We study private stochastic convex optimization (SCO) under user-level differential privacy (DP) constraints. In this setting, there are nnn users, each possessing mmm data items, and we need to protect the privacy of each user’s entire collection of data items. Existing algorithms for user-level DP SCO are impractical in many large-scale machine learning scenarios because: (i) they make restrictive assumptions on the smoothness parameter of the loss function and require the number of users to grow polynomially with the dimension of the parameter space; or (ii) they are prohibitively slow…Apple Machine Learning Research
Private Stochastic Convex Optimization with Heavy Tails: Near-Optimality from Simple Reductions
We study the problem of differentially private stochastic convex optimization (DP-SCO) with heavy-tailed gradients, where we assume a kthk^{text{th}}kth-moment bound on the Lipschitz constants of sample functions, rather than a uniform bound. We propose a new reduction-based approach that enables us to obtain the first optimal rates (up to logarithmic factors) in the heavy-tailed setting, achieving error G2⋅1n+Gk⋅(dnε)1−1kG_2 cdot frac 1 {sqrt n} + G_k cdot (frac{sqrt d}{nvarepsilon})^{1 – frac 1 k}G2⋅n1+Gk⋅(nεd)1−k1 under (ε,δ)(varepsilon, delta)(ε,δ)-approximate…Apple Machine Learning Research
Private Online Learning via Lazy Algorithms
We study the problem of private online learning, specifically, online prediction from experts (OPE) and online convex optimization (OCO). We propose a new transformation that transforms lazy online learning algorithms into private algorithms. We apply our transformation for differentially private OPE and OCO using existing lazy algorithms for these problems. Our final algorithms obtain regret which significantly improves the regret in the high privacy regime ε≪1varepsilon ll 1ε≪1, obtaining Tlogd+T1/3log(d)/ε2/3sqrt{T log d} + T^{1/3} log(d)/varepsilon^{2/3}Tlogd+T1/3log(d)/ε2/3 for…Apple Machine Learning Research
Do LLMs Estimate Uncertainty Well in Instruction-Following?
This paper was accepted at the Safe Generative AI Workshop (SGAIW) at NeurIPS 2024.
Large language models (LLMs) could be valuable personal AI agents across various domains, provided they can precisely follow user instructions. However, recent studies have shown significant limitations in LLMs’ instruction-following capabilities, raising concerns about their reliability in high-stakes applications. Accurately estimating LLMs’ uncertainty in adhering to instructions is critical to mitigating deployment risks. We present, to our knowledge, the first systematic evaluation of uncertainty…Apple Machine Learning Research

Racing into the future: How AWS DeepRacer fueled my AI and ML journey
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer—a fully autonomous 1/18th scale race car driven by reinforcement learning. At the time, I knew little about AI or machine learning (ML). As an engineer transitioning from legacy networks to cloud technologies, I had never considered myself a developer. But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML.

The AWS DeepRacer League was also announced, featuring physical races at AWS Summits worldwide in 2019 and a virtual league in a simulated environment. Winners would qualify to compete for the grand champion title in Las Vegas the following year. For 2018, because AWS DeepRacer had just been unveiled, re:Invent attendees could compete in person at the MGM Grand using pre-trained models.
My colleagues and I from JigsawXYZ immediately headed to the MGM Grand after the keynote. Despite long queues, we persevered, observing others racing while we waited. Participants answered questions about driving preferences to select a pre-trained model. Unlike later competitions, racers had to physically follow the car and place it back on track when it veered off.
We noticed that the AWS-provided models were unstable and slow by today’s standards, frequently going off-track. We concluded that quickly replacing the car on the track could result in a good lap time. Using this strategy, we secured second place on the leaderboard.
The night before the finals, we learned that we had qualified because of a dropout. Panic set in as we realized we would be competing on stage in front of thousands of people while knowing little about ML. We frantically tried to train a model overnight to avoid embarrassment.
The next morning, we found ourselves in the front row of the main auditorium, next to Andy Jassy. Our boss, Rick Fish, represented our team. After an energetic introduction from Indycar commentator Ryan Myrehn, Rick set a lap time of 51.50 seconds, securing the 2018 AWS DeepRacer grand champion title!

Image 2 – Rick Fish accepting the AWS DeepRacer trophy from Matt Wood
2019: Building a community and diving deeper
Back in London, interest in AWS DeepRacer exploded. We spoke at multiple events, including hosting our own An evening with DeepRacer gathering. As the 2019 season approached, I needed to earn my own finals spot. I began training models in the AWS DeepRacer console and experimenting with the physical car, including remote control and first-person view projects.
At the 2019 London AWS Summit, I won the AWS DeepRacer Championship with a lap time of 8.9 seconds, a significant improvement from the previous year. This event also sparked the creation of the AWS DeepRacer Community, which has since grown to over 45,000 members.
My interest in understanding the inner workings of AWS DeepRacer grew. I contributed to open source projects that allowed running the training stack locally, diving deep into AWS services such as Amazon SageMaker and AWS RoboMaker. These efforts led to my nomination as an AWS Community Builder.
Working on community projects improved my skills in Python, Jupyter, numpy, pandas, and ROS. These experiences proved invaluable when I joined Unitary, an AI startup focused on reducing harmful online content. Within a year, we built a world-class inference platform processing over 2 billion video frames daily using dynamically scaled Amazon Elastic Kubernetes Service (Amazon EKS) clusters.

Image 3 – Unitary at the AWS London Summit showcasing dynamically scaled inference using 1000+ EKS nodes
2020-2023: Virtual racing and continued growth
The COVID-19 pandemic shifted AWS DeepRacer competitions online for 2020 and 2021. Despite this, exciting events like the AWS DeepRacer F1 Pro-Am kept the community engaged. The introduction of the AWS DeepRacer Evo, with stereo cameras and a lidar detector, marked a significant hardware upgrade.
In-person racing returned in 2022, and I set a new world record at the London Summit. While I didn’t win the finals that year, the experience of competing and connecting with fellow racers remained invaluable.

Images 4 & 5 – the author hoists the trophy from the 2022 London Summit (left) DeepRacer Community members and Pit Crew hosting a AWS DeepRacer workshop at re:Invent 2023 (right)
2023 brought more intense competition. Although I set another world record in London, it wasn’t enough for first place. I eventually secured a finals spot by winning a virtual league round for Europe. While my performance in the finals didn’t improve on previous results, the opportunity to reconnect with the AWS DeepRacer community was rewarding.
Conclusion: The lasting impact of AWS DeepRacer
Over the past six years, AWS DeepRacer has profoundly impacted my professional and personal life. It has helped me develop a strong foundation in AI and ML, improve my coding skills, and build a network of friends and professional contacts in the tech industry. The experience gained through AWS DeepRacer directly contributed to my success at Unitary, where we’ve achieved recognition as a top UK startup.
As the official AWS DeepRacer league comes to an end, I’m excited to see what the community will achieve next. This journey has shaped my career and life in ways I never expected when I first saw that small autonomous car on stage in 2018.
For those interested in starting their own AI and ML journey, I encourage you to explore the AWS DeepRacer resources available on the AWS website. You can also join the thriving community on Discord to connect with other enthusiasts and learn from their experiences.
About the author
Matt Camp is an AI and ML enthusiast who has been involved with AWS DeepRacer since its inception. He is currently working at Unitary, applying his skills to develop cutting-edge content moderation technology. Matt is an AWS Community Builder and continues to contribute to open source projects in the AWS DeepRacer community.

Your guide to generative AI and ML at AWS re:Invent 2024
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. As you continue to innovate and partner with us to advance the field of generative AI, we’ve curated a diverse range of sessions to support you at every stage of your journey. These sessions are strategically organized across multiple learning topics, so there’s something valuable for everyone, regardless of your experience level.
In this attendee guide, we’re highlighting a few of our favorite sessions to give you a glimpse into what’s in store. As you browse the re:Invent catalog, select your learning topic and use the “Generative AI” area of interest tag to find the sessions most relevant to you.
The technical sessions covering generative AI are divided into six areas: First, we’ll spotlight Amazon Q, the generative AI-powered assistant transforming software development and enterprise data utilization. These sessions, featuring Amazon Q Business, Amazon Q Developer, Amazon Q in QuickSight, and Amazon Q Connect, span the AI/ML, DevOps and Developer Productivity, Analytics, and Business Applications topics. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations. You will also explore AWS App Studio, a generative AI-powered service that empowers a new set of builders to rapidly create enterprise-grade applications using natural language, generating intelligent, secure, and scalable apps in minutes. Second, we’ll delve into Amazon Bedrock, our fully managed service for building generative AI applications. Learn how you can use leading foundation models (FMs) from industry leaders and Amazon to build and scale your generative AI applications, and understand customization techniques like fine-tuning and Retrieval Augmented Generation (RAG). We’ll cover Amazon Bedrock Agents, capable of running complex tasks using your company’s systems and data. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker, AWS Trainium, and AWS Inferentia under AI/ML, as well as Compute topics. Discover how the fully managed infrastructure of SageMaker enables high-performance, low cost ML throughout the ML lifecycle, from building and training to deploying and managing models at scale. Fourth, we’ll address responsible AI, so you can build generative AI applications with responsible and transparent practices. Fifth, we’ll showcase various generative AI use cases across industries. And finally, get ready for the AWS DeepRacer League as it takes it final celebratory lap. You don’t want to miss this moment in AWS DeepRacer history, where racers will go head-to-head one last time to become the final champion. Off the race track, we will have dedicated sessions designed to help you continue your learning journey and apply your skills to the rapidly growing field of generative AI.
Visit the Generative AI Zone (GAIZ) at AWS Village in the Venetian Expo Hall to explore hands-on experiences with our newest launches and connect with our generative AI and ML specialists. Through a series of immersive exhibits, you can gain insights into AWS infrastructure for generative AI, learn about building and scaling generative AI applications, and discover how AI assistants are driving business transformation and modernization. As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production. Experience an immersive selection of innovative generative AI exhibits at the Generative AI and Innovations Pavilion through interactive displays spanning the AWS generative AI stack. Additionally, you can deep-dive into your industry-specific generative AI and ML use cases with our industry experts at the AWS Industries Pavilion.
If you’re new to re:Invent, you can attend sessions of the following types:
- Keynotes – Join in person or virtually and learn about all the exciting announcements.
- Innovation talks – Learn about the latest cloud technology from AWS technology leaders and discover how these advancements can help you push your business forward. These sessions will be livestreamed, recorded, and published to YouTube.
- Breakout sessions – These 60-minute sessions are expected to have broad appeal, are delivered to larger audiences, and will be recorded. If you miss them, you can watch them on demand after re:Invent.
- Chalk talks – Enjoy 60 minutes of content delivered to smaller audiences with an interactive whiteboarding session. Chalk talks are where discussions happen, and these offer you the greatest opportunity to ask questions or share your opinion.
- Workshops – In these hands-on learning opportunities, in 2 hours, you’ll be able to build a solution to a problem, and understand the inner workings of the resulting infrastructure and cross-service interaction. Bring your laptop and be ready to learn!
- Builders’ sessions – These highly interactive 60-minute mini-workshops are conducted in small groups of fewer than 10 attendees. Some of these appeal to beginners, and others are on specialized topics.
- Code talks – These talks are similar to our popular chalk talk format, but instead of focusing on an architecture solution with whiteboarding, the speakers lead an interactive discussion featuring live coding or code samples. These 60-minute sessions focus on the actual code that goes into building a solution. Attendees are encouraged to ask questions and follow along.
If you have reserved your seat at any of the sessions, great! If not, we always set aside some spots for walk-ins, so make a plan and come to the session early.
To help you plan your agenda for this year’s re:Invent, here are some highlights of the generative AI and ML sessions. Visit the session catalog to learn about all our generative AI and ML sessions.
Keynotes

Matt Garman, Chief Executive Officer, Amazon Web Services
Tuesday December 3| 8:00 AM – 10:30 AM (PST) | The Venetian
Join AWS CEO Matt Garman to hear how AWS is innovating across every aspect of the world’s leading cloud. He explores how we are reinventing foundational building blocks as well as developing brand-new experiences, all to empower customers and partners with what they need to build a better future.

Swami Sivasubramanian, Vice President of AI and Data
Wednesday December 4 | 8:30 AM – 10:30 AM (PST) | The Venetian
Join Dr. Swami Sivasubramanian, VP of AI and Data at AWS, to discover how you can use a strong data foundation to create innovative and differentiated solutions for your customers. Hear from customer speakers with real-world examples of how they’ve used data to support a variety of use cases, including generative AI, to create unique customer experiences.
Innovation talks

Pasquale DeMaio, Vice President & General Manager of Amazon Connect| BIZ221-INT | Generative AI for customer service
Monday December 2 | 10:30 AM – 11:30 AM (PST) | Venetian | Level 5 | Palazzo Ballroom B
Generative AI promises to revolutionize customer interactions, ushering in a new era of automation, cost efficiencies, and responsiveness. However, realizing this transformative potential requires a holistic approach that harmonizes people, processes, and technology. Through customer success stories and demonstrations of the latest AWS innovations, gain insights into operationalizing generative AI for customer service from the Vice President of Amazon Connect, Pasquale DeMaio. Whether you’re just starting your journey or well on your way, leave this talk with the knowledge and tools to unlock the transformative power of AI for customer interactions, the agent experience, and more.

Mai-Lan Tomsen Bukovec, Vice President, Technology | AIM250-INT | Modern data patterns for modern data strategies
Tuesday December 3 | 11:30 AM – 12:30 PM (PST) | Venetian | Level 5 | Palazzo Ballroom B
Every modern business is a data business, and organizations need to stay nimble to balance data growth with data-driven value. In this talk, you’ll understand how to recognize the latest signals in changing data patterns, and adapt data strategies that flex to changes in consumer behavior and innovations in technology like AI. Plus, learn how to evolve from data aggregation to data semantics to support data-driven applications while maintaining flexibility and governance. Hear from AWS customers who successfully evolved their data strategies for analytics, ML, and AI, and get practical guidance on implementing similar strategies using cutting-edge AWS tools and services.

Dilip Kumar, Vice President, Amazon Q Business | INV202-INT | Creating business breakthroughs with Amazon Q
Wednesday December 4| 11:30 AM – 12:30 PM (PST) | Venetian | Level 5 | Palazzo Ballroom B
Get an overview of Amazon Q Business capabilities, including its ability to answer questions, provide summaries, generate content, and complete assigned tasks. Learn how Amazon Q Business goes beyond search to enable AI-powered actions. Explore how simple it is to build applications using Amazon Q Apps. Then, examine how AWS App Studio empowers a new set of builders to rapidly create business applications tailored to their organization’s needs, and discover how to build richer analytics using Amazon Q in QuickSight.

Baskar Sridharan, VP, AI/ML Services & Infrastructure | AIM276-INT | Generative AI in action: From prototype to production
Wednesday December 4 | 1:00 PM – 2:00 PM (PST) | Venetian | Level 5 | Palazzo Ballroom B
Learn how to transition generative AI from prototypes to production. This includes building custom models, implementing robust data strategies, and scaling architectures for performance and reliability. Additionally, the session will cover empowering business users to drive innovation and growth through this transformative technology.

Adam Seligman, Vice President, Developer Experience | DOP220-INT | Reimagining the developer experience at AWS
Thursday December 5 | 2:00 PM – 3:00 PM (PST) | Venetian | Level 5 | Palazzo Ballroom B
Dive into the pioneering approach AWS takes to integrating generative AI across the entire software development lifecycle. Explore the rich ecosystem of technical resources, networking opportunities, and knowledge-sharing platforms available to you with AWS. Learn from real-world examples of how AWS, developers, and software teams are using the power of generative AI to creative innovative solutions that are shaping the future of software development.
Breakout sessions

DOP210: Accelerate multi-step SDLC tasks with Amazon Q Developer Agents
Monday December 2 | 8:30 AM – 9:30 AM PT
While existing AI assistants focus on code generation with close human guidance, Amazon Q Developer has a unique capability called agents that can use reasoning and planning capabilities to perform multi-step tasks beyond code generation with minimal human intervention. Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Join this session to discover new agent capabilities that help developers go from planning to getting new features in front of customers even faster.
AIM201: Maximize business impact with Amazon Q Apps: The Volkswagen AI journey
Monday December 2 | 10:00 AM – 11:00 AM PT
Discover how Volkswagen harnesses generative AI for optimized job matching and career growth with Amazon Q. Learn from the AWS Product Management team about the benefits of Amazon Q Business and the latest innovations in Amazon Q Apps. Then, explore how Volkswagen used these tools to streamline a job role mapping project, saving thousands of hours. Mario Duarte, Senior Director at Volkswagen Group of America, details the journey toward their first Amazon Q application that helps Volkswagen’s Human Resources build a learning ecosystem that boosts employee development. Leave the session inspired to bring Amazon Q Apps to supercharge your teams’ productivity engines.
BSI101: Reimagine business intelligence with generative AI
Monday December 2 | 1:00 PM – 2:00 PM PT
In this session, get an overview of the generative AI capabilities of Amazon Q in QuickSight. Learn how analysts can build interactive dashboards rapidly, and discover how business users can use natural language to instantly create documents and presentations explaining data and extract insights beyond what’s available in dashboards with data Q&A and executive summaries. Hear from Availity on how 1.5 million active users are using Amazon QuickSight to distill insights from dashboards instantly, and learn how they are using Amazon Q internally to increase efficiency across their business.
AIM272: 7 Principles for effective and cost-efficient Gen AI Apps
Monday December 2 | 2:30 PM – 3: 30 PM PT
As generative AI gains traction, building effective and cost-efficient solutions is paramount. This session outlines seven guiding principles for building effective and cost-efficient generative AI applications. These principles can help businesses and developers harness generative AI’s potential while optimizing resources. Establishing objectives, curating quality data, optimizing architectures, monitoring performance, upholding ethics, and iterating improvements are crucial. With these principles, organizations can develop impactful generative AI applications that drive responsible innovation. Join this session to hear from ASAPP, a leading contact center solutions provider, as they discuss the principles they used to add generative AI-powered innovations to their software with Amazon Bedrock.
DOP214: Unleashing generative AI: Amazon’s journey with Amazon Q Developer
Tuesday December 3 | 12:00 PM – 1:00 PM
Join us to discover how Amazon rolled out Amazon Q Developer to thousands of developers, trained them in prompt engineering, and measured its transformative impact on productivity. In this session, learn best practices for effectively adopting generative AI in your organization. Gain insights into training strategies, productivity metrics, and real-world use cases to empower your developers to harness the full potential of this game-changing technology. Don’t miss this opportunity to stay ahead of the curve and drive innovation within your team.
AIM229: Scale FM development with Amazon SageMaker HyperPod (customer panel)
Tuesday December 3 | 2:30 PM – 3: 30 PM PT
From startups to enterprises, organizations trust AWS to innovate with comprehensive, secure, and price-performant generative AI infrastructure. Amazon SageMaker HyperPod is a purpose-built infrastructure for FM development at scale. In this session, learn how leading AI companies strategize their FM development process and use SageMaker HyperPod to build state-of-the-art FMs efficiently.
BIZ212: Elevate your contact center performance with AI‑powered analytics
Wednesday December 4 | 8:30 AM – 9:30 AM PT
AI is unlocking deeper insights about contact center performance, including customer sentiment, agent performance, and workforce scheduling. Join this session to hear how contact center managers are using AI-powered analytics in Amazon Connect to proactively identify and act on opportunities to improve customer service outcomes. Learn how Toyota utilizes analytics to detect emerging themes and unlock insights used by leaders across the enterprise.
AIM357: Customizing models for enhanced results: Fine-tuning in Amazon Bedrock
Wednesday December 4 | 4:00 PM – 5:00 PM PT
Unleash the power of customized AI by fine-tuning generative AI models in Amazon Bedrock to achieve higher quality results. Discover how to adapt FMs like Meta’s Llama and Anthropic’s Claude models to your specific use cases and domains, boosting accuracy and efficiency. This session covers the technical process, from data preparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Gain the knowledge to take your generative AI applications to new heights, harnessing tailored, high-performance language processing solutions that give you a competitive advantage.
AIM304: Using multiple agents for scalable generative AI applications
Wednesday December 4 | 5:30 PM – 6:30 PM PT
Join this session to learn how Northwestern Mutual transformed their application development support system using Amazon Bedrock multi-agent collaboration with better planning and communication among agents. Learn how they created specialized agents for different tasks like account management, repos, pipeline management, and more to help their developers go faster. Explore the significant productivity gains and efficiency improvements achieved across the organization.
CMP208: Customer Stories: Optimizing AI performance and costs with AWS AI chips
Thursday December 5 | 12:30 PM – 1:30 PM PT
As you increase the use of generative AI to transform your business at scale, rising costs in your model development and deployment infrastructure can adversely impact your ability to innovate and deliver delightful customer experiences. AWS Trainium and AWS Inferentia deliver high-performance AI training and inference while reducing your costs by up to 50%. Attend this session to hear from AWS customers ByteDance, Ricoh, and Arcee about how they realized these benefits to grow their businesses and deliver innovative experiences to their end-users.
AIM359: Streamline model evaluation and selection with Amazon Bedrock
Friday December 6 | 8:30 AM – 9:30 AM
Explore the robust model evaluation capabilities of Amazon Bedrock, designed to select the optimal FMs for your applications. Discover how to create and manage evaluation jobs, use automatic and human reviews, and analyze critical metrics like accuracy, robustness, and toxicity. This session provides practical steps to streamline your model selection process, providing high-quality, reliable AI deployments. Gain essential insights to enhance your generative AI applications through effective model evaluation techniques.
AIM342: Responsible generative AI: Evaluation best practices and tools
Friday December 6 | 10:00 AM – 11:00 AM
With the newfound prevalence of applications built with large language models (LLMs) including features such as RAG, agents, and guardrails, a responsibly driven evaluation process is necessary to measure performance and mitigate risks. This session covers best practices for a responsible evaluation. Learn about open access libraries and AWS services that can be used in the evaluation process, and dive deep on the key steps of designing an evaluation plan, including defining a use case, assessing potential risks, choosing metrics and release criteria, designing an evaluation dataset, and interpreting results for actionable risk mitigation.
Chalk talks

AIM347-R1 : Real-time issue resolution from machine-generated signals with gen AI
Tuesday December 3 | 1:00 PM – 2:00 PM PT
Resolving urgent service issues quickly is crucial for efficient operations and customer satisfaction. This chalk talk demonstrates how to process machine-generated signals into your contact center, allowing your knowledge base to provide real-time solutions. Discover how generative AI can identify problems, provide resolution content, and deliver it to the right person or device through text, voice, and data. Through a real-life IoT company case study, learn how to monitor devices, collect error messages, and respond to issues through a contact center framework using generative AI to accelerate solution provision and delivery, increasing uptime and reducing technician deployments.
AIM407-R: Understand the deep security & privacy controls within Amazon Bedrock
Tuesday December 3 | 2:30 PM – 3:30 PM PT
Amazon Bedrock is designed to keep your data safe and secure, with none of your data being used to train the supported models. While the inference pathways are straightforward to understand, there are many nuances of some of the complex features of Amazon Bedrock that use your data for other non-inference purposes. This includes Amazon Bedrock Guardrails, Agents, and Knowledge Bases, along with the creation of custom models. In this chalk talk, explore the architectures, secure data flows, and complete lifecycle and usage of your data within these features, as you learn the deep details of the security capabilities in Amazon Bedrock.
AIM352: Unlock Extensibility in AWS App Studio with JavaScript and Lambda
Wednesday December 4 | 10:30 AM – 11:30 AM PT
Looking for a better way to build applications that boost your team’s productivity and drive innovation? Explore the fastest and simplest way to build enterprise-grade applications—and how to extend your app’s potential with JavaScript and AWS Lambda. Join to learn hands-on techniques for automating workflows, creating AI-driven experiences, and integrating with popular AWS services. You’ll leave with practical skills to supercharge your application development!
CMP329: Beyond Text: Unlock multimodal AI with AWS AI chips
Wednesday December 4 | 1:30 PM – 2:30 PM PT
Revolutionize your applications with multi-modal AI. Learn how to harness the power of AWS AI chips to create intelligent systems that understand and process text, images, and video. Explore advanced models, like Idefics2 and Chameleon, to build exceptional AI assistants capable of OCR, document analysis, visual reasoning, and creative content generation.
AIM343-R: Advancing responsible AI: Managing generative AI risk
Wednesday December 4 | 4:00 PM – 5:00 PM
Risk assessment is an essential part of responsible AI (RAI) development and is an increasingly common requirement in AI standards and laws such as ISO 42001 and the EU AI Act. This chalk talk provides an introduction to best practices for RAI risk assessment for generative AI applications, covering controllability, veracity, fairness, robustness, explainability, privacy and security, transparency, and governance. Explore examples to estimate the severity and likelihood of potential events that could be harmful. Learn about Amazon SageMaker tooling for model governance, bias, explainability, and monitoring, and about transparency in the form of service cards as potential risk mitigation strategies.
AIM366: Bring your gen AI models to Amazon Bedrock using Custom Model Import
Thursday December 5 | 1:00 PM – 2:00 PM
Learn how to accelerate your generative AI application development with Amazon Bedrock Custom Model Import. Seamlessly bring your fine-tuned models into a fully managed, serverless environment, and use the Amazon Bedrock standardized API and features like Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases to accelerate generative AI application development. Discover how Salesforce achieved 73% cost savings while maintaining high accuracy through this capability. Walk away with knowledge on how to build a production-ready, serverless generative AI application with a fine-tuned model.
Workshops

AIM315: Transforming intelligent document processing with generative AI
Monday December 2 | 8 AM – 10 AM PT
This workshop covers the use of generative AI models for intelligent document processing tasks. It introduces intelligent document processing and demonstrates how generative AI can enhance capabilities like multilingual OCR, document classification based on content/structure/visuals, document rule matching using RAG models, and agentic frameworks that combine generative models with decision-making and task orchestration. Attendees will learn practical applications of generative AI for streamlining and automating document-centric workflows.
DOP308-R: Accelerating enterprise development with Amazon Q Developer
Monday December | 12:00 PM – 2:00 PM PT
In this workshop, explore the transformative impact of generative AI in development. Get hands-on experience with Amazon Q Developer to learn how it can help you understand, build, and operate AWS applications. Explore the IDE to see how Amazon Q provides software development assistance, including code explanation, generation, modernization, and much more. You must bring your laptop to participate.
BSI204-R1: Hands-on with Amazon Q in QuickSight: A step-by-step workshop
Wednesday December 4 | 1:00 PM – 3:00 PM
In this workshop, explore the generative BI capabilities of Amazon Q in QuickSight. Experience authoring visuals and refining them using natural language. Learn how business users can use natural language to generate data stories to create highly customizable narratives or slide decks from data. Discover how natural language Q&A with Amazon Q helps users gain insights beyond what is presented on dashboards while executive summaries provide an at-a-glance view of data, surfacing trends and explanations. You must bring your laptop to participate.
AIM327: Fine-tune and deploy an LLM using Amazon SageMaker and AWS AI chips
Wednesday December 4 | 3:30 PM – 5:30 PM PT
As deep learning models have grown in size and complexity, there is a need for specialized ML accelerators to address the increasing training and inference demands of these models, while also delivering high performance, scalability, and cost-effectiveness. In this workshop, use AWS purpose-built ML accelerators, AWS Trainium and AWS Inferentia, to fine-tune and then run inference using an LLM based on the Meta Llama architecture. You must bring your laptop to participate.
AIM402: Revolutionizing multimodal data search with Amazon Q Business
Wednesday December 4 | 3:30 PM – 5:30 PM PT
Today’s enterprises deal with data in various formats, including audio, image, video, and text, scattered across different documents. Searching through this diverse content to find useful information is a significant challenge. This workshop explores how Amazon Q Business transforms the way enterprises search and discover data across multiple formats. By utilizing cutting-edge AI and ML technologies, Amazon Q Business helps enterprises navigate their content seamlessly. Find out how this powerful tool accelerates real-world use cases by making it straightforward to extract actionable insights from multimodal datasets. You must bring your laptop to participate.
Builder’s sessions

CMP304-R: Fine-tune Hugging Face LLMs using Amazon SageMaker and AWS Trainium
December Tuesday 3 | 2:30 PM – 3:30 PM
LLMs are pre-trained on vast amounts of data and perform well across a variety of general-purpose tasks and benchmarks without further specialized training. In practice, however, it is common to improve the performance of a pre-trained LLM by fine-tuning the model using a smaller task-specific or domain-specific dataset. In this builder’s session, learn how to use Amazon SageMaker to fine-tune a pre-trained Hugging Face LLM using AWS Trainium, and then use the fine-tuned model for inference. You must bring your laptop to participate.
AIM328: Optimize your cloud investments using Amazon Bedrock
December Thursday 5 | 2:30 PM – 3:30 PM
Manually tracking the interconnected nature of deployed cloud resources and reviewing their utilization can be complex and time-consuming. In this builders’ session, see a demo on how you can optimize your cloud investments to maximize efficiency and cost-effectiveness. Explore a novel approach that harnesses AWS services like Amazon Bedrock, AWS CloudFormation, Amazon Neptune, and Amazon CloudWatch to analyze resource utilization and manage unused AWS resources. Using Amazon Bedrock, analyze the source code to identify the AWS resources used in the application. Apply this information to build a knowledge graph that represents the interconnected AWS resources. You must bring a laptop to participate.
AIM403-R: Accelerate FM pre-training on Amazon SageMaker HyperPod
December Monday 2 | 2:30 – 3:30 PM
Amazon SageMaker HyperPod removes the undifferentiated heavy lifting involved in building and optimizing ML infrastructure for training FMs, reducing training time by up to 40%. In this builders’ session, learn how to pre-train an LLM using Slurm on SageMaker HyperPod. Explore the model pre-training workflow from start to finish, including setting up clusters, troubleshooting convergence issues, and running distributed training to improve model performance.
Code talks

DOP315: Optimize your cloud environments in the AWS console with generative AI
December Monday 2 | 5:30 PM – 6 30 PM
Available on the AWS Management Console, Amazon Q Developer is the only AI assistant that is an expert on AWS, helping developers and IT pros optimize their AWS Cloud environments. Proactively diagnose and resolve errors and networking issues, provide guidance on architectural best practices, analyze billing information and trends, and use natural language in chat to manage resources in your AWS account. Learn how Amazon Q Developer accelerates task completion with tailored recommendations based on your specific AWS workloads, shifting from a reactive review to proactive notifications and remediation.
AIM405: Learn to securely invoke Amazon Q Business Chat API
December Wednesday 4 | 2:30 PM – 3:30 PM
Join this code talk to learn how to use the Amazon Q Business identity-aware ChatSync API. First, hear an overview of identity-aware APIs, and then learn how to configure an identity provider as a trusted token issuer. Next, discover how your application can obtain an AWS STS token to assume a role that calls the ChatSync API. Finally, see how a client-side application uses the ChatSync API to answer questions from your documents indexed in Amazon Q Business.
AIM406: Attain ML excellence with proficiency in Amazon SageMaker Python SDK
December Wednesday 4 |4:30 PM – 5:30 PM
In this comprehensive code talk, delve into the robust capabilities of the Amazon SageMaker Python SDK. Explore how this powerful tool streamlines the entire ML lifecycle, from data preparation to model deployment. Discover how to use pre-built algorithms, integrate custom models seamlessly, and harness the power of popular Python libraries within the SageMaker platform. Gain hands-on experience in data management, model training, monitoring, and seamless deployment to production environments. Learn best practices and insider tips to optimize your data science workflow and accelerate your ML journey using the SageMaker Python SDK.
AWS DeepRacer

ML enthusiasts, start your engines—AWS DeepRacer is back at re:Invent with a thrilling finale to 6 years of ML innovation! Whether you’re an ML pro or just starting out, the AWS DeepRacer championship offers an exciting glimpse into cutting-edge reinforcement learning. The action kicks off on December 2 with the Last Chance Qualifier, followed by 3 days of intense competition as 32 global finalists race for a whopping $50,000 prize pool. Don’t miss the grand finale on December 5, where top racers will battle it out on the challenging Forever Raceway in the Data Pavilion. This year, we’re taking AWS DeepRacer beyond the track with a series of four all-new workshops. These sessions are designed to help you use your reinforcement learning skills in the rapidly expanding field of generative AI. Learn to apply AWS DeepRacer skills to LLMs, explore multi-modal semantic search, and create AI-powered chatbots.
Exciting addition: We are introducing the AWS LLM League—a groundbreaking program that builds on the success of AWS DeepRacer to bring hands-on learning to the world of generative AI. The LLM League offers participants a unique opportunity to gain practical experience in model customization and fine-tuning, skills that are increasingly crucial in today’s AI landscape. Join any of the three DPR-101 sessions to demystify LLMs using your AWS DeepRacer know-how.
Make sure to check out the re:Invent content catalog for all the generative AI and ML content at re:Invent.
Let the countdown begin. See you at re:Invent!
About the authors
 Mukund Birje is a Sr. Product Marketing Manager on the AIML team at AWS. In his current role he’s focused on driving adoption of AWS data services for generative AI. He has over 10 years of experience in marketing and branding across a variety of industries. Outside of work you can find him hiking, reading, and trying out new restaurants. You can connect with him on LinkedIN
Mukund Birje is a Sr. Product Marketing Manager on the AIML team at AWS. In his current role he’s focused on driving adoption of AWS data services for generative AI. He has over 10 years of experience in marketing and branding across a variety of industries. Outside of work you can find him hiking, reading, and trying out new restaurants. You can connect with him on LinkedIN
 Dr. Andrew Kane is an AWS Principal WW Tech Lead (AI Language Services) based out of London. He focuses on the AWS Language and Vision AI services, helping our customers architect multiple AI services into a single use-case driven solution. Before joining AWS at the beginning of 2015, Andrew spent two decades working in the fields of signal processing, financial payments systems, weapons tracking, and editorial and publishing systems. He is a keen karate enthusiast (just one belt away from Black Belt) and is also an avid home-brewer, using automated brewing hardware and other IoT sensors.
Dr. Andrew Kane is an AWS Principal WW Tech Lead (AI Language Services) based out of London. He focuses on the AWS Language and Vision AI services, helping our customers architect multiple AI services into a single use-case driven solution. Before joining AWS at the beginning of 2015, Andrew spent two decades working in the fields of signal processing, financial payments systems, weapons tracking, and editorial and publishing systems. He is a keen karate enthusiast (just one belt away from Black Belt) and is also an avid home-brewer, using automated brewing hardware and other IoT sensors.

AI at COP29: Balancing Innovation and Sustainability
As COP29 attendees gather in Baku, Azerbaijan, to tackle climate change, the role AI plays in environmental sustainability is front and center.
A panel hosted by Deloitte brought together industry leaders to explore ways to reduce AI’s environmental footprint and align its growth with climate goals.
Experts from Crusoe Energy Systems, EON, the International Energy Agency (IEA) and NVIDIA sat down for a conversation about the energy efficiency of AI.
The Environmental Impact of AI
Deloitte’s recent report, “Powering Artificial Intelligence: A study of AI’s environmental footprint,” shows AI’s potential to drive a climate-neutral economy. The study looks at how organizations can achieve “Green AI” in the coming decades and addresses AI’s energy use.
Deloitte analysis predicts that AI adoption will fuel data center power demand, likely reaching 1,000 terawatt-hours (TWh) by 2030, and potentially climbing to 2,000 TWh by 2050. This will account for 3% of global electricity consumption, indicating faster growth than in other uses like electric cars and green hydrogen production.
While data centers currently consume around 2% of total electricity, and AI is a small fraction of that, the discussion at COP29 emphasized the need to meet rising energy demands with clean energy sources to support global climate goals.
Energy Efficiency From the Ground Up

NVIDIA is prioritizing energy-efficient data center operations with innovations like liquid-cooled GPUs. Direct-to-chip liquid cooling allows data centers to cool systems more effectively than traditional air conditioning, consuming less power and water.
“We see a very rapid trend toward direct-to-chip liquid cooling, which means water demands in data centers are dropping dramatically right now,” said Josh Parker, senior director of legal – corporate sustainability at NVIDIA.
As AI continues to scale, the future of data centers will hinge on designing for energy efficiency from the outset. By prioritizing energy efficiency from the ground up, data centers can meet the growing demands of AI while contributing to a more sustainable future.
Parker emphasized that existing data center infrastructure is becoming dated and less efficient. “The data shows that it’s 10x more efficient to run workloads on accelerated computing platforms than on traditional data center platforms,” he said. “There’s a huge opportunity for us to reduce the energy consumed in existing infrastructures.”
The Path to Green Computing
AI has the potential to play a large role in moving toward climate-neutral economies, according to Deloitte’s study. This approach, often called Green AI, involves reducing the environmental impact of AI throughout the value chain with practices like purchasing renewable energy and improving hardware design.
Until now, Green AI has mostly been led by industry leaders. Take accelerated computing, for instance, which is all about doing more with less. It uses special hardware — like GPUs — to perform tasks faster and with less energy than general-purpose servers that use CPUs, which handle a task at a time.
That’s why accelerated computing is sustainable computing.
“Accelerated computing is actually the most energy-efficient platform that we’ve seen for AI but also for a lot of other computing applications,” said Parker.
“The trend in energy efficiency for accelerated computing over the last several years shows a 100,000x reduction in energy consumption. And just in the past 2 years, we’ve become 25x more efficient for AI inference. That’s a 96% reduction in energy for the same computational workload,” he said.
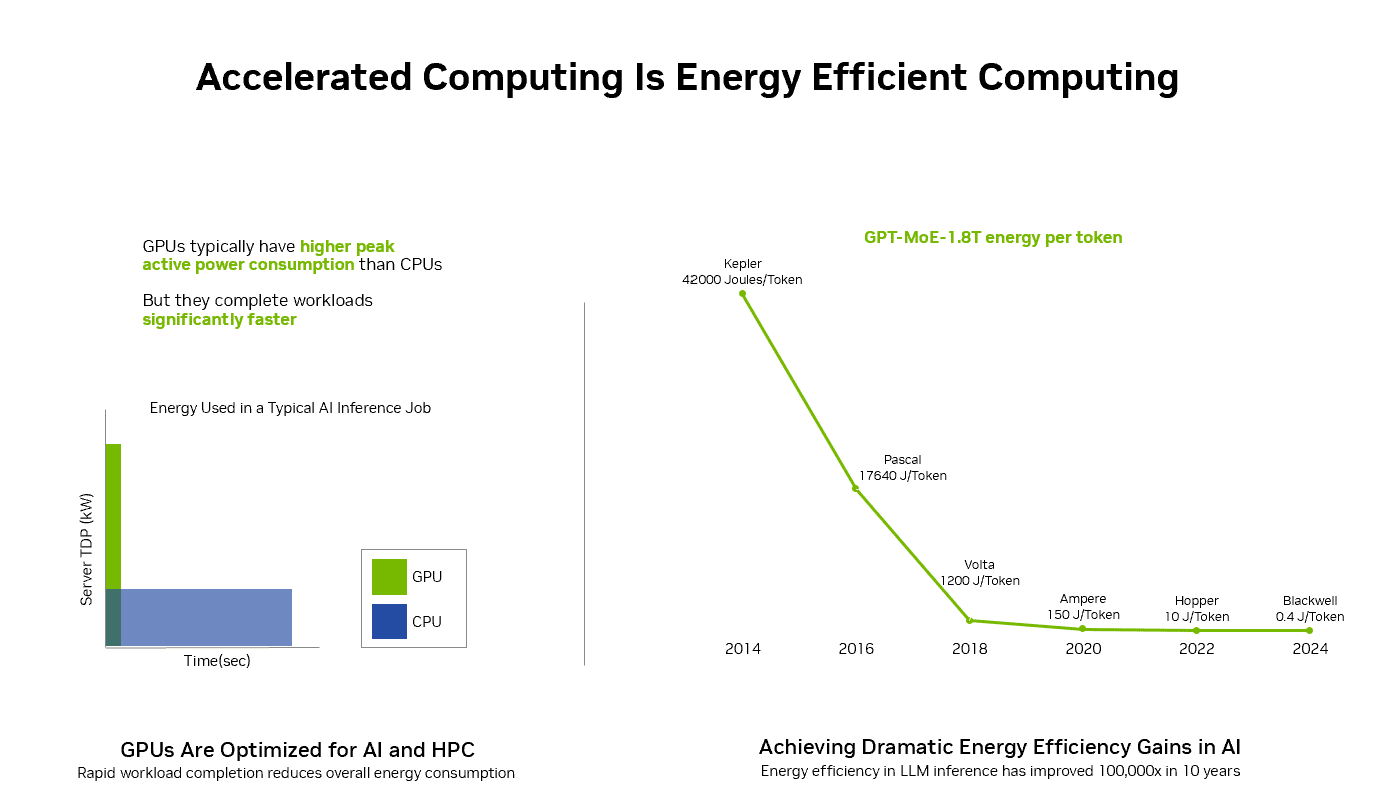
Reducing Energy Consumption Across Sectors
Innovations like the NVIDIA Blackwell and Hopper architectures significantly improve energy efficiency with each new generation. NVIDIA Blackwell is 25x more energy-efficient for large language models, and the NVIDIA H100 Tensor Core GPU is 20x more efficient than CPUs for complex workloads.
“AI has the potential to make other sectors much more energy efficient,” said Parker. Murex, a financial services firm, achieved a 4x reduction in energy use and 7x faster performance with the NVIDIA Grace Hopper Superchip.
“In manufacturing, we’re seeing around 30% reductions in energy requirements if you use AI to help optimize the manufacturing process through digital twins,” he said.
For example, manufacturing company Wistron improved energy efficiency using digital twins and NVIDIA Omniverse, a platform for developing OpenUSD applications for industrial digitalization and physical AI simulation. The company reduced its electricity consumption by 120,000 kWh and carbon emissions by 60,000 kg annually.
A Tool for Energy Management
Deloitte reports that AI can help optimize resource use and reduce emissions, playing a crucial role in energy management. This means it has the potential to lower the impact of industries beyond its own carbon footprint.
Combined with digital twins, AI is transforming energy management systems by improving the reliability of renewable sources like solar and wind farms. It’s also being used to optimize facility layouts, monitor equipment, stabilize power grids and predict climate patterns, aiding in global efforts to reduce carbon emissions.
COP29 discussions emphasized the importance of powering AI infrastructure with renewables and setting ethical guidelines. By innovating with the environment in mind, industries can use AI to build a more sustainable world.
Watch a replay of the on-demand COP29 panel discussion.
Customize small language models on AWS with automotive terminology
In the rapidly evolving world of AI, the ability to customize language models for specific industries has become more important. Although large language models (LLMs) are adept at handling a wide range of tasks with natural language, they excel at general purpose tasks as compared with specialized tasks. This can create challenges when processing text data from highly specialized domains with their own distinct terminology or specialized tasks where intrinsic knowledge of the LLM is not well-suited for solutions such as Retrieval Augmented Generation (RAG).
For instance, in the automotive industry, users might not always provide specific diagnostic trouble codes (DTCs), which are often proprietary to each manufacturer. These codes, such as P0300 for a generic engine misfire or C1201 for an ABS system fault, are crucial for precise diagnosis. Without these specific codes, a general purpose LLM might struggle to provide accurate information. This lack of specificity can lead to hallucinations in the generated responses, where the model invents plausible but incorrect diagnoses, or sometimes result in no answers at all. For example, if a user simply describes “engine running rough” without providing the specific DTC, a general LLM might suggest a wide range of potential issues, some of which may be irrelevant to the actual problem, or fail to provide any meaningful diagnosis due to insufficient context. Similarly, in tasks like code generation and suggestions through chat-based applications, users might not specify the APIs they want to use. Instead, they often request help in resolving a general issue or in generating code that utilizes proprietary APIs and SDKs.
Moreover, generative AI applications for consumers can offer valuable insights into the types of interactions from end-users. With appropriate feedback mechanisms, these applications can also gather important data to continuously improve the behavior and responses generated by these models.
For these reasons, there is a growing trend in the adoption and customization of small language models (SLMs). SLMs are compact transformer models, primarily utilizing decoder-only or encoder-decoder architectures, typically with parameters ranging from 1–8 billion. They are generally more efficient and cost-effective to train and deploy compared to LLMs, and are highly effective when fine-tuned for specific domains or tasks. SLMs offer faster inference times, lower resource requirements, and are suitable for deployment on a wider range of devices, making them particularly valuable for specialized applications and edge computing scenarios. Additionally, more efficient techniques for customizing both LLMs and SLMs, such as Low Rank Adaptation (LoRA), are making these capabilities increasingly accessible to a broader range of customers.
AWS offers a wide range of solutions for interacting with language models. Amazon Bedrock is a fully managed service that offers foundation models (FMs) from Amazon and other AI companies to help you build generative AI applications and host customized models. Amazon SageMaker is a comprehensive, fully managed machine learning (ML) service to build, train, and deploy LLMs and other FMs at scale. You can fine-tune and deploy models with Amazon SageMaker JumpStart or directly through Hugging Face containers.
In this post, we guide you through the phases of customizing SLMs on AWS, with a specific focus on automotive terminology for diagnostics as a Q&A task. We begin with the data analysis phase and progress through the end-to-end process, covering fine-tuning, deployment, and evaluation. We compare a customized SLM with a general purpose LLM, using various metrics to assess vocabulary richness and overall accuracy. We provide a clear understanding of customizing language models specific to the automotive domain and its benefits. Although this post focuses on the automotive domain, the approaches are applicable to other domains. You can find the source code for the post in the associated Github repository.
Solution overview
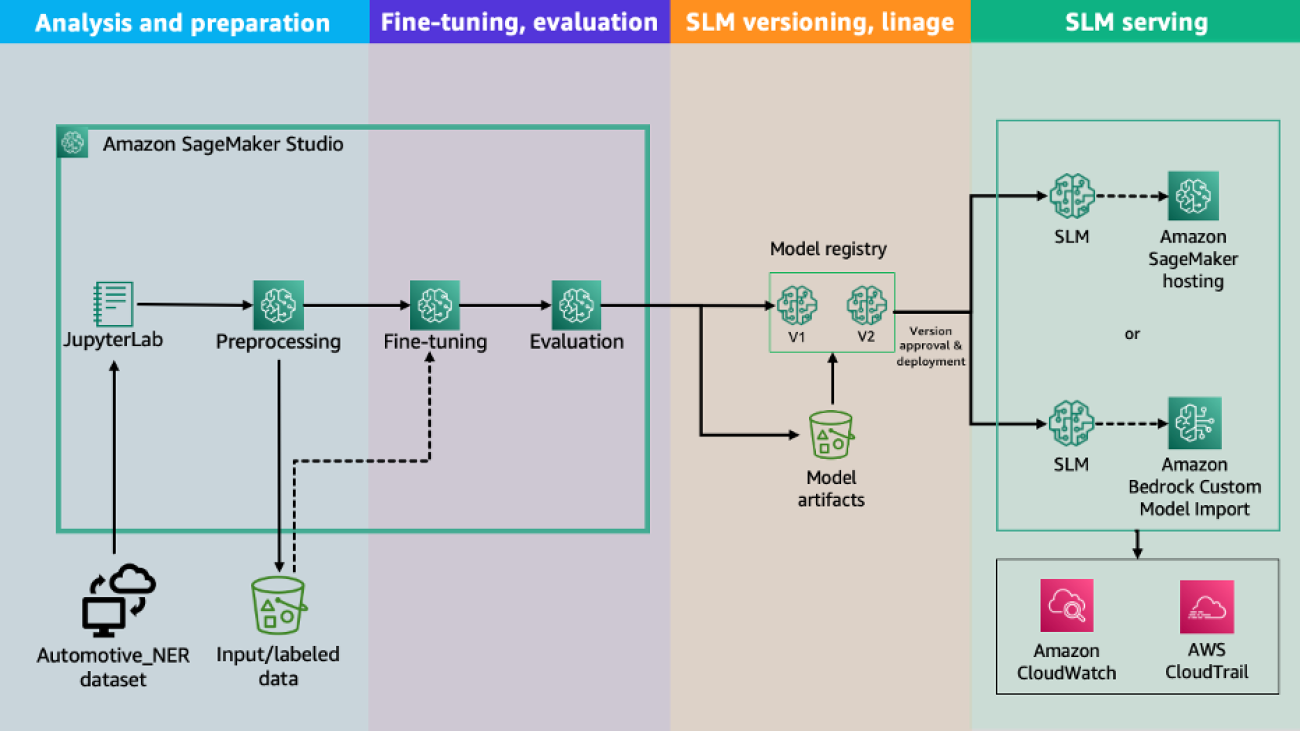
This solution uses multiple features of SageMaker and Amazon Bedrock, and can be divided into four main steps:
- Data analysis and preparation – In this step, we assess the available data, understand how it can be used to develop solution, select data for fine-tuning, and identify required data preparation steps. We use Amazon SageMaker Studio, a comprehensive web-based integrated development environment (IDE) designed to facilitate all aspects of ML development. We also employ SageMaker jobs to access more computational power on-demand, thanks to the SageMaker Python SDK.
- Model fine-tuning – In this step, we prepare prompt templates for fine-tuning SLM. For this post, we use Meta Llama3.1 8B Instruct from Hugging Face as the SLM. We run our fine-tuning script directly from the SageMaker Studio JupyterLab environment. We use the @remote decorator feature of the SageMaker Python SDK to launch a remote training job. The fine-tuning script uses LoRA, distributing compute across all available GPUs on a single instance.
- Model deployment – When the fine-tuning job is complete and the model is ready, we have two deployment options:
- Deploy in SageMaker by selecting the best instance and container options available.
- Deploy in Amazon Bedrock by importing the fine-tuned model for on-demand use.
- Model evaluation – In this final step, we evaluate the fine-tuned model against a similar base model and a larger model available from Amazon Bedrock. Our evaluation focuses on how well the model uses specific terminology for the automotive space, as well as the improvements provided by fine-tuning in generating answers.
The following diagram illustrates the solution architecture.
Using the Automotive_NER dataset
The Automotive_NER dataset, available on the Hugging Face platform, is designed for named entity recognition (NER) tasks specific to the automotive domain. This dataset is specifically curated to help identify and classify various entities related to the automotive industry and uses domain-specific terminologies.
The dataset contains approximately 256,000 rows; each row contains annotated text data with entities related to the automotive domain, such as car brands, models, component, description of defects, consequences, and corrective actions. The terminology used to describe defects, reference to components, or error codes reported is a standard for the automotive industry. The fine-tuning process enables the language model to learn the domain terminologies better and helps improve the vocabulary used in the generation of answers and overall accuracy for the generated answers.
The following table is an example of rows contained in the dataset.
| 1 | COMPNAME | DESC_DEFECT | CONEQUENCE_DEFECT | CORRECTIVE_ACTION |
| 2 | ELECTRICAL SYSTEM:12V/24V/48V BATTERY:CABLES | CERTAIN PASSENGER VEHICLES EQUIPPED WITH ZETEC ENGINES, LOOSE OR BROKEN ATTACHMENTS AND MISROUTED BATTERY CABLES COULD LEAD TO CABLE INSULATION DAMAGE. | THIS, IN TURN, COULD CAUSE THE BATTERY CABLES TO SHORT RESULTING IN HEAT DAMAGE TO THE CABLES. BESIDES HEAT DAMAGE, THE “CHECK ENGINE” LIGHT MAY ILLUMINATE, THE VEHICLE MAY FAIL TO START, OR SMOKE, MELTING, OR FIRE COULD ALSO OCCUR. | DEALERS WILL INSPECT THE BATTERY CABLES FOR THE CONDITION OF THE CABLE INSULATION AND PROPER TIGHTENING OF THE TERMINAL ENDS. AS NECESSARY, CABLES WILL BE REROUTED, RETAINING CLIPS INSTALLED, AND DAMAGED BATTERY CABLES REPLACED. OWNER NOTIFICATION BEGAN FEBRUARY 10, 2003. OWNERS WHO DO NOT RECEIVE THE FREE REMEDY WITHIN A REASONABLE TIME SHOULD CONTACT FORD AT 1-866-436-7332. |
| 3 | ELECTRICAL SYSTEM:12V/24V/48V BATTERY:CABLES | CERTAIN PASSENGER VEHICLES EQUIPPED WITH ZETEC ENGINES, LOOSE OR BROKEN ATTACHMENTS AND MISROUTED BATTERY CABLES COULD LEAD TO CABLE INSULATION DAMAGE. | THIS, IN TURN, COULD CAUSE THE BATTERY CABLES TO SHORT RESULTING IN HEAT DAMAGE TO THE CABLES. BESIDES HEAT DAMAGE, THE “CHECK ENGINE” LIGHT MAY ILLUMINATE, THE VEHICLE MAY FAIL TO START, OR SMOKE, MELTING, OR FIRE COULD ALSO OCCUR. | DEALERS WILL INSPECT THE BATTERY CABLES FOR THE CONDITION OF THE CABLE INSULATION AND PROPER TIGHTENING OF THE TERMINAL ENDS. AS NECESSARY, CABLES WILL BE REROUTED, RETAINING CLIPS INSTALLED, AND DAMAGED BATTERY CABLES REPLACED. OWNER NOTIFICATION BEGAN FEBRUARY 10, 2003. OWNERS WHO DO NOT RECEIVE THE FREE REMEDY WITHIN A REASONABLE TIME SHOULD CONTACT FORD AT 1-866-436-7332. |
| 4 | EQUIPMENT:OTHER:LABELS | ON CERTAIN FOLDING TENT CAMPERS, THE FEDERAL CERTIFICATION (AND RVIA) LABELS HAVE THE INCORRECT GROSS VEHICLE WEIGHT RATING, TIRE SIZE, AND INFLATION PRESSURE LISTED. | IF THE TIRES WERE INFLATED TO 80 PSI, THEY COULD BLOW RESULTING IN A POSSIBLE CRASH. | OWNERS WILL BE MAILED CORRECT LABELS FOR INSTALLATION ON THEIR VEHICLES. OWNER NOTIFICATION BEGAN SEPTEMBER 23, 2002. OWNERS SHOULD CONTACT JAYCO AT 1-877-825-4782. |
| 5 | STRUCTURE | ON CERTAIN CLASS A MOTOR HOMES, THE FLOOR TRUSS NETWORK SUPPORT SYSTEM HAS A POTENTIAL TO WEAKEN CAUSING INTERNAL AND EXTERNAL FEATURES TO BECOME MISALIGNED. THE AFFECTED VEHICLES ARE 1999 – 2003 CLASS A MOTOR HOMES MANUFACTURED ON F53 20,500 POUND GROSS VEHICLE WEIGHT RATING (GVWR), FORD CHASSIS, AND 2000-2003 CLASS A MOTOR HOMES MANUFACTURED ON W-22 22,000 POUND GVWR, WORKHORSE CHASSIS. | CONDITIONS CAN RESULT IN THE BOTTOMING OUT THE SUSPENSION AND AMPLIFICATION OF THE STRESS PLACED ON THE FLOOR TRUSS NETWORK. THE ADDITIONAL STRESS CAN RESULT IN THE FRACTURE OF WELDS SECURING THE FLOOR TRUSS NETWORK SYSTEM TO THE CHASSIS FRAME RAIL AND/OR FRACTURE OF THE FLOOR TRUSS NETWORK SUPPORT SYSTEM. THE POSSIBILITY EXISTS THAT THERE COULD BE DAMAGE TO ELECTRICAL WIRING AND/OR FUEL LINES WHICH COULD POTENTIALLY LEAD TO A FIRE. | DEALERS WILL INSPECT THE FLOOR TRUSS NETWORK SUPPORT SYSTEM, REINFORCE THE EXISTING STRUCTURE, AND REPAIR, AS NEEDED, THE FLOOR TRUSS NETWORK SUPPORT. OWNER NOTIFICATION BEGAN NOVEMBER 5, 2002. OWNERS SHOULD CONTACT MONACO AT 1-800-685-6545. |
| 6 | STRUCTURE | ON CERTAIN CLASS A MOTOR HOMES, THE FLOOR TRUSS NETWORK SUPPORT SYSTEM HAS A POTENTIAL TO WEAKEN CAUSING INTERNAL AND EXTERNAL FEATURES TO BECOME MISALIGNED. THE AFFECTED VEHICLES ARE 1999 – 2003 CLASS A MOTOR HOMES MANUFACTURED ON F53 20,500 POUND GROSS VEHICLE WEIGHT RATING (GVWR), FORD CHASSIS, AND 2000-2003 CLASS A MOTOR HOMES MANUFACTURED ON W-22 22,000 POUND GVWR, WORKHORSE CHASSIS. | CONDITIONS CAN RESULT IN THE BOTTOMING OUT THE SUSPENSION AND AMPLIFICATION OF THE STRESS PLACED ON THE FLOOR TRUSS NETWORK. THE ADDITIONAL STRESS CAN RESULT IN THE FRACTURE OF WELDS SECURING THE FLOOR TRUSS NETWORK SYSTEM TO THE CHASSIS FRAME RAIL AND/OR FRACTURE OF THE FLOOR TRUSS NETWORK SUPPORT SYSTEM. THE POSSIBILITY EXISTS THAT THERE COULD BE DAMAGE TO ELECTRICAL WIRING AND/OR FUEL LINES WHICH COULD POTENTIALLY LEAD TO A FIRE. | DEALERS WILL INSPECT THE FLOOR TRUSS NETWORK SUPPORT SYSTEM, REINFORCE THE EXISTING STRUCTURE, AND REPAIR, AS NEEDED, THE FLOOR TRUSS NETWORK SUPPORT. OWNER NOTIFICATION BEGAN NOVEMBER 5, 2002. OWNERS SHOULD CONTACT MONACO AT 1-800-685-6545. |
Data analysis and preparation on SageMaker Studio
When you’re fine-tuning LLMs, the quality and composition of your training data are crucial (quality over quantity). For this post, we implemented a sophisticated method to select 6,000 rows out of 256,000. This method uses TF-IDF vectorization to identify the most significant and the rarest words in the dataset. By selecting rows containing these words, we maintained a balanced representation of common patterns and edge cases. This improves computational efficiency and creates a high-quality, diverse subset leading to effective model training.
The first step is to open a JupyterLab application previously created in our SageMaker Studio domain.

After you clone the git repository, install the required libraries and dependencies:
The next step is to read the dataset:
The first step of our data preparation activity is to analyze the importance of the words in our dataset, for identifying both the most important (frequent and distinctive) words and the rarest words in the dataset, by using Term Frequency-Inverse Document Frequency (TF-IDF) vectorization.
Given the dataset’s size, we decided to run the fine-tuning job using Amazon SageMaker Training.
By using the @remote function capability of the SageMaker Python SDK, we can run our code into a remote job with ease.
In our case, the TF-IDF vectorization and the extraction of the top words and bottom words are performed in a SageMaker training job directly from our notebook, without any code changes, by simply adding the @remote decorator on top of our function. You can define the configurations required by the SageMaker training job, such as dependencies and training image, in a config.yaml file. For more details on the settings supported by the config file, see Using the SageMaker Python SDK
See the following code:
Next step is to define and execute our processing function:
After we extract the top and bottom 6,000 words based on their TF-IDF scores from our original dataset, we classify each row in the dataset based on whether it contained any of these important or rare words. Rows are labeled as ‘top’ if they contained important words, ‘bottom’ if they contained rare words, or ‘neither’ if they don’t contain either:
Finally, we create a balanced subset of the dataset by selecting all rows containing important words (‘top’) and an equal number of rows containing rare words (‘bottom’). If there aren’t enough ‘bottom’ rows, we filled the remaining slots with ‘neither’ rows.
| DESC_DEFECT | CONEQUENCE_DEFECT | CORRECTIVE_ACTION | word_type | |
| 2 | ON CERTAIN FOLDING TENT CAMPERS, THE FEDERAL C… | IF THE TIRES WERE INFLATED TO 80 PSI, THEY COU… | OWNERS WILL BE MAILED CORRECT LABELS FOR INSTA… | top |
| 2402 | CERTAIN PASSENGER VEHICLES EQUIPPED WITH DUNLO… | THIS COULD RESULT IN PREMATURE TIRE WEAR. | DEALERS WILL INSPECT AND IF NECESSARY REPLACE … | bottom |
| 0 | CERTAIN PASSENGER VEHICLES EQUIPPED WITH ZETEC… | THIS, IN TURN, COULD CAUSE THE BATTERY CABLES … | DEALERS WILL INSPECT THE BATTERY CABLES FOR TH… | neither |
Finally, we randomly sampled 6,000 rows from this balanced set:
Fine-tuning Meta Llama 3.1 8B with a SageMaker training job
After selecting the data, we need to prepare the resulting dataset for the fine-tuning activity. By examining the columns, we aim to adapt the model for two different tasks:
The following code is for the first prompt:
With this prompt, we instruct the model to highlight the possible consequences of a defect, given the manufacturer, component name, and description of the defect.
The following code is for the second prompt:
With this second prompt, we instruct the model to suggest possible corrective actions for a given defect and component of a specific manufacturer.
First, let’s split the dataset into train, test, and validation subsets:
Next, we create prompt templates to convert each row item into the two prompt formats previously described:
Now we can apply the template functions template_dataset_consequence and template_dataset_corrective_action to our datasets:


As a final step, we concatenate the four resulting datasets for train and test:

Our final training dataset comprises approximately 12,000 elements, properly split into about 11,000 for training and 1,000 for testing.
Now we can prepare the training script and define the training function train_fn and put the @remote decorator on the function.
The training function does the following:
- Tokenizes and chunks the dataset
- Sets up
BitsAndBytesConfig, for model quantization, which specifies the model should be loaded in 4-bit - Uses mixed precision for the computation, by converting model parameters to
bfloat16 - Loads the model
- Creates LoRA configurations that specify ranking of update matrices (
r), scaling factor (lora_alpha), the modules to apply the LoRA update matrices (target_modules), dropout probability for Lora layers (lora_dropout),task_type, and more - Starts the training and evaluation
Because we want to distribute the training across all the available GPUs in our instance, by using PyTorch Distributed Data Parallel (DDP), we use the Hugging Face Accelerate library that enables us to run the same PyTorch code across distributed configurations.
For optimizing memory resources, we have decided to run a mixed precision training:
We can specify to run a distributed job in the @remote function through the parameters use_torchrun and nproc_per_node, which indicates if the SageMaker job should use as entrypoint torchrun and the number of GPUs to use. You can pass optional parameters like volume_size, subnets, and security_group_ids using the @remote decorator.
Finally, we run the job by invoking train_fn():
The training job runs on the SageMaker training cluster. The training job took about 42 minutes, by distributing the computation across the 4 available GPUs on the selected instance type ml.g5.12xlarge.
We choose to merge the LoRA adapter with the base model. This decision was made during the training process by setting the merge_weights parameter to True in our train_fn() function. Merging the weights provides us with a single, cohesive model that incorporates both the base knowledge and the domain-specific adaptations we’ve made through fine-tuning.
By merging the model, we gain flexibility in our deployment options.
Model deployment
When deploying a fine-tuned model on AWS, multiple deployment strategies are available. In this post, we explore two deployment methods:
- SageMaker real-time inference – This option is designed for having full control of the inference resources. We can use a set of available instances and deployment options for hosting our model. By using the SageMaker built-in containers, such as DJL Serving or Hugging Face TGI, we can use the inference script and the optimization options provided in the container.
- Amazon Bedrock Custom Model Import – This option is designed for importing and deploying custom language models. We can use this fully managed capability for interacting with the deployed model with on-demand throughput.
Model deployment with SageMaker real-time inference
SageMaker real-time inference is designed for having full control over the inference resources. It allows you to use a set of available instances and deployment options for hosting your model. By using the SageMaker built-in container Hugging Face Text Generation Inference (TGI), you can take advantage of the inference script and optimization options available in the container.
In this post, we deploy the fine-tuned model to a SageMaker endpoint for running inference, which will be used for evaluating the model in the next step.
We create the HuggingFaceModel object, which is a high-level SageMaker model class for working with Hugging Face models. The image_uri parameter specifies the container image URI for the model, and model_data points to the Amazon Simple Storage Service (Amazon S3) location containing the model artifact (automatically uploaded by the SageMaker training job). We also specify a set of environment variables to configure the number of GPUs (SM_NUM_GPUS), quantization methodology (QUANTIZE), and maximum input and total token lengths (MAX_INPUT_LENGTH and MAX_TOTAL_TOKENS).
After creating the model object, we can deploy it to an endpoint using the deploy method. The initial_instance_count and instance_type parameters specify the number and type of instances to use for the endpoint. The container_startup_health_check_timeout and model_data_download_timeout parameters set the timeout values for the container startup health check and model data download, respectively.
It takes a few minutes to deploy the model before it becomes available for inference and evaluation. The endpoint is invoked using the AWS SDK with the boto3 client for sagemaker-runtime, or directly by using the SageMaker Python SDK and the predictor previously created, by using the predict API.
Model deployment with Amazon Bedrock Custom Model Import
Amazon Bedrock Custom Model Import is a fully managed capability, currently in public preview, designed for importing and deploying custom language models. It allows you to interact with the deployed model both on-demand and by provisioning the throughput.
In this section, we use the Custom Model Import feature in Amazon Bedrock for deploying our fine-tuned model in the fully managed environment of Amazon Bedrock.


After defining the model and job_name variables, we import our model from the S3 bucket by supplying it in the Hugging Face weights format.

Next, we use a preexisting AWS Identity and Access Management (IAM) role that allows reading the binary file from Amazon S3 and create the import job resource in Amazon Bedrock for hosting our model.

It takes a few minutes to deploy the model, and it can be invoked using the AWS SDK with the boto3 client for bedrock-runtime by using the invoke_model API:
Model evaluation
In this final step, we evaluate the fine-tuned model against the base models Meta Llama 3 8B Instruct and Meta Llama 3 70B Instruct on Amazon Bedrock. Our evaluation focuses on how well the model uses specific terminology for the automotive space and the improvements provided by fine-tuning in generating answers.
The fine-tuned model’s ability to understand components and error descriptions for diagnostics, as well as identify corrective actions and consequences in the generated answers, can be evaluated on two dimensions.
To evaluate the quality of the generated text and whether the vocabulary and terminology used are appropriate for the task and industry, we use the Bilingual Evaluation Understudy (BLEU) score. BLEU is an algorithm for evaluating the quality of text, by calculating n-gram overlap between the generated and the reference text.
To evaluate the accuracy of the generated text and see if the generated answer is similar to the expected one, we use the Normalized Levenshtein distance. This algorithm evaluates how close the calculated or measured values are to the actual value.
The evaluation dataset comprises 10 unseen examples of component diagnostics extracted from the original training dataset.
The prompt template for the evaluation is structured as follows:
BLEU score evaluation with base Meta Llama 3 8B and 70B Instruct
The following table and figures show the calculated values for the BLEU score comparison (higher is better) with Meta Llama 3 8B and 70 B Instruct.
| Example | Fine-Tuned Score | Base Score: Meta Llama 3 8B | Base Score: Meta Llama 3 70B | |
| 1 | 2733 | 0. 2936 | 5.10E-155 | 4.85E-155 |
| 2 | 3382 | 0.1619 | 0.058 | 1.134E-78 |
| 3 | 1198 | 0.2338 | 1.144E-231 | 3.473E-155 |
| 4 | 2942 | 0.94854 | 2.622E-231 | 3.55E-155 |
| 5 | 5151 | 1.28E-155 | 0 | 0 |
| 6 | 2101 | 0.80345 | 1.34E-78 | 1.27E-78 |
| 7 | 5178 | 0.94854 | 0.045 | 3.66E-155 |
| 8 | 1595 | 0.40412 | 4.875E-155 | 0.1326 |
| 9 | 2313 | 0.94854 | 3.03E-155 | 9.10E-232 |
| 10 | 557 | 0.89315 | 8.66E-79 | 0.1954 |


By comparing the fine-tuned and base scores, we can assess the performance improvement (or degradation) achieved by fine-tuning the model in the vocabulary and terminology used.
The analysis suggests that for the analyzed cases, the fine-tuned model outperforms the base model in the vocabulary and terminology used in the generated answer. The fine-tuned model appears to be more consistent in its performance.
Normalized Levenshtein distance with base Meta Llama 3 8B Instruct
The following table and figures show the calculated values for the Normalized Levenshtein distance comparison with Meta Llama 3 8B and 70B Instruct.
| Example | Fine-tuned Score | Base Score – Llama 3 8B | Base Score – Llama 3 70B | |
| 1 | 2733 | 0.42198 | 0.29900 | 0.27226 |
| 2 | 3382 | 0.40322 | 0.25304 | 0.21717 |
| 3 | 1198 | 0.50617 | 0.26158 | 0.19320 |
| 4 | 2942 | 0.99328 | 0.18088 | 0.19420 |
| 5 | 5151 | 0.34286 | 0.01983 | 0.02163 |
| 6 | 2101 | 0.94309 | 0.25349 | 0.23206 |
| 7 | 5178 | 0.99107 | 0.14475 | 0.17613 |
| 8 | 1595 | 0.58182 | 0.19910 | 0.27317 |
| 9 | 2313 | 0.98519 | 0.21412 | 0.26956 |
| 10 | 557 | 0.98611 | 0.10877 | 0.32620 |


By comparing the fine-tuned and base scores, we can assess the performance improvement (or degradation) achieved by fine-tuning the model on the specific task or domain.
The analysis shows that the fine-tuned model clearly outperforms the base model across the selected examples, suggesting the fine-tuning process has been quite effective in improving the model’s accuracy and generalization in understanding the specific cause of the component defect and providing suggestions on the consequences.
In the evaluation analysis performed for both selected metrics, we can also highlight some areas for improvement:
- Example repetition – Provide similar examples for further improvements in the vocabulary and generalization of the generated answer, increasing the accuracy of the fine-tuned model.
- Evaluate different data processing techniques – In our example, we selected a subset of the original dataset by analyzing the frequency of words across the entire dataset, extracting the rows containing the most meaningful information and identifying outliers. Further curation of the dataset by properly cleaning and expanding the number of examples can increase the overall performance of the fine-tuned model.
Clean up
After you complete your training and evaluation experiments, clean up your resources to avoid unnecessary charges. If you deployed the model with SageMaker, you can delete the created real-time endpoints using the SageMaker console. Next, delete any unused SageMaker Studio resources. If you deployed the model with Amazon Bedrock Custom Model Import, you can delete the imported model using the Amazon Bedrock console.
Conclusion
This post demonstrated the process of customizing SLMs on AWS for domain-specific applications, focusing on automotive terminology for diagnostics. The provided steps and source code show how to analyze data, fine-tune models, deploy them efficiently, and evaluate their performance against larger base models using SageMaker and Amazon Bedrock. We further highlighted the benefits of customization by enhancing vocabulary within specialized domains.
You can evolve this solution further by implementing proper ML pipelines and LLMOps practices through Amazon SageMaker Pipelines. SageMaker Pipelines enables you to automate and streamline the end-to-end workflow, from data preparation to model deployment, enhancing reproducibility and efficiency. You can also improve the quality of training data using advanced data processing techniques. Additionally, using the Reinforcement Learning from Human Feedback (RLHF) approach can align the model response to human preferences. These enhancements can further elevate the performance of customized language models across various specialized domains. You can find the sample code discussed in this post on the GitHub repo.
About the authors
 Bruno Pistone is a Senior Generative AI and ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations
Bruno Pistone is a Senior Generative AI and ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations
 Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive and Industrial customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive and Industrial customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
Automate emails for task management using Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, and Amazon Bedrock Guardrails
In this post, we demonstrate how to create an automated email response solution using Amazon Bedrock and its features, including Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, and Amazon Bedrock Guardrails.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon Web Services available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure.
With Amazon Bedrock and other AWS services, you can build a generative AI-based email support solution to streamline email management, enhancing overall customer satisfaction and operational efficiency.
Challenges of knowledge management
Email serves as a crucial communication tool for businesses, but traditional processing methods such as manual processing often fall short when handling the volume of incoming messages. This can lead to inefficiencies, delays, and errors, diminishing customer satisfaction.
Key challenges include the need for ongoing training for support staff, difficulties in managing and retrieving scattered information, and maintaining consistency across different agents’ responses.
Organizations possess extensive repositories of digital documents and data that may remain underutilized due to their unstructured and dispersed nature. Additionally, although specific APIs and applications exist to handle customer service tasks, they often function in silos and lack integration.
The benefits of AI-powered solutions
To address these challenges, businesses are adopting generative AI to automate and refine email response processes. AI integration accelerates response times and increases the accuracy and relevance of communications, enhancing customer satisfaction. By using AI-driven solutions, organizations can overcome the limitations of manual email processing, streamlining operations and improving the overall customer experience.
A robust AI-driven email support agent must have the following capabilities:
- Comprehensively access and apply knowledge – Extract and use information from various file formats and data stores across the organization to inform customer interactions.
- Seamlessly integrate with APIs – Interact with existing business APIs to perform real-time actions such as transaction processing or customer data updates directly through email.
- Incorporate continuous awareness – Continually integrate new data, such as updated documents or revised policies, allowing the AI to recognize and use the latest information without retraining.
- Uphold security and compliance standards – Adhere to required data security protocols and compliance mandates specific to the industry to protect sensitive customer information and maintain trust. Implement governance mechanisms to make sure AI-generated responses align with brand standards and regulatory requirements, preventing non-relevant communications.
Solution overview
This section outlines the architecture designed for an email support system using generative AI. The following diagram illustrates the integration of various components crucial for improving the handling of customer emails.

High Level System Design
The solution consists of the following components:
- Email service – This component manages incoming and outgoing customer emails, serving as the primary interface for email communications.
- AI-powered email processing engine – Central to the solution, this engine uses AI to analyze and process emails. It interacts with databases and APIs, extracting necessary information and determining appropriate responses to provide timely and accurate customer service.
- Information repository – This repository holds essential documents and data that support customer service processes. The AI engine accesses this resource to pull relevant information needed to effectively address customer inquiries.
- Business applications – This component performs specific actions identified from email requests, such as processing transactions or updating customer records, enabling prompt and precise fulfillment of customer needs.
- Non-functional requirements (NFRs) – This includes the following:
- Security – Protects data and secures processing across interactions to maintain customer trust.
- Monitoring – Monitors system performance and user activity to maintain operational reliability and efficiency.
- Performance – Provides high efficiency and speed in email responses to sustain customer satisfaction.
- Brand protection – Maintains the quality and consistency of customer interactions, protecting the company’s reputation.
The following diagram provides a detailed view of the architecture to enhance email support using generative AI. This system integrates various AWS services and custom components to automate the processing and handling of customer emails efficiently and effectively.

The workflow includes the following steps:
- Amazon WorkMail manages incoming and outgoing customer emails. When a customer sends an email, WorkMail receives it and invokes the next component in the workflow.
- An email handler AWS Lambda function is invoked by WorkMail upon the receipt of an email, and acts as the intermediary that receives requests and passes it to the appropriate agent.
- These AI agents process the email content, apply decision-making logic, and draft email responses based on the customer’s inquiry and relevant data accessed.
- Guardrails make sure the interactions conform to predefined standards and policies to maintain consistency and accuracy.
- The system indexes documents and files stored in Amazon Simple Storage Service (Amazon S3) using Amazon OpenSearch Service for quick retrieval. These indexed documents provide a comprehensive knowledge base that the AI agents consult to inform their responses.
- Business APIs are invoked by AI agents when specific transactions or updates need to be run in response to a customer’s request. The APIs make sure actions taken are appropriate and accurate according to the processed instructions.
- After the response email is finalized by the AI agents, it’s sent to Amazon Simple Email Service (Amazon SES).
- Amazon SES dispatches the response back to the customer, completing the interaction loop.
Deploy the solution
To evaluate this solution, we have provided sample code that allows users to make a restaurant reservation through email and ask other questions about the restaurant, such as menu offerings. Refer to the GitHub repository for deployment instructions.
The high-level deployment steps are as follows:
- Install the required prerequisites, including the AWS Command Line Interface (AWS CLI), Node.js, and AWS Cloud Development Kit (AWS CDK), then clone the repository and install the necessary NPM packages.
- Deploy the AWS CDK project to provision the required resources in your AWS account.
- Follow the post-deployment steps in the GitHub repository’s README file to configure an email support account to receive emails in WorkMail to invoke the Lambda function upon email receipt.
When the deployment is successful (which may take 7–10 minutes to complete), you can start testing the solution.
Test the solution
This solution uses Amazon Bedrock to automate restaurant table reservations and menu inquiries as an example; however, a similar approach can be adapted for various industries and workflows. Traditionally, customers email restaurants for these services, requiring staff to respond manually. By automating these processes, the solution streamlines operations, reduces manual effort, and enhances user experience by delivering real-time responses.
You can send an email to the support email address to test the generative AI system’s ability to process requests, make reservations, and provide menu information while adhering to the guardrails.
- On the WorkMail console, navigate to the organization gaesas-stk-org-<random id>.
- Choose Users in the navigation pane, and navigate to the support user.
- Locate the email address for this user.

- Send an email requesting information from the automated support account using your preferred email application.
The following image shows a conversation between the customer and the automated support agent.

Clean up
To clean up resources, run the following command from the project’s folder:
Conclusion
In this post, we examined how you can integrate AWS services to build a generative AI-based email support solution. By using WorkMail for handling email traffic, Lambda for the processing logic, and Amazon SES for dispatching responses, the system efficiently manages and responds to customer emails. Additionally, Amazon Bedrock agents, supplemented by guardrails and supported by an OpenSearch Service powered information repository, make sure responses are accurate and compliant with regulatory standards. This cohesive use of AWS services not only streamlines email management but also makes sure each customer interaction is handled with precision, enhancing overall customer satisfaction and operational efficiency.
You can adapt and extend the business logic and processes demonstrated in this solution to suit specific organizational needs. Developers can modify the Lambda functions, update the knowledge bases, and adjust the agent behavior to align with unique business requirements. This flexibility empowers you to tailor the solution, providing a seamless integration with your existing systems and workflows.
About the Authors
 Manu Mishra is a Senior Solutions Architect at AWS with over 16 years of experience in the software industry, specializing in artificial intelligence, data and analytics, and security. His expertise spans strategic oversight and hands-on technical leadership, where he reviews and guides the work of both internal and external customers. Manu collaborates with AWS customers to shape technical strategies that drive impactful business outcomes, providing alignment between technology and organizational goals.
Manu Mishra is a Senior Solutions Architect at AWS with over 16 years of experience in the software industry, specializing in artificial intelligence, data and analytics, and security. His expertise spans strategic oversight and hands-on technical leadership, where he reviews and guides the work of both internal and external customers. Manu collaborates with AWS customers to shape technical strategies that drive impactful business outcomes, providing alignment between technology and organizational goals.
 AK Soni is a Senior Technical Account Manager with AWS Enterprise Support, where he empowers enterprise customers to achieve their business goals by offering proactive guidance on implementing innovative cloud and AI/ML-based solutions aligned with industry best practices. With over 19 years of experience in enterprise application architecture and development, he uses his expertise in generative AI technologies to enhance business operations and overcome existing technological limitations. As a part of the AI/ML community at AWS, AK guides customers in designing generative AI solutions and trains AI/ML enthusiastic AWS employees to gain membership in the AWS generative AI community, providing valuable insights and recommendations to harness the power of generative AI.
AK Soni is a Senior Technical Account Manager with AWS Enterprise Support, where he empowers enterprise customers to achieve their business goals by offering proactive guidance on implementing innovative cloud and AI/ML-based solutions aligned with industry best practices. With over 19 years of experience in enterprise application architecture and development, he uses his expertise in generative AI technologies to enhance business operations and overcome existing technological limitations. As a part of the AI/ML community at AWS, AK guides customers in designing generative AI solutions and trains AI/ML enthusiastic AWS employees to gain membership in the AWS generative AI community, providing valuable insights and recommendations to harness the power of generative AI.
Accelerate analysis and discovery of cancer biomarkers with Amazon Bedrock Agents
According to the National Cancer Institute, a cancer biomarker is a “biological molecule found in blood, other body fluids, or tissues that is a sign of a normal or abnormal process, or of a condition or disease such as cancer.” Biomarkers typically differentiate an affected patient from a person without the disease. Well-known cancer biomarkers include EGFR for lung cancer, HER2 for breast cancer, PSA for prostrate cancer, and so on. The BEST (Biomarkers, EndpointS, and other Tools) resource categorizes biomarkers into several types such as diagnostic, prognostic, and predictive biomarkers that can be measured with various techniques including molecular, imaging, and physiological measurements.
A study published in Nature Reviews Drug Discovery mentions that the overall success rate for oncology drugs from Phase I to approval is only around 5%. Biomarkers play a crucial role in enhancing the success of clinical development by improving patient stratification for trials, expediting drug development, reducing costs and risks, and enabling personalized medicine. For example, a study of 1,079 oncology drugs found that the success rates for drugs developed with a biomarker was 24% versus 6% for compounds developed without biomarkers.
Research scientists and real-world evidence (RWE) experts face numerous challenges to analyze biomarkers and validate hypotheses for biomarker discovery with their existing set of tools. Most notably, this includes manual and time-consuming steps for search, summarization, and insight generation across various biomedical literature (for example, PubMed), public scientific databases (for example, Protein Data Bank), commercial data banks and internal enterprise proprietary data. They want to quickly use, modify, or develop tools necessary for biomarker identification and correlation across modalities, indications, drug exposures and treatments, and associated endpoint outcomes such as survival. Each experiment might employ various combinations of data, tools, and visualization. Evidence in scientific literature should be simple to identify and cite with relevant context.
Amazon Bedrock Agents enables generative AI applications to execute multistep tasks across internal and external resources. Bedrock agents can streamline workflows and provide AI automation to boost productivity. In this post, we show you how agentic workflows with Amazon Bedrock Agents can help accelerate this journey for research scientists with a natural language interface. We define an example analysis pipeline, specifically for lung cancer survival with clinical, genomics, and imaging modalities of biomarkers. We showcase a variety of tools including database retrieval with Text2SQL, statistical models and visual charts with scientific libraries, biomedical literature search with public APIs and internal evidence, and medical image processing with Amazon SageMaker jobs. We demonstrate advanced capabilities of agents for self-review and planning that help build trust with end users by breaking down complex tasks into a series of steps and showing the chain of thought to generate the final answer. The code for this solution is available in GitHub.
Multi-modal biomarker analysis workflow
Some example scientific requirements from research scientists analyzing multi-modal patient biomarkers include:
- What are the top five biomarkers associated with overall survival? Show me a Kaplan Meier plot for high and low risk patients.
- According to literature evidence, what properties of the tumor are associated with metagene X activity and EGFR pathway?
- Can you compute the imaging biomarkers for patient cohort with low gene X expression? Show me the tumor segmentation and the sphericity and elongation values.
To answer the preceding questions, research scientists typically run a survival analysis pipeline (as shown in the following illustration) with multimodal data; including clinical, genomic, and computed tomography (CT) imaging data.
They might need to:
- Preprocess programmatically a diverse set of input data, structured and unstructured, and extract biomarkers (radiomic/genomic/clinical and others).
- Conduct statistical survival analyses such as the Cox proportional hazards model, and generate visuals such as Kaplan-Meier curves for interpretation.
- Conduct gene set enrichment analysis (GSEA) to identify significant genes.
- Research relevant literature to validate initial findings.
- Associate findings to radiogenomic biomarkers.

Diagram illustrates cancer biomarker discovery workflow. Four inputs: CT scans, gene data, survival data, and drug data undergo preprocessing. Analysis follows through survival analysis, gene enrichment, evidence gathering, and radio-genomic associations.
Solution overview
We propose a large-language-model (LLM) agents-based framework to augment and accelerate the above analysis pipeline. Design patterns for LLM agents, as described in Agentic Design Patterns Part 1 by Andrew Ng, include the capabilities for reflection, tool use, planning and multi-agent collaboration. An agent helps users complete actions based on both proprietary and public data and user input. Agents orchestrate interactions between foundation models (FMs), data sources, software applications, and user conversations. In addition, agents automatically call APIs to take actions and search knowledge bases to supplement information for these actions.

Architecture diagram showing Agents for Bedrock system flow. Left side shows agents processing steps 1 to n. Right side displays tools including biomarker query engine, scientific analysis tools, data analysis, external APIs, literature store, and medical imaging.
As shown in the preceding figure, we define our solution to include planning and reasoning with multiple tools including:
- Biomarker query engine: Convert natural language questions to SQL statements and execute on an Amazon Redshift database of biomarkers.
- Scientific analysis and plotting engine: Use a custom container with lifelines library to build survival regression models and visualization such as Kaplan Meier charts for survival analysis.
- Custom data analysis: Process intermediate data and generate visualizations such as bar charts automatically to provide further insights. Use custom actions or Code Interpreter functionality with Bedrock Agents.
- External data API: Use PubMed APIs to search biomedical literature for specific evidence.
- Internal literature: Use Amazon Bedrock Knowledge Bases to give agents contextual information from internal literature evidence for Retrieval Augmented Generation (RAG) to deliver responses from a curated repository of publications.
- Medical imaging: Use Amazon SageMaker jobs to augment agents with the capability to trigger asynchronous jobs with an ephemeral cluster to process CT scan images.
Dataset description
The non-small cell lung cancer (NSCLC) radiogenomic dataset comprises medical imaging, clinical, and genomic data collected from a cohort of early-stage NSCLC patients referred for surgical treatment. Each data modality presents a different view of a patient. It consists of clinical data reflective of electronic health records (EHR) such as age, gender, weight, ethnicity, smoking status, tumor node metastasis (TNM) stage, histopathological grade, and survival outcome. The genomic data contains gene mutation and RNA sequencing data from samples of surgically excised tumor tissue. It includes CT, positron emission tomography (PET)/CT images, semantic annotations of the tumors as observed on the medical images using a controlled vocabulary, segmentation maps of tumors in the CT scans, and quantitative values obtained from the PET/CT scans.
We reuse the data pipelines described in this blog post.
Clinical data
The data is stored in CSV format as shown in the following table. Each row corresponds to the medical records of a patient.

Sample table from NSCLC dataset showing two patient records. Data includes demographics (age, weight), clinical history (smoking status), and treatment information (chemotherapy, EGFR mutation status). Case R01-005 shows a deceased 84-year-old former smoker, while R01-006 shows a living 62-year-old former smoker.
Genomics data
The following table shows the tabular representation of the gene expression data. Each row corresponds to a patient, and the columns represent a subset of genes selected for demonstration. The value denotes the expression level of a gene for a patient. A higher value means the corresponding gene is highly expressed in that specific tumor sample.

Table displays gene expression data for patients R01-024 and R01-153. Shows expression levels for genes IRIG1, HPGD, GDF15, CDH2, and POSTN. Values range from 0 to 36.4332, with CDH2 showing no expression (0) in both cases.
Medical imaging data
The following image is an example overlay of a tumor segmentation onto a lung CT scan (case R01-093 in the dataset).

Three grayscale CT scan views of lungs showing tumor segmentation marked with bright spots. Images display frontal, sagittal, and axial views of the lung, each with crosshair markers indicating the tumor location.
Deployment and getting started
Follow the deployment instructions described in the GitHub repo.
Full deployment takes approximately 10–15 minutes. After deployment, you can access the sample UI to test the agent with sample questions available in the UI or the chain of thought reasoning example.
The stack can also be launched in the us-east-1 or us-west-2 AWS Regions by choosing launch stack in the following:
| Region | Infrastructure.yaml |
|---|---|
| us-east-1 |  |
| us-west-2 | |
Amazon Bedrock Agents deep dive
The following diagram describes the key components of the agent that interacts with the users through a web application.

Architecture diagram showcasing Agents for Bedrock as the central orchestrator. The Agent processes user queries by coordinating multiple tools: handling biomarker queries through Redshift, running scientific analysis with Lambda, searching biomedical literature, and processing medical images via SageMaker. The Agent uses foundation models hosted on Amazon Bedrock to understand requests and generate responses.
Large language models
LLMs, such as Anthropic’s Claude or Amazon Titan models, possess the ability to understand and generate human-like text. They enable agents to comprehend user queries, generate appropriate responses, and perform complex reasoning tasks. In the deployment, we use Anthropic’s Claude 3 Sonnet model.
Prompt templates
Prompt templates are pre-designed structures that guide the LLM’s responses and behaviors. These templates help shape the agent’s personality, tone, and specific capabilities to understand scientific terminology. By carefully crafting prompt templates, you can help make sure that agents maintain consistency in their interactions and adhere to specific guidelines or brand voice. Amazon Bedrock Agents provides default prompt templates for pre-processing users’ queries, orchestration, a knowledge base, and a post-processing template.
Instructions
In addition to the prompt templates, instructions describe what the agent is designed to do and how it can interact with users. You can use instructions to define the role of a specific agent and how it can use the available set of actions under different conditions. Instructions are augmented with the prompt templates as context for each invocation of the agent. You can find how we define our agent instructions in agent_build.yaml.
User input
User input is the starting point for an interaction with an agent. The agent processes this input, understanding the user’s intent and context, and then formulates an appropriate chain of thought. The agent will determine whether it has the required information to answer the user’s question or need to request more information from the user. If more information is required from the user, the agent will formulate the question to request additional information. Amazon Bedrock Agents are designed to handle a wide range of user inputs, from simple queries to complex, multi-turn conversations.
Amazon Bedrock Knowledge Bases
The Amazon Bedrock knowledge base is a repository of information that has been vectorized from the source data and that the agent can access to supplement its responses. By integrating an Amazon Bedrock knowledge base, agents can provide more accurate and contextually appropriate answers, especially for domain-specific queries that might not be covered by the LLM’s general knowledge. In this solution, we include literature on non-small cell lung cancer that can represent internal evidence belonging to a customer.
Action groups
Action groups are collections of specific functions or API calls that Amazon Bedrock Agents can perform. By defining action groups, you can extend the agent’s capabilities beyond mere conversation, enabling it to perform practical, real-world tasks. The following tools are made available to the agent through action groups in the solution. The source code can be found in the ActionGroups folder in the repository.
- Text2SQL and Redshift database invocation: The Text2SQL action group allows the agent to get the relevant schema of the Redshift database, generate a SQL query for the particular sub-question, review and refine the SQL query with an additional LLM invocation, and finally execute the SQL query to retrieve the relevant results from the Redshift database. The action group contains OpenAPI schema for these actions. If the query execution returns a result greater than the acceptable lambda return payload size, the action group writes the data to an intermediate Amazon Simple Storage Service (Amazon S3) location instead.
- Scientific analysis with a custom container: The scientific analysis action group allows the agent to use a custom container to perform scientific analysis with specific libraries and APIs. In this solution, these include tasks such as fitting survival regression models and Kaplan Meier plot generation for survival analysis. The custom container allows a user to verify that the results are repeatable without deviations in library versions or algorithmic logic. This action group defines functions with specific parameters for each of the required tasks. The Kaplan Meier plot is output to Amazon S3.
- Custom data analysis: By enabling Code Interpreter with the Amazon Bedrock agent, the agent can generate and execute Python code in a secure compute environment. You can use this to run custom data analysis with code and generate generic visualizations of the data.
- Biomedical literature evidence with PubMed: The PubMed action group allows the agent to interact with the PubMed Entrez Programming Utilities (E-utilities) API to fetch biomedical literature. The action group contains OpenAPI schema that accepts user queries to search across PubMed for articles. The Lambda function provides a convenient way to search for and retrieve scientific articles from the PubMed database. It allows users to perform searches using specific queries, retrieve article metadata, and handle the complexities of API interactions. Overall, the agent uses this action group and serves as a bridge between a researcher’s query and the PubMed database, simplifying the process of accessing and processing biomedical research information.
- Medical imaging with SageMaker jobs: The medical imaging action group allows the agent to process CT scan images of specific patient groups by triggering a SageMaker processing job. We re-use the medical imaging component from this previous blog.
The action group creates patient-level 3-dimensional radiomic features that explain the size, shape, and visual attributes of the tumors observed in the CT scans and stores them in Amazon S3. For each patient study, the following steps are performed, as shown in the figure that follows:
-
- Read the 2D DICOM slice files for both the CT scan and tumor segmentation, combine them to 3D volumes, and save the volumes in NIfTI format.
- Align CT volume and tumor segmentation so we can focus the computation inside the tumor.
- Compute radiomic features describing the tumor region using the pyradiomics library. It extracts 120 radiomic features of eight classes such as statistical representations of the distribution and co-occurrence of the intensity within the tumorous region of interest, and shape-based measurements describing the tumor morphologically.

Workflow diagram illustrating the medical image processing steps for tumor analysis. Process starts with 2D DICOM files (scan and segmentation) from S3 bucket, combines them into 3D volumes in NIfTI format, aligns CT study with segmentation, and ends with radiomic feature computation. Icons show each stage: document icons for DICOM files, S3 bucket symbol, lung CT scan images, segmented tumor view, and tabular data representing extracted features. Green arrows indicate data flow between stages.
Chain of thought reasoning and responses
Let’s look at a few examples of chain of thought reasoning and execution with the agent. The agent interprets the user question, generates a sequence of steps, and executes them with the relevant action group.
To respond to the following questions, the agent sets up the following orchestration workflows with the available action groups.
Question 1:
What is the best gene expression biomarker (lowest p value) with overall survival for patients that have undergone chemotherapy, show me a bar chart with the top five biomarkers.
Steps:
- Get DB schema and generate SQL
- Review and refine the SQL with self-evaluation
- Execute the SQL query and store the results in Amazon S3
- Fit a survival regression model with the custom container API
- Retrieve the model fit summary results and sort the top five biomarkers based on the lowest p-value
- Generate a bar chart with the top five biomarkers
- Summarize the result to the user
Agent response: Gene biomarker ‘gdf15’ has the lowest p value of 0.02, therefore gdf15 is the best gene biomarker. The bar chart shows the top 5 biomarkers and their corresponding p values.
Question 2:
Show me a Kaplan Meier plot for chemotherapy patients stratified by GDF15 expression levels less than 10 and greater than 10.
Steps:
- Get DB schema and generate SQL
- Review and refine the SQL with self-evaluation
- Execute the SQL query and retrieve the results
- Process survival data by splitting it into 2 groups based on threshold
- Generate a Kaplan-Meier survival chart for baseline and condition groups
- Summarize the results to the user
Agent response: The Kaplan-Meier chart has been output to Amazon S3 and shows the survival curves for the two groups of chemotherapy patients stratified by their gdf15 expression levels. A clear separation between the curves indicates that the baseline group (less than 10) has better survival outcomes than the condition group (greater than 10).
Question 3:
Can you compute the imaging biomarkers for patient cohort with low gene X expression? Show me the tumor segmentation and the sphericity and elongation values.
Steps:
- Get DB schema and generate SQL
- Review and refine the SQL with self-evaluation
- Execute the SQL query and identify the patient cohort
- Compute imaging biomarkers for each patient in the cohort with a SageMaker medical imaging job
- Wait for job execution to complete
- On job completion, retrieve and analyze the results
- Extract the required biomarkers and visualize the tumor segmentation output images
Agent response: The compute imaging biomarker job to process the medical images of the patients was triggered and is now complete. The following patients were selected based on their gene X expression values. The elongation and sphericity values for the patient tumors are displayed along with the corresponding tumor segmentation images.
Conclusion
Research scientists face significant challenges in identifying and validating biomarkers specific to cancer subtypes and relevant to interventions and patient outcomes. Existing tools often require intensive manual steps to search, summarize, and generate insights across diverse data sources. This post has demonstrated how Amazon Bedrock Agents can offer a flexible framework and relevant tools to help accelerate this critical discovery process.
By providing an example analysis pipeline for lung cancer survival, we showcased how these agentic workflows use a natural language interface, database retrieval, statistical modeling, literature search, and medical image processing to transform complex research queries into actionable insights. The agent used advanced and intelligent capabilities such as self-review and planning, breaking down tasks into step-by-step analyses and transparently displaying the chain of thought behind the final answers. While the potential impact of this technology on pharmaceutical research and clinical trial outcomes remains to be fully realized, solutions like this can help automate data analysis and hypothesis validation tasks.
The code for this solution is available on GitHub, and we encourage you to explore and build upon this template. For examples to get started with Amazon Bedrock Agents, check out the Amazon Bedrock Agents GitHub repository.
About the Authors
 Hasan Poonawala is a Senior AI/ML Solutions Architect at AWS, working with Healthcare and Life Sciences customers. Hasan helps design, deploy and scale Generative AI and Machine learning applications on AWS. He has over 15 years of combined work experience in machine learning, software development and data science on the cloud. In his spare time, Hasan loves to explore nature and spend time with friends and family.
Hasan Poonawala is a Senior AI/ML Solutions Architect at AWS, working with Healthcare and Life Sciences customers. Hasan helps design, deploy and scale Generative AI and Machine learning applications on AWS. He has over 15 years of combined work experience in machine learning, software development and data science on the cloud. In his spare time, Hasan loves to explore nature and spend time with friends and family.
 Michael Hsieh is a Principal AI/ML Specialist Solutions Architect. He works with HCLS customers to advance their ML journey with AWS technologies and his expertise in medical imaging. As a Seattle transplant, he loves exploring the great mother nature the city has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at Shilshole Bay.
Michael Hsieh is a Principal AI/ML Specialist Solutions Architect. He works with HCLS customers to advance their ML journey with AWS technologies and his expertise in medical imaging. As a Seattle transplant, he loves exploring the great mother nature the city has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at Shilshole Bay.
 Nihir Chadderwala is a Senior AI/ML Solutions Architect on the Global Healthcare and Life Sciences team. His background is building big data and AI-powered solutions to customer problems in a variety of domains such as software, media, automotive, and healthcare. In his spare time, he enjoys playing tennis, and watching and reading about Cosmos.
Nihir Chadderwala is a Senior AI/ML Solutions Architect on the Global Healthcare and Life Sciences team. His background is building big data and AI-powered solutions to customer problems in a variety of domains such as software, media, automotive, and healthcare. In his spare time, he enjoys playing tennis, and watching and reading about Cosmos.
 Zeek Granston is an Associate AI/ML Solutions Architect focused on building effective artificial intelligence and machine learning solutions. He stays current with industry trends to deliver practical results for clients. Outside of work, Zeek enjoys building AI applications, and playing basketball.
Zeek Granston is an Associate AI/ML Solutions Architect focused on building effective artificial intelligence and machine learning solutions. He stays current with industry trends to deliver practical results for clients. Outside of work, Zeek enjoys building AI applications, and playing basketball.