation Center. With over 9 years of experience building AI and machine learning solutions for industrial applications, he specializes in generative AI, computer vision, and time series modeling.
Yanxiang Yu is an Applied Scientist at the Amazon Generative AI Innovation Center. With over 9 years of experience building AI and machine learning solutions for industrial applications, he specializes in generative AI, computer vision, and time series modeling.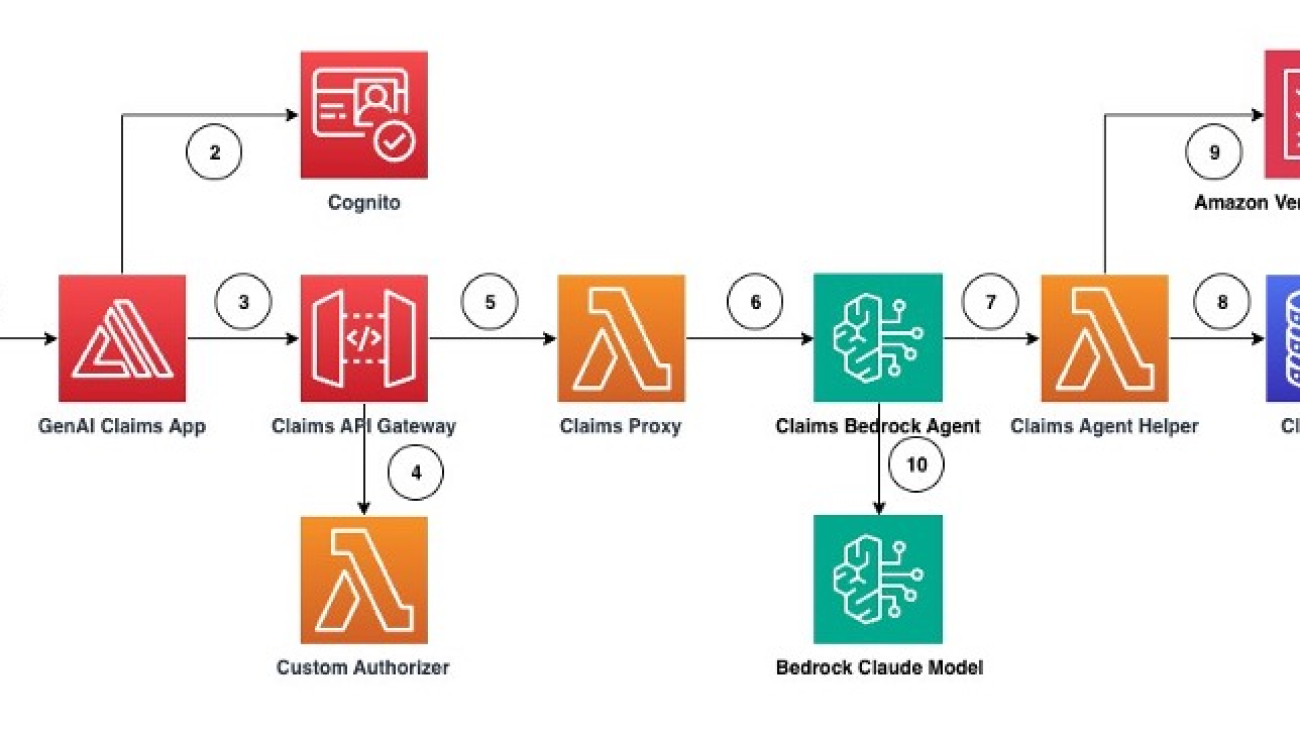








 Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure, scalable, reliable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his three-year old sheep-a-doodle!
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure, scalable, reliable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his three-year old sheep-a-doodle! Samantha Wylatowska is a Solutions Architect at AWS. With a background in DevSecOps, her passion lies in guiding organizations towards secure operational efficiency, leveraging the power of automation for a seamless cloud experience. In her free time, she’s usually learning something new through music, literature, or film.
Samantha Wylatowska is a Solutions Architect at AWS. With a background in DevSecOps, her passion lies in guiding organizations towards secure operational efficiency, leveraging the power of automation for a seamless cloud experience. In her free time, she’s usually learning something new through music, literature, or film. Anil Nadiminti is a Senior Solutions Architect at AWS specializing in empowering organizations to harness cloud computing and AI for digital transformation and innovation. His expertise in architecting scalable solutions and implementing data-driven strategies enables companies to innovate and thrive in today’s rapidly evolving technological landscape.
Anil Nadiminti is a Senior Solutions Architect at AWS specializing in empowering organizations to harness cloud computing and AI for digital transformation and innovation. His expertise in architecting scalable solutions and implementing data-driven strategies enables companies to innovate and thrive in today’s rapidly evolving technological landscape. Michael Daniels is an AI/ML Specialist at AWS. His expertise lies in building and leading AI/ML and generative AI solutions for complex and challenging business problems, which is enhanced by his PhD from the Univ. of Texas and his MSc in computer science specialization in machine learning from the Georgia Institute of Technology. He excels in applying cutting-edge cloud technologies to innovate, inspire, and transform industry-leading organizations while also effectively communicating with stakeholders at any level or scale. In his spare time, you can catch Michael skiing or snowboarding.
Michael Daniels is an AI/ML Specialist at AWS. His expertise lies in building and leading AI/ML and generative AI solutions for complex and challenging business problems, which is enhanced by his PhD from the Univ. of Texas and his MSc in computer science specialization in machine learning from the Georgia Institute of Technology. He excels in applying cutting-edge cloud technologies to innovate, inspire, and transform industry-leading organizations while also effectively communicating with stakeholders at any level or scale. In his spare time, you can catch Michael skiing or snowboarding. Maira Ladeira Tanke is a Senior Generative AI Data Scientist at AWS. With a background in machine learning, she has over 10 years of experience architecting and building AI applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through generative AI solutions on Amazon Bedrock. In her free time, Maira enjoys traveling, playing with her cat, and spending time with her family someplace warm.
Maira Ladeira Tanke is a Senior Generative AI Data Scientist at AWS. With a background in machine learning, she has over 10 years of experience architecting and building AI applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through generative AI solutions on Amazon Bedrock. In her free time, Maira enjoys traveling, playing with her cat, and spending time with her family someplace warm.