[MUSIC FADES]
Today I’m talking to Dr. Siddharth Suri, also known as Sid, who’s a computational social scientist and a senior principal researcher at Microsoft Research. With him is Dr. David Holtz, an assistant professor in the Haas School of Business at the University of California, Berkeley. Sid and David are co-leading a team of researchers who are exploring the fascinating world of prompt engineering as part of the AI, Cognition, and the Economy, or AICE, initiative at Microsoft Research. I can’t wait to get into the meat of this research, but before we do, let’s meet our researchers. Sid, you first!
SIDDHARTH SURI: Hey, Gretchen, thanks for having me.
HUIZINGA: Tell us about yourself. At what intersection do your research interests lie, and what path led you to what you’re doing at Microsoft Research today?
SURI: So I got to where I am now through a very long and circuitous route, and I’ll give you the sort of CliffsNotes version of it, if you will. If you start back in grad school, my dream was to become a theoretical computer scientist. And what that basically means is writing algorithms. And what that basically means is pushing Greek symbols around a page. [LAUGHTER] And it turns out I’m good at that, but I’m not great at that. And towards the end of grad school, I was working with another professor, and he was doing these experiments that involved humans, and what we would do is we bring undergraduates into a lab. They were sitting in front of a computer using our software. We’d arrange them in different networks, so you’re trying to solve a problem with the people who are next to you in this network. And then we would change the structure of that network and have them solve the problem again. And we would try to understand, how does the structure of this network affect their ability to solve this problem? And I remember analyzing this data. I just was swimming around in this data and having a grand old time. I … nights, weekends … I remember riding the bus to school in Philadelphia, and I was trying to think about new analyses I could do. And it was just so … it was fun. I couldn’t get enough. And I remember my adviser talking to me one day, and he’s like, Sid, you’re really good at this. And I responded with, really good at what? I’m just doing the obvious thing that anybody would do. And he was like, bro, this is not obvious. Like, you know, you got a knack for this. And then that, sort of, set me on this path, and then, just to make a little long story short, I don’t have tons of self-awareness. So it took me like 10 full years to go from, like, deciding to hang up being a theoretical computer scientist and understanding humans, human behavior, and using technology to understand human behavior. And that’s, kind of, where I ended up as a computational social scientist. I’ve sort of gone all in in that space, as a computational social scientist. And that’s how David and I met. He’s a rising star in that space, as well. He became my intern. And that’s how we met. I’ll let him share his origin story with you.
HUIZINGA: Well, let’s do, David. I noticed you have a strong science background, but now you’re an assistant professor in a business school. So you got to do a little dot-connecting here. How did a guy with a degree in physics and astronomy—and should I also mention theater and dance? I’m so intrigued—um, how did that guy wind up working with MBAs and economists?
DAVID HOLTZ: Yeah, thanks for having me, Gretchen. Similar to Sid, my path to where I am today is also long and circuitous, and I will try to give you the CliffsNotes version. When I was young, I was always super interested in physics, and I think what drew me to physics was the way that it combined math, which I was very good at when I was younger, and the ability to answer big existential questions. Where does the universe come from? What’s the universe made out of? Is it growing? Is it shrinking? Things like that. And so when I went to college, I didn’t think too deeply about what I was going to study. I just, sort of, you know, always wanted to do physics. I’m going to do physics. And so I majored in physics. And then … I did my undergrad at Princeton, and there’s something about the physics department at Princeton where it’s almost just assumed everyone’s going to go get their PhD. And so there was a lot of “ambient pressure” to apply to graduate school. And so I actually started my physics PhD at Johns Hopkins. And as a PhD student, I was working on these large telescopes that look at remnant light from right after the Big Bang and try to characterize, you know, tiny fluctuations in this field of light that fills the night sky in a wavelength-like range that is not visible to the human eye. And by, sort of, characterizing those fluctuations in the light field, you can learn things about what the universe is made out of and how it’s evolving and all these types of things. It all sounds very cool. But the teams that conduct this research at this point are really big. It’s like you’re in a company, essentially. So there’s a hundred people working on building this telescope, analyzing these telescopes, so on and so forth. And so the actual day to day of my life as a physics PhD student was really far removed from the big existential questions that I was actually really interested in. My PhD dissertation probably would have been developing a system that moved a mirror in exactly this way so that light polarization appears, you know, in the experimental apparatus. You’re basically doing an engineering degree. And on top of all that, like Sid, I was good at physics, but I think I realized I was not great at physics. And I saw a lot of people around me in my classes and in my labs that were great at physics and moreover were having a really hard time finding a job as a physics professor after they graduated despite being great at physics. And so I started having these realizations during graduate school and had never done anything really except physics and so took a leave of absence and actually came out to the Bay Area and started working out here in advertising, which is not something that I’m necessarily super excited about—and as a product manager, which is not what I do. But it was kind of the hop that I needed to try something different. And after some amount of time, moved from doing product management to doing data science. This was right when the data science boom was starting. I think the year that I came to the Bay Area, DJ Patil, who used to be the chief data scientist for the US, had written this very famous HBR article about, you know, how data science was the sexiest job of the 21st century …
HUIZINGA: Right!
HOLTZ: … so I, kind of, took my physics credentials and became a data scientist and eventually also moved out of advertising and went and worked at Airbnb, which at the time was growing really quickly and, you know, was sort of a young company where a lot of exciting things were happening. You know, I loved working at Airbnb. I learned a lot. I met a lot of interesting people. I learned a lot working in ad tech, as well, and eventually just found myself feeling pulled back to academia. Like, I really liked the questions that I was working on, the types of work that I was doing. Similar to Sid, I found that I was really good at analyzing data. I didn’t feel like I was doing anything particularly crazy, but people around me were saying, no man, you’re really good at this! And so I started looking for PhD programs where I could do the type of work that I was doing as a data scientist at Airbnb but in a more academic environment. And that, sort of, naturally led me to PhD programs in business schools. I didn’t know what a PhD in a business school entailed, but there were professors in those departments that were doing the research that I wanted to do. And so that’s how I ended up there. And so my research when I started out as a PhD student was, I think, relative to a lot of people, I didn’t start from, like, first principles. I don’t know that I necessarily had this one little thing that I was super interested in. I was really interested in solving applied problems and, in particular, I think some of the applied problems that I had seen out in the world working in tech. And over time, I think I found that I’m just really interested in new technologies and how those technologies affect, you know, the flow of information, how people collaborate, what happens to the economy, so on and so forth. And so I sort of started by just trying to answer a few problems that were in front of me and discovered this was kind of, you know, sort of the unifying theory of the things that I was interested in studying. And I think … you know, in hindsight, I think one thing that is true that has kind of guided, you know, my path—and this connects back to the theater and dance, you know, minor that you had alluded to earlier—is I’ve always been a really social person. I’ve always been really interested in humans and how they interact. I think that type of storytelling is really at the crux of, you know, theater and music and things like that. And when I was younger, for sure, I spent a lot of time writing music, playing music, doing improv comedy, performing on stage. And as a physicist, that itch wasn’t necessarily getting scratched, both because I was just studying, you know, extremely small particles and was doing it in a pretty lonely lab. And a nice thing about being a computational social scientist is that I’m studying humans, which is really interesting. I think it plugs into something that I’m really passionate about. And a cool thing about getting to do that in particular in a business-school setting, I think, is that, you know, I’m talking often to people at companies and, you know, lecturing to MBA students, who are really outgoing, gregarious people. And so it presents a really nice opportunity to, kind of, fuse, you know, my interest in science and information and technology with that other interest in humans and connection and, you know, the opportunity to, sort of, interact with people.
HUIZINGA: Yeah, yeah. Well, escaping from middle management in physics is probably a good thing … Well, before we get into the details of your collaboration on prompt engineering, let’s make sure everyone knows what we’re talking about. Sid, when we talked before, I told you, to be honest, when I first heard the phrase “prompt engineer” a couple years ago, I laughed because I thought it was a joke, like sanitation engineer. Then when I heard it was a real job, I laughed a little bit less. And then when I heard it was not only a real job but one that, if you were good at it, could pay six figures, I stopped laughing altogether and started paying attention. So I’d like you, Sid, to give us a brief history of prompt engineering. What is it, when and how did it become a thing, and why is it different from anything I’d do in garden-variety internet search?
SURI: So generative AI wants to do just that. It wants to generate something for you. But how do you express what you want? What do you want the system to give you? And the answer is a prompt. So I’ll give you an example. Whenever there’s a new model out there, especially one that generates images, a prompt I use—you might laugh at this—is, “Show me a picture of Bruno Mars on the surface of Mars eating a Mars bar.” [LAUGHTER] And the reason why I use that prompt is because Mars bars aren’t in the training data. There’s not a lot of pictures of Mars in the training data. And everybody knows who Bruno Mars is. So that’s me describing to the model what I want. That is a prompt. Show me a picture with these elements in it, OK? But this is where the hard part starts. It sends you something. Oh. I didn’t want Mars to be that color of red. Could you change it to a deeper red or more of an orange? OK. Now, could you put a little dust in the atmosphere? OK. Well, I want a moon in the background. I didn’t know I wanted a moon in the background, but now I do. Where’s the sun in this image? I don’t know. And then the whole thing, kind of, becomes much more rich and a much bigger exploration compared to, say, putting keywords into a search engine. It’s a really much more rich space to explore. Now you asked me … a part of your question was, why is prompt engineering difficult? It’s difficult for a number of reasons. Number one, you don’t always know what you want.
HUIZINGA: Yeah …
SURI: And so it’s that conversation with the system to figure that out. Number two, you might not be expressing what you want as clearly as you think you are.
HUIZINGA: Right …
SURI: Number three, the problem could be on the receiver end. These models are new. You might be expressing it clearly, but they might not be understanding what you’re saying as clearly as you would hope. And then the fourth reason is the one I just said, which is, like, what you’re asking for is not just like, “Give me a document relevant to these keywords,” or “Give me some information relative to these keywords,” as you would do in traditional search. You’re asking for something much more rich. And to get that richness that you were hoping for requires this prompt. And that requires an exploration of the idea in your head and an expression of that idea in the real world. So that’s what prompt engineering is, and that’s why it’s hard.
HUIZINGA: OK, and when would you say it became a thing? I mean, prompt engineer is an actual job, but it was a thing first, right? It didn’t start out to be a job; it started out to be something you did, so …
SURI: So when these models came out, you know, what was it, late, around 2020, late 2020, I think, when they first started becoming popular. So prompting had been around in academia a few years prior to that, but it first hit the mainstream when these models, sort of, first came out around 2020, and why … why this job? Why this six-figure salary? Why all … what’s all the hoopla about it? And like I said before, these systems are new. No one knew how to use them. No one knew how to express what they want, A. B, there’s a lot of arcane ways to prompt that aren’t obvious at the beginning. Like, I’ll give you a few examples. One way to prompt is to give the system examples of what you’re looking for. Say you want something to classify an email as spam or not spam. You might give it a few emails that are spam and a few emails that are not spam and say, hey, if it’s more like this, call it spam; if it looks more like that, call it not spam. And so that’s one example. Another example would be like, OK, I’m a small-business owner. I need some advice. This is the problem I’m facing. Give me some advice to solve this problem as if you were Bill Gates.
HUIZINGA: Oh …
SURI: That’s, like, adopting a persona. That’s another example. A third example would be, like, OK, you have a math problem. You’re trying to solve this math problem, and to get it done correctly, some of these systems need what’s known as chain-of-thought prompting, which is tell me all the steps you’re going through to solve this problem. Don’t just give me the answer 17. Give me all the steps you needed to get to 17. And that helps the system guide it, more likely, towards a correct answer. And so these are all arcane, esoteric methodologies to getting one of these models to give you the right answer, the answer you want. And being a prompt engineer means you’re an expert in these things and you’re more likely to get these correct answers than maybe someone off the street who isn’t familiar with these techniques.
HUIZINGA: Right, right, right. Well, we’re going to talk a lot more about technique and the research that you did. And you’ve alluded to, at the beginning here, a visual, like describing … I heard graphic designers hearing the client when you were talking about it: “I didn’t want that red. Maybe put the moon in …” [LAUGHS]
SURI: Yeah, exactly!
HUIZINGA: Can you just tell me what you want to begin with? No, apparently not. But you’re also talking about verbal prompts and writing and so on. So we’ll get into that in a bit. But I want to go over and talk a little bit more about this research and why it’s where it is. This episode is the latest in our “series within a series” on AI, Cognition, and the Economy at Microsoft Research. And so far, we’ve talked about the impacts of AI on both cognition with Abi Sellen and the economy with Mert [Demirer] and Brendan [Lucier]. You can look up those episodes, fantastic episodes. This topic is a little less obvious, at least to me. So, David, maybe you could shed some light on how research for prompt engineering became part of AICE and why it’s an important line of research right now.
HOLTZ: So I think this project relates to both cognition and the economy. And let me lay out for you the argument for both. So first, you know, I’m not a cognitive scientist, but I think there are some interesting questions around how people, and in particular common people who are not computer scientists, conceive of and interact with these models, right. So how do they learn how to prompt? Do they think about different generative models as all being the same, or are they sort of developing different prompting strategies for different models? What are the types of tricks that they discover or use when they’re prompting models? And at the time that we started working on this project, there wasn’t a lot of research on this and there wasn’t a lot of data on this. You know, the data that existed typically is on the servers of big companies like Microsoft. It’s not really available to the public or to many researchers. And then the research is all, you know, sort of disproportionately focused on these esoteric prompting strategies that Sid mentioned, like chain-of-thought prompting, which are useful but are not things that, you know, my family members that are not scientists are going to be using when they’re trying to interact with, you know, the latest large language model that has been launched. So that was one draw of the project. The other thing that I think is interesting—and the reason that this project was well-suited to the AICE program—is that around the time that we were starting to work on this project, a bunch of research was coming out, and I’ve contributed to some of this research on a different project, on the impacts that generative AI can have on different economic outcomes that we care about. So things like productivity and job performance. And one interesting pattern that has emerged across numerous different studies trying to answer those types of questions is that the benefits of generative AI are often not uniform. Usually, generative AI really helps some workers, and there are other workers that it doesn’t help as much. And so there’s some interesting questions around why is it that some people are able to unlock big productivity gains using generative AI and others can’t. And one potential reason for this is the ways that people prompt the models, right. So I think understanding how people are actually interacting with these models when they’re trying to do work is a big part of understanding the potential impact that these models can have on the economy.
HUIZINGA: OK, it’s “how I met your mother” time. Let’s talk for a minute about how you two came to be working, along with what you’ve referred to as a “crack team” of researchers, on this study. So, Sid, why don’t you tell us, as you remember it, who called who, how the conversation went down, and who’s all involved. And then David can confirm, deny, or add color from his perspective.
SURI: OK, I need you to mentally rewind back to, like, November 2020. So it’s, like, just before Thanksgiving 2020. My manager came to me, and she was like, Sid, we need somebody to understand, what are the effects of AI on society? And I was like, “Oh, yeah, small question! Yeah, I can do that by myself! Yeah. I’ll get you an answer by Tuesday,” OK? Like, what the heck, man? That was like one of the biggest questions of all time. The first thing I did was assemble a team. We write an agenda; we start going forward from there. You know, Scott Counts is a colleague of mine; he was on that team. Not long after that … as I had mentioned before, David was my intern, and he and I started brainstorming. I don’t remember who called who. Maybe David does. I don’t remember that. But what I do remember is having several fun, productive brainstorming conversations with him. I remember vividly, I was, like, sort of walking around my house, you know, upstairs, kind of, trying to bounce ideas off of him and get the creative juices flowing. And one of the things we were talking about was, I just felt like, again, this is early on, but prompting is the thing. Like, everybody’s talking about it; nobody knows how to do it; people are arguing. So David and I were brainstorming, and then we came up with this idea of studying prompting and how prompting changes as the models get better and better, which they are, at a torrid rate. And so that was our, sort of, key question. And then David actually was primarily involved in assembling the crack team, and he’s going to talk more about that. But as a side note, it’s really cool for me to see David, kind of, grow from being, you know, just a great, sort of, individual scientist to, like, the leader of this team, so that was, kind of, a cool thing for me to see.
HUIZINGA: Hmm. You know, you tell that story … Peter Lee, who’s the president of Microsoft Research, tells a similar story where a certain CEO from a certain company came and dropped him in the middle of the AI and healthcare ocean and said find land. So did it have that same sort of “overwhelmed-ness” to it when you got asked to do this?
SURI: Overwhelmed would be an understatement! [LAUGHTER] It was overwhelming to the point where I was borderline afraid.
HUIZINGA: Oh, dear!
SURI: Like, you know, Peter has this analogy you mentioned, you know, “dropped in the ocean, find land.” I felt like I was dropped in outer space and I had to find Earth. And I didn’t even … I couldn’t even see the sun. Like, I … there was this entirely new system out there. No one knew how to use it. What are the right questions to ask? We were using the system to study how people use the system? Like, what the heck is going on? This was, like, stress levels were on 12. It was a sort of wild, white-knuckle, anxiety-inducing, fun, intense ride. All of those emotions wrapped up together. And I’m happy it’s over [LAUGHS] because, you know, I don’t think it was sustainable, but it was an intensely productive, intensely … again, just in case there’s any budding scientists out there, whenever you’re like swimming around in a problem and your gut is a little scared, like, I don’t know how to do this. I don’t know if I’m doing this right. You’re probably working on the right problem. Because if you know how to do it and you know how to do it right, it’s probably too easy.
HUIZINGA: Yeah!
SURI: And in this moment, boy, my gut was telling me that nobody knows how to do this and we got to figure this out.
HUIZINGA: Right. David, from your theater background, did you have some of these same emotions?
HOLTZ: Yeah, I think so. I think Sid and I, it’s interesting, we have different perspectives on this kind of interesting generative AI moment. And to use the theater analogy, I think being, you know, like, a researcher at Microsoft, Sid has kind of been able, the whole time, to see behind the curtain and see everything that’s going on. And then as someone that is, you know, a researcher in academia, I’ve sort of been in the audience to some extent. Like, I can see what’s coming out onto the stage but haven’t seen all the craziness that was happening behind the curtain. And so I think for me, the way that I would tell the story of how this project came together is, after I had finished my internship and Sid and I—and a number of coauthors—had this very successful remote work paper, we just kept in touch, and every few weeks we’d say, hey, you know, want to chat, see what we’re both working on, swap research ideas?
HUIZINGA: Yeah …
HOLTZ: And for me, I was always looking for a way to work together with Sid. And if you look around at, you know, the history of science, there’s these Kahneman and Tversky, like, Watson and Crick. Like, there are these teams that stay together over long periods of time and they’re able to produce really amazing research, and so I realized that one thing that I should prioritize is trying to find people that I really like working together, that I really click with, and just trying to keep on working with those people. Because that’s one of the keys to having a really successful career. At the same time, all this generative AI stuff was happening, and I went to a few talks. One of them was on the Berkeley campus, and it was a talk by someone at Microsoft Research, and it was about, sort of, early signs of how amazing, you know, GPT-4 was. And I remember thinking, this seems like the most important thing that a person could be working on and studying right now. Like, anything else that I’m working on seems unimportant in comparison to the impact that this technology …
HUIZINGA: Wow …
HOLTZ: … is poised to have on so many different facets of, you know, life and the economy and things like that. And so I think things kind of came together nicely in that there was this opportunity for Sid and I to work together again and to work together again on something that we both agreed was just so incredibly important. And I think we realized this is really important. We really want to work on this problem. But we’re also both super busy people, and we don’t necessarily have all the skills that we need to do this project. And given how important this question is and how quickly things are moving, we can’t afford to have this be a project where it’s like, every now and then … we come back to it … maybe we’ll have a paper in, like, three years. You know, like, things needed to happen really quickly. And so that’s where we got to thinking, OK, we need to put together a team. And that’s kind of where this, like, almost, like, Ocean’s Eleven, sort of, scene emerged [LAUGHTER] where we’re like, we’re putting together a team. We need a set of people that all have very particular skills, you know, and I’m very lucky that I did my PhD at MIT in this sort of community that is, I would say, one of the highest concentrations of really skilled computational social scientists in the world, basically.
HUIZINGA: Wow.
HOLTZ: And so I, sort of, went to, you know, to that community and looked for people. I reached out to people that I had met during the PhD admissions program that were really promising, you know, young PhD students that might want to work on the project and, sort of, put the team together. And so this project is not just Sid and I. It’s six other people: Eaman Jahani, Ben Manning, Hong-Yi TuYe, Joe Zhang, Mohammed Alsobay, and Christos Nicolaides. And everyone has brought something unique and important to the project. And it’s really kind of crazy when you think about it because on the one hand, you know, sometimes, when we’re talking, it’s like, wow, eight people. It’s really a lot of people to have on a paper. But at the same time, you, kind of, look at the contributions that every single person made to the project and you, kind of, realize, oh, this project actually could not have happened if any one of these people were not involved. So it’s been a really interesting and fun project in that way.
SURI: One thing I just wanted to add Gretchen is, I’m a little bit older than David, and when I look back at my career and my favorite projects, they all have that property that David was alluding to. If you knocked one of the coauthors off that project, it wouldn’t have been as good. To this day, I can’t figure out why is that so important, but it is. It’s just this notion that everyone contributed something and that something was unique that no one else would have figured out.
HUIZINGA: Well, and the allusion to Ocean’s Eleven is exactly that. Like, they have to get someone who can crack a safe, and they have to get someone who’s a contortionist and can fit into a box that no one can see, and blah, blah, blah. And I don’t know if you’ve argued about which one of you is George Clooney and which one of you is Brad Pitt, but we’ll leave that for a separate podcast.
SURI: Well, actually … [LAUGHTER] it’s not even a question because Eaman Jahani is by far the most handsome one of us, so he’s Brad Pitt. It’s not even close. [LAUGHS]
HUIZINGA: David’s giggling!
HOLTZ: Yeah, I think Sid … I’d agree with that. I think Sid is probably George Clooney.
SURI: I’ll take it. I’ll take it!
HUIZINGA: Anytime! Well, we’ll talk about some more movies in a minute, but let’s get into the details of this research. And, Sid, I was looking at some of the research that you’re building on from your literature, and I found some interesting papers that suggest there’s some debate on the topic. You’ve just alluded to that. But let’s talk about the titles: AI’s hottest job: Prompt engineer, and, like, Tech’s hottest new job: AI whisperer. No coding required. But then there’s this Harvard Business Review article titled AI prompt engineering isn’t the future. And that left me wondering who’s right. So I suspect this was part of the “prompting” for this research. Tell us exactly what you did and how you did it.
SURI: Sure, so where we came to this question was, we came at it from a couple directions. One is what you just said. There’s this conversation going on in the public sphere, which is on the one hand, there’s these jobs; there’s this notion that prompting, prompt engineering, is a super important thing; it’s paying six figures. On the other hand, there’s also this notion that these models are getting better and better. They’re more able to figure out what you needed and guess what you needed and so maybe we’re not going to need prompting going forward.
HUIZINGA: Right.
SURI: And David and I were like, this is perfect. One of my mentors, Duncan Watts, I always joke with him that every introduction of our paper is the same. It’s “There’s this group of people that say x, and there’s this group of people that say the opposite of x. So we did an experiment to figure it out.” And the reason why every introduction of one of my papers is the same is because you can never say at the end it was obvious. If it was so obvious, then how come there’s two groups of people disagreeing on what the outcome’s going to be? So what we did in the experiment—it’s very simple to explain—is we gave people a target image, and then they randomly either got DALL-E 2 or DALL-E 3. And we said, “OK, write a prompt to generate this target image that we’ve given you,” and we give them 10 tries. “And you can iterate; you can improve; you can experiment. Do whatever you want.” And the notion was, as models progress, what is the relationship between people’s ability to prompt them to get to the target?
HUIZINGA: That’s the end of it. [LAUGHS]
SURI: Yeah. [LAUGHS]
HUIZINGA: That’s the most succinct explanation of a research study that I’ve ever heard. Congratulations, Sid Suri! So I have a question, and this is like … you’ve talked a bit already about how you iterate to get to the target image. My experience is that it can’t remember what I told it last time. [LAUGHTER] So if I put something in and then I say, well, I want you to change that, it starts over, and it doesn’t remember what color red it put in the first image. Is that part of the process, or are these models better than what I’ve done before?
SURI: The models are changing, and that is … and, sort of, the history, the context, the personalization is what you’re referring to. That is coming online in these models already and in the near future. Maybe at the time we did the study, it wasn’t so common. And so they were suffering the same issue that you just alluded to. But going forward, I do expect that to, sort of, fade away a little.
HUIZINGA: OK. Well, David, Sid’s just given us the most beautifully succinct description of people trying to get the model to give them the target image and how many tries they got. What did you find? What were the big takeaways of this research?
HOLTZ: So let me start out with the most obvious finding that, you know, like, Sid was saying, ideally, you know, you’re, kind of, answering a question where it makes sense that people are on both sides of this argument. One thing that we looked at that you’d be surprised if there was someone on the other side of the argument is, OK, do people do a better job when we give them the better model? If we give them DALL-E 3 instead of DALL-E 2, do they do a better job of re-creating the target image? And the answer is unsurprisingly, yes. People do a better job when we give them the better model. The next thing that we looked at—and this is where I think the results start to get interesting—is why do they do better with the better model? And there’s a couple of different reasons why this can be the case. The first could be that they’re writing the exact same prompts. They interact with the model exactly the same, whether it’s DALL-E 2 or DALL-E 3, and it’s just the case that DALL-E 3 is way better at taking that input and translating it into an image that is the image that you had in mind with that prompt. So, you know, sort of, imagine there’s two different artists. One is like a boardwalk caricature artist; the other one is Vincent van Gogh. Like, one of them is probably going to be better at taking your input and producing a really high-quality image that’s what you had in mind. The other possibility is that people, sort of, pick up on the fact that one of these models is different than the other. Maybe it’s more expressive. Maybe it responds to different types of input differently. And as you start to figure that out, you’re going to actually prompt the model, kind of, differently. And so I think the analogy I would draw here is, you know, imagine that you’re driving a couple of different cars maybe, like, one has really nice power steering and four-wheel drive and things like that. The other one doesn’t have all these cool features. You know, you’re probably going to actually handle that car a little bit differently when you take it out on the road relative to a really simple car. And what we find when we actually analyze the data is that both of these factors contributes to people doing better with the higher-quality model. And they actually both contribute equally, right. So insofar as people do better with DALL-E 3, half of that is because DALL-E 3 is just a better model at, like, taking the same input and giving you, like, an image that’s closer to what you had in mind. But the other half is due to the fact that people, sort of, figure out on their own, oh, this model is different. This model is better. It can maybe respond to my inputs a little bit more expressively. And they start prompting differently. And one thing that’s really neat and interesting about the study is we didn’t tell people whether they were given DALL-E 2 or DALL-E 3. So it’s not even like they said, oh, you gave me the good model. OK, let me start prompting differently. They kind of just figure this out by interacting with the tool and kind of, you know, realizing what it can do and what it can’t do. And specifically when we look at what people are doing differently, they’re, kind of, writing longer prompts; they’re writing more descriptive prompts. They have way more nouns and verbs. They’re kind of doing less feeling around in the dark and kind of finding, like, a way of interacting with the model that seems to work well. And they’re kind of doubling down on that way of interacting with the model. And so that’s what we saw. And so when it connects back to your question of, you know, OK, prompt engineering, like, is it here to stay, …
HUIZINGA: Yeah.
HOLTZ: … or is prompt engineering going away? I think one way that we think about interpreting these results is that the prompts do matter, right. Like, if you didn’t think about how to prompt different models and you just wrote the same prompts and left that prompt “as is” for, you know, months or years, you’d be missing out on tons of the gains that we stand to experience from these new, more powerful models because you need to update the prompts so that they take advantage of the new model capabilities. But on the flip side, it’s not like these people needed to, you know, go read the literature on all these complicated, esoteric prompting strategies. They kind of figured it out on their own. And so it seems like prompting is important, but is it necessarily prompt engineering, where it’s this really, you know, heavy-duty, like, thing that you need to do or you maybe need to go take, like, a class or get a master’s degree? Maybe not. Maybe it’s just a matter of people interacting with the models and, kind of, learning how to engage with them.
HUIZINGA: Well, David, I want to ask you another question on that same line, because AI is moving so fast on so many levels. And it’s still a relatively new field. But now that you’ve had some time to reflect on the work you just did, is there anything that’s already changed in the conversation around prompt engineering? And if so, what are you thinking about now?
HOLTZ: Yeah. Thanks for the question. Definitely things are changing. I mean, as Sid mentioned, you know, more and more the way that people interact with these models, the models have some notion of history. They have some notion of context. You know, I think that informs how people are going to write prompts. And also, the types of things that people are trying to do with these models is constantly changing, right. And so I think as a result, the way that we think about prompting and, sort of, how to construct prompts is also evolving. So I think the way that we think about this study is that it’s by no means, you know, the definitive study on prompt engineering and how people learn to prompt. I think everyone on our team would agree there’s so much more to do. But I think the thing that struck us was that this debate that we mentioned earlier, you know, is prompting important? Will prompt engineering stay? Maybe it doesn’t matter? It was really a debate that was pretty light on evidence. And so I think the thing that we were excited to do is to sort of, you know, start to chip away at this big question with data and with, you know, an experiment and just try to start developing some understanding of how prompting works. And I think there’s tons more to do.
HUIZINGA: Right, right, right.
SURI: Just to add to that …
HUIZINGA: Yeah, please.
SURI: Again, if there’s any sort of young scientists out there, one of the things I hate doing with other scientists is arguing about what’s the answer to this question. So what I always do when there’s an argument is I just shift the argument to instead of arguing about is this question going to be yes or no, is what’s the data we need to answer the question? And that’s where David and I, sort of, came in. There was this argument going on. Instead of just arguing between the two of us about what we think it’s going to be, we just shifted the conversation to, OK dude, what data do we need to gather to figure out the answer to this question? And then boom, this project was off and running.
HUIZINGA: You know, that could solve so many arguments, you know, in real life, just like, you don’t know and I don’t know, why are we arguing? Let’s go find out.
SURI: Yeah, so instead of arguing about who knows what, let’s argue about what’s the data we need so that we’ll be convinced!
HUIZINGA: Well, on that line, Sid, another paper in the literature that you looked at was called The prompt report: A systematic survey of prompting techniques. And we’ve talked a little bit about what those techniques involve. But what has your research added to the conversation? Specifically, I’m interested to know, I mean, we did talk about tricks, but is there coaching involved or is this just sort of feel-your-way-in-the-dark kind of thing? And how fine is the line between what you referred to as alchemy and chemistry in this field?
SURI: The alchemy and chemistry analogy was David’s brilliant analogy, and what he was saying was, way back when, there was alchemy, and then out of that grew chemistry. And at the moment, there’s these, sort of, niche, esoteric ways of prompting—chain-of-thought, embody a persona, this kind of thing. And how are those going to get propagated out into the mainstream? That’s how we go from alchemy to, sort of, chemistry. That was his brilliant analogy. And there’s several punchlines of our work, but one of the punchlines is, people can figure out how to take advantage of the new capabilities of these models on their own, even when they don’t know the model changed. So that’s a great democratization argument.
HUIZINGA: Hmm …
SURI: That, OK, you don’t need to be the six-figure Silicon Valley hotshot to figure this out. That maybe, maybe everyone in the world who has access—who has internet access, electricity, and access to one of these models—they can sort of pick themselves up by their own bootstraps, learn how to use these things on their own. And I want to go back to an analogy you said a while ago, which was the analogy to traditional internet search, …
HUIZINGA: Yeah.
SURI: OK? People forgot this, but we’ve learned how to search over the course of about 30 years. I’m 45 years old, so I remember the early search engines like AltaVista, Lycos, things like that. And basically, getting anything useful out of them was pretty much impossible. I really wanted to swear right there, but I didn’t. [LAUGHTER] And what people forgot, people forgot that they didn’t know how to ride a bike, OK? And they forgot that we didn’t actually know … these systems didn’t work that well; we didn’t know how to query them that well; we didn’t know how to get anything useful out of them. And then 30 years later, no one thinks about searching the internet as a thing we do. It’s like turning on the faucet. You just do it. It’s taken for granted. It’s part of our workflows. It’s part of our daily life. We do it without thinking about it. Right now, we’re back in those AltaVista/Lycos days, like, where, you know, it’s still esoteric. It’s still niche. We’re still not getting what we need out of these models. The models are going to change. People are going to get better at it. And part of what we’re arguing in our paper is that people can get better at it on their own. All they need is access and a few tries and they figure it out.
HUIZINGA: Right. You know what’s really funny is, I was trying to find some information about a paper on Sparks. That’s the Sparks paper. And I was doing some internet search, and I wasn’t getting what I wanted. And then I moved over to ChatGPT and put basically the same question, but it was a little more question-oriented instead of keywords, and it gave me everything I was looking for. And I thought, wow, that’s a huge leap from even … that I could use ChatGPT like a search engine only better. So … well, listen, anyone who’s ever listened to my podcast knows I’m borderline obsessed with thinking about unintended consequences of technical innovation, so I always ask what could possibly go wrong if you got everything right. But as I’ve said on this series before, one of the main mandates of AICE research is to identify unintended consequences and try to get ahead of them. So, David, rather than talking about the potential pitfalls of prompt engineering, instead talk about what we need to do to keep up with or keep ahead of the speeding train of generative AI. And by we, I mean you.
HOLTZ: Yeah, I mean, I think the thing to keep in mind—and I think this has come up a couple of times in this conversation already—is at least right now, and presumably for the foreseeable future, you know, generative AI is moving so fast and is also not a monolith, right. Like, I think we tend to talk about generative AI, but there’s different types of models, even within a particular class of models. There’s so many different models that are floating around out there. And so I think it’s important to just keep on sort of revisiting things that we think we already know, seeing if those things remain true. You know, I think from a research perspective, like, kind of, answering the same questions over and over with different models over time and seeing if the results stay the same. And I think that’s one of the big takeaways from, like, sort of, a policy or applications perspective from our research, as well, is that just generative AI is moving really quickly. These models are evolving, and the way that we interact with them, the way that we prompt them, needs to change. So if you think about it, you know, there are many tech companies, many startups, that are building products or building entire, you know, companies on, basically, on top of API calls to OpenAI or to Anthropic or something like that. And behind the scenes, those models are changing all the time, whether it’s, you know, sort of a publicly announced shift from GPT-3.5 to GPT-4 or whether it’s the fact that maybe, you know, GPT-4 is kind of being tweaked and adjusted, you know, every couple of weeks based on things that are happening internally at the company. And one of the takeaways from our research is that, you know, all those tweaks are actually pretty meaningful. The prompts that you wrote two weeks ago might not be as effective you know today if they aren’t as well suited to the to the newest, latest, greatest model. And so I think just being really cognizant of that moving target, of the fact that we are living through, sort of, like, very exciting, unprecedented, crazy times and kind of just staying alert and staying on our toes is I think probably the most important thing.
HUIZINGA: Yeah. You know, when I was thinking about that question, I, my mind went to the Wallace & Gromit … I don’t know if you’re familiar with those animations, but there’s a scene where they’re on a toy train track chasing a criminal penguin, and they run out of track and then Gromit miraculously finds spare track. He starts laying it as the train is going. And it sort of feels like there’s a little bit of that in your research! [LAUGHS] I usually ask my guests on Collaborators where their research is on the spectrum from lab to life. But you’ve actually completed this particular study, and it leans more toward policy than product. And again, we’ve talked about a lot of this. Sometimes there seems to be a Venn diagram overlap with my questions. But, Sid, I want to know from your perspective, what would be a good outcome for this particular study, in your mind?
SURI: So AI systems are more and more being embedded in the workflows of companies and institutions. It used to just be all software, but now it’s specifically custom-built software, AI systems, and their prompts. I see it all the time here at Microsoft. It’s part of our workflows. It’s part of our products. It’s part of our day-to-day life. And as the models are getting better and better and these prompts are sort of embedded in our systems, someone’s got to pay attention to those prompts to make sure they’re still behaving the way we thought they were because they were written for an older version, the model changed, and now is that new model interpreting that prompt in the same way? That’s one question. The second question is, well, the new model has new capabilities, so now can you boost these prompts to take advantage of those new capabilities, to get the full economic gain, the full productivity gain of these new models? So you want to get your value for your money, so you need to adjust your prompts in response to those new models to get the full value. And part of the point of this paper is that that’s actually not that big a deal. That, as the models get better and better, even when people don’t know about it, they can still take advantage of the new affordances, the new capabilities, even when they aren’t made aware that, hey, it does a different thing right now.
HUIZINGA: Interesting.
SURI: But the point we’re making with this paper is, you have to pay attention to that.
HUIZINGA: OK, it’s last word time and I want to go a little off script with you two for this show. NVIDIA’s co-founder and CEO Jensen Huang recently said, and I paraphrase Willie Nelson here, “Mamas don’t let your babies grow up to be coders.” In essence, he’s predicting that AI is going to do that for us in the future and people would be better served pursuing different educational priorities. So that’s a bold claim. Do you guys want to make a bold claim? Here’s your chance to make a pithy prediction from your perch in research. What’s something you think will be true some years out? You don’t have to say how many years, but that you might have been reluctant to say out loud for fear that it wouldn’t age well. Remember, this is a podcast, not a paper, so no one’s going to hold you to your word, but you might end up being prophetic. Who knows? David, you go first, and then Sid can close the show. Tell us what’s going to happen in the future.
HOLTZ: I’m not sure how bold of a prediction this is, but I think there’s a lot of concern right now about the impact that AI will have in various creative domains, right. As generative AI gets better and AI can produce images and music and videos, you know, what will happen to all of the people that have been making a living creating this type of content? And my belief is that, if anything, as we just get flooded with more and more AI-generated content, people are going to place a really heavy premium on content that is produced by humans. Like, I think so much of what people value about art and creative output is the sort of human connection and the idea that something sort of emerged from someone’s lived experiences and hardships. I mean, this is why people really like reading, you know, the curator’s notes when they go to a museum, so that they can kind of understand what’s behind, you know, behind the image. And so I think generative AI is going to be really amazing in a lot of ways, and I think it will have really big impacts that we’ll need to deal with as a society in terms of how it affects work and things like that. But I don’t think that we’re moving towards a future where, you know, we’re all just consuming AI-generated, you know, art all the time and we don’t care at all about things being made by people.
HUIZINGA: You know, there’s a podcast called Acquired, and they talked about the brand Hermès,which is the French luxury leather company, and saying that to get a particular kind of bag that’s completely handmade—it’s an artifact from a human—that’s why you pay tens of thousands of dollars for those instead of a bag that comes off a factory line. So I like that. Sid, what do you think?
SURI: So I’m going to make two points. David made the argument about AI affecting the creative space. I want to zoom in on the knowledge workspace.
HUIZINGA: Hmm …
SURI: And one of the big issues in knowledge work today is it’s incredibly difficult still to get insights out of data. To give you an example, in the remote work study that David and I did, it took a handful of PhDs, tons of data, two years, sophisticated statistical techniques to make sense of what is the effect of remote work on information workers, OK? And I feel, where I see knowledge work going is there’s going to be this great democratization on how to get insights out of data. These models are very good at classifying things, summarizing things, categorizing things. Massive amounts of data. In the old days, you had to like basically be an advanced statistician, be an advanced machine learning person, train one of these models. They’re very esoteric. They’re very arcane. They’re very hard to use. And then unleash it on your data. Now if you just know how to prompt a little bit, you can get these same insights as a professional statistician would a few years ago in a much, much shorter time, you know, one-tenth of the time. So I feel like there’s going to be this great democratization of getting insights out of data in the knowledge workspace. That’s prediction number one. And then the second point I wanted to make, and I want to give a little credit to some of the academics who’ve inspired this notion, which is Erik Brynjolfsson and David Autor, and that is this: I think a lot of people are looking for the impact of AI in kind of the wrong way. Rewind in your mind back to the time when, like, the internal combustion engine was invented. OK, so we used to get around with horses; now we have cars. OK, horses went 20 miles an hour; cars go 40 miles an hour. OK, big deal. What no one foresaw was there’s going to be an entire aviation industry that’s going to make it possible to do things we couldn’t do before, speed up the economy, speed up everything, add trillions of dollars of value to the world. And I feel like right now everyone’s focusing on AI to do things we already know how to do. And I don’t think that’s the most interesting use case. Let’s instead turn our attention to, what could we not do before that we can do now?
HUIZINGA: Right.
SURI: And that’s where the really exciting stuff is. So those are the two points I’d like to leave you.
HUIZINGA: I love it. I hope you’re not saying that I could rewind my mind to when the internal combustion engine was developed …
SURI: No, no. Present company excluded! [LAUGHTER]
HUIZINGA: Oh my gosh. Sid Suri, David Holtz, this has been fantastic. I can’t get the phrase “AI whisperer” out of my head now, [LAUGHTER] and I think that’s what I want to be when I grow up. So thanks for coming on the show to share your insights on the topic and help to illuminate the path. This is awesome.
SURI: Thank you.
HOLTZ: Well, thank you.
SURI: That was fun.
[MUSIC FADES]



 Google is committed to make benefits of AI more accessible and inclusive for everyone in the Middle East and North Africa.
Google is committed to make benefits of AI more accessible and inclusive for everyone in the Middle East and North Africa.

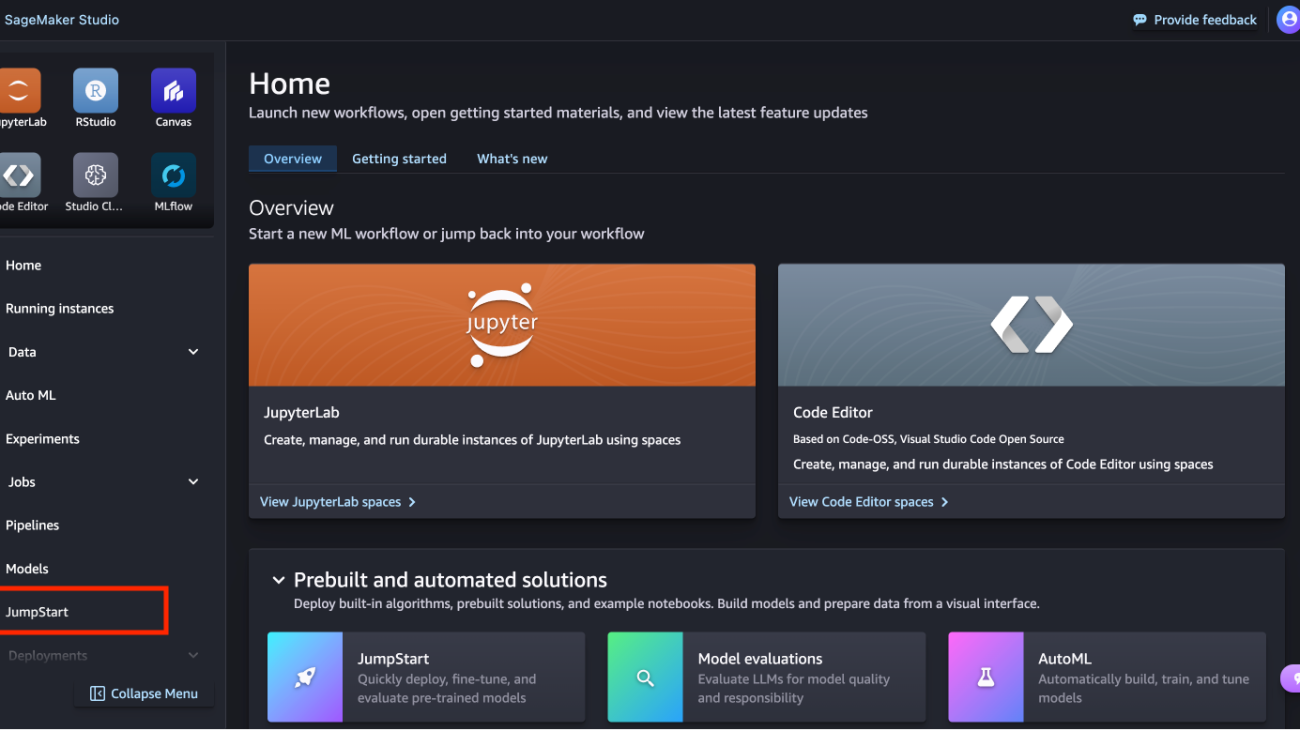
 You’re presented with the list of public models offered by SageMaker, where you can explore other models from other providers.
You’re presented with the list of public models offered by SageMaker, where you can explore other models from other providers. You’re presented with a list of the models available.
You’re presented with a list of the models available. Here you can view the model details, as well as train, deploy, optimize, and evaluate the model.
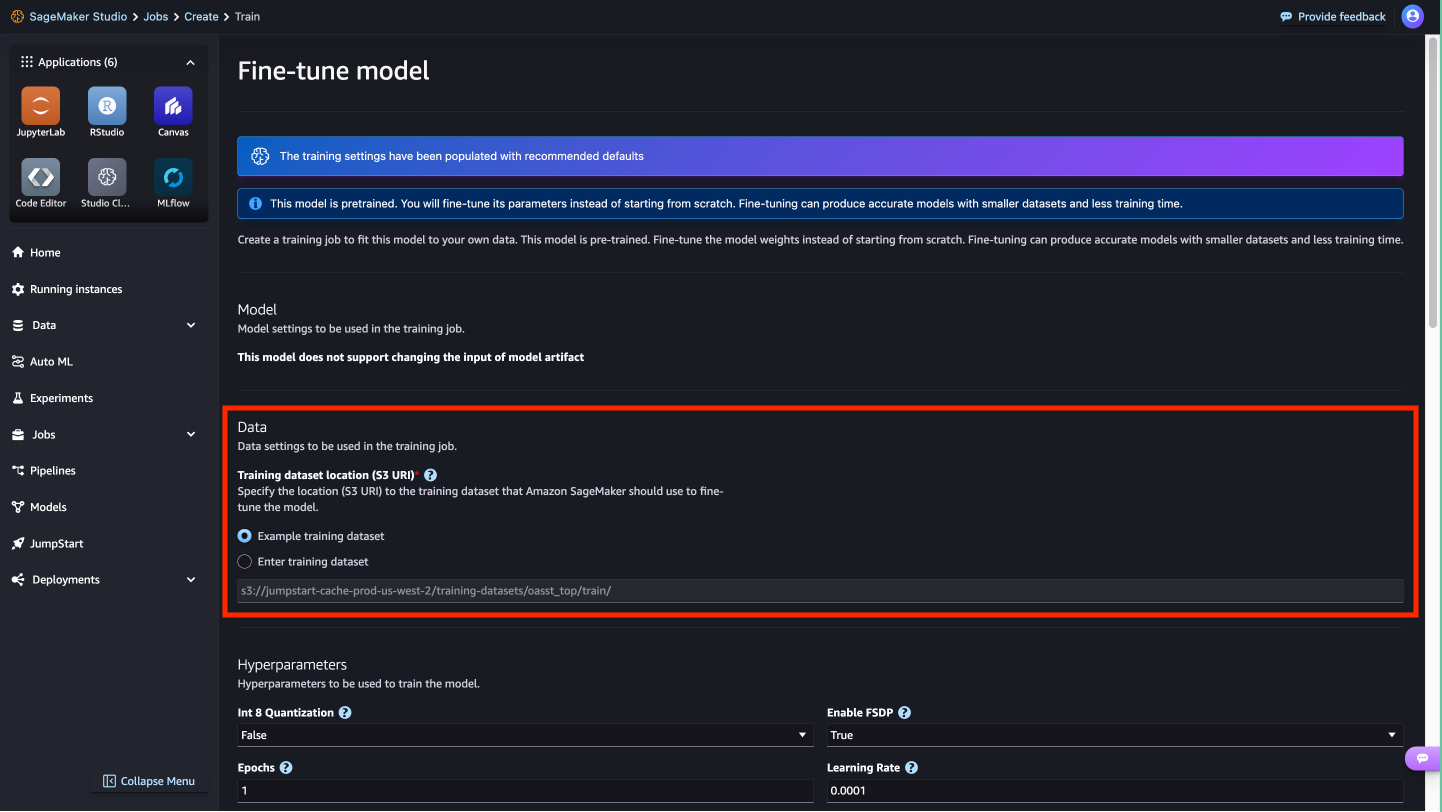
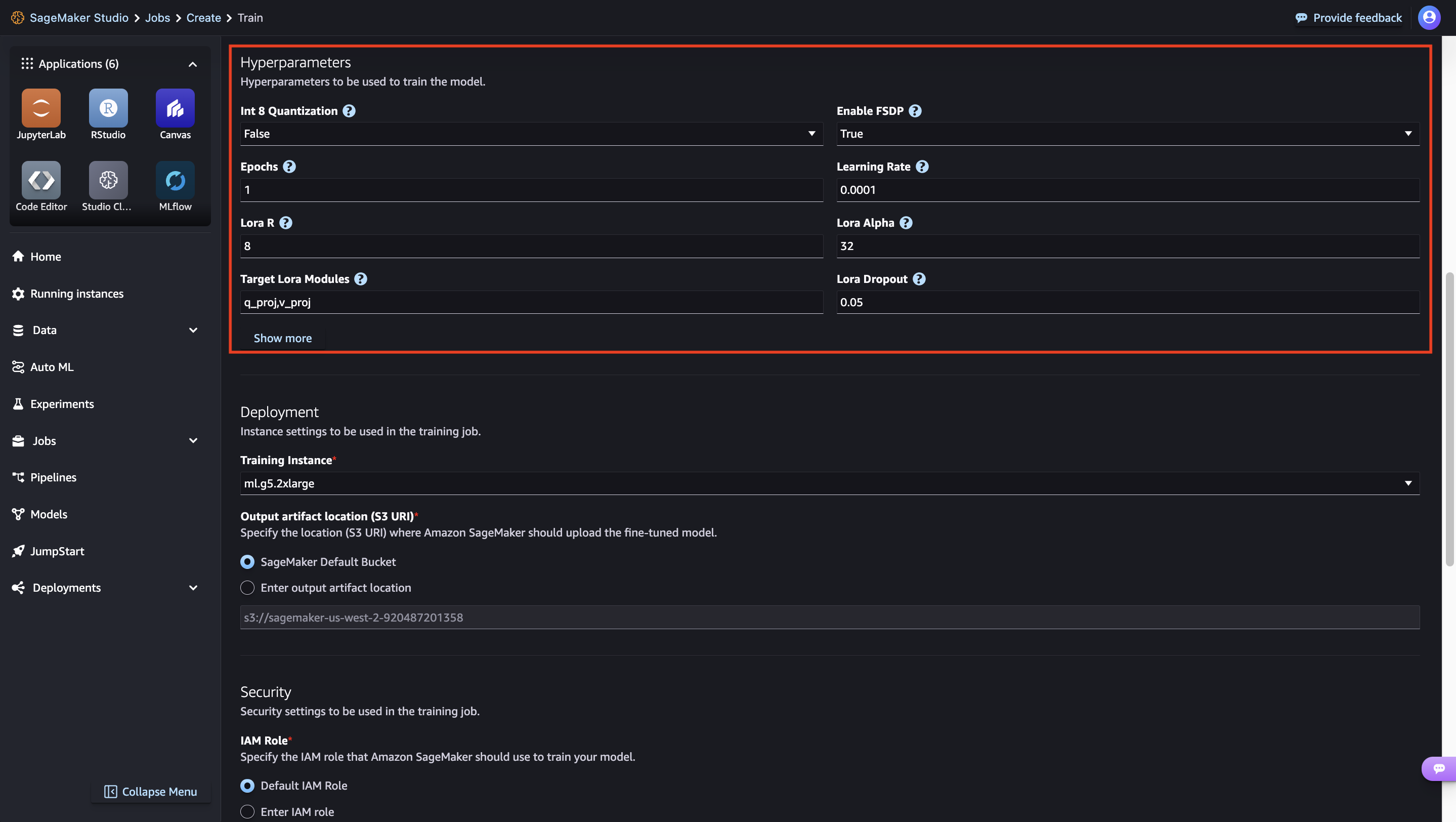
Here you can view the model details, as well as train, deploy, optimize, and evaluate the model.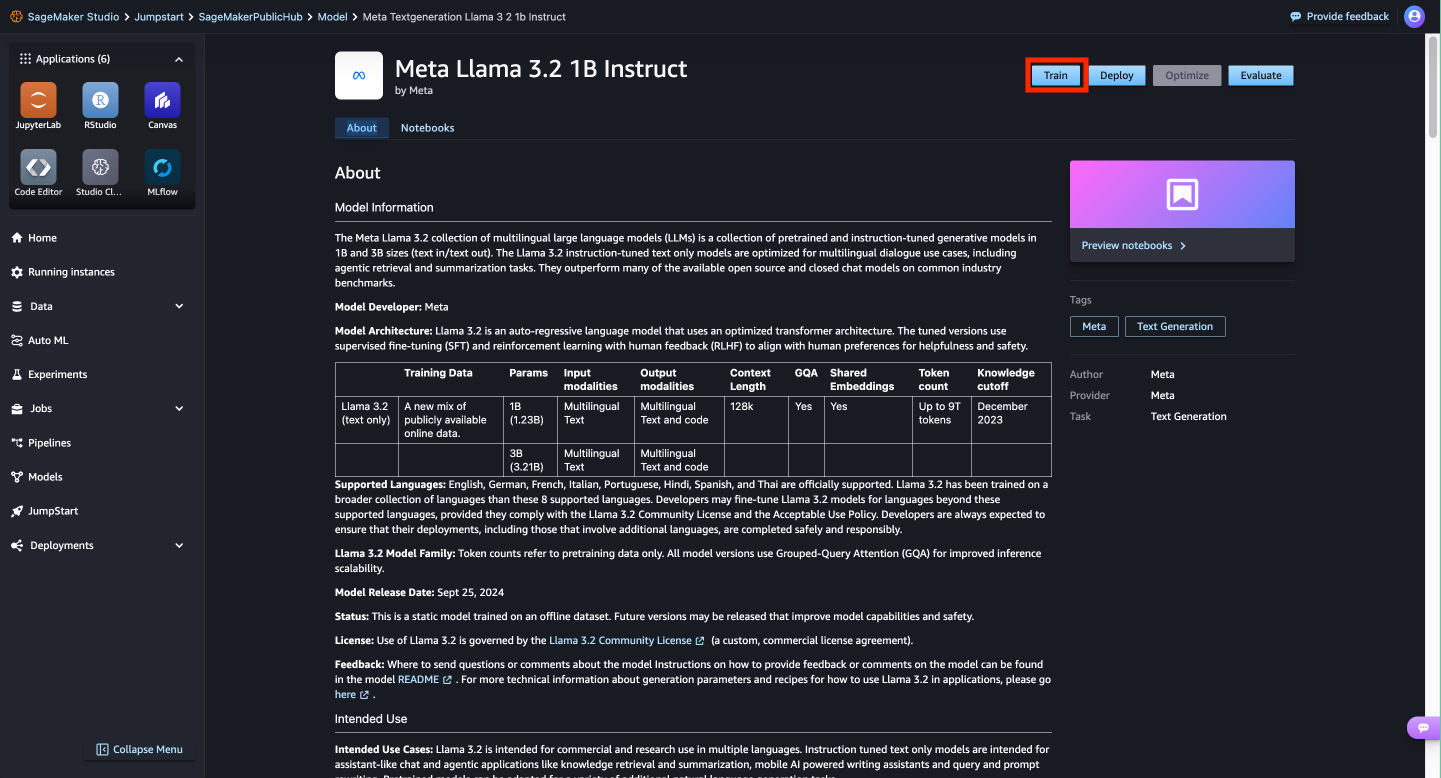
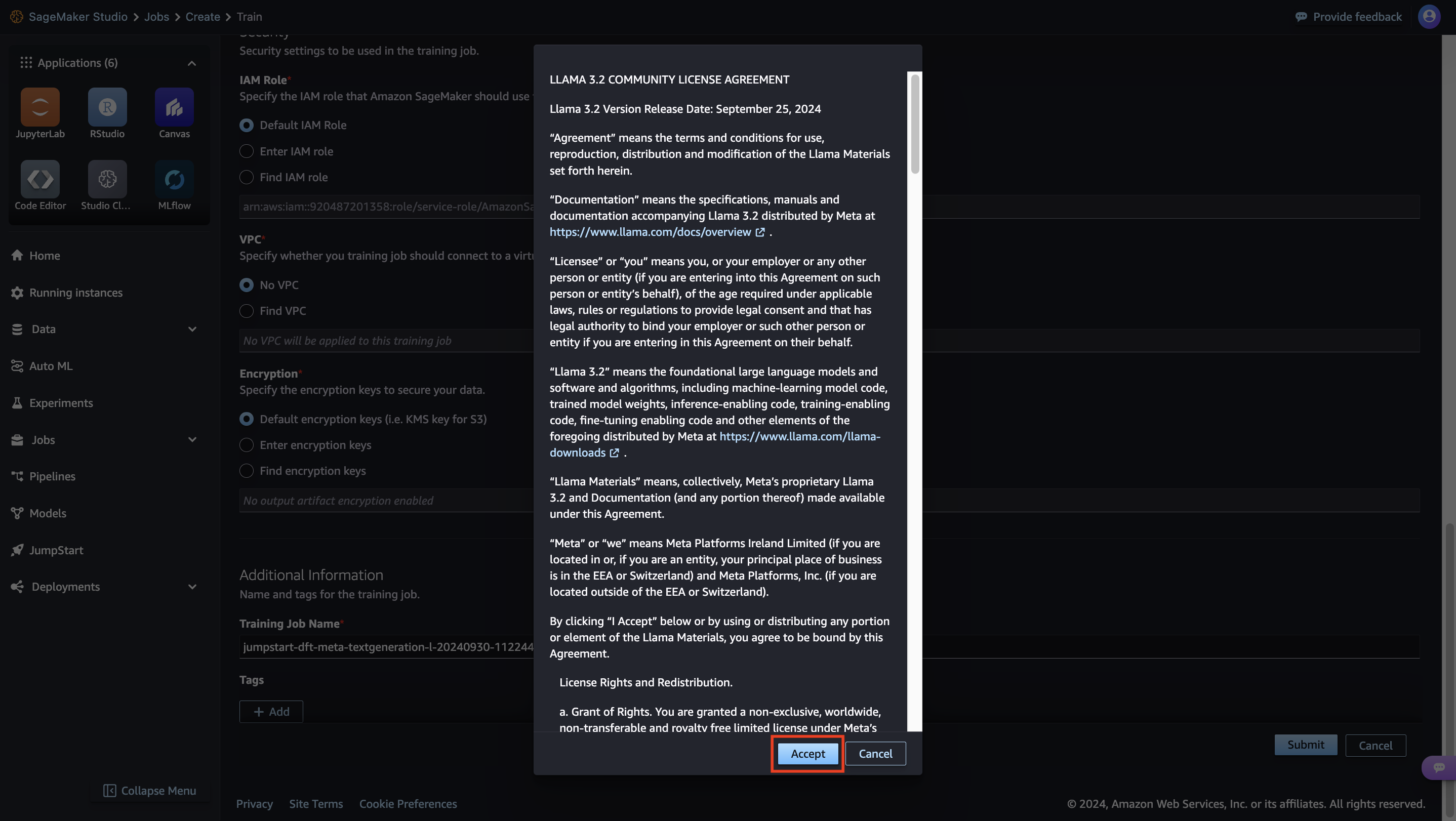
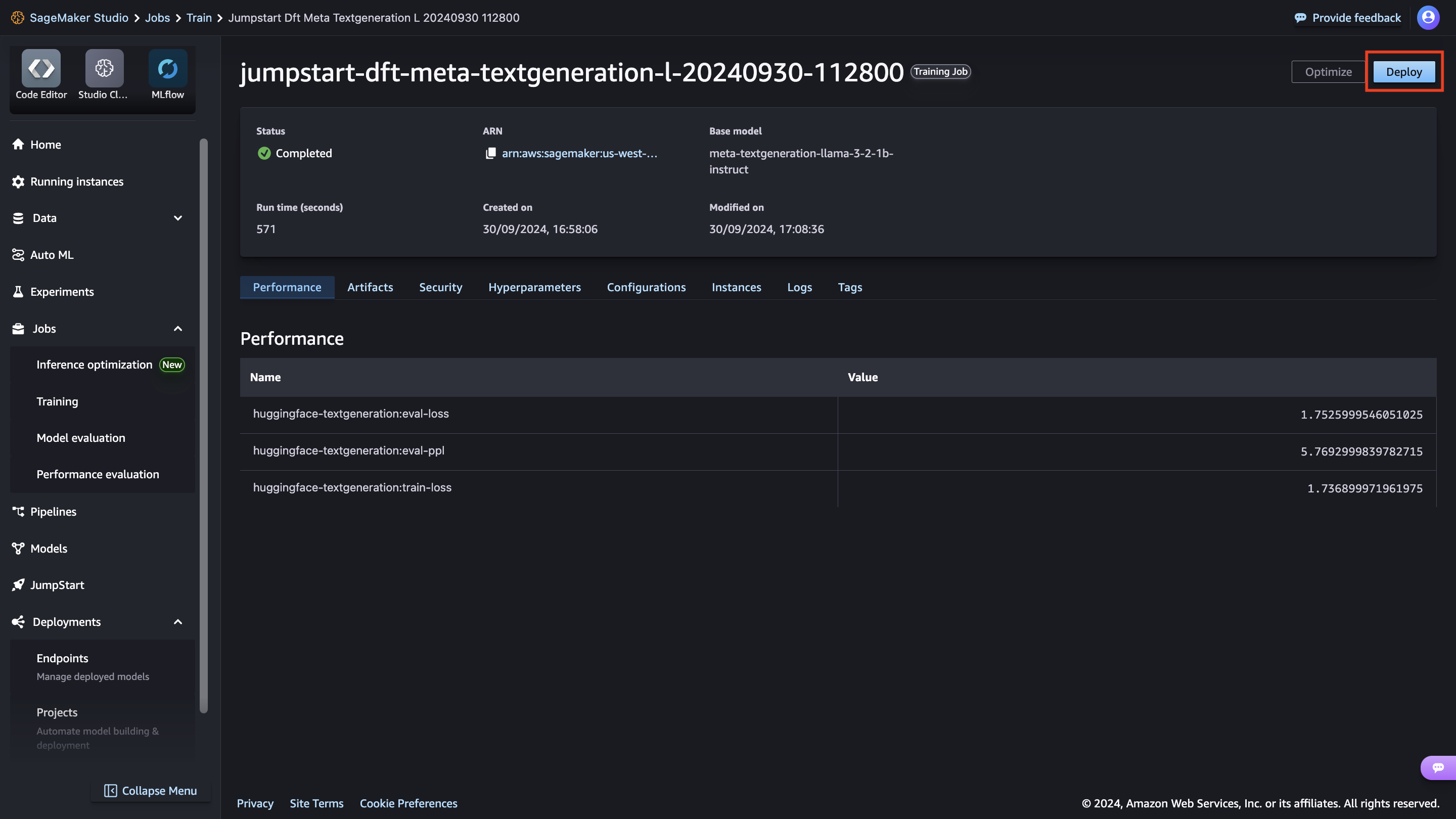
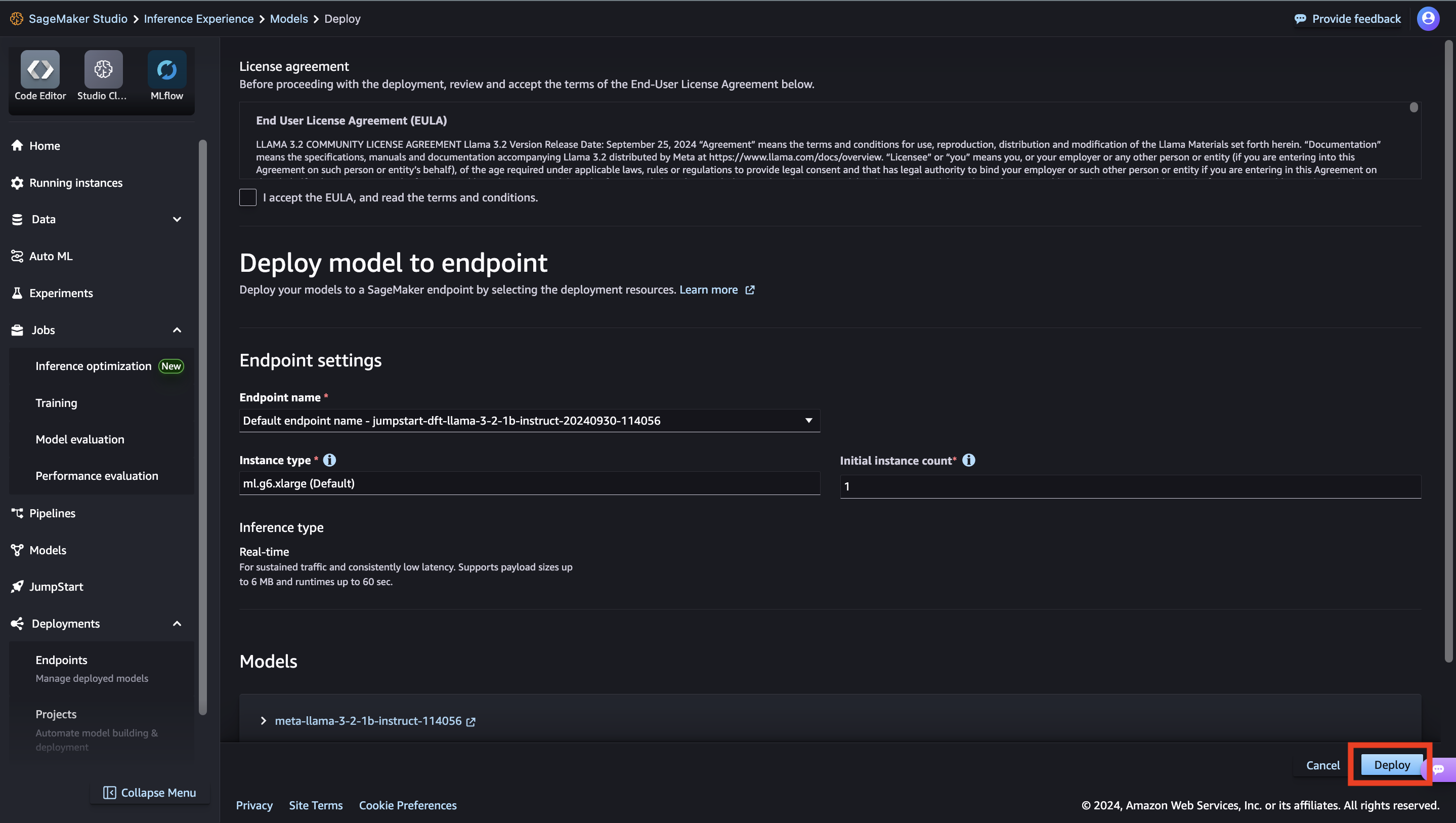
 Pavan Kumar Rao Navule is a Solutions Architect at Amazon Web Services, where he works with ISVs in India to help them innovate on the AWS platform. He is specialized in architecting AI/ML and generative AI services at AWS. Pavan is a published author for the book “Getting Started with V Programming.” In his free time, Pavan enjoys listening to the great magical voices of Sia and Rihanna.
Pavan Kumar Rao Navule is a Solutions Architect at Amazon Web Services, where he works with ISVs in India to help them innovate on the AWS platform. He is specialized in architecting AI/ML and generative AI services at AWS. Pavan is a published author for the book “Getting Started with V Programming.” In his free time, Pavan enjoys listening to the great magical voices of Sia and Rihanna. Jin Tan Ruan is a Prototyping Developer at AWS, part of the AWSI Strategic Prototyping and Customer Engineering (PACE) team, where he focuses on NLP and generative AI. With nine AWS certifications and a robust background in software development, Jin uses his expertise to help AWS strategic customers bring their AI/ML and generative AI projects to life. He holds a Master’s degree in Machine Learning and Software Engineering from Syracuse University. Outside of work, Jin is an avid gamer and a fan of horror films. You can find Jin on
Jin Tan Ruan is a Prototyping Developer at AWS, part of the AWSI Strategic Prototyping and Customer Engineering (PACE) team, where he focuses on NLP and generative AI. With nine AWS certifications and a robust background in software development, Jin uses his expertise to help AWS strategic customers bring their AI/ML and generative AI projects to life. He holds a Master’s degree in Machine Learning and Software Engineering from Syracuse University. Outside of work, Jin is an avid gamer and a fan of horror films. You can find Jin on  dléb…õ Åk] (listen); Palatine German: Heidlberg) is a city in the German state of Baden-W√ºrttemberg, situated on the river Neckar in south-west Germany. As of the 2016 census, its population was 159,914, of which roughly a quarter consisted of students.
dléb…õ Åk] (listen); Palatine German: Heidlberg) is a city in the German state of Baden-W√ºrttemberg, situated on the river Neckar in south-west Germany. As of the 2016 census, its population was 159,914, of which roughly a quarter consisted of students.



























 Genta Watanabe is a Senior Technical Account Manager at Amazon Web Services. He spends his time working with strategic automotive customers to help them achieve operational excellence. His areas of interest are machine learning and artificial intelligence. In his spare time, Genta enjoys spending quality time with his family and traveling.
Genta Watanabe is a Senior Technical Account Manager at Amazon Web Services. He spends his time working with strategic automotive customers to help them achieve operational excellence. His areas of interest are machine learning and artificial intelligence. In his spare time, Genta enjoys spending quality time with his family and traveling.
 We’re expanding flood forecasting to over 100 countries and making our breakthrough AI model available to researchers and partners.
We’re expanding flood forecasting to over 100 countries and making our breakthrough AI model available to researchers and partners.
