This post is co-written with Kaustubh Kambli from DXC Technology.
DXC Technology is an IT services leader with more than 130,000 employees supporting 6,000 customers in over 70 countries. DXC builds offerings across industry verticals to deliver accelerated value to their customers.
One of the sectors DXC has deep expertise in is energy. The oil and gas industry relies on discovering new drilling sites to drive growth. Data-driven insights can accelerate the process of identifying potential locations and improve decision-making. For the largest companies in the sector, shaving even a single day off the time to first oil can impact operational costs and revenue by millions of dollars.
In this post, we show you how DXC and AWS collaborated to build an AI assistant using large language models (LLMs), enabling users to access and analyze different data types from a variety of data sources. The AI assistant is powered by an intelligent agent that routes user questions to specialized tools that are optimized for different data types such as text, tables, and domain-specific formats. It uses the LLM’s ability to understand natural language, write code, and reason about conversational context.
Data plays a key role in identifying sites for oil exploration and in accelerating the time to extract oil from those sites, but data in this industry is scattered, non-standard, and of various types. These companies have remote sites, offshore drilling locations, branch offices, and corporate offices. Relevant data is also in various formats, ranging from spreadsheets to complex datasets like satellite images and GIS data. Moreover, there are industry-specific data formats like Log ASCII standard (LAS).
The assistant architecture consists of several key components powered by Anthropic’s Claude on Amazon Bedrock. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
In this project, Amazon Bedrock enabled us to seamlessly switch between different variants of Anthropic’s Claude models. We used smaller, faster models for basic tasks such as routing, and more powerful models for complex processes such as code generation. Additionally, we took advantage of Amazon Bedrock Knowledge Bases, a managed service that enhances the LLM’s knowledge by integrating external documents. This service seamlessly integrates with FMs on Bedrock and can be set up through the console in a few minutes.
Solution overview
The solution is composed of several components powered by Anthropic’s Claude models on Bedrock:
- Router – The router analyzes the user query and routes it to the appropriate tool
- Custom built tools – These tools are optimized for different data sources such as file systems, tables, and LAS files
- Conversational capabilities – These capabilities enable the model to understand context and rewrite queries when needed
We also use an Amazon Simple Storage Service (Amazon S3) bucket to store the data. The data is indexed by relevant tools when deploying the solution, and we use signed S3 URLs to provide access to the relevant data sources in the UI.
The following diagram illustrates the solution architecture.

In the following sections, we go over these components in detail. The examples presented in this post use the Teapot dome dataset, which describes geophysical and well log data from the Rocky Mountain Oilfield Testing Center (RMOTC) related to the Tensleep Formation and is available for educational and research purposes.
LLM-powered router
The types of questions that the chatbot can be asked can be broken down into distinct categories:
- File name questions – For example, “How many 3D seg-y files do we have?” For these questions, we don’t need to look at the file content; we only need to filter by file extension and count.
- File content questions – For example, “What can you say about the geology of teapot dome?” For these questions, we need to do semantic search on the file content.
- Production questions – For example, “How much oil did API 490251069400 produce on March 2001?” For these questions, we need to filter the production Excel sheet (here, match on API number) and make operations on the columns (here, sum on the oil production column).
- Directional survey questions – For example, “What APIs have a total depth of more than 6000 ft?” For these questions, we need to filter the directional survey Excel sheet. The process is similar to the production questions, but the data differs.
- LAS files questions – For example, “What log measurements were acquired for API 490251069400?” For these questions, we need to open and process the LAS file to look at the measurements present in the file.
The way to deal with each of these questions requires different processing steps. We can design LLM-powered tools that can address each question type, but the first step upon receiving the user query is to route it to the right tool. For this, we use Anthropic’s Claude v2.1 on Amazon Bedrock with the following prompt:
routing_prompt = """
Human: You are an AI assistant that is an expert in Oil and Gas exploration.
Use the following information as background to categorize the question
- An API well number or API# can can have up to 14 digits sometimes divided
by dashes.
- There can be different unique identifiers for wells other than API #.
- .las or .LAS refers to Log ASCII file format. It is a standard file
format for storing well log data, which is crucial in the exploration and production of oil and gas. Well logs are detailed records of the geological formations penetrated by a borehole, and they are essential for understanding the subsurface conditions.
Determine the right category of the question to route it to the appropriate service by following the instructions below
- Repond with single word (the category name).
- Use the information provided in <description> to determine the category of
the question.
- If you are unable to categorize the question or it is not related to one of
the below categories then return "unknown".
- Use the category names provided below. Do not make up new categories.
- If the category is ambiguous then output all the categories that are relevant
as a comma separated list.
<categories>
<category>
<name>filename</name>
<description>The questions about searching for files or objects or
those related to counting files of specific types such as .pdf, .las, .xls, .sgy etc.
</description>
</category>
<category>
<name>production</name>
<description>well production related information. This can correlate API#, Well, Date of production, Amount Produces, Formation, Section </description>
</category>
<category>
<name>las</name>
<description>related to log data or .las or .LAS or Log ASCII files.
Except questions related
to searching or counting the files with .las extension.
Those belong to filesystem category. </description>
</category>
<category>
<name>directional_survey</name>
<description>directional survey contains information about multiple
wells and associates API, Measured Depth, Inclination and Azimuth
</description>
</category>
<category>
<name>knowledge_base</name>
<description>related to oil and gas exploration but does not fit in any of the categories above, include seismic, logging and core analysis related questions.
</description>
</category>
<category>
<name>unrelated</name>
<description> Question does not belong to one of the above categories and it is not related to oil and gas exploration in general. </description>
</category>
</categories>
Here is the question
<question>
{query}
</question>
Return your answer in the following format
<answer>
<reason>$REASON_JUSTIFYING_CATEGORY</reason>
<labels>$COMMA_SEPARETED_LABELS</labels>
</answer>
"""
Using XML tags in the output allows you to parse out the right category for the question. You can then pass the query down to the relevant tool for further processing. Note that with the release of new powerful Anthropic models, you could also use Anthropic’s Claude Haiku on Amazon Bedrock to improve latency for the routing.
The prompt also includes guardrails to make sure queries not pertaining to oil and gas data are gently dismissed.
LLM-powered tools
To optimally handle the variety of tasks for the chatbot, we built specialized tools. The tools that we built are data-type specific (text, tables, and LAS), except for the file search tool, which is task specific.
File search tool
When searching for files and information, we identified two distinct types of search. One type pertains to identifying files based on the name or extension; the other requires analyzing the contents of the file to answer a question. We call the first type file name-based search and the second semantic-content based search.
File name-based search
For this tool, we don’t need to look at the contents of the file; only at the file name. To initialize the tool, we first crawl the S3 bucket containing the data to get a list of the available files. Then for each query, the steps are as follows:
- LLM call to extract file extension and keywords from the query. When searching for relevant files to answer a query, we can look for specific file extensions or keywords that might be present in the content of the files. Our approach is to first use an LLM to analyze the user’s query and extract potential file extensions and keywords that could be relevant. We then search through the list of available files, looking for matches to those file extensions and keywords identified by the LLM. This allows us to narrow down the set of files that might contain information pertinent to answering the user’s question. Because we’re working with Anthropic’s Claude models, we ask the LLM to format its answer using XML tags. This structured output allows us to parse and extract file extensions and keywords from the answer. For instance, if the question is “Do we have any *.SGY files,” the LLM response should be
<file-extension>.sgy</file-extension> <keywords></keywords> because there are no keywords. On the other hand, if the question is “Can you show me the 2Dseismic base map,” the response should be <file-extension></file-extension> <keywords>2D, seismic, base, map</keywords>.
- Retrieve files that match the extension or keywords identified by the LLM. Retrieval is done by doing simple string matching over the list of available files. If a file extension is extracted by the LLM, simple string matching is done on the end of the file name; if keywords are extracted by the LLM, string matching is done for each of the keywords.
- LLM call to confirm that retrieved files match the user query, and provide a final answer. To reach the final answer, we build a prompt containing the user query and the files retrieved at Step 2. We also give specific output formatting instructions to the LLM. Similar to Step 1, we rely on an XML structure to parse and extract desired information. In this step, the desired outputs are as follows:
- <success> – Whether the search was successful.
- <resources> – The list of Amazon S3 locations that the LLM deems relevant to the user query.
- <answer> – The final answer from the LLM.
To be mindful of the limited number of input and output tokens, we also implement controls to make sure the retrieved context isn’t too large and that the LLM’s answer isn’t cut off, which can happen if there are too many resources that match the user query.
The following screenshot is an example of a query that’s answered using that tool. It shows the query “show me the .sgy files” and the tool’s response, which includes a list of files.

Semantic content-based search
The implementation for semantic content-based search relies on Amazon Bedrock Knowledge Bases. Amazon Bedrock Knowledge Bases provides a seamless way to implement semantic search by pointing the service to an S3 bucket containing the data. The managed service takes care of the processing, chunking, and data management when files are added or deleted from the bucket. For setup instructions, see Knowledge Bases now delivers fully managed RAG experience in Amazon Bedrock.
For a given user query that’s passed to the tool, the steps are as follows:
- Use the retrieve API from Amazon Bedrock Knowledge Bases to retrieve documents semantically close to the query.
- Construct a prompt with the retrieved documents formatted with XML tags—<content> for text content and <location> for the corresponding Amazon S3 location.
- Call Anthropic’s Claude v2.1 model with the prompt to get the final answer. Similarly to the file name-based search, we instruct the LLM to use <success>, <answer>, and <resources> tags in the answer.
Using the retrieve_and_reply API instead of the retrieve API would get the answer in a single step, but this approach gives us more flexibility in the prompting to get the output with the desired format.
The following screenshot is an example of a question answered using the semantic search tool. It shows the query “what information do you have about the geology of teapot dome?” and the tool’s response.

Tables tool
This tool is designed to filter tables and compute certain metrics from the information they contain. It uses the LLM’s ability to write Python code for data analysis. We implemented a generic tables tool that takes the following as input:
- An Excel or CSV file
- A description of the table (optional)
- Table-specific instructions (optional)
In practice, with every new CSV or Excel file, we create a standalone tool for the router. This means that the tables tool applied to the production Excel sheet constitutes the production tool, whereas the tables tool coupled with the directional survey Excel sheet constitutes the directional survey tool.
Some out-of-the-box data analysis tools, such as LangChain’s Pandas agent, are available in open source libraries. The way these agents work is that they use an LLM to generate Python code, execute the code, and send the result of the code back to the LLM to generate a final response. However, for certain data analysis tasks, it would be preferable to directly output the result of Python code. Having an LLM generate the response as an extra step after the code execution introduces both latency and a risk for hallucination.
For example, many sample questions require filtering a DataFrame and potentially returning dozens of entries. The ability to filter a DataFrame and return the filtered results as an output was essential for our use case. To address this limitation, we wanted the LLM to generate code that we could run to obtain the desired output directly, so we built a custom agent to enable this functionality. Our custom agent also has the ability to self-correct if the generated code outputs an error. The main difference with traditional code-writing agents is that after the code is run, we return the output, whereas with traditional agents, this output is passed back to the agent to generate the final response. In our example with filtering and returning a large DataFrame, passing the DataFrame back to the agent to generate the final response would have the LLM rewrite that large DataFrame with risk of either exceeding the context window or hallucinating some of the data.
The following screenshot is an example of a question answered using the production data tool, which is the tables tool applied to the production data CSV file. It shows the query “What were the top 3 oil producing wells in March 2024” and the tool’s response. The response includes a DataFrame with the top 3 oil producing wells as well as the logic behind how the DataFrame was obtained.

The following code is the LLM response generated in the background; you can see in <code> tags the code that is being run to get the result in the data section of the UI. We explicitly prompt the LLM to store the final result in a variable called result so we can send it back to the user in the frontend.
<scratchpad>
To find wells with total depth greater than 6000 feet, I need to:
1. Filter the df dataframe on the 'Total Depth' column
2. Check if the value is greater than 6000
3. Handle any NaN values so they are not included
</scratchpad>
<code>
import pandas as pd
import numpy as np
result = df[df['Total Depth'].replace({np.nan: 0}) > 6000]
</code>
<answer>
I filtered the dataframe on the 'Total Depth' column, replaced any NaN values with 0 so they would not be included, and checked for values greater than 6000 feet. The final filtered dataframe is stored in the variable 'result'.
</answer>
LAS tool
The LAS tool is built to analyze Log ASCII Standard (LAS) files, which contain a wide variety of log curves and data to fully characterize the drilled formations and support petroleum engineering analysis. This file format, which is in essence a structured text file, can be efficiently queried and analyzed using the lasio Python library.
Similarly to the tables tool, we use the code-writing abilities of the LLM to generate Python code using the lasio library. We used the XML agent implemented in LangChain, along with the Python REPL tool, which allows the agent to run Python code.
Because lasio isn’t a common Python library, we give detailed instructions in the prompt on how to use it properly. The following code shows an example of the extract from the larger prompt:
""" ...
If the question is to display a particular log data, you can use the `lasio` package
in Python to load every LAS file into dataframe and display them iteratively as
follows.
import lasio
#Extract the las file names as a list from the dataframe df
las_files = df[df['API Number'] == api_num]['las_files'].values[0]
print(las_files)
for las_file in las_files: #enumerate the las file name in the list
las = lasio.read(las_file) # read a single LAS file
las_df = las.df() # convert the LAS data into dataframe
print(las_df) # print the dataframe
... """
The following screenshot shows an example of a question answered using the LAS tool. It shows the query “What log measurements were acquired for API #490251107500” and the tool’s response, which includes processed data from the LAS files.

The following code is the LLM’s response in the backend, which contains the relevant Python code:
<tool>Python_REPL</tool><tool_input>
import pandas as pd
import lasio
df = pd.read_parquet("/home/ec2-user/SageMaker/AmazonSageMaker-DXC-GAIIC-Opibus-Repo/data/processed/teapot_dome/las_index.parq")
api_num = 490251107500
las_files = df[df['API Number'] == api_num]['las_files'].values[0]
print(f"LAS files for API #{api_num}: {las_files}")
log_measurements = []
for las_file in las_files:
las = lasio.read(las_file)
for curve in las.curves:
if curve.mnemonic not in log_measurements:
log_measurements.append(curve.mnemonic)
print(f"Log measurements acquired: {log_measurements}")
The following is the output of the code run by the Python REPL tool, which is returned to the LLM to generate its final answer:
"""
LAS files for API #490251107500: ['/home/ec2-user/SageMaker/AmazonSageMaker-DXC-GAIIC-Opibus-Repo/data/raw/teapot_dome/Well Log Data/LAS_log_files/Shallow_LAS_files/49025110750000_480593.LAS']
Log measurements acquired: ['DEPT', 'GRR', 'RILD', 'RILM', 'RLL', 'SPR']
"""
Lastly, we have the LLM’s final answer in the backend, before it’s parsed and returned to the UI:
<final_answer>
<data>
<log_measurements>
DEPT, GRR, RILD, RILM, RLL, SPR
</log_measurements>
</data>
<resources>
<resource>
<location>/home/ec2-user/SageMaker/AmazonSageMaker-DXC-GAIIC-Opibus-Repo/data/raw/teapot_dome/Well Log Data/LAS_log_files/Shallow_LAS_files/49025110750000_480593.LAS</location>
Conversational capabilities
The basic router handles a single user query and isn’t aware of chat history. However, conversational context is an essential part of the user experience. For instance, when a user asks “What API produced the most oil in 2010,” a natural follow-up question would be “What measurements do we have for that API,” in which case we need to recall the API number from the previous context, or “What about 2011,” in which case we need to recall the fact that the question is to find the API that produced the most oil. To enable this ability to add follow-up questions, we added another layer before the router that takes the user query and the conversation history and rewrites the user query with context that might be missing from it. We can also use this query-rewriting layer to directly translate or summarize previous responses, without having to go to the router, which saves time for simple queries.
The following is the sample prompt for context-aware query rewriting. We give the LLM two choices: either directly reply to the question if it’s a translation of summarization of a previous interaction, because this doesn’t require the use of tools, or rewrite the query to forward it to an expert (the router plus the tool framework). To differentiate between the options, the LLM can use either <answer> tags or <new_query> tags in its reply. In both cases, we ask the LLM to start out by using <thinking> tags to logically think about which one is more appropriate. If the <answer> tag is present in the LLM’s reply, we directly forward that answer to the user. Otherwise, if the <new_query> tag is present, we forward that new query to the router for appropriate tool use. We also added few-shot examples to the prompt to make the query rewriting process more explicit for the LLM, and in our experience they were instrumental to the success of query rewriting.
query_rewriting_prompt = """
You are an AI assistant that helps a human answer oil and gas question.
You only know how to or rewrite previous interactions.
If the human asks for oil and gas specific knowledge, or to count and find specific
files, you should rewrite the query so it can be forwarded to an expert.
If the human tries to ask a question that is not related to oil and gas,
you should politely tell them that only oil and gas related questions are supported.
Here is the conversation between the human and the expert so far.
H is the human and E is the expert:
<history>
{history}
</history>
Here is the new query
<query>
{query}
</query>
If you can answer the question, your answer should be formatted as follows.
In the example, H is the human, E is the expert and A is you, the assistant.
<example>
H: How many wells are in section 24?
E: There are 42 wells
H: Can you rewrite that in French?
A: <think> This is a translation, I can answer.</think>
<answer>Il y a 42 puits.</answer>
</example>
<example>
H: Can you summarize that in one sentence?
A: <think> This is just rewriting, I can summarize the previous reply and
answer directly.</think>
<answer>Il y a 42 puits.</answer>
</example>
<example>
H: Who's the queen of England?
A: <think>This is unrelated, I can tell the user I can't answer.</think>
<answer>I am sorry but I can only answer questions about your files.</answer>
</example>
If you need to forward the question to the expert, your answer should be as follows
<example>
H: What is the depth of well x250?
E: It's 2000 ft
H : What about well y890?
A: <think>This requires expert knowledge and some context, and I need to rewrite
the query before I ask the expert.</think>
<new_query>What is the depth of well y890?</new_query>
</example>
<example>
H: How many pdf files do I have?
A: <think>This requires to look into the file system,
I need to forward the question to the expert.</think>
</new_query>How many pdf files do I have?</new_query>
</example>
Remember, You only know how to translate or rewrite previous interactions.
If the human asks for anything other than rewriting or translating,
you should rewrite the query so it can be forwarded to an expert.
If the query needs context from previous questions, rewrite the query so
the expert can understand it, otherwise, forward the query as-is.
If the human tries to ask a question that is not related to oil and gas,
you should politely tell them that only oil and gas related questions are supported.
"""
This query rewriting step adds an extra second in terms of latency, and could be toggled off, but it greatly enhances user experience because it enables follow-up questions. Another way to handle this would have been to combine the query rewriting and the router in a single prompt, but we find that it’s more straightforward for LLMs to perform tasks separately, because they can get overwhelmed when faced with too many instructions.
The following is an example of a conversational flow. The user first asks about the measurements for a given API, which requires the LAS tool. Then they follow up by asking production questions about that API, all using the production tool. Each of these questions builds on previous questions, which highlights the need for query rewriting. The table shows the initial user query and corresponding LLM-rewritten query, which accounts for previous context.
| User Query |
LLM Rewritten Query (Context Aware) |
| What log measurements were acquired for API #490251107500 |
What log measurements were acquired for API #490251107500? |
| How much oil did this API produce in September 2003? |
How much oil did API #490251107500 produce in September 2003? |
| What about November? |
For API #490251107500, how much oil did it produce in November 2003? |
| What month had the highest production that year? |
What steps would you take to analyze the production data for API #490251107500 and determine which month had the highest oil production in the year 2003? |
| Get me a table of the monthly productions for that API for that year, include the monthly production and the months in the table |
Please provide a table of the monthly oil productions for API #490251107500 for the year 2003. This API number and year were referenced in our previous discussion. |
The following screenshots show the corresponding flow in the UI and demonstrates that the tool is able to respond based on previous context.



Conclusion
In this post, we presented an AI assistant for efficient data exploration in the oil and gas industry powered by LLMs and optimized tools. The router uses the language understanding abilities of LLMs to route queries to specialized tools. We built custom tools optimized for major data types such as text, tables, and domain-specific formats like LAS. Conversational capabilities enable clarification and context-aware follow-up questions. The end-to-end solution showcases how LLMs can transform data exploration workflows through the use of specialized tools and conversational interfaces. Data exploration tasks that took hours can now be achieved in just a few minutes, dramatically reducing time to first oil for DXC’s customers.
In addition to the tools presented here, you can create additional generative AI tools to query SQL data bases or analyze other industry-specific formats. Additionally, instead of creating separate table tools for each CSV dataset, the selection of the relevant dataset could be part of the tables tools itself, further reducing the need for preprocessing when onboarding the solution.
If you’re interested in building a similar AI assistant that can use multiple tools, you can get started with Amazon Bedrock Agents, a fully managed AWS solution that helps orchestrate complex tasks.
About the authors
 Aude Genevay is a Senior Applied Scientist at the Generative AI Innovation Center, where she helps customers tackle critical business challenges and create value using generative AI. She holds a PhD in theoretical machine learning and enjoys turning cutting-edge research into real-world solutions.
Aude Genevay is a Senior Applied Scientist at the Generative AI Innovation Center, where she helps customers tackle critical business challenges and create value using generative AI. She holds a PhD in theoretical machine learning and enjoys turning cutting-edge research into real-world solutions.
 Asif Fouzi is a Principal Solutions Architect leading a team of seasoned technologists supporting Global Service Integrators (GSI) helping GSIs such as DXC in their cloud journey. When he is not innovating on behalf of users, he likes to play guitar, travel and spend time with his family.
Asif Fouzi is a Principal Solutions Architect leading a team of seasoned technologists supporting Global Service Integrators (GSI) helping GSIs such as DXC in their cloud journey. When he is not innovating on behalf of users, he likes to play guitar, travel and spend time with his family.
 Kaustubh Kambli is a Senior Manager responsible for Generative AI and Cloud Analytics Delivery at DXC. His team drives innovation and AI-powered solutions to meet client needs across multiple industries in AMS region. When he’s not focused on advancing AI technologies, Kaustubh enjoys exploring new places, engaging in creative pursuits and spending quality time with his loved ones.
Kaustubh Kambli is a Senior Manager responsible for Generative AI and Cloud Analytics Delivery at DXC. His team drives innovation and AI-powered solutions to meet client needs across multiple industries in AMS region. When he’s not focused on advancing AI technologies, Kaustubh enjoys exploring new places, engaging in creative pursuits and spending quality time with his loved ones.
 Anveshi Charuvaka is a Senior Applied Scientist at the Generative AI Innovation Center, where he develops Generative AI-driven solutions for customers’ critical business challenges. With a PhD in Machine Learning and over a decade of experience, he specializes in applying innovative machine learning and generative AI techniques to address complex real-world problems.
Anveshi Charuvaka is a Senior Applied Scientist at the Generative AI Innovation Center, where he develops Generative AI-driven solutions for customers’ critical business challenges. With a PhD in Machine Learning and over a decade of experience, he specializes in applying innovative machine learning and generative AI techniques to address complex real-world problems.
 Mofijul Islam is an Applied Scientist II at the AWS Generative AI Innovation Center, where he helps customers tackle customer-centric research and business challenges using generative AI, large language models (LLM), multi-agent learning, and multimodal learning. He holds a PhD in machine learning from the University of Virginia, where his work focused on multimodal machine learning, multilingual NLP, and multitask learning. His research has been published in top-tier conferences like NeurIPS, ICLR, AISTATS, and AAAI, as well as IEEE and ACM Transactions.
Mofijul Islam is an Applied Scientist II at the AWS Generative AI Innovation Center, where he helps customers tackle customer-centric research and business challenges using generative AI, large language models (LLM), multi-agent learning, and multimodal learning. He holds a PhD in machine learning from the University of Virginia, where his work focused on multimodal machine learning, multilingual NLP, and multitask learning. His research has been published in top-tier conferences like NeurIPS, ICLR, AISTATS, and AAAI, as well as IEEE and ACM Transactions.
 Yingwei Yu is an Applied Science Manager at Generative AI Innovation Center, AWS, where he leverages machine learning and generative AI to drive innovation across industries. With a PhD in Computer Science from Texas A&M University and years of working experience in Oil&Gas industry, Yingwei brings extensive expertise in applying cutting-edge technologies to real-world applications. Outside of work, he enjoys swimming, painting, MIDI composing, and spending time with family and friends.
Yingwei Yu is an Applied Science Manager at Generative AI Innovation Center, AWS, where he leverages machine learning and generative AI to drive innovation across industries. With a PhD in Computer Science from Texas A&M University and years of working experience in Oil&Gas industry, Yingwei brings extensive expertise in applying cutting-edge technologies to real-world applications. Outside of work, he enjoys swimming, painting, MIDI composing, and spending time with family and friends.
Read More




 Shreyas Subramanian is a principal data scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.
Shreyas Subramanian is a principal data scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks. Ron Widha is a Senior Software Development Manager with Amazon Bedrock Knowledge Bases, helping customers easily build scalable RAG applications.
Ron Widha is a Senior Software Development Manager with Amazon Bedrock Knowledge Bases, helping customers easily build scalable RAG applications. Satish Nandi is a Senior Product Manager with Amazon OpenSearch Service. He is focused on OpenSearch Serverless and has years of experience in networking, security and AI/ML. He holds a bachelor’s degree in computer science and an MBA in entrepreneurship. In his free time, he likes to fly airplanes and hang gliders and ride his motorcycle.
Satish Nandi is a Senior Product Manager with Amazon OpenSearch Service. He is focused on OpenSearch Serverless and has years of experience in networking, security and AI/ML. He holds a bachelor’s degree in computer science and an MBA in entrepreneurship. In his free time, he likes to fly airplanes and hang gliders and ride his motorcycle. Vamshi Vijay Nakkirtha is a Senior Software Development Manager working on the OpenSearch Project and Amazon OpenSearch Service. His primary interests include distributed systems.
Vamshi Vijay Nakkirtha is a Senior Software Development Manager working on the OpenSearch Project and Amazon OpenSearch Service. His primary interests include distributed systems.










 Rajdeep Banerjee is a Senior Partner Solutions Architect at AWS helping strategic partners and clients in the AWS cloud migration and digital transformation journey. Rajdeep focuses on working with partners to provide technical guidance on AWS, collaborate with them to understand their technical requirements, and designing solutions to meet their specific needs. He is a member of Serverless technical field community. Rajdeep is based out of Richmond, Virginia.
Rajdeep Banerjee is a Senior Partner Solutions Architect at AWS helping strategic partners and clients in the AWS cloud migration and digital transformation journey. Rajdeep focuses on working with partners to provide technical guidance on AWS, collaborate with them to understand their technical requirements, and designing solutions to meet their specific needs. He is a member of Serverless technical field community. Rajdeep is based out of Richmond, Virginia.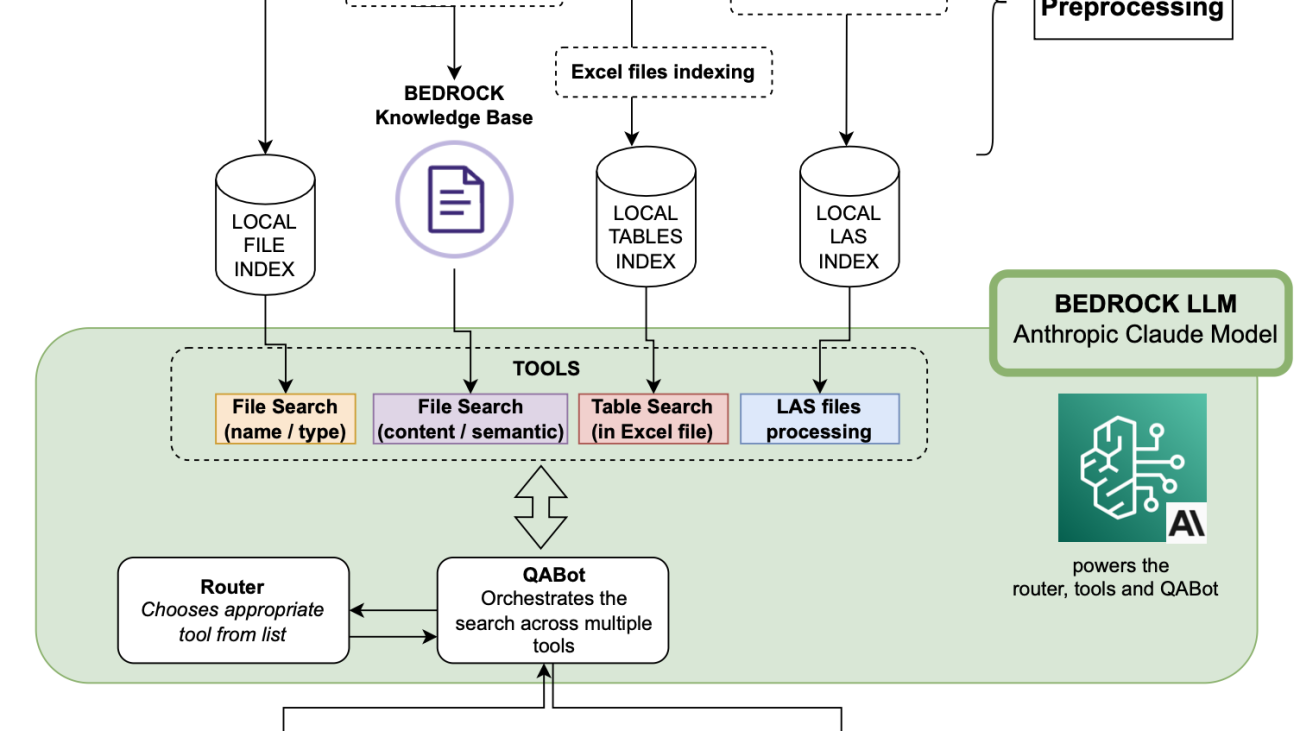



 Tesfagabir Meharizghi is an Applied Scientist at the AWS Generative AI Innovation Center, where he leads projects and collaborates with enterprise customers across various industries to leverage cutting-edge generative AI technologies in solving complex business challenges. He specializes in identifying and prioritizing high-impact use cases, developing scalable AI solutions, and fostering knowledge-sharing partnerships with stakeholders.
Tesfagabir Meharizghi is an Applied Scientist at the AWS Generative AI Innovation Center, where he leads projects and collaborates with enterprise customers across various industries to leverage cutting-edge generative AI technologies in solving complex business challenges. He specializes in identifying and prioritizing high-impact use cases, developing scalable AI solutions, and fostering knowledge-sharing partnerships with stakeholders. Aude Genevay is a Senior Applied Scientist at the Generative AI Innovation Center, where she helps customers tackle critical business challenges and create value using generative AI. She holds a PhD in theoretical machine learning and enjoys turning cutting-edge research into real-world solutions.
Aude Genevay is a Senior Applied Scientist at the Generative AI Innovation Center, where she helps customers tackle critical business challenges and create value using generative AI. She holds a PhD in theoretical machine learning and enjoys turning cutting-edge research into real-world solutions. Shinan Zhang is an Applied Science Manager at the AWS Generative AI Innovation Center. With over a decade of experience in ML and NLP, he has worked with large organizations from diverse industries to solve business problems with innovative AI solutions, and bridge the gap between research and industry applications.
Shinan Zhang is an Applied Science Manager at the AWS Generative AI Innovation Center. With over a decade of experience in ML and NLP, he has worked with large organizations from diverse industries to solve business problems with innovative AI solutions, and bridge the gap between research and industry applications.
 Henry Wang is a senior applied scientist at the AWS Generative AI Innovation Center, where he researches and builds generative AI solutions for AWS customers. His interest in adapting multimodal LLMs and building agentic workflows across custom domains. During his spare time, he likes to play tennis and golf.
Henry Wang is a senior applied scientist at the AWS Generative AI Innovation Center, where he researches and builds generative AI solutions for AWS customers. His interest in adapting multimodal LLMs and building agentic workflows across custom domains. During his spare time, he likes to play tennis and golf. Vladimir Turzhitsky is a Director of Data Science and Outcomes research at MSD. He received a Ph.D. degree from Northwestern University and obtained postdoctoral training at Harvard Medical School, where he later served as faculty researching algorithms and devices for cancer and other disease prediction. He joined Merck Research Laboratories in 2018, where his focus has been on applying data science methods for observational studies in healthcare.
Vladimir Turzhitsky is a Director of Data Science and Outcomes research at MSD. He received a Ph.D. degree from Northwestern University and obtained postdoctoral training at Harvard Medical School, where he later served as faculty researching algorithms and devices for cancer and other disease prediction. He joined Merck Research Laboratories in 2018, where his focus has been on applying data science methods for observational studies in healthcare. Varun Kumar Nomula is Principal AI/ML Engineer consultant for MSD, specializing in Generative AI, Cloud computing, and Data Science. He is passionate about leveraging cutting-edge technology to solve real-world challenges and creating impactful AI-driven solutions. Varun is also a published author of several books and research papers in the fields of AI and Healthcare, contributing to the academic and professional community.
Varun Kumar Nomula is Principal AI/ML Engineer consultant for MSD, specializing in Generative AI, Cloud computing, and Data Science. He is passionate about leveraging cutting-edge technology to solve real-world challenges and creating impactful AI-driven solutions. Varun is also a published author of several books and research papers in the fields of AI and Healthcare, contributing to the academic and professional community. Yezhou Sun is a data scientist and outcome researcher, and associate director at MSD. His works focus on real world evidence generation for market access and reimbursement, and the application of advanced analytics and AI/ML methods in outcome research. Prior to MSD, he was senior principal engineer at UnitedHealth Group/Optum, building AI/ML solutions for risk stratification and business process automation.
Yezhou Sun is a data scientist and outcome researcher, and associate director at MSD. His works focus on real world evidence generation for market access and reimbursement, and the application of advanced analytics and AI/ML methods in outcome research. Prior to MSD, he was senior principal engineer at UnitedHealth Group/Optum, building AI/ML solutions for risk stratification and business process automation.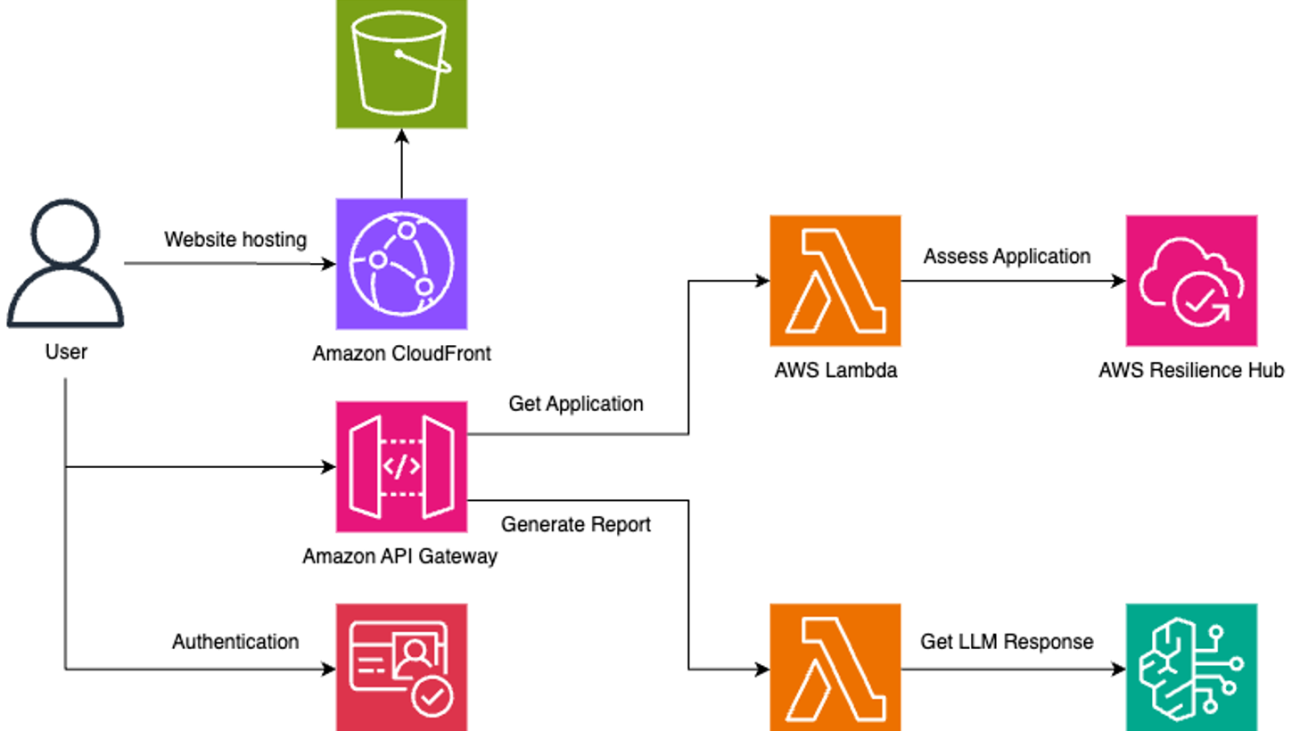





 Ibrahim Ahmad is a Solutions Architect at AWS with a focus in resilience and machine learning. He builds solutions for government technology customers to scale and modernize their cloud solutions. Outside of work, he loves to spend time with friends and family, work out, and race cars.
Ibrahim Ahmad is a Solutions Architect at AWS with a focus in resilience and machine learning. He builds solutions for government technology customers to scale and modernize their cloud solutions. Outside of work, he loves to spend time with friends and family, work out, and race cars. Mike P. is a Sr. Solutions Architect at AWS based in South Florida. He specializes in helping customers use AWS services to enhance their security posture and explore the potential of generative AI technologies. Mike works closely with organizations to design and implement robust security solutions while exploring innovative use cases for generative AI.
Mike P. is a Sr. Solutions Architect at AWS based in South Florida. He specializes in helping customers use AWS services to enhance their security posture and explore the potential of generative AI technologies. Mike works closely with organizations to design and implement robust security solutions while exploring innovative use cases for generative AI. Leland Johnson is a Sr. Solutions Architect for AWS focusing on travel and hospitality. As a Solutions Architect, he plays a crucial role in guiding customers through their cloud journey by designing scalable and secure cloud solutions. Outside of work, he enjoys playing music and flying light aircraft.
Leland Johnson is a Sr. Solutions Architect for AWS focusing on travel and hospitality. As a Solutions Architect, he plays a crucial role in guiding customers through their cloud journey by designing scalable and secure cloud solutions. Outside of work, he enjoys playing music and flying light aircraft.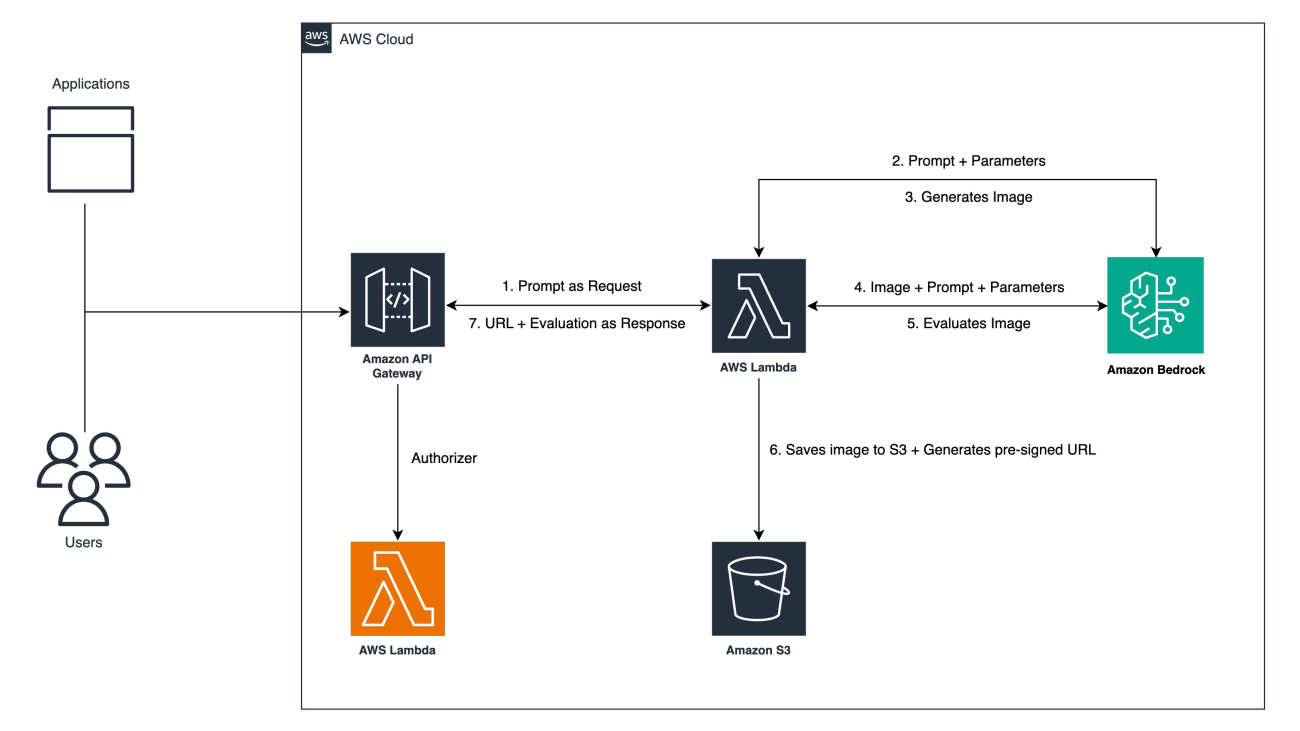






 Raul Tavares is a Solutions Architect focused on games customers across EMEA. With a strong engineering approach, when not knee-deep in cloud architecture, you can find him transforming ideas into solutions, writing code samples or listening to some Japanese heavy metal bands to relax.
Raul Tavares is a Solutions Architect focused on games customers across EMEA. With a strong engineering approach, when not knee-deep in cloud architecture, you can find him transforming ideas into solutions, writing code samples or listening to some Japanese heavy metal bands to relax.
