 A recap of the some of the biggest scientific breakthroughs over the past two years.Read More
A recap of the some of the biggest scientific breakthroughs over the past two years.Read More

A recap of the some of the biggest scientific breakthroughs over the past two years.Read More
In this blog, we present a case study on distilling a Llama 3.1 8B model into Llama 3.2 1B using torchtune’s knowledge distillation recipe. We demonstrate how knowledge distillation (KD) can be used in post-training to improve instruction-following task performance and showcase how users can leverage the recipe.
Knowledge Distillation is a widely used compression technique that transfers knowledge from a larger (teacher) model to a smaller (student) model. Larger models have more parameters and capacity for knowledge, however, this larger capacity is also more computationally expensive to deploy. Knowledge distillation can be used to compress the knowledge of a larger model into a smaller model. The idea is that performance of smaller models can be improved by learning from larger model’s outputs.
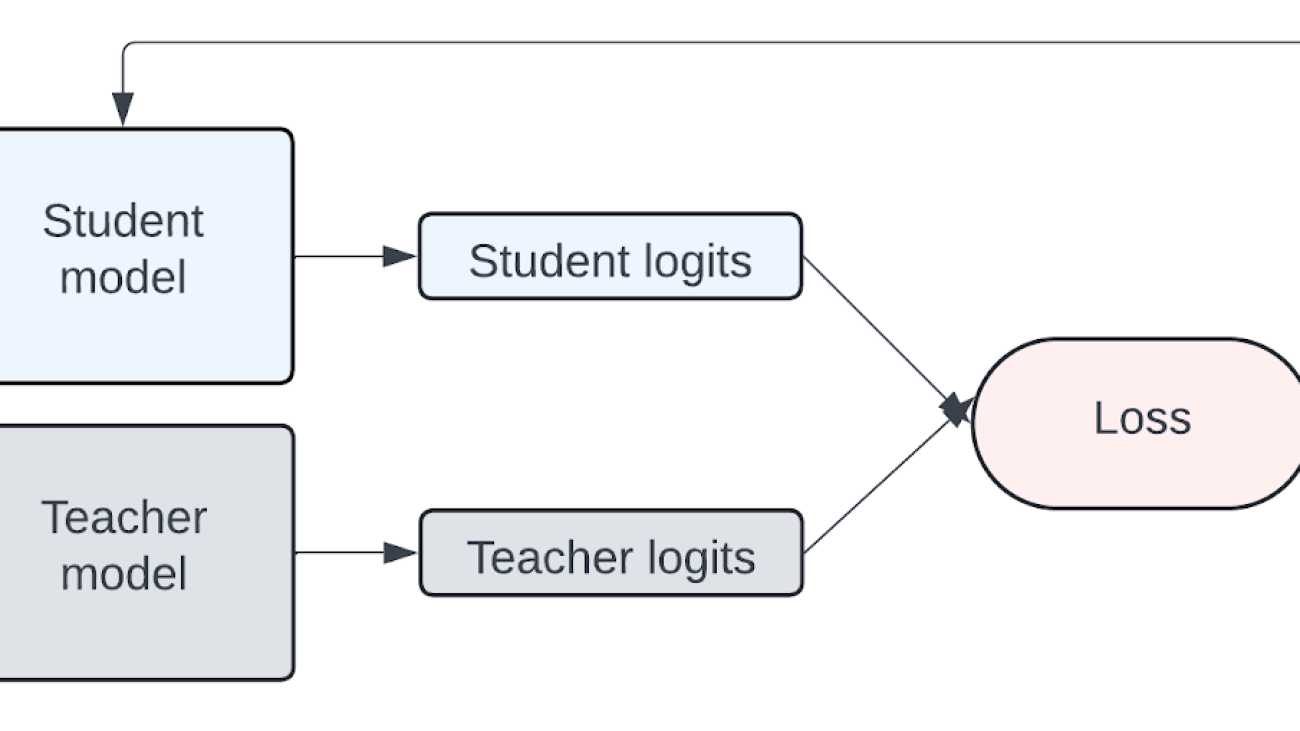
Knowledge is transferred from the teacher to student model by training on a transfer set where the student is trained to imitate the token-level probability distributions of the teacher. The assumption is that the teacher model distribution is similar to the transfer dataset. The diagram below is a simplified representation of how KD works.
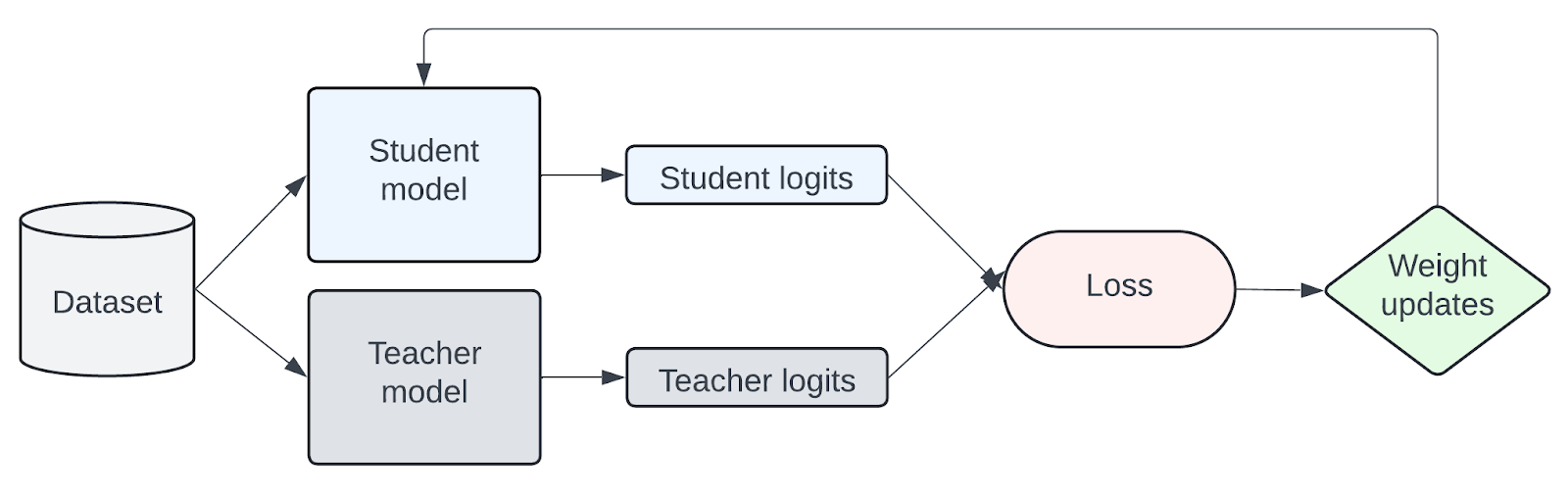
Figure 1: Simplified representation of knowledge transfer from teacher to student model
As knowledge distillation for LLMs is an active area of research, there are papers, such as MiniLLM, DistiLLM, AKL, and Generalized KD, investigating different loss approaches. In this case study, we focus on the standard cross-entropy (CE) loss with the forward Kullback-Leibler (KL) divergence loss as the baseline. Forward KL divergence aims to minimize the difference by forcing the student’s distribution to align with all of the teacher’s distributions.
The idea of knowledge distillation is that a smaller model can achieve better performance using a teacher model’s outputs as an additional signal than it could training from scratch or with supervised fine-tuning. For instance, Llama 3.2 lightweight 1B and 3B text models incorporated logits from Llama 3.1 8B and 70B to recover performance after pruning. In addition, for fine-tuning on instruction-following tasks, research in LLM distillation demonstrates that knowledge distillation methods can outperform supervised fine-tuning (SFT) alone.
| Model | Method | DollyEval | Self-Inst | S-NI |
| GPT-4 Eval | GPT-4 Eval | Rouge-L | ||
| Llama 7B | SFT | 73.0 | 69.2 | 32.4 |
| KD | 73.7 | 70.5 | 33.7 | |
| MiniLLM | 76.4 | 73.1 | 35.5 | |
| Llama 1.1B | SFT | 22.1 | – | 27.8 |
| KD | 22.2 | – | 28.1 | |
| AKL | 24.4 | – | 31.4 | |
| OpenLlama 3B | SFT | 47.3 | 41.7 | 29.3 |
| KD | 44.9 | 42.1 | 27.9 | |
| SeqKD | 48.1 | 46.0 | 29.1 | |
| DistiLLM | 59.9 | 53.3 | 37.6 |
Table 1: Comparison of knowledge distillation approaches to supervised fine-tuning
Below is a simplified example of how knowledge distillation differs from supervised fine-tuning.
| Supervised fine-tuning | Knowledge distillation |
|---|---|
|
|
With torchtune, we can easily apply knowledge distillation to Llama3, as well as other LLM model families, using torchtune’s KD recipe. The objective for this recipe is to fine-tune Llama3.2-1B on the Alpaca instruction-following dataset by distilling from Llama3.1-8B. This recipe focuses on post-training and assumes the teacher and student models have already been pre-trained.
First, we have to download the model weights. To be consistent with other torchtune fine-tuning configs, we will use the instruction tuned models of Llama3.1-8B as teacher and Llama3.2-1B as student.
tune download meta-llama/Meta-Llama-3.1-8B-Instruct --output-dir /tmp/Meta-Llama-3.1-8B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
tune download meta-llama/Llama-3.2-1B-Instruct --output-dir /tmp/Llama-3.2-1B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
In order for the teacher model distribution to be similar to the Alpaca dataset, we will fine-tune the teacher model using LoRA. Based on our experiments, shown in the next section, we’ve found that KD performs better when the teacher model is already fine-tuned on the target dataset.
tune run lora_finetune_single_device --config llama3_1/8B_lora_single_device
Finally, we can run the following command to distill the fine-tuned 8B model into the 1B model on a single GPU. For this case study, we used a single A100 80GB GPU. We also have a distributed recipe for running on multiple devices.
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_device
In this section, we demonstrate how changing configurations and hyperparameters can affect performance. By default, our configuration uses the LoRA fine-tuned 8B teacher model, downloaded 1B student model, learning rate of 3e-4 and KD loss ratio of 0.5. For this case study, we fine-tuned on the alpaca_cleaned_dataset and evaluated the models on truthfulqa_mc2, hellaswag and commonsense_qa tasks through the EleutherAI LM evaluation harness. Let’s take a look at the effects of:
The default settings in the config uses the fine-tuned teacher model. Now, let’s take a look at the effects of not fine-tuning the teacher model first.
Taking a loss at the losses, using the baseline 8B as teacher results in a higher loss than using the fine-tuned teacher model. The KD loss also remains relatively constant, suggesting that the teacher model should have the same distributions as the transfer dataset.
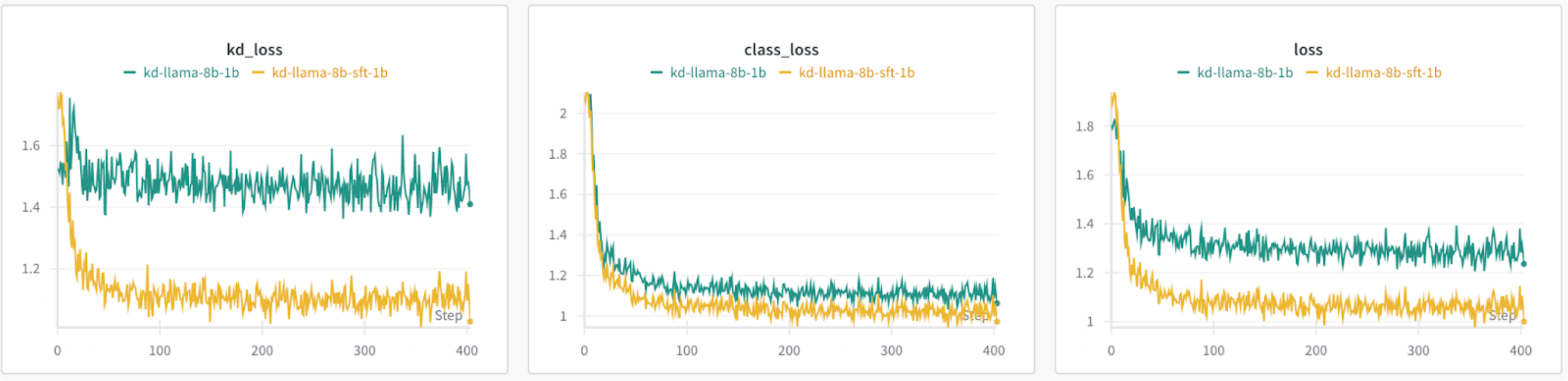
Figure 2: (left to right) KD loss from forward KL divergence, class loss from cross entropy, total loss: even combination of KD and class loss.
In our benchmarks, we can see that supervised fine-tuning of the 1B model achieves better accuracy than the baseline 1B model. By using the fine-tuned 8B teacher model, we see comparable results for truthfulqa and improvement for hellaswag and commonsense. When using the baseline 8B as a teacher, we see improvement across all metrics, but lower than the other configurations.
| Model | TruthfulQA | hellaswag | commonsense | |
| mc2 | acc | acc_norm | acc | |
| Baseline Llama 3.1 8B | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| Fine-tuned Llama 3.1 8B using LoRA | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| Baseline Llama 3.2 1B | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| Fine-tuned Llama 3.2 1B using LoRA | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| KD using baseline 8B as teacher | 0.444 | 0.4576 | 0.6123 | 0.5561 |
| KD using fine-tuned 8B as teacher | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
Table 2: Comparison between using baseline and fine-tuned 8B as teacher model
For these experiments, we look at the effects of KD when the student model is already fine-tuned. We analyze the effects using different combinations of baseline and fine-tuned 8B and 1B models.
Based on the loss graphs, using a fine-tuned teacher model results in a lower loss irrespective of whether the student model is fine-tuned or not. It’s also interesting to note that the class loss starts to increase when using a fine-tuned student model.
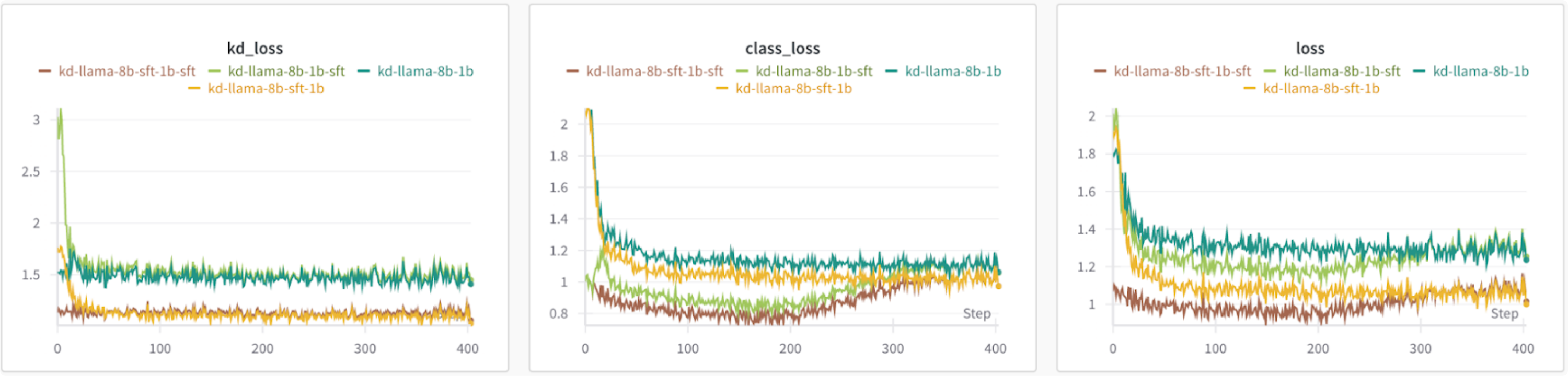
Figure 3: Comparing losses of different teacher and student model initializations
Using the fine-tuned student model boosts accuracy even further for truthfulqa, but the accuracy drops for hellaswag and commonsense. Using a fine-tuned teacher model and baseline student model achieved the best results on hellaswag and commonsense dataset. Based on these findings, the best configuration will change depending on which evaluation dataset and metric you are optimizing for.
| Model | TruthfulQA | hellaswag | commonsense | |
| mc2 | acc | acc_norm | acc | |
| Baseline Llama 3.1 8B | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| Fine-tuned Llama 3.1 8B using LoRA | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| Baseline Llama 3.2 1B | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| Fine-tuned Llama 3.2 1B using LoRA | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| KD using baseline 8B and baseline 1B | 0.444 | 0.4576 | 0.6123 | 0.5561 |
| KD using baseline 8B and fine-tuned 1B | 0.4508 | 0.448 | 0.6004 | 0.5274 |
| KD using fine-tuned 8B and baseline 1B | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
| KD using fine-tuned 8B and fine-tuned 1B | 0.4713 | 0.4512 | 0.599 | 0.5233 |
Table 3: Comparison using baseline and fine-tuned teacher and student models
By default, the recipe has a learning rate of 3e-4. For these experiments, we changed the learning rate from as high as 1e-3 to as low as 1e-5.
Based on the loss graphs, all learning rates result in similar losses except for 1e-5, which has a higher KD and class loss.
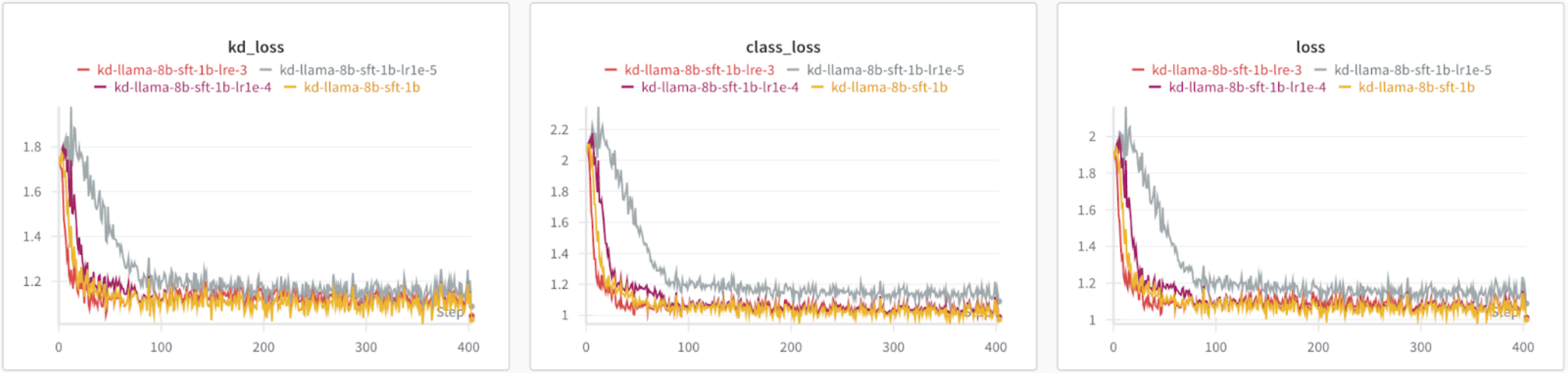
Figure 4: Comparing losses of different learning rates
Based on our benchmarks, the optimal learning rate changes depending on which metric and tasks you are optimizing for.
| Model | learning rate | TruthfulQA | hellaswag | commonsense | |
| mc2 | acc | acc_norm | acc | ||
| Baseline Llama 3.1 8B | – | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| Fine-tuned Llama 3.1 8B using LoRA | – | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| Baseline Llama 3.2 1B | – | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| Fine-tuned Llama 3.2 1B using LoRA | – | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| KD using fine-tuned 8B and baseline 1B | 3e-4 | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
| KD using fine-tuned 8B and baseline 1B | 1e-3 | 0.4453 | 0.4535 | 0.6071 | 0.5258 |
| KD using fine-tuned 8B and baseline 1B | 1e-4 | 0.4489 | 0.4606 | 0.6156 | 0.5586 |
| KD using fine-tuned 8B and baseline 1B | 1e-5 | 0.4547 | 0.4548 | 0.6114 | 0.5487 |
Table 4: Effects of tuning learning rate
By default, the KD ratio is set to 0.5, which gives even weighting to both the class and KD loss. In these experiments, we look at the effects of different KD ratios, where 0 only uses the class loss and 1 only uses the KD loss.
Overall, the benchmark results show that for these tasks and metrics, higher KD ratios perform slightly better.
| Model | kd_ratio (lr=3e-4) | TruthfulQA | hellaswag | commonsense | |
| mc2 | acc | acc_norm | acc | ||
| Baseline Llama 3.1 8B | – | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| Fine-tuned Llama 3.1 8B using LoRA | – | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| Baseline Llama 3.2 1B | – | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| Fine-tuned Llama 3.2 1B using LoRA | – | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| KD using fine-tuned 8B and baseline 1B | 0.25 | 0.4485 | 0.4595 | 0.6155 | 0.5602 |
| KD using fine-tuned 8B and baseline 1B | 0.5 | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
| KD using fine-tuned 8B and baseline 1B | 0.75 | 0.4543 | 0.463 | 0.6189 | 0.5643 |
| KD using fine-tuned 8B and baseline 1B | 1.0 | 0.4537 | 0.4641 | 0.6177 | 0.5717 |
Table 5: Effects of tuning KD ratio
In this blog, we presented a study on how to distill LLMs through torchtune using the forward KL divergence loss on Llama 3.1 8B and Llama 3.2 1B logits. There are many directions for future exploration to further improve performance and offer more flexibility in distillation methods.
This paper was accepted at the Self-Supervised Learning – Theory and Practice (SSLTP) Workshop at NeurIPS 2024.
Image-based Joint-Embedding Predictive Architecture (IJEPA) offers an attractive alternative to Masked Autoencoder (MAE) for representation learning using the Masked Image Modeling framework. IJEPA drives representations to capture useful semantic information by predicting in latent rather than input space. However, IJEPA relies on carefully designed context and target windows to avoid representational collapse. The encoder modules in IJEPA cannot adaptively modulate the type of…Apple Machine Learning Research
This paper considers the learning of logical (Boolean) functions with a focus on the generalization on the unseen (GOTU) setting, a strong case of out-of-distribution generalization. This is motivated by the fact that the rich combinatorial nature of data in certain reasoning tasks (e.g., arithmetic/logic) makes representative data sampling challenging, and learning successfully under GOTU gives a first vignette of an ‘extrapolating’ or ‘reasoning’ learner. We study how different network architectures trained by (S)GD perform under GOTU and provide both theoretical and experimental evidence…Apple Machine Learning Research
This paper was accepted at the Efficient Natural Language and Speech Processing (ENLSP) Workshop at NeurIPS 2024.
Large Language Models (LLMs) typically generate outputs token by token using a fixed compute budget, leading to inefficient resource utilization. To address this shortcoming, recent advancements in mixture of expert (MoE) models, speculative decoding, and early exit strategies leverage the insight that computational demands can vary significantly based on the complexity and nature of the input. However, identifying optimal routing patterns for dynamic execution remains an open…Apple Machine Learning Research
We present Recurrent Drafter (ReDrafter), an advanced speculative decoding approach that achieves state-of-the-art speedup for large language models (LLMs) inference. The performance gains are driven by three key aspects: (1) leveraging a recurrent neural network (RNN) as the draft model conditioning on LLM’s hidden states, (2) applying a dynamic tree attention algorithm over beam search results to eliminate duplicated prefixes in candidate sequences, and (3) training through knowledge distillation from the LLM. ReDrafter accelerates Vicuna inference in MT-Bench by up to 3.5x with a PyTorch…Apple Machine Learning Research
The rapid advancement of generative AI promises transformative innovation, yet it also presents significant challenges. Concerns about legal implications, accuracy of AI-generated outputs, data privacy, and broader societal impacts have underscored the importance of responsible AI development. Responsible AI is a practice of designing, developing, and operating AI systems guided by a set of dimensions with the goal to maximize benefits while minimizing potential risks and unintended harm. Our customers want to know that the technology they are using was developed in a responsible way. They also want resources and guidance to implement that technology responsibly in their own organization. Most importantly, they want to make sure the technology they roll out is for everyone’s benefit, including end-users. At AWS, we are committed to developing AI responsibly, taking a people-centric approach that prioritizes education, science, and our customers, integrating responsible AI across the end-to-end AI lifecycle.
What constitutes responsible AI is continually evolving. For now, we consider eight key dimensions of responsible AI: Fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency. These dimensions make up the foundation for developing and deploying AI applications in a responsible and safe manner.
At AWS, we help our customers transform responsible AI from theory into practice—by giving them the tools, guidance, and resources to get started with purpose-built services and features, such as Amazon Bedrock Guardrails. In this post, we introduce the core dimensions of responsible AI and explore considerations and strategies on how to address these dimensions for Amazon Bedrock applications. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
The safety dimension in responsible AI focuses on preventing harmful system output and misuse. It focuses on steering AI systems to prioritize user and societal well-being.
Amazon Bedrock is designed to facilitate the development of secure and reliable AI applications by incorporating various safety measures. In the following sections, we explore different aspects of implementing these safety measures and provide guidance for each.
Amazon Bedrock Guardrails supports AI safety by working towards preventing the application from generating or engaging with content that is considered unsafe or undesirable. These safeguards can be created for multiple use cases and implemented across multiple FMs, depending on your application and responsible AI requirements. For example, you can use Amazon Bedrock Guardrails to filter out harmful user inputs and toxic model outputs, redact by either blocking or masking sensitive information from user inputs and model outputs, or help prevent your application from responding to unsafe or undesired topics.
Content filters can be used to detect and filter harmful or toxic user inputs and model-generated outputs. By implementing content filters, you can help prevent your AI application from responding to inappropriate user behavior, and make sure your application provides only safe outputs. This can also mean providing no output at all, in situations where certain user behavior is unwanted. Content filters support six categories: hate, insults, sexual content, violence, misconduct, and prompt injections. Filtering is done based on confidence classification of user inputs and FM responses across each category. You can adjust filter strengths to determine the sensitivity of filtering harmful content. When a filter is increased, it increases the probability of filtering unwanted content.
Denied topics are a set of topics that are undesirable in the context of your application. These topics will be blocked if detected in user queries or model responses. You define a denied topic by providing a natural language definition of the topic along with a few optional example phrases of the topic. For example, if a medical institution wants to make sure their AI application avoids giving any medication or medical treatment-related advice, they can define the denied topic as “Information, guidance, advice, or diagnoses provided to customers relating to medical conditions, treatments, or medication” and optional input examples like “Can I use medication A instead of medication B,” “Can I use Medication A for treating disease Y,” or “Does this mole look like skin cancer?” Developers will need to specify a message that will be displayed to the user whenever denied topics are detected, for example “I am an AI bot and cannot assist you with this problem, please contact our customer service/your doctor’s office.” Avoiding specific topics that aren’t toxic by nature but can potentially be harmful to the end-user is crucial when creating safe AI applications.
Word filters are used to configure filters to block undesirable words, phrases, and profanity. Such words can include offensive terms or undesirable outputs, like product or competitor information. You can add up to 10,000 items to the custom word filter to filter out topics you don’t want your AI application to produce or engage with.
Sensitive information filters are used to block or redact sensitive information such as personally identifiable information (PII) or your specified context-dependent sensitive information in user inputs and model outputs. This can be useful when you have requirements for sensitive data handling and user privacy. If the AI application doesn’t process PII information, your users and your organization are safer from accidental or intentional misuse or mishandling of PII. The filter is configured to block sensitive information requests; upon such detection, the guardrail will block content and display a preconfigured message. You can also choose to redact or mask sensitive information, which will either replace the data with an identifier or delete it completely.
Amazon Bedrock provides a built-in capability for model evaluation. Model evaluation is used to compare different models’ outputs and select the most appropriate model for your use case. Model evaluation jobs support common use cases for large language models (LLMs) such as text generation, text classification, question answering, and text summarization. You can choose to create either an automatic model evaluation job or a model evaluation job that uses a human workforce. For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. For human-in-the-loop evaluation, which can be done by either AWS managed or customer managed teams, you must bring your own dataset.
If you are planning on using automated model evaluation for toxicity, start by defining what constitutes toxic content for your specific application. This may include offensive language, hate speech, and other forms of harmful communication. Automated evaluations come with curated datasets to choose from. For toxicity, you can use either RealToxicityPrompts or BOLD datasets, or both. If you bring your custom model to Amazon Bedrock, you can implement scheduled evaluations by integrating regular toxicity assessments into your development pipeline at key stages of model development, such as after major updates or retraining sessions. For early detection, implement custom testing scripts that run toxicity evaluations on new data and model outputs continuously.
Amazon Bedrock and its safety capabilities helps developers create AI applications that prioritize safety and reliability, thereby fostering trust and enforcing ethical use of AI technology. You should experiment and iterate on chosen safety approaches to achieve their desired performance. Diverse feedback is also important, so think about implementing human-in-the-loop testing to assess model responses for safety and fairness.
Controllability focuses on having mechanisms to monitor and steer AI system behavior. It refers to the ability to manage, guide, and constrain AI systems to make sure they operate within desired parameters.
To provide direct control over what content the AI application can produce or engage with, you can use Amazon Bedrock Guardrails, which we discussed under the safety dimension. This allows you to steer and manage the system’s outputs effectively.
You can use content filters to manage AI outputs by setting sensitivity levels for detecting harmful or toxic content. By controlling how strictly content is filtered, you can steer the AI’s behavior to help avoid undesirable responses. This allows you to guide the system’s interactions and outputs to align with your requirements. Defining and managing denied topics helps control the AI’s engagement with specific subjects. By blocking responses related to defined topics, you help AI systems remain within the boundaries set for its operation.
Amazon Bedrock Guardrails can also guide the system’s behavior for compliance with content policies and privacy standards. Custom word filters allow you to block specific words, phrases, and profanity, giving you direct control over the language the AI uses. And managing how sensitive information is handled, whether by blocking or redacting it, allows you to control the AI’s approach to data privacy and security.
To asses and adjust AI performance, you can look at Amazon Bedrock model evaluation. This helps systems operate within desired parameters and meet safety and ethical standards. You can explore both automatic and human-in-the loop evaluation. These evaluation methods help you monitor and guide model performance by assessing how well models meet safety and ethical standards. Regular evaluations allow you to adjust and steer the AI’s behavior based on feedback and performance metrics.
Integrating scheduled toxicity assessments and custom testing scripts into your development pipeline helps you continuously monitor and adjust model behavior. This ongoing control helps AI systems to remain aligned with desired parameters and adapt to new data and scenarios effectively.
The fairness dimension in responsible AI considers the impacts of AI on different groups of stakeholders. Achieving fairness requires ongoing monitoring, bias detection, and adjustment of AI systems to maintain impartiality and justice.
To help with fairness in AI applications that are built on top of Amazon Bedrock, application developers should explore model evaluation and human-in-the-loop validation for model outputs at different stages of the machine learning (ML) lifecycle. Measuring bias presence before and after model training as well as at model inference is the first step in mitigating bias. When developing an AI application, you should set fairness goals, metrics, and potential minimum acceptable thresholds to measure performance across different qualities and demographics applicable to the use case. On top of these, you should create remediation plans for potential inaccuracies and bias, which may include modifying datasets, finding and deleting the root cause for bias, introducing new data, and potentially retraining the model.
Amazon Bedrock provides a built-in capability for model evaluation, as we explored under the safety dimension. For general text generation evaluation for measuring model robustness and toxicity, you can use the built-in fairness dataset Bias in Open-ended Language Generation Dataset (BOLD), which focuses on five domains: profession, gender, race, religious ideologies, and political ideologies. To assess fairness for other domains or tasks, you must bring your own custom prompt datasets.
The transparency dimension in generative AI focuses on understanding how AI systems make decisions, why they produce specific results, and what data they’re using. Maintaining transparency is critical for building trust in AI systems and fostering responsible AI practices.
To help meet the growing demand for transparency, AWS introduced AWS AI Service Cards, a dedicated resource aimed at enhancing customer understanding of our AI services. AI Service Cards serve as a cornerstone of responsible AI documentation, consolidating essential information in one place. They provide comprehensive insights into the intended use cases, limitations, responsible AI design principles, and best practices for deployment and performance optimization of our AI services. They are part of a comprehensive development process we undertake to build our services in a responsible way.
At the time of writing, we offer the following AI Service Cards for Amazon Bedrock models:
Service cards for other Amazon Bedrock models can be found directly on the provider’s website. Each card details the service’s specific use cases, the ML techniques employed, and crucial considerations for responsible deployment and use. These cards evolve iteratively based on customer feedback and ongoing service enhancements, so they remain relevant and informative.
An additional effort in providing transparency is the Amazon Titan Image Generator invisible watermark. Images generated by Amazon Titan come with this invisible watermark by default. This watermark detection mechanism enables you to identify images produced by Amazon Titan Image Generator, an FM designed to create realistic, studio-quality images in large volumes and at low cost using natural language prompts. By using watermark detection, you can enhance transparency around AI-generated content, mitigate the risks of harmful content generation, and reduce the spread of misinformation.
Content creators, news organizations, risk analysts, fraud detection teams, and more can use this feature to identify and authenticate images created by Amazon Titan Image Generator. The detection system also provides a confidence score, allowing you to assess the reliability of the detection even if the original image has been modified. Simply upload an image to the Amazon Bedrock console, and the API will detect watermarks embedded in images generated by the Amazon Titan model, including both the base model and customized versions. This tool not only supports responsible AI practices, but also fosters trust and reliability in the use of AI-generated content.
The veracity and robustness dimension in responsible AI focuses on achieving correct system outputs, even with unexpected or adversarial inputs. The main focus of this dimension is to address possible model hallucinations. Model hallucinations occur when an AI system generates false or misleading information that appears to be plausible. Robustness in AI systems makes sure model outputs are consistent and reliable under various conditions, including unexpected or adverse situations. A robust AI model maintains its functionality and delivers consistent and accurate outputs even when faced with incomplete or incorrect input data.
As introduced in the AI safety and controllability dimensions, Amazon Bedrock provides tools for evaluating AI models in terms of toxicity, robustness, and accuracy. This makes sure the models don’t produce harmful, offensive, or inappropriate content and can withstand various inputs, including unexpected or adversarial scenarios.
Accuracy evaluation helps AI models produce reliable and correct outputs across various tasks and datasets. In the built-in evaluation, accuracy is measured against a TREX dataset and the algorithm calculates the degree to which the model’s predictions match the actual results. The actual metric for accuracy depends on the chosen use case; for example, in text generation, the built-in evaluation calculates a real-world knowledge score, which examines the model’s ability to encode factual knowledge about the real world. This evaluation is essential for maintaining the integrity, credibility, and effectiveness of AI applications.
Robustness evaluation makes sure the model maintains consistent performance across diverse and potentially challenging conditions. This includes handling unexpected inputs, adversarial manipulations, and varying data quality without significant degradation in performance.
There are several techniques that you can consider when using LLMs in your applications to maximize veracity and robustness:
Model providers and tuners might not mitigate these hallucinations, but can inform the user that they might occur. This could be done by adding some disclaimers about using AI applications at the user’s own risk. We currently also see advances in research in methods that estimate uncertainty based on the amount of variation (measured as entropy) between multiple outputs. These new methods have proved much better at spotting when a question was likely to be answered incorrectly than previous methods.
The explainability dimension in responsible AI focuses on understanding and evaluating system outputs. By using an explainable AI framework, humans can examine the models to better understand how they produce their outputs. For the explainability of the output of a generative AI model, you can use techniques like training data attribution and CoT prompting, which we discussed under the veracity and robustness dimension.
For customers wanting to see attribution of information in completion, we recommend using RAG with an Amazon Bedrock knowledge base. Attribution works with RAG because the possible attribution sources are included in the prompt itself. Information retrieved from the knowledge base comes with source attribution to improve transparency and minimize hallucinations. Amazon Bedrock Knowledge Bases manages the end-to-end RAG workflow for you. When using the RetrieveAndGenerate API, the output includes the generated response, the source attribution, and the retrieved text chunks.
If there is one thing that is absolutely critical to every organization using generative AI technologies, it is making sure everything you do is and remains private, and that your data is protected at all times. The security and privacy dimension in responsible AI focuses on making sure data and models are obtained, used, and protected appropriately.
With Amazon Bedrock, if we look from a data privacy and localization perspective, AWS does not store your data—if we don’t store it, it can’t leak, it can’t be seen by model vendors, and it can’t be used by AWS for any other purpose. The only data we store is operational metrics—for example, for accurate billing, AWS collects metrics on how many tokens you send to a specific Amazon Bedrock model and how many tokens you receive in a model output. And, of course, if you create a fine-tuned model, we need to store that in order for AWS to host it for you. Data used in your API requests remains in the AWS Region of your choosing—API requests to the Amazon Bedrock API to a specific Region will remain completely within that Region.
If we look at data security, a common adage is that if it moves, encrypt it. Communications to, from, and within Amazon Bedrock are encrypted in transit—Amazon Bedrock doesn’t have a non-TLS endpoint. Another adage is that if it doesn’t move, encrypt it. Your fine-tuning data and model will by default be encrypted using AWS managed AWS Key Management Service (AWS KMS) keys, but you have the option to use your own KMS keys.
When it comes to identity and access management, AWS Identity and Access Management (IAM) controls who is authorized to use Amazon Bedrock resources. For each model, you can explicitly allow or deny access to actions. For example, one team or account could be allowed to provision capacity for Amazon Titan Text, but not Anthropic models. You can be as broad or as granular as you need to be.
Looking at network data flows for Amazon Bedrock API access, it’s important to remember that traffic is encrypted at all time. If you’re using Amazon Virtual Private Cloud (Amazon VPC), you can use AWS PrivateLink to provide your VPC with private connectivity through the regional network direct to the frontend fleet of Amazon Bedrock, mitigating exposure of your VPC to internet traffic with an internet gateway. Similarly, from a corporate data center perspective, you can set up a VPN or AWS Direct Connect connection to privately connect to a VPC, and from there you can have that traffic sent to Amazon Bedrock over PrivateLink. This should negate the need for your on-premises systems to send Amazon Bedrock related traffic over the internet. Following AWS best practices, you secure PrivateLink endpoints using security groups and endpoint policies to control access to these endpoints following Zero Trust principles.
Let’s also look at network and data security for Amazon Bedrock model customization. The customization process will first load your requested baseline model, then securely read your customization training and validation data from an S3 bucket in your account. Connection to data can happen through a VPC using a gateway endpoint for Amazon S3. That means bucket policies that you have can still be applied, and you don’t have to open up wider access to that S3 bucket. A new model is built, which is then encrypted and delivered to the customized model bucket—at no time does a model vendor have access to or visibility of your training data or your customized model. At the end of the training job, we also deliver output metrics relating to the training job to an S3 bucket that you had specified in the original API request. As mentioned previously, both your training data and customized model can be encrypted using a customer managed KMS key.
The first thing to keep in mind when implementing a generative AI application is data encryption. As mentioned earlier, Amazon Bedrock uses encryption in transit and at rest. For encryption at rest, you have the option to choose your own customer managed KMS keys over the default AWS managed KMS keys. Depending on your company’s requirements, you might want to use a customer managed KMS key. For encryption in transit, we recommend using TLS 1.3 to connect to the Amazon Bedrock API.
For terms and conditions and data privacy, it’s important to read the terms and conditions of the models (EULA). Model providers are responsible for setting up these terms and conditions, and you as a customer are responsible for evaluating these and deciding if they’re appropriate for your application. Always make sure you read and understand the terms and conditions before accepting, including when you request model access in Amazon Bedrock. You should make sure you’re comfortable with the terms. Make sure your test data has been approved by your legal team.
For privacy and copyright, it is the responsibility of the provider and the model tuner to make sure the data used for training and fine-tuning is legally available and can actually be used to fine-tune and train those models. It is also the responsibility of the model provider to make sure the data they’re using is appropriate for the models. Public data doesn’t automatically mean public for commercial usage. That means you can’t use this data to fine-tune something and show it to your customers.
To protect user privacy, you can use the sensitive information filters in Amazon Bedrock Guardrails, which we discussed under the safety and controllability dimensions.
Lastly, when automating with generative AI (for example, with Amazon Bedrock Agents), make sure you’re comfortable with the model making automated decisions and consider the consequences of the application providing wrong information or actions. Therefore, consider risk management here.
The governance dimension makes sure AI systems are developed, deployed, and managed in a way that aligns with ethical standards, legal requirements, and societal values. Governance encompasses the frameworks, policies, and rules that direct AI development and use in a way that is safe, fair, and accountable. Setting and maintaining governance for AI allows stakeholders to make informed decisions around the use of AI applications. This includes transparency about how data is used, the decision-making processes of AI, and the potential impacts on users.
Robust governance is the foundation upon which responsible AI applications are built. AWS offers a range of services and tools that can empower you to establish and operationalize AI governance practices. AWS has also developed an AI governance framework that offers comprehensive guidance on best practices across vital areas such as data and model governance, AI application monitoring, auditing, and risk management.
When looking at auditability, Amazon Bedrock integrates with the AWS generative AI best practices framework v2 from AWS Audit Manager. With this framework, you can start auditing your generative AI usage within Amazon Bedrock by automating evidence collection. This provides a consistent approach for tracking AI model usage and permissions, flagging sensitive data, and alerting on issues. You can use collected evidence to assess your AI application across eight principles: responsibility, safety, fairness, sustainability, resilience, privacy, security, and accuracy.
For monitoring and auditing purposes, you can use Amazon Bedrock built-in integrations with Amazon CloudWatch and AWS CloudTrail. You can monitor Amazon Bedrock using CloudWatch, which collects raw data and processes it into readable, near real-time metrics. CloudWatch helps you track usage metrics such as model invocations and token count, and helps you build customized dashboards for audit purposes either across one or multiple FMs in one or multiple AWS accounts. CloudTrail is a centralized logging service that provides a record of user and API activities in Amazon Bedrock. CloudTrail collects API data into a trail, which needs to be created inside the service. A trail enables CloudTrail to deliver log files to an S3 bucket.
Amazon Bedrock also provides model invocation logging, which is used to collect model input data, prompts, model responses, and request IDs for all invocations in your AWS account used in Amazon Bedrock. This feature provides insights on how your models are being used and how they are performing, enabling you and your stakeholders to make data-driven and responsible decisions around the use of AI applications. Model invocation logs need to be enabled, and you can decide whether you want to store this log data in an S3 bucket or CloudWatch logs.
From a compliance perspective, Amazon Bedrock is in scope for common compliance standards, including ISO, SOC, FedRAMP moderate, PCI, ISMAP, and CSA STAR Level 2, and is Health Insurance Portability and Accountability Act (HIPAA) eligible. You can also use Amazon Bedrock in compliance with the General Data Protection Regulation (GDPR). Amazon Bedrock is included in the Cloud Infrastructure Service Providers in Europe Data Protection Code of Conduct (CISPE CODE) Public Register. This register provides independent verification that Amazon Bedrock can be used in compliance with the GDPR. For the most up-to-date information about whether Amazon Bedrock is within the scope of specific compliance programs, see AWS services in Scope by Compliance Program and choose the compliance program you’re interested in.
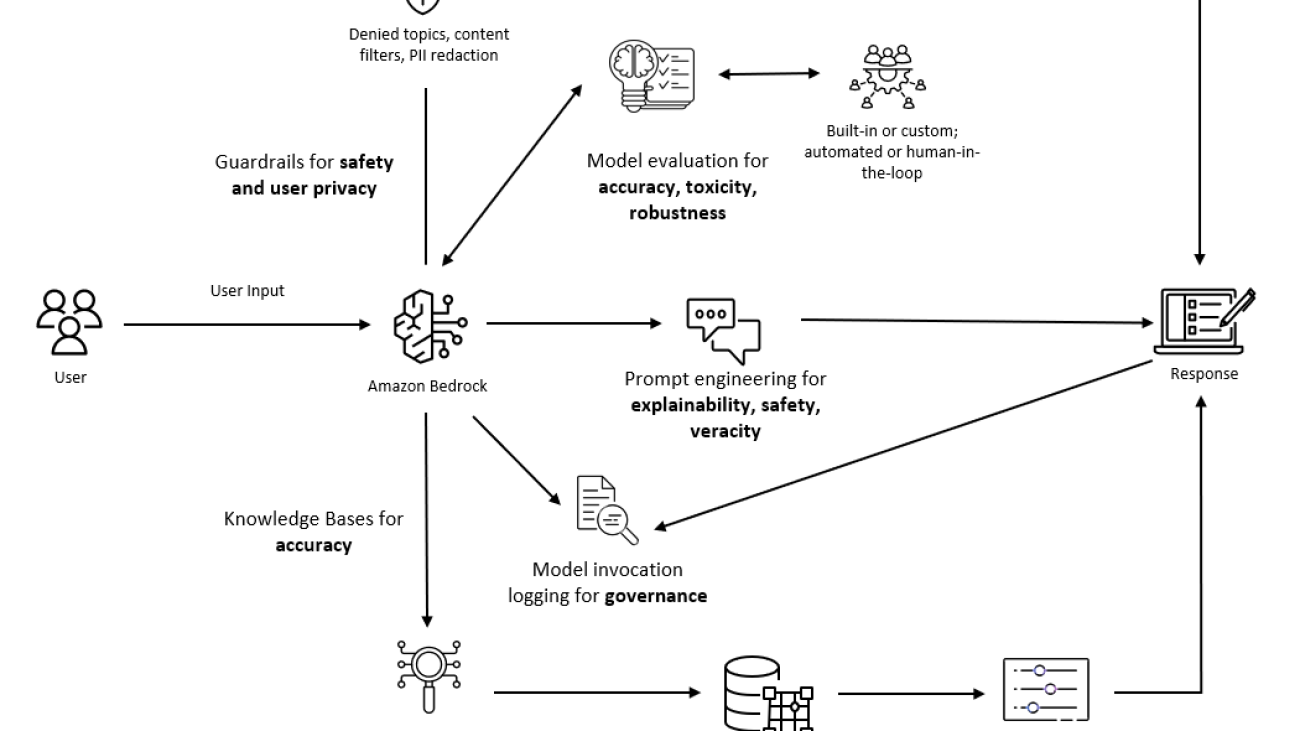
When building applications in Amazon Bedrock, consider your application context, needs, and behaviors of your end-users. Also, look into your organization’s needs, legal and regulatory requirements, and metrics you want or need to collect when implementing responsible AI. Take advantage of managed and built-in features available. The following diagram outlines various measures you can implement to address the core dimensions of responsible AI. This is not an exhaustive list, but rather a proposition of how the measures mentioned in this post could be combined together. These measures include:

Diagram outlining the various measures you can implement to address the core dimensions of responsible AI.
Building responsible AI applications requires a deliberate and structured approach, iterative development, and continuous effort. Amazon Bedrock offers a robust suite of built-in capabilities that support the development and deployment of responsible AI applications. By providing customizable features and the ability to integrate your own datasets, Amazon Bedrock enables developers to tune AI solutions to their specific application contexts and align them with organizational requirements for responsible AI. This flexibility makes sure AI applications are not only effective, but also ethical and aligned with best practices for fairness, safety, transparency, and accountability.
Implementing AI by following the responsible AI dimensions is key for developing and using AI solutions transparently, and without bias. Responsible development of AI will also help with AI adoption across your organization and build reliability with end customers. The broader the use and impact of your application, the more important following the responsibility framework becomes. Therefore, consider and address the responsible use of AI early on in your AI journey and throughout its lifecycle.
To learn more about the responsible use of ML framework, refer to the following resources:
 Laura Verghote is a senior solutions architect for public sector customers in EMEA. She works with customers to design and build solutions in the AWS Cloud, bridging the gap between complex business requirements and technical solutions. She joined AWS as a technical trainer and has wide experience delivering training content to developers, administrators, architects, and partners across EMEA.
Laura Verghote is a senior solutions architect for public sector customers in EMEA. She works with customers to design and build solutions in the AWS Cloud, bridging the gap between complex business requirements and technical solutions. She joined AWS as a technical trainer and has wide experience delivering training content to developers, administrators, architects, and partners across EMEA.
 Maria Lehtinen is a solutions architect for public sector customers in the Nordics. She works as a trusted cloud advisor to her customers, guiding them through cloud system development and implementation with strong emphasis on AI/ML workloads. She joined AWS through an early-career professional program and has previous work experience from cloud consultant position at one of AWS Advanced Consulting Partners.
Maria Lehtinen is a solutions architect for public sector customers in the Nordics. She works as a trusted cloud advisor to her customers, guiding them through cloud system development and implementation with strong emphasis on AI/ML workloads. She joined AWS through an early-career professional program and has previous work experience from cloud consultant position at one of AWS Advanced Consulting Partners.
In Part 1 of this series, we defined the Retrieval Augmented Generation (RAG) framework to augment large language models (LLMs) with a text-only knowledge base. We gave practical tips, based on hands-on experience with customer use cases, on how to improve text-only RAG solutions, from optimizing the retriever to mitigating and detecting hallucinations.
This post focuses on doing RAG on heterogeneous data formats. We first introduce routers, and how they can help managing diverse data sources. We then give tips on how to handle tabular data and will conclude with multimodal RAG, focusing specifically on solutions that handle both text and image data.
After a first wave of text-only RAG, we saw an increase in customers wanting to use a variety of data for Q&A. The challenge here is to retrieve the relevant data source to answer the question and correctly extract information from that data source. Use cases we have worked on include:
In RAG systems, a router is a component that directs incoming user queries to the appropriate processing pipeline based on the query’s nature and the required data type. This routing capability is crucial when dealing with heterogeneous data sources, because different data types often require distinct retrieval and processing strategies.
Consider a financial data analysis system. For a qualitative question like “What caused inflation in 2023?”, the router would direct the query to a text-based RAG that retrieves relevant documents and uses an LLM to generate an answer based on textual information. However, for a quantitative question such as “What was the average inflation in 2023?”, the router would direct the query to a different pipeline that fetches and analyzes the relevant dataset.
The router accomplishes this through intent detection, analyzing the query to determine the type of data and analysis required to answer it. In systems with heterogeneous data, this process makes sure each data type is processed appropriately, whether it’s unstructured text, structured tables, or multimodal content. For instance, analyzing large tables might require prompting the LLM to generate Python or SQL and running it, rather than passing the tabular data to the LLM. We give more details on that aspect later in this post.
In practice, the router module can be implemented with an initial LLM call. The following is an example prompt for a router, following the example of financial analysis with heterogeneous data. To avoid adding too much latency with the routing step, we recommend using a smaller model, such as Anthropic’s Claude Haiku on Amazon Bedrock.
Prompting the LLM to explain the routing logic may help with accuracy, by forcing the LLM to “think” about its answer, and also for debugging purposes, to understand why a category might not be routed properly.
The prompt uses XML tags following Anthropic’s Claude best practices. Note that in this example prompt we used <data_source> tags but something similar such as <category> or <label> could also be used. Asking the LLM to also structure its response with XML tags allows us to parse out the category from the LLM answer, which can be done with the following code:
From a user’s perspective, if the LLM fails to provide the right routing category, the user can explicitly ask for the data source they want to use in the query. For instance, instead of saying “What caused inflation in 2023?”, the user could disambiguate by asking “What caused inflation in 2023 according to analysts?”, and instead of “What was the average inflation in 2023?”, the user could ask “What was the average inflation in 2023? Look at the indicators.”
Another option for a better user experience is to add an option to ask for clarifications in the router, if the LLM finds that the query is too ambiguous. We can add this as an additional “data source” in the router using the following code:
We use an associated example:
If in the LLM’s response, the data source is Clarifications, we can then directly return the content of the <reason> tags to the user for clarifications.
An alternative approach to routing is to use the native tool use capability (also known as function calling) available within the Bedrock Converse API. In this scenario, each category or data source would be defined as a ‘tool’ within the API, enabling the model to select and use these tools as needed. Refer to this documentation for a detailed example of tool use with the Bedrock Converse API.
Consider an oil and gas company analyzing a dataset of daily oil production. The analyst may ask questions such as “Show me all wells that produced oil on June 1st 2024,” “What well produced the most oil in June 2024?”, or “Plot the monthly oil production for well XZY for 2024.” Each question requires different treatment, with varying complexity. The first one involves filtering the dataset to return all wells with production data for that specific date. The second one requires computing the monthly production values from the daily data, then finding the maximum and returning the well ID. The third one requires computing the monthly average for well XYZ and then generating a plot.
LLMs don’t perform well at analyzing tabular data when it’s added directly in the prompt as raw text. A simple way to improve the LLM’s handling of tables is to add it in the prompt in a more structured format, such as markdown or XML. However, this method will only work if the question doesn’t require complex quantitative reasoning and the table is small enough. In other cases, we can’t reliably use an LLM to analyze tabular data, even when provided as structured format in the prompt.
On the other hand, LLMs are notably good at code generation; for instance, Anthropic’s Claude Sonnet 3.5 has 92% accuracy on the HumanEval code benchmark. We can take advantage of that capability by asking the LLM to write Python (if the data is stored in a CSV, Excel, or Parquet file) or SQL (if the data is stored in a SQL database) code that performs the required analysis. Popular libraries Llama Index and LangChain both offer out-of-the-box solutions for text-to-SQL (Llama Index, LangChain) and text-to-Pandas (Llama Index, LangChain) pipelines for quick prototyping. However, for better control over prompts, code execution, and outputs, it might be worth writing your own pipeline. Out-of-the-box solutions will typically prompt the LLM to write Python or SQL code to answer the user’s question, then parse and run the code from the LLM’s response, and finally send the code output back to the LLM for a final answer.
Going back to the oil and gas data analysis use case, take the question “Show me all wells that produced oil on June 1st 2024.” There could be hundreds of entries in the dataframe. In that case, a custom pipeline that directly returns the code output to the UI (the filtered dataframe for the date of June 1st 2024, with oil production greater than 0) would be more efficient than sending it to the LLM for a final answer. If the filtered dataframe is large, the additional call might cause high latency and even risks causing hallucinations. Writing your custom pipelines also allows you to perform some sanity checks on the code, to verify, for instance, that the code generated by the LLM will not create issues (such as modify existing files or data bases).
The following is an example of a prompt that can be used to generate Pandas code for data analysis:
We can then parse the code out from the <code> tags in the LLM response and run it using exec in Python. The following code is a full example:
Because we explicitly prompt the LLM to store the final result in the result variable, we know it will be stored in the local_vars dictionary under that key, and we can retrieve it that way. We can then either directly return this result to the user, or send it back to the LLM to generate its final response. Sending the variable back to the user directly can be useful if the request requires filtering and returning a large dataframe, for instance. Directly returning the variable to the user removes the risk of hallucination that can occur with large inputs and outputs.
An emerging trend in generative AI is multimodality, with models that can use text, images, audio, and video. In this post, we focus exclusively on mixing text and image data sources.
In an industrial maintenance use case, consider a technician facing an issue with a machine. To troubleshoot, they might need visual information about the machine, not just a textual guide.
In ecommerce, using multimodal RAG can enhance the shopping experience not only by allowing users to input images to find visually similar products, but also by providing more accurate and detailed product descriptions from visuals of the products.
We can categorize multimodal text and image RAG questions in three categories:
As with traditional RAG pipelines, the retrieval component is the basis of these solutions. Constructing a multimodal retriever requires having an embedding strategy that can handle this multimodality. There are two main options for this.
First, you could use a multimodal embedding model such as Amazon Titan Multimodal Embeddings, which can embed both images and text into a shared vector space. This allows for direct comparison and retrieval of text and images based on semantic similarity. This simple approach is effective for finding images that match a high-level description or for matching images of similar items. For instance, a query like “Show me summer dresses” would return a variety of images that fit that description. It’s also suitable for queries where the user uploads a picture and asks, “Show me dresses similar to that one.”
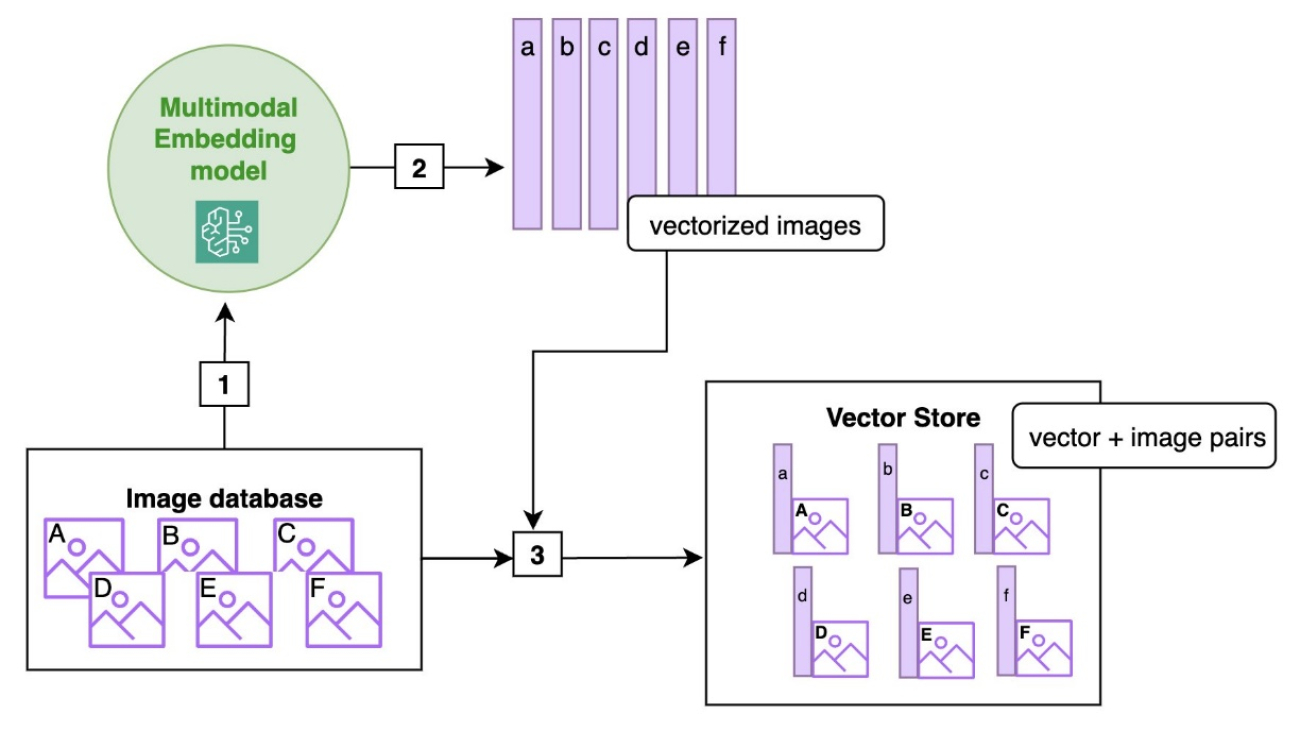
The following diagram shows the ingestion logic with a multimodal embedding. The images in the database are sent to a multimodal embedding model that returns vector representations of the images. The images and the corresponding vectors are paired up and stored in the vector database.

At retrieval time, the user query (which can be text or image) is passed to the multimodal embedding model, which returns a vectorized user query that is used by the retriever module to search for images that are close to the user query, in the embedding distance. The closest images are then returned.

Alternatively, you could use a multimodal foundation model (FM) such as Anthropic’s Claude v3 Haiku, Sonnet, or Opus, and Sonnet 3.5, all available on Amazon Bedrock, which can generate the caption of an image, which will then be used for retrieval. Specifically, the generated image description is embedded using a traditional text embedding (e.g. Amazon Titan Embedding Text v2) and stored in a vector store along with the image as metadata.
Captions can capture finer details in images, and can be guided to focus on specific aspects such as color, fabric, pattern, shape, and more. This would be better suited for queries where the user uploads an image and looks for similar items but only in some aspects (such as uploading a picture of a dress, and asking for skirts in a similar style). This would also work better to capture the complexity of diagrams in industrial maintenance.
The following figure shows the ingestion logic with a multimodal FM and text embedding. The images in the database are sent to a multimodal FM that returns image captions. The image captions are then sent to a text embedding model and converted to vectors. The images are paired up with the corresponding vectors and captions and stored in the vector database.

At retrieval time, the user query (text) is passed to the text embedding model, which returns a vectorized user query that is used by the retriever module to search for captions that are close to the user query, in the embedding distance. The images corresponding to the closest captions are then returned, optionally with the caption as well. If the user query contains an image, we need to use a multimodal LLM to describe that image similarly to the previous ingestion steps.

The following is a code sample performing ingestion with Amazon Titan Multimodal Embeddings as described earlier. The embedded image is stored in an OpenSearch index with a k-nearest neighbors (k-NN) vector field.
The following is the code sample performing the retrieval with Amazon Titan Multimodal Embeddings:
In the response, we have the images that are closest to the user query in embedding space, thanks to the multimodal embedding.
The following is a code sample performing the retrieval and ingestion described earlier. It uses Anthropic’s Claude Sonnet 3 to caption the image first, and then Amazon Titan Text Embeddings to embed the caption. You could also use another multimodal FM such as Anthropic’s Claude Sonnet 3.5, Haiku 3, or Opus 3 on Amazon Bedrock. The image, caption embedding, and caption are stored in an OpenSearch index. At retrieval time, we embed the user query using the same Amazon Titan Text Embeddings model and perform a k-NN search on the OpenSearch index to retrieve the relevant image.
The following is code to perform the retrieval step using text embeddings:
This returns the images whose captions are closest to the user query in the embedding space, thanks to the text embeddings. In the response, we get both the images and the corresponding captions for downstream use.
The following table provides a comparison between using multimodal embeddings and using a multimodal LLM for image captioning, across several key factors. Multimodal embeddings offer faster ingestion and are generally more cost-effective, making them suitable for large-scale applications where speed and efficiency are crucial. On the other hand, using a multimodal LLM for captions, though slower and less cost-effective, provides more detailed and customizable results, which is particularly useful for scenarios requiring precise image descriptions. Considerations such as latency for different input types, customization needs, and the level of detail required in the output should guide the decision-making process when selecting your approach.
| . | Multimodal Embeddings | Multimodal LLM for Captions |
| Speed | Faster ingestion | Slower ingestion due to additional LLM call |
| Cost | More cost-effective | Less cost-effective |
| Detail | Basic comparison based on embeddings | Detailed captions highlighting specific features |
| Customization | Less customizable | Highly customizable with prompts |
| Text Input Latency | Same as multimodal LLM | Same as multimodal embeddings |
| Image Input Latency | Faster, no extra processing required | Slower, requires extra LLM call to generate image caption |
| Best Use Case | General use, quick and efficient data handling | Precise searches needing detailed image descriptions |
Building real-world RAG systems with heterogeneous data formats presents unique challenges, but also unlocks powerful capabilities for enabling natural language interactions with complex data sources. By employing techniques like intent detection, code generation, and multimodal embeddings, you can create intelligent systems that can understand queries, retrieve relevant information from structured and unstructured data sources, and provide coherent responses. The key to success lies in breaking down the problem into modular components and using the strengths of FMs for each component. Intent detection helps route queries to the appropriate processing logic, and code generation enables quantitative reasoning and analysis on structured data sources. Multimodal embeddings and multimodal FMs enable you to bridge the gap between text and visual data, enabling seamless integration of images and other media into your knowledge bases.
Get started with FMs and embedding models in Amazon Bedrock to build RAG solutions that seamlessly integrate tabular, image, and text data for your organization’s unique needs.
 Aude Genevay is a Senior Applied Scientist at the Generative AI Innovation Center, where she helps customers tackle critical business challenges and create value using generative AI. She holds a PhD in theoretical machine learning and enjoys turning cutting-edge research into real-world solutions.
Aude Genevay is a Senior Applied Scientist at the Generative AI Innovation Center, where she helps customers tackle critical business challenges and create value using generative AI. She holds a PhD in theoretical machine learning and enjoys turning cutting-edge research into real-world solutions.
The Cohere Embed multimodal embeddings model is now generally available on Amazon SageMaker JumpStart. This model is the newest Cohere Embed 3 model, which is now multimodal and capable of generating embeddings from both text and images, enabling enterprises to unlock real value from their vast amounts of data that exist in image form.
In this post, we discuss the benefits and capabilities of this new model with some examples.
Multimodal embeddings are mathematical representations that integrate information not only from text but from multiple data modalities—such as product images, graphs, and charts—into a unified vector space. This integration allows for seamless interaction and comparison between different types of data. As foundational models (FMs) advance, they increasingly require the ability to interpret and generate content across various modalities to better mimic human understanding and communication. This trend toward multimodality enhances the capabilities of AI systems in tasks like cross-modal retrieval, where a query in one modality (such as text) retrieves data in another modality (such as images or design files).
Multimodal embeddings can enable personalized recommendations by understanding user preferences and matching them with the most relevant assets. For instance, in ecommerce, product images are a critical factor influencing purchase decisions. Multimodal embeddings models can enhance personalization through visual similarity search, where users can upload an image or select a product they like, and the system finds visually similar items. In the case of retail and fashion, multimodal embeddings can capture stylistic elements, enabling the search system to recommend products that fit a particular aesthetic, such as “vintage,” “bohemian,” or “minimalist.”
Multimodal Retrieval Augmented Generation (MM-RAG) is emerging as a powerful evolution of traditional RAG systems, addressing limitations and expanding capabilities across diverse data types. Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. However, as data becomes increasingly multimodal in nature, extending these systems to handle various data types is crucial to provide more comprehensive and contextually rich responses. MM-RAG systems that use multimodal embeddings models to encode both text and images into a shared vector space can simplify retrieval across modalities. MM-RAG systems can also enable enhanced customer service AI agents that can handle queries that involve both text and images, such as product defects or technical issues.
Cohere’s embeddings model, Embed 3, is an industry-leading AI search model that is designed to transform semantic search and generative AI applications. Cohere Embed 3 is now multimodal and capable of generating embeddings from both text and images. This enables enterprises to unlock real value from their vast amounts of data that exist in image form. Businesses can now build systems that accurately search important multimodal assets such as complex reports, ecommerce product catalogs, and design files to boost workforce productivity.
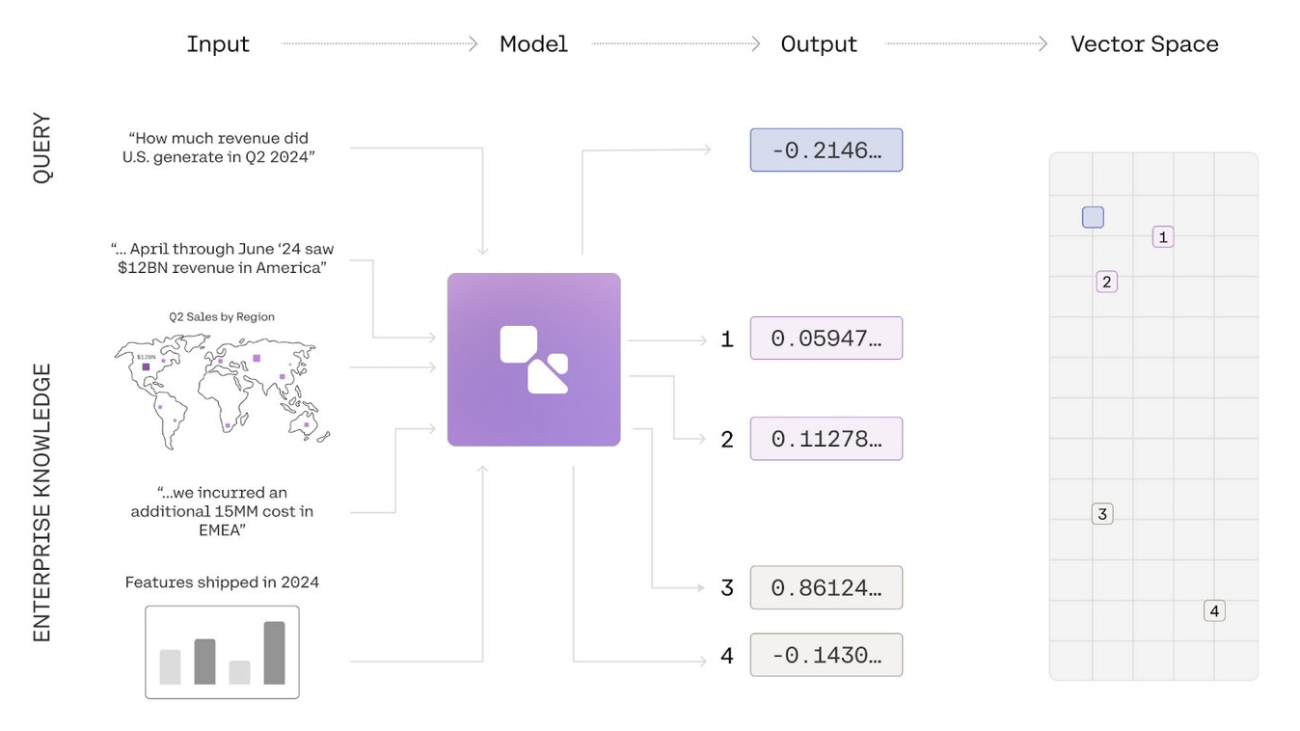
Cohere Embed 3 translates input data into long strings of numbers that represent the meaning of the data. These numerical representations are then compared to each other to determine similarities and differences. Cohere Embed 3 places both text and image embeddings in the same space for an integrated experience.
The following figure illustrates an example of this workflow. This figure is simplified for illustrative purposes. In practice, the numerical representations of data (seen in the output column) are far longer and the vector space that stores them has a higher number of dimensions.

This similarity comparison enables applications to retrieve enterprise data that is relevant to an end-user query. In addition to being a fundamental component of semantic search systems, Cohere Embed 3 is useful in RAG systems because it makes generative models like the Command R series have the most relevant context to inform their responses.
All businesses, across industry and size, can benefit from multimodal AI search. Specifically, customers are interested in the following real-world use cases:
The following figure illustrates some examples of these use cases.

At a time when businesses are increasingly expected to use their data to drive outcomes, Cohere Embed 3 offers several advantages that accelerate productivity and improves customer experience.
The following chart compares Cohere Embed 3 with another embeddings model. All text-to-image benchmarks are evaluated using Recall@5; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo. Graphs and charts benchmark accuracy is based on business reports and presentations constructed internally. ecommerce benchmark accuracy is based on a mix of product catalog and fashion catalog datasets. Design files benchmark accuracy is based on a product design retrieval dataset constructed internally.

BEIR (Benchmarking IR) is a heterogeneous benchmark—it uses a diverse collection of datasets and tasks designed for evaluating information retrieval (IR) models across diverse tasks. It provides a common framework for assessing the performance of natural language processing (NLP)-based retrieval models, making it straightforward to compare different approaches. Recall@5 is a specific metric used in information retrieval evaluation, including in the BEIR benchmark. Recall@5 measures the proportion of relevant items retrieved within the top five results, compared to the total number of relevant items in the dataset
Cohere’s latest Embed 3 model’s text and image encoders share a unified latent space. This approach has a few important benefits. First, it enables you to include both image and text features in a single database and therefore reduces complexity. Second, it means current customers can begin embedding images without re-indexing their existing text corpus. In addition to leading accuracy and ease of use, Embed 3 continues to deliver the same useful enterprise search capabilities as before. It can output compressed embeddings to save on database costs, it’s compatible with over 100 languages for multilingual search, and it maintains strong performance on noisy real-world data.
SageMaker JumpStart offers access to a broad selection of publicly available FMs. These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases. You can now use state-of-the-art model architectures, such as language models, computer vision models, and more, without having to build them from scratch.
Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from data preparation to model deployment and monitoring. Data scientists and developers can use the SageMaker integrated development environment (IDE) to access a vast array of pre-built algorithms, customize their own models, and seamlessly scale their solutions. The platform’s strength lies in its ability to abstract away the complexities of infrastructure management, allowing you to focus on innovation rather than operational overhead.
You can access the Cohere Embed family of models using SageMaker JumpStart in Amazon SageMaker Studio.
For those new to SageMaker JumpStart, we walk through using SageMaker Studio to access models in SageMaker JumpStart.
Make sure you meet the following prerequisites:
AmazonSageMakerFullAccess permission policy attached.aws-marketplace:ViewSubscriptionsaws-marketplace:Unsubscribeaws-marketplace:SubscribeDeployment starts when you choose the Deploy option. You may be prompted to subscribe to this model through AWS Marketplace. If you’re already subscribed, then you can proceed and choose Deploy. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK.

To subscribe to the model package, complete the following steps:
You will see a product ARN displayed. This is the model package ARN that you need to specify while creating a deployable model using Boto3.
arn:aws:sagemaker:[REGION]:[ACCOUNT_ID]:model-package/cohere-embed-english-v3-7-6d097a095fdd314d90a8400a620cac54To deploy the model using the SDK, copy the product ARN from the previous step and specify it in the model_package_arn in the following code:
Use the SageMaker SDK to create a client and deploy the models:
If the endpoint is already created using SageMaker Studio, you can simply connect to it:
Consider the following best practices:
The following code example illustrates how to perform real-time inference using Cohere Embed 3. We walk through a sample notebook to get started. You can also find the source code on the accompanying GitHub repo.
Import all required packages using the following code:
Use the following code to create helper functions that determine whether the input document is text or image, and download images given a list of URLs:
The following code shows a compute_embeddings() function we defined that will accept multimodal inputs to generate embeddings with Cohere Embed 3:
The Search() function generates query embeddings and computes a similarity matrix between the query and embeddings:
Let’s assemble all the input documents; notice that there are both text and image inputs:
Generate embeddings for the documents:
The output is a matrix of 11 items of 1,024 embedding dimensions.
Search for the most relevant documents given the query “Fun animal toy”
The following screenshots show the output.








Try another query “Learning toy for a 6 year old”.
As you can see from the results, the images and documents are returns based on the queries from the user and demonstrates functionality of the new version of Cohere embed 3 for multimodal embeddings.
To avoid incurring unnecessary costs, when you’re done, delete the SageMaker endpoints using the following code snippets:
Alternatively, to use the SageMaker console, complete the following steps:
Cohere Embed 3 for multimodal embeddings is now available with SageMaker and SageMaker JumpStart. To get started, refer to SageMaker JumpStart pretrained models.
Interested in diving deeper? Check out the Cohere on AWS GitHub repo.
 Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption. Breanne is also on the Women@Amazon board as co-director of Allyship with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor of Science in Computer Engineering from University of Illinois at Urbana Champaign.
Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption. Breanne is also on the Women@Amazon board as co-director of Allyship with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor of Science in Computer Engineering from University of Illinois at Urbana Champaign.
 Karan Singh is a Generative AI Specialist for third-party models at AWS, where he works with top-tier third-party foundation model (FM) providers to develop and execute joint Go-To-Market strategies, enabling customers to effectively train, deploy, and scale FMs to solve industry specific challenges. Karan holds a Bachelor of Science in Electrical and Instrumentation Engineering from Manipal University, a master’s in science in Electrical Engineering from Northwestern University and is currently an MBA Candidate at the Haas School of Business at University of California, Berkeley.
Karan Singh is a Generative AI Specialist for third-party models at AWS, where he works with top-tier third-party foundation model (FM) providers to develop and execute joint Go-To-Market strategies, enabling customers to effectively train, deploy, and scale FMs to solve industry specific challenges. Karan holds a Bachelor of Science in Electrical and Instrumentation Engineering from Manipal University, a master’s in science in Electrical Engineering from Northwestern University and is currently an MBA Candidate at the Haas School of Business at University of California, Berkeley.
 Yang Yang is an Independent Software Vendor (ISV) Solutions Architect at Amazon Web Services based in Seattle, where he supports customers in the financial services industry. Yang focuses on developing generative AI solutions to solve business and technical challenges and help drive faster time-to-market for ISV customers. Yang holds a Bachelor’s and Master’s degree in Computer Science from Texas A&M University.
Yang Yang is an Independent Software Vendor (ISV) Solutions Architect at Amazon Web Services based in Seattle, where he supports customers in the financial services industry. Yang focuses on developing generative AI solutions to solve business and technical challenges and help drive faster time-to-market for ISV customers. Yang holds a Bachelor’s and Master’s degree in Computer Science from Texas A&M University.
 Malhar Mane is an Enterprise Solutions Architect at AWS based in Seattle. He supports enterprise customers in the Digital Native Business (DNB) segment and specializes in generative AI and storage. Malhar is passionate about helping customers adopt generative AI to optimize their business. Malhar holds a Bachelor’s in Computer Science from University of California, Irvine.
Malhar Mane is an Enterprise Solutions Architect at AWS based in Seattle. He supports enterprise customers in the Digital Native Business (DNB) segment and specializes in generative AI and storage. Malhar is passionate about helping customers adopt generative AI to optimize their business. Malhar holds a Bachelor’s in Computer Science from University of California, Irvine.
This post is co-written with Mayur Patel, Nick Koenig, and Karthik Jetti from GoDaddy.
GoDaddy empowers everyday entrepreneurs by providing all the help and tools to succeed online. With 21 million customers worldwide, GoDaddy’s global solutions help seamlessly connect entrepreneurs’ identity and presence with commerce, leading to profitable growth. At GoDaddy, we take pride in being a data-driven company. Our relentless pursuit of valuable insights from data fuels our business decisions and works to achieve customer satisfaction.
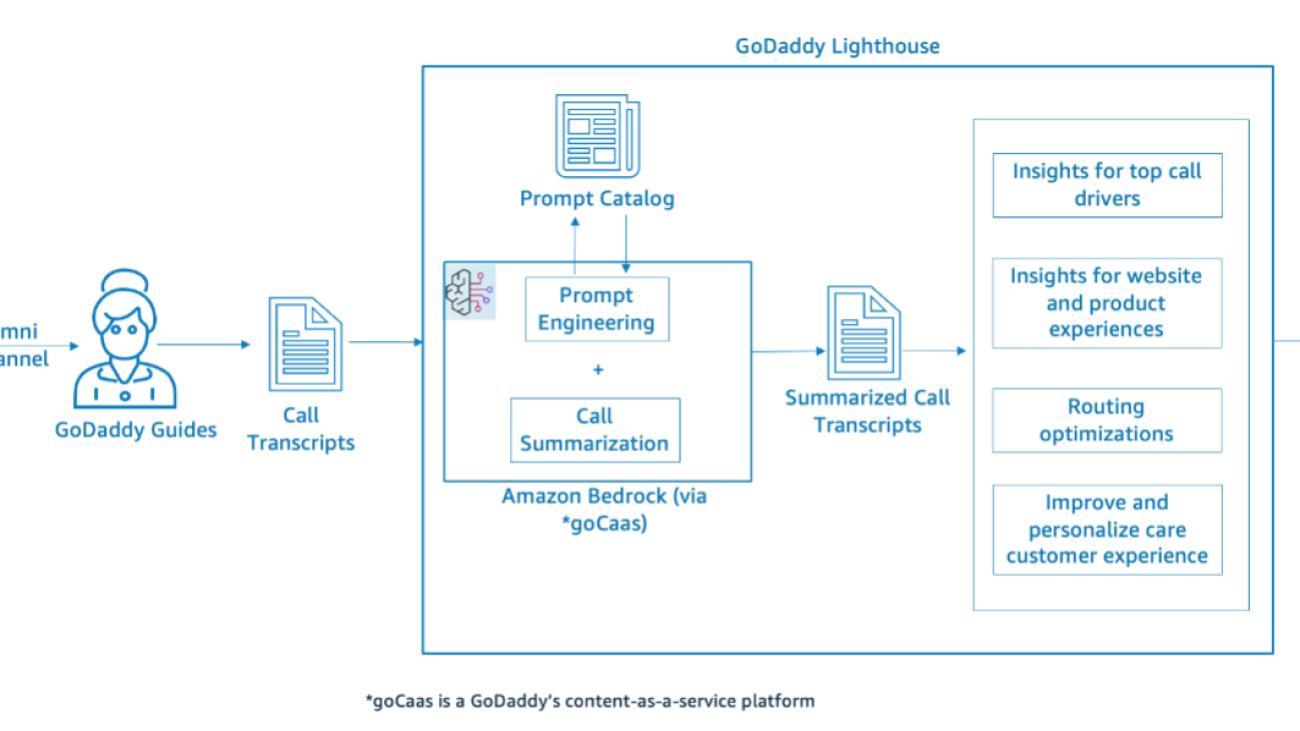
In this post, we discuss how GoDaddy’s Care & Services team, in close collaboration with the AWS GenAI Labs team, built Lighthouse—a generative AI solution powered by Amazon Bedrock. Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the AWS tools without having to manage infrastructure. With Amazon Bedrock, GoDaddy’s Lighthouse mines insights from customer care interactions using crafted prompts to identify top call drivers and reduce friction points in customers’ product and website experiences, leading to improved customer experience.
Data has always been a competitive advantage for GoDaddy, as has the Care & Services team . We realize the potential to derive meaningful insights from this data and identify key call drivers and pain points. In the world before generative AI, however, the technology for mining insights from unstructured data was computationally expensive and challenging to operationalize.
This changed with GoDaddy Lighthouse, a generative AI-powered interactions analytics solution, which unlocks the rich mine of insights sitting within our customer care transcript data. Fed by customer care interactions data, it enables scale for deep and actionable analysis, allowing us to:
The following diagram illustrates the high-level business workflow of Lighthouse.

GoDaddy Lighthouse is an insights solution powered by large language models (LLMs) that allows prompt engineers throughout the company to craft, manage, and evaluate prompts using a portal where they can interact with an LLM of their choice. By engineering prompts that run against an LLM, we can systematically derive powerful and standardized insights across text-based data. Product subject matter experts use the Lighthouse platform UI to test and iterate on generative AI prompts that produce tailored insights about a Care & Services interaction.
The below diagram shows the iterative process of creating and strengthening the prompts.

After the prompts are tested and confirmed to work as intended, they are deployed into production, where they are scaled across thousands of interactions. Then, the insights produced for each interaction are aggregated and visualized in dashboards and other analytical tools. Additionally, Lighthouse lets GoDaddy users craft one-time generative AI prompts to reveal rich insights for a highly specific customer scenario.
Let’s dive into how the Lighthouse architecture and features support users in generating insights. The following diagram illustrates the Lighthouse architecture on AWS.

The Lighthouse UI is powered by data generated from Amazon Bedrock LLM calls on thousands of transcripts, utilizing a library of prompts from GoDaddy’s internal prompt catalog. The UI facilitates the selection of LLM model based on the user’s choice, making the solution independent of one model. These LLM calls are processed sequentially using Amazon EMR and Amazon EMR Serverless. The seamless integration of backend data into the UI is facilitated by Amazon API Gateway and Amazon Lambdas functions, while the UI/UX is supported by AWS Fargate and Elastic Load Balancing to maintain high availability. For data storage and retrieval, Lighthouse employs a combination of Amazon DynamoDB, Amazon Simple Storage Service (Amazon S3), and Amazon Athena. Visual data analysis and representation are achieved through dashboards built on Tableau and Amazon QuickSight.
Lighthouse offers a unique proposition by allowing users to evaluate their one-time generative AI prompts using an LLM of their choice. This feature empowers users to write a new one-time prompt specifically for evaluation purposes. Lighthouse processes this new prompt using the actual transcript and response from a previous LLM call.
This capability is particularly valuable for users seeking to refine their prompts through multiple iterations. By iteratively adjusting and evaluating their prompts, users can progressively enhance and solidify the effectiveness of their queries. This iterative refinement process makes sure that users can achieve the highest-quality outputs tailored to their specific needs.
The flexibility and precision offered by this feature make Lighthouse an indispensable tool for anyone trying to optimize their interactions with LLMs, fostering continuous improvement and innovation in prompt engineering.
The following screenshot illustrates how Lighthouse lets users validate the accuracy of the model response with an evaluation prompt

After a prompt is evaluated for quality and the user is satisfied with the results, the prompt can be promoted into the prompt catalog.
After the user submits their prompt, Lighthouse processes this prompt against each available transcript, generating a series of responses. The user can then view the generated responses for that query on a dedicated page. This page serves as a valuable resource, allowing users to review the responses in detail and even download them into an Excel sheet for further analysis.
However, the sheer volume of responses can sometimes make this task overwhelming. To address this, Lighthouse offers a feature that allows users to pass these responses through a new prompt for summarization. This functionality enables users to obtain concise, single-line summaries of the responses, significantly simplifying the review process and enhancing efficiency.
The following screenshot shows an example of the prompt with which Lighthouse lets users meta-analyze all responses into one, reducing the time needed to review each response individually.

With this summarization tool, users can quickly distill large sets of data into easily digestible insights, streamlining their workflow and making Lighthouse an indispensable tool for data analysis and decision-making.
Lighthouse generates valuable insights, providing a deeper understanding of key focus areas, opportunities for improvement, and strategic directions. With these insights, GoDaddy can make informed, strategic decisions that enhance operational efficiency and drive revenue growth.
The following screenshot is an example of the dashboard based on insights generated by Lighthouse, showing the distribution of categories in each insight.

Through Lighthouse, we analyzed the distribution of root causes and intents across the vast number of daily calls handled by GoDaddy agents. This analysis identified the most frequent causes of escalations and factors most likely to lead to customer dissatisfaction.
To date (as of the time of writing), Lighthouse has generated 15 new insights. Most notably, the team used insights from Lighthouse to quantify the impact and cost of the friction within the current process, enabling them to prioritize necessary improvements across multiple departments. This strategic approach led to a streamlined password reset process, reducing support contacts related to the password reset process and shortening resolution times, ultimately providing significant cost savings.
Other insights leading to improvements to the GoDaddy business include:
GoDaddy’s Lighthouse, powered by Amazon Bedrock, represents a transformative leap in using generative AI to unlock the value hidden within unstructured customer interaction data. By scaling deep analysis and generating actionable insights, Lighthouse empowers GoDaddy to enhance customer experiences, optimize operations, and drive business growth. As a testament to its success, Lighthouse has already delivered financial and operational improvements, solidifying GoDaddy’s position as a data-driven leader in the industry.
 Mayur Patel is a Director, Software Development in the Data & Analytics (DnA) team at GoDaddy, specializing in data engineering and AI-driven solutions. With nearly 20 years of experience in engineering, architecture, and leadership, he has designed and implemented innovative solutions to improve business processes, reduce costs, and increase revenue. His work has enabled companies to achieve their highest potential through data. Passionate about leveraging data and AI, he aims to create solutions that delight customers, enhance operational efficiency, and optimize costs. Outside of his professional life, he enjoys reading, hiking, DIY projects, and exploring new technologies.
Mayur Patel is a Director, Software Development in the Data & Analytics (DnA) team at GoDaddy, specializing in data engineering and AI-driven solutions. With nearly 20 years of experience in engineering, architecture, and leadership, he has designed and implemented innovative solutions to improve business processes, reduce costs, and increase revenue. His work has enabled companies to achieve their highest potential through data. Passionate about leveraging data and AI, he aims to create solutions that delight customers, enhance operational efficiency, and optimize costs. Outside of his professional life, he enjoys reading, hiking, DIY projects, and exploring new technologies.
 Nick Koenig is a Senior Director of Data Analytics and has worked across GoDaddy building data solutions for the last 10 years. His first job at GoDaddy included listening to calls and finding trends, so he’s particularly proud to be involved in building an AI solution for this a decade later.
Nick Koenig is a Senior Director of Data Analytics and has worked across GoDaddy building data solutions for the last 10 years. His first job at GoDaddy included listening to calls and finding trends, so he’s particularly proud to be involved in building an AI solution for this a decade later.
 Karthik Jetti is a Senior Data Engineer in the Data & Analytics organization at GoDaddy. With more than 12 years of experience in engineering and architecture in data technologies, AI, and cloud platforms, he has produced data to support advanced analytics and AI initiatives. His work drives strategy and innovation, focusing on revenue generation and improving efficiency.
Karthik Jetti is a Senior Data Engineer in the Data & Analytics organization at GoDaddy. With more than 12 years of experience in engineering and architecture in data technologies, AI, and cloud platforms, he has produced data to support advanced analytics and AI initiatives. His work drives strategy and innovation, focusing on revenue generation and improving efficiency.
 Ranjit Rajan is a Principal GenAI Lab Solutions Architect with AWS. Ranjit works with AWS customers to help them design and build data and analytics applications in the cloud.
Ranjit Rajan is a Principal GenAI Lab Solutions Architect with AWS. Ranjit works with AWS customers to help them design and build data and analytics applications in the cloud.
 Satveer Khurpa is a Senior Solutions Architect on the GenAI Labs team at Amazon Web Services. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value.
Satveer Khurpa is a Senior Solutions Architect on the GenAI Labs team at Amazon Web Services. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value.
 Richa Gupta is a Solutions Architect at Amazon Web Services specializing in generative AI and AI/ML designs. She helps customers implement scalable, cloud-based solutions to use advanced AI technologies and drive business growth. She has also presented generative AI use cases in AWS Summits. Prior to joining AWS, she worked in the capacity of a software engineer and solutions architect, building solutions for large telecom operators.
Richa Gupta is a Solutions Architect at Amazon Web Services specializing in generative AI and AI/ML designs. She helps customers implement scalable, cloud-based solutions to use advanced AI technologies and drive business growth. She has also presented generative AI use cases in AWS Summits. Prior to joining AWS, she worked in the capacity of a software engineer and solutions architect, building solutions for large telecom operators.