Large pretrained models are showing increasingly better performance in reasoning and planning tasks across different modalities, opening the possibility to leverage them for complex sequential decision making problems. In this paper, we investigate the capabilities of Large Language Models (LLMs) for reinforcement learning (RL) across a diversity of interactive domains. We evaluate their ability to produce decision-making policies, either directly, by generating actions, or indirectly, by first generating reward models to train an agent with RL. Our results show that, even without…Apple Machine Learning Research
DSplats: 3D Generation by Denoising Splats-Based Multiview Diffusion Models
Generating high-quality 3D content requires models capable of learning robust distributions of complex scenes and the real-world objects within them. Recent Gaussian-based 3D reconstruction techniques have achieved impressive results in recovering high-fidelity 3D assets from sparse input images by predicting 3D Gaussians in a feed-forward manner. However, these techniques often lack the extensive priors and expressiveness offered by Diffusion Models. On the other hand, 2D Diffusion Models, which have been successfully applied to denoise multiview images, show potential for generating a wide…Apple Machine Learning Research
Delayed Fusion: Integrating Large Language Models into First-Pass Decoding in End-to-end Speech Recognition
This paper presents an efficient decoding approach for end-to-end automatic speech recognition (E2E-ASR) with large language models (LLMs). Although shallow fusion is the most common approach to incorporate language models into E2E-ASR decoding, we face two practical problems with LLMs. (1) LLM inference is computationally costly. (2) There may be a vocabulary mismatch between the ASR model and the LLM. To resolve this mismatch, we need to retrain the ASR model and/or the LLM, which is at best time-consuming and in many cases not feasible. We propose “delayed fusion,” which applies LLM scores…Apple Machine Learning Research

Research Focus: Week of January 13, 2025
In this edition:
- We introduce privacy enhancements for multiparty deep learning, a framework using smaller, open-source models to provide relevance judgments, and other notable new research.
- We congratulate Yasuyuki Matsushita, who was named an IEEE Computer Society Fellow.
- We’ve included a recap of the extraordinary, far-reaching work done by researchers at Microsoft in 2024.

NEW RESEARCH
AI meets materials discovery
Two of the transformative tools that play a central role in Microsoft’s work on AI for science are MatterGen and MatterSim. In the world of materials discovery, each plays a distinct yet complementary role in reshaping how researchers design and validate new materials.
NEW RESEARCH
Communication Efficient Secure and Private Multi-Party Deep Learning
Distributed training enables multiple parties to jointly train a machine learning model on their respective datasets, which can help address the challenges posed by requirements in modern machine learning for large volumes of diverse data. However, this can raise security and privacy issues – protecting each party’s data during training and preventing leakage of private information from the model after training through various inference attacks.
In a recent paper, Communication Efficient Secure and Private Multi-Party Deep Learning, researchers from Microsoft address these concerns simultaneously by designing efficient Differentially Private, secure Multiparty Computation (DP-MPC) protocols for jointly training a model on data distributed among multiple parties. This DP-MPC protocol in the two-party setting is 56-to-794 times more communication-efficient and 16-to-182 times faster than previous such protocols. This work simplifies and improves on previous attempts to combine techniques from secure multiparty computation and differential privacy, especially in the context of training machine learning models.
NEW RESEARCH
JudgeBlender: Ensembling Judgments for Automatic Relevance Assessment
Training and evaluating retrieval systems requires significant relevance judgments, which are traditionally collected from human assessors. This process is both costly and time-consuming. Large language models (LLMs) have shown promise in generating relevance labels for search tasks, offering a potential alternative to manual assessments. Current approaches often rely on a single LLM. While effective, this approach can be expensive and prone to intra-model biases that can favor systems leveraging similar models.
In a recent paper: JudgeBlender: Ensembling Judgments for Automatic Relevance Assessment, researchers from Microsoft we introduce a framework that employs smaller, open-source models to provide relevance judgments by combining evaluations across multiple LLMs (LLMBlender) or multiple prompts (PromptBlender). By leveraging the LLMJudge benchmark, they compare JudgeBlender with state-of-the-art methods and the top performers in the LLMJudge challenge. This research shows that JudgeBlender achieves competitive performance, demonstrating that very large models are often unnecessary for reliable relevance assessments.
NEW RESEARCH
Convergence to Equilibrium of No-regret Dynamics in Congestion Games
Congestion games are used to describe the behavior of agents who share a set of resources. Each player chooses a combination of resources, which may become congested, decreasing utility for the players who choose them. Players can avoid congestion by choosing combinations that are less popular. This is useful for modeling a range of real-world scenarios, such as traffic flow, data routing, and wireless communication networks.
In a recent paper: Convergence to Equilibrium of No-regret Dynamics in Congestion Games; researchers from Microsoft and external colleagues propose CongestEXP, a decentralized algorithm based on the classic exponential weights method. They evaluate CongestEXP in a traffic congestion game setting. As more drivers use a particular route, congestion increases, leading to higher travel times and lower utility. Players can choose a different route every day to optimize their utility, but the observed utility by each player may be subject to randomness due to uncertainty (e.g., bad weather). The researchers show that this approach provides both regret guarantees and convergence to Nash Equilibrium, where no player can unilaterally improve their outcome by changing their strategy.
NEW RESEARCH
RD-Agent: An open-source solution for smarter R&D
Research and development (R&D) plays a pivotal role in boosting industrial productivity. However, the rapid advance of AI has exposed the limitations of traditional R&D automation. Current methods often lack the intelligence needed to support innovative research and complex development tasks, underperforming human experts with deep knowledge.
LLMs trained on vast datasets spanning many subjects are equipped with extensive knowledge and reasoning capabilities that support complex decision-making in diverse workflows. By autonomously performing tasks and analyzing data, LLMs can significantly increase the efficiency and precision of R&D processes.
In a recent article, researchers from Microsoft introduce RD-Agent, a tool that integrates data-driven R&D systems and harnesses advanced AI to automate innovation and development.
At the heart of RD-Agent is an autonomous agent framework with two key components: a) Research and b) Development. Research focuses on actively exploring and generating new ideas, while Development implements these ideas. Both components improve through an iterative process, illustrated in Figure 1 of the article, ensures the system becomes increasingly effective over time.
Spotlight: Blog post

MedFuzz: Exploring the robustness of LLMs on medical challenge problems
Medfuzz tests LLMs by breaking benchmark assumptions, exposing vulnerabilities to bolster real-world accuracy.
Microsoft Research | In case you missed it
Microsoft Research 2024: A year in review
December 20, 2024
Microsoft Research did extraordinary work this year, using AI and scientific research to make progress on real-world challenges like climate change, food security, global health, and human trafficking. Here’s a look back at the broad range of accomplishments and advances in 2024.
AIOpsLab: Building AI agents for autonomous clouds
December 20, 2024
AIOpsLab is a holistic evaluation framework for researchers and developers, to enable the design, development, evaluation, and enhancement of AIOps agents, which also serves the purpose of reproducible, standardized, interoperable, and scalable benchmarks.
Yasuyuki Matsushita, IEEE Computer Society 2025 Fellow
December 19, 2024
Congratulations to Yasuyuki Matsushita, Senior Principal Research Manager at Microsoft Research, who was named a 2025 IEEE Computer Society Fellow. Matsushita was recognized for contributions to photometric 3D modeling and computational photography.
The post Research Focus: Week of January 13, 2025 appeared first on Microsoft Research.
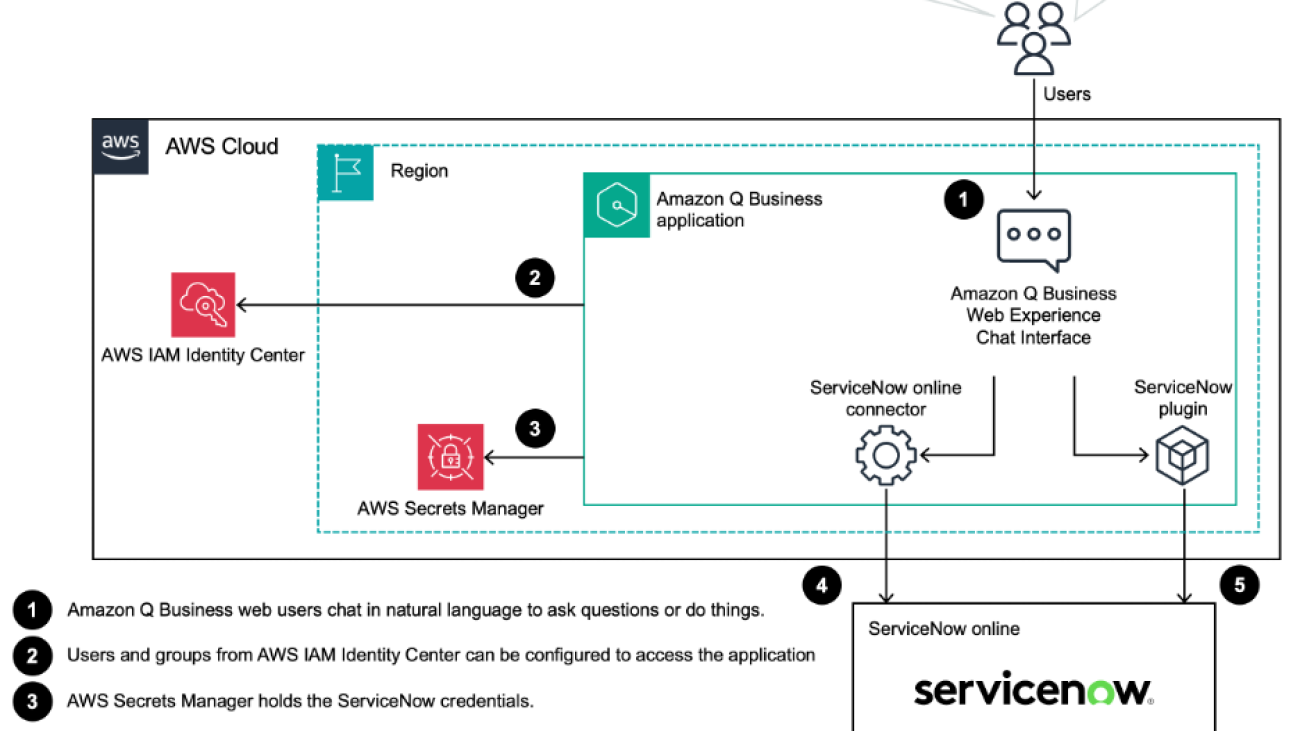
How Kyndryl integrated ServiceNow and Amazon Q Business
This post is co-written with Sujith R Pillai from Kyndryl.
In this post, we show you how Kyndryl, an AWS Premier Tier Services Partner and IT infrastructure services provider that designs, builds, manages, and modernizes complex, mission-critical information systems, integrated Amazon Q Business with ServiceNow in a few simple steps. You will learn how to configure Amazon Q Business and ServiceNow, how to create a generative AI plugin for your ServiceNow incidents, and how to test and interact with ServiceNow using the Amazon Q Business web experience. By the end of this post, you will be able to enhance your ServiceNow experience with Amazon Q Business and enjoy the benefits of a generative AI–powered interface.
Solution overview
Amazon Q Business has three main components: a front-end chat interface, a data source connector and retriever, and a ServiceNow plugin. Amazon Q Business uses AWS Secrets Manager secrets to store the ServiceNow credentials securely. The following diagram shows the architecture for the solution.

Chat
Users interact with ServiceNow through the generative AI–powered chat interface using natural language.
Data source connector and retriever
A data source connector is a mechanism for integrating and synchronizing data from multiple repositories into one container index. Amazon Q Business has two types of retrievers: native retrievers and existing retrievers using Amazon Kendra. The native retrievers support a wide range of Amazon Q Business connectors, including ServiceNow. The existing retriever option is for those who already have an Amazon Kendra retriever and would like to use that for their Amazon Q Business application. For the ServiceNow integration, we use the native retriever.
ServiceNow plugin
Amazon Q Business provides a plugin feature for performing actions such as creating incidents in ServiceNow.
The following high-level steps show how to configure the Amazon Q Business – ServiceNow integration:
- Create a user in ServiceNow for Amazon Q Business to communicate with ServiceNow
- Create knowledge base articles in ServiceNow if they do not exist already
- Create an Amazon Q Business application and configure the ServiceNow data source and retriever in Amazon Q Business
- Synchronize the data source
- Create a ServiceNow plugin in Amazon Q Business
Prerequisites
To run this application, you must have an Amazon Web Services (AWS) account, an AWS Identity and Access Management (IAM) role, and a user that can create and manage the required resources. If you are not an AWS account holder, see How do I create and activate a new Amazon Web Services account?
You need an AWS IAM Identity Center set up in the AWS Organizations organizational unit (OU) or AWS account in which you are building the Amazon Q Business application. You should have a user or group created in IAM Identity Center. You will assign this user or group to the Amazon Q Business application during the application creation process. For guidance, refer to Manage identities in IAM Identity Center.
You also need a ServiceNow user with incident_manager and knowledge_admin permissions to create and view knowledge base articles and to create incidents. We use a developer instance of ServiceNow for this post as an example. You can find out how to get the developer instance in Personal Developer Instances.
Solution walkthrough
To integrate ServiceNow and Amazon Q Business, use the steps in the following sections.
Create a knowledge base article
Follow these steps to create a knowledge base article:
- Sign in to ServiceNow and navigate to Self-Service > Knowledge
- Choose Create an Article
- On the Create new article page, select a knowledge base and choose a category. Optionally, you may create a new category.
- Provide a Short description and type in the Article body
- Choose Submit to create the article, as shown in the following screenshot
Repeat these steps to create a couple of knowledge base articles. In this example, we created a hypothetical enterprise named Example Corp for demonstration purposes.

Create an Amazon Q Business application
Amazon Q offers three subscription plans: Amazon Q Business Lite, Amazon Q Business Pro, and Amazon Q Developer Pro. Read the Amazon Q Documentation for more details. For this example, we used Amazon Q Business Lite.
Create application
Follow these steps to create an application:
- In the Amazon Q Business console, choose Get started, then choose Create application to create a new Amazon Q Business application, as shown in the following screenshot

- Name your application in Application name. In Service access, select Create and use a new service-linked role (SLR). For more information about example service roles, see IAM roles for Amazon Q Business. For information on service-linked roles, including how to manage them, see Using service-linked roles for Amazon Q Business. We named our application ServiceNow-Helpdesk. Next, select Create, as shown in the following screenshot.

Choose a retriever and index provisioning
To choose a retriever and index provisioning, follow these steps in the Select retriever screen, as shown in the following screenshot:
- For Retrievers, select Use native retriever
- For Index provisioning, choose Starter
- Choose Next

Connect data sources
Amazon Q Business has ready-made connectors for common data sources and business systems.
- Enter “ServiceNow” to search and select ServiceNow Online as the data source, as shown in the following screenshot

- Enter the URL and the version of your ServiceNow instance. We used the ServiceNow version Vancouver for this post.

- Scroll down the page to provide additional details about the data source. Under Authentication, select Basic authentication. Under AWS Secrets Manager secret, select Create and add a new secret from the dropdown menu as shown in the screenshot.

- Provide the Username and Password you created in ServiceNow to create an AWS Secrets Manager secret. Choose Save.

- Under Configure VPC and security group, keep the setting as No VPC because you will be connecting to the ServiceNow by the internet. You may choose to create a new service role under IAM role. This will create a role specifically for this application.

- In the example, we synchronize the ServiceNow knowledge base articles and incidents. Provide the information as shown in the following image below. Notice that for Filter query the example shows the following code.
This filter query aims to sync the articles that meet the following criteria:
- workflow_state = published
- kb_knowledge_base = dfc19531bf2021003f07e2c1ac0739ab (This is the default Sys ID for the knowledge base named “Knowledge” in ServiceNow).
- Type = text (This field contains the text in the Knowledge article).
- Active = true (This field filters the articles to sync only the ones that are active).
The filter fields are separated by ^, and the end of the query is represented by EQ. You can find more details about the Filter query and other parameters in Connecting Amazon Q Business to ServiceNow Online using the console.

- Provide the Sync scope for the Incidents, as shown in the following screenshot

- You may select Full sync initially so that a complete synchronization is performed. You need to select the frequency of the synchronization as well. For this post, we chose Run on demand. If you need to keep the knowledge base and incident data more up-to-date with the ServiceNow instance, choose a shorter window.

- A field mapping will be provided for you to validate. You won’t be able to change the field mapping at this stage. Choose Add data source to proceed.

This completes the data source configuration for Amazon Q Business. The configuration takes a few minutes to be completed. Watch the screen for any errors and updates. Once the data source is created, you will be greeted with a message You successfully created the following data source: ‘ServiceNow-Datasource’
Add users and groups
Follow these steps to add users and groups:
- Choose Next
- In the Add groups and users page, click Add groups and users. You will be presented with the option of Add and assign new users or Assign existing users and groups. Select Assign existing users and groups. Choose Next, as shown in the following image.

- Search for an existing user or group in your IAM Identity Center, select one, and choose Assign. After selecting the right user or group, choose Done.
This completes the activity of assigning the user and group access to the Amazon Q Business application.

Create a web experience
Follow these steps to create a web experience in the Add groups and users screen, as shown in the following screenshot.
- Choose Create and use a new service role in the Web experience service access section
- Choose Create application

The deployed application with the application status will be shown in the Amazon Q Business > Applications console as shown in the following screenshot.

Synchronize the data source
Once the data source is configured successfully, it’s time to start the synchronization. To begin this process, the ServiceNow fields that require synchronization must be updated. Because we intend to get answers from the knowledge base content, the text field needs to be synchronized. To do so, follow these steps:
- In the Amazon Q Business console, select Applications in the navigation pane
- Select ServiceNow-Helpdesk and then ServiceNow-Datasource
- Choose Actions. From the dropdown, choose Edit, as shown in the following screenshot.

- Scroll down to the bottom of the page to the Field mappings Select text and description.

- Choose Update. After the update, choose Sync now.

The synchronization takes a few minutes to complete depending on the amount of data to be synchronized. Make sure that the Status is Completed, as shown in the following screenshot, before proceeding further. If you notice any error, you can choose the error hyperlink. The error hyperlink will take you to Amazon CloudWatch Logs to examining the logs for further troubleshooting.

Create ServiceNow plugin
A ServiceNow plugin in Amazon Q Business helps you create incidents in ServiceNow through Amazon Q Business chat. To create one, follow these steps:
- In the Amazon Q Business console, select Enhancements from the navigation pane
- Under Plugins, choose Add plugin, as shown in the following screenshot

- In the Add Plugin page, shown in the following screenshot, and select the ServiceNow plugin

- Provide a Name for the plugin
- Enter the ServiceNow URL and use the previously created AWS Secrets Manager secret for the Authentication
- Select Create and use a new service role
- Choose Add plugin

- The status of the plugin will be shown in the Plugins If Plugin status is Active, the plugin is configured and ready to use.

Use the Amazon Q Business chat interface
To use the Amazon Q Business chat interface, follow these steps:
- In the Amazon Q Business console, choose Applications from the navigation pane. The web experience URL will be provided for each Amazon Q Business application.

- Choose the Web experience URL to open the chat interface. Enter an IAM Identity Center username and password that was assigned to this application. The following screenshot shows the Sign in

You can now ask questions and receive responses, as shown in the following image. The answers will be specific to your organization and are retrieved from the knowledge base in ServiceNow.

You can ask the chat interface to create incidents as shown in the next screenshot.
A new pop-up window will appear, providing additional information related to the incident. In this window, you can provide more information related to the ticket and choose Create.

This will create a ServiceNow incident using the web experience of Amazon Q Business without signing in to ServiceNow. You may verify the ticket in the ServiceNow console as shown in the next screenshot.

Conclusion
In this post, we showed how Kyndryl is using Amazon Q Business to enable natural language conversations with ServiceNow using the ServiceNow connector provided by Amazon Q Business. We also showed how to create a ServiceNow plugin that allows users to create incidents in ServiceNow directly from the Amazon Q Business chat interface. We hope that this tutorial will help you take advantage of the power of Amazon Q Business for your ServiceNow needs.
About the authors
 Asif Fouzi is a Principal Solutions Architect leading a team of seasoned technologists supporting Global Service Integrators (GSI) such as Kyndryl in their cloud journey. When he is not innovating on behalf of users, he likes to play guitar, travel, and spend time with his family.
Asif Fouzi is a Principal Solutions Architect leading a team of seasoned technologists supporting Global Service Integrators (GSI) such as Kyndryl in their cloud journey. When he is not innovating on behalf of users, he likes to play guitar, travel, and spend time with his family.

Sujith R Pillai is a cloud solution architect in the Cloud Center of Excellence at Kyndryl with extensive experience in infrastructure architecture and implementation across various industries. With his strong background in cloud solutions, he has led multiple technology transformation projects for Kyndryl customers.

NVIDIA Releases NIM Microservices to Safeguard Applications for Agentic AI
AI agents are poised to transform productivity for the world’s billion knowledge workers with “knowledge robots” that can accomplish a variety of tasks. To develop AI agents, enterprises need to address critical concerns like trust, safety, security and compliance.
New NVIDIA NIM microservices for AI guardrails — part of the NVIDIA NeMo Guardrails collection of software tools — are portable, optimized inference microservices that help companies improve the safety, precision and scalability of their generative AI applications.
Central to the orchestration of the microservices is NeMo Guardrails, part of the NVIDIA NeMo platform for curating, customizing and guardrailing AI. NeMo Guardrails helps developers integrate and manage AI guardrails in large language model (LLM) applications. Industry leaders Amdocs, Cerence AI and Lowe’s are among those using NeMo Guardrails to safeguard AI applications.
Developers can use the NIM microservices to build more secure, trustworthy AI agents that provide safe, appropriate responses within context-specific guidelines and are bolstered against jailbreak attempts. Deployed in customer service across industries like automotive, finance, healthcare, manufacturing and retail, the agents can boost customer satisfaction and trust.
One of the new microservices, built for moderating content safety, was trained using the Aegis Content Safety Dataset — one of the highest-quality, human-annotated data sources in its category. Curated and owned by NVIDIA, the dataset is publicly available on Hugging Face and includes over 35,000 human-annotated data samples flagged for AI safety and jailbreak attempts to bypass system restrictions.
NVIDIA NeMo Guardrails Keeps AI Agents on Track
AI is rapidly boosting productivity for a broad range of business processes. In customer service, it’s helping resolve customer issues up to 40% faster. However, scaling AI for customer service and other AI agents requires secure models that prevent harmful or inappropriate outputs and ensure the AI application behaves within defined parameters.
NVIDIA has introduced three new NIM microservices for NeMo Guardrails that help AI agents operate at scale while maintaining controlled behavior:
- Content safety NIM microservice that safeguards AI against generating biased or harmful outputs, ensuring responses align with ethical standards.
- Topic control NIM microservice that keeps conversations focused on approved topics, avoiding digression or inappropriate content.
- Jailbreak detection NIM microservice that adds protection against jailbreak attempts, helping maintain AI integrity in adversarial scenarios.
By applying multiple lightweight, specialized models as guardrails, developers can cover gaps that may occur when only more general global policies and protections exist — as a one-size-fits-all approach doesn’t properly secure and control complex agentic AI workflows.
Small language models, like those in the NeMo Guardrails collection, offer lower latency and are designed to run efficiently, even in resource-constrained or distributed environments. This makes them ideal for scaling AI applications in industries such as healthcare, automotive and manufacturing, in locations like hospitals or warehouses.
Industry Leaders and Partners Safeguard AI With NeMo Guardrails
NeMo Guardrails, available to the open-source community, helps developers orchestrate multiple AI software policies — called rails — to enhance LLM application security and control. It works with NVIDIA NIM microservices to offer a robust framework for building AI systems that can be deployed at scale without compromising on safety or performance.
Amdocs, a leading global provider of software and services to communications and media companies, is harnessing NeMo Guardrails to enhance AI-driven customer interactions by delivering safer, more accurate and contextually appropriate responses.
“Technologies like NeMo Guardrails are essential for safeguarding generative AI applications, helping make sure they operate securely and ethically,” said Anthony Goonetilleke, group president of technology and head of strategy at Amdocs. “By integrating NVIDIA NeMo Guardrails into our amAIz platform, we are enhancing the platform’s ‘Trusted AI’ capabilities to deliver agentic experiences that are safe, reliable and scalable. This empowers service providers to deploy AI solutions safely and with confidence, setting new standards for AI innovation and operational excellence.”
Cerence AI, a company specializing in AI solutions for the automotive industry, is using NVIDIA NeMo Guardrails to help ensure its in-car assistants deliver contextually appropriate, safe interactions powered by its CaLLM family of large and small language models.
“Cerence AI relies on high-performing, secure solutions from NVIDIA to power our in-car assistant technologies,” said Nils Schanz, executive vice president of product and technology at Cerence AI. “Using NeMo Guardrails helps us deliver trusted, context-aware solutions to our automaker customers and provide sensible, mindful and hallucination-free responses. In addition, NeMo Guardrails is customizable for our automaker customers and helps us filter harmful or unpleasant requests, securing our CaLLM family of language models from unintended or inappropriate content delivery to end users.”
Lowe’s, a leading home improvement retailer, is leveraging generative AI to build on the deep expertise of its store associates. By providing enhanced access to comprehensive product knowledge, these tools empower associates to answer customer questions, helping them find the right products to complete their projects and setting a new standard for retail innovation and customer satisfaction.
“We’re always looking for ways to help associates to above and beyond for our customers,” said Chandhu Nair, senior vice president of data, AI and innovation at Lowe’s. “With our recent deployments of NVIDIA NeMo Guardrails, we ensure AI-generated responses are safe, secure and reliable, enforcing conversational boundaries to deliver only relevant and appropriate content.”
To further accelerate AI safeguards adoption in AI application development and deployment in retail, NVIDIA recently announced at the NRF show that its NVIDIA AI Blueprint for retail shopping assistants incorporates NeMo Guardrails microservices for creating more reliable and controlled customer interactions during digital shopping experiences.
Consulting leaders Taskus, Tech Mahindra and Wipro are also integrating NeMo Guardrails into their solutions to provide their enterprise clients safer, more reliable and controlled generative AI applications.
NeMo Guardrails is open and extensible, offering integration with a robust ecosystem of leading AI safety model and guardrail providers, as well as AI observability and development tools. It supports integration with ActiveFence’s ActiveScore, which filters harmful or inappropriate content in conversational AI applications, and provides visibility, analytics and monitoring.
Hive, which provides its AI-generated content detection models for images, video and audio content as NIM microservices, can be easily integrated and orchestrated in AI applications using NeMo Guardrails.
The Fiddler AI Observability platform easily integrates with NeMo Guardrails to enhance AI guardrail monitoring capabilities. And Weights & Biases, an end-to-end AI developer platform, is expanding the capabilities of W&B Weave by adding integrations with NeMo Guardrails microservices. This enhancement builds on Weights & Biases’ existing portfolio of NIM integrations for optimized AI inferencing in production.
NeMo Guardrails Offers Open-Source Tools for AI Safety Testing
Developers ready to test the effectiveness of applying safeguard models and other rails can use NVIDIA Garak — an open-source toolkit for LLM and application vulnerability scanning developed by the NVIDIA Research team.
With Garak, developers can identify vulnerabilities in systems using LLMs by assessing them for issues such as data leaks, prompt injections, code hallucination and jailbreak scenarios. By generating test cases involving inappropriate or incorrect outputs, Garak helps developers detect and address potential weaknesses in AI models to enhance their robustness and safety.
Availability
NVIDIA NeMo Guardrails microservices, as well as NeMo Guardrails for rail orchestration and the NVIDIA Garak toolkit, are now available for developers and enterprises. Developers can get started building AI safeguards into AI agents for customer service using NeMo Guardrails with this tutorial.
See notice regarding software product information.
Fantastic Four-ce Awakens: Season One of ‘Marvel Rivals’ Joins GeForce NOW
Time to suit up, members. The multiverse is about to get a whole lot cloudier as GeForce NOW opens a portal to the first season of hit game Marvel Rivals from NetEase Games.
Members can now game in a new dimension with expanded support for virtual- and mixed-reality devices. This week’s GeForce NOW app update 2.0.70 begins rolling out compatibility for Apple Vision Pro spatial computers, Meta Quest 3 and 3S, and Pico 4 and 4 Ultra devices.
Plus, no GFN Thursday is complete without new games. Get ready for seven new titles joining the cloud this week, including multiplayer online battle arena game SMITE 2.
Invisible No More

Eternal night falls for Marvel Rivals, the superhero, team-based player vs. player shooter that lets players assemble an ever-evolving all-star squad of Super Heroes and Super Villains battling with unique powers across a dynamic lineup of destructible maps from the Marvel Multiverse.
The Fantastic Four will be playable in season one of the game. For Eternal Night Falls, Invisible Woman and Mister Fantastic will be released in the first half of the season, followed by Human Torch and The Thing in the second. Season one will also feature three new maps, special events and an all-new Doom Match game mode.
Stream it all with a GeForce NOW membership across devices, from an underpowered laptop, Mac devices, a Steam Deck or the supported platform of virtual- and mixed-reality devices.
Head in the Clouds
The latest GeForce NOW app update is expanding cloud streaming capabilities to Apple Vision Pro spatial computers, Meta Quest 3 and 3S, and Pico 4 and 4 Ultra virtual- and mixed-reality headsets starting this week.
These newly supported devices will give members access to an extensive library of games to stream through GeForce NOW. Members can gain access by visiting play.geforcenow.com or via the Android-native client on the PICO store. The rollout will be complete on Tuesday, Jan. 21.
Members will be able to transform their space into a personal gaming theater by playing, on massive virtual screens, their favorite PC games, such as the latest season of Marvel Rivals, Dragon Age and more. With access to NVIDIA technologies, including ray tracing and NVIDIA DLSS on supported games, these devices now provide an enhanced visual experience with the highest frame rates and lowest latency.
Here Comes The New

SMITE 2 is now free to play and has brought a huge update to mark the start of open beta. New god Aladdin joins, along with SMITE 1 fan favourites Geb, Agni, Mulan and Ullr — bringing the total god roster to 45. Twenty of the gods now feature Aspects — an optional spin on each god’s ability kit that opens up even more strategic options. The 3v3 mode Joust has also arrived, featuring a brand-new, Arthurian-themed map. Assault and Duel game modes are also available. Finally, the Conquest mode brings a wealth of updates to the map, features and balance.
- Hyper Light Breaker (New release on Steam, Jan. 14)
- Aloft (New release on Steam, Jan. 15)
- Assetto Corsa EVO (New release on Steam, Jan. 16)
- Generation Zero (Xbox, available on PC Game Pass)
- HOT WHEELS UNLEASHED 2 – Turbocharged (Xbox, available on PC Game Pass)
- SMITE 2 (Steam)
- Voidwrought (Steam)
What are you planning to play this weekend? Let us know on X or in the comments below.
Which role is your main?
Tank
Damage
Support
—
NVIDIA GeForce NOW (@NVIDIAGFN) January 15, 2025

Ideas: AI for materials discovery with Tian Xie and Ziheng Lu

Behind every emerging technology is a great idea propelling it forward. In the Microsoft Research Podcast series Ideas, members of the research community at Microsoft discuss the beliefs that animate their research, the experiences and thinkers that inform it, and the positive human impact it targets.
In this episode, guest host Lindsay Kalter talks with Principal Research Manager Tian Xie and Principal Researcher Ziheng Lu about their groundbreaking AI tools for materials discovery. Xie introduces MatterGen, which can generate new materials tailored to the specific needs of an application, such as materials with powerful magnetic properties or those that efficiently conduct lithium ions for better batteries. Lu explains how MatterSim accelerates simulations to validate and refine these discoveries. Together, these tools act as a “copilot” for scientists, proposing creative hypotheses and exploring vast material spaces far beyond traditional methods. The conversation highlights the challenges of bridging AI and experimental science and the potential of these tools to drive advancements in energy, manufacturing, and sustainability. At the cutting edge of AI research, Xie and Lu share their vision for the future of materials design and how these technologies could transform the field.
Learn more:
MatterSim: A deep-learning model for materials under real-world conditions
Microsoft Research blog, May 2024
MatterSim: A Deep Learning Atomistic Model Across Elements, Temperatures and Pressures
Publication, March 2024
MatterSim (opens in new tab)
GitHub repo
A generative model for inorganic materials design (opens in new tab)
Publication, January 2025
MatterGen: A Generative Model for Materials Design
Video, Microsoft Research Forum, June 2024
MatterGen: Property-guided materials design
Microsoft Research blog, December 2023
MatterGen (opens in new tab)
GitHub repo
Crystal Diffusion Variational Autoencoder for Periodic Material Generation
Publication, October 2021
Crystal Graph Convolutional Neural Networks for an Accurate and Interpretable Prediction of Material Properties
Publication, April 2018
Subscribe to the Microsoft Research Podcast:
Transcript
[TEASER] [MUSIC PLAYS UNDER DIALOGUE]TIAN XIE: Yeah, so the problem of generating materials from properties is actually a pretty old one. I still remember back in 2018, when I was giving a talk about property-prediction models, right, one of the first questions people asked is, instead of going from material structure to properties, can you, kind of, inversely generate the materials directly from their property conditions? So in a way, this is, kind of, like a dream for material scientists because, like, the end goal is really about finding materials property, right, [that] will satisfy your application.
ZIHENG LU: Previously, a lot of people are using this atomistic simulator and this generative models alone. But if you think about it, now that we have these two foundation models together, it really can make things different, right. You have a very good idea generator. And you have a very good goalkeeper. And you put them together. They form a loop. And now you can use this loop to design materials really quickly.
[TEASER ENDS]LINDSAY KALTER: You’re listening to Ideas, a Microsoft Research Podcast that dives deep into the world of technology research and the profound questions behind the code. In this series, we’ll explore the technologies that are shaping our future and the big ideas that propel them forward.
[MUSIC FADES]
I’m your guest host, Lindsay Kalter. Today I’m talking to Microsoft Principal Research Manager Tian Xie and Microsoft Principal Researcher Ziheng Lu. Tian is doing fascinating work with MatterGen, an AI tool for generating new materials guided by specific design requirements. Ziheng is one of the visionaries behind MatterSim, which puts those new materials to the test through advanced simulations. Together, they’re redefining what’s possible in materials science. Tian and Ziheng, welcome to the podcast.
TIAN XIE: Very excited to be here.
ZIHENG LU: Thanks, Lindsay, very excited.
KALTER: Before we dig into the specifics of MatterGen and MatterSim, let’s give our audience a sense of how you, as researchers, arrived at this moment. Materials science, especially at the intersection of computer science, is such a cutting-edge and transformative field. What first drew each of you to this space? And what, if any, moment or experience made you realize this was where you wanted to innovate? Tian, do you want to start?
XIE: So I started working on AI for materials back in 2015, when I started my PhD. So I come as a chemist and materials scientist, but I was, kind of, figuring out what I want to do during my PhD. So there is actually one moment really drove me into the field. That was AlphaGo. AlphaGo was, kind of, coming out in 2016, where it was able to beat the world champion in go in 2016. I was extremely impressed by that because I, kind of, learned how to do go, like, in my childhood. I know how hard it is and how much effort those professional go players have spent, right, in learning about go. So I, kind of, have the feeling that if AI can surpass the world-leading go players, one day, it will too surpass material scientists, right, in their ability to design novel materials. So that’s why I ended up deciding to focus my entire PhD on working on AI for materials. And I have been working on that since then. So it was actually very interesting because it was a very small field back then. And it’s great to see how much progress has been made, right, in the past 10 years and how much bigger a field it is now compared with 10 years ago.
LU: That’s very interesting, Tian. So, actually, I think I started, like, two years before you as a PhD student. So I, actually, I was trained as a computational materials scientist solely, not really an AI expert. But at that time, the computational materials science did not really work that well. It works but not working that well. So after, like, two or three years, I went back to experiments for, like, another two or three years because, I mean, the experiment is always the gold standard, right. And I worked on this experiments for a few years, and then about three years ago, I went back to this field of computation, especially because of AI. At that time, I think GPT and these large AI models that currently we’re using is not there, but we already have their prior forms like BERT, so we see the very large potential of AI. We know that these large AIs might work. So one idea is really to use AI to learn the entire space of materials and really grasp the physics there, and that really drove me to this field and that’s why I’m here working on this field, yeah.
KALTER: We’re going to get into what MatterGen and MatterSim mean for materials science—the potential, the challenges, and open questions. But first, give us an overview of what each of these tools are, how they do what they do, and—as this show is about big ideas—the idea driving the work. Ziheng, let’s have you go first.
LU: So MatterSim is a tool to do in silico characterizations of materials. If you think about working on materials, you have several steps. You first need to synthesize it, and then you need to characterize this. Basically, you need to know what property, what structures, whatever stuff about these materials. So for MatterSim, what we want to do is to really move the characterization process, a lot of these processes, into using computations. So the idea behind MatterSim is to really learn the fundamentals of physics. So we learn the energies and forces and stresses from these atomic structures and the charge densities, all of these things, and then with these, we can really simulate any sort of materials using our computational machines. And then with these, we can really characterize a lot of these materials’ properties using our computer, that is very fast. It’s much faster than we do experiments so that we can accelerate the materials design. So just in a word, basically, you input your material into your computer, a structure into your computer, and MatterSim will try to simulate these materials like what you do in a furnace or with an XRD (x-ray diffraction) and then you get your properties out of that, and a lot of times it’s much faster than you do experiments.
KALTER: All right, thank you very much. Tian, why don’t you tell us about MatterGen?
XIE: Yeah, thank you. So, actually, Ziheng, once you start with explaining MatterSim, it makes it much easier for me to explain MatterGen. So MatterGen actually represents a new way to design materials with generative AI. Material discovery is like finding needles in a haystack. You’re looking for a material with a very specific property for a material application. For example, like finding a room-temperature superconductor or finding a solid that can conduct a lithium ion very well inside a battery. So it’s like finding one very specific material from a million, kind of, candidates. So the conventional way of doing material discovery is via screening, where you, kind of, go over millions of candidates to find the one that you’re looking for, where MatterSim is able to significantly accelerate that process by making the simulation much faster. But it’s still very inefficient because you need to go through this million candidates, right. So with MatterGen, you can, kind of, directly generate materials given the prompts of the design requirements for the application. So this means that you can discover materials—discover useful materials— much more efficiently. And it also allows us to explore a much larger space beyond the set of known materials.
KALTER: Thank you, Tian. Can you tell us a little bit about how MatterGen and MatterSim work together?
XIE: So you can really think about MatterSim and MatterGen accelerating different parts of materials discovery process. MatterSim is trying to accelerate the simulation of material properties, while MatterGen is trying to accelerate the search of novel material candidates. It means that they can really work together as a flywheel and you can compound the acceleration from both models. They are also both foundation AI models, meaning they can both be used for a broad range of materials design problems. So we’re really looking forward to see how they can, kind of, working together iteratively as a tool to design novel materials for a broad range of applications.
LU: I think that’s a very good, like, general introduction of how they work together. I think I can provide an example of how they really fit together. If you want a material with a specific, like, bulk modulus or lithium-ion conductivity or thermal conductivity for your CPU chips, so basically what you want to do is start with a pool of material structures, like some structures from the database, and then you compute or you characterize your wanted property from that stack of materials. And then what you do, you’ve got these properties and structure pairs, and you input these pairs into MatterGen. And MatterGen will be able to give you a lot more of these structures that are highly possible to be real. But the number will be very large. For example, for the bulk modulus, I don’t remember the number we generated in our work … was that like thousands, tens of thousands?
XIE: Thousands, tens of thousands.
LU: Yeah, that would be a very large number pool even with MatterGen, so then the next step will be, how would you like to screen that? You cannot really just send all of those structures to a lab to synthesize. It’s too much, right. That’s when MatterSim again comes in. So MatterSim comes in and screen all those structures again and see which ones are the most likely to be synthesized and which ones have the closest property you wanted. And then after screening, you probably get five, 10 top candidates and then you send to a lab. Boom, everything goes down. That’s it.
KALTER: I’m wondering if there’s any prior research or advancements that you drew from in creating MatterGen and MatterSim. Were there any specific breakthroughs that influenced your approaches at all?
LU: Thanks, Lindsay. I think I’ll take that question first. So interestingly for MatterSim, a very fundamental idea was drew from Chi Chen, who was a previous lab mate of mine and now also works for Microsoft at Microsoft Quantum. He made this fantastic model named M3GNet, which is a prior form of a lot of these large-scale models for atomistic simulations. That model, M3GNet, actually resolves the near ground state prediction problem. I mean, the near ground state problem sounds like a fancy but not realistic word, but what that actually means is that it can simulate materials at near-zero covalent states. So basically at very low temperatures. So at that time, we were thinking since the models are now able to simulate materials at their near ground states, it’s not a very large space. But if you also look at other larger models, like GPT whatever, those models are large enough to simulate entire human language. So it’s possible to really extend the capability from these such prior models to very large space. Because we believe in the capability of AI, then it really drove us to use MatterSim to learn the entire space of materials. I mean, the entire space really means the entire periodic table, all the temperatures and the pressures people can actually grasp.
XIE: Yeah, I still remember a lot of the amazing works from Chi Chen whenever we’re, kind of, back working on property-prediction models. So, yeah, so the problem of generating materials from properties is actually a pretty old one. I still remember back in 2018, when I was, kind of, working on CGCNN (crystal graph convolutional neural networks) and giving a talk about property-prediction models, right, one of the first questions people asked is, OK, can you inverse this process? Instead of going from material structure to properties, can you, kind of, inversely generate the materials directly from their property conditions? So in a way, this is, kind of, like a dream for material scientists—some people even call it, like, holy grail—because, like, the end goal is really about finding materials property, right, [that] will satisfy your application. So I’ve been, kind of, thinking about this problem for a while and also there has been a lot of work, right, over the past few years in the community to build a generative model for materials. A lot of people have tried before, like 2020, using ideas like VAEs or GANs. But it’s hard to represent materials in this type of generative model architecture, and many of those models generated relatively poor candidates. So I thought it was a hard problem. I, kind of, know it for a while. But there is no good solutions back then. So I started to focus more on this problem during my postdoc, when I studied that in 2020 and I keep working on that in 2021. At the beginning, I wasn’t really sure exactly what approach to take because it’s, kind of, like open question and really tried a lot of random ideas. So one day actually in my group back then with Tommi Jaakkola and Regina Barzilay at MIT’s CSAIL (Computer Science & Artificial Intelligence Laboratory), we, kind of, get to know this method called diffusion model. It was a very early stage of a diffusion model back then, but it already began to show very promising signs, kind of, achieving state of art in many problems like 3D point cloud generation and the 3D molecular conformer generation. So the work that really inspired me a lot is two works that was for molecular conformer generation. One is ConfGF, and one is GeoDiff. So they, kind of, inspired me to, kind of, focus more on diffusion models. That actually lead to CDVAE (crystal diffusion variational autoencoder). So it’s interesting that we, kind of, spend like a couple of weeks in trying all this diffusion idea, and without that much work, it actually worked quite out of box. And at that time, CDVAE achieves much better performance than any previous models in materials generation, and we’re, kind of, super happy with that. So after CDVAE, I, kind of, joined Microsoft, now working with more people together on this problem of generative model for materials. So we, kind of, know what the limitations of CDVAE are, is that it can do unconditional material generation well means it can generate novel material structures, but it is very hard to use CDVAE to do property-guided generations. So basically, it uses an architecture called a variational autoencoder, where you have a latent space. So the way that you do property-guided generation there was to do a, kind of, a gradient update inside the latent space. But because the latent space wasn’t learned very well, so it actually … you cannot do, kind of, good property-guided generation. We only managed to do energy-guided generation, but it wasn’t successful in going beyond energy. So that comes us to really thinking, right, how can we make the property-guided generation much better? So I remember like one day, actually, my colleague, Daniel Zügner, who actually really showed me this blog which basically explains this idea of classifier-free guidance, which is the powerhouse behind the text-image generative models. And so, yeah, then we began to think about, can we actually make the diffusion model work for classifier-free guidance? That lead us to remove the, kind of, the variational autoencoder component from CDVAE and begin to work on a pure diffusion architecture. But then there was, kind of, a lot of development around that. But it turns out that classifier-free guidance is the key really to make property-guided generation work, and then combined with a lot more effort in, kind of, improving architecture and also generating more data and also trying out all these different downstream tasks that end up leading into MatterGen as we see today.
KALTER: Yeah, I think you’ve both done a really great job of explaining how MatterGen and MatterSim work together and how MatterGen can offer a lot in terms of reducing the amount of time and work that goes into finding new materials. Tian, how does the process of using MatterGen to generate materials translate into real-world applications?
XIE: Yeah, that’s a fantastic question. So one way that I think about MatterGen, right, is that you can think about it as like a copilot for materials scientists, right. So they can help you to come up with, kind of, potential good hypothesis for the materials design problems that you’re looking for. So say you’re trying to design a battery, right. So you may have some ideas over, OK, what candidates you want to make, but this is, kind of, based on your own experience, right. Depths of experience as a researcher. But MatterGen is able to, kind of, learn from a very broad set of data, so therefore, it may be able to come up with some good suggestions, even surprising suggestions, for you so that you can, kind of, try this out, right, both with computation or even one day in wet lab and experimentally synthesize it. But I also want to note that this, in a way, this is still an early stage in generative AI for materials means that I don’t expect all the candidates MatterGen generates will be, kind of, suits your needs, right. So you still need to, kind of, look into them with expertise or with some kind of computational screening. But I think in the future, as this model keep improving themselves, they will become a key component, right, in the design process of many of the materials we’re seeing today, like designing new batteries, new solar cells, or even computer chips, right, so that like Ziheng mentioned earlier.
KALTER: I want to pivot a little bit to the MatterSim side of things. I know identifying new combinations of compounds is key to meeting changing needs for things like sustainable materials. But testing them is equally important to developing materials that can be put to use. Ziheng, how does MatterSim handle the uncertainty of how materials behave under various conditions, and how do you ensure that the predictions remain robust despite the inherent complexity of molecular systems?
LU: Thanks. That’s a very, very good question. So uncertainty quantification is a key to make sure all these predictions and simulations are trustworthy. And that’s actually one of the questions we got almost every time after a presentation. So people will ask, well—especially those experimentalists—would ask, well, I’ve been using your model; how do I know those predictions are true under the very complex conditions I’m using in my experiments? So to understand how we deal with uncertainty, we need to know how MatterSim really functions in predicting an arbitrary property, especially under the condition you want, like the temperature and pressure. That would be quite complex, right? So in the ideal case, we would hope that by using MatterSim, you can directly simulate the properties you want using molecular dynamics combined with statistical mechanics. So if so, it would be easy to really quantify the uncertainty because there are just two parts: the error from the model and the error from the simulations, the statistical mechanics. So the error from the model will be able to be measured by, what we call, an ensemble. So basically you start with different random seeds when you train the model, and then when you predict your property, you use several models from the ensemble and then you get different numbers. If the variance from the numbers are very large, you’ll say the prediction is not that trustworthy. But a lot of times, we will see the variance is very small. So basically, an ensemble of several different models will give you almost exactly the same number; you’re quite sure that the number is somehow very, like, useful. So that’s one level of the way we want to get our property. But sometimes, it’s very hard to really directly simulate the property you want. For example, for catalytic processes, it’s very hard to imagine how you really get those coefficients. It’s very hard. The process is just too complicated. So for that process, what we do is to really use the, what we call, embeddings learned from the entire material space. So basically that vector we learned for any arbitrary material. And then start from that, we build a very shallow layer of a neural network to predict the property, but that also means you need to bring in some of your experimental or simulation data from your side. And for that way of predicting a property to measure the uncertainty, it’s still like the two levels, right. So we don’t really have the statistical error anymore, but what we have is, like, only the model error. So you can still stick to the ensemble, and then it will work, right. So to be short, so MatterSim can provide you an uncertainty to make sure the prediction tells you whether it’s true or not.
KALTER: So in many ways, MatterSim is the realist in the equation, and it’s there to sort of be a gatekeeper for MatterGen, which is the idea generator.
XIE: I really like the analogy.
LU: Yeah.
KALTER: As is the case with many AI models, the development of MatterGen and MatterSim relies on massive amounts of data. And here you use a simulation to create the needed training data. Can you talk about that process and why you’ve chosen that approach, Tian?
XIE: So one advantage here is that we can really use large-scale simulation to generate data. So we have a lot of compute here at Microsoft on our Azure platform, right. So how we generate the data is that we use a method called density functional theory, DFT, which is a quantum mechanical method. And we use a simulation workflow built on top with DFT to simulate the stability of materials. So what we do is that we curate a huge amount of material structures from multiple different sources of open data, mostly including Materials Project and Alexandria database, and in total, there are around 3 million materials candidates coming from these two databases. But not all of these structures, they are stable. So therefore, we try to use DFT to compute their stability and try to filter down the candidates such that we are making sure that our training data only have the most stable ones. This leads into around 600,000 training data, which was used to train the base model of MatterGen. So I want to note that actually we also use MatterSim as part of the workflow because MatterSim can be used to prescreen unstable candidates so that we don’t need to use DFT to compute all of them. I think at the end, we computed around 1 million DFT calculations where two-thirds of them, they are already filtered out by MatterSim, which saves us a lot of compute in generating our training data.
LU: Tian, you have a very good description of how we really get those ground state structures for the MatterGen model. Actually, we’ve been also using MatterGen for MatterSim to really get the training data. So if you think about the simulation space of materials, it’s extremely large. So we would think it in a way that it has three axis, so basically the elements, the temperature, and the pressure. So if you think about existing databases, they have pretty good coverage of the elements space. Basically, we think about Materials Project, NOMAD, they really have this very good coverage of lithium oxide, lithium sulfide, hydrogen sulfide, whatever, those different ground-state structures. But they don’t really tell you how these materials behave under certain temperature and pressure, especially under those extreme conditions like 1,600 Kelvin, which you really use to synthesize your materials. That’s where we really focused on to generate the data for MatterSim. So it’s really easy to think about how we generate the data, right. You put your wanted material into a pressure cooker, basically, molecular dynamics; it can simulate the materials behavior on the temperature and pressure. So that’s it. Sounds easy, right? But that’s not true because what we want is not one single material. What we want is the entire material space. So that will be making the effort almost impossible because the space is just so large. So that’s where we really develop this active learning pipeline. So basically, what we do is, like, we generate a lot of these structures for different elements and temperatures, pressures. Really, really a lot. And then what we do is, like, we ask the active learning or the uncertainty measurements to really say whether the model knows about this structure already. So if the model thinks, well, I think I know the structure already. So then, we don’t really calculate this structure using density function theory, as Tian just said. So this will really save us like 99% of the effort in generating the data. So in the end, by combining this molecular dynamics, basically pressure cooker, together with active learning, we gathered around 17 million data for MatterSim. So that was used to train the model. And now it can cover the entire periodic table and a lot of temperature and pressures.
KALTER: Thank you, Ziheng. Now, I’m sure this is not news to either one of you, given that you’re both at the forefront of these efforts, but there are a growing number of tools aimed at advancing materials science. So what is it about MatterGen and MatterSim in their approach or capabilities that distinguish them?
XIE: Yeah, I think I can start. So I think there is, in the past one year, there is a huge interest in building up generative AI tools for materials. So we have seen lots and lots of innovations from the community published in top conferences like NeurIPS, ICLR, ICML, etc. So I think what distinguishes MatterGen, in my point of view, are two things. First is that we are trained with a very big dataset that we curated very, very carefully, and we also spent quite a lot of time to refining our diffusion architecture, which means that our model is capable of generating very, kind of, high-quality, highly stable and novel materials. We have some kind of bar plot in our paper showcasing the advantage of our performance. I think that’s one key aspect. And I think the second aspect, which in my point of view is even more important, is that it has the ability to do property-guided generation. Many of the works that we saw in the community, they are more focused on the problem of crystal structure prediction, which MatterGen can also do, but we focus more on really property-guided generation because we think this is one of the key problems that really materials scientists care about. So the ability to do a very broad range of property-guided generation—and we have, kind of, both computational and now experimental result to validate those—I think that’s the second strong point for MatterGen.
KALTER: Ziheng, do you want to add to that?
LU: Yeah, thanks, Lindsay. So on the MatterSim side, I think it’s really the diverse condition it can handle that makes a difference. We’ve been talking about, like, the training data we collected really covers the entire periodic table and also, more importantly, the temperatures from 0 Kelvin to 5,000 Kelvin and the pressures from 0 gigapascal to 1,000 gigapascal. That really covers what humans can control nowadays. I mean, it’s very hard to go beyond that. If you know anyone [who] can go beyond that, let me know. So that really makes MatterSim different. Like, it can handle the realistic conditions. I think beyond that, I would say the combo between MatterSim and MatterGen really makes these set of tools really different. So previously, a lot of people are using this atomistic simulator and this generative models alone. But if you think about it, now that we have these two foundation models together, they really can make things different, right. So we have predictor; we have the generator; you have a very good idea generator. And you have a very good goalkeeper. And you put them together. They form a loop. And now you can use this loop to design materials really quickly. So I would say to me, now, when I think about it, it’s really the combo that makes these set of tools different.
KALTER: I know that I’ve spoken with both of you recently about how there’s so much excitement around this, and it’s clear that we’re on the precipice of this—as both of you have called it—a paradigm shift. And Microsoft places a very strong emphasis on ensuring that its innovations are grounded in reality and capable of addressing real-world problems. So with that in mind, how do you balance the excitement of scientific exploration with the practical challenges of implementation? Tian, do you want to take this?
XIE: Yeah, I think this is a very, very important point, because … as there are so many hypes around AI that is happening right now, right. We must be very, very careful about the claims that we are making so that people will not have unrealistic expectations, right, over how these models can do. So for MatterGen, we’re pretty careful about that. We’re trying to, basically, we’re trying to say that this is an early stage of generative AI in materials where this model will be improved over time quite significantly, but you should not say, oh, all the materials generated by MatterGen is going to be amazing. That’s not what is happening today. So we try to be very careful to understand how far MatterGen is already capable of designing materials with real-world impact. So therefore, we went all the way to synthesize one material that was generated by MatterGen. So this material we generated is called tantalum chromium oxide1. So this is a new material. It has not been discovered before. And it was generated by MatterGen by conditioning a bulk modulus equal to 200 gigapascal. Bulk modulus is, like, the compressiveness of the material. So we end up measuring the experimental synthesized material experimentally, and the measured bulk modulus is 169 gigapascal, which is within 20% of error. So this is a very good proof concept, in our point of view, to show that, oh, you can actually give it a prompt, right, and then MatterGen can generate a material, and the material actually have the property that is very close to your target. But it’s still a proof of concept. And we’re still working to see how MatterGen can design materials that are much more useful with a much broader range of applications. And I’m sure that there will be more challenges we are seeing along the way. But we’re looking forward to further working with our experimental partners to, kind of, push this further. And also working with MatterSim, right, to see how these two tools can be used to design really useful materials and bringing this into real-world impact.
LU: Yeah, Tian, I think that’s very well said. It’s not really only for MatterGen. For MatterSim, we’re also very careful, right. So we really want to make sure that people understand how these models really behave under their instructions and understand, like, what they can do and they cannot do. So I think one thing that we really care about is that in the next few, maybe one or two years, we want to really work with our experimental partners to make this realistic materials, like, in different areas so that we can, even us, can really better understand the limitations and at the same time explore the forefront of materials science to make this excitement become true.
KALTER: Ziheng, could you give us a concrete example of what exactly MatterSim is capable of doing?
LU: Now MatterSim can really do, like, whatever you have on a potential energy surface. So what that means is, like, anything that can be simulated with the energy and forces, stresses alone. So to give you an example, we can compute … the first example would be the stability of a material. So basically, you input a structure, and from the energies of the relaxed structures, you can really tell whether the material is likely to be stable, like, the composition, right. So another example would be the thermal conductivity. Thermal conductivity is like a fundamental property of materials that tells you how fast heat can transfer in the material, right. So for MatterSim, it can really simulate how fast this heat can go through your diamond, your graphene, your copper, right. So basically, those are two examples. So these examples are based on energies and forces alone. But there are things MatterSim cannot do—at least for now. For example, you cannot really do anything related to electronic structures. So you cannot really compute the light absorption of a semitransparent material. That would be a no-no for now.
KALTER: It’s clear from speaking with researchers, both from MatterSim and MatterGen, that despite these very rapid advancements in technology, you take very seriously the responsibility to consider the broader implications of the challenges that are still ahead. How do you think about the ethical considerations of creating entirely new materials and simulating their properties, particularly in terms of things like safety, sustainability, and societal impact?
XIE: Yeah, that’s a fantastic question. So it’s extremely important that we are making sure that these AI tools, they are not misused. A potential misuse, right, as you just mentioned, is that people begin to use these AI tools—MatterGen, MatterSim—to, kind of, design harmful materials. There was actually extensive discussion over how generative AI tools that was originally purposed for drug design can be then misused to create bioweapons. So at Microsoft, we take this very seriously because we believe that when we create new technologies, you must also ensure that the technology is used responsibly. So we have an extensive process to ensure that all of our models respect those ethical considerations. In the meantime, as you mentioned, maybe sustainability and the societal impact, right, so there’s a huge amount these AI tools—MatterGen, MatterSim—can do for sustainability because a lot of the sustainability challenges, they are really, at the end, materials design challenges, right. So therefore, I think that MatterGen and MatterSim can really help with that in solving, in helping us to alleviate climate change and having positive societal impact for the broader society.
KALTER: And, Ziheng, how about from a simulation standpoint?
LU: Yeah, I think Tian gave a very good, like, description. At Microsoft, we are really careful about these ethical, like, considerations. So I would add a little bit on the more, like, the bright side of things. Like, so for MatterSim, like, it really carries out these simulations at atomic scales. So one thing you can think about is really the educational purpose. So back in my bachelor and PhD period, so I would sit, like, at the table and really grab a pen to really deal with those very complex equations and get into those statistics using my pen. It’s really painful. But now with MatterSim, these simulation tools at atomic level, what you can do is to really simulate the reactions, the movement of atoms, at atomic scale in real time. You can really see the chemical reactions and see the statistics. So you can get really the feeling, like very direct feeling, of how the system works instead of just working on those toy systems with your pen. I think it’s going to be a very good educational tool using MatterSim, yeah. Also MatterGen. MatterGen as, like, a generative tool and generating those i.i.d. (independent and identically distributed) distributions, it will be a perfect example to show the students how the Boltzmann distribution works. I think, Tian, you will agree with that, right?
XIE: 100%. Yeah, I really, really like the example that Ziheng mentioned about the educational purposes. I still remember, like, when I was, kind of, learning material simulation class, right. So everything is DFT. You, kind of, need to wait for an hour, right, for getting some simulation. Maybe then you’ll make some animation. Now you can do this in real time. This is, like, a huge step forward, right, for our young researchers to, kind of, gaining a sense, right, about how atoms interact at an atomic level.
LU: Yeah, and the results are really, I mean, true; not really those toy models. I think it’s going to be very exciting stuff.
KALTER: And, Tian, I’m directing this question to you, even though, Ziheng, I’m sure you can chime in, as well. But, Tian, I know that you and I have previously discussed this specifically. I know that you said back in, you know, 2017, 2018, that you knew an AI-based approach to materials science was possible but that even you were surprised by how far the technology has come so fast in aiding this area. What is the status of these tools right now? Are they in use? And if so, who are they available to? And, you know, what’s next for them?
XIE: Yes, this is a fantastic question, right. So I think for AI generative tools like MatterGen, as I said many times earlier, it’s still in its early stages. MatterGen is the first tool that we managed to show that generative AI can enable very broad property-guided generation, and we have managed to have experimental validation to show it’s possible. But it will take more work to show, OK, it can actually design batteries, can design solar cells, right. It can design really useful materials in these broader domains. So this is, kind of, exactly why we are now taking a pretty open approach with MatterGen. We make our code, our training data, and model weights available to the general public. We’re really hoping the community can really use our tools to the problem that they care about and even build on top of that. So in terms of what next, I always like to use what happened with generative AI for drugs, right, to kind of predict how generative AI will impact materials. Three years ago, there is a lot of research around generative model for drugs, first coming from the machine learning community, right. So then all the big drug companies begin to take notice, and then there are, kind of, researchers in these drug companies begin to use these tools in actual drug design processes. From my colleague, Marwin Segler, because he, kind of, works together with Novartis in Microsoft and Novartis collaboration, he has been basically telling me that at the beginning, all the chemists in the drug companies, they’re all very suspicious, right. The molecules generated by these generative models, they all look a bit weird, so they don’t believe this will work. But once these chemists see one or two examples that actually turns out to be performing pretty well from the experimental result, then they begin to build more trust, right, into these generative AI models. And today, these generative AI tools, they are part of the standard drug discovery pipeline that is widely used in all the drug companies. That is today. So I think generative AI for materials is going through a very similar period. People will have doubts; people will have suspicions at the beginning. But I think in three years, right, so it will become a standard tool over how people are going to design new solar cells, design new batteries, and many other different applications.
KALTER: Great. Ziheng, do you have anything to add to that?
LU: So actually for MatterSim, we released the model, I think, back in last year, December. I mean, both the weights and the models, right. So we’re really grateful how much the community has contributed to the repo. And now, I mean, we really welcome the community to contribute more to both MatterSim and MatterGen via our open-source code bases. So, I mean, the community effort is really important, yeah.
KALTER: Well, it has been fascinating to pick your brains, and as we close, you know, I know that you’re both capable of quite a bit, which you have demonstrated. I know that asking you to predict the future is a big ask, so I won’t explicitly ask that. But just as a fun thought exercise, let’s fast-forward 20 years and look back. How have MatterGen and MatterSim and the big ideas behind them impacted the world, and how are people better off because of how you and your teams have worked to make them a reality? Tian, you want to start?
XIE: Yeah, I think one of the biggest challenges our human society is going to face, right, in the next 20 years is going to be climate change, right, and there are so many materials design problems people need to solve in order to properly handle climate change, like finding new materials that can absorb CO2 from atmosphere to create a carbon capture industry or have a battery materials that is able to do large-scale energy grid storage so that we can fully utilizing all the wind powers and the solar power, etc., right. So if you want me to make one prediction, I really believe that these AI tools, like MatterGen and MatterSim, is going to play a central role in our human’s ability to design these new materials for climate problems. So therefore in 20 years, I would like to see we have already solved climate change, right. We have large-scale energy storage systems that was designed by AI that is … basically that we have removed all the fossil fuels, right, from our energy production, and for the rest of the carbon emissions that is very hard to remove, we will have a carbon capture industry with materials designed by AI that absorbs the CO2 from the atmosphere. It’s hard to predict exactly what will happen, but I think AI will play a key role, right, into defining how our society will look like in 20 years.
LU: Tian, very well said. So I think instead of really describing the future, I would really quote a science fiction scene in Iron Man. So basically in 20 years, I will say when we want to really get a new material, we will just sit in an office and say, “Well, J.A.R.V.I.S., can you design us a new material that really fits my newest MK 7 suit?” That will be the end. And it will run automatically, and we get this auto lab running, and all those MatterGen and MatterSim, these AI models, running, and then probably in a few hours, in a few days, we get the material.
KALTER: Well, I think I speak for many people from several industries when I say that I cannot wait to see what is on the horizon for these projects. Tian and Ziheng, thank you so much for joining us on Ideas. It’s been a pleasure.
[MUSIC]XIE: Thank you so much.
LU: Thank you.
[MUSIC FADES]
1 Learn more about MatterGen and the new material tantalum chromium oxide in the Nature paper “A generative model for inorganic materials design (opens in new tab).”
The post Ideas: AI for materials discovery with Tian Xie and Ziheng Lu appeared first on Microsoft Research.

MatterGen: A new paradigm of materials design with generative AI

Materials innovation is one of the key drivers of major technological breakthroughs. The discovery of lithium cobalt oxide in the 1980s laid the groundwork for today’s lithium-ion battery technology. It now powers modern mobile phones and electric cars, impacting the daily lives of billions of people. Materials innovation is also required for designing more efficient solar cells, cheaper batteries for grid-level energy storage, and adsorbents to recycle CO2 from atmosphere.
Finding a new material for a target application is like finding a needle in a haystack. Historically, this task has been done via expensive and time-consuming experimental trial-and-error. More recently, computational screening of large materials databases has allowed researchers to speed up this process. Nonetheless, finding the few materials with the desired properties still requires the screening of millions of candidates.
Today, in a paper published in Nature (opens in new tab), we share MatterGen, a generative AI tool that tackles materials discovery from a different angle. Instead of screening the candidates, it directly generates novel materials given prompts of the design requirements for an application. It can generate materials with desired chemistry, mechanical, electronic, or magnetic properties, as well as combinations of different constraints. MatterGen enables a new paradigm of generative AI-assisted materials design that allows for efficient exploration of materials, going beyond the limited set of known ones.

A novel diffusion architecture
MatterGen is a diffusion model that operates on the 3D geometry of materials. Much like an image diffusion model generates pictures from a text prompt by modifying the color of pixels from a noisy image, MatterGen generates proposed structures by adjusting the positions, elements, and periodic lattice from a random structure. The diffusion architecture is specifically designed for materials to handle specialties like periodicity and 3D geometry.

The base model of MatterGen achieves state-of-the-art performance in generating novel, stable, diverse materials (Figure 3). It is trained on 608,000 stable materials from the Materials Project (opens in new tab) (MP) and Alexandria (opens in new tab) (Alex) databases. The performance improvement can be attributed to both the architecture advancements, as well as the quality and size of our training data.

MatterGen can be fine-tuned with a labelled dataset to generate novel materials given any desired conditions. We demonstrate examples of generating novel materials given a target’s chemistry and symmetry, as well as electronic, magnetic, and mechanical property constraints (Figure 2).
Outperforming screening

The key advantage of MatterGen over screening is its ability to access the full space of unknown materials. In Figure 4, we show that MatterGen continues to generate more novel candidate materials with high bulk modulus above 400 GPa, for example, which are hard to compress. In contrast, screening baseline saturates due to exhausting known candidates.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Handling compositional disorder

Compositional disorder (Figure 5) is a commonly observed phenomenon where different atoms can randomly swap their crystallographic sites in a synthesized material. Recently (opens in new tab), the community has been exploring what it means for a material to be novel in the context of computationally designed materials, as widely employed algorithms will not distinguish between pairs of structures where the only difference is a permutation of similar elements in their respective sites.
We provide an initial solution to this issue by introducing a new structure matching algorithm that considers compositional disorder. The algorithm assesses whether a pair of structures can be identified as ordered approximations of the same underlying compositionally disordered structure. This provides a new definition of novelty and uniqueness, which we adopt in our computational evaluation metrics. We also make our algorithm publicly available (opens in new tab) as part of our evaluation package.
Experimental lab verification

In addition to our extensive computational evaluation, we have validated MatterGen’s capabilities through experimental synthesis. In collaboration with the team led by Prof Li Wenjie from the Shenzhen Institutes of Advanced Technology (opens in new tab) (SIAT) of the Chinese Academy of Sciences, we have synthesized a novel material, TaCr2O6, whose structure was generated by MatterGen after conditioning the model on a bulk modulus value of 200 GPa. The synthesized material’s structure aligns with the one proposed by MatterGen, with the caveat of compositional disorder between Ta and Cr. Additionally, we experimentally measure a bulk modulus of 169 GPa against the 200 GPa given as design specification, with a relative error below 20%, very close from an experimental perspective. If similar results can be translated to other domains, it will have a profound impact on the design of batteries, fuel cells, and more.
AI emulator and generator flywheel
MatterGen presents a new opportunity for AI accelerated materials design, complementing our AI emulator MatterSim. MatterSim follows the fifth paradigm of scientific discovery, significantly accelerating the speed of material properties’ simulations. MatterGen in turn accelerates the speed of exploring new material candidates with property guided generation. MatterGen and MatterSim can work together as a flywheel to speed up both the simulation and exploration of novel materials.
Making MatterGen available
We believe the best way to make an impact in materials design is to make our model available to the public. We release the source code of MatterGen (opens in new tab) under the MIT license, together with the training and fine-tuning data. We welcome the community to use and build on top of our model.
Looking ahead
MatterGen represents a new paradigm of materials design enabled by generative AI technology. It explores a significantly larger space of materials than screening-based methods. It is also more efficient by guiding materials exploration with prompts. Similar to how generative AI has impacted drug discovery (opens in new tab), it will have profound impact on how we design materials in broad domains including batteries, magnets, and fuel cells.
We plan to continue our work with external collaborators to further develop and validate the technology. “At the Johns Hopkins University Applied Physics Laboratory (APL), we’re dedicated to the exploration of tools with the potential to advance discovery of novel, mission-enabling materials. That’s why we are interested in understanding the impact that MatterGen could have on materials discovery,” said Christopher Stiles, a computational materials scientists leading multiple materials discovery efforts at APL.
Acknowledgement
This work is the result of highly collaborative team efforts at Microsoft Research AI for Science. The full authors include: Claudio Zeni, Robert Pinsler, Daniel Zügner, Andrew Fowler, Matthew Horton, Xiang Fu, Zilong Wang, Aliaksandra Shysheya, Jonathan Crabbé, Shoko Ueda, Roberto Sordillo, Lixin Sun, Jake Smith, Bichlien Nguyen, Hannes Schulz, Sarah Lewis, Chin-Wei Huang, Ziheng Lu, Yichi Zhou, Han Yang, Hongxia Hao, Jielan Li, Chunlei Yang, Wenjie Li, Ryota Tomioka, Tian Xie.
The post MatterGen: A new paradigm of materials design with generative AI appeared first on Microsoft Research.
Interpreting CLIP: Insights on the Robustness to ImageNet Distribution Shifts
What distinguishes robust models from non-robust ones? While for ImageNet distribution shifts it has been shown that such differences in robustness can be traced back predominantly to differences in training data, so far it is not known what that translates to in terms of what the model has learned. In this work, we bridge this gap by probing the representation spaces of 16 robust zero-shot CLIP vision encoders with various backbones (ResNets and ViTs) and pretraining sets (OpenAI, LAION-400M, LAION-2B, YFCC15M, CC12M and DataComp), and comparing them to the representation spaces of less…Apple Machine Learning Research