 Kent Walker shares three national security imperatives for the AI era.Read More
Kent Walker shares three national security imperatives for the AI era.Read More

Kent Walker shares three national security imperatives for the AI era.Read More
We are excited to announce the release of PyTorch® 2.6 (release notes)! This release features multiple improvements for PT2: torch.compile can now be used with Python 3.13; new performance-related knob torch.compiler.set_stance; several AOTInductor enhancements. Besides the PT2 improvements, another highlight is FP16 support on X86 CPUs.
NOTE: Starting with this release we are not going to publish on Conda, please see [Announcement] Deprecating PyTorch’s official Anaconda channel for the details.
For this release the experimental Linux binaries shipped with CUDA 12.6.3 (as well as Linux Aarch64, Linux ROCm 6.2.4, and Linux XPU binaries) are built with CXX11_ABI=1 and are using the Manylinux 2.28 build platform. If you build PyTorch extensions with custom C++ or CUDA extensions, please update these builds to use CXX_ABI=1 as well and report any issues you are seeing. For the next PyTorch 2.7 release we plan to switch all Linux builds to Manylinux 2.28 and CXX11_ABI=1, please see [RFC] PyTorch next wheel build platform: manylinux-2.28 for the details and discussion.
Also in this release as an important security improvement measure we have changed the default value for weights_only parameter of torch.load. This is a backward compatibility-breaking change, please see this forum post for more details.
This release is composed of 3892 commits from 520 contributors since PyTorch 2.5. We want to sincerely thank our dedicated community for your contributions. As always, we encourage you to try these out and report any issues as we improve PyTorch. More information about how to get started with the PyTorch 2-series can be found at our Getting Started page.
| Beta | Prototype |
| torch.compiler.set_stance | Improved PyTorch user experience on Intel GPUs |
| torch.library.triton_op | FlexAttention support on X86 CPU for LLMs |
| torch.compile support for Python 3.13 | Dim.AUTO |
| New packaging APIs for AOTInductor | CUTLASS and CK GEMM/CONV Backends for AOTInductor |
| AOTInductor: minifier | |
| AOTInductor: ABI-compatible mode code generation | |
| FP16 support for X86 CPUs |
*To see a full list of public feature submissions click here.
This feature enables the user to specify different behaviors (“stances”) that torch.compile can take between different invocations of compiled functions. One of the stances, for example, is
“eager_on_recompile”, that instructs PyTorch to code eagerly when a recompile is necessary, reusing cached compiled code when possible.
For more information please refer to the set_stance documentation and the Dynamic Compilation Control with torch.compiler.set_stance tutorial.
torch.library.triton_op offers a standard way of creating custom operators that are backed by user-defined triton kernels.
When users turn user-defined triton kernels into custom operators, torch.library.triton_op allows torch.compile to peek into the implementation, enabling torch.compile to optimize the triton kernel inside it.
For more information please refer to the triton_op documentation and the Using User-Defined Triton Kernels with torch.compile tutorial.
torch.compile previously only supported Python up to version 3.12. Users can now optimize models with torch.compile in Python 3.13.
A new package format, “PT2 archive”, has been introduced. This essentially contains a zipfile of all the files that need to be used by AOTInductor, and allows users to send everything needed to other environments. There is also functionality to package multiple models into one artifact, and to store additional metadata inside of the package.
For more details please see the updated torch.export AOTInductor Tutorial for Python runtime.
If a user encounters an error while using AOTInductor APIs, AOTInductor Minifier allows creation of a minimal nn.Module that reproduces the error.
For more information please see the AOTInductor Minifier documentation.
AOTInductor-generated model code has dependency on Pytorch cpp libraries. As Pytorch evolves quickly, it’s important to make sure previously AOTInductor compiled models can continue to run on newer Pytorch versions, i.e. AOTInductor is backward compatible.
In order to guarantee application binary interface (ABI) backward compatibility, we have carefully defined a set of stable C interfaces in libtorch and make sure AOTInductor generates code that only refers to the specific set of APIs and nothing else in libtorch. We will keep the set of C APIs stable across Pytorch versions and thus provide backward compatibility guarantees for AOTInductor-compiled models.
Float16 datatype is commonly used for reduced memory usage and faster computation in AI inference and training. CPUs like the recently launched Intel® Xeon® 6 with P-Cores support Float16 datatype with native accelerator AMX. Float16 support on X86 CPUs was introduced in PyTorch 2.5 as a prototype feature, and now it has been further improved for both eager mode and Torch.compile + Inductor mode, making it Beta level feature with both functionality and performance verified with a broad scope of workloads.
PyTorch user experience on Intel GPUs is further improved with simplified installation steps, Windows release binary distribution and expanded coverage of supported GPU models including the latest Intel® Arc™ B-Series discrete graphics. Application developers and researchers seeking to fine-tune, inference and develop with PyTorch models on Intel® Core™ Ultra AI PCs and Intel® Arc™ discrete graphics will now be able to directly install PyTorch with binary releases for Windows, Linux and Windows Subsystem for Linux 2.
For more information regarding Intel GPU support, please refer to Getting Started Guide.
FlexAttention was initially introduced in PyTorch 2.5 to provide optimized implementations for Attention variants with a flexible API. In PyTorch 2.6, X86 CPU support for FlexAttention was added through TorchInductor CPP backend. This new feature leverages and extends current CPP template abilities to support broad attention variants (e.x.: PageAttention, which is critical for LLMs inference) based on the existing FlexAttention API, and brings optimized performance on x86 CPUs. With this feature, it’s easy to use FlexAttention API to compose Attention solutions on CPU platforms and achieve good performance.
Dim.AUTO allows usage of automatic dynamic shapes with torch.export. Users can export with Dim.AUTO and “discover” the dynamic behavior of their models, with min/max ranges, relations between dimensions, and static/dynamic behavior being automatically inferred.
This is a more user-friendly experience compared to the existing named-Dims approach for specifying dynamic shapes, which requires the user to fully understand the dynamic behavior of their models at export time. Dim.AUTO allows users to write generic code that isn’t model-dependent, increasing ease-of-use for exporting with dynamic shapes.
Please see torch.export tutorial for more information.
The CUTLASS and CK backend adds kernel choices for GEMM autotuning in Inductor. This is now also available in AOTInductor which can run in C++ runtime environments. A major improvement to the two backends is improved compile-time speed by eliminating redundant kernel binary compilations and dynamic shapes support.
Scaling the capacity of language models has consistently proven to be a reliable approach for
improving performance and unlocking new capabilities. Capacity can be primarily defined by
two dimensions: the number of model parameters and the compute per example. While scaling
typically involves increasing both, the precise interplay between these factors and their combined contribution to overall capacity remains not fully understood. We explore this relationship
in the context of sparse Mixture-of-Experts (MoEs) , which allow scaling the number of parameters without proportionally increasing…Apple Machine Learning Research
We give a principled method for decomposing the predictive uncertainty of a model into aleatoric and epistemic components with explicit semantics relating them to the real-world data distribution. While many works in the literature have proposed such decompositions, they lack the type of formal guarantees we provide. Our method is based on the new notion of higher-order calibration, which generalizes ordinary calibration to the setting of higher-order predictors that predict mixtures over label distributions at every point. We show how to measure as well as achieve higher-order calibration…Apple Machine Learning Research
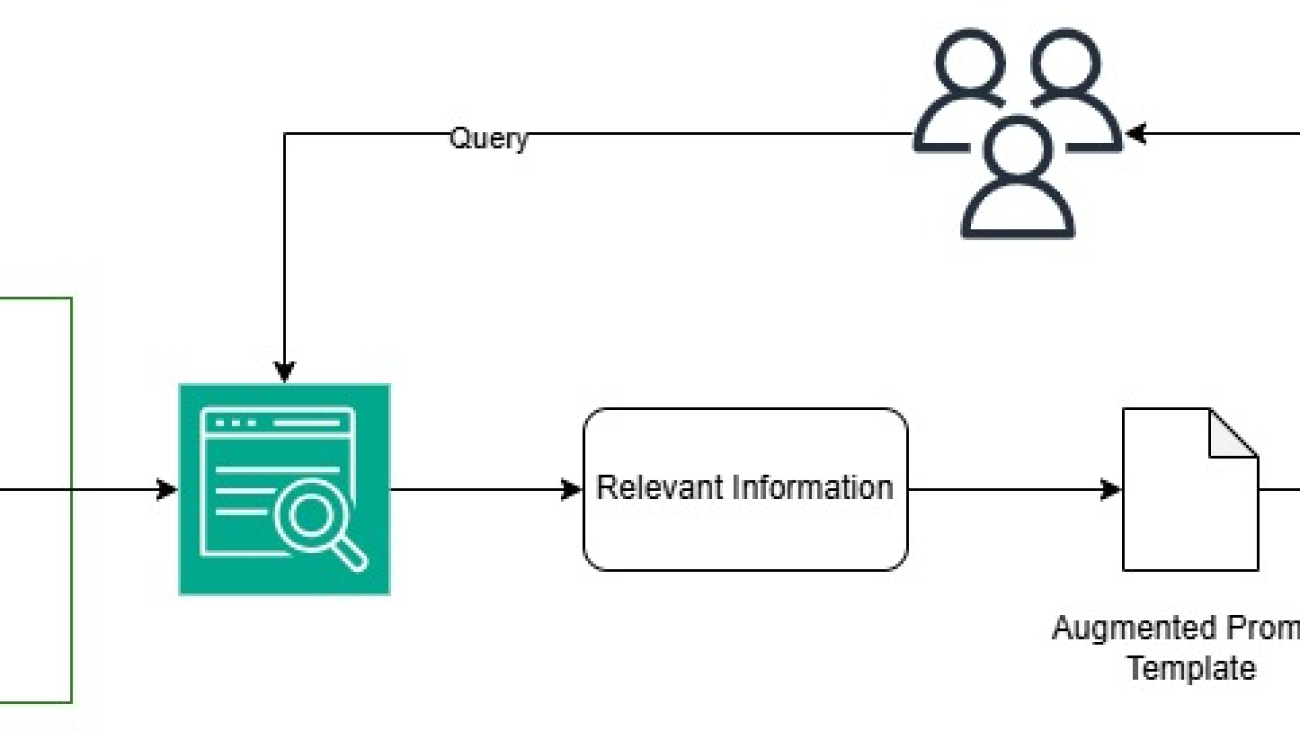
Generative AI and large language models (LLMs) are revolutionizing organizations across diverse sectors to enhance customer experience, which traditionally would take years to make progress. Every organization has data stored in data stores, either on premises or in cloud providers.
You can embrace generative AI and enhance customer experience by converting your existing data into an index on which generative AI can search. When you ask a question to an open source LLM, you get publicly available information as a response. Although this is helpful, generative AI can help you understand your data along with additional context from LLMs. This is achieved through Retrieval Augmented Generation (RAG).
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLM’s knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of data preparation is required, which involves a big learning curve.
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud. Aurora combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open source databases.
In this post, we walk you through how to convert your existing Aurora data into an index without needing data preparation for Amazon Kendra to perform data search and implement RAG that combines your data along with LLM knowledge to produce accurate responses.
In this solution, use your existing data as a data source (Aurora), create an intelligent search service by connecting and syncing your data source to Amazon Kendra search, and perform generative AI data search, which uses RAG to produce accurate responses by combining your data along with the LLM’s knowledge. For this post, we use Anthropic’s Claude on Amazon Bedrock as our LLM.
The following are the high-level steps for the solution:
The following diagram illustrates the solution architecture.

To follow this post, the following prerequisites are required:
Run the following AWS CLI commands to create an Aurora PostgreSQL Serverless v2 cluster:
The following screenshot shows the created instance.

Connect to the Aurora instance using the pgAdmin tool. Refer to Connecting to a DB instance running the PostgreSQL database engine for more information. To ingest your data, complete the following steps:



The Amazon Kendra index holds the contents of your documents and is structured in a way to make the documents searchable. It has three index types:
To create an Amazon Kendra index, complete the following steps:
genai-kendra-index).genai-kendra). Your role name will be prefixed with AmazonKendra-<region>- (for example, AmazonKendra-us-east-2-genai-kendra).



It might take some time for the index to create. Check the list of indexes to watch the progress of creating your index. When the status of the index is ACTIVE, your index is ready to use.
Complete the following steps to set up your data source connector:

data_source_genai_kendra_postgresql).
cvgupdj47zsh.us-east-2.rds.amazonaws.com).5432).genai).
AmazonKendra-Aurora-PostgreSQL-genai-kendra-secret).

select * from employees.amazon_review.pk).reviews_title).reviews_text).After the sync completes successfully, your Amazon Kendra index will contain the data from the specified Aurora PostgreSQL table. You can then use this index for intelligent search and RAG applications.




Your data source will appear on the Data sources page after the data source has been created successfully.

The Amazon Kendra index sync can take minutes to hours depending on the volume of your data. When the sync completes without error, you are ready to develop your RAG solution in your preferred IDE. Complete the following steps:
AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables or by using the ~/.aws/credentials file:
KendraRetriever with your Amazon Kendra index ID by replacing the Kendra_index_id that you created earlier and the Amazon Kendra client:

To avoid incurring future charges, delete the resources you created as part of this post:
In this post, we discussed how to convert your existing Aurora data into an Amazon Kendra index and implement a RAG-based solution for the data search. This solution drastically reduces the data preparation need for Amazon Kendra search. It also increases the speed of generative AI application development by reducing the learning curve behind data preparation.
Try out the solution, and if you have any comments or questions, leave them in the comments section.
 Aravind Hariharaputran is a Data Consultant with the Professional Services team at Amazon Web Services. He is passionate about Data and AIML in general with extensive experience managing Database technologies .He helps customers transform legacy database and applications to Modern data platforms and generative AI applications. He enjoys spending time with family and playing cricket.
Aravind Hariharaputran is a Data Consultant with the Professional Services team at Amazon Web Services. He is passionate about Data and AIML in general with extensive experience managing Database technologies .He helps customers transform legacy database and applications to Modern data platforms and generative AI applications. He enjoys spending time with family and playing cricket.
 Ivan Cui is a Data Science Lead with AWS Professional Services, where he helps customers build and deploy solutions using ML and generative AI on AWS. He has worked with customers across diverse industries, including software, finance, pharmaceutical, healthcare, IoT, and entertainment and media. In his free time, he enjoys reading, spending time with his family, and traveling.
Ivan Cui is a Data Science Lead with AWS Professional Services, where he helps customers build and deploy solutions using ML and generative AI on AWS. He has worked with customers across diverse industries, including software, finance, pharmaceutical, healthcare, IoT, and entertainment and media. In his free time, he enjoys reading, spending time with his family, and traveling.
In production generative AI applications, responsiveness is just as important as the intelligence behind the model. Whether it’s customer service teams handling time-sensitive inquiries or developers needing instant code suggestions, every second of delay, known as latency, can have a significant impact. As businesses increasingly use large language models (LLMs) for these critical tasks and processes, they face a fundamental challenge: how to maintain the quick, responsive performance users expect while delivering the high-quality outputs these sophisticated models promise.
The impact of latency on user experience extends beyond mere inconvenience. In interactive AI applications, delayed responses can break the natural flow of conversation, diminish user engagement, and ultimately affect the adoption of AI-powered solutions. This challenge is compounded by the increasing complexity of modern LLM applications, where multiple LLM calls are often needed to solve a single problem, significantly increasing total processing times.
During re:Invent 2024, we launched latency-optimized inference for foundation models (FMs) in Amazon Bedrock. This new inference feature provides reduced latency for Anthropic’s Claude 3.5 Haiku model and Meta’s Llama 3.1 405B and 70B models compared to their standard versions. This feature is especially helpful for time-sensitive workloads where rapid response is business critical.
In this post, we explore how Amazon Bedrock latency-optimized inference can help address the challenges of maintaining responsiveness in LLM applications. We’ll dive deep into strategies for optimizing application performance and improving user experience. Whether you’re building a new AI application or optimizing an existing one, you’ll find practical guidance on both the technical aspects of latency optimization and real-world implementation approaches. We begin by explaining latency in LLM applications.
Latency in LLM applications is a multifaceted concept that goes beyond simple response times. When you interact with an LLM, you can receive responses in one of two ways: streaming or nonstreaming mode. In nonstreaming mode, you wait for the complete response before receiving any output—like waiting for someone to finish writing a letter. In streaming mode, you receive the response as it’s being generated—like watching someone type in real time.
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications.
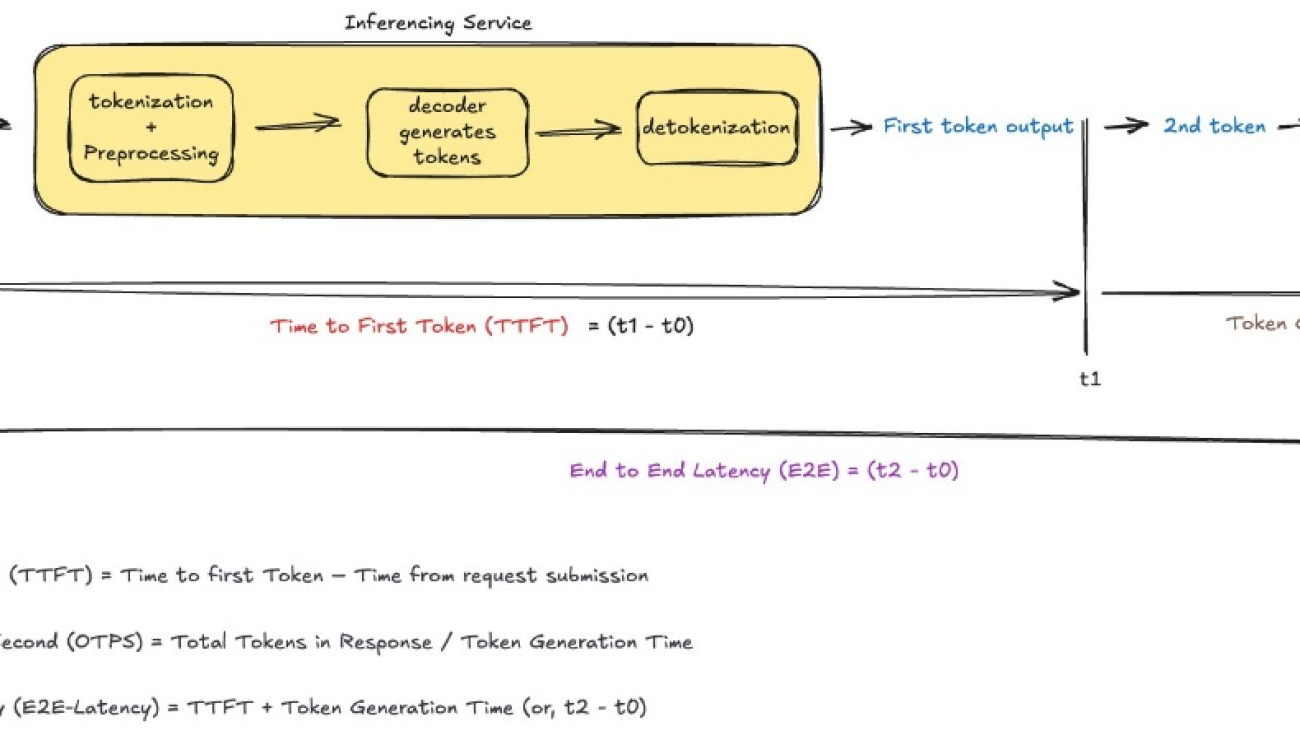
Time to first token (TTFT) represents how quickly your streaming application starts responding. It’s the amount of time from when a user submits a request until they receive the beginning of a response (the first word, token, or chunk). Think of it as the initial reaction time of your AI application.
TTFT is affected by several factors:
Calculation: TTFT = Time to first chunk/token – Time from request submission
Interpretation: Lower is better
Output tokens per second (OTPS) indicates how quickly your model generates new tokens after it starts responding. This metric is crucial for understanding the actual throughput of your model and how it maintains its response speed throughout longer generations.
OTPS is influenced by:
Calculation: OTPS = Total number of output tokens / Total generation time
Interpretation: Higher is better
End-to-end latency (E2E) measures the total time from request to complete response. As illustrated in the figure above, this encompasses the entire interaction.
Key factors affecting this metric include:
Calculation: E2E latency = Time at completion of request – Time from request submission
Interpretation: Lower is better
Although these metrics provide a solid foundation for understanding latency, there are additional factors and considerations that can impact the perceived performance of LLM applications. These metrics are shown in the following diagram.

An often-overlooked aspect of latency is how different models tokenize text differently. Each model’s tokenization strategy is defined by its provider during training and can’t be modified. For example, a prompt that generates 100 tokens in one model might generate 150 tokens in another. When comparing model performance, remember that these inherent tokenization differences can affect perceived response times, even when the models are equally efficient. Awareness of this variation can help you better interpret latency differences between models and make more informed decisions when selecting models for your applications.
The psychology of waiting in AI applications reveals interesting patterns about user expectations and satisfaction. Users tend to perceive response times differently based on the context and complexity of their requests. A slight delay in generating a complex analysis might be acceptable, and even a small lag in a conversational exchange can feel disruptive. This understanding helps us set appropriate optimization priorities for different types of applications.
Consistent response times, even if slightly slower, often lead to better user satisfaction than highly variable response times with occasional quick replies. This is crucial for streaming responses and implementing optimization strategies.
When processing times are longer, simple indicators such as “Processing your request” or “loading animations” messages help keep users engaged, especially during the initial response time. In such scenarios, you want to optimize for TTFT.
Output quality often matters more than speed. Users prefer accurate responses over quick but less reliable ones. Consider benchmarking your user experience to find the best latency for your use case, considering that most humans can’t read faster than 225 words per minute and therefore extremely fast response can hinder user experience.
By understanding these nuances, you can make more informed decisions to optimize your AI applications for better user experience.
Amazon Bedrock latency-optimized inference capabilities are designed to provide higher OTPS and quicker TTFT, enabling applications to handle workloads more reliably. This optimization is available in the US East (Ohio) AWS Region for select FMs, including Anthropic’s Claude 3.5 Haiku and Meta’s Llama 3.1 models (both 405B and 70B versions). The optimization supports the following models:
To enable latency optimization, you need to set the latency parameter to optimized in your API calls:
To understand the performance gains both for TTFT and OTPS, we conducted an offline experiment with around 1,600 API calls spread across various hours of the day and across multiple days. We used a dummy dataset comprising different task types: sequence-counting, story-writing, summarization, and translation. The input prompt ranged from 100 tokens to 100,000 tokens, and the output tokens ranged from 100 to 1,000 output tokens. These tasks were chosen to represent varying complexity levels and various model output lengths. Our test setup was hosted in the US West (Oregon) us-west-2 Region, and both the optimized and standard models were hosted in US East (Ohio) us-east-2 Region. This cross-Region setup introduced realistic network variability, helping us measure performance under conditions similar to real-world applications.
When analyzing the results, we focused on the key latency metrics discussed earlier: TTFT and OTPS. As a quick recap, lower TTFT values indicate faster initial response times, and higher OTPS values represent faster token generation speeds. We also looked at the 50th percentile (P50) and 90th percentile (P90) values to understand both typical performance and performance boundaries under challenging or upper bound conditions. Following the central limit theorem, we observed that, with sufficient samples, our results converged toward consistent values, providing reliable performance indicators.
It’s important to note that these results are from our specific test environment and datasets. Your actual results may vary based on your specific use case, prompt length, expected model response length, network conditions, client location, and other implementation components. When conducting your own benchmarks, make sure your test dataset represents your actual production workload characteristics, including typical input lengths and expected output patterns.
Our experiments with the latency-optimized models revealed substantial performance improvements across both TTFT and OTPS metrics. The results in the following table show the comparison between standard and optimized versions of Anthropic’s Claude 3.5 Haiku and Meta’s Llama 3.1 70B models. For each model, we ran multiple iterations of our test scenarios to promote reliable performance. The improvements were particularly notable in high-percentile measurements, suggesting more consistent performance even under challenging conditions.
| Model | Inference profile | TTFT P50 (in seconds) | TTFT P90 (in seconds) | OTPS P50 | OTPS P90 |
| us.anthropic.claude-3-5-haiku-20241022-v1:0 | Optimized | 0.6 | 1.4 | 85.9 | 152.0 |
| us.anthropic.claude-3-5-haiku-20241022-v1:0 | Standard | 1.1 | 2.9 | 48.4 | 67.4 |
| Improvement | -42.20% | -51.70% | 77.34% | 125.50% | |
| us.meta.llama3-1-70b-instruct-v1:0 | Optimized | 0.4 | 1.2 | 137.0 | 203.7 |
| us.meta.llama3-1-70b-instruct-v1:0 | Standard | 0.9 | 42.8 | 30.2 | 32.4 |
| Improvement | -51.65% | -97.10% | 353.84% | 529.33% |
These results demonstrate significant improvements across all metrics for both models. For Anthropic’s Claude 3.5 Haiku model, the optimized version achieved up to 42.20% reduction in TTFT P50 and up to 51.70% reduction in TTFT P90, indicating more consistent initial response times. Additionally, the OTPS saw improvements of up to 77.34% at the P50 level and up to 125.50% at the P90 level, enabling faster token generation.
The gains for Meta’s Llama 3.1 70B model are even more impressive, with the optimized version achieving up to 51.65% reduction in TTFT P50 and up to 97.10% reduction in TTFT P90, providing consistently rapid initial responses. Furthermore, the OTPS saw a massive boost, with improvements of up to 353.84% at the P50 level and up to 529.33% at the P90 level, enabling up to 5x faster token generation in some scenarios.
Although these benchmark results show the powerful impact of latency-optimized inference, they represent just one piece of the optimization puzzle. To make best use of these performance improvements and achieve the best possible response times for your specific use case, you’ll need to consider additional optimization strategies beyond merely enabling the feature.
Even though Amazon Bedrock latency-optimized inference offers great improvements from the start, getting the best performance requires a well-rounded approach to designing and implementing your application. In the next section, we explore some other strategies and considerations to make your application as responsive as possible.
When optimizing LLM applications for latency, the way you craft your prompts affects both input processing and output generation.
To optimize your input prompts, follow these recommendations:
To engineer for brief outputs, follow these recommendations:
One of the best ways to make your AI application feel faster is to use streaming. Instead of waiting for the complete response, streaming shows the response as it’s being generated—like watching someone type in real-time. Streaming the response is one of the most effective ways to improve perceived performance in LLM applications maintaining user engagement.
These techniques can significantly reduce token usage and generation time, improving both latency and cost-efficiency.
Although individual optimizations are important, production applications require a holistic approach to latency management. In this section, we explore how different system components and architectural decisions impact overall application responsiveness.
In production environments, overall system latency extends far beyond model inference time. Each component in your AI application stack contributes to the total latency experienced by users. For instance, when implementing responsible AI practices through Amazon Bedrock Guardrails, you might notice a small additional latency overhead. Similar considerations apply when integrating content filtering, user authentication, or input validation layers. Although each component serves a crucial purpose, their cumulative impact on latency requires careful consideration during system design.
Geographic distribution plays a significant role in application performance. Model invocation latency can vary considerably depending on whether calls originate from different Regions, local machines, or different cloud providers. This variation stems from data travel time across networks and geographic distances. When designing your application architecture, consider factors such as the physical distance between your application and model endpoints, cross-Region data transfer times, and network reliability in different Regions. Data residency requirements might also influence these architectural choices, potentially necessitating specific Regional deployments.
Integration patterns significantly impact how users perceive application performance. Synchronous processing, although simpler to implement, might not always provide the best user experience. Consider implementing asynchronous patterns where appropriate, such as pre-fetching likely responses based on user behavior patterns or processing noncritical components in the background. Request batching for bulk operations can also help optimize overall system throughput, though it requires careful balance with response time requirements.
As applications scale, additional infrastructure components become necessary but can impact latency. Load balancers, queue systems, cache layers, and monitoring systems all contribute to the overall latency budget. Understanding these components’ impact helps in making informed decisions about infrastructure design and optimization strategies.
Complex tasks often require orchestrating multiple model calls or breaking down problems into subtasks. Consider a content generation system that first uses a fast model to generate an outline, then processes different sections in parallel, and finally uses another model for coherence checking and refinement. This orchestration approach requires careful attention to cumulative latency impact while maintaining output quality. Each step needs appropriate timeouts and fallback mechanisms to provide reliable performance under various conditions.
Although our focus is on latency-optimized inference, it’s worth noting that Amazon Bedrock also offers prompt caching (in preview) to optimize for both cost and latency. This feature is particularly valuable for applications that frequently reuse context, such as document-based chat assistants or applications with repetitive query patterns. When combined with latency-optimized inference, prompt caching can provide additional performance benefits by reducing the processing overhead for frequently used contexts.
Similar to prompt caching, Amazon Bedrock Intelligent Prompt Routing (in preview) is another powerful optimization feature. This capability automatically directs requests to different models within the same model family based on the complexity of each prompt. For example, simple queries can be routed to faster, more cost-effective models, and complex requests that require deeper understanding are directed to more sophisticated models. This automatic routing helps optimize both performance and cost without requiring manual intervention.
Application architecture plays a crucial role in overall latency optimization. Consider implementing a multitiered caching strategy that includes response caching for frequently requested information and smart context management for historical information. This isn’t only about storing exact matches—consider implementing semantic caching that can identify and serve responses to similar queries.
In AI applications, there’s a constant balancing act between model sophistication, latency, and cost, as illustrated in the diagram. Although more advanced models often provide higher quality outputs, they might not always meet strict latency requirements. In such cases, using a less sophisticated but faster model might be the better choice. For instance, in applications requiring near-instantaneous responses, opting for a smaller, more efficient model could be necessary to meet latency goals, even if it means a slight trade-off in output quality. This approach aligns with the broader need to optimize the interplay between cost, speed, and quality in AI systems.

Features such as Amazon Bedrock Intelligent Prompt Routing help manage this balance effectively. By automatically handling model selection based on request complexity, you can optimize for all three factors—quality, speed, and cost—without requiring developers to commit to a single model for all requests.
As we’ve explored throughout this post, optimizing LLM application latency involves multiple strategies, from using latency-optimized inference and prompt caching to implementing intelligent routing and careful prompt engineering. The key is to combine these approaches in a way that best suits your specific use case and requirements.
Making your AI application fast and responsive isn’t a one-time task, it’s an ongoing process of testing and improvement. Amazon Bedrock latency-optimized inference gives you a great starting point, and you’ll notice significant improvements when you combine it with the strategies we’ve discussed.
Ready to get started? Here’s what to do next:
Remember, in today’s AI applications, being smart isn’t enough, being responsive is just as important. Start implementing these optimization strategies today and watch your application’s performance improve.
 Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
 Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
 Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
 Vivek Singh is a Senior Manager, Product Management at AWS AI Language Services team. He leads the Amazon Transcribe product team. Prior to joining AWS, he held product management roles across various other Amazon organizations such as consumer payments and retail. Vivek lives in Seattle, WA and enjoys running, and hiking.
Vivek Singh is a Senior Manager, Product Management at AWS AI Language Services team. He leads the Amazon Transcribe product team. Prior to joining AWS, he held product management roles across various other Amazon organizations such as consumer payments and retail. Vivek lives in Seattle, WA and enjoys running, and hiking.
 Ankur Desai is a Principal Product Manager within the AWS AI Services team.
Ankur Desai is a Principal Product Manager within the AWS AI Services team.
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLM’s capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk. Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input data quality, and ultimately, the entire application stack. As LLMs take on more significant roles in areas like healthcare, education, and decision support, robust evaluation frameworks are vital for building trust and realizing the technology’s potential while mitigating risks.
Developers interested in using LLMs should prioritize a comprehensive evaluation process for several reasons. First, it assesses the model’s suitability for specific use cases, because performance can vary significantly across different tasks and domains. Evaluations are also a fundamental tool during application development to validate the quality of prompt templates. This process makes sure that solutions align with the company’s quality standards and policy guidelines before deploying them to production. Regular interval evaluation also allows organizations to stay informed about the latest advancements, making informed decisions about upgrading or switching models. Moreover, a thorough evaluation framework helps companies address potential risks when using LLMs, such as data privacy concerns, regulatory compliance issues, and reputational risk from inappropriate outputs. By investing in robust evaluation practices, companies can maximize the benefits of LLMs while maintaining responsible AI implementation and minimizing potential drawbacks.
To support robust generative AI application development, it’s essential to keep track of models, prompt templates, and datasets used throughout the process. This record-keeping allows developers and researchers to maintain consistency, reproduce results, and iterate on their work effectively. By documenting the specific model versions, fine-tuning parameters, and prompt engineering techniques employed, teams can better understand the factors contributing to their AI system’s performance. Similarly, maintaining detailed information about the datasets used for training and evaluation helps identify potential biases and limitations in the model’s knowledge base. This comprehensive approach to tracking key components not only facilitates collaboration among team members but also enables more accurate comparisons between different iterations of the AI application. Ultimately, this systematic approach to managing models, prompts, and datasets contributes to the development of more reliable and transparent generative AI applications.
In this post, we show how to use FMEval and Amazon SageMaker to programmatically evaluate LLMs. FMEval is an open source LLM evaluation library, designed to provide data scientists and machine learning (ML) engineers with a code-first experience to evaluate LLMs for various aspects, including accuracy, toxicity, fairness, robustness, and efficiency. In this post, we only focus on the quality and responsible aspects of model evaluation, but the same approach can be extended by using other libraries for evaluating performance and cost, such as LLMeter and FMBench, or richer quality evaluation capabilities like those provided by Amazon Bedrock Evaluations.
SageMaker is a data, analytics, and AI/ML platform, which we will use in conjunction with FMEval to streamline the evaluation process. We specifically focus on SageMaker with MLflow. MLflow is an open source platform for managing the end-to-end ML lifecycle, including experimentation, reproducibility, and deployment. The managed MLflow in SageMaker simplifies the deployment and operation of tracking servers, and offers seamless integration with other AWS services, making it straightforward to track experiments, package code into reproducible runs, and share and deploy models.
By combining FMEval’s evaluation capabilities with SageMaker with MLflow, you can create a robust, scalable, and reproducible workflow for assessing LLM performance. This approach can enable you to systematically evaluate models, track results, and make data-driven decisions in your generative AI development process.
FMEval is an open-source library for evaluating foundation models (FMs). It consists of three main components:
You can use pre-built components because it provides native components for both Amazon Bedrock and Amazon SageMaker JumpStart, or create custom ones by inheriting from the base core component. The library supports various evaluation scenarios, including pre-computed model outputs and on-the-fly inference. FMEval offers flexibility in dataset handling, model integration, and algorithm implementation. Refer to Evaluate large language models for quality and responsibility or the Evaluating Large Language Models with fmeval paper to dive deeper into FMEval, or see the official GitHub repository.
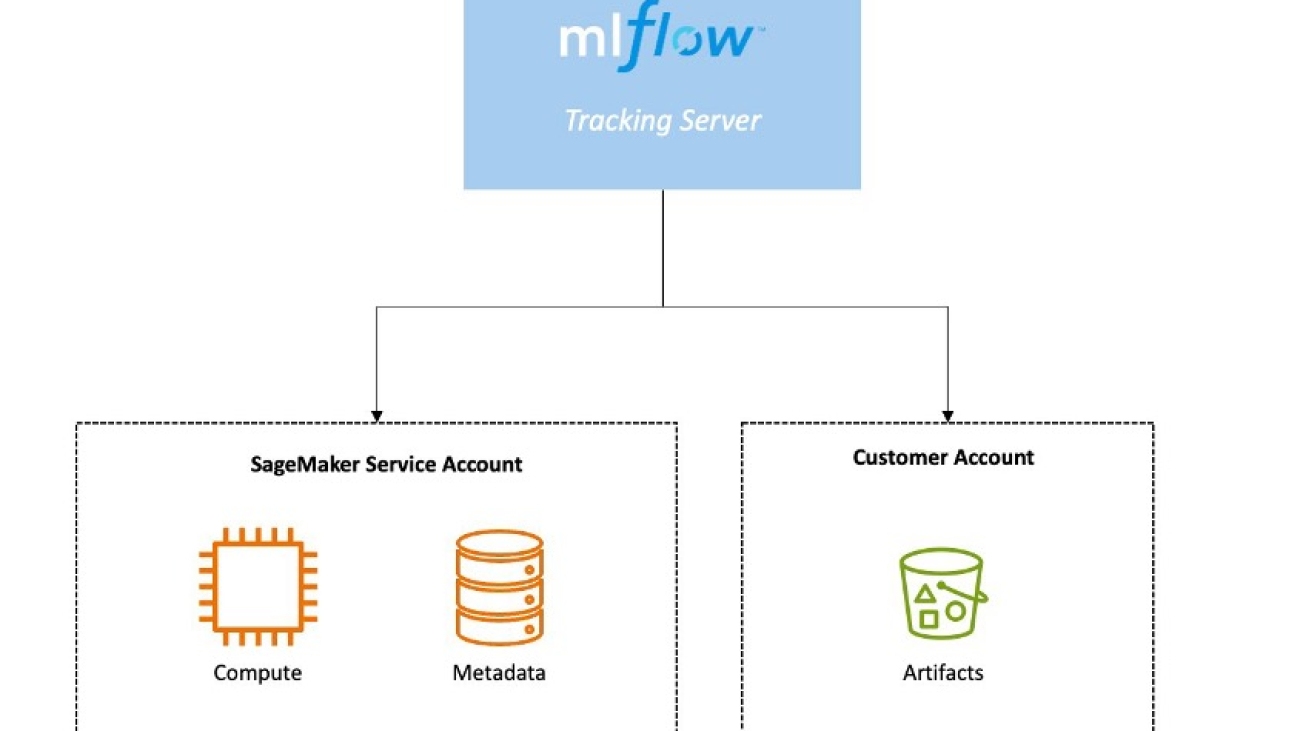
The fully managed MLflow capability on SageMaker is built around three core components:
The following diagram depicts the different components and where they run within AWS.

You can follow the full sample code from the GitHub repository.
You must have the following prerequisites:
Refer to the documentation best practices regarding AWS Identity and Access Management (IAM) policies for SageMaker, MLflow, and Amazon Bedrock on how to set up permissions for the SageMaker execution role. Remember to always following the least privilege access principle.
We provide two sample notebooks to evaluate models hosted in Amazon Bedrock (Bedrock.ipynb) and models deployed to SageMaker Hosting using SageMaker JumpStart (JumpStart.ipynb). The workflow implemented in these two notebooks is essentially the same, although a few differences are noteworthy:
ModelRunners implementations differ. FMEval provides native implementations for both Amazon Bedrock, using the BedrockModelRunner class, and SageMaker JumpStart, using the JumpStartModelRunner class. We discuss the main differences in the following section.For BedrockModelRunner, we need to find the model content_template. We can find this information conveniently on the Amazon Bedrock console in the API request sample section, and look at value of the body. The following example is the content template for Anthropic’s Claude 3 Haiku:
output_jmespath = "content[0].text"
content_template = """{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 512,
"temperature": 0.5,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": $prompt
}
]
}
]
}"""
model_runner = BedrockModelRunner(
model_id=model_id,
output=output_jmespath,
content_template=content_template,
)
For JumpStartModelRunner, we need to find the model and model_version. This information can be retrieved directly using the get_model_info_from_endpoint(endpoint_name=endpoint_name) utility provided by the SageMaker Python SDK, where endpoint_name is the name of the SageMaker endpoint where the SageMaker JumpStart model is hosted. See the following code example:
from sagemaker.jumpstart.session_utils import get_model_info_from_endpoint
model_id, model_version, , , _ = get_model_info_from_endpoint(endpoint_name=endpoint_name)
model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_id,
model_version=model_version,
)
For each model runner, we want to evaluate three categories: Summarization, Factual Knowledge, and Toxicity. For each of this category, we prepare a DataConfig object for the appropriate dataset. The following example shows only the data for the Summarization category:
dataset_path = Path("datasets")
dataset_uri_summarization = dataset_path / "gigaword_sample.jsonl"
if not dataset_uri_summarization.is_file():
print("ERROR - please make sure the file, gigaword_sample.jsonl, exists.")
data_config_summarization = DataConfig(
dataset_name="gigaword_sample",
dataset_uri=dataset_uri_summarization.as_posix(),
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location="document",
target_output_location="summary",
)
We can now create an evaluation set for each algorithm we want to use in our test. For the Summarization evaluation set, replace with your own prompt according to the input signature identified earlier. fmeval uses $model_input as placeholder to get the input from your evaluation dataset. See the following code:
summarization_prompt = "Summarize the following text in one sentence: $model_input"
summarization_accuracy = SummarizationAccuracy()
evaluation_set_summarization = EvaluationSet(
data_config_summarization,
summarization_accuracy,
summarization_prompt,
)
We are ready now to group the evaluation sets:
evaluation_list = [
evaluation_set_summarization,
evaluation_set_factual,
evaluation_set_toxicity,
]
We set up the MLflow experiment used to track the evaluations. We then create a new run for each model, and run all the evaluations for that model within that run, so that the metrics will all appear together. We use the model_id as the run name to make it straightforward to identify this run as part of a larger experiment, and run the evaluation using the run_evaluation_sets() defined in utils.py. See the following code:
run_name = f"{model_id}"
experiment_name = "fmeval-mlflow-simple-runs"
experiment = mlflow.set_experiment(experiment_name)
with mlflow.start_run(run_name=run_name) as run:
run_evaluation_sets(model_runner, evaluation_list)
It is up to the user to decide how to best organize the results in MLflow. In fact, a second possible approach is to use nested runs. The sample notebooks implement both approaches to help you decide which one fits best your needs.
experiment_name = "fmeval-mlflow-nested-runs"
experiment = mlflow.set_experiment(experiment_name)
with mlflow.start_run(run_name=run_name, nested=True) as run:
run_evaluation_sets_nested(model_runner, evaluation_list)
Tracking the evaluation process involves storing information about three aspects:
We provide a helper library (fmeval_mlflow) to abstract the logging of these aspects to MLflow, streamlining the interaction with the tracking server. For the information we want to store, we can refer to the following three functions:
log_input_dataset(data_config: DataConfig | list[DataConfig]) – Log one or more input datasets to MLflow for evaluation purposeslog_runner_parameters(model_runner: ModelRunner, custom_parameters_map: dict | None = None, model_id: str | None = None,) – Log the parameters associated with a given ModelRunner instance to MLflowlog_metrics(eval_output: list[EvalOutput], log_eval_output_artifact: bool = False) – Log metrics and artifacts for a list of SingleEvalOutput instances to MLflow.When the evaluations are complete, we can analyze the results directly in the MLflow UI for a first visual assessment.
In the following screenshots, we show the visualization differences between logging using simple runs or nested runs.


You might want to create your own custom visualizations. For example, spider plots are often used to make visual comparison across multiple metrics. In the notebook compare_models.ipynb, we provide an example on how to use metrics stored in MLflow to generate such plots, which ultimately can also be stored in MLflow as part of your experiments. The following screenshots show some example visualizations.


Once created, an MLflow tracking server will incur costs until you delete or stop it. Billing for tracking servers is based on the duration the servers have been running, the size selected, and the amount of data logged to the tracking servers. You can stop the tracking servers when they are not in use to save costs or delete them using the API or SageMaker Studio UI. For more details on pricing, see Amazon SageMaker pricing.
Similarly, if you deployed a model using SageMaker, endpoints are priced by deployed infrastructure time rather than by requests. You can avoid unnecessary charges by deleting your endpoints when you’re done with the evaluation.
In this post, we demonstrated how to create an evaluation framework for LLMs by combining SageMaker managed MLflow with FMEval. This integration provides a comprehensive solution for tracking and evaluating LLM performance across different aspects including accuracy, toxicity, and factual knowledge.
To enhance your evaluation journey, you can explore the following:
By adopting these practices, you can build more reliable and trustworthy LLM applications while maintaining a clear record of your evaluation process and results.
 Paolo Di Francesco is a Senior Solutions Architect at Amazon Web Services (AWS). He holds a PhD in Telecommunications Engineering and has experience in software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
Paolo Di Francesco is a Senior Solutions Architect at Amazon Web Services (AWS). He holds a PhD in Telecommunications Engineering and has experience in software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
 Dr. Alessandro Cerè is a GenAI Evaluation Specialist and Solutions Architect at AWS. He assists customers across industries and regions in operationalizing and governing their generative AI systems at scale, ensuring they meet the highest standards of performance, safety, and ethical considerations. Bringing a unique perspective to the field of AI, Alessandro has a background in quantum physics and research experience in quantum communications and quantum memories. In his spare time, he pursues his passion for landscape and underwater photography.
Dr. Alessandro Cerè is a GenAI Evaluation Specialist and Solutions Architect at AWS. He assists customers across industries and regions in operationalizing and governing their generative AI systems at scale, ensuring they meet the highest standards of performance, safety, and ethical considerations. Bringing a unique perspective to the field of AI, Alessandro has a background in quantum physics and research experience in quantum communications and quantum memories. In his spare time, he pursues his passion for landscape and underwater photography.
2024 has been a year of incredible growth for PyTorch. As that continues in 2025, the PyTorch Foundation has made important steps towards evolving the governance of the project under the Linux Foundation’s vendor-neutral umbrella.
An important piece of governance for PyTorch is represented by the Technical Advisory Council (TAC). The TAC acts as a bridge between the industry, including but not limited to the PyTorch Foundation members, the community, and the PyTorch core development team.
Operating with transparency and inclusivity, the TAC gathers input, facilitates collaboration, and drives initiatives that enhance the experience for everyone who relies on PyTorch.
In 2025, the TAC will focus on four key areas:
By focusing on these priorities, the TAC aims to maintain PyTorch’s position as the leading deep learning framework, while ensuring it remains open, accessible, and responsive to the needs of its diverse community.
As members of the TAC, we’re extremely excited to contribute to the success of PyTorch and to the impact it’s having in the real world. If you are a PyTorch user or developer, consider participating in our monthly calls (they are open to everyone, and the recordings are available here). Also, if you develop or maintain a project based on PyTorch, consider contributing it to the new PyTorch ecosystem (instructions).
![]() Learn how Google teams built the Pixel 9 series’ Add Me feature, which uses AI for easier group photos.Read More
Learn how Google teams built the Pixel 9 series’ Add Me feature, which uses AI for easier group photos.Read More
Amazon SageMaker provides a seamless experience for building, training, and deploying machine learning (ML) models at scale. Although SageMaker offers a wide range of built-in algorithms and pre-trained models through Amazon SageMaker JumpStart, there are scenarios where you might need to bring your own custom model or use specific software dependencies not available in SageMaker managed container images. Examples for this could include use cases like geospatial analysis, bioinformatics research, or quantum machine learning. In such cases, SageMaker allows you to extend its functionality by creating custom container images and defining custom model definitions. This approach enables you to package your model artifacts, dependencies, and inference code into a container image, which you can deploy as a SageMaker endpoint for real-time inference. This post walks you through the end-to-end process of deploying a single custom model on SageMaker using NASA’s Prithvi model. The Prithvi model is a first-of-its-kind temporal Vision transformer pre-trained by the IBM and NASA team on contiguous US Harmonised Landsat Sentinel 2 (HLS) data. It can be finetuned for image segmentation using the mmsegmentation library for use cases like burn scars detection, flood mapping, and multi-temporal crop classification. Due to its unique architecture and fine-tuning dependency on the MMCV library, it is an effective example of how to deploy complex custom models to SageMaker. We demonstrate how to use the flexibility of SageMaker to deploy your own custom model, tailored to your specific use case and requirements. Whether you’re working with unique model architectures, specialized libraries, or specific software versions, this approach empowers you to harness the scalability and management capabilities of SageMaker while maintaining control over your model’s environment and dependencies.
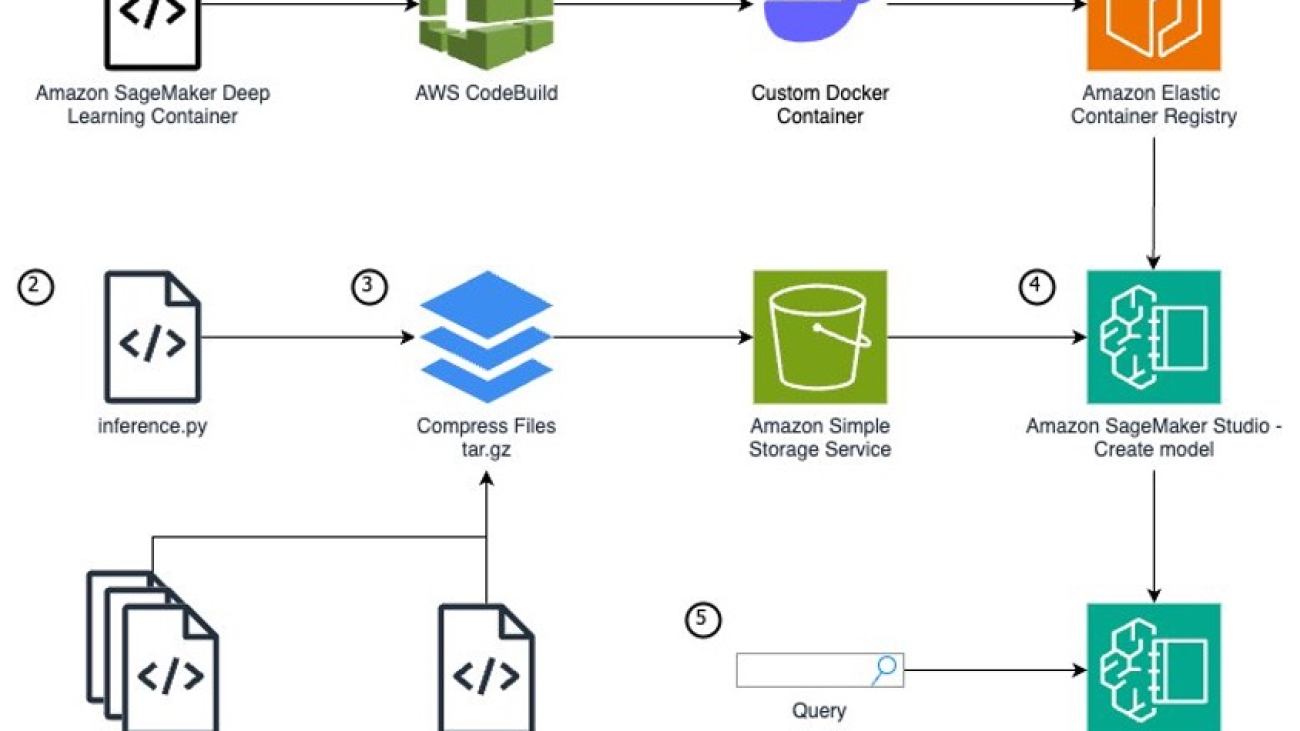
To run a custom model that needs unique packages as a SageMaker endpoint, you need to follow these steps:
inference.py file format.The following diagram illustrates the solution architecture and workflow:
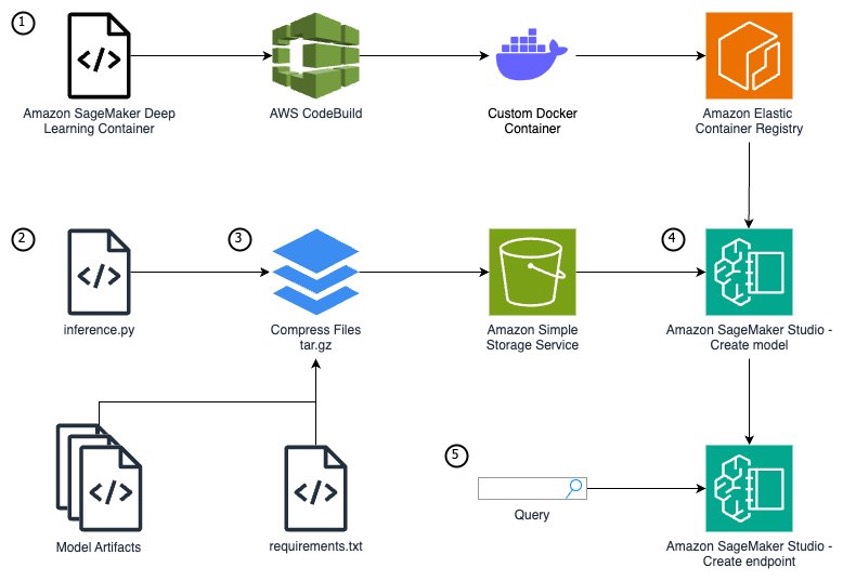
You need the following prerequisites before you can proceed. For this post, we use the us-east-1 AWS Region:
Although AWS provides pre-built container images optimized for deep learning on the AWS Deep Learning Containers (DLCs) GitHub for PyTorch and TensorFlow use cases, there are scenarios where models require additional libraries not included in these containers. The installation of these dependencies can take minutes or hours, so it’s more efficient to pre-build these dependencies into a custom container image. For this example, we deploy the Prithvi model, which is dependent on the MMCV library for advanced computer vision techniques. This library is not available within any of the SageMaker DLCs, so you will have to create an extended container to add it. Both MMCV and Prithvi are third-party models which have not undergone AWS security reviews, so please review these models yourself or use at your own risk. This post uses CodeBuild and a Docker Dockerfile to build the extended container.
Complete the following steps:
This Docker container installs the Prithvi model and MMCV v1.6.2. These models are third-party models not produced by AWS and therefore may have security vulnerabilities. Use at your own risk.
buildspec file to define the build process for the CodeBuild project. This buildspec file will instruct CodeBuild to install the nvidia-container-toolkit to make sure the Docker container has GPU access, run the Dockerfile build, and push the built container image to your ECR repository.
buildspec.yml files to the S3 bucket. This zip file will serve as the source code for the CodeBuild project.
codebuild-project.json specification defined in the previous step:
The build will take approximately 30 minutes to complete and cost approximately $1.50 to run. The CodeBuild compute instance type gpu1.small costs $0.05 per minute.
After you run the preceding command, you can press Ctrl+C to exit and run future commands. The build will already be running on AWS and will not be canceled by closing the command.
buildStatus=SUCCEEDED before proceeding to the next step:
After your CodeBuild project has completed, make sure that you do not close your terminal. The environment variables here will be used again.
inference.py fileTo run a custom model for inference on AWS, you need to build out an inference.py file that initializes your model, defines the input and output structure, and produces your inference results. In this file, you must define four functions:
model_fn – Initializes your modelinput_fn – Defines how your data should be input and how to convert to a usable formatpredict_fn – Takes the input data and receives the predictionoutput_fn – Converts the prediction into an API call formatWe use the following completed inference.py file for the SageMaker endpoint in this post. Download this inference.py to continue because it includes the helper functions to process the TIFF files needed for this model’s input. The following code is contained within the inference.py and is only shown to provide an explanation of what is being done in the file.
model_fnThe model_fn function builds your model, which is called and used within the predict_fn function. This function loads the model weights into a torch model checkpoint, opens the model config, defines global variables, instantiates the model, loads the model checkpoint into the model, and returns the model.
input_fnThis function defines the expected input for the model and how to load the input for use in predict_fn. The endpoint expects a string URL path linked to a TIFF file you can find online from the Prithvi demo on Hugging Face. This function also defines the content type of the request sent in the body (such as application/json, image/tiff).
predict_fn:In predict_fn, you create the prediction from the given input. In this case, creating the prediction image uses two helper functions specific to this endpoint (preprocess_image and enhance_raster_for_visualization). You can find both functions here. The preprocess_image function normalizes the image, then the function uses torch.no_grad to disable gradient calculations for the model. This is useful during inference to decrease inference time and reduce memory usage. Next, the function collects the prediction from the instantiated model. The mask ratio determines the number of pixels on the image zeroed out during inference. The two unpatchify functions convert the smaller patchified results produced by the model back to the original image space. The function normalized.clone() clones the normalized images and replaces the masked Regions from rec_img with the Regions from the pred_img. Finally, the function reshapes the image back into TIFF format, removes the normalization, and returns the image in raster format, which is valuable for visualization. The result of this is an image that can be converted to bytes for the user and then visualized on the user’s screen.
output_fnoutput_fn returns the TIFF image received from predict_fn as an array of bytes.
inference.py fileNow that you have downloaded the complete inference.py file, there are two options to test your model before compressing the files and uploading them to Amazon S3:
inference.py functions on your custom container within an Amazon Elastic Compute Cloud (Amazon EC2) instanceBefore you start this step, download the Prithvi model artifacts and the Prithvi flood fine-tuning of the model. The first link will provide all of the model data from the base Prithvi model, and the flood fine-tuning of the model builds upon the model to perform flood plain detection on satellite images. Install git-lfs using brew on Mac or using https://git-lfs.com/ on Windows to install the GitHub repo’s large files.
To create a SageMaker model on the SageMaker console, you must store your model data within Amazon S3 because your SageMaker endpoint will pull your model artifacts directly from Amazon S3 using a tar.gz format. Within your tar.gz file, the data must have a specific file format defined by SageMaker. The following is the file structure for the Prithvi foundation model (our requirements are installed on the container, so requirements.txt has been left intentionally blank):
This folder structure remains true for other models as well. The /code folder must hold the inference.py file and any files used within inference.py. These additional files are generally model artifacts (configs, weights, and so on). In our case, this will be the whole Prithvi base model folder as well as the weights and configs for the fine-tuned version we will use. Because we have already installed these packages within our container, this is not used; however, there still must be a requirements.txt file, otherwise your endpoint will fail to build. All other files belong in the root folder.
With the preceding file structure in place, open your terminal and route into the model folder.
The command will create a compressed version of your model files called model.tar.gz from the files in your current directory. You can now upload this file into an S3 bucket.
model.tar.gz file:
The file you uploaded will be used in the next step to define the model to be created in the endpoint.
You now create a SageMaker inference endpoint using the CLI. There are three steps to creating a SageMaker endpoint: create a model, create an endpoint configuration, and create an endpoint.
In this post, you will create a public SageMaker endpoint because this will simplify running and testing the endpoint. For details about how to limit access to SageMaker endpoints, refer to Deploy models with SageMaker Studio.
Complete the following steps:
The model definition will include the role you created, the ECR container image, and the Amazon S3 location of the model.tar.gz file that you created previously.
A SageMaker endpoint configuration specifies the infrastructure that the model will be hosted on. The model will be hosted on a ml.g4dn.xlarge instance for GPU-based acceleration.
The ml.g4dn.xlarge inference endpoint will cost $0.736 per hour while running. It will take several minutes for the endpoint to finish deploying.
When the endpoint’s status is InService, proceed to the next section.
To test your SageMaker endpoint, you will query your endpoint with an image and display it. The following command sends a URL that references a TIFF image to the SageMaker endpoint, the model sends back a byte array, and the command reforms the byte array into an image. Open up a notebook locally or on Sagemaker Studio JupyterLab. The below code will need to be run outside of the command line to view the image
This Python code creates a predictor object for your endpoint and sets the predictor’s serializer to NumPy for the conversion on the endpoint. It queries the predictor object using a payload of a URL pointing to a TIFF image. You use a helper function to display the image and enhance the raster. You will be able to find that helper function here. After you add the helper function, display the image:
You should observe an image that has been taken from a satellite.
To clean up the resources from this post and avoid incurring costs, follow these steps:
model.tar.gz file in the S3 bucket that was created.customsagemakercontainer-model and customsagemakercontainer-codebuildsource S3 buckets.In this post, we extended a SageMaker container to include custom dependencies, wrote a Python script to run a custom ML model, and deployed that model on the SageMaker container within a SageMaker endpoint for real-time inference. This solution produces a running GPU-enabled endpoint for inference queries. You can use this same process to create custom model SageMaker endpoints by extending other SageMaker containers and writing an inference.py file for new custom models. Furthermore, with adjustments, you could create a multi-model SageMaker endpoint for custom models or run a batch processing endpoint for scenarios where you run large batches of queries at once. These solutions enable you to go beyond the most popular models used today and customize models to fit your own unique use case.
 Aidan is a solutions architect supporting US federal government health customers. He assists customers by developing technical architectures and providing best practices on Amazon Web Services (AWS) cloud with a focus on AI/ML services. In his free time, Aidan enjoys traveling, lifting, and cooking
Aidan is a solutions architect supporting US federal government health customers. He assists customers by developing technical architectures and providing best practices on Amazon Web Services (AWS) cloud with a focus on AI/ML services. In his free time, Aidan enjoys traveling, lifting, and cooking
 Nate is a solutions architect supporting US federal government sciences customers. He assists customers in developing technical architectures on Amazon Web Services (AWS), with a focus on data analytics and high performance computing. In his free time, he enjoys skiing and golfing.
Nate is a solutions architect supporting US federal government sciences customers. He assists customers in developing technical architectures on Amazon Web Services (AWS), with a focus on data analytics and high performance computing. In his free time, he enjoys skiing and golfing.
 Charlotte is a solutions architect on the aerospace & satellite team at Amazon Web Services (AWS), where she helps customers achieve their mission objectives through innovative cloud solutions. Charlotte specializes in machine learning with a focus on Generative AI. In her free time, she enjoys traveling, painting, and running.
Charlotte is a solutions architect on the aerospace & satellite team at Amazon Web Services (AWS), where she helps customers achieve their mission objectives through innovative cloud solutions. Charlotte specializes in machine learning with a focus on Generative AI. In her free time, she enjoys traveling, painting, and running.