Large Language Models (LLMs) are regularly updated to enhance performance, typically through changes in data or architecture. Within the update process, developers often prioritize improving overall performance metrics, paying less attention to maintaining compatibility with earlier model versions. Instance-level degradation (instance regression) of performance from one model version to the next can interfere with a user’s mental model of the capabilities of a particular language model. Users having to adapt their mental model with every update can lead to dissatisfaction, especially when the…Apple Machine Learning Research

NVIDIA CEO Jensen Huang to Spotlight Innovation at India’s AI Summit
The NVIDIA AI Summit India, taking place Oct. 23–25 at the Jio World Convention Centre in Mumbai, will bring together the brightest minds to explore how India is tackling the world’s grand challenges.
A major highlight: a fireside chat with NVIDIA founder and CEO Jensen Huang on October 24. He’ll share his insights on AI’s pivotal role in reshaping industries and how India is emerging as a global AI leader, and be joined by the chairman and managing director of Reliance Industries, Mukesh Ambani.
Passes for the event are sold out. But don’t worry — audiences can tune in via livestream or watch on-demand sessions at NVIDIA AI Summit.
With over 50 sessions, live demos and hands-on workshops, the event will showcase AI’s transformative impact across industries like robotics, supercomputing and industrial digitalization.
It will explore opportunities both globally and locally in India. Over 70% of the use cases discussed will focus on how AI can address India’s most pressing challenges.
India’s AI Journey
India’s rise to become a global AI leader is powered by its focus on building AI infrastructure and foundational models.
NVIDIA’s accelerated computing platform, now 100,000x more energy-efficient for processing large language models than a decade ago, is driving this progress.
If car efficiency had improved at the same rate, vehicles today would get 280,000 miles per gallon — enough to drive to the moon with a single gallon of gas.
As India solidifies its place in AI leadership, the summit will tackle key topics.
These include building AI infrastructure with NVIDIA’s advanced GPUs, harnessing foundational models for Indian languages, fueling innovation in India’s startup ecosystem and upskilling developers to take the country’s workforce to the AI front office. The momentum is undeniable.
India’s AI Summit: Driving Innovation, Solving Grand Challenges
NVIDIA is at the heart of India’s rise as an AI powerhouse.
With six locations across the country hosting over 4,000 employees, NVIDIA plays a central role in the country’s rapid progress in AI.
The company works with enterprises, cloud providers and startups to build AI infrastructure powered by NVIDIA’s accelerated computing stack comprising tens of thousands of its most advanced GPUs, high-performance networking, and AI software platforms and tools.
The summit will feature sessions on how this infrastructure empowers sectors like healthcare, agriculture, education and manufacturing.
Jensen Huang’s Fireside Chat
The fireside chat with Huang on October 24 is a must-watch.
He’ll discuss how AI is revolutionizing industries worldwide and India’s increasingly important role as a global AI leader.
To hear his thoughts firsthand, tune in to the livestream or catch the session on demand for insights from one of the most influential figures in AI.
Key Sessions and Speakers
Top industry experts like Niki Parmar (Essential AI), Deepu Talla (NVIDIA) and Abhinav Aggarwal (Fluid AI) will dive into a range of game-changing topics, including:
- Generative AI and large language models (LLMs): Discover innovations in video synthesis and high-quality data models for large-scale inference.
- Robotics and industrial efficiency: See how AI-powered robotics tackle automation challenges in manufacturing and warehouse operations.
- AI in healthcare: Learn how AI transforms diagnostics and treatments, improving outcomes across India’s healthcare system.
These sessions will also introduce cutting-edge NVIDIA AI networking technologies, essential for building next-gen AI data centers.
Workshops and Startup Innovation
India’s vibrant startup ecosystem will be in the spotlight at the summit.
Nearly 2,000 companies in India are part of NVIDIA Inception, a program that supports startups driving innovation in AI and other fields.
Onsite workshops at the AI Summit will offer hands-on experiences with NVIDIA’s advanced AI tools, giving developers and startups practical skills to push the boundaries of innovation.
Meanwhile, Reverse VC Pitches will provide startups with unique insights as venture capital firms pitch their visions for the future, sparking fresh ideas and collaborations.
Industrial AI and Manufacturing Innovation
NVIDIA is also backing India’s industrial expansion by deploying AI technologies like Omniverse and Isaac.
These tools are enhancing everything from factory planning to manufacturing and construction, helping build greenfield factories that are more efficient and sustainable.
These technologies integrate advanced AI capabilities into factory operations, cutting costs while boosting sustainability.
Through hands-on workshops and deep industry insights, participants will see how India is positioning itself to lead the world in AI innovation.
Join the livestream or explore sessions on demand at NVIDIA AI Summit.

NVIDIA CEO Jensen Huang to Spotlight Innovation at India’s AI Summit
The NVIDIA AI Summit India, taking place Oct. 23–25 at the Jio World Convention Centre in Mumbai, will bring together the brightest minds to explore how India is tackling the world’s grand challenges.
A major highlight: a fireside chat with NVIDIA founder and CEO Jensen Huang on October 24. He’ll share his insights on AI’s pivotal role in reshaping industries and how India is emerging as a global AI leader, and be joined by the chairman and managing director of Reliance Industries, Mukesh Ambani.
Passes for the event are sold out. But don’t worry — audiences can tune in via livestream or watch on-demand sessions at NVIDIA AI Summit.
With over 50 sessions, live demos and hands-on workshops, the event will showcase AI’s transformative impact across industries like robotics, supercomputing and industrial digitalization.
It will explore opportunities both globally and locally in India. Over 70% of the use cases discussed will focus on how AI can address India’s most pressing challenges.
India’s AI Journey
India’s rise to become a global AI leader is powered by its focus on building AI infrastructure and foundational models.
NVIDIA’s accelerated computing platform, now 100,000x more energy-efficient for processing large language models than a decade ago, is driving this progress.
If car efficiency had improved at the same rate, vehicles today would get 280,000 miles per gallon — enough to drive to the moon with a single gallon of gas.
As India solidifies its place in AI leadership, the summit will tackle key topics.
These include building AI infrastructure with NVIDIA’s advanced GPUs, harnessing foundational models for Indian languages, fueling innovation in India’s startup ecosystem and upskilling developers to take the country’s workforce to the AI front office. The momentum is undeniable.
India’s AI Summit: Driving Innovation, Solving Grand Challenges
NVIDIA is at the heart of India’s rise as an AI powerhouse.
With six locations across the country hosting over 4,000 employees, NVIDIA plays a central role in the country’s rapid progress in AI.
The company works with enterprises, cloud providers and startups to build AI infrastructure powered by NVIDIA’s accelerated computing stack comprising tens of thousands of its most advanced GPUs, high-performance networking, and AI software platforms and tools.
The summit will feature sessions on how this infrastructure empowers sectors like healthcare, agriculture, education and manufacturing.
Jensen Huang’s Fireside Chat
The fireside chat with Huang on October 24 is a must-watch.
He’ll discuss how AI is revolutionizing industries worldwide and India’s increasingly important role as a global AI leader.
To hear his thoughts firsthand, tune in to the livestream or catch the session on demand for insights from one of the most influential figures in AI.
Key Sessions and Speakers
Top industry experts like Niki Parmar (Essential AI), Deepu Talla (NVIDIA) and Abhinav Aggarwal (Fluid AI) will dive into a range of game-changing topics, including:
- Generative AI and large language models (LLMs): Discover innovations in video synthesis and high-quality data models for large-scale inference.
- Robotics and industrial efficiency: See how AI-powered robotics tackle automation challenges in manufacturing and warehouse operations.
- AI in healthcare: Learn how AI transforms diagnostics and treatments, improving outcomes across India’s healthcare system.
These sessions will also introduce cutting-edge NVIDIA AI networking technologies, essential for building next-gen AI data centers.
Workshops and Startup Innovation
India’s vibrant startup ecosystem will be in the spotlight at the summit.
Nearly 2,000 companies in India are part of NVIDIA Inception, a program that supports startups driving innovation in AI and other fields.
Onsite workshops at the AI Summit will offer hands-on experiences with NVIDIA’s advanced AI tools, giving developers and startups practical skills to push the boundaries of innovation.
Meanwhile, Reverse VC Pitches will provide startups with unique insights as venture capital firms pitch their visions for the future, sparking fresh ideas and collaborations.
Industrial AI and Manufacturing Innovation
NVIDIA is also backing India’s industrial expansion by deploying AI technologies like Omniverse and Isaac.
These tools are enhancing everything from factory planning to manufacturing and construction, helping build greenfield factories that are more efficient and sustainable.
These technologies integrate advanced AI capabilities into factory operations, cutting costs while boosting sustainability.
Through hands-on workshops and deep industry insights, participants will see how India is positioning itself to lead the world in AI innovation.
Join the livestream or explore sessions on demand at NVIDIA AI Summit.
Generative AI foundation model training on Amazon SageMaker
To stay competitive, businesses across industries use foundation models (FMs) to transform their applications. Although FMs offer impressive out-of-the-box capabilities, achieving a true competitive edge often requires deep model customization through pre-training or fine-tuning. However, these approaches demand advanced AI expertise, high performance compute, fast storage access and can be prohibitively expensive for many organizations.
In this post, we explore how organizations can address these challenges and cost-effectively customize and adapt FMs using AWS managed services such as Amazon SageMaker training jobs and Amazon SageMaker HyperPod. We discuss how these powerful tools enable organizations to optimize compute resources and reduce the complexity of model training and fine-tuning. We explore how you can make an informed decision about which Amazon SageMaker service is most applicable to your business needs and requirements.
Business challenge
Businesses today face numerous challenges in effectively implementing and managing machine learning (ML) initiatives. These challenges include scaling operations to handle rapidly growing data and models, accelerating the development of ML solutions, and managing complex infrastructure without diverting focus from core business objectives. Additionally, organizations must navigate cost optimization, maintain data security and compliance, and democratize both ease of use and access of machine learning tools across teams.
Customers have built their own ML architectures on bare metal machines using open source solutions such as Kubernetes, Slurm, and others. Although this approach provides control over the infrastructure, the amount of effort needed to manage and maintain the underlying infrastructure (for example, hardware failures) over time can be substantial. Organizations often underestimate the complexity involved in integrating these various components, maintaining security and compliance, and keeping the system up-to-date and optimized for performance.
As a result, many companies struggle to use the full potential of ML while maintaining efficiency and innovation in a competitive landscape.
How Amazon SageMaker can help
Amazon SageMaker addresses these challenges by providing a fully managed service that streamlines and accelerates the entire ML lifecycle. You can use the comprehensive set of SageMaker tools for building and training your models at scale while offloading the management and maintenance of underlying infrastructure to SageMaker.
You can use SageMaker to scale your training cluster to thousands of accelerators, with your own choice of compute and optimize your workloads for performance with SageMaker distributed training libraries. For cluster resiliency, SageMaker offers self-healing capabilities that automatically detect and recover from faults, allowing for continuous FM training for months with little to no interruption and reducing training time by up to 40%. SageMaker also supports popular ML frameworks such as TensorFlow and PyTorch through managed pre-built containers. For those who need more customization, SageMaker also allows users to bring in their own libraries or containers.
To address various business and technical use cases, Amazon SageMaker offers two options for distributed pre-training and fine-tuning: SageMaker training jobs and SageMaker HyperPod.
SageMaker training jobs
SageMaker training jobs offer a managed user experience for large, distributed FM training, removing the undifferentiated heavy lifting around infrastructure management and cluster resiliency while offering a pay-as-you-go option. SageMaker training jobs automatically spin up a resilient distributed training cluster, provide managed orchestration, monitor the infrastructure, and automatically recovers from faults for a smooth training experience. After the training is complete, SageMaker spins down the cluster and the customer is billed for the net training time in seconds. FM builders can further optimize this experience by using SageMaker Managed Warm Pools, which allows you to retain and reuse provisioned infrastructure after the completion of a training job for reduced latency and faster iteration time between different ML experiments.
With SageMaker training jobs, FM builders have the flexibility to choose the right instance type to best fit an individual to further optimize their training budget. For example, you can pre-train a large language model (LLM) on a P5 cluster or fine-tune an open source LLM on p4d instances. This allows businesses to offer a consistent training user experience across ML teams with varying levels of technical expertise and different workload types.
Additionally, Amazon SageMaker training jobs integrate tools such as SageMaker Profiler for training job profiling, Amazon SageMaker with MLflow for managing ML experiments, Amazon CloudWatch for monitoring and alerts, and TensorBoard for debugging and analyzing training jobs. Together, these tools enhance model development by offering performance insights, tracking experiments, and facilitating proactive management of training processes.
AI21 Labs, Technology Innovation Institute, Upstage, and Bria AI chose SageMaker training jobs to train and fine-tune their FMs with the reduced total cost of ownership by offloading the workload orchestration and management of underlying compute to SageMaker. They delivered faster results by focusing their resources on model development and experimentation while SageMaker handled the provisioning, creation, and termination of their compute clusters.
The following demo provides a high-level, step-by-step guide to using Amazon SageMaker training jobs.

SageMaker HyperPod
SageMaker HyperPod offers persistent clusters with deep infrastructure control, which builders can use to connect through Secure Shell (SSH) into Amazon Elastic Compute Cloud (Amazon EC2) instances for advanced model training, infrastructure management, and debugging. To maximize availability, HyperPod maintains a pool of dedicated and spare instances (at no additional cost to the customer), minimizing downtime for critical node replacements. Customers can use familiar orchestration tools such as Slurm or Amazon Elastic Kubernetes Service (Amazon EKS), and the libraries built on top of these tools for flexible job scheduling and compute sharing. Additionally, orchestrating SageMaker HyperPod clusters with Slurm allows NVIDIA’s Enroot and Pyxis integration to quickly schedule containers as performant unprivileged sandboxes. The operating system and software stack are based on the Deep Learning AMI, which are preconfigured with NVIDIA CUDA, NVIDIA cuDNN, and the latest versions of PyTorch and TensorFlow. HyperPod also includes SageMaker distributed training libraries, which are optimized for AWS infrastructure so users can automatically split training workloads across thousands of accelerators for efficient parallel training.
FM builders can use built-in ML tools in HyperPod to enhance model performance, such as using Amazon SageMaker with TensorBoard to visualize model a model architecture and address convergence issues, while Amazon SageMaker Debugger captures real-time training metrics and profiles. Additionally, integrating with observability tools such as Amazon CloudWatch Container Insights, Amazon Managed Service for Prometheus, and Amazon Managed Grafana offer deeper insights into cluster performance, health, and utilization, saving valuable development time.
This self-healing, high-performance environment, trusted by customers like Articul8, IBM, Perplexity AI, Hugging Face, Luma, and Thomson Reuters, supports advanced ML workflows and internal optimizations.
The following demo provides a high-level, step-by-step guide to using Amazon SageMaker HyperPod.

Choosing the right option
For organizations that require granular control over training infrastructure and extensive customization options, SageMaker HyperPod is the ideal choice. HyperPod offers custom network configurations, flexible parallelism strategies, and support for custom orchestration techniques. It integrates seamlessly with tools such as Slurm, Amazon EKS, Nvidia’s Enroot, and Pyxis, and provides SSH access for in-depth debugging and custom configurations.
SageMaker training jobs are tailored for organizations that want to focus on model development rather than infrastructure management and prefer ease of use with a managed experience. SageMaker training jobs feature a user-friendly interface, simplified setup and scaling, automatic handling of distributed training tasks, built-in synchronization, checkpointing, fault tolerance, and abstraction of infrastructure complexities.
When choosing between SageMaker HyperPod and training jobs, organizations should align their decision with their specific training needs, workflow preferences, and desired level of control over the training infrastructure. HyperPod is the preferred option for those seeking deep technical control and extensive customization, and training jobs is ideal for organizations that prefer a streamlined, fully managed solution.
Conclusion
Learn more about Amazon SageMaker and large-scale distributed training on AWS by visiting Getting Started on Amazon SageMaker, watching the Generative AI on Amazon SageMaker Deep Dive Series, and exploring the awsome-distributed-training and amazon-sagemaker-examples GitHub repositories.
About the authors
 Trevor Harvey is a Principal Specialist in Generative AI at Amazon Web Services and an AWS Certified Solutions Architect – Professional. Trevor works with customers to design and implement machine learning solutions and leads go-to-market strategies for generative AI services.
Trevor Harvey is a Principal Specialist in Generative AI at Amazon Web Services and an AWS Certified Solutions Architect – Professional. Trevor works with customers to design and implement machine learning solutions and leads go-to-market strategies for generative AI services.
 Kanwaljit Khurmi is a Principal Generative AI/ML Solutions Architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
Kanwaljit Khurmi is a Principal Generative AI/ML Solutions Architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
 Miron Perel is a Principal Machine Learning Business Development Manager with Amazon Web Services. Miron advises Generative AI companies building their next generation models.
Miron Perel is a Principal Machine Learning Business Development Manager with Amazon Web Services. Miron advises Generative AI companies building their next generation models.
![]() Guillaume Mangeot is Senior WW GenAI Specialist Solutions Architect at Amazon Web Services with over one decade of experience in High Performance Computing (HPC). With a multidisciplinary background in applied mathematics, he leads highly scalable architecture design in cutting-edge fields such as GenAI, ML, HPC, and storage, across various verticals including oil & gas, research, life sciences, and insurance.
Guillaume Mangeot is Senior WW GenAI Specialist Solutions Architect at Amazon Web Services with over one decade of experience in High Performance Computing (HPC). With a multidisciplinary background in applied mathematics, he leads highly scalable architecture design in cutting-edge fields such as GenAI, ML, HPC, and storage, across various verticals including oil & gas, research, life sciences, and insurance.
Automate fine-tuning of Llama 3.x models with the new visual designer for Amazon SageMaker Pipelines
You can now create an end-to-end workflow to train, fine tune, evaluate, register, and deploy generative AI models with the visual designer for Amazon SageMaker Pipelines. SageMaker Pipelines is a serverless workflow orchestration service purpose-built for foundation model operations (FMOps). It accelerates your generative AI journey from prototype to production because you don’t need to learn about specialized workflow frameworks to automate model development or notebook execution at scale. Data scientists and machine learning (ML) engineers use pipelines for tasks such as continuous fine-tuning of large language models (LLMs) and scheduled notebook job workflows. Pipelines can scale up to run tens of thousands of workflows in parallel and scale down automatically depending on your workload.

Whether you are new to pipelines or are an experienced user looking to streamline your generative AI workflow, this step-by-step post will demonstrate how you can use the visual designer to enhance your productivity and simplify the process of building complex AI and machine learning (AI/ML) pipelines. Specifically, you will learn how to:
- Access and navigate the new visual designer in Amazon SageMaker Studio.
- Create a complete AI/ML pipeline for fine-tuning an LLM using drag-and-drop functionality.
- Configure the steps in the pipeline including the new model fine-tuning, model deployment, and notebook and code execution
- Implement conditional logic to automate decision-making based on a model’s performance.
- Register a successful model in the Amazon SageMaker Model Registry.
Llama fine-tuning pipeline overview
In this post, we will show you how to set up an automated LLM customization (fine-tuning) workflow so that the Llama 3.x models from Meta can provide a high-quality summary of SEC filings for financial applications. Fine-tuning allows you to configure LLMs to achieve improved performance on your domain-specific tasks. After fine-tuning, the Llama 3 8b model should be able to generate insightful financial summaries for its application users. But fine-tuning an LLM just once isn’t enough. You need to regularly tune the LLM to keep it up to date with the most recent real-world data, which in this case would be the latest SEC filings from companies. Instead of repeating this task manually each time new data is available (for example, once every quarter after earnings calls), you can create a Llama 3 fine-tuning workflow using SageMaker Pipelines that can be automatically triggered in the future. This will help you improve the quality of financial summaries produced by the LLM over time while ensuring accuracy, consistency, and reproducibility.
The SEC filings dataset is publicly available through an Amazon SageMaker JumpStart bucket. Here’s an overview of the steps to create the pipeline.
- Fine tune a Meta Llama 3 8B model from SageMaker JumpStart using the SEC financial dataset.
- Prepare the fine-tuned Llama 3 8B model for deployment to SageMaker Inference.
- Deploy the fine-tuned Llama 3 8B model to SageMaker Inference.
- Evaluate the performance of the fine-tuned model using the open-source Foundation Model Evaluations (fmeval) library
- Use a condition step to determine if the fine-tuned model meets your desired performance. If it does, register the fine-tuned model to the SageMaker Model Registry. If the performance of the fine-tuned model falls below the desired threshold, then the pipeline execution fails.

Prerequisites
To build this solution, you need the following prerequisites:
- An AWS account that will contain all your AWS resources.
- An AWS Identity and Access Management (IAM) role to access SageMaker. To learn more about how IAM works with SageMaker, see Identity and Access Management for Amazon SageMaker.
- Access to SageMaker Studio to access the SageMaker Pipelines visual editor. You first need to create a SageMaker domain and a user profile. See the Guide to getting set up with Amazon SageMaker.
- An ml.g5.12xlarge instance for endpoint usage to deploy the model to, and an ml.g5.12xlarge training instance to fine-tune the model. You might need to request a quota increase; see Requesting a quota increase for more information.
Accessing the visual editor
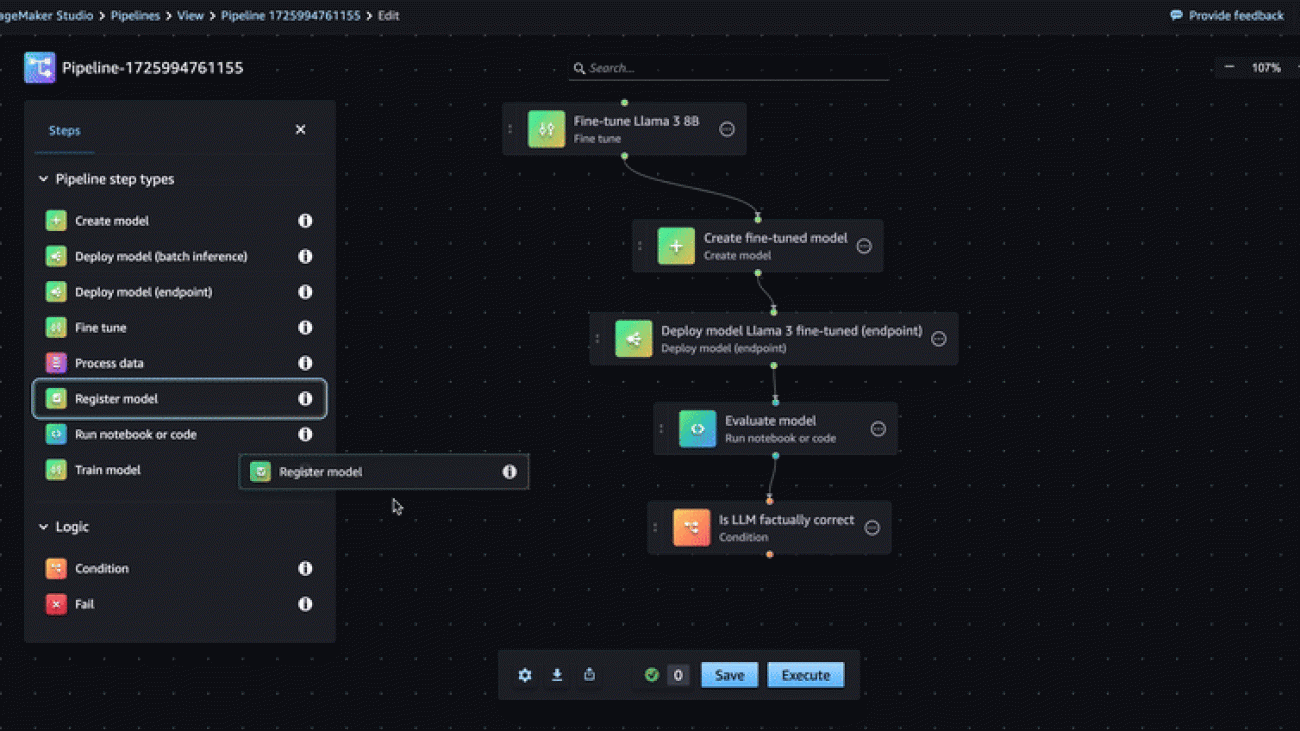
Access the visual editor in the SageMaker Studio console by choosing Pipelines in the navigation pane, and then selecting Create in visual editor on the right. SageMaker pipelines are composed of a set of steps. You will see a list of step types that the visual editor supports.

At any time while following this post, you can pause your pipeline building process, save your progress, and resume later. Download the pipeline definition as a JSON file to your local environment by choosing Export at the bottom of the visual editor. Later, you can resume building the pipeline by choosing Import button and re-uploading the JSON file.
Step #1: Fine tune the LLM
With the new editor, we introduce a convenient way to fine tune models from SageMaker JumpStart using the Fine tune step. To add the Fine tune step, drag it to the editor and then enter the following details:
- In the Model (input) section select Meta-Llama-3-8B. Scroll to the bottom of the window to accept the EULA and choose Save.
- The Model (output) section automatically populates the default Amazon Simple Storage Service (Amazon S3) You can update the S3 URI to change the location where the model artifacts will be stored.
- This example uses the default SEC dataset for training. You can also bring your own dataset by updating the Dataset (input)

- Choose the ml.g5.12x.large instance.
- Leave the default hyperparameter settings. These can be adjusted depending on your use case.
- Optional) You can update the name of the step on the Details tab under Step display name. For this example, update the step name to Fine tune Llama 3 8B.

Step #2: Prepare the fine-tuned LLM for deployment
Before you deploy the model to an endpoint, you will create the model definition, which includes the model artifacts and Docker container needed to host the model.
- Drag the Create model step to the editor.
- Connect the Fine tune step to the Create model step using the visual editor.
- Add the following details under the Settings tab:
- Choose an IAM role with the required permissions.
- Model (input):Step variable and Fine-tuning Model Artifacts.
- Container: Bring your own container and enter the image URI
dkr.ecr.<region_name>.amazonaws.com/djl-inference:0.28.0-lmi10.0.0-cu124(replace <region_name> with your AWS Region) as the Location (ECR URI). This example uses a large model inference container. You can learn more about the deep learning containers that are available on GitHub.

Step #3: Deploy the fine-tuned LLM
Next, deploy the model to a real-time inference endpoint.
- Drag the Deploy model (endpoint) step to the editor.
- Enter a name such as llama-fine-tune for the endpoint name.
- Connect this step to the Create model step using the visual editor.

- In the Model (input) section, select Inherit model. Under Model name, select Step variable and the Model Name variable should be populated from the previous step. Choose Save.

- Select g5.12xlarge instance as the Endpoint Type.

Step #4: Evaluate the fine-tuned LLM
After the LLM is customized and deployed on an endpoint, you want to evaluate its performance against real-world queries. To do this, you will use an Execute code step type that allows you to run the Python code that performs model evaluation using the factual knowledge evaluation from the fmeval library. The Execute code step type was introduced along with the new visual editor and provides three execution modes in which code can be run: Jupyter Notebooks, Python functions, and Shell or Python scripts. For more information about the Execute code step type, see the developer guide. In this example, you will use a Python function. The function will install the fmeval library, create a dataset to use for evaluation, and automatically test the model on its ability to reproduce facts about the real world.
Download the complete Python file, including the function and all imported libraries. The following are some code snippets of the model evaluation.
Define the LLM evaluation logic
Define a predictor to test your endpoint with a prompt:
Invoke your endpoint:
Generate a dataset:
Set up and run model evaluation using fmeval:
Upload the LLM evaluation logic
Drag a new Execute code (Run notebook or code) step onto the editor and update the display name to Evaluate model using the Details tab from the settings panel.

To configure the Execute code step settings, follow these steps in the Settings panel:
- Upload the python file py containing the function.
- Under Code Settings change the Mode to Function and update the Handler to
evaluating_function.py:evaluate_model. The handler input parameter is structured by putting the file name on the left side of the colon, and the handler function name on the right side:file_name.py:handler_function. - Add the
endpoint_nameparameter for your handler with the value of the endpoint created previously under Function Parameters (input); for example,llama-fine-tune. - Keep the default container and instance type settings.

After configuring this step, you connect the Deploy model (endpoint) step to the Execute code step using the visual editor.
Step #5: Condition step
After you execute the model evaluation code, you drag a Condition step to the editor. The condition step registers the fine-tuned model to a SageMaker Model Registry if the factual knowledge evaluation score exceeded the desired threshold. If the performance of the model was below the threshold, then the model isn’t added to the model registry and the pipeline execution fails.
- Update the Condition step name under the Details tab to Is LLM factually correct.
- Drag a Register model step and a Fail step to the editor as shown in the following GIF. You will not configure these steps until the next sections.
- Return to the Condition step and add a condition under Conditions (input).
- For the first String, enter factual_knowledge.
- Select Greater Than as the test.
- For the second String enter 7. The evaluation averages a single binary metric across every prompt in the dataset. For more information, see Factual Knowledge.

- In the Conditions (output) section, for Then (execute if true), select Register model, and for Else (execute if false), select Fail.

- After configuring this step, connect the Execute code step to the Condition step using the visual editor.
You will configure the Register model and Fail steps in the following sections.
Step #6: Register the model
To register your model to the SageMaker Model Registry, you need to configure the step to include the S3 URI of the model and the image URI.
- Return to the Register model step in the Pipelines visual editor that you created in the previous section and use the following steps to connect the Fine-tune step to the Register model This is required to inherit the model artifacts of the fine-tuned model.
- Select the step and choose Add under the Model (input)
- Enter the image URI dkr.ecr.<region_name>.amazonaws.com/djl-inference:0.28.0-lmi10.0.0-cu124(replace <region_name> with your Region) in the Image field. For the Model URI field, select Step variable and Fine-tuning Model Artifacts. Choose Save.

- Enter a name for the Model group.
Step #7: Fail step
Select the Fail step on the canvas and enter a failure message to be displayed if the model fails to be registered to the model registry. For example: Model below evaluation threshold. Failed to register.

Save and execute the pipeline
Now that your pipeline has been constructed, choose Execute and enter a name for the execution to run the pipeline. You can then select the pipeline to view its progress. The pipeline will take 30–40 minutes to execute.


LLM customization at scale
In this example you executed the pipeline once manually from the UI. But by using the SageMaker APIs and SDK, you can trigger multiple concurrent executions of this pipeline with varying parameters (for example, different LLMs, different datasets, or different evaluation scripts) as part of your regular CI/CD processes. You don’t need to manage the capacity of the underlying infrastructure for SageMaker Pipelines because it automatically scales up or down based on the number of pipelines, number of steps in the pipelines, and number of pipeline executions in your AWS account. To learn more about the default scalability limits and request an increase in the performance of Pipelines, see the Amazon SageMaker endpoints and quotas.
Clean up
Delete the SageMaker model endpoint to avoid incurring additional charges.
Conclusion
In this post, we walked you through a solution to fine-tune a Llama 3 model using the new visual editor for Amazon SageMaker Pipelines. We introduced the fine-tuning step to fine-tune LLMs, and the Execute code step to run your own code in a pipeline step. The visual editor provides a user-friendly interface to create and manage AI/ML workflows. By using this capability, you can rapidly iterate on workflows before executing them at scale in production tens of thousands of times. For more information about this new feature, see Create and Manage Pipelines. Try it out and let us know your thoughts in the comments!
About the Authors
 Lauren Mullennex is a Senior AI/ML Specialist Solutions Architect at AWS. She has a decade of experience in DevOps, infrastructure, and ML. Her areas of focus include MLOps/LLMOps, generative AI, and computer vision.
Lauren Mullennex is a Senior AI/ML Specialist Solutions Architect at AWS. She has a decade of experience in DevOps, infrastructure, and ML. Her areas of focus include MLOps/LLMOps, generative AI, and computer vision.
 Brock Wade is a Software Engineer for Amazon SageMaker. Brock builds solutions for MLOps, LLMOps, and generative AI, with experience spanning infrastructure, DevOps, cloud services, SDKs, and UIs.
Brock Wade is a Software Engineer for Amazon SageMaker. Brock builds solutions for MLOps, LLMOps, and generative AI, with experience spanning infrastructure, DevOps, cloud services, SDKs, and UIs.
 Piyush Kadam is a Product Manager for Amazon SageMaker, a fully managed service for generative AI builders. Piyush has extensive experience delivering products that help startups and enterprise customers harness the power of foundation models.
Piyush Kadam is a Product Manager for Amazon SageMaker, a fully managed service for generative AI builders. Piyush has extensive experience delivering products that help startups and enterprise customers harness the power of foundation models.

Implement Amazon SageMaker domain cross-Region disaster recovery using custom Amazon EFS instances
Amazon SageMaker is a cloud-based machine learning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. Extensively used by data scientists and ML engineers across various industries, this robust tool provides high availability and uninterrupted access for its users. When working with SageMaker, your environment resides within a SageMaker domain, which encompasses critical components like Amazon Elastic File System (Amazon EFS) for storage, user profiles, and a diverse array of security configurations. This comprehensive setup enables collaborative efforts by allowing users to store, share, and access notebooks, Python files, and other essential artifacts.
In 2023, SageMaker announced the release of the new SageMaker Studio, which offers two new types of applications: JupyterLab and Code Editor. The old SageMaker Studio was renamed to SageMaker Studio Classic. Unlike other applications that share one single storage volume in SageMaker Studio Classic, each JupyterLab and Code Editor instance has its own Amazon Elastic Block Store (Amazon EBS) volume. For more information about this architecture, see New – Code Editor, based on Code-OSS VS Code Open Source now available in Amazon SageMaker Studio. Another new feature was the ability to bring your own EFS instance, which enables you to attach and detach a custom EFS instance.
A SageMaker domain exclusive to the new SageMaker Studio is composed of the following entities:
- User profiles
- Applications including JupyterLab, Code Editor, RStudio, Canvas, and MLflow
- A variety of security, application, policy, and Amazon Virtual Private Cloud (Amazon VPC) configurations
As a precautionary measure, some customers may want to ensure continuous operation of SageMaker in unlikely event of regional impairment of SageMaker service. This solution leverages Amazon EFS’s built-in cross-region replication capability to serve as a robust disaster recovery mechanism, providing continuous and uninterrupted access to your SageMaker domain data across multiple regions. Replicating your data and resources across multiple Regions helps to safeguards against Regional outages and fortifies your defenses against natural disasters or unforeseen technical failures, thereby providing business continuity and disaster recovery capabilities. This setup is particularly crucial for mission-critical and time-sensitive workloads, so data scientists and ML engineers can seamlessly continue their work without any disruptive interruptions.
The solution illustrated in this post focuses on the new SageMaker Studio experience, particularly private JupyterLab and Code Editor spaces. Although the code base doesn’t include shared spaces, the solution is straightforward to extend with the same concept. In this post, we guide you through a step-by-step process to seamlessly migrate and safeguard your new SageMaker domain in Amazon SageMaker Studio from one active AWS to another AWS Region, including all associated user profiles and files. By using a combination of AWS services, you can implement this feature effectively, overcoming the current limitations within SageMaker.
Solution overview
In active-passive mode, the SageMaker domain infrastructure is only provisioned in the primary AWS Region. Data backup is in near real time using Amazon EFS replication. Diagram 1 illustrates this architecture.
Diagram 1:
When the primary Region is down, a new domain is launched in the secondary Region, and an AWS Step Functions workflow runs to restore data as seen in diagram 2.
Diagram 2:

In active-active mode depicted in diagram 3, the SageMaker domain infrastructure is provisioned in two AWS Regions. Data backup is in near real time using Amazon EFS replication. The data sync is completed by the Step Functions workflow, and its cadence can be on demand, scheduled, or invoked by an event.
Diagram 3:

You can find the complete code sample in the GitHub repo.
Click here to open the AWS console and follow along.
With all the benefits of upgraded SageMaker domains, we developed a fast and robust cross- AWS Region disaster recovery solution, using Amazon EFS to back up and recover user data stored in SageMaker Studio applications. In addition, domain user profiles and respective custom Posix are managed by a YAML file in an AWS Cloud Development Kit (AWS CDK) code base to make sure domain entities in the secondary AWS Region are identical to those in the primary AWS Region. Because user-level custom EFS instances are only configurable through programmatic API calls, creating users on the AWS Management Console is not considered in our context.
Backup
Backup is performed within the primary AWS Region. There are two types of sources: an EBS space and a custom EFS instance.
For an EBS space, a lifecycle config is attached to JupyterLab or Code Editor for the purposes of backing up files. Every time the user opens the application, the lifecycle config takes a snapshot of its EBS spaces and stores them in the custom EFS instance using an rsync command.
For a custom EFS instance, it’s automatically replicated to its read-only replica in the secondary AWS Region.
Recovery
For recovery in the secondary AWS Region, a SageMaker domain with the same user profiles and spaces is deployed, and an empty custom EFS instance is created and attached to it. Then an Amazon Elastic Container Service (Amazon ECS) task runs to copy all the backup files to the empty custom EFS instance. At the last step, a lifecycle config script is run to restore the Amazon EBS snapshots before the SageMaker space launched.
Prerequisites
Complete the following prerequisite steps:
- Clone the GitHub repo to your local machine by running the following command in your terminal:
- Navigate to the project working directory and set up the Python virtual environment:
- Install the required dependencies:
- Bootstrap your AWS account and set up the AWS CDK environment in both Regions:
- Synthesize the AWS CloudFormation templates by running the following code:
- Configure the necessary arguments in the constants.py file:
- Set the primary Region in which you want to deploy the solution.
- Set the secondary Region in which you want to recover the primary domain.
- Replace the account ID variable with your AWS account ID.
Deploy the solution
Complete the following steps to deploy the solution:
- Deploy the primary SageMaker domain:
- Deploy the secondary SageMaker domain:
- Deploy the disaster recovery Step Functions workflow:
- Launch the application with the custom EFS instance attached and add files to the application’s EBS volume and custom EFS instance.

Test the solution
Complete the following steps to test the solution:
- Add test files using Code Editor or JupyterLab in the primary Region.

- Stop and restart the application.
This invokes the lifecycle config script to take an Amazon EBS snapshot on the application.
- On the Step Functions console in the secondary Region, run the disaster recovery Step Functions workflow.

The following figure illustrates the workflow steps.

- On the SageMaker console in the secondary Region, launch the same user’s SageMaker Studio.
You will find your files backed up in either Code Editor or JupyterLab.

Clean up
To avoid incurring ongoing charges, clean up the resources you created as part of this post:
- Stop all Code Editor and JupyterLab Apps
- Delete all cdk stacks
Conclusion
SageMaker offers a robust and highly available ML platform, enabling data scientists and ML engineers to build, train, and deploy models efficiently. For critical use cases, implementing a comprehensive disaster recovery strategy enhances the resilience of your SageMaker domain, ensuring continuous operation in the unlikely event of regional impairment. This post presents a detailed solution for migrating and safeguarding your SageMaker domain, including user profiles and files, from one active AWS Region to another passive or active AWS Region. By using a strategic combination of AWS services, such as Amazon EFS, Step Functions, and the AWS CDK, this solution overcomes the current limitations within SageMaker Studio and provides continuous access to your valuable data and resources. Whether you choose an active-passive or active-active architecture, this solution provides a robust and resilient backup and recovery mechanism, fortifying your defenses against natural disasters, technical failures, and Regional outages. With this comprehensive guide, you can confidently safeguard your mission-critical and time-sensitive workloads, maintaining business continuity and uninterrupted access to your SageMaker domain, even in the case of unforeseen circumstances.
For more information on disaster recovery on AWS, refer to the following:
- What is disaster recovery?
- Disaster Recovery of Workloads on AWS: Recovery in the Cloud
- AWS Elastic Disaster Recovery
- Implement backup and recovery using an event-driven serverless architecture with Amazon SageMaker Studio
About the Authors
 Jinzhao Feng is a Machine Learning Engineer at AWS Professional Services. He focuses on architecting and implementing large-scale generative AI and classic ML pipeline solutions. He is specialized in FMOps, LLMOps, and distributed training.
Jinzhao Feng is a Machine Learning Engineer at AWS Professional Services. He focuses on architecting and implementing large-scale generative AI and classic ML pipeline solutions. He is specialized in FMOps, LLMOps, and distributed training.
 Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
 Natasha Tchir is a Cloud Consultant at the Generative AI Innovation Center, specializing in machine learning. With a strong background in ML, she now focuses on the development of generative AI proof-of-concept solutions, driving innovation and applied research within the GenAIIC.
Natasha Tchir is a Cloud Consultant at the Generative AI Innovation Center, specializing in machine learning. With a strong background in ML, she now focuses on the development of generative AI proof-of-concept solutions, driving innovation and applied research within the GenAIIC.
 Katherine Feng is a Cloud Consultant at AWS Professional Services within the Data and ML team. She has extensive experience building full-stack applications for AI/ML use cases and LLM-driven solutions.
Katherine Feng is a Cloud Consultant at AWS Professional Services within the Data and ML team. She has extensive experience building full-stack applications for AI/ML use cases and LLM-driven solutions.
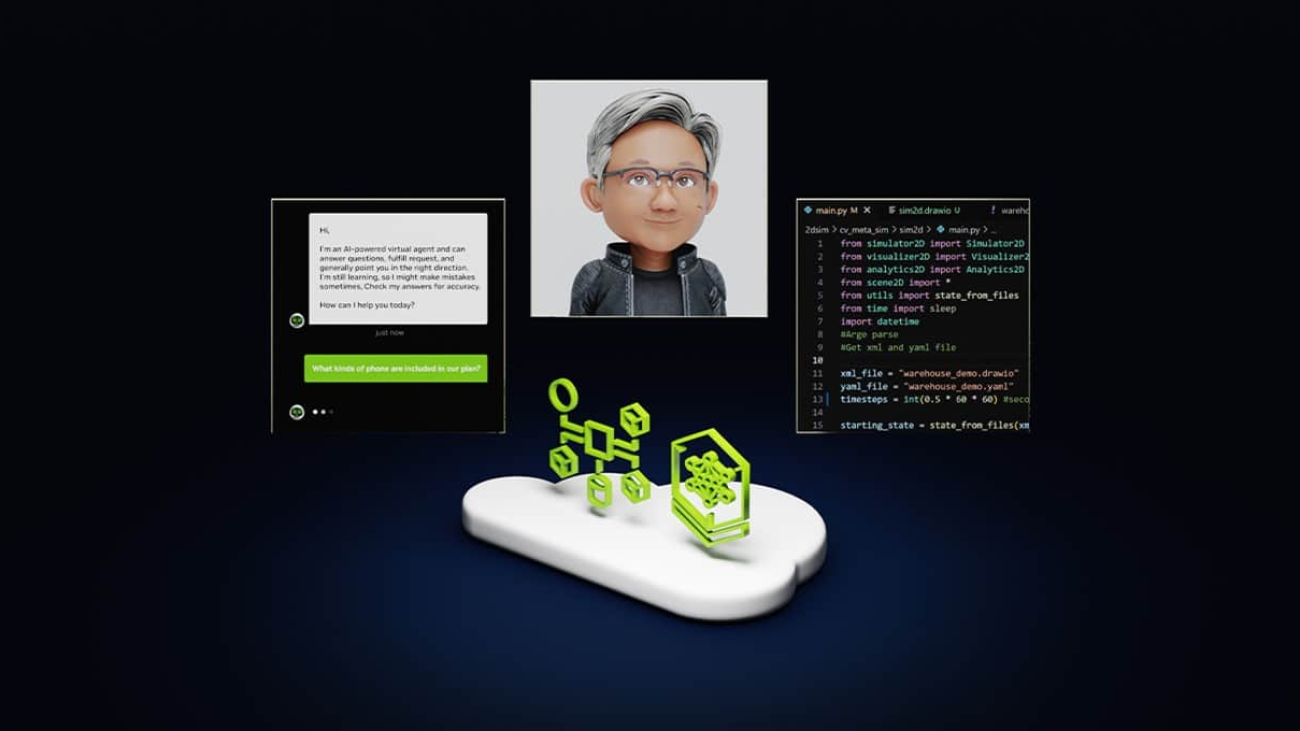
What Is Agentic AI?
AI chatbots use generative AI to provide responses based on a single interaction. A person makes a query and the chatbot uses natural language processing to reply.
The next frontier of artificial intelligence is agentic AI, which uses sophisticated reasoning and iterative planning to autonomously solve complex, multi-step problems. And it’s set to enhance productivity and operations across industries.
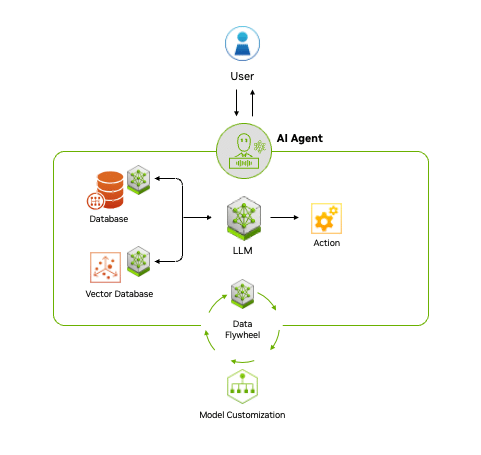
Agentic AI systems ingest vast amounts of data from multiple sources to independently analyze challenges, develop strategies and execute tasks like supply chain optimization, cybersecurity vulnerability analysis and helping doctors with time-consuming tasks.
How Does Agentic AI Work?
Agentic AI uses a four-step process for problem-solving:
- Perceive: AI agents gather and process data from various sources, such as sensors, databases and digital interfaces. This involves extracting meaningful features, recognizing objects or identifying relevant entities in the environment.
- Reason: A large language model acts as the orchestrator, or reasoning engine, that understands tasks, generates solutions and coordinates specialized models for specific functions like content creation, vision processing or recommendation systems. This step uses techniques like retrieval-augmented generation (RAG) to access proprietary data sources and deliver accurate, relevant outputs.
- Act: By integrating with external tools and software via application programming interfaces, agentic AI can quickly execute tasks based on the plans it has formulated. Guardrails can be built into AI agents to help ensure they execute tasks correctly. For example, a customer service AI agent may be able to process claims up to a certain amount, while claims above the amount would have to be approved by a human.
- Learn: Agentic AI continuously improves through a feedback loop, or
“data flywheel,” where the data generated from its interactions is fed into the system to enhance models. This ability to adapt and become more effective over time offers businesses a powerful tool for driving better decision-making and operational efficiency.
 Fueling Agentic AI With Enterprise Data
Fueling Agentic AI With Enterprise Data
Across industries and job functions, generative AI is transforming organizations by turning vast amounts of data into actionable knowledge, helping employees work more efficiently.
AI agents build on this potential by accessing diverse data through accelerated AI query engines, which process, store and retrieve information to enhance generative AI models. A key technique for achieving this is RAG, which allows AI to tap into a broader range of data sources.
Over time, AI agents learn and improve by creating a data flywheel, where data generated through interactions is fed back into the system, refining models and increasing their effectiveness.
The end-to-end NVIDIA AI platform, including NVIDIA NeMo microservices, provides the ability to manage and access data efficiently, which is crucial for building responsive agentic AI applications.
Agentic AI in Action
The potential applications of agentic AI are vast, limited only by creativity and expertise. From simple tasks like generating and distributing content to more complex use cases such as orchestrating enterprise software, AI agents are transforming industries.

Customer Service: AI agents are improving customer support by enhancing self-service capabilities and automating routine communications. Over half of service professionals report significant improvements in customer interactions, reducing response times and boosting satisfaction.
There’s also growing interest in digital humans — AI-powered agents that embody a company’s brand and offer lifelike, real-time interactions to help sales representatives answer customer queries or solve issues directly when call volumes are high.
Content Creation: Agentic AI can help quickly create high-quality, personalized marketing content. Generative AI agents can save marketers an average of three hours per content piece, allowing them to focus on strategy and innovation. By streamlining content creation, businesses can stay competitive while improving customer engagement.
Software Engineering: AI agents are boosting developer productivity by automating repetitive coding tasks. It’s projected that by 2030 AI could automate up to 30% of work hours, freeing developers to focus on more complex challenges and drive innovation.
Healthcare: For doctors analyzing vast amounts of medical and patient data, AI agents can distill critical information to help them make better-informed care decisions. Automating administrative tasks and capturing clinical notes in patient appointments reduces the burden of time-consuming tasks, allowing doctors to focus on developing a doctor-patient connection.
AI agents can also provide 24/7 support, offering information on prescribed medication usage, appointment scheduling and reminders, and more to help patients adhere to treatment plans.
How to Get Started
With its ability to plan and interact with a wide variety of tools and software, agentic AI marks the next chapter of artificial intelligence, offering the potential to enhance productivity and revolutionize the way organizations operate.
To accelerate the adoption of generative AI-powered applications and agents, NVIDIA NIM Agent Blueprints provide sample applications, reference code, sample data, tools and comprehensive documentation.
NVIDIA partners including Accenture are helping enterprises use agentic AI with solutions built with NIM Agent Blueprints.
Visit ai.nvidia.com to learn more about the tools and software NVIDIA offers to help enterprises build their own AI agents.
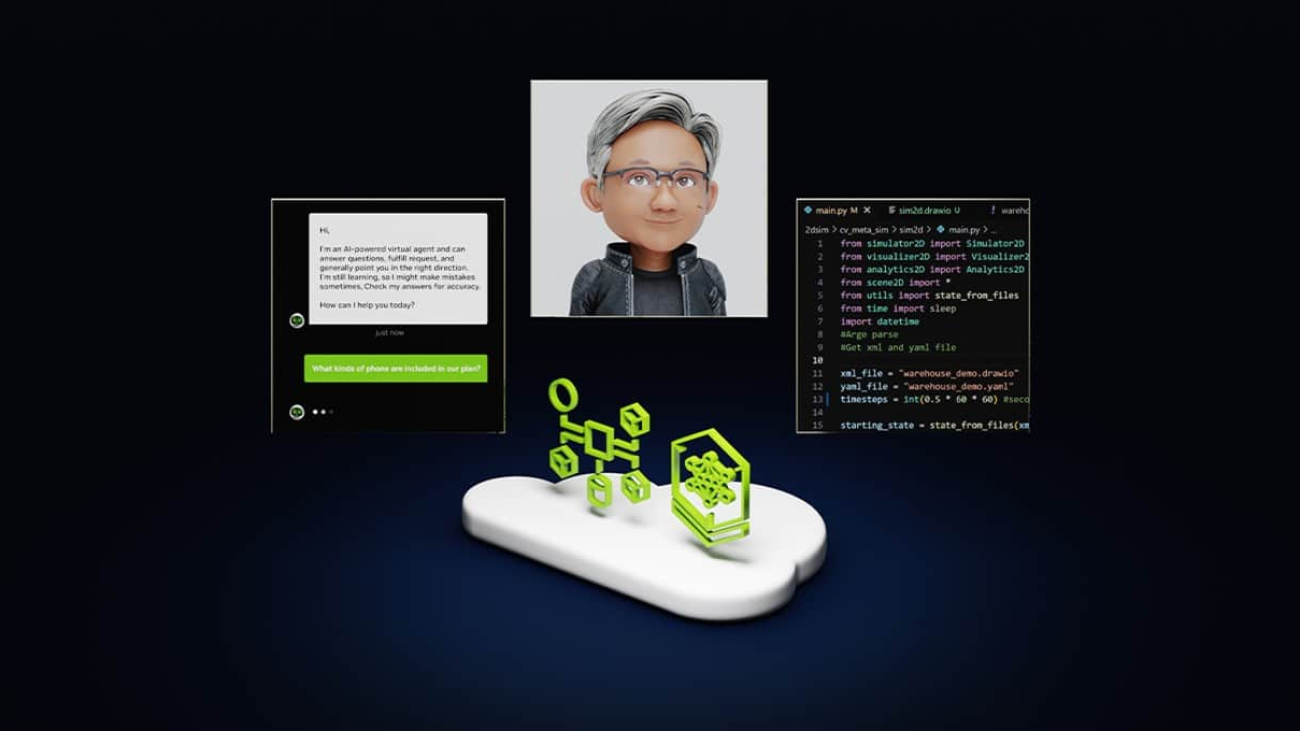
What Is Agentic AI?
AI chatbots use generative AI to provide responses based on a single interaction. A person makes a query and the chatbot uses natural language processing to reply.
The next frontier of artificial intelligence is agentic AI, which uses sophisticated reasoning and iterative planning to autonomously solve complex, multi-step problems. And it’s set to enhance productivity and operations across industries.
Agentic AI systems ingest vast amounts of data from multiple sources to independently analyze challenges, develop strategies and execute tasks like supply chain optimization, cybersecurity vulnerability analysis and helping doctors with time-consuming tasks.
How Does Agentic AI Work?
Agentic AI uses a four-step process for problem-solving:
- Perceive: AI agents gather and process data from various sources, such as sensors, databases and digital interfaces. This involves extracting meaningful features, recognizing objects or identifying relevant entities in the environment.
- Reason: A large language model acts as the orchestrator, or reasoning engine, that understands tasks, generates solutions and coordinates specialized models for specific functions like content creation, vision processing or recommendation systems. This step uses techniques like retrieval-augmented generation (RAG) to access proprietary data sources and deliver accurate, relevant outputs.
- Act: By integrating with external tools and software via application programming interfaces, agentic AI can quickly execute tasks based on the plans it has formulated. Guardrails can be built into AI agents to help ensure they execute tasks correctly. For example, a customer service AI agent may be able to process claims up to a certain amount, while claims above the amount would have to be approved by a human.
- Learn: Agentic AI continuously improves through a feedback loop, or
“data flywheel,” where the data generated from its interactions is fed into the system to enhance models. This ability to adapt and become more effective over time offers businesses a powerful tool for driving better decision-making and operational efficiency.
Fueling Agentic AI With Enterprise Data
Across industries and job functions, generative AI is transforming organizations by turning vast amounts of data into actionable knowledge, helping employees work more efficiently.
AI agents build on this potential by accessing diverse data through accelerated AI query engines, which process, store and retrieve information to enhance generative AI models. A key technique for achieving this is RAG, which allows AI to tap into a broader range of data sources.
Over time, AI agents learn and improve by creating a data flywheel, where data generated through interactions is fed back into the system, refining models and increasing their effectiveness.
The end-to-end NVIDIA AI platform, including NVIDIA NeMo microservices, provides the ability to manage and access data efficiently, which is crucial for building responsive agentic AI applications.
Agentic AI in Action
The potential applications of agentic AI are vast, limited only by creativity and expertise. From simple tasks like generating and distributing content to more complex use cases such as orchestrating enterprise software, AI agents are transforming industries.
Customer Service: AI agents are improving customer support by enhancing self-service capabilities and automating routine communications. Over half of service professionals report significant improvements in customer interactions, reducing response times and boosting satisfaction.
There’s also growing interest in digital humans — AI-powered agents that embody a company’s brand and offer lifelike, real-time interactions to help sales representatives answer customer queries or solve issues directly when call volumes are high.
Content Creation: Agentic AI can help quickly create high-quality, personalized marketing content. Generative AI agents can save marketers an average of three hours per content piece, allowing them to focus on strategy and innovation. By streamlining content creation, businesses can stay competitive while improving customer engagement.
Software Engineering: AI agents are boosting developer productivity by automating repetitive coding tasks. It’s projected that by 2030 AI could automate up to 30% of work hours, freeing developers to focus on more complex challenges and drive innovation.
Healthcare: For doctors analyzing vast amounts of medical and patient data, AI agents can distill critical information to help them make better-informed care decisions. Automating administrative tasks and capturing clinical notes in patient appointments reduces the burden of time-consuming tasks, allowing doctors to focus on developing a doctor-patient connection.
AI agents can also provide 24/7 support, offering information on prescribed medication usage, appointment scheduling and reminders, and more to help patients adhere to treatment plans.
How to Get Started
With its ability to plan and interact with a wide variety of tools and software, agentic AI marks the next chapter of artificial intelligence, offering the potential to enhance productivity and revolutionize the way organizations operate.
To accelerate the adoption of generative AI-powered applications and agents, NVIDIA NIM Agent Blueprints provide sample applications, reference code, sample data, tools and comprehensive documentation.
NVIDIA partners including Accenture are helping enterprises use agentic AI with solutions built with NIM Agent Blueprints.
Visit ai.nvidia.com to learn more about the tools and software NVIDIA offers to help enterprises build their own AI agents.
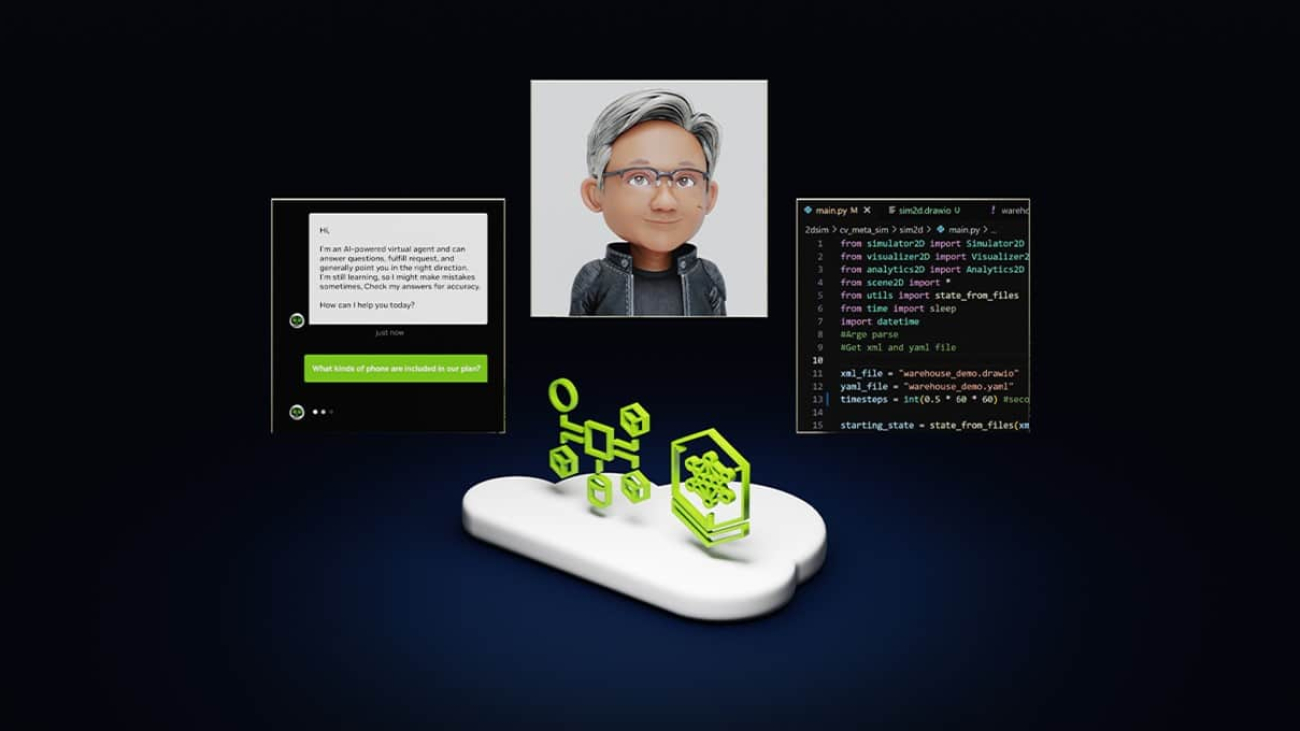
What Is Agentic AI?
AI chatbots use generative AI to provide responses based on a single interaction. A person makes a query and the chatbot uses natural language processing to reply.
The next frontier of artificial intelligence is agentic AI, which uses sophisticated reasoning and iterative planning to autonomously solve complex, multi-step problems. And it’s set to enhance productivity and operations across industries.
Agentic AI systems ingest vast amounts of data from multiple sources to independently analyze challenges, develop strategies and execute tasks like supply chain optimization, cybersecurity vulnerability analysis and helping doctors with time-consuming tasks.
How Does Agentic AI Work?
Agentic AI uses a four-step process for problem-solving:
- Perceive: AI agents gather and process data from various sources, such as sensors, databases and digital interfaces. This involves extracting meaningful features, recognizing objects or identifying relevant entities in the environment.
- Reason: A large language model acts as the orchestrator, or reasoning engine, that understands tasks, generates solutions and coordinates specialized models for specific functions like content creation, vision processing or recommendation systems. This step uses techniques like retrieval-augmented generation (RAG) to access proprietary data sources and deliver accurate, relevant outputs.
- Act: By integrating with external tools and software via application programming interfaces, agentic AI can quickly execute tasks based on the plans it has formulated. Guardrails can be built into AI agents to help ensure they execute tasks correctly. For example, a customer service AI agent may be able to process claims up to a certain amount, while claims above the amount would have to be approved by a human.
- Learn: Agentic AI continuously improves through a feedback loop, or
“data flywheel,” where the data generated from its interactions is fed into the system to enhance models. This ability to adapt and become more effective over time offers businesses a powerful tool for driving better decision-making and operational efficiency.
Fueling Agentic AI With Enterprise Data
Across industries and job functions, generative AI is transforming organizations by turning vast amounts of data into actionable knowledge, helping employees work more efficiently.
AI agents build on this potential by accessing diverse data through accelerated AI query engines, which process, store and retrieve information to enhance generative AI models. A key technique for achieving this is RAG, which allows AI to tap into a broader range of data sources.
Over time, AI agents learn and improve by creating a data flywheel, where data generated through interactions is fed back into the system, refining models and increasing their effectiveness.
The end-to-end NVIDIA AI platform, including NVIDIA NeMo microservices, provides the ability to manage and access data efficiently, which is crucial for building responsive agentic AI applications.
Agentic AI in Action
The potential applications of agentic AI are vast, limited only by creativity and expertise. From simple tasks like generating and distributing content to more complex use cases such as orchestrating enterprise software, AI agents are transforming industries.
Customer Service: AI agents are improving customer support by enhancing self-service capabilities and automating routine communications. Over half of service professionals report significant improvements in customer interactions, reducing response times and boosting satisfaction.
There’s also growing interest in digital humans — AI-powered agents that embody a company’s brand and offer lifelike, real-time interactions to help sales representatives answer customer queries or solve issues directly when call volumes are high.
Content Creation: Agentic AI can help quickly create high-quality, personalized marketing content. Generative AI agents can save marketers an average of three hours per content piece, allowing them to focus on strategy and innovation. By streamlining content creation, businesses can stay competitive while improving customer engagement.
Software Engineering: AI agents are boosting developer productivity by automating repetitive coding tasks. It’s projected that by 2030 AI could automate up to 30% of work hours, freeing developers to focus on more complex challenges and drive innovation.
Healthcare: For doctors analyzing vast amounts of medical and patient data, AI agents can distill critical information to help them make better-informed care decisions. Automating administrative tasks and capturing clinical notes in patient appointments reduces the burden of time-consuming tasks, allowing doctors to focus on developing a doctor-patient connection.
AI agents can also provide 24/7 support, offering information on prescribed medication usage, appointment scheduling and reminders, and more to help patients adhere to treatment plans.
How to Get Started
With its ability to plan and interact with a wide variety of tools and software, agentic AI marks the next chapter of artificial intelligence, offering the potential to enhance productivity and revolutionize the way organizations operate.
To accelerate the adoption of generative AI-powered applications and agents, NVIDIA NIM Agent Blueprints provide sample applications, reference code, sample data, tools and comprehensive documentation.
NVIDIA partners including Accenture are helping enterprises use agentic AI with solutions built with NIM Agent Blueprints.
Visit ai.nvidia.com to learn more about the tools and software NVIDIA offers to help enterprises build their own AI agents.
What Is Agentic AI?
AI chatbots use generative AI to provide responses based on a single interaction. A person makes a query and the chatbot uses natural language processing to reply.
The next frontier of artificial intelligence is agentic AI, which uses sophisticated reasoning and iterative planning to autonomously solve complex, multi-step problems. And it’s set to enhance productivity and operations across industries.
Agentic AI systems ingest vast amounts of data from multiple sources to independently analyze challenges, develop strategies and execute tasks like supply chain optimization, cybersecurity vulnerability analysis and helping doctors with time-consuming tasks.
How Does Agentic AI Work?
Agentic AI uses a four-step process for problem-solving:
- Perceive: AI agents gather and process data from various sources, such as sensors, databases and digital interfaces. This involves extracting meaningful features, recognizing objects or identifying relevant entities in the environment.
- Reason: A large language model acts as the orchestrator, or reasoning engine, that understands tasks, generates solutions and coordinates specialized models for specific functions like content creation, vision processing or recommendation systems. This step uses techniques like retrieval-augmented generation (RAG) to access proprietary data sources and deliver accurate, relevant outputs.
- Act: By integrating with external tools and software via application programming interfaces, agentic AI can quickly execute tasks based on the plans it has formulated. Guardrails can be built into AI agents to help ensure they execute tasks correctly. For example, a customer service AI agent may be able to process claims up to a certain amount, while claims above the amount would have to be approved by a human.
- Learn: Agentic AI continuously improves through a feedback loop, or
“data flywheel,” where the data generated from its interactions is fed into the system to enhance models. This ability to adapt and become more effective over time offers businesses a powerful tool for driving better decision-making and operational efficiency.
Fueling Agentic AI With Enterprise Data
Across industries and job functions, generative AI is transforming organizations by turning vast amounts of data into actionable knowledge, helping employees work more efficiently.
AI agents build on this potential by accessing diverse data through accelerated AI query engines, which process, store and retrieve information to enhance generative AI models. A key technique for achieving this is RAG, which allows AI to tap into a broader range of data sources.
Over time, AI agents learn and improve by creating a data flywheel, where data generated through interactions is fed back into the system, refining models and increasing their effectiveness.
The end-to-end NVIDIA AI platform, including NVIDIA NeMo microservices, provides the ability to manage and access data efficiently, which is crucial for building responsive agentic AI applications.
Agentic AI in Action
The potential applications of agentic AI are vast, limited only by creativity and expertise. From simple tasks like generating and distributing content to more complex use cases such as orchestrating enterprise software, AI agents are transforming industries.
Customer Service: AI agents are improving customer support by enhancing self-service capabilities and automating routine communications. Over half of service professionals report significant improvements in customer interactions, reducing response times and boosting satisfaction.
There’s also growing interest in digital humans — AI-powered agents that embody a company’s brand and offer lifelike, real-time interactions to help sales representatives answer customer queries or solve issues directly when call volumes are high.
Content Creation: Agentic AI can help quickly create high-quality, personalized marketing content. Generative AI agents can save marketers an average of three hours per content piece, allowing them to focus on strategy and innovation. By streamlining content creation, businesses can stay competitive while improving customer engagement.
Software Engineering: AI agents are boosting developer productivity by automating repetitive coding tasks. It’s projected that by 2030 AI could automate up to 30% of work hours, freeing developers to focus on more complex challenges and drive innovation.
Healthcare: For doctors analyzing vast amounts of medical and patient data, AI agents can distill critical information to help them make better-informed care decisions. Automating administrative tasks and capturing clinical notes in patient appointments reduces the burden of time-consuming tasks, allowing doctors to focus on developing a doctor-patient connection.
AI agents can also provide 24/7 support, offering information on prescribed medication usage, appointment scheduling and reminders, and more to help patients adhere to treatment plans.
How to Get Started
With its ability to plan and interact with a wide variety of tools and software, agentic AI marks the next chapter of artificial intelligence, offering the potential to enhance productivity and revolutionize the way organizations operate.
To accelerate the adoption of generative AI-powered applications and agents, NVIDIA NIM Agent Blueprints provide sample applications, reference code, sample data, tools and comprehensive documentation.
NVIDIA partners including Accenture are helping enterprises use agentic AI with solutions built with NIM Agent Blueprints.
Visit ai.nvidia.com to learn more about the tools and software NVIDIA offers to help enterprises build their own AI agents.