In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information.
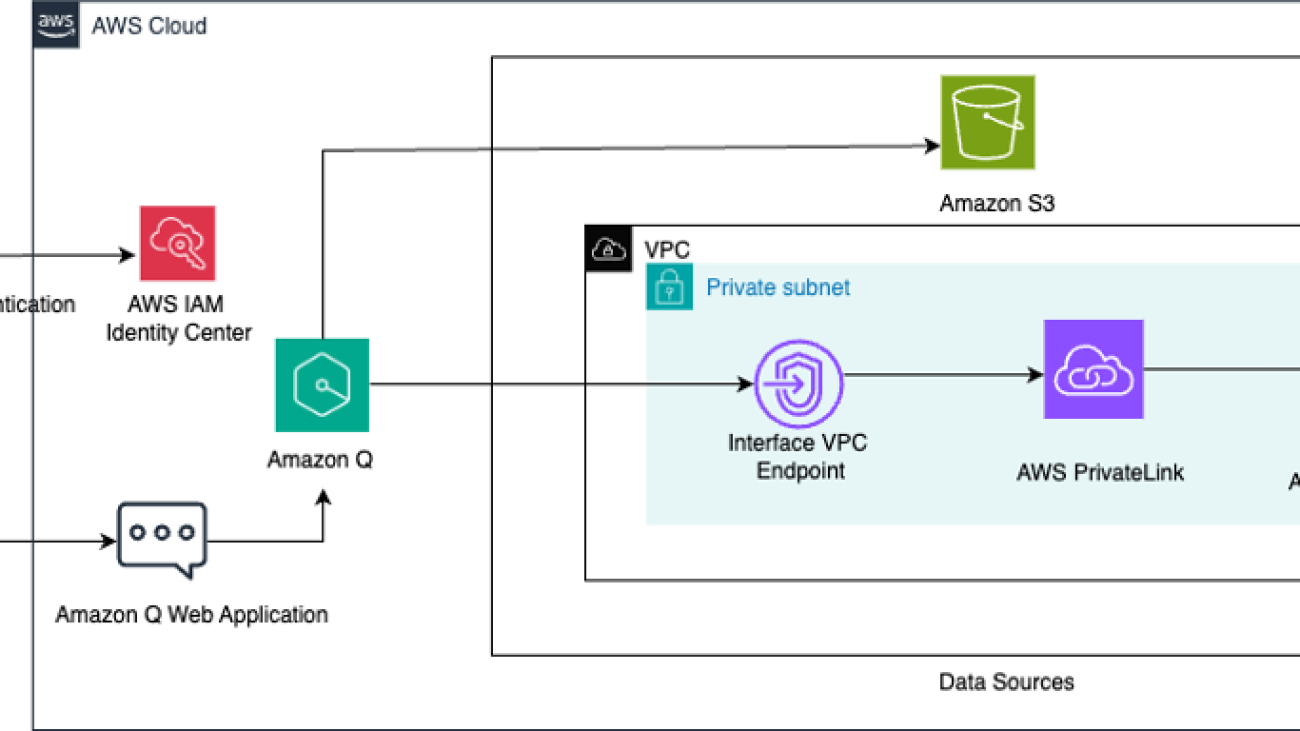
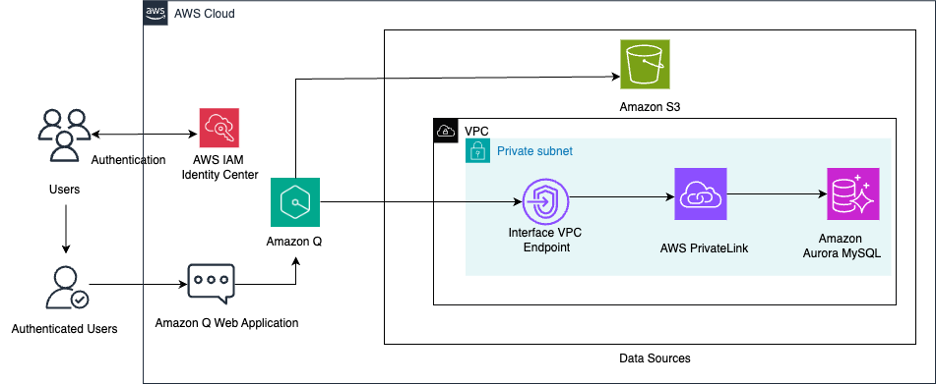
In this post, we explore how you can use Amazon Q Business, the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Solution overview
Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge. The key to using the full potential of Amazon Q lies in its ability to seamlessly integrate and query multiple data sources, from structured databases to unstructured content stores. In this solution, we use Amazon Q to build a comprehensive knowledge base that combines sales-related data from an Aurora MySQL database and sales documents stored in an S3 bucket. Aurora MySQL-Compatible is a fully managed, MySQL-compatible, relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance.
This custom knowledge base that connects these diverse data sources enables Amazon Q to seamlessly respond to a wide range of sales-related questions using the chat interface. The following diagram illustrates the solution architecture.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- A virtual private cloud (VPC) with at least two subnets
- An Aurora MySQL database
- An Amazon Elastic Compute Cloud (Amazon EC2) bastion host
- AWS IAM Identity Center configured
- An S3 bucket
Set up your VPC
Establishing a VPC provides a secure, isolated network environment for hosting the data sources that Amazon Q Business will access to index. In this post, we use an Aurora MySQL database in a private subnet, and Amazon Q Business accesses the private DB instance in a secure manner using an interface VPC endpoint.
Complete the following steps:
- Choose an AWS Region Amazon Q supports (for this post, we use the us-east-1 Region).
- Create a VPC or use an existing VPC with at least two subnets. These subnets must be in two different Availability Zones in the Region where you want to deploy your DB instance.
- Refer to Steps 1 and 2 in Configuring Amazon VPC support for Amazon Q Business connectors to configure your VPC so that you have a private subnet to host an Aurora MySQL database along with a security group for your database.
- Additionally, create a public subnet that will host an EC2 bastion server, which we create in the next steps.
- Create an interface VPC endpoint for Aurora powered by AWS PrivateLink in the VPC you created. For instructions, refer to Access an AWS service using an interface VPC endpoint.
- Specify the private subnet where the Aurora MySQL database resides along with the database security group you created.
Each interface endpoint is represented by one or more elastic network interfaces in your subnets, which is then used by Amazon Q Business to connect to the private database.
Set up an Aurora MySQL database
Complete the following steps to create an Aurora MySQL database to host the structured sales data:
- On the Amazon RDS console, choose Databases in the navigation pane.
- Choose Create database.
- Select Aurora, then Aurora (MySQL compatible).
- For Templates, choose Production or Dev/test.
- Under Settings, enter a name for your database cluster identifier. For example, q-aurora-mysql-source.
- For Credentials settings, choose Self-managed, give the admin user a password, and keep the rest of the parameters as default.
- Under Connectivity, for Virtual private cloud (VPC), choose the VPC that you created.
- For DB subnet group, create a new subnet group or choose an existing one. Keep the rest of the parameters as default.
- For Publicly accessible, choose NO.
- Under VPC security group (firewall), choose Existing and choose the existing security group that you created for the Aurora MySQL DB instance.
- Leave the remaining parameters as default and create the database.
Create an EC2 bastion host to connect to the private Aurora MySQL DB instance
In this post, you connect to the private DB instance from the MySQL Workbench client on your local machine through an EC2 bastion host. Launch the EC2 instance in the public subnet of the VPC you configured. The security group attached to this EC2 bastion host instance should be configured to allow SSH traffic (port 22) from your local machine’s IP address. To facilitate the connection between the EC2 bastion host and the Aurora MySQL database, the security group for the Aurora MySQL database should have an inbound rule to allow MySQL traffic (port 3306) from the security group of the EC2 bastion host. Conversely, the security group for the EC2 bastion host should have an outbound rule to allow traffic to the security group of the Aurora MySQL database on port 3306. Refer to Controlling access with security groups for more details.
Configure IAM Identity Center
An Amazon Q Business application requires you to use IAM Identity Center to manage user access. IAM Identity Center is a single place where you can assign your workforce users, also known as workforce identities, to provide consistent access to multiple AWS accounts and applications. In this post, we use IAM Identity Center as the SAML 2.0-aligned identity provider (IdP). Make sure you have enabled an IAM Identity Center instance, provisioned at least one user, and provided each user with a valid email address. The Amazon Q Business application needs to be in the same Region as the IAM Identity Center instance. For more information on enabling users in IAM Identity Center, see Add users to your Identity Center directory.
Create an S3 bucket
Create a S3 bucket in the us-east-1 Region with the default settings and create a folder with a name of your choice inside the bucket.
Create and load sample data
In this post, we use two sample datasets: a total sales dataset CSV file and a sales target document in PDF format. The total sales dataset contains information about orders placed by customers located in various geographical locations, through different sales channels. The sales document contains information about sales targets for the year for each of the sales channel. Complete the steps in the section below to load both datasets.
Aurora MySQL database
In the Amazon Q Business application, you create two indexes for the same Aurora MySQL table: one on the total sales dataset and another on an aggregated view of the total sales data, to cater to the different type of queries. Complete the following steps:
- Securely connect to your private Aurora MySQL database using an SSH tunnel through an EC2 bastion host.
This enables you to manage and interact with your database resources directly from your local MySQL Workbench client.
- Create the database and tables using the following commands on the local MySQL Workbench client:
- Download the sample file csv in your local environment.
- Use the following code to insert sample data in your MYSQL client:
If you encounter the error LOAD DATA LOCAL INFILE file request rejected due to restrictions on access when running the statements in MySQL Workbench 8.0, you might need to edit the connection. On the Connection tab, go to the Advanced sub-tab, and in the Others field, add the line OPT_LOCAL_INFILE=1 and start a new query tab after testing the connection.
- Verify the data load by running a select statement:
This should return 7,991 rows.
The following screenshot shows the database table schema and the sample data in the table.

Amazon S3 bucket
Download the sample file 2020_Sales_Target.pdf in your local environment and upload it to the S3 bucket you created. This sales target document contains information about the sales target for four sales channels and looks like the following screenshot.

Create an Amazon Q application
Complete the following steps to create an Amazon Q application:
- On the Amazon Q console, choose Applications in the navigation pane.
- Choose Create application.
- Provide the following details:
- In the Application details section, for Application name, enter a name for the application (for example,
sales_analyzer). - In the Service access section, for Choose a method to authorize Amazon Q, select Create and use a new service role.
- Leave all other default options and choose Create.
- In the Application details section, for Application name, enter a name for the application (for example,

- On the Select retriever page, you configure the retriever. The retriever is an index that will be used by Amazon Q to fetch data in real time.
- For Retrievers, select Use native retriever.
- For Index provisioning, select Starter.
- For Number of units, use the default value of 1. Each unit can support up to 20,000 documents. For a database, each database row is considered a document.
- Choose Next.

Configure Amazon Q to connect to Aurora MySQL-Compatible
Complete the following steps to configure Amazon Q to connect to Aurora MySQL-Compatible:
- On the Connect data sources page, under Data sources, choose the Aurora (MySQL) data source.
- Choose Next.

- In the Name and description section, configure the following parameters:
- For Data source name, enter a name (for example,
aurora_mysql_sales). - For Description, enter a description.
- For Data source name, enter a name (for example,
- In the Source section, configure the following parameters:
- For Host, enter the database endpoint (for example,
<databasename>.<ID>.<region>.rds.amazonaws.com).
- For Host, enter the database endpoint (for example,
You can obtain the endpoint on the Amazon RDS console for the instance on the Connectivity & security tab.
-
- For Port, enter the Amazon RDS port for MySQL:
3306. - For Instance, enter the database name (for example,
sales). - Select Enable SSL Certificate location.
- For Port, enter the Amazon RDS port for MySQL:

- For Authentication, choose Create a new secret with a name of your choice.
- Provide the user name and password for your MySQL database to create the secret.
- In the Configure VPC and security group section, choose the VPC and subnets where your Aurora MySQL database is located, and choose the default VPC security group.

- For IAM role, choose Create a new service role.
- For Sync scope, under SQL query, enter the following query:
This select statement returns a primary key column, a document title column, and a text column that serves your document body for Amazon Q to answer questions. Make sure you don’t put ; at the end of the query.
- For Primary key column, enter
order_number. - For Title column, enter
sales_channel. - For Body column, enter
sales_details.

- Under Sync run schedule, for Frequency, choose Run on demand.
- Keep all other parameters as default and choose Add data source.

This process may take a few minutes to complete. After the aurora_mysql_sales data source is added, you will be redirected to the Connect data sources page.
- Repeat the steps to add another Aurora MySQL data source, called
aggregated_sales, for the same database but with the following details in the Sync scope This data source will be used by Amazon Q for answering questions on aggregated sales.- Use the following SQL query:
-
- For Primary key column, enter
scoy_id. - For Title column, enter
sales_channel. - For Body column, enter
sales_aggregates.
- For Primary key column, enter

After adding the aggregated_sales data source, you will be redirected to the Connect data sources page again.
Configure Amazon Q to connect to Amazon S3
Complete the following steps to configure Amazon Q to connect to Amazon S3:
- On the Connect data sources page, under Data sources, choose Amazon S3.
- Under Name and description, enter a data source name (for example,
s3_sales_targets) and a description. - Under Configure VPC and security group settings, choose No VPC.

- For IAM role, choose Create a new service role.
- Under Sync scope, for the data source location, enter the S3 bucket name containing the sales target PDF document.
- Leave all other parameters as default.

- Under Sync run schedule, for Frequency, choose Run on demand.
- Choose Add data source.

- On the Connect data sources page, choose Next.
- In the Update groups and users section, choose Add users and groups.
- Choose the user as entered in IAM Identity Center and choose Assign.

- After you add the user, you can choose the Amazon Q Business subscription to assign to the user. For this post, we choose Q Business Lite.
- Under Web experience service access, select Create and use a new service role and enter a service role name.
- Choose Create application.

After few minutes, the application will be created and you will be taken to the Applications page on the Amazon Q Business console.

Sync the data sources
Choose the name of your application and navigate to the Data sources section. For each of the three data sources, select the data source and choose Sync now. It will take several minutes to complete. After the sources have synced, you should see the Last sync status show as Completed.

Customize and interact with the Amazon Q application
At this point, you have created an Amazon Q application, synced the data source, and deployed the web experience. You can customize your web experience to make it more intuitive to your application users.
- On the application details page, choose Customize web experience.

- For this post, we have customized the Title, Subtitle and Welcome message fields for our assistant.

- After you have completed your customizations for the web experience, go back to the application details page and choose the web experience URL.
- Sign in with the IAM Identity Center user name and password you created earlier to start the conversation with assistant.

You can now test the application by asking different questions, as shown in the following screenshot. You can observe in the following question that the channel names were fetched from the Amazon S3 sales target PDF.

The following screenshots show more example interactions.



The answer in the preceding example was derived from the two sources: the S3 bucket and the Aurora database. You can verify the output by cross-referencing the PDF, which has a target as $12 million for the in-store sales channel in 2020. The following SQL shows the actual sales achieved in 2020 for the same channel:

As seen from the sales target PDF data, the 2020 sales target for the distributor sales channel was $7 million.

The following SQL in the Aurora MySQL database shows the actual sales achieved in 2020 for the same channel:

The following screenshots show additional questions.



You can verify the preceding answers with the following SQL:

Clean up
To avoid incurring future charges, clean up any resources you created as part of this solution, including the Amazon Q Business application:
- On the Amazon Q Business console, choose Applications in the navigation pane, select the application you created, and on the Actions menu, choose Delete.
- Delete the AWS Identity and Access Management (IAM) roles created for the application and data retriever. You can identify the IAM roles used by the Amazon Q Business application and data retriever by inspecting the associated configuration using the AWS console or AWS Command Line Interface (AWS CLI).
- Delete the IAM Identity Center instance you created for this walkthrough.
- Empty the bucket you created and then delete the bucket.
- Delete the Aurora MySQL instance and Aurora cluster.
- Shut down the EC2 bastion host instance.
- Delete the VPC and related components—the NAT gateway and interface VPC endpoint.
Conclusion
In this post, we demonstrated how organizations can use Amazon Q to build a unified knowledge base that integrates structured data from an Aurora MySQL database and unstructured data from an S3 bucket. By connecting these disparate data sources, Amazon Q enables you to seamlessly query information from two data sources and gain valuable insights that drive better decision-making.
We encourage you to try this solution and share your experience in the comments. Additionally, you can explore the many other data sources that Amazon Q for Business can seamlessly integrate with, empowering you to build robust and insightful applications.
About the Authors
 Monjumi Sarma is a Technical Account Manager at Amazon Web Services. She helps customers architect modern, scalable, and cost-effective solutions on AWS, which gives them an accelerated path towards modernization initiatives. She has experience across analytics, big data, ETL, cloud operations, and cloud infrastructure management.
Monjumi Sarma is a Technical Account Manager at Amazon Web Services. She helps customers architect modern, scalable, and cost-effective solutions on AWS, which gives them an accelerated path towards modernization initiatives. She has experience across analytics, big data, ETL, cloud operations, and cloud infrastructure management.
 Akchhaya Sharma is a Sr. Data Engineer at Amazon Ads. He builds and manages data-driven solutions for recommendation systems, working together with a diverse and talented team of scientists, engineers, and product managers. He has experience across analytics, big data, and ETL.
Akchhaya Sharma is a Sr. Data Engineer at Amazon Ads. He builds and manages data-driven solutions for recommendation systems, working together with a diverse and talented team of scientists, engineers, and product managers. He has experience across analytics, big data, and ETL.

 Darrin Weber is a Senior Solutions Architect at AWS, helping customers realize their cloud journey with secure, scalable, and innovative AWS solutions. He brings over 25 years of experience in architecture, application design and development, digital transformation, and the Internet of Things. When Darrin isn’t transforming and optimizing businesses with innovative cloud solutions, he’s hiking or playing pickleball.
Darrin Weber is a Senior Solutions Architect at AWS, helping customers realize their cloud journey with secure, scalable, and innovative AWS solutions. He brings over 25 years of experience in architecture, application design and development, digital transformation, and the Internet of Things. When Darrin isn’t transforming and optimizing businesses with innovative cloud solutions, he’s hiking or playing pickleball. Marc Luescher is a Senior Solutions Architect at AWS, helping enterprise customers be successful, focusing strongly on threat detection, incident response, and data protection. His background is in networking, security, and observability. Previously, he worked in technical architecture and security hands-on positions within the healthcare sector as an AWS customer. Outside of work, Marc enjoys his 3 dogs, 4 cats, and over 20 chickens, and practices his skills in cabinet making and woodworking.
Marc Luescher is a Senior Solutions Architect at AWS, helping enterprise customers be successful, focusing strongly on threat detection, incident response, and data protection. His background is in networking, security, and observability. Previously, he worked in technical architecture and security hands-on positions within the healthcare sector as an AWS customer. Outside of work, Marc enjoys his 3 dogs, 4 cats, and over 20 chickens, and practices his skills in cabinet making and woodworking. Matt Richards is a Senior Solutions Architect at AWS, assisting customers in the retail industry. Having formerly been an AWS customer himself with a background in software engineering and solutions architecture, he now focuses on helping other customers in their application modernization and digital transformation journeys. Outside of work, Matt has a passion for music, singing, and drumming in several groups.
Matt Richards is a Senior Solutions Architect at AWS, assisting customers in the retail industry. Having formerly been an AWS customer himself with a background in software engineering and solutions architecture, he now focuses on helping other customers in their application modernization and digital transformation journeys. Outside of work, Matt has a passion for music, singing, and drumming in several groups.

 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach. Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in machine learning and natural language processing, Ishan specializes in developing safe and responsible AI systems that drive business value. Outside of work, he enjoys playing competitive volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in machine learning and natural language processing, Ishan specializes in developing safe and responsible AI systems that drive business value. Outside of work, he enjoys playing competitive volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.

 Lawrence Zorio III serves as the Chief Information Security Officer at Mark43, where he leads a team of cybersecurity professionals dedicated to safeguarding the confidentiality, integrity, and availability (CIA) of enterprise and customer data, assets, networks, and products. His leadership ensures Mark43’s security strategy aligns with the unique requirements of public safety agencies worldwide. With over 20 years of global cybersecurity experience across the Public Safety, Finance, Healthcare, and Technology sectors, Zorio is a recognized leader in the field. He chairs the Integrated Justice Information System (IJIS) Cybersecurity Working Group, where he helps develop standards, best practices, and recommendations aimed at strengthening cybersecurity defenses against rising cyber threats. Zorio also serves as an advisor to universities and emerging technology firms. Zorio holds a Bachelor of Science in Business Information Systems from the University of Massachusetts Dartmouth and a Master of Science in Innovation from Northeastern University’s D’Amore-McKim School of Business. He has been featured in various news publications, authored multiple security-focused white papers, and is a frequent speaker at industry events.
Lawrence Zorio III serves as the Chief Information Security Officer at Mark43, where he leads a team of cybersecurity professionals dedicated to safeguarding the confidentiality, integrity, and availability (CIA) of enterprise and customer data, assets, networks, and products. His leadership ensures Mark43’s security strategy aligns with the unique requirements of public safety agencies worldwide. With over 20 years of global cybersecurity experience across the Public Safety, Finance, Healthcare, and Technology sectors, Zorio is a recognized leader in the field. He chairs the Integrated Justice Information System (IJIS) Cybersecurity Working Group, where he helps develop standards, best practices, and recommendations aimed at strengthening cybersecurity defenses against rising cyber threats. Zorio also serves as an advisor to universities and emerging technology firms. Zorio holds a Bachelor of Science in Business Information Systems from the University of Massachusetts Dartmouth and a Master of Science in Innovation from Northeastern University’s D’Amore-McKim School of Business. He has been featured in various news publications, authored multiple security-focused white papers, and is a frequent speaker at industry events. Ritesh Shah is a Senior Generative AI Specialist at AWS. He partners with customers like Mark43 to drive AI adoption, resulting in millions of dollars in top and bottom line impact for these customers. Outside work, Ritesh tries to be a dad to his AWSome daughter. Connect with him on
Ritesh Shah is a Senior Generative AI Specialist at AWS. He partners with customers like Mark43 to drive AI adoption, resulting in millions of dollars in top and bottom line impact for these customers. Outside work, Ritesh tries to be a dad to his AWSome daughter. Connect with him on  Prajwal Shetty is a GovTech Solutions Architect at AWS and collaborates with Justice and Public Safety (JPS) customers like Mark43. He designs purpose-driven solutions that foster an efficient and secure society, enabling organizations to better serve their communities through innovative technology. Connect with him on
Prajwal Shetty is a GovTech Solutions Architect at AWS and collaborates with Justice and Public Safety (JPS) customers like Mark43. He designs purpose-driven solutions that foster an efficient and secure society, enabling organizations to better serve their communities through innovative technology. Connect with him on  Garrett Kopeski is an Enterprise GovTech Senior Account Manager at AWS responsible for the business relationship with Justice and Public Safety partners such as Mark43. Garrett collaborates with his customers’ Executive Leadership Teams to connect their business objectives with AWS powered initiatives and projects. Outside work, Garrett pursues physical fitness challenges when he’s not chasing his energetic 2-year-old son. Connect with him on
Garrett Kopeski is an Enterprise GovTech Senior Account Manager at AWS responsible for the business relationship with Justice and Public Safety partners such as Mark43. Garrett collaborates with his customers’ Executive Leadership Teams to connect their business objectives with AWS powered initiatives and projects. Outside work, Garrett pursues physical fitness challenges when he’s not chasing his energetic 2-year-old son. Connect with him on  Bobby Williams is a Senior Solutions Architect at AWS. He has decades of experience designing, building, and supporting enterprise software solutions that scale globally. He works on solutions across industry verticals and horizontals and is driven to create a delightful experience for every customer.
Bobby Williams is a Senior Solutions Architect at AWS. He has decades of experience designing, building, and supporting enterprise software solutions that scale globally. He works on solutions across industry verticals and horizontals and is driven to create a delightful experience for every customer.



 Romil Shah is a Sr. Data Scientist at AWS Professional Services. Romil has more than 8 years of industry experience in computer vision, machine learning, generative AI, and IoT edge devices. He works with customers, helping in training, optimizing and deploying foundation models for edge devices and on the cloud.
Romil Shah is a Sr. Data Scientist at AWS Professional Services. Romil has more than 8 years of industry experience in computer vision, machine learning, generative AI, and IoT edge devices. He works with customers, helping in training, optimizing and deploying foundation models for edge devices and on the cloud. Mike Garrison is a Global Solutions Architect based in Ypsilanti, Michigan. Utilizing his twenty years of experience, he helps accelerate tech transformation of automotive companies. In his free time, he enjoys playing video games and travel.
Mike Garrison is a Global Solutions Architect based in Ypsilanti, Michigan. Utilizing his twenty years of experience, he helps accelerate tech transformation of automotive companies. In his free time, he enjoys playing video games and travel.

 Google is releasing a report on music AI technology insights from co-creation sessions with artists, musicians and producers.
Google is releasing a report on music AI technology insights from co-creation sessions with artists, musicians and producers.
 Whether you need help perfecting a presentation or practising a tough talk with your boss, here’s how Gemini Live can step in to help.
Whether you need help perfecting a presentation or practising a tough talk with your boss, here’s how Gemini Live can step in to help.