In this post, we present a solution that harnesses the power of generative AI to streamline the user onboarding process for financial services through a digital assistant. Onboarding new customers in the banking industry is a crucial step in the customer journey, involving a series of activities designed to fulfill know your customer (KYC) requirements, conduct necessary verifications, and introduce them to the bank’s products or services. Traditionally, customer onboarding has been a tedious and heavily manual process. Our solution provides practical guidance on addressing this challenge by using a generative AI assistant on AWS.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. Using Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock, we build a digital assistant that automates document processing, identity verifications, and engages customers through conversational interactions. As a result, customers can be onboarded in a matter of minutes through secure, automated workflows. In this post we provide you a solution and the accompanying code that banks can use to dramatically enhance the customer experience and establish a strong customer relationship from the outset.
Challenges with traditional onboarding
The traditional onboarding process for banks faces challenges in the current digital landscape because many institutions don’t have fully automated account-opening systems. While customers in other sectors have access to intelligent assistants, those in banking often encounter legacy processes. As the financial services industry adapts to changing consumer expectations, there’s a need to address the demand for instant and 24/7 availability of services.
The challenges associated with the manual onboarding process include but aren’t limited to, the following:
- Time-consuming paperwork – New customers are asked to manually fill out extensive paperwork including account opening forms, disclosures, and so on. Reviewing physical documents also takes up valuable staff time. This lengthy paperwork process can result in slow onboarding and a poor customer experience.
- Security risks – Paper documents and in-person ID verification lack security compared to digital processes because of their susceptibility to tampering, loss, and lack of traceability. For example, there’s a greater risk of identity theft and fraud with physical documents, because they can be altered or misplaced without leaving an audit trail.
- Accessibility issues – Requiring in-person account opening at branches can create accessibility challenges for many customers, including senior citizens and disabled individuals.
- Limited service hours – The account opening process is available only during branch operating hours, which limits the timeframe when customers can complete the onboarding process. This constraint impacts the flexibility for customers to initiate account opening at their preferred time.
- High costs – Manual paperwork processing and in-person verification are labor-intensive tasks that require significant staff time and resources, leading to high operational costs.
AI-powered services enable automated, secure, and compliant processes for self-service account opening. Providing onboarding experiences aligned with current digital standards might offer a competitive edge for banks in the future.
Solution overview
The solution allows users to open bank accounts remotely through a conversational interface, eliminating the need to visit a physical branch. We created a digital assistant named Penny to guide users through the process, including uploading KYC documents and facilitating identity verification using document scanning and facial recognition. The approach uses Retrieval Augmented Generation (RAG), which combines text generation capabilities with database querying to provide contextually relevant responses to customer inquiries. Implementing digital onboarding reduces the accessibility barriers present in traditional manual account opening processes. The code for this solution is available in a GitHub repository.
The brain of our application is a custom LangChain Agent. When a user wants to open a new bank account, the agent will help them complete the onboarding process using preconfigured stages corresponding to each onboarding step. Each stage might use a LangChain tool, allowing for the automation and orchestration of onboarding. These tools call on AWS service APIs for the required functionality.
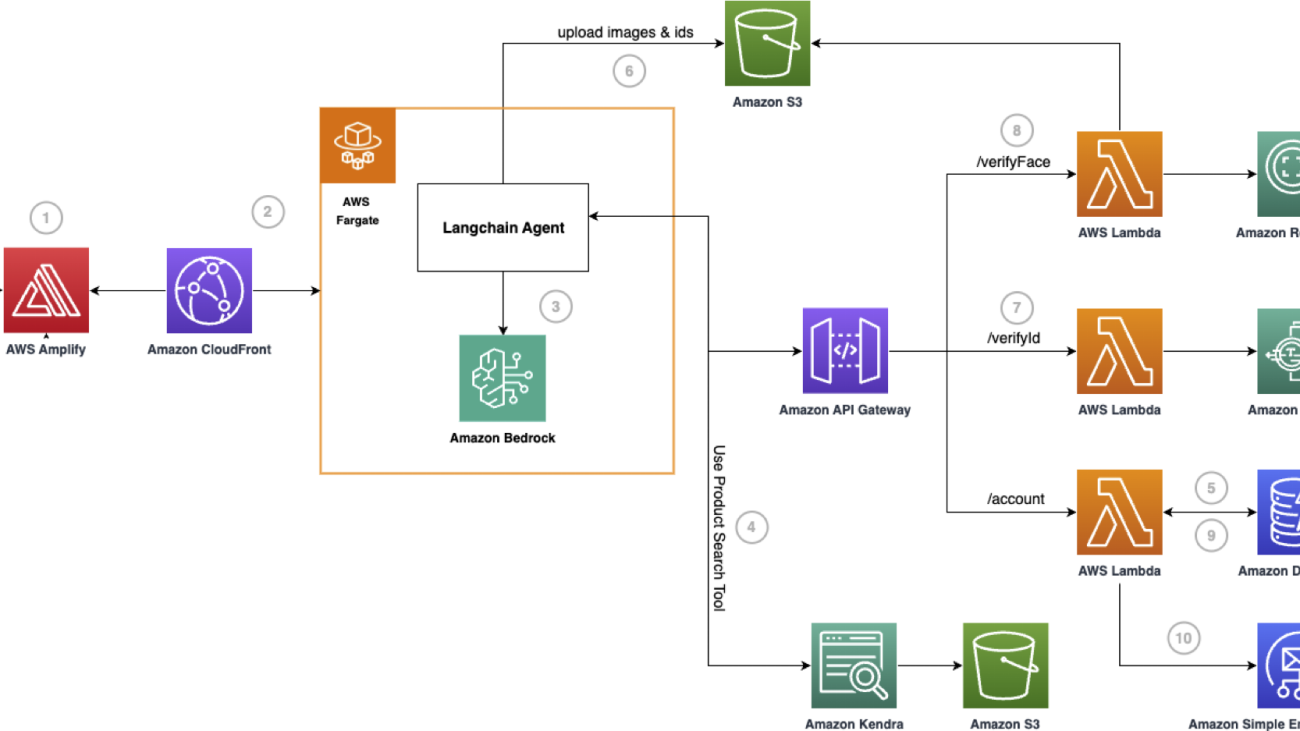
The following figure represents the high-level architecture of the proposed solution.

The flow of the application is as follows:
- Users access the frontend website hosted within AWS Amplify. AWS Amplify is an end-to-end solution that enables frontend web developers to build and deploy secure, scalable full stack applications.
- The website invokes an Amazon CloudFront endpoint to interact with the digital assistant, Penny, which is containerized and deployed in AWS Fargate. Fargate is a serverless compute engine for containers that manages and scales your containers for you, compatible with Amazon Elastic Container Service (Amazon ECS).
- The digital assistant uses a custom LangChain agent to answer questions on the bank’s products and services and orchestrate the onboarding flow.
- If the user asks a general question related to the bank’s products or service, the agent will use a custom LangChain tool called ProductSearch. This tool uses Amazon Kendra linked with an Amazon Simple Storage Service (Amason S3) data source that contains the bank’s data. Amazon Kendra is an intelligent enterprise search service powered by machine learning that enables companies to index and search content across their document stores.
- If the user indicates that they want to open a new account, the agent will prompt the user for their email. After the user responds, the application will invoke a custom LangChain tool called EmailValidation. This tools checks if there is an existing account in the bank’s Amazon DynamoDB database, by calling an endpoint deployed in Amazon API Gateway.
- After the email validation, KYC information is gathered, such as first and last name. Then, the user is prompted for an identity document, which is uploaded to Amazon S3.
- The agent will invoke a custom LangChain tool called IDVerification. This tool checks if the user details entered during the session match the ID by calling an endpoint deployed in Amazon API Gateway. The details are verified by extracting the document text using Amazon Textract, a machine learning (ML) service that automatically extracts text, handwriting, layout elements, and data from scanned documents.
- After the ID verification, the user is asked for a selfie. The image is uploaded to Amazon S3. Then, the agent will invoke a custom LangChain tool called SelfieVerification. This tool checks if the uploaded selfie matches the face on the ID by calling an endpoint deployed in API Gateway. The face match is detected using Amazon Rekognition, which offers pre-trained and customizable computer vision (CV) capabilities to extract information and insights from your images and videos.
- After the face verification is successful, the agent will use a custom LangChain tool called SaveData. This tool creates a new account in the bank’s DynamoDB database by calling an endpoint deployed in API Gateway.
- The user is notified that their new account has been created successfully, using Amazon Simple Email Service (Amazon SES).
Prompt design for agent orchestration
Now, let’s take a look at how we give our digital assistant, Penny, the capability to handle onboarding for financial services. The key is the prompt engineering for the custom LangChain agent. This has been specified in PennyAgent.py. This prompt includes onboarding stages and relevant LangChain tools that the agent might need to complete the onboarding steps.
To begin, we provide the agent with a name, role and company.
Next, we define the various stages of onboarding and specify the respective tools and expected responses. Having stages in a sequential and structured format while also providing awareness of all possible stages helps the agent determine the onboarding stage with accuracy.
We append the tools, their descriptions, and their response formats to the prompt. When calling on a specific tool, the agent can generate input parameters as required. Access to all the tools helps the agent identify the best tool choice based on the conversation stage.
We include some guidelines that the agent needs to follow while generating outputs. By using emotion-based prompt engineering, we minimize hallucinations and deviation from expected outputs. These guidelines were chosen after extensive testing to minimize edge cases and help prevent common agent mistakes.
The agent uses the ReAct framework to make decisions about how to respond based on user input. ReAct provides the agent with a thinking structure, through which it selects the most appropriate tool for a given task. Such frameworks make LLM agents versatile and adaptable to different use cases.
Based on the stage descriptions and the tools available, if the LLM generates a response that requires access to an external tool, then the response of the LLM will include Thought, Decision, Action, Action Input and Observation. The agent comes with a string matcher, which will detect Action and Action Input from the LLM’s response and trigger the respective tool. Based on the response from the tool, the LLM with decide whether to proceed with the Final Answer, and then the output will be returned by the agent.
Finally, we give the agent access to the conversation history to better decide what stage the conversation is currently in. In addition, we also give access to an agent scratchpad where it can store its thought processes to execute certain actions.
Orchestrating intelligent digital assistants requires thoughtful prompt engineering to handle complex tasks. By structuring the conversation into stages, providing tooling, and setting guidelines, we enable the assistant to systematically complete the onboarding process. This approach allows assistants to scale across use cases while maintaining accuracy. With the right guardrails, assistants can deliver smooth, trustworthy customer experiences.
Prompt design is key to unlocking the versatility of LLMs for real-world automation. Amazon Bedrock Prompt Management can be used to streamline the creation, evaluation, versioning and testing of prompts. This will help developers and prompt engineers save time by applying the same prompt to different onboarding processes. When you create a prompt, you can select a different model for inference and adjust the variables to obtain the best-suited results for a variety of workflows.
The following sections explain how to deploy the solution in your AWS account.
Note: Running this workload would have an estimated hourly cost of $1.34 for the Oregon (us-west-2) AWS Region. Check the pricing details for each service to understand the costs you might be charged for different usage tiers and resource configurations.
Setup
To deploy the agent, visit the project Github Repository, and use the following instructions:
- Ensure the pre-requisites are completed as mentioned in the README.
- Deploy the solution including the agent, tools infrastructure, and demo application—in that order—based on the instructions in the README.
- After the deployment is successful, visit the outputted domain where the demo application is running. You can now begin testing the agent.
Testing the agent
Begin your exploration by accessing the Amplify endpoint where the demonstration is hosted. The demonstration incorporates an interactive chat interface, enabling you to engage in a conversational exchange with the digital assistant, Penny. Whenever you want to initiate a new instance of the agent, refresh the web page.
Let’s start talking to Penny:
- Enter
Hi
Penny will respond with a friendly greeting
- Enter
What are the cutoff times to receive wire transfers on the same day?
Penny will use the ProductSearch tool to find the relevant information from the loaded product catalog. You can try asking other questions about the bank’s product or services including the AnyBank Travel Rewards Visa Infinite Card or New Vehicle Loans.
- Enter
I would like to open a new bank account
Penny will recognize that the account opening flow needs to be initiated and will proceed with the first step, which is asking you for an email address.

- Enter the verified customer email you registered with the Amazon SES identity. For our demonstration, we will use
anup@test.com(parameterSesCustomerEmailused in the example command to setup infrastructure)
Penny will take the email address and run the EmailValidation Tool. If there is an existing account with this email, it will ask you to retry. Otherwise, it will move on to the next step which is gathering your account type.
- Enter
I want a savings accountor indicate that you want a checking account.
Penny will record your account type and move on to the KYC questions.
- Enter
Anup
Penny will record your first name and continue gathering the remaining KYC information.

- Enter
Ravi
It will record your last name and prompt you for an ID next. We used Ravi to match the ID document provided below.
- Download the picture ID. It’s also located at
./api/lambdas/test/passport.png

Upload it to the chat by selecting Choose File.
After uploading the image, you will receive a confirmation message on the chat stating We have received your document. Penny will use ID Verification to compare the name entered during the session to the document. After verification is complete, Penny will prompt you to upload a selfie.
- Upload the selfie located at
./api/lambdas/test/selfie.pngto the chat by selecting Choose File.

After the upload is complete, you will receive a confirmation message on the chat stating We have received your document. Penny will use Selfie Verification to compare the face on the ID to the selfie for a face match. After verification is complete, Penny will prompt you to confirm that you want to proceed.

- Enter
Yes I confirm

Penny will use Create Account to complete the onboarding process and send an email confirmation. It will inform to you of this update in the chat.

Check the customer email you used. The email address specified as the SesCustomerEmail parameter (in this example: anup@test.com) during setup will receive a new email from the email address you set as the SesBankEmail parameter (in this example: owner@anybank.com).
- Go to the DynamoDB console, select Table from the navigation pane and select the table created by the AWS CloudFormation This is the accounts table in the bank’s AWS account. From the Table page, choose Explore items. You will see a new account created with the details that you entered.

Guardrails and security
Security is a critical part of any application and must be rigorously addressed when developing and deploying solutions, especially those that involve handling sensitive data or interacting with users. For a solution similar to the example in this post, several robust security measures should be implemented to maintain the confidentiality, integrity, and availability of the system.
- Address the security of the service itself. One approach to mitigate potential biases, toxicity, or other undesirable outputs is to use Constitutional AI techniques, such as those provided by the LangChain library or Guardrails for Amazon Bedrock. By defining and enforcing a set of rules or constraints, the system can be trained to generate outputs that align with predefined ethical principles and values, thereby enhancing the trustworthiness and reliability of the service.
- To maintain data protection and privacy, implementing a write-only database architecture is recommended. In this setup, the agent or service can write data to the database but is prohibited from reading or retrieving sensitive stored information. This measure effectively isolates sensitive user data, making sure that the agent would be unable to access or disclose confidential details even in the event of a compromise.
- Prompt injection attacks, where malicious inputs are crafted to manipulate the system’s behavior, are a serious concern in conversational AI systems. To mitigate this risk, it’s crucial to implement robust input validation and sanitization mechanisms. This could include techniques like whitelisting permissible characters, filtering out potentially harmful patterns, and employing context-aware input processing.
- Secure coding practices, such as input validation, output encoding, and proper error handling, should be rigorously followed throughout the development process. Regular security audits, penetration testing, and vulnerability assessments should be conducted to identify and address potential weaknesses in the system.
- Amazon API Gateway, a fully managed service, securely handles API traffic, acting as a front door for applications running on AWS. It supports multiple security mechanisms, including AWS Identity and Access Management (IAM) for authentication and authorization, AWS WAF for web application protection, AWS Secrets Manager for securely storing and retrieving secrets, and integration with AWS CloudTrail for API activity logging. API Gateway also supports client-side SSL certificates, API keys, and resource policies for granular access control.
- Communication between users, the solution, and its internal dependencies should be protected using TLS to encrypt data in transit.
- Additionally, the data should be encrypted using data-at-rest encryption with AWS Key Management Service (AWS KMS) customer managed keys (CMK).
By implementing these robust security measures and fostering a culture of continuous security awareness and improvement, the solution can better protect against potential threats, safeguard user privacy, and maintain the integrity and reliability of the service.
Cleanup
Follow the cleanup Instructions in the README of the Github repository to remove the environment from your account.
Conclusion
In this post, we presented an end-to-end solution that demonstrates how banks can transform user onboarding with an AI-powered digital assistant. By orchestrating workflows across AWS services, we enabled automated, secure account opening within minutes. The conversational interface delivers exceptional customer experiences while reducing operational costs.
This solution can be quickly deployed and enhanced using the features of Amazon Bedrock. Amazon Bedrock Agents streamlines workflows by executing multistep tasks and integrating with company systems and data sources. Amazon Bedrock Knowledge Bases provides contextual information from proprietary data sources, enhancing the accuracy and relevance of responses. Additionally, Amazon Bedrock Guardrails implements safeguards to enable responsible AI usage, filtering harmful content and protecting sensitive information. These can enable a robust and secure deployment of an AI-powered onboarding solution.
Key outcomes of this solution include:
- Fully digital onboarding without paper forms or branch visits
- Automated KYC verification using documents and facial recognition
- Customers onboarded securely in minutes with email confirmations
- Lower costs by reducing manual verification workloads
- Personalized assistance for any product questions 24/7
Instant, secure, and scalable delivery has become the norm that customers demand. This AI assistant solution, powered by AWS, showcases the potential future of user onboarding for financial institutions. As consumer behaviors and expectations continue to be influenced by the latest digital experiences across industries, banks that invest in advanced technologies will gain a competitive edge over their rivals.
Ready to future proof your banking experience? Visit Artificial Intelligence and Machine learning for Financial services with AWS.
About the authors
 Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada working with Financial Services organizations. He helps customers to transform their businesses and innovate on cloud.
Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada working with Financial Services organizations. He helps customers to transform their businesses and innovate on cloud.
 Arya Subramanyam is a Solutions Architect based in Toronto, Canada. She works with Enterprise Greenfield customers as well as Small & Medium businesses as a technical advisor, helping them solve business challenges with cloud solutions. Arya holds a Bachelor of Applied Science in Computer Engineering from the University of British Columbia, Vancouver. Her passion for Generative AI has led her to develop various solutions leveraging Large Language Models (LLMs) with a focus on prompt engineering and AI agents.
Arya Subramanyam is a Solutions Architect based in Toronto, Canada. She works with Enterprise Greenfield customers as well as Small & Medium businesses as a technical advisor, helping them solve business challenges with cloud solutions. Arya holds a Bachelor of Applied Science in Computer Engineering from the University of British Columbia, Vancouver. Her passion for Generative AI has led her to develop various solutions leveraging Large Language Models (LLMs) with a focus on prompt engineering and AI agents.
 Venkata Satyanarayana Chivatam is a Solutions Architect at AWS. He specializes in Generative AI and Computer Vision, with a particular focus on driving adoption across industries such as healthcare and finance. At AWS, he helps ISV and SMB customers leverage cutting-edge AI technologies to unlock new possibilities and solve complex challenges. He is passionate about supporting businesses of all sizes in their AI journey.
Venkata Satyanarayana Chivatam is a Solutions Architect at AWS. He specializes in Generative AI and Computer Vision, with a particular focus on driving adoption across industries such as healthcare and finance. At AWS, he helps ISV and SMB customers leverage cutting-edge AI technologies to unlock new possibilities and solve complex challenges. He is passionate about supporting businesses of all sizes in their AI journey.
 Akshata Ramesh Rao is a Solutions Architect in Toronto, Canada. Akshata works with enterprise customers to accelerate innovation and advise them through technical challenges. She also loves working with SMB customers and help them reach their business objectives quickly, safely, and cost-effectively with AWS services, frameworks, and best practices. Prior to joining AWS, Akshata worked as Devops Engineer at Amazon and holds a master’s degree in computer science from University of Ottawa.
Akshata Ramesh Rao is a Solutions Architect in Toronto, Canada. Akshata works with enterprise customers to accelerate innovation and advise them through technical challenges. She also loves working with SMB customers and help them reach their business objectives quickly, safely, and cost-effectively with AWS services, frameworks, and best practices. Prior to joining AWS, Akshata worked as Devops Engineer at Amazon and holds a master’s degree in computer science from University of Ottawa.
 Here are seven of Google’s latest AI updates from September.
Here are seven of Google’s latest AI updates from September.