Large pretrained vision-language models like CLIP have shown promising generalization capability, but may struggle in specialized domains (e.g., satellite imagery) or fine-grained classification (e.g., car models) where the visual concepts are unseen or under-represented during pretraining. Prompt learning offers a parameter-efficient finetuning framework that can adapt CLIP to downstream tasks even when limited annotation data are available. In this paper, we improve prompt learning by distilling the textual knowledge from natural language prompts (either human- or LLM-generated) to provide…Apple Machine Learning Research
Best practices and lessons for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI, allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications. By fine-tuning, the LLM can adapt its knowledge base to specific data and tasks, resulting in enhanced task-specific capabilities. To achieve optimal results, having a clean, high-quality dataset is of paramount importance. A well-curated dataset forms the foundation for successful fine-tuning. Additionally, careful adjustment of hyperparameters such as learning rate multiplier and batch size plays a crucial role in optimizing the model’s adaptation to the target task.
The capabilities in Amazon Bedrock for fine-tuning LLMs offer substantial benefits for enterprises. This feature enables companies to optimize models like Anthropic’s Claude 3 Haiku on Amazon Bedrock for custom use cases, potentially achieving performance levels comparable to or even surpassing more advanced models such as Anthropic’s Claude 3 Opus or Anthropic’s Claude 3.5 Sonnet. The result is a significant improvement in task-specific performance, while potentially reducing costs and latency. This approach offers a versatile solution to satisfy your goals for performance and response time, allowing businesses to balance capability, domain knowledge, and efficiency in your AI-powered applications.
In this post, we explore the best practices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models. We also provide insights on how to achieve optimal results for different dataset sizes and use cases, backed by experimental data and performance metrics.
As part of this post, we first introduce general best practices for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock, and then present specific examples with the TAT- QA dataset (Tabular And Textual dataset for Question Answering).
Recommended use cases for fine-tuning
The use cases that are the most well-suited for fine-tuning Anthropic’s Claude 3 Haiku include the following:
- Classification – For example, when you have 10,000 labeled examples and want Anthropic’s Claude 3 Haiku to do well at this task.
- Structured outputs – For example, when you have 10,000 labeled examples specific to your use case and need Anthropic’s Claude 3 Haiku to accurately identify them.
- Tools and APIs – For example, when you need to teach Anthropic’s Claude 3 Haiku how to use your APIs well.
- Particular tone or language – For example, when you need Anthropic’s Claude 3 Haiku to respond with a particular tone or language specific to your brand.
Fine-tuning Anthropic’s Claude 3 Haiku has demonstrated superior performance compared to few-shot prompt engineering on base Anthropic’s Claude 3 Haiku, Anthropic’s Claude 3 Sonnet, and Anthropic’s Claude 3.5 Sonnet across various tasks. These tasks include summarization, classification, information retrieval, open-book Q&A, and custom language generation such as SQL. However, achieving optimal performance with fine-tuning requires effort and adherence to best practices.
To better illustrate the effectiveness of fine-tuning compared to other approaches, the following table provides a comprehensive overview of various problem types, examples, and their likelihood of success when using fine-tuning versus prompting with Retrieval Augmented Generation (RAG). This comparison can help you understand when and how to apply these different techniques effectively.
| Problem | Examples | Likelihood of Success with Fine-tuning | Likelihood of Success with Prompting + RAG |
| Make the model follow a specific format or tone | Instruct the model to use a specific JSON schema or talk like the organization’s customer service reps | Very High | High |
| Teach the model a new skill | Teach the model how to call APIs, fill out proprietary documents, or classify customer support tickets | High | Medium |
| Teach the model a new skill, and hope it learns similar skills | Teach the model to summarize contract documents, in order to learn how to write better contract documents | Low | Medium |
| Teach the model new knowledge, and expect it to use that knowledge for general tasks | Teach the model the organizations’ acronyms or more music facts | Low | Medium |
Prerequisites
Before diving into the best practices and optimizing fine-tuning LLMs on Amazon Bedrock, familiarize yourself with the general process and how-to outlined in Fine-tune Anthropic’s Claude 3 Haiku in Amazon Bedrock to boost model accuracy and quality. The post provides essential background information and context for the fine-tuning process, including step-by-step guidance on fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock both through the Amazon Bedrock console and Amazon Bedrock API.
LLM fine-tuning lifecycle
The process of fine-tuning an LLM like Anthropic’s Claude 3 Haiku on Amazon Bedrock typically follows these key stages:
- Use case definition – Clearly define the specific task or knowledge domain for fine-tuning
- Data preparation – Gather and clean high-quality datasets relevant to the use case
- Data formatting – Structure the data following best practices, including semantic blocks and system prompts where appropriate
- Model customization – Configure the fine-tuning job on Amazon Bedrock, setting parameters like learning rate and batch size, enabling features like early stopping to prevent overfitting
- Training and monitoring – Run the training job and monitor the status of training job
- Performance evaluation – Assess the fine-tuned model’s performance against relevant metrics, comparing it to base models
- Iteration and deployment – Based on the result, refine the process if needed, then deploy the model for production
Throughout this journey, depending on the business case, you may choose to combine fine-tuning with techniques like prompt engineering for optimal results. The process is inherently iterative, allowing for continuous improvement as new data or requirements emerge.
Use case and dataset
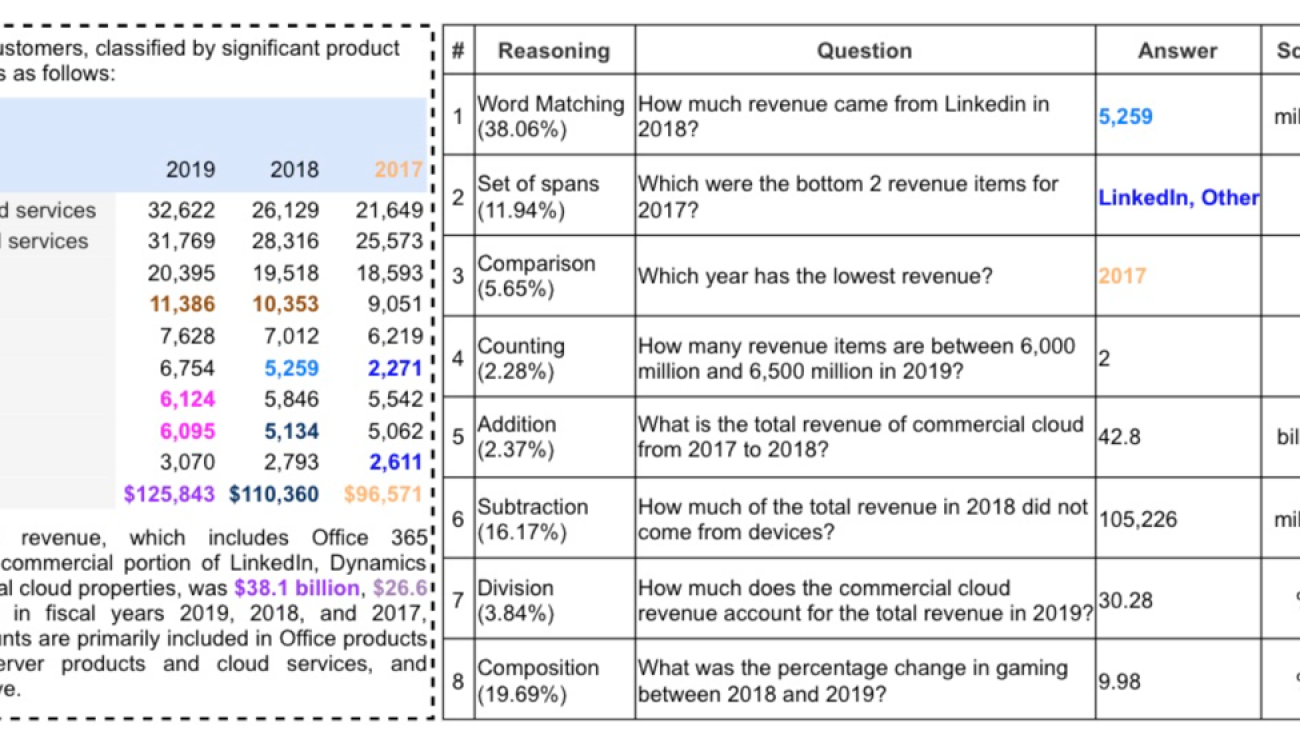
The TAT-QA dataset is related to a use case for question answering on a hybrid of tabular and textual content in finance where tabular data is organized in table formats such as HTML, JSON, Markdown, and LaTeX. We focus on the task of answering questions about the table. The evaluation metric is the F1 score that measures the word-to-word matching of the extracted content between the generated output and the ground truth answer. The TAT-QA dataset has been divided into train (28,832 rows), dev (3,632 rows), and test (3,572 rows).
The following screenshot provides a snapshot of the TAT-QA data, which comprises a table with tabular and textual financial data. Following this financial data table, a detailed question-answer set is presented to demonstrate the complexity and depth of analysis possible with the TAT-QA dataset. This comprehensive table is from the paper TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance, and it includes several key components:
- Reasoning types – Each question is categorized by the type of reasoning required
- Questions – A variety of questions that test different aspects of understanding and interpreting the financial data
- Answers – The correct responses to each question, showcasing the precision required in financial analysis
- Scale – Where applicable, the unit of measurement for the answer
- Derivation – For some questions, the calculation or logic used to arrive at the answer is provided

The following screenshot shows a formatted version of the data as JSONL and is passed to Anthropic’s Claude 3 Haiku for fine-tuning training data. The preceding table has been structured in JSONL format with system, user role (which contains the data and the question), and assistant role (which has answers). The table is enclosed within the XML tag <table><table>, helping Anthropic’s Claude 3 Haiku parse the prompt with the data from the table. For the model fine-tuning and performance evaluation, we randomly selected 10,000 examples from the TAT-QA dataset to fine-tune the model, and randomly picked 3,572 records from the remainder of the dataset as testing data.

Best practices for data cleaning and data validation
When fine-tuning the Anthropic’s Claude 3 Haiku model, the quality of training data is paramount and serves as the primary determinant of the output quality, surpassing the importance of any other step in the fine-tuning process. Our experiments have consistently shown that high-quality datasets, even if smaller in size, yield better results than a larger but less refined one. This “quality over quantity” approach should guide the entire data preparation process. Data cleaning and validation are essential steps in maintaining the quality of the training set. The following are two effective methods:
- Human evaluation – This method involves subject matter experts (SMEs) manually reviewing each data point for quality and relevance. Though time-consuming, it provides unparalleled insight into the nuances of the specific tasks.
- LLM as a judge – For large datasets, using Anthropic’s Claude models as a judge can be more efficient. For example, you can use Anthropic’s Claude 3.5 Sonnet as a judge to decide whether each provided training record meets the high quality requirement. The following is an example prompt template:
{'prompt': {'system': "You are a reliable and impartial expert judge in question/answering data assessment. ",'messages': [{'role': 'user', 'content': [{'type': 'text', 'text': 'Your task is to take a question, an answer, and a context which may include multiple documents, and provide a judgment on whether the answer to the question is correct or not. This decision should be based either on the provided context or your general knowledge and memory. If the answer contradicts the information in context, it's incorrect. A correct answer is ideally derived from the given context. If no context is given, a correct answer should be factually true and directly and unambiguously address the question.nnProvide a short step-by-step reasoning with a maximum of 4 sentences within the <reason></reason> xml tags and provide a single correct or incorrect response within the <judgement></judgement> xml tags.n <context>n...n</context>n<question>n...n</question>n<answer>n...n</answer>n'}]}]}}
The following is a sample output from Anthropic’s Claude 3.5 Sonnet:
{'id': 'job_id', 'type': 'message', 'role': 'assistant', 'model': 'claude-3-5-sonnet-20240620', 'content': [{'type': 'text', 'text': '<reason>n1. I'll check the table for information... </reason>nn<judgement>correct</judgement>'}], 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 923, 'output_tokens': 90}}
This LLM-as-a-judge approach is effective for large datasets, allowing for efficient and consistent quality assessment across a wide range of examples. It can help identify and filter out low-quality or irrelevant data points, making sure only the most suitable examples are used for fine-tuning.
The format of your training data is equally important. Although it’s optional, it’s highly recommended to include a system prompt that clearly defines the model’s role and tasks. In addition, including rationales within XML tags can provide valuable context for the model and facilitate extraction of key information. Prompt optimization is one of the key factors in improving model performance. Following established guidelines, such as those provided by Anthropic, can significantly enhance results. This might include structuring prompts with semantic blocks within XML tags, both in training samples and at inference time.
By adhering to these best practices in data cleaning, validation, and formatting, you can create a high-quality dataset that forms the foundation for successful fine-tuning. In the world of model training, quality outweighs quantity, and a well-prepared dataset is key to unlocking the full potential of fine-tuning Anthropic’s Claude 3 Haiku.
Best practices for performing model customization training jobs
When fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock, it’s crucial to optimize your training parameters to achieve the best possible performance. Our experiments have revealed several key insights that can guide you in effectively setting up your customization training jobs.
One of the most critical aspects of fine-tuning is selecting the right hyperparameters, particularly learning rate multiplier and batch size (see the appendix in this post for definitions). Our experiment results have shown that these two factors can significantly impact the model’s performance, with improvements ranging from 2–10% across different tasks. For the learning rate multiplier, the value ranges between 0.1–2.0, with a default value of 1.0. We suggest starting with the default value and potentially adjusting this value based on your evaluation result. Batch size is another important parameter, and its optimal value can vary depending on your dataset size. Based on our hyperparameter tuning experiments across different use cases, the API allows a range of 4–256, with a default of 32. However, we’ve observed that dynamically adjusting the batch size based on your dataset size can lead to better results:
- For datasets with 1,000 or more examples, aim for a batch size between 32–64
- For datasets between 500–1,000 examples, a batch size between 16–32 is generally suitable
- For smaller datasets with fewer than 500 examples, consider a batch size between 4–16
The following chart illustrates how model performance improves as the size of the training dataset increases, as well as the change of optimal parameters, using the TAT-QA dataset. Each data point is annotated with the optimal learning rate multiplier (LRM), batch size (BS), and number of epochs (Epoch) used to achieve the best performance with the dataset size. We can observe that larger datasets tend to benefit from higher learning rates and batch sizes, whereas smaller datasets require more training epochs. The red dashed line is the baseline Anthropic’s Claude 3 Haiku performance without fine-tuning efforts.

By following these guidelines, you can configure an Anthropic’s Claude 3 Haiku fine-tuning job with a higher chance of success. However, remember that these are general recommendations and the optimal settings may vary depending on your specific use case and dataset characteristics.
In scenarios with large amounts of data (1,000–10,000 examples), the learning rate tends to have a more significant impact on performance. Conversely, for smaller datasets (32–100 examples), the batch size becomes the dominant factor.
Performance evaluations
The fine-tuned Anthropic’s Claude 3 Haiku model demonstrated substantial performance improvements over base models when evaluated on the financial Q&A task, highlighting the effectiveness of the fine-tuning process on specialized data. Based on the evaluation results, we found the following:
- Fine-tuned Anthropic’s Claude 3 Haiku performed better than Anthropic’s Claude 3 Haiku, Anthropic’s Claude 3 Sonnet, and Anthropic’s Claude 3.5 Sonnet for TAT-QA dataset across the target use case of question answering on financial text and tabular content.
- For the performance evaluation metric F1 score (see the appendix for definition), fine-tuned Anthropic’s Claude 3 Haiku achieved a score of 91.2%, which is a 24.60% improvement over the Anthropic’s Claude 3 Haiku base model’s score of 73.2%. Fine-tuned Anthropic’s Claude 3 Haiku also achieved a 19.6% improvement over the Anthropic’s Claude 3 Sonnet base model’s performance, which obtained an F1 score of 76.3%. Fine-tuned Anthropic’s Claude 3 Haiku even achieved better performance over the Anthropic’s Claude 3.5 Sonnet base model.
The following table provides a detailed comparison of the performance metrics for the fine-tuned Claude 3 Haiku model against various base models, illustrating the significant improvements achieved through fine-tuning.
| . | . | . | . | . | Fine-Tuned Model Performance | Base Model Performance | Improvement: Fine-Tuned Anthropic’s Claude 3 Haiku vs. Base Models | ||||
| Target Use Case | Task Type | Fine-Tuning Data Size | Test Data Size | Eval Metric | Anthropic’s Claude 3 Haiku | Anthropic’s Claude 3 Haiku (Base Model) | Anthropic’s Claude 3 Sonnet | Anthropic’s Claude 3.5 Sonnet | vs. Anthropic’s Claude 3 Haiku Base | vs. Anthropic’s Claude 3 Sonnet Base | vs. Anthropic’s Claude 3.5 Sonnet Base |
| TAT-QA | Q&A on financial text and tabular content | 10,000 | 3,572 | F1 score | 91.2% | 73.2% | 76.3% | 83.0% | 24.6% | 19.6% | 9.9% |
Few-shot examples improve performance not only on the base model, but also on fine-tuned models, especially when the fine-tuning data is small.
Fine-tuning also demonstrated significant benefits in reducing token usage. On the TAT-QA HTML test set (893 examples), the fine-tuned Anthropic’s Claude 3 Haiku model reduced the average output token count by 35% compared to the base model, as shown in the following table.
| Model | Average Output Token | % Reduced | Median | % Reduced | Standard Deviation | Minimum Token | Maximum Token |
| Anthropic’s Claude 3 Haiku Base | 34 | – | 28 | – | 27 | 13 | 245 |
| Anthropic’s Claude 3 Haiku Fine-Tuned | 22 | 35% | 17 | 39% | 14 | 13 | 179 |
We use the following figures to illustrate the token count distribution for both the base Anthropic’s Claude 3 Haiku and fine-tuned Anthropic’s Claude 3 Haiku models. The left graph shows the distribution for the base model, and the right graph displays the distribution for the fine-tuned model. These histograms demonstrate a shift towards more concise output in the fine-tuned model, with a notable reduction in the frequency of longer token sequences.

To further illustrate this improvement, consider the following example from the test set:
- Question:
"How did the company adopt Topic 606?" - Ground truth answer:
"the modified retrospective method" - Base Anthropic’s Claude 3 Haiku response:
"The company adopted the provisions of Topic 606 in fiscal 2019 utilizing the modified retrospective method" - Fine-tuned Anthropic’s Claude 3 Haiku response:
"the modified retrospective method"
As evident from this example, the fine-tuned model produces a more concise and precise answer, matching the ground truth exactly, whereas the base model includes additional, unnecessary information. This reduction in token usage, combined with improved accuracy, can lead to enhanced efficiency and reduced costs in production deployments.
Conclusion
Fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock offers significant performance improvements for specialized tasks. Our experiments demonstrate that careful attention to data quality, hyperparameter optimization, and best practices in the fine-tuning process can yield substantial gains over base models. Key takeaways include the following:
- The importance of high-quality, task-specific datasets, even if smaller in size
- Optimal hyperparameter settings vary based on dataset size and task complexity
- Fine-tuned models consistently outperform base models across various metrics
- The process is iterative, allowing for continuous improvement as new data or requirements emerge
Although fine-tuning provides impressive results, combining it with other techniques like prompt engineering may lead to even better outcomes. As LLM technology continues to evolve, mastering fine-tuning techniques will be crucial for organizations looking to use these powerful models for specific use cases and tasks.
Now you’re ready to fine-tune Anthropic’s Claude 3 Haiku on Amazon Bedrock for your use case. We look forward to seeing what you build when you put this new technology to work for your business.
Appendix
We used the following hyperparameters as part of our fine-tuning:
- Learning rate multiplier – Learning rate multiplier is one of the most critical hyperparameters in LLM fine-tuning. It influences the learning rate at which model parameters are updated after each batch.
- Batch size – Batch size is the number of training examples processed in one iteration. It directly impacts GPU memory consumption and training dynamics.
- Epoch – One epoch means the model has seen every example in the dataset one time. The number of epochs is a crucial hyperparameter that affects model performance and training efficiency.
For our evaluation, we used the F1 score, which is an evaluation metric to assess the performance of LLMs and traditional ML models.
To compute the F1 score for LLM evaluation, we need to define precision and recall at the token level. Precision measures the proportion of generated tokens that match the reference tokens, and recall measures the proportion of reference tokens that are captured by the generated tokens. The F1 score ranges from 0–100, with 100 being the best possible score and 0 being the lowest. However, interpretation can vary depending on the specific task and requirements.
We calculate these metrics as follows:
- Precision = (Number of matching tokens in generated text) / (Total number of tokens in generated text)
- Recall = (Number of matching tokens in generated text) / (Total number of tokens in reference text)
- F1 = (2 * (Precision * Recall) / (Precision + Recall)) * 100
For example, let’s say the LLM generates the sentence “The cat sits on the mat in the sun” and the reference sentence is “The cat sits on the soft mat under the warm sun.” The precision would be 6/9 (6 matching tokens out of 9 generated tokens), and the recall would be 6/11 (6 matching tokens out of 11 reference tokens).
- Precision = 6/9 ≈ 0.667
- Recall = 6/11 ≈ 0.545
- F1 score = (2 * (0.667 * 0.545) / (0.667 + 0.545)) * 100 ≈ 59.90
About the Authors
 Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
 Sovik Kumar Nath is an AI/ML and Generative AI Senior Solutions Architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double master’s degrees from the University of South Florida and University of Fribourg, Switzerland, and a bachelor’s degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, and adventures.
Sovik Kumar Nath is an AI/ML and Generative AI Senior Solutions Architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double master’s degrees from the University of South Florida and University of Fribourg, Switzerland, and a bachelor’s degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, and adventures.
 Jennifer Zhu is a Senior Applied Scientist at AWS Bedrock, where she helps building and scaling generative AI applications with foundation models. Jennifer holds a PhD degree from Cornell University, and a master degree from University of San Francisco. Outside of work, she enjoys reading books and watching tennis games.
Jennifer Zhu is a Senior Applied Scientist at AWS Bedrock, where she helps building and scaling generative AI applications with foundation models. Jennifer holds a PhD degree from Cornell University, and a master degree from University of San Francisco. Outside of work, she enjoys reading books and watching tennis games.
 Fang Liu is a principal machine learning engineer at Amazon Web Services, where he has extensive experience in building AI/ML products using cutting-edge technologies. He has worked on notable projects such as Amazon Transcribe and Amazon Bedrock. Fang Liu holds a master’s degree in computer science from Tsinghua University.
Fang Liu is a principal machine learning engineer at Amazon Web Services, where he has extensive experience in building AI/ML products using cutting-edge technologies. He has worked on notable projects such as Amazon Transcribe and Amazon Bedrock. Fang Liu holds a master’s degree in computer science from Tsinghua University.
 Yanjun Qi is a Senior Applied Science Manager at the Amazon Bedrock Science. She innovates and applies machine learning to help AWS customers speed up their AI and cloud adoption.
Yanjun Qi is a Senior Applied Science Manager at the Amazon Bedrock Science. She innovates and applies machine learning to help AWS customers speed up their AI and cloud adoption.

AI-powered microgrids facilitate energy resilience and equity in regional communities

The rise of affordable small-scale renewable energy, like rooftop solar panels, is reshaping energy systems around the world. This shift away from fossil fuel-powered grids creates new opportunities for energy distribution that prioritize decentralized energy ownership and community empowerment. Despite this progress, centralized energy systems still dominate, often failing to provide vulnerable communities with reliable, affordable renewable energy. In response, Microsoft researchers are collaborating with local communities to explore how AI can enable community-scale energy solutions focused on energy availability and equity as well as decarbonization.
AI-powered microgrids support resilient communities
Microgrids, small and localized energy systems, hold promise as a solution to the challenges of centralized energy systems. These microgrids can operate independently from the larger grid, providing participants with resilience and control. Figure 1 shows how these systems integrate renewable energy sources and storage to efficiently manage local energy needs.
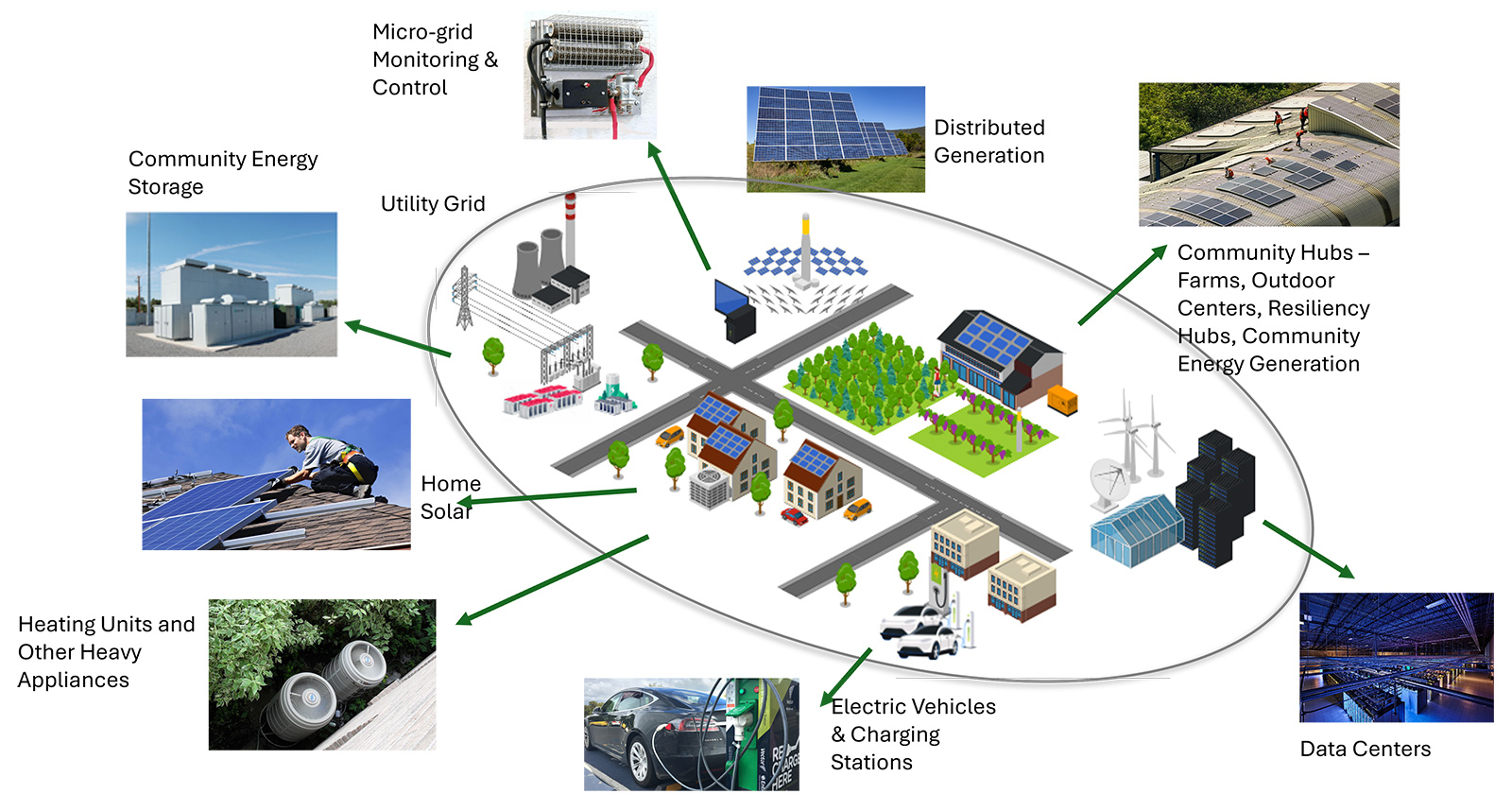
AI improves energy reliability by integrating data about energy consumption, market prices, and weather forecasts, necessary when using wind and solar power, which rely on weather conditions. Advanced forecasting predicts renewable energy availability, while AI-driven analytics determine when to generate, store, or sell electricity. This increases efficiency and stabilizes the grid by balancing supply and demand.
When powered by AI, microgrids can also contribute to energy equity. In many rural parts of the US, flat-rate billing models are still common, often leading to unfair pricing. AI-enabled microgrids provide an alternative by allowing communities to pay only for the energy they use. By analyzing consumption patterns, AI can ensure optimized distribution that promotes equitable pricing and access. These systems also improve resilience during crises, enabling communities to manage energy distribution more effectively and reduce reliance on centralized utilities. AI allows microgrids to predict energy demands, identify system vulnerabilities, and recover quickly during outages.
Evaluating AI’s impact on microgrid efficiency and equity
To explore AI’s potential in improving efficiency and equity in energy management, a team of Microsoft researchers collaborated with community organizations on simulations and a case study. They built a tabletop simulator to test whether AI could effectively determine when to generate, store, or sell electricity based on real-time data. The AI model was optimized for resilience and efficiency, using reinforcement learning to control grid and battery processes, enabling microgrids adapt to changing energy conditions and market dynamics.
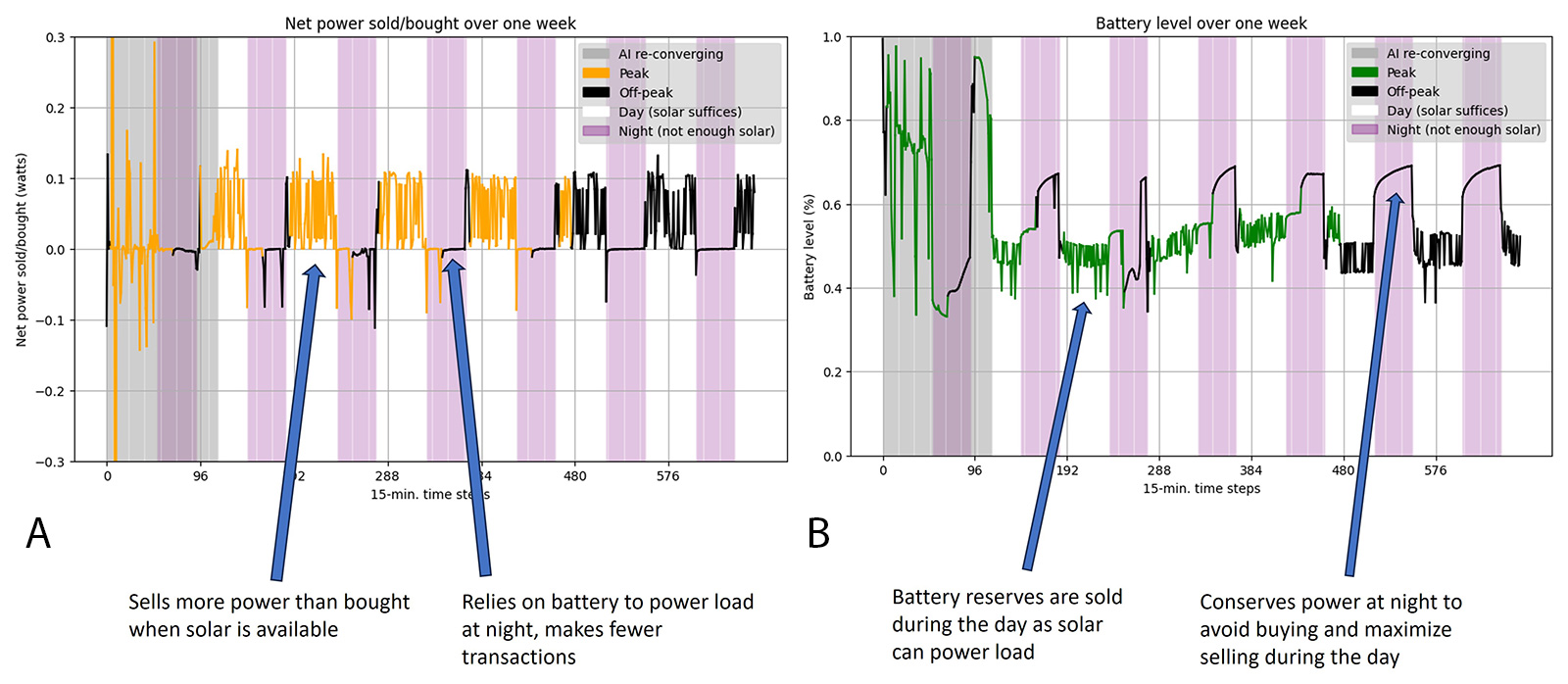
This simulation used a theoretical model with external data to show how an AI-driven microgrid could autonomously buy and sell energy based on strategic design parameters. By controlling when the battery is charged and discharged based on energy production and consumption patterns, the model maximized efficiency and maintained local power availability. Figure 2 shows the AI-controlled grid’s optimal decisions using open-source data from the California Independent System Operator (CAISO), serving as a proof of concept (PoC) for AI-driven microgrids operating under real-world conditions.
Case study: AI-powered microgrid for community energy transition
Microsoft researchers, in partnership with community-based organizations Remix: The Soul of Innovation (opens in new tab), Maverick IQ (opens in new tab) and Ayika Solutions (opens in new tab), are designing and implementing an AI-powered microgrid system in West Atlanta. Working closely with the Vicars Community Center (VCC) resilience hub (opens in new tab), they aim to address challenges faced by the community due to rapid development. West Atlanta, like many Atlanta neighborhoods, faces rising housing prices and energy costs that disproportionately affect long-time residents. Communities relying on centralized grids are more vulnerable to outages, with slow recovery times, highlighting systemic inequalities in energy distribution.
The VCC resilience hub is tackling these issues by helping to establish a solar microgrid for the West Atlanta Watershed Alliance (opens in new tab) (WAWA) community farm and surrounding neighborhoods. Microsoft researchers and collaborators are integrating AI into the microgrid to achieve energy savings, improve resilience, and create local job opportunities. Figure 3 shows the VCC resilience hub and WAWA community farm powered by the microgrid, highlighting key infrastructure for installing distributed energy resources (DERs).

Project phases
Co-innovation design
Microsoft researchers, architects, and community partners held a participatory design session with state and utility representatives to define the project’s mission and key metrics. The CDC’s Social Vulnerability Index informed the site selection, supporting the project’s diversity, equity, and inclusion goals.
Renewables and microgrid siting
A renewable siting survey conducted by community partners identified the VCC as a key resilience hub for solar panel and battery installation.
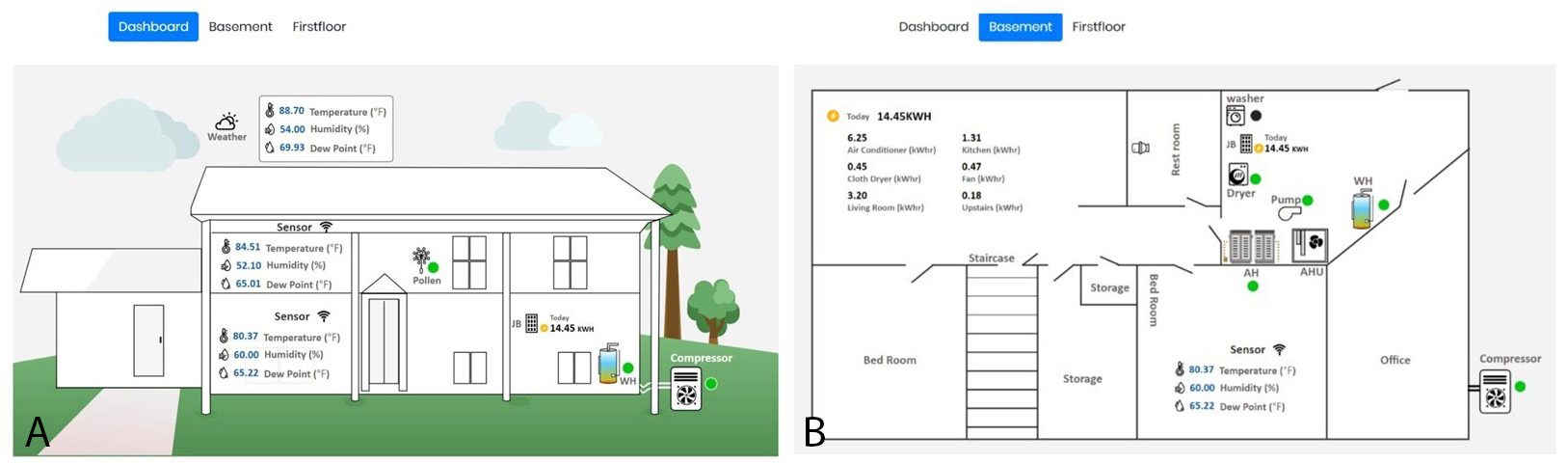
To deliver these benefits, the site first needed upgrades. Older homes required energy-efficiency improvements, such as electrical upgrades and better insulation, before they could be integrated into the microgrid. As a PoC, the team collaborated with community partners to modernize an older home with inefficient energy consumption. Sensors were installed to track energy usage and environmental conditions (Figure 4).

Students from Morehouse College (opens in new tab) used this data to create a digital twin of the home, which provided actionable insights (Figure 5). The analysis confirmed issues like high radon levels and energy drains from outdated appliances. Guided by these findings, the team upgraded the house into a “smart home” where AI monitors energy and environmental conditions, enabling it to join the microgrid and making it eligible for LEED certification (opens in new tab).
Microgrid simulation phase
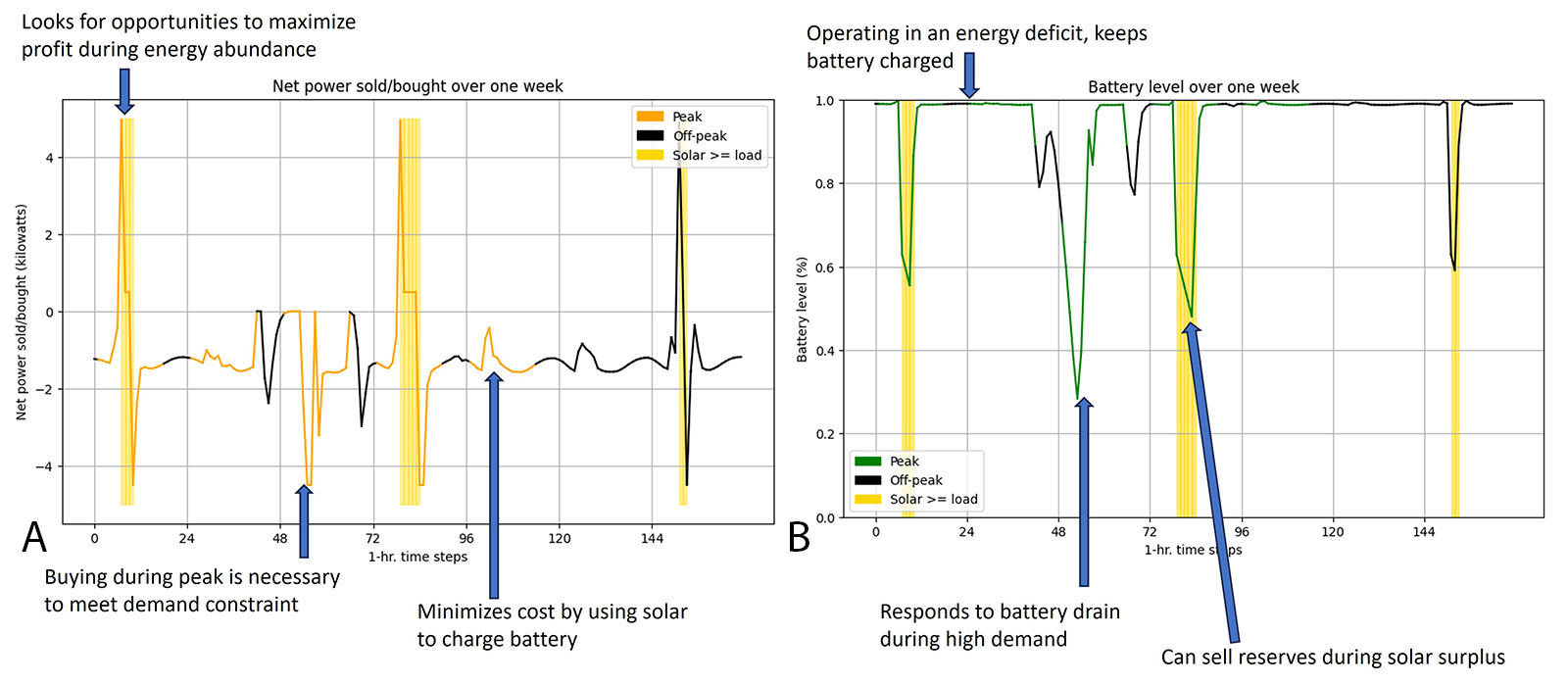
To prepare the AI-powered microgrid, Microsoft researchers built a simplified tabletop prototype simulating the setup using real data from the design and siting phases. This prototype demonstrated the control mechanism’s ability to manage DERs—solar panels, batteries, and appliances—and the interface between the microgrid and the larger grid. Figure 6 shows the tabletop model during prototyping.
Figure 7 illustrates the results of this simulation, showing power bought and sold and the battery charge-discharge profile. The AI controller made optimal buying and selling decisions, promoting efficiency and reliability.
Erica Holloman-Hill, director of WAWA, CEO of Ayika Solutions and owner of the PoC home, reflected: “This study helped me understand how our home’s outdated condition affects our quality of life. Upgrading homes like mine could make a significant difference. Thanks to partnerships like this one, controlling and sharing the electricity the community generates is within reach, highlighting the potential of AI-supported technologies like microgrids for communities like ours.”
Building on the simulation’s success, the VCC resilience hub and local organizations are continuing to install solar panels to power the microgrid. AI will play a key role in siting and controlling the system as it expands. Efforts are also underway to establish sustainable financing models and assess homes for modernization to enable broader participation in the microgrid.
AI: A path to equity and resilience
The transition to decentralized microgrids offers new opportunities for energy efficiency, with AI playing a critical role in managing these systems. Yet additional efforts are needed for communities to fully realize these benefits. Residents of aging homes are burdened with outdated wiring, inefficient appliances, and poor insulation—factors that drive up energy costs. Their dependence on centralized grids offers little relief, underscoring the need for community-focused energy solutions.
The West Atlanta project illustrates AI’s potential to create resilient, equitable, community-driven energy systems, paving the way for a more inclusive and sustainable future. Microsoft researchers are continuing to collaborate with local organizations to promote smarter energy management.
For additional details, please review the project report.
Acknowledgements
I would like to thank all the collaborators on these projects: West Atlanta microgrid: Erica L. Holloman-Hill, John Jordan Jr, Markese Bryant. I also want to thank Karin Strauss for reviewing and providing feedback on this blog post; Andalib Samandari, the intern who supported this project; Vaishnavi Ranganathan for helping to brainstorm throughout the project; AI & Society Fellows program for supporting projects in this domain; and Microsoft’s Datacenter Community Affairs team, Jon McKenley and Kelly Lanier Arnold for supporting the project in West Atlanta.
The post AI-powered microgrids facilitate energy resilience and equity in regional communities appeared first on Microsoft Research.
Track, allocate, and manage your generative AI cost and usage with Amazon Bedrock
As enterprises increasingly embrace generative AI , they face challenges in managing the associated costs. With demand for generative AI applications surging across projects and multiple lines of business, accurately allocating and tracking spend becomes more complex. Organizations need to prioritize their generative AI spending based on business impact and criticality while maintaining cost transparency across customer and user segments. This visibility is essential for setting accurate pricing for generative AI offerings, implementing chargebacks, and establishing usage-based billing models.
Without a scalable approach to controlling costs, organizations risk unbudgeted usage and cost overruns. Manual spend monitoring and periodic usage limit adjustments are inefficient and prone to human error, leading to potential overspending. Although tagging is supported on a variety of Amazon Bedrock resources—including provisioned models, custom models, agents and agent aliases, model evaluations, prompts, prompt flows, knowledge bases, batch inference jobs, custom model jobs, and model duplication jobs—there was previously no capability for tagging on-demand foundation models. This limitation has added complexity to cost management for generative AI initiatives.
To address these challenges, Amazon Bedrock has launched a capability that organization can use to tag on-demand models and monitor associated costs. Organizations can now label all Amazon Bedrock models with AWS cost allocation tags, aligning usage to specific organizational taxonomies such as cost centers, business units, and applications. To manage their generative AI spend judiciously, organizations can use services like AWS Budgets to set tag-based budgets and alarms to monitor usage, and receive alerts for anomalies or predefined thresholds. This scalable, programmatic approach eliminates inefficient manual processes, reduces the risk of excess spending, and ensures that critical applications receive priority. Enhanced visibility and control over AI-related expenses enables organizations to maximize their generative AI investments and foster innovation.
Introducing Amazon Bedrock application inference profiles
Amazon Bedrock recently introduced cross-region inference, enabling automatic routing of inference requests across AWS Regions. This feature uses system-defined inference profiles (predefined by Amazon Bedrock), which configure different model Amazon Resource Names (ARNs) from various Regions and unify them under a single model identifier (both model ID and ARN). While this enhances flexibility in model usage, it doesn’t support attaching custom tags for tracking, managing, and controlling costs across workloads and tenants.
To bridge this gap, Amazon Bedrock now introduces application inference profiles, a new capability that allows organizations to apply custom cost allocation tags to track, manage, and control their Amazon Bedrock on-demand model costs and usage. This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications.
Creating application inference profiles
Application inference profiles allow users to define customized settings for inference requests and resource management. These profiles can be created in two ways:
- Single model ARN configuration: Directly create an application inference profile using a single on-demand base model ARN, allowing quick setup with a chosen model.
- Copy from system-defined inference profile: Copy an existing system-defined inference profile to create an application inference profile, which will inherit configurations such as cross-Region inference capabilities for enhanced scalability and resilience.
The application inference profile ARN has the following format, where the inference profile ID component is a unique 12-digit alphanumeric string generated by Amazon Bedrock upon profile creation.
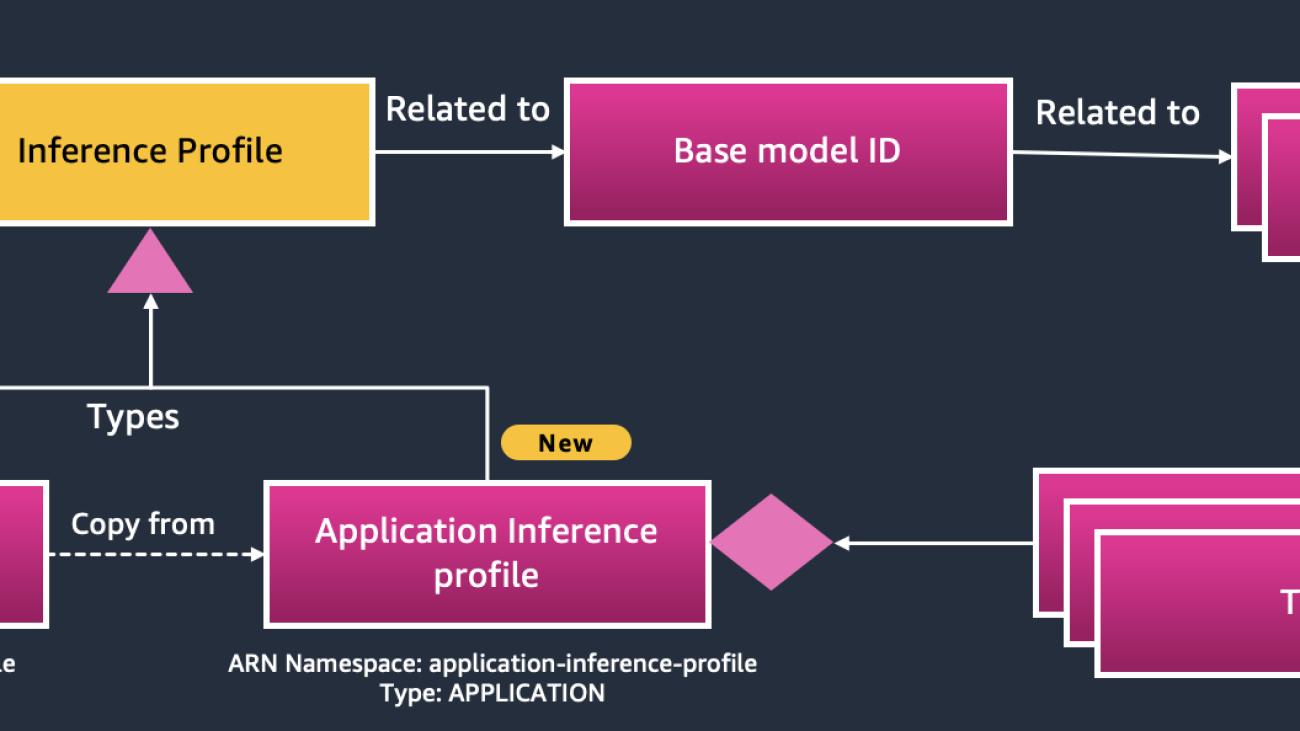
System-defined compared to application inference profiles
The primary distinction between system-defined and application inference profiles lies in their type attribute and resource specifications within the ARN namespace:
- System-defined inference profiles: These have a type attribute of
SYSTEM_DEFINEDand utilize theinference-profileresource type. They’re designed to support cross-Region and multi-model capabilities but are managed centrally by AWS. - Application inference profiles: These profiles have a
typeattribute ofAPPLICATIONand use theapplication-inference-profileresource type. They’re user-defined, providing granular control and flexibility over model configurations and allowing organizations to tailor policies with attribute-based access control (ABAC) using AWS Identity and Access Management (IAM). This enables more precise IAM policy authoring to manage Amazon Bedrock access more securely and efficiently.
These differences are important when integrating with Amazon API Gateway or other API clients to help ensure correct model invocation, resource allocation, and workload prioritization. Organizations can apply customized policies based on profile type, enhancing control and security for distributed AI workloads. Both models are shown in the following figure.

Establishing application inference profiles for cost management
Imagine an insurance provider embarking on a journey to enhance customer experience through generative AI. The company identifies opportunities to automate claims processing, provide personalized policy recommendations, and improve risk assessment for clients across various regions. However, to realize this vision, the organization must adopt a robust framework for effectively managing their generative AI workloads.
The journey begins with the insurance provider creating application inference profiles that are tailored to their diverse business units. By assigning AWS cost allocation tags, the organization can effectively monitor and track their Bedrock spend patterns. For example, the claims processing team established an application inference profile with tags such as dept:claims, team:automation, and app:claims_chatbot. This tagging structure categorizes costs and allows assessment of usage against budgets.
Users can manage and use application inference profiles using Bedrock APIs or the boto3 SDK:
- CreateInferenceProfile: Initiates a new inference profile, allowing users to configure the parameters for the profile.
- GetInferenceProfile: Retrieves the details of a specific inference profile, including its configuration and current status.
- ListInferenceProfiles: Lists all available inference profiles within the user’s account, providing an overview of the profiles that have been created.
- TagResource: Allows users to attach tags to specific Bedrock resources, including application inference profiles, for better organization and cost tracking.
- ListTagsForResource: Fetches the tags associated with a specific Bedrock resource, helping users understand how their resources are categorized.
- UntagResource: Removes specified tags from a resource, allowing for management of resource organization.
- Invoke models with application inference profiles:
-
- Converse API: Invokes the model using a specified inference profile for conversational interactions.
- ConverseStream API: Similar to the Converse API but supports streaming responses for real-time interactions.
- InvokeModel API: Invokes the model with a specified inference profile for general use cases.
- InvokeModelWithResponseStream API: Invokes the model and streams the response, useful for handling large data outputs or long-running processes.
Note that application inference profile APIs cannot be accessed through the AWS Management Console.
Invoke model with application inference profile using Converse API
The following example demonstrates how to create an application inference profile and then invoke the Converse API to engage in a conversation using that profile –
Tagging, resource management, and cost management with application inference profiles
Tagging within application inference profiles allows organizations to allocate costs with specific generative AI initiatives, ensuring precise expense tracking. Application inference profiles enable organizations to apply cost allocation tags at creation and support additional tagging through the existing TagResource and UnTagResource APIs, which allow metadata association with various AWS resources. Custom tags such as project_id, cost_center, model_version, and environment help categorize resources, improving cost transparency and allowing teams to monitor spend and usage against budgets.
Visualize cost and usage with application inference profiles and cost allocation tags
Leveraging cost allocation tags with tools like AWS Budgets, AWS Cost Anomaly Detection, AWS Cost Explorer, AWS Cost and Usage Reports (CUR), and Amazon CloudWatch provides organizations insights into spending trends, helping detect and address cost spikes early to stay within budget.
With AWS Budgets, organization can set tag-based thresholds and receive alerts as spending approach budget limits, offering a proactive approach to maintaining control over AI resource costs and quickly addressing any unexpected surges. For example, a $10,000 per month budget could be applied on a specific chatbot application for the Support Team in the Sales Department by applying the following tags to the application inference profile: dept:sales, team:support, and app:chat_app. AWS Cost Anomaly Detection can also monitor tagged resources for unusual spending patterns, making it easier to operationalize cost allocation tags by automatically identifying and flagging irregular costs.
The following AWS Budgets console screenshot illustrates an exceeded budget threshold:

For deeper analysis, AWS Cost Explorer and CUR enable organizations to analyze tagged resources daily, weekly, and monthly, supporting informed decisions on resource allocation and cost optimization. By visualizing cost and usage based on metadata attributes, such as tag key/value and ARN, organizations gain an actionable, granular view of their spending.
The following AWS Cost Explorer console screenshot illustrates a cost and usage graph filtered by tag key and value:

The following AWS Cost Explorer console screenshot illustrates a cost and usage graph filtered by Bedrock application inference profile ARN:

Organizations can also use Amazon CloudWatch to monitor runtime metrics for Bedrock applications, providing additional insights into performance and cost management. Metrics can be graphed by application inference profile, and teams can set alarms based on thresholds for tagged resources. Notifications and automated responses triggered by these alarms enable real-time management of cost and resource usage, preventing budget overruns and maintaining financial stability for generate AI workloads.
The following Amazon CloudWatch console screenshot highlights Bedrock runtime metrics filtered by Bedrock application inference profile ARN:

The following Amazon CloudWatch console screenshot highlights an invocation limit alarm filtered by Bedrock application inference profile ARN:

Through the combined use of tagging, budgeting, anomaly detection, and detailed cost analysis, organizations can effectively manage their AI investments. By leveraging these AWS tools, teams can maintain a clear view of spending patterns, enabling more informed decision-making and maximizing the value of their generative AI initiatives while ensuring critical applications remain within budget.
Retrieving application inference profile ARN based on the tags for Model invocation
Organizations often use a generative AI gateway or large language model proxy when calling Amazon Bedrock APIs, including model inference calls. With the introduction of application inference profiles, organizations need to retrieve the inference profile ARN to invoke model inference for on-demand foundation models. There are two primary approaches to obtain the appropriate inference profile ARN.
- Static configuration approach: This method involves maintaining a static configuration file in the AWS Systems Manager Parameter Store or AWS Secrets Manager that maps tenant/workload keys to their corresponding application inference profile ARNs. While this approach offers simplicity in implementation, it has significant limitations. As the number of inference profiles scales from tens to hundreds or even thousands, managing and updating this configuration file becomes increasingly cumbersome. The static nature of this method requires manual updates whenever changes occur, which can lead to inconsistencies and increased maintenance overhead, especially in large-scale deployments where organizations need to dynamically retrieve the correct inference profile based on tags.
- Dynamic retrieval using the Resource Groups API: The second, more robust approach leverages the AWS Resource Groups GetResources API to dynamically retrieve application inference profile ARNs based on resource and tag filters. This method allows for flexible querying using various tag keys such as tenant ID, project ID, department ID, workload ID, model ID, and region. The primary advantage of this approach is its scalability and dynamic nature, enabling real-time retrieval of application inference profile ARNs based on current tag configurations.
However, there are considerations to keep in mind. The GetResources API has throttling limits, necessitating the implementation of a caching mechanism. Organizations should maintain a cache with a Time-To-Live (TTL) based on the API’s output to optimize performance and reduce API calls. Additionally, implementing thread safety is crucial to help ensure that organizations always read the most up-to-date inference profile ARNs when the cache is being refreshed based on the TTL.
As illustrated in the following diagram, this dynamic approach involves a client making a request to the Resource Groups service with specific resource type and tag filters. The service returns the corresponding application inference profile ARN, which is then cached for a set period. The client can then use this ARN to invoke the Bedrock model through the InvokeModel or Converse API.
By adopting this dynamic retrieval method, organizations can create a more flexible and scalable system for managing application inference profiles, allowing for more straightforward adaptation to changing requirements and growth in the number of profiles.

The architecture in the preceding figure illustrates two methods for dynamically retrieving inference profile ARNs based on tags. Let’s describe both approaches with their pros and cons:
- Bedrock client maintaining the cache with TTL: This method involves the client directly querying the AWS
ResourceGroupsservice using theGetResourcesAPI based on resource type and tag filters. The client caches the retrieved keys in a client-maintained cache with a TTL. The client is responsible for refreshing the cache by calling theGetResourcesAPI in the thread safe way. - Lambda-based Method: This approach uses AWS Lambda as an intermediary between the calling client and the
ResourceGroupsAPI. This method employs Lambda Extensions core with an in-memory cache, potentially reducing the number of API calls toResourceGroups. It also interacts with Parameter Store, which can be used for configuration management or storing cached data persistently.
Both methods use similar filtering criteria (resource-type-filter and tag-filters) to query the ResourceGroup API, allowing for precise retrieval of inference profile ARNs based on attributes such as tenant, model, and Region. The choice between these methods depends on factors such as the expected request volume, desired latency, cost considerations, and the need for additional processing or security measures. The Lambda-based approach offers more flexibility and optimization potential, while the direct API method is simpler to implement and maintain.
Overview of Amazon Bedrock resources tagging capabilities
The tagging capabilities of Amazon Bedrock have evolved significantly, providing a comprehensive framework for resource management across multi-account AWS Control Tower setups. This evolution enables organizations to manage resources across development, staging, and production environments, helping organizations track, manage, and allocate costs for their AI/ML workloads.
At its core, the Amazon Bedrock resource tagging system spans multiple operational components. Organizations can effectively tag their batch inference jobs, agents, custom model jobs, knowledge bases, prompts, and prompt flows. This foundational level of tagging supports granular control over operational resources, enabling precise tracking and management of different workload components. The model management aspect of Amazon Bedrock introduces another layer of tagging capabilities, encompassing both custom and base models, and distinguishes between provisioned and on-demand models, each with its own tagging requirements and capabilities.
With the introduction of application inference profiles, organizations can now manage and track their on-demand Bedrock base foundation models. Because teams can create application inference profiles derived from system-defined inference profiles, they can configure more precise resource tracking and cost allocation at the application level. This capability is particularly valuable for organizations that are running multiple AI applications across different environments, because it provides clear visibility into resource usage and costs at a granular level.
The following diagram visualizes the multi-account structure and demonstrates how these tagging capabilities can be implemented across different AWS accounts.

Conclusion
In this post we introduced the latest feature from Amazon Bedrock, application inference profiles. We explored how it operates and discussed key considerations. The code sample for this feature is available in this GitHub repository. This new capability enables organizations to tag, allocate, and track on-demand model inference workloads and spending across their operations. Organizations can label all Amazon Bedrock models using tags and monitoring usage according to their specific organizational taxonomy—such as tenants, workloads, cost centers, business units, teams, and applications. This feature is now generally available in all AWS Regions where Amazon Bedrock is offered.
About the authors
 Kyle T. Blocksom is a Sr. Solutions Architect with AWS based in Southern California. Kyle’s passion is to bring people together and leverage technology to deliver solutions that customers love. Outside of work, he enjoys surfing, eating, wrestling with his dog, and spoiling his niece and nephew.
Kyle T. Blocksom is a Sr. Solutions Architect with AWS based in Southern California. Kyle’s passion is to bring people together and leverage technology to deliver solutions that customers love. Outside of work, he enjoys surfing, eating, wrestling with his dog, and spoiling his niece and nephew.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
7 pieces of AI news we announced in October
 Here are 7 of Google’s latest AI updates from October.Read More
Here are 7 of Google’s latest AI updates from October.Read More
Advance environmental sustainability in clinical trials using AWS
Traditionally, clinical trials not only place a significant burden on patients and participants due to the costs associated with transportation, lodging, meals, and dependent care, but also have an environmental impact. With the advancement of available technologies, decentralized clinical trials have become a widely popular topic of discussion and offer a more sustainable approach. Decentralized clinical trials reduce the need to travel to study sites by lowering the financial burden on all parties involved, thereby accelerating patient recruitment and reducing dropout rates. Decentralized clinical trials use technologies such as wearable devices, patient apps, smartphones, and telemedicine to accelerate recruitment, reduce dropout, and minimize the carbon footprint of clinical research. AWS can play a key role in enabling fast implementation of these decentralized clinical trials.
In this post, we discuss how to use AWS to support a decentralized clinical trial across the four main pillars of a decentralized clinical trial (virtual trials, personalized patient engagement, patient-centric trial design, and centralized data management). By exploring these AWS powered alternatives, we aim to demonstrate how organizations can drive progress towards more environmentally friendly clinical research practices.
The challenge and impact of sustainability on clinical trials
With the rise of greenhouse gas emissions globally, finding ways to become more sustainable is quickly becoming a challenge across all industries. At the same time, global health awareness and investments in clinical research have increased as a result of motivations by major events like the COVID-19 pandemic. For instance, in 2021, we saw a significant increase in awareness of clinical research studies seeking volunteers, which was reported at 63% compared to 54% in 2019 by Applied Clinical Trials. This suggests that the COVID-19 pandemic brought increased attention to clinical trials among the public and magnified the importance of including diverse populations in clinical research.
These clinical research trials study new tests and treatments while evaluating their effects on human health outcomes. People often volunteer to take part in clinical trials to test medical interventions, including drugs, biological products, surgical procedures, radiological procedures, devices, behavioral treatments, and preventive care. The rise of clinical trials presents a major sustainability challenge—they are often not sustainable and can contribute substantially to greenhouse gas emissions due to how they are being implemented. The main sources of these are usually associated with the intensive energy use associated with research premises and air travel.
This post discusses an alternative to clinical trials—by decentralizing clinical trials, we can reduce the major greenhouse gas emissions caused by human activities present in clinical trials today.
The CRASH trial case study
We can further examine the impact of carbon emissions associated with clinical trials through the carbon audit of the CRASH trial case lead by medical research journal, BMJ. The CRASH trial was a clinical trial conducted from 1999–2004 and recruited patients from 49 countries in the span of 5 years. In the study, the effect of intravenous corticosteroids (a drug produced by Pfizer) on death within 14 days in 10,008 adults with clinically significant head injuries was examined. BMJ conducted an audit on the total emissions of greenhouse gases that were produced by the trials and calculated that roughly 126 metric tons (carbon dioxide equivalent) was emitted during a 1-year period. Over a 5-year period, it would mean that the entire trial would be responsible for about 630 metric tons of carbon dioxide equivalent.
Much of these greenhouse gas emissions can be attributed to travel (such as air travel, hotel, meetings), distribution associated for drugs and documents, and electricity used in coordination centers. According to the EPA, the average passenger vehicle emits about 4.6 metric tons of carbon dioxide per year. In comparison, 630 tons of carbon dioxide would be equivalent to the annual emissions of around 137 passenger vehicles. Similarly, the average US household generates about 20 metric tons of carbon dioxide per year from energy use. 630 tons of carbon dioxide would also be equal to the annual emissions of around 31 average US homes. 630 tons of carbon dioxide already represents a very substantial amount of greenhouse gas for one clinical trial. According to sources from government databases and research institutions, there are around 300,000–600,000 clinical trials conducted globally each year, amplifying this impact by several hundred thousand times.
Clinical trials vs. decentralized clinical trials
Decentralized clinical trials present opportunities to address the sustainability challenges associated with traditional clinical trial models. As a byproduct of decentralized trials, there are also improvements in the patient experience by reducing their burden, making the process more convenient and sustainable.
Today, clinical trials can contribute significantly to greenhouse gas emissions, primarily through energy use in research facilities and air travel. In contrast to the energy-intensive nature of centralized trial sites, the distributed nature of decentralized clinical trials offers a more practical and cost-effective approach to implementing renewable energy solutions.
For centralized clinical trials, many are conducted in energy-intensive healthcare facilities. Traditional trial sites, such as hospitals and dedicated research centers, can have high energy demands for equipment, lighting, and climate control. These facilities often rely on regional or national power grids for their energy needs. Integrating renewable energy solutions in these facilities can also be costly and challenging, because it can involve significant investments into new equipment, renewable energy projects, and more.
In decentralized clinical trials, the reduction in infrastructure and onsite resources will allow for a lower energy demand overall. This, in turn, will result in benefits such as simplified trial designs, reduced bureaucracy, and less human travel required for video conferencing. Furthermore, the additional appointments required for clinical trials might create additional time and financial burdens for participants. Decentralized clinical trials can reduce the burden on patients for in-person visits and increase patient retention and long-term follow-up.
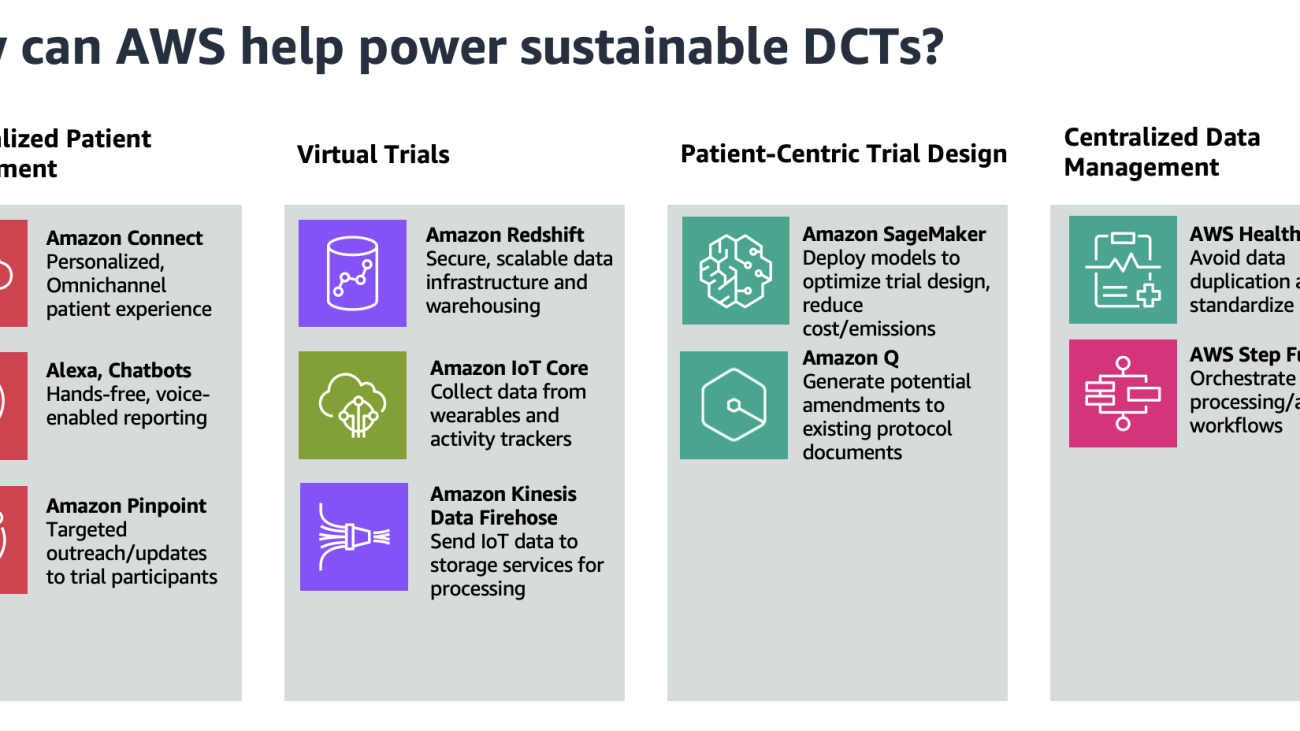
Core pillars on how AWS can power sustainable decentralized clinical trials
AWS customers have developed proven solutions that power sustainable decentralized clinical trials. SourceFuse is an AWS partner that has developed a mobile app and web interface that enables patients to participate in decentralized clinical trials remotely from their homes, eliminating the environmental impact of travel and paper-based data collection. The platform’s cloud-centered architecture, built on AWS services, supports the scalable and sustainable operation of these remote clinical trials.
In this post, we provide sustainability-oriented guidance focused on four key areas: virtual trials, personalized patient engagement, patient-centric trial design, and centralized data management. The following figure showcases the AWS services that can help in these four areas.

Personalized remote patient engagement
The average dropout rate for clinical trials is 30%, so providing an omnichannel experience for subjects to interact with trial facilitators is imperative. Because decentralized clinical trials provide flexibility for patients to participate at home, the experience for patients to collect and report data should be seamless. One solution is to use voice applications to enable patient data reporting, using Amazon Alexa and Amazon Connect. For example, a patient can report symptoms to their Amazon Echo device, invoking an automated patient outreach scheduler using Amazon Connect.
Trial facilitators can also use Amazon Pinpoint to connect with customers through multiple channels. They can use Amazon Pinpoint to send medication reminders, automate surveys, or push other communications without the need for paper mail delivery.
Virtual trials
Decentralized clinical trials reduce emissions compared to regular clinical trials by eliminating the need for travel and physical infrastructure. Instead, a core component of decentralized clinical trials is a secure, scalable data infrastructure with strong data analytics capabilities. Amazon Redshift is a fully managed cloud data warehouse that trial scientists can use to perform analytics.
Clinical Research Organizations (CROs) and life sciences organizations can also use AWS for mobile device and wearable data capture. Patients, in the comfort of their own home, can collect data passively through wearables, activity trackers, and other smart devices. This data is streamed to AWS IoT Core, which can write data to Amazon Data Firehose in real time. This data can then be sent to services like Amazon Simple Storage Service (Amazon S3) and AWS Glue for data processing and insight extraction.
Patient-centric trial design
A key characteristic of decentralized clinical trials is patient-centric protocol design, which prioritizes the patients’ needs throughout the entire clinical trial process. This involves patient-reported outcomes and often implement flexible participation, which can complicate protocol development and necessitate more extensive regulatory documentation. This can add days or even weeks to the lifespan of a trial, leading to avoidable costs. Amazon SageMaker enables trial developers to build and train machine learning (ML) models that reduce the likelihood of protocol amendments and inconsistencies. Models can also be built to determine the appropriate sample size and recruitment timelines.
With SageMaker, you can optimize your ML environment for sustainability. Amazon SageMaker Debugger provides profiler capabilities to detect under-utilization of system resources, which helps right-size your environment and avoid unnecessary carbon emissions. Organizations can further reduce emissions by choosing deployment regions near renewable energy projects. Currently, there are 22 AWS data center regions where 100% of the electricity consumed is matched by renewable energy sources. Additionally, you can use Amazon Q, a generative AI-powered assistant, to surface and generate potential amendments to avoid expensive costs associated with protocol revisions.
Centralized data management
CROs and bio-pharmaceutical companies are striving to achieve end-to-end data linearity for all clinical trials within an organization. They want to see traceability across the board, while achieving data harmonization for regulatory clinical trial guardrails. The pipeline approach to data management in clinical trials has led to siloed, disconnected data across an organization, because separate storage is used for each trial. Decentralized clinical trials, however, often employ a singular data lake for all of an organization’s clinical trials.
With a centralized data lake, organizations can avoid the duplication of data across separate trial databases. This leads to savings in storage costs and computing resources, as well as a reduction in the environmental impact of maintaining multiple data silos. To build a data management platform, the process could begin with ingesting and normalizing clinical trial data using AWS HealthLake. HealthLake is designed to ingest data from various sources, such as electronic health records, medical imaging, and laboratory results, and automatically transform the data into the industry-standard FHIR format. This clinical voice application solution built entirely on AWS showcases the advantages of having a centralized location for clinical data, such as avoiding data drift and redundant storage.
With the normalized data now available in HealthLake, the next step would be to orchestrate the various data processing and analysis workflows using AWS Step Functions. You can use Step Functions to coordinate the integration of the HealthLake data into a centralized data lake, as well as invoke subsequent processing and analysis tasks. This could involve using serverless computing with AWS Lambda to perform event-driven data transformation, quality checks, and enrichment activities. By combining the power powerful data normalization capabilities of HealthLake and the orchestration features of Step Functions, the platform can provide a robust, scalable, and streamlined approach to managing decentralized clinical trial data within the organization.
Conclusion
In this post, we discussed the critical importance of sustainability in clinical trials. We provided an overview of the key distinctions between traditional centralized clinical trials and decentralized clinical trials. Importantly, we explored how AWS technologies can enable the development of more sustainable clinical trials, addressing the four main pillars that underpin a successful decentralized trial approach.
To learn more about how AWS can power sustainable clinical trials for your organization, reach out to your AWS Account representatives. For more information about optimizing your workloads for sustainability, see Optimizing Deep Learning Workloads for Sustainability on AWS.
References
[1] https://www.appliedclinicaltrialsonline.com/view/awareness-of-clinical-research-increases-among-underrepresented-groups [2] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1839193/ [3] https://pubmed.ncbi.nlm.nih.gov/15474134/ [4] ClinicalTrials.gov and https://www.iqvia.com/insights/the-iqvia-institute/reports/the-global-use-of-medicines-2022 [5] https://aws.amazon.com/startups/learn/next-generation-data-management-for-clinical-trials-research-built-on-aws?lang=en-US#overview [6] https://pubmed.ncbi.nlm.nih.gov/39148198/About the Authors
 Sid Rampally is a Customer Solutions Manager at AWS driving GenAI acceleration for Life Sciences customers. He writes about topics relevant to his customers, focusing on data engineering and machine learning. In his spare time, Sid enjoys walking his dog in Central Park and playing hockey.
Sid Rampally is a Customer Solutions Manager at AWS driving GenAI acceleration for Life Sciences customers. He writes about topics relevant to his customers, focusing on data engineering and machine learning. In his spare time, Sid enjoys walking his dog in Central Park and playing hockey.
 Nina Chen is a Customer Solutions Manager at AWS specializing in leading software companies to leverage the power of the AWS cloud to accelerate their product innovation and growth. With over 4 years of experience working in the strategic Independent Software Vendor (ISV) vertical, Nina enjoys guiding ISV partners through their cloud transformation journeys, helping them optimize their cloud infrastructure, driving product innovation, and deliver exceptional customer experiences.
Nina Chen is a Customer Solutions Manager at AWS specializing in leading software companies to leverage the power of the AWS cloud to accelerate their product innovation and growth. With over 4 years of experience working in the strategic Independent Software Vendor (ISV) vertical, Nina enjoys guiding ISV partners through their cloud transformation journeys, helping them optimize their cloud infrastructure, driving product innovation, and deliver exceptional customer experiences.
Use Amazon Q to find answers on Google Drive in an enterprise
Amazon Q Business is a generative AI-powered assistant designed to enhance enterprise operations. It’s a fully managed service that helps provide accurate answers to users’ questions while adhering to the security and access restrictions of the content. You can tailor Amazon Q Business to your specific business needs by connecting to your company’s information and enterprise systems using built-in connectors to a variety of enterprise data sources. It enables users in various roles, such as marketing managers, project managers, and sales representatives, to have tailored conversations, solve business problems, generate content, take action, and more, through a web interface. This service aims to help make employees work smarter, move faster, and drive significant impact by providing immediate and relevant information to help them with their tasks.
One such enterprise data repository you can use to store and manage content is Google Drive. Google Drive is a cloud-based storage service that provides a centralized location for storing digital assets, including documents, knowledge articles, and spreadsheets. This service helps your teams collaborate effectively by enabling the sharing and organization of important files across the enterprise. To use Google Drive within Amazon Q Business, you can configure the Amazon Q Business Google Drive connector. This connector allows Amazon Q Business to securely index files stored in Google Drive using access control lists (ACLs). These ACLs make sure that users only access the documents they’re permitted to view, allowing them to ask questions and retrieve information relevant to their work directly through Amazon Q Business.
This post covers the steps to configure the Amazon Q Business Google Drive connector, including authentication setup and verifying the secure indexing of your Google Drive content.
Index Google Drive documents using the Amazon Q Google Drive connector
The Amazon Q Google Drive connector can index Google Drive documents hosted in a Google Workspace account. The connector can’t index documents stored on Google Drive in a personal Google Gmail account. Amazon Q Business can authenticate with your Google Workspace using a service account or OAuth 2.0 authentication. A service account enables indexing files for user accounts across an enterprise in a Google Workspace. Using OAuth 2.0 authentication allows for crawling and indexing files in a single Google Workspace account. This post shows you how to configure Amazon Q Business to authenticate using a Google service account.
Google prescribes that in order to index multiple users’ documents, the crawler must support the capability to authenticate with a service account with domain-wide delegation. This allows the connector to index the documents of all users in your drive and shared drives. Amazon Q Business connectors only crawl the documents that the Amazon Q Business application administrator specifies need to be crawled. Administrators can specify the paths to crawl, specific file name patterns, or types. Amazon Q Business doesn’t use customer data to train any models. All customer data is indexed only in the customer account. Also, Amazon Q Business Connectors will only index content specified by the administrator. It won’t index any content on its own without explicitly being configured to do so by the administrator of Amazon Q Business.
You can configure the Amazon Q Google Drive connector to crawl and index file types supported by Amazon Q Business. Google Write documents are exported as Microsoft Word and Google Sheet documents are exported as Microsoft Excel during the crawling phase.
Metadata
Every document has structural attributes—or metadata—attached to it. Document attributes can include information such as document title, document author, time created, time updated, and document type.
When you connect Amazon Q Business to a data source, it automatically maps specific data source document attributes to fields within an Amazon Q Business index. If a document attribute in your data source doesn’t have an attribute mapping already available, or if you want to map additional document attributes to index fields, you can use the custom field mappings to specify how a data source attribute maps to an Amazon Q Business index field. You can create field mappings by editing your data source after your application and retriever are created.
There are four default metadata attributes indexed for each Google Drive document: authors, source URL, creation date, and last update date. You can also select additional reserved data field mappings.
Amazon Q Business crawls Google Drive ACLs defined in a Google Workspace for document security. Google Workspace users and groups are mapped to the _user_id and _group_ids fields associated with the Amazon Q Business application in AWS IAM Identity Center. These user and group associations are persisted in the user store associated with the Amazon Q Business index created for crawled Google Drive documents.
Overview of ACLs in Amazon Q Business
In the context of knowledge management and generative AI chatbot applications, an ACL plays a crucial role in managing who can access information and what actions they can perform within the system. They also facilitate knowledge sharing within specific groups or teams while restricting access to others.
In this solution, we deploy an Amazon Q web experience to demonstrate that two business users can only ask questions about documents they have access to according to the ACL. With the Amazon Q Business Google Drive connector, the Google Workspace ACL will be ingested with documents. This enables Amazon Q Business to control the scope of documents that each user can access in the Amazon Q web experience.
Authentication types
An Amazon Q Business application requires you to use IAM Identity Center to manage user access. Although it’s recommended to have an IAM Identity Center instance configured (with users federated and groups added) before you start, you can also choose to create and configure an IAM Identity Center instance for your Amazon Q Business application using the Amazon Q console.
You can also add users to your IAM Identity Center instance from the Amazon Q Business console, if you aren’t federating identity. When you add a new user, make sure that the user is enabled in your IAM Identity Center instance and that they have verified their email ID. They need to complete these steps before they can log in to your Amazon Q Business web experience.
Your identity source in IAM Identity Center defines where your users and groups are managed. After you configure your identity source, you can look up users or groups to grant them single sign-on access to AWS accounts, applications, or both.
You can have only one identity source per organization in AWS Organizations. You can choose one of the following as your identity source:
- IAM Identity Center directory – When you enable IAM Identity Center for the first time, it’s automatically configured with an IAM Identity Center directory as your default identity source. This is where you create your users and groups, and assign their level of access to your AWS accounts and applications. For more details, see Manage identities in IAM Identity Center.
- Active Directory – Choose this option if you want to continue managing users in either your AWS Managed Microsoft AD directory using AWS Directory Service or your self- managed directory in Active Directory (AD).
- External identity provider – Choose this option if you want to manage users in other external identity providers (IdPs) through the SAML 2.0 standard, such as Okta.
- IAM identity provider – Amazon Q Business applications can now federate with an enterprise’s IAM IdP. For more information, refer to Build private and secure enterprise generative AI applications with Amazon Q Business using IAM Federation.
Overview of solution
With Amazon Q Business, you can configure multiple data sources to provide a central place to search across your document repository. For our solution, we demonstrate how to index Google Drive data using the Amazon Q Business Google Drive connector. We complete the following steps:
- Configure Google Workspace prerequisites.
- Configure an Amazon Q Business application.
- Connect Google Drive to Amazon Q Business.
- Create users and index the data in the Google Drive.
- Run a sample query to test the solution.
Configure Google Workspace prerequisites
For this solution, Amazon Q will connect to a Google Workspace and crawl Google Drive documents owned by business users in different groups using a service account. Complete the following steps to configure your Google Workspace:
- Log in to the Google API console as an admin user.
- Choose the dropdown menu next to the search box, then choose New Project.

- Enter the project name, choose the Google organization, and choose Create.

The Google Drive and Admin SDK APIs need to be enabled for Amazon Q to crawl Google Drive files.
- Search for each API on the Google Cloud console and choose Enable.

- Search for Service Accounts to access the IAM & Admin navigation pane and choose Create Service Account.
- Enter the service account name, service account ID, and description, and choose Done.

- Choose the email of the service account created in the previous step.
- On the Keys tab, choose Add Key, then choose Create New Key.
- For Key type, select JSON, and choose Create to download and locally save a new private key.

Now we enable domain-wide delegation for the five required API scopes on the Domain-wide Delegation page.
- Choose Add new.
- Add the following comma delimited API scopes for client ID generated for the private key created in the previous step:
https://www.googleapis.com/auth/drive.readonly,https://www.googleapis.com/auth/drive.metadata.readonly,https://www.googleapis.com/auth/admin.directory.group.readonly,https://www.googleapis.com/auth/admin.directory.user.readonly,https://www.googleapis.com/auth/cloud-platform - Choose Authorize.

Now we create users and add them to groups.
- Navigate to the Google Workspace Admin console and choose Users in the navigation pane.
- Choose Add new user to create two new business users.

- Choose Groups in the navigation pane.
- Choose Create group to create two Google groups and add one business user to each group.

- Upload files that Amazon Q supports into each business user’s Google Drive.
In this solution, we upload the Amazon 2020 annual report to the first business user’s Google Drive and upload the Amazon 2021 annual report and Amazon 2022 annual report to the second business user’s Google Drive.
The business user that uploaded the Amazon 2021 annual report can also share it with the other business user’s Google group.
- Choose the options menu (three vertical dots) for the Google Drive file and choose Share.
- Enter the name of the other Google group and choose Send.
Create an Amazon Q Business application with a Google Drive connector
An Amazon Q Business application needs to be created with a Google Drive connector to crawl and index Google Drive files. To create an Amazon Q application, complete the following steps:
- On the Amazon Q console, choose Applications in the navigation pane.
- Choose Create application.
- For Application name, enter a name.
- Leave application configuration settings as defaults.
- Choose Create.

- After the application is created, choose Data Sources.
- Then choose Select retriever and Confirm to use a Native retriever and Enterprise provisioning.

- After confirming retriever settings, choose Add data source, and then choose the plus sign next to Google Drive.

- Under Name and description, enter a data source name and optional description.
- Under Authentication, select Google service account and choose Create a new secret from the AWS Secrets Manager secret drop down to create an AWS Secrets Manager secret.

- Enter a secret name, admin account email, client email, and the JSON key you downloaded earlier, then choose Save.

- Under IAM role, choose Create a new service role.
- Under Additional Configuration, choose User email, and add the two recently created Google Workspace business user email addresses.

- Under Sync run schedule, for Frequency, choose Run on demand.
- Choose Add data source.

Create and manage users
To create an Amazon Q web experience accessible by Google Workspace users, you need to create corresponding users in IAM Identity Center. Amazon Q applications are only accessible by IAM Identity Center users with user identities that own indexed documents. To create the IAM Identity Center users, complete the following steps:
- On the IAM Identity Center console, choose Users in the navigation pane.
- Choose Add user.
- Create IAM Identity Center users that mirror your Google Workspace users by entering the required user information.

- Accept the IAM Identity Center invitation sent through email to each new business user and set each business user’s IAM Identity Center password.
- On the Amazon Q Business console, navigate to the application with the Google Drive data source.
- Choose Manage user access.
- Choose Add groups and users, select Assign existing users and groups, and choose Next.

- Assign users to the Amazon Q application, choose Assign, and choose Confirm if each business user is subscribed to Q Business Pro.

After you add IAM Identity Center users to your Amazon Q application, its web experience URL will appear in the Q Business applications list. You can use the URL to connect to the Amazon Q web experience with either of your Google business users. By default, each user can only ask questions about documents in their Google Drive.
Run sample queries in Amazon Q
To test the Amazon Q application with the Amazon annual reports you uploaded to Google Drive, complete the following steps:
- On the Amazon Q Business console, navigate to the data source you created.
- Run an on-demand sync of the data source by choosing Sync now.

- Navigate to the web experience URL in a new private browser window and log in as the first business user.

- Ask Amazon Q a question, such as how many employees work at Amazon.
The source documents should be the Amazon 2020 and 2021 annual reports, assuming the first business user uploaded the Amazon 2020 annual report and the second business user shared the Amazon 2021 annual report with the first business user.
- Navigate to the web experience URL in a new private browser window and log in as the second business user.
- Ask Amazon Q the same question (how many employees work at Amazon).
The source documents should be the Amazon 2021 and 2022 annual reports.
Troubleshooting
In this section, we share some common issues and troubleshooting tips.
IAM Identity Center login error
You might receive an error on the IAM Identity Center login page that says “We couldn’t verify your sign-in credentials.”
To troubleshoot, complete the following steps:
- Confirm that the business users that mirror the Google Workspace users were created in IAM Identity Center.
- If the users exist, navigate to the user in IAM Identity Center and choose Reset password, then select Generate a one-time password and share the password with the user.
A password will be provided for login and the user will be asked to change their password after a successful login.
Google Drive data source crawling or indexing failure
If the Google Drive data source crawling or indexing fails, complete the following steps:
- Confirm the business users provisioned in the Google Workspace are members of the Google groups.
- Inspect the Amazon CloudWatch logs for the last time the Google Drive data source was crawled for users with Google Drive files in the Google Workspace.
- If the crawler didn’t successfully log the indexing of an expected user’s files, check the IAM Identity Center users, then compare the attributes in the Secrets Manager secret to the corresponding Google Workspace attributes, including client ID, service account email, and service account private key.
- Use the Amazon Q Business document-level sync reports to confirm the intended Google Drive documents were indexed by Amazon Q.
Google Drive data source crawling and indexing job doesn’t crawl and index documents
If the Google Drive data source crawling and indexing job doesn’t crawl and index any documents, complete the following steps:
- Confirm the business users provisioned in the Google Workspace are members of the Google groups.
- Confirm there are IAM Identity Center users that mirror the Google Workspace users.
- Confirm both IAM Identity Center users subscribe to Q Business Pro.
- Confirm the Google Workspace admin user has enabled the Google Drive API.
Amazon Q web experience doesn’t return expected answers from the expected source
If the Amazon Q web experience doesn’t return expected answers from the expected source, complete the following steps:
- Upload the expected source document into an Amazon Q Business chat session by choosing the paperclip icon in the Amazon Q chat interface and then choosing the file.

After you upload the document into the session, if the expected answers are generated from the expected document, the document wasn’t successfully indexed from the Google Drive data source.
- If Amazon Q doesn’t return the expected answer for the uploaded document, modify the prompt used to ask the question.
Clean up
To prevent incurring additional costs, it’s essential to clean up and remove any resources created during the implementation of this solution. Specifically, you should delete the Amazon Q application, which will consequently remove the associated index and data connectors. However, any Secrets Manager secrets created during the Amazon Q application setup process need to be removed separately. Failing to clean up these resources may result in ongoing charges, so it’s crucial to take the necessary steps to completely remove all components related to this solution.
Complete the following steps to delete the Amazon Q application, secret, and IAM Identity Center users in your AWS account:
- On the Amazon Q Business console, choose Applications in the navigation pane.
- Select the application that you created and on the Actions menu, choose Delete and confirm the deletion.
- On the Secrets Manager console, choose Secrets in the navigation pane.
- Select the secret that was created for the Google Drive connector and on the Actions menu, choose Delete.
- Specify the waiting period as 7 days and choose Schedule deletion.
- On the IAM Identity Center console, choose Users in the navigation pane.
- Select the two users that you created and choose Delete users to remove these users.
Additionally, you should remove the business users added to your Google Workspace during the implementation of this solution because Google Workspaces costs are billed on a per-user basis.
Conclusion
In this post, you created an Amazon Q application that indexed Google Drive documents using the Google Drive connector. You were able to connect to the Amazon Q conversational interface as each of your business users and ask questions about the documents each user could access in accordance with the ACL.
You can continue to experiment by adding more PDF documents to your business users’ Google Drives and re-syncing your Amazon Q Google Drive data source.
Amazon Q Business offers other connectors, such as for Confluence Cloud. To learn more about the Amazon Q Business Confluence Cloud connector, refer to Connecting Confluence (Cloud) to Amazon Q Business.
About the Authors
 Glen Ireland is a Senior Enterprise Account Engineer at AWS in the Worldwide Public Sector. Glen’s areas of focus include empowering customers interested in building generative AI solutions using Amazon Q.
Glen Ireland is a Senior Enterprise Account Engineer at AWS in the Worldwide Public Sector. Glen’s areas of focus include empowering customers interested in building generative AI solutions using Amazon Q.
 Julia Hu is a Specialist Solutions Architect who helps AWS customers and partners build generative AI solutions using Amazon Q Business on AWS. Julia has over 4 years of experience developing solutions for customers adopting AWS services on the forefront of cloud technology.
Julia Hu is a Specialist Solutions Architect who helps AWS customers and partners build generative AI solutions using Amazon Q Business on AWS. Julia has over 4 years of experience developing solutions for customers adopting AWS services on the forefront of cloud technology.
How Druva used Amazon Bedrock to address foundation model complexity when building Dru, Druva’s backup AI copilot
This post is co-written with David Gildea and Tom Nijs from Druva.
Druva enables cyber, data, and operational resilience for thousands of enterprises, and is trusted by 60 of the Fortune 500. Customers use Druva Data Resiliency Cloud to simplify data protection, streamline data governance, and gain data visibility and insights. Independent software vendors (ISVs) like Druva are integrating AI assistants into their user applications to make software more accessible.
Dru, the Druva backup AI copilot, enables real-time interaction and personalized responses, with users engaging in a natural conversation with the software. From finding inconsistencies and errors across the environment to scheduling backup jobs and setting retention policies, users need only ask and Dru responds. Dru can also recommend actions to improve the environment, remedy backup failures, and identify opportunities to enhance security.
In this post, we show how Druva approached natural language querying (NLQ)—asking questions in English and getting tabular data as answers—using Amazon Bedrock, the challenges they faced, sample prompts, and key learnings.
Use case overview
The following screenshot illustrates the Dru conversation interface.

In a single conversation interface, Dru provides the following:
- Interactive reporting with real-time insights – Users can request data or customized reports without extensive searching or navigating through multiple screens. Dru also suggests follow-up questions to enhance user experience.
- Intelligent responses and a direct conduit to Druva’s documentation – Users can gain in-depth knowledge about product features and functionalities without manual searches or watching training videos. Dru also suggests resources for further learning.
- Assisted troubleshooting – Users can request summaries of top failure reasons and receive suggested corrective measures. Dru on the backend decodes log data, deciphers error codes, and invokes API calls to troubleshoot.
- Simplified admin operations, with increased seamlessness and accessibility – Users can perform tasks like creating a new backup policy or triggering a backup, managed by Druva’s existing role-based access control (RBAC) mechanism.
- Customized website navigation through conversational commands – Users can instruct Dru to navigate to specific website locations, eliminating the need for manual menu exploration. Dru also suggests follow-up actions to speed up task completion.
Challenges and key learnings
In this section, we discuss the challenges and key learnings of Druva’s journey.
Overall orchestration
Originally, we adopted an AI agent approach and relied on the foundation model (FM) to make plans and invoke tools using the reasoning and acting (ReAct) method to answer user questions. However, we found the objective too broad and complicated for the AI agent. The AI agent would take more than 60 seconds to plan and respond to a user question. Sometimes it would even get stuck in a thought-loop, and the overall success rate wasn’t satisfactory.
We decided to move to the prompt chaining approach using a directed acyclic graph (DAG). This approach allowed us to break the problem down into multiple steps:
- Identify the API route.
- Generate and invoke private API calls.
- Generate and run data transformation Python code.
Each step became an independent stream, so our engineers could iteratively develop and evaluate the performance and speed until they worked well in isolation. The workflow also became more controllable by defining proper error paths.
Stream 1: Identify the API route
Out of the hundreds of APIs that power Druva products, we needed to match the exact API the application needs to call to answer the user question. For example, “Show me my backup failures for the past 72 hours, grouped by server.” Having similar names and synonyms in API routes make this retrieval problem more complex.
Originally, we formulated this task as a retrieval problem. We tried different methods, including k-nearest neighbor (k-NN) search of vector embeddings, BM25 with synonyms, and a hybrid of both across fields including API routes, descriptions, and hypothetical questions. We found that the simplest and most accurate way was to formulate it as a classification task to the FM. We curated a small list of examples in question-API route pairs, which helped improve the accuracy and make the output format more consistent.
Stream 2: Generate and invoke private API calls
Next, we API call with the correct parameters and invoke it. FM hallucination of parameters, particularly those with free-form JSON object, is one of the major challenges in the whole workflow. For example, the unsupported key server can appear in the generated parameter:
We tried different prompting techniques, such as few-shot prompting and chain of thought (CoT), but the success rate was still unsatisfactory. To make API call generation and invocation more robust, we separated this task into two steps:
- First, we used an FM to generate parameters in a JSON dictionary instead of a full API request headers and body.
- Afterwards, we wrote a postprocessing function to remove parameters that didn’t conform to the API schema.
This method provided a successful API invocation, at the expense of getting more data than required for downstream processing.
Stream 3: Generate and run data transformation Python code
Next, we took the response from the API call and transformed it to answer the user question. For example, “Create a pandas dataframe and group it by server column.” Similar to stream 2, FM hallucination is again an obstacle. Generated code can contain syntax errors, such as confusing PySpark functions with Pandas functions.
After trying many different prompting techniques without success, we looked at the reflection pattern, asking the FM to self-correct code in a loop. This improved the success rate at the expense of more FM invocations, which were slower and more expensive. We found that although smaller models are faster and more cost-effective, at times they had inconsistent results. Anthropic’s Claude 2.1 on Amazon Bedrock gave more accurate results on the second try.
Model choices
Druva selected Amazon Bedrock for several compelling reasons, with security and latency being the most important. A key factor in this decision was the seamless integration with Druva’s services. Using Amazon Bedrock aligned naturally with Druva’s existing environment on AWS, maintaining a secure and efficient extension of their capabilities.
Additionally, one of our primary challenges in developing Dru involved selecting the optimal FMs for specific tasks. Amazon Bedrock effectively addresses this challenge with its extensive array of available FMs, each offering unique capabilities. This variety enabled Druva to conduct the rapid and comprehensive testing of various FMs and their parameters, facilitating the selection of the most suitable one. The process was streamlined because Druva didn’t need to delve into the complexities of running or managing these diverse FMs, thanks to the robust infrastructure provided by Amazon Bedrock.
Through the experiments, we found that different models performed better in specific tasks. For example, Meta Llama 2 performed better with code generation task; Anthropic Claude Instance was good in efficient and cost-effective conversation; whereas Anthropic Claude 2.1 was good in getting desired responses in retry flows.
These were the latest models from Anthropic and Meta at the time of this writing.
Solution overview
The following diagram shows how the three streams work together as a single workflow to answer user questions with tabular data.

The following are the steps of the workflow:
- The authenticated user submits a question to Dru, for example, “Show me my backup job failures for the last 72 hours,” as an API call.
- The request arrives at the microservice on our existing Amazon Elastic Container Service (Amazon ECS) cluster. This process consists of the following steps:
- A classification task using the FM provides the available API routes in the prompt and asks for the one that best matches with user question.
- An API parameters generation task using the FM gets the corresponding API swagger, then asks the FM to suggest key-value pairs to the API call that can retrieve data to answer the question.
- A custom Python function verifies, formats, and invokes the API call, then passes the data in JSON format to the next step.
- A Python code generation task using the FM samples a few records of data from the previous step, then asks the FM to write Python code to transform the data to answer the question.
- A custom Python function runs the Python code and returns the answer in tabular format.
To maintain user and system security, we make sure in our design that:
- The FM can’t directly connect to any Druva backend services.
- The FM resides in a separate AWS account and virtual private cloud (VPC) from the backend services.
- The FM can’t initiate actions independently.
- The FM can only respond to questions sent from Druva’s API.
- Normal customer permissions apply to the API calls made by Dru.
- The call to the API (Step 1) is only possible for authenticated user. The authentication component lives outside the Dru solution and is used across other internal solutions.
- To avoid prompt injection, jailbreaking, and other malicious activities, a separate module checks for these before the request reaches this service (Amazon API Gateway in Step 1).
For more details, refer to Druva’s Secret Sauce: Meet the Technology Behind Dru’s GenAI Magic.
Implementation details
In this section, we discuss Steps 2a–2e in the solution workflow.
2a. Look up the API definition
This step uses an FM to perform classification. It takes the user question and a full list of available API routes with meaningful names and descriptions as the input, and responds The following is a sample prompt:
2b. Generate the API call
This step uses an FM to generate API parameters. It first looks up the corresponding swagger for the API route (from Step 2a). Next, it passes the swagger and the user question to an FM and responds with some key-value pairs to the API route that can retrieve relevant data. The following is a sample prompt:
2c. Validate and invoke the API call
In the previous step, even with an attempt to ground responses with swagger, the FM can still hallucinate wrong or nonexistent API parameters. This step uses a programmatic way to verify, format, and invoke the API call to get data. The following is the pseudo code:
2d. Generate Python code to transform data
This step uses an FM to generate Python code. It first samples a few records of input data to reduce input tokens. Then it passes the sample data and the user question to an FM and responds with a Python script that transforms data to answer the question. The following is a sample prompt:
2e. Run the Python code
This step involves a Python script, which imports the generated Python package, runs the transformation, and returns the tabular data as the final response. If an error occurs, it will invoke the FM to try to correct the code. When everything fails, it returns the input data. The following is the pseudo code:
Conclusion
Using Amazon Bedrock for the solution foundation led to remarkable achievements in accuracy, as evidenced by the following metrics in our evaluations using an internal dataset:
- Stream 1: Identify the API route – Achieved a perfect accuracy rate of 100%
- Stream 2: Generate and invoke private API calls – Maintained this standard with a 100% accuracy rate
- Stream 3: Generate and run data transformation Python code – Attained a highly commendable accuracy of 90%
These results are not just numbers; they are a testament to the robustness and efficiency of the Amazon Bedrock based solution. With such high levels of accuracy, Druva is now poised to confidently broaden their horizons. Our next goal is to extend this solution to encompass a wider range of APIs across Druva products. The next expansion will be scaling up usage and substantially enrich the experience of Druva customers. By integrating more APIs, Druva will offer a more seamless, responsive, and contextual interaction with Druva products, further enhancing the value delivered to Druva users.
To learn more about Druva’s AI solutions, visit the Dru solution page, where you can see some of these capabilities in action through recorded demos. Visit the AWS Machine Learning blog to see how other customers are using Amazon Bedrock to solve their business problems.
About the Authors
 David Gildea is the VP of Product for Generative AI at Druva. With over 20 years of experience in cloud automation and emerging technologies, David has led transformative projects in data management and cloud infrastructure. As the founder and former CEO of CloudRanger, he pioneered innovative solutions to optimize cloud operations, later leading to its acquisition by Druva. Currently, David leads the Labs team in the Office of the CTO, spearheading R&D into generative AI initiatives across the organization, including projects like Dru Copilot, Dru Investigate, and Amazon Q. His expertise spans technical research, commercial planning, and product development, making him a prominent figure in the field of cloud technology and generative AI.
David Gildea is the VP of Product for Generative AI at Druva. With over 20 years of experience in cloud automation and emerging technologies, David has led transformative projects in data management and cloud infrastructure. As the founder and former CEO of CloudRanger, he pioneered innovative solutions to optimize cloud operations, later leading to its acquisition by Druva. Currently, David leads the Labs team in the Office of the CTO, spearheading R&D into generative AI initiatives across the organization, including projects like Dru Copilot, Dru Investigate, and Amazon Q. His expertise spans technical research, commercial planning, and product development, making him a prominent figure in the field of cloud technology and generative AI.
 Tom Nijs is an experienced backend and AI engineer at Druva, passionate about both learning and sharing knowledge. With a focus on optimizing systems and using AI, he’s dedicated to helping teams and developers bring innovative solutions to life.
Tom Nijs is an experienced backend and AI engineer at Druva, passionate about both learning and sharing knowledge. With a focus on optimizing systems and using AI, he’s dedicated to helping teams and developers bring innovative solutions to life.
 Corvus Lee is a Senior GenAI Labs Solutions Architect at AWS. He is passionate about designing and developing prototypes that use generative AI to solve customer problems. He also keeps up with the latest developments in generative AI and retrieval techniques by applying them to real-world scenarios.
Corvus Lee is a Senior GenAI Labs Solutions Architect at AWS. He is passionate about designing and developing prototypes that use generative AI to solve customer problems. He also keeps up with the latest developments in generative AI and retrieval techniques by applying them to real-world scenarios.
 Fahad Ahmed is a Senior Solutions Architect at AWS and assists financial services customers. He has over 17 years of experience building and designing software applications. He recently found a new passion of making AI services accessible to the masses.
Fahad Ahmed is a Senior Solutions Architect at AWS and assists financial services customers. He has over 17 years of experience building and designing software applications. He recently found a new passion of making AI services accessible to the masses.
Deep Dive on Cutlass Ping-Pong GEMM Kernel
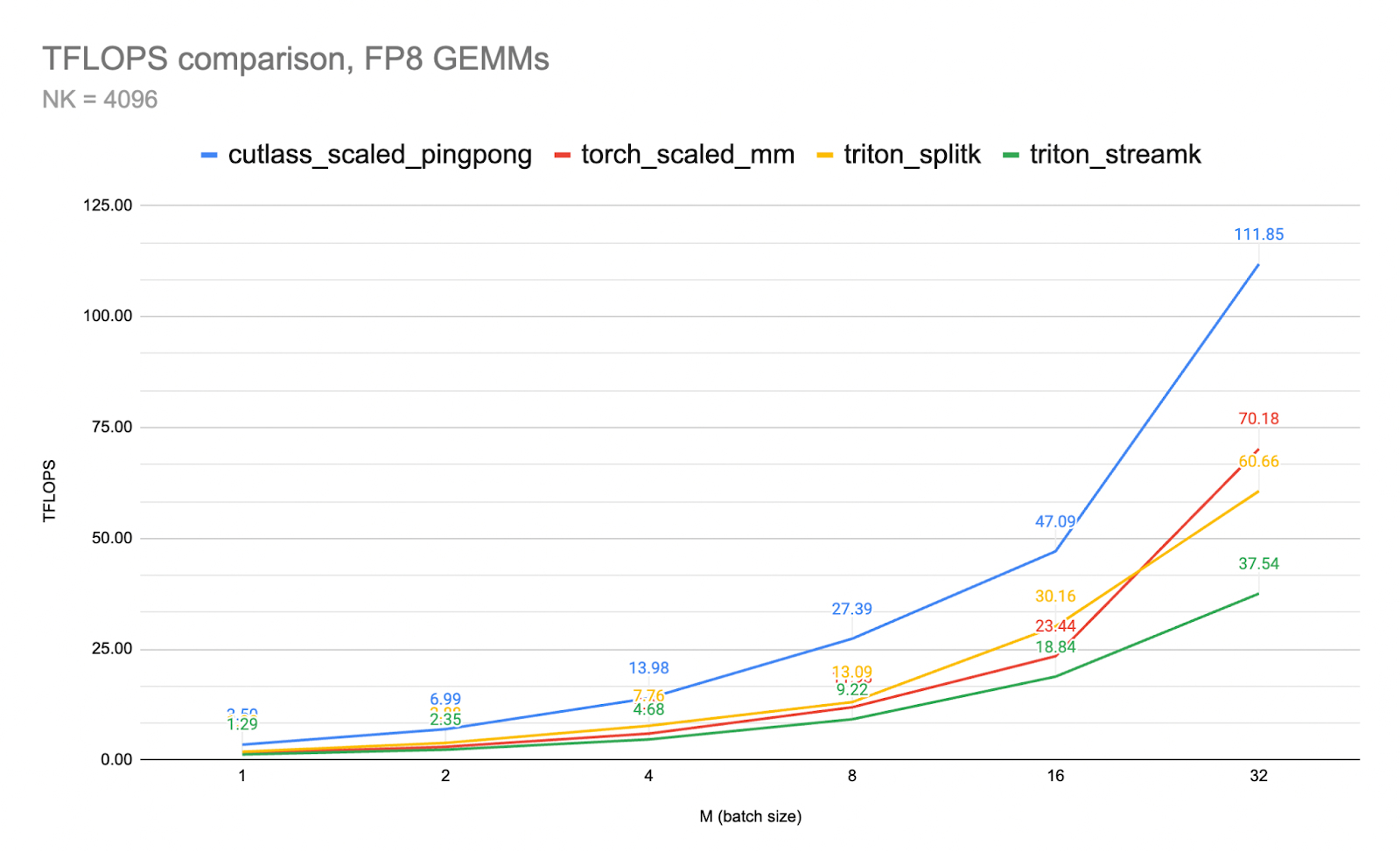
Figure 1. FP8 GEMM Throughput Comparison CUTLASS vs Triton
Summary
In this post, we provide an overview, with relevant FP8 inference kernel benchmarking, of the cutlass Ping-Pong GEMM kernel.
Ping-Pong is one of the fastest matmul (GEMM) kernel architectures available for the Hopper GPU architecture. Ping-Pong is a member of the Warp Group Specialized Persistent Kernels family, which includes both Cooperative and Ping-Pong variants. Relative to previous GPUs, Hopper’s substantial tensor core compute capability requires deep asynchronous software pipelining in order to achieve peak performance.
The Ping-Pong and Cooperative kernels exemplify this paradigm, as the key design patterns are persistent kernels to amortize launch and prologue overhead, and ‘async everything’ with specialized warp groups with two consumers and one producer, to create a highly overlapped processing pipeline that is able to continuously supply data to the tensor cores.
When the H100 (Hopper) GPU was launched, Nvidia billed it as the first truly asynchronous GPU. That statement highlights the need for H100 specific kernel architectures to also be asynchronous in order to fully maximize computational/GEMM throughput.
The pingpong GEMM, introduced in CUTLASS 3.x, exemplifies this by moving all aspects of the kernel to a ‘fully asynchronous’ processing paradigm. In this blog, we’ll showcase the core features of the ping-pong kernel design as well as showcase its performance on inference workloads vs cublas and triton split-k kernels.
Ping-Pong Kernel Design
Ping-Pong (or technically ‘sm90_gemm_tma_warpspecialized_pingpong’) operates with an asynchronous pipeline, leveraging warp specialization. Instead of the more classical homogeneous kernels, “warp groups” take on specialized roles. Note that a warp group consists of 4 warps of 32 threads each, or 128 total threads.
On earlier architectures, latency was usually hidden by running multiple thread blocks per SM. However, with Hopper, the Tensor Core throughput is so high that it necessitates moving to deeper pipelines. These deeper pipelines then hinder running multiple thread blocks per SM. Thus, persistent thread blocks now issue collective main loops across multiple tiles and multiple warp groups. Thread block clusters are allocated based on the total SM count.
For Ping-Pong, each warp group takes on a specialized role of either Data producer or Data consumer.
The producer warp group focuses on producing data movement to fill the shared memory buffers (via TMA). Two other warp groups are dedicated consumers that process the math (MMA) portion with tensor cores, and then do any follow up work and write their results back to global memory (epilogue).
Producer warp groups work with TMA (Tensor Memory Accelerator), and are deliberately kept as lightweight as possible. In fact, in Ping-Pong, they deliberately reduce their register resources to improve occupancy. Producers will reduce their max register counts by 40, vs consumers will increase their max register count by 232, an effect we can see in the cutlass source and corresponding SASS:

Unique to Ping-Pong, each consumer works on separate C output tiles. (For reference, the cooperative kernel is largely equivalent to Ping-Pong, but both consumer groups work on the same C output tile). Further, the two consumer warp groups then split their work between the main loop MMA and epilogue.
This is shown in the below image:
Figure 2: An overview of the Ping-Pong Kernel pipeline. Time moves left to right.
By having two consumers, it means that one can be using the tensor cores for MMA while the other performs the epilogue, and then vice-versa. This maximizes the ‘continuous usage’ of the tensor cores on each SM, and is a key part of the reason for the max throughput. The tensor cores can be continuously fed data to realize their (near) maximum compute capability. (See the bottom section of the Fig 2 illustration above).
Similar to how Producer threads stay focused only on data movements, MMA threads only issue MMA instructions in order to achieve peak issue rate. MMA threads must issue multiple MMA instructions and keep these in flight against TMA wait barriers.
An excerpt of the kernel code is shown below to cement the specialization aspects:
// Two types of warp group 'roles'
enum class WarpGroupRole {
Producer = 0,
Consumer0 = 1,
Consumer1 = 2
};
//warp group role assignment
auto warp_group_role = WarpGroupRole(canonical_warp_group_idx());
Data Movement with Producers and Tensor Memory Accelerator
The producer warps focus exclusively on data movement – specifically they are kept as lightweight as possible and in fact give up some of their register space to the consumer warps (keeping only 40 registers, while consumers will get 232). Their main task is issuing TMA (tensor memory accelerator) commands to move data from Global memory to shared memory as soon as a shared memory buffer is signaled as being empty.
To expand on TMA, or Tensor Memory Accelerator, TMA is a hardware component introduced with H100’s that asynchronously handles the transfer of memory from HBM (global memory) to shared memory. By having a dedicated hardware unit for memory movement, worker threads are freed to engage in other work rather than computing and managing data movement. TMA not only handles the movement of the data itself, but also calculates the required destination memory addresses, can apply any transforms (reductions, etc.) to the data and can handle layout transformations to deliver data to shared memory in a ‘swizzled’ pattern so that it’s ready for use without any bank conflicts. Finally, it can also multicast the same data if needed to other SM’s that are members of the same thread cluster. Once the data has been delivered, TMA will then signal the consumer of interest that the data is ready.
CUTLASS Asynchronous Pipeline Class
This signaling between producers and consumers is coordinated via the new Asynchronous Pipeline Class which Cutlass describes as follows:
“Implementing a persistent GEMM algorithm calls for managing dozens of different kinds of asynchronously executing operations that synchronize using multiple barriers organized as a circular list.
This complexity is too much for human programmers to manage by hand.
As a result, we have developed [Cutlass Pipeline Async Class]…”
Barriers and synchronization within the Ping-Pong async pipeline
Producers must ‘acquire’ a given smem buffer via ‘producer_acquire’. At the start, a pipeline is empty meaning that producer threads can immediately acquire the barrier and begin moving data.
PipelineState mainloop_pipe_producer_state = cutlass::make_producer_start_state<MainloopPipeline>();
Once the data movement is complete, producers issue the ‘producer_commit’ method to signal the consumer threads that data is ready.
However, for Ping-Pong, this is actually a noop instruction since TMA based producer’s barriers are automatically updated by the TMA when writes are completed.
consumer_wait – wait for data from producer threads (blocking).
consumer_release – signal waiting producer threads that they are finished consuming data from a given smem buffer. In other words, allow producers to go to work refilling this with new data.
From there, synchronization will begin in earnest where the producers will wait via the blocking producer acquire until they can acquire a lock, at which point their data movement work will repeat. This continues until the work is finished.
To provide a pseudo-code overview:
//producer
While (work_tile_info.is_valid_tile) {
collective_mainloop.dma() // fetch data with TMA
scheduler.advance_to_next_work()
Work_tile_info = scheduler.get_current_work()
}
// Consumer 1, Consumer 2
While (work_tile_info.is_valid_tile()) {
collective_mainloop.mma()
scheduler.advance_to_next_work()
Work_tile_info = scheduler.get_current_work()
}
And a visual birds-eye view putting it all together with the underlying hardware:
Figure 3: An overview of the full async pipeline for Ping-Pong
Step-by-Step Breakdown of Ping-Pong Computation Loop
Finally, a more detailed logical breakout of the Ping-Pong processing loop:
A – Producer (DMA) warp group acquires a lock on a shared memory buffer.
B – this allows it to kick off a tma cp_async.bulk request to the tma chip (via a single thread).
C – TMA computes the actual shared memory addressing required, and moves the data to shared memory. As part of this, swizzling is performed in order to layout the data in smem for the fastest (no bank conflict) access.
C1 – potentially, data can also be multicast to other SMs and/or it may need to wait for data from other tma multicast to complete the loading. (threadblock clusters now share shared memory across multiple SMs!)
D – At this point, the barrier is updated to signal the arrival of the data to smem.
E – The relevant consumer warpgroup now gets to work by issuing multiple wgmma.mma_async commands, which then read the data from smem to Tensor cores as part of it’s wgmma.mma_async matmul operation.
F – the MMA accumulator values are written to register memory as the tiles are completed.
G – the consumer warp group releases the barrier on the shared memory.
H – the producer warp groups go to work issuing the next tma instruction to refill the now free smem buffer.
I – The consumer warp group simultaneously applies any epilogue actions to the accumulator, and then move data from register to a different smem buffer.
J – The consumer warp issues a cp_async command to move data from smem to global memory.
The cycle repeats until the work is completed. Hopefully this provides you with a working understanding of the core concepts that power Ping-Pong’s impressive performance.
Microbenchmarks
To showcase some of Ping-Pong’s performance, below are some comparison charts related to our work on designing fast inference kernels.
First a general benchmarking of the three fastest kernels so far (lower is better):
Figure 4, above: Benchmark timings of FP8 GEMMs, lower is better (faster)
And translating that into a relative speedup chart of Ping-Pong vs cuBLAS and Triton:
Figure 5, above: Relative speedup of Ping-Pong vs the two closest kernels.
The full source code for the Ping-Pong kernel is here (619 lines of deeply templated Cutlass code, or to paraphrase the famous turtle meme – “it’s templates…all the way down! ):
In addition, we have implemented PingPong as a CPP extension to make it easy to integrate into use with PyTorch here (along with a simple test script showing it’s usage):
https://github.com/pytorch-labs/applied-ai/tree/main/kernels/cuda/cutlass_gemm
Future Work
Data movement is usually the biggest impediment to top performance for any kernel, and thus having an optimal strategy understanding of TMA (Tensor Memory Accelerator) on Hopper is vital. We previously published work on TMA usage in Triton. Once features like warp specialization are enabled in Triton, we plan to do another deep dive on how Triton kernels like FP8 GEMM and FlashAttention can leverage kernel designs like Ping-Pong for acceleration on Hopper GPUs.
On Device Llama 3.1 with Core ML
Many app developers are interested in building on device experiences that integrate increasingly capable large language models (LLMs). Running these models locally on Apple silicon enables developers to leverage the capabilities of the user’s device for cost-effective inference, without sending data to and from third party servers, which also helps protect user privacy. In order to do this, the models must be carefully optimized to effectively utilize the available system resources, because LLMs often have high demands for both memory and processing power.
This technical post details how to…Apple Machine Learning Research