This post introduces HCLTech’s AutoWise Companion, a transformative generative AI solution designed to enhance customers’ vehicle purchasing journey. By tailoring recommendations based on individuals’ preferences, the solution guides customers toward the best vehicle model for them. Simultaneously, it empowers vehicle manufacturers (original equipment manufacturers (OEMs)) by using real customer feedback to drive strategic decisions, boosting sales and company profits. Powered by generative AI services on AWS and large language models’ (LLMs’) multi-modal capabilities, HCLTech’s AutoWise Companion provides a seamless and impactful experience.
In this post, we analyze the current industry challenges and guide readers through the AutoWise Companion solution functional flow and architecture design using built-in AWS services and open source tools. Additionally, we discuss the design from security and responsible AI perspectives, demonstrating how you can apply this solution to a wider range of industry scenarios.
Opportunities
Purchasing a vehicle is a crucial decision that can induce stress and uncertainty for customers. The following are some of the real-life challenges customers and manufacturers face:
- Choosing the right brand and model – Even after narrowing down the brand, customers must navigate through a multitude of vehicle models and variants. Each model has different features, price points, and performance metrics, making it difficult to make a confident choice that fits their needs and budget.
- Analyzing customer feedback – OEMs face the daunting task of sifting through extensive quality reporting tool (QRT) reports. These reports contain vast amounts of data, which can be overwhelming and time-consuming to analyze.
- Aligning with customer sentiments – OEMs must align their findings from QRT reports with the actual sentiments of customers. Understanding customer satisfaction and areas needing improvement from raw data is complex and often requires advanced analytical tools.
HCLTech’s AutoWise Companion solution addresses these pain points, benefiting both customers and manufacturers by simplifying the decision-making process for customers and enhancing data analysis and customer sentiment alignment for manufacturers.
The solution extracts valuable insights from diverse data sources, including OEM transactions, vehicle specifications, social media reviews, and OEM QRT reports. By employing a multi-modal approach, the solution connects relevant data elements across various databases. Based on the customer query and context, the system dynamically generates text-to-SQL queries, summarizes knowledge base results using semantic search, and creates personalized vehicle brochures based on the customer’s preferences. This seamless process is facilitated by Retrieval Augmentation Generation (RAG) and a text-to-SQL framework.
Solution overview
The overall solution is divided into functional modules for both customers and OEMs.
Customer assist
Every customer has unique preferences, even when considering the same vehicle brand and model. The solution is designed to provide customers with a detailed, personalized explanation of their preferred features, empowering them to make informed decisions. The solution presents the following capabilities:
- Natural language queries – Customers can ask questions in plain language about vehicle features, such as overall ratings, pricing, and more. The system is equipped to understand and respond to these inquiries effectively.
- Tailored interaction – The solution allows customers to select specific features from an available list, enabling a deeper exploration of their preferred options. This helps customers gain a comprehensive understanding of the features that best suit their needs.
- Personalized brochure generation – The solution considers the customer’s feature preferences and generates a customized feature explanation brochure (with specific feature images). This personalized document helps the customer gain a deeper understanding of the vehicle and supports their decision-making process.
OEM assist
OEMs in the automotive industry must proactively address customer complaints and feedback regarding various automobile parts. This comprehensive solution enables OEM managers to analyze and summarize customer complaints and reported quality issues across different categories, thereby empowering them to formulate data-driven strategies efficiently. This enhances decision-making and competitiveness in the dynamic automotive industry. The solution enables the following:
- Insight summaries – The system allows OEMs to better understand the insightful summary presented by integrating and aggregating data from various sources, such as QRT reports, vehicle transaction sales data, and social media reviews.
- Detailed view – OEMs can seamlessly access specific details about issues, reports, complaints, or data point in natural language, with the system providing the relevant information from the referred reviews data, transaction data, or unstructured QRT reports.
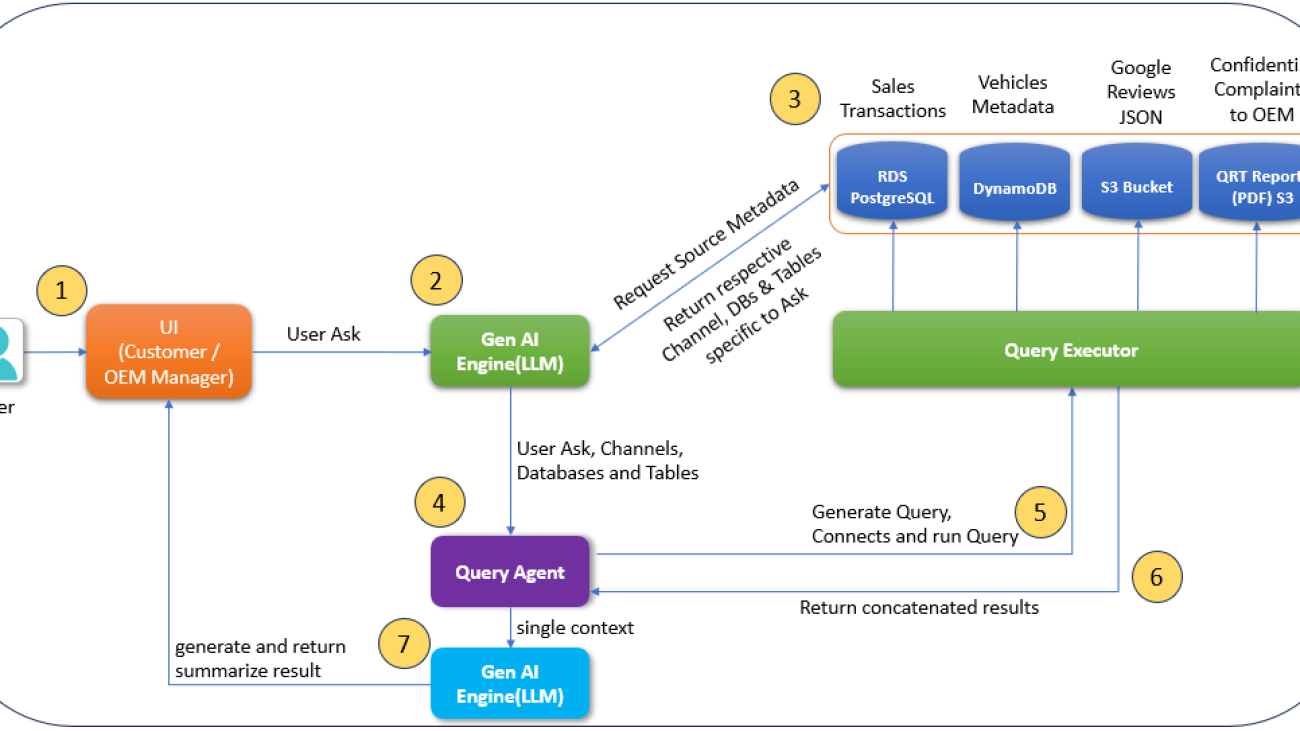
To better understand the solution, we use the seven steps shown in the following figure to explain the overall function flow.

The overall function flow consists of the following steps:
- The user (customer or OEM manager) interacts with the system through a natural language interface to ask various questions.
- The system’s natural language interpreter, powered by a generative AI engine, analyzes the query’s context, intent, and relevant persona to identify the appropriate data sources.
- Based on the identified data sources, the respective multi-source query execution plan is generated by the generative AI engine.
- The query agent parses the execution plan and send queries to the respective query executor.
- Requested information is intelligently fetched from multiple sources such as company product metadata, sales transactions, OEM reports, and more to generate meaningful responses.
- The system seamlessly combines the collected information from the various sources, applying contextual understanding and domain-specific knowledge to generate a well-crafted, comprehensive, and relevant response for the user.
- The system generates the response for the original query and empowers the user to continue the interaction, either by asking follow-up questions within the same context or exploring new areas of interest, all while benefiting from the system’s ability to maintain contextual awareness and provide consistently relevant and informative responses.
Technical architecture
The overall solution is implemented using AWS services and LangChain. Multiple LangChain functions, such as CharacterTextSplitter and embedding vectors, are used for text handling and embedding model invocations. In the application layer, the GUI for the solution is created using Streamlit in Python language. The app container is deployed using a cost-optimal AWS microservice-based architecture using Amazon Elastic Container Service (Amazon ECS) clusters and AWS Fargate.
The solution contains the following processing layers:
- Data pipeline – The various data sources, such as sales transactional data, unstructured QRT reports, social media reviews in JSON format, and vehicle metadata, are processed, transformed, and stored in the respective databases.
- Vector embedding and data cataloging – To support natural language query similarity matching, the respective data is vectorized and stored as vector embeddings. Additionally, to enable the natural language to SQL (text-to-SQL) feature, the corresponding data catalog is generated for the transactional data.
- LLM (request and response formation) – The system invokes LLMs at various stages to understand the request, formulate the context, and generate the response based on the query and context.
- Frontend application – Customers or OEMs interact with the solution using an assistant application designed to enable natural language interaction with the system.
The solution uses the following AWS data stores and analytics services:
- Unstructured data – Amazon Simple Storage Service (Amazon S3) buckets are used to store the JSON-based social media feedback data, quality report PDFs (specific to OEMs), and the vehicle and its features images.
- Transactional sales data – Amazon Relational Database Service (Amazon RDS) for PostgreSQL is used to hold transactional reports of vehicles on a quarterly or monthly basis.
- Vehicle specification data – Amazon DynamoDB is used to store the vehicle metadata (its features and specifications).
- Amazon Athena – Amazon Athena is used to query the JSON-based social media feedback data stored in an S3 bucket.
- AWS Glue – AWS Glue is used for data cataloging.
The following figure depicts the technical flow of the solution.

The workflow consists of the following steps:
- The user’s query, expressed in natural language, is processed by an orchestrated AWS Lambda
- The Lambda function tries to find the query match from the LLM cache. If a match is found, the response is returned from the LLM cache. If no match is found, the function invokes the respective LLMs through Amazon Bedrock. This solution uses LLMs (Anthropic’s Claude 2 and Claude 3 Haiku) on Amazon Bedrock for response generation. The Amazon Titan Embeddings G1 – Text LLM is used to convert the knowledge documents and user queries into vector embeddings.
- Based on the context of the query and the available catalog, the LLM identifies the relevant data sources:
- The transactional sales data, social media reviews, vehicle metadata, and more, are transformed and used for customers and OEM interactions.
- The data in this step is restricted and is only accessible for OEM personas to help diagnose the quality related issues and provide insights on the QRT reports. This solution uses Amazon Textract as a data extraction tool to extract text from PDFs (such as quality reports).
- The LLM generates queries (text-to-SQL) to fetch data from the respective data channels according to the identified sources.
- The responses from each data channel are assembled to generate the overall context.
- Additionally, to generate a personalized brochure, relevant images (described as text-based embeddings) are fetched based on the query context. Amazon OpenSearch Serverless is used as a vector database to store the embeddings of text chunks extracted from quality report PDFs and image descriptions.
- The overall context is then passed to a response generator LLM to generate the final response to the user. The cache is also updated.
Responsible generative AI and security considerations
Customers implementing generative AI projects with LLMs are increasingly prioritizing security and responsible AI practices. This focus stems from the need to protect sensitive data, maintain model integrity, and enforce ethical use of AI technologies. The AutoWise Companion solution uses AWS services to enable customers to focus on innovation while maintaining the highest standards of data protection and ethical AI use.
Amazon Bedrock Guardrails
Amazon Bedrock Guardrails provides configurable safeguards that can be applied to user input and foundation model output as safety and privacy controls. By incorporating guardrails, the solution proactively steers users away from potential risks or errors, promoting better outcomes and adherence to established standards. In the automobile industry, OEM vendors usually apply safety filters for vehicle specifications. For example, they want to validate the input to make sure that the queries are about legitimate existing models. Amazon Bedrock Guardrails provides denied topics and contextual grounding checks to make sure the queries about non-existent automobile models are identified and denied with a custom response.
Security considerations
The system employs a RAG framework that relies on customer data, making data security the foremost priority. By design, Amazon Bedrock provides a layer of data security by making sure that customer data stays encrypted and protected and is neither used to train the underlying LLM nor shared with the model providers. Amazon Bedrock is in scope for common compliance standards, including ISO, SOC, CSA STAR Level 2, is HIPAA eligible, and customers can use Amazon Bedrock in compliance with the GDPR.
For raw document storage on Amazon S3, transactional data storage, and retrieval, these data sources are encrypted, and respective access control mechanisms are put in place to maintain restricted data access.
Key learnings
The solution offered the following key learnings:
- LLM cost optimization – In the initial stages of the solution, based on the user query, multiple independent LLM calls were required, which led to increased costs and execution time. By using the AWS Glue Data Catalog, we have improved the solution to use a single LLM call to find the best source of relevant information.
- LLM caching – We observed that a significant percentage of queries received were repetitive. To optimize performance and cost, we implemented a caching mechanism that stores the request-response data from previous LLM model invocations. This cache lookup allows us to retrieve responses from the cached data, thereby reducing the number of calls made to the underlying LLM. This caching approach helped minimize cost and improve response times.
- Image to text – Generating personalized brochures based on customer preferences was challenging. However, the latest vision-capable multimodal LLMs, such as Anthropic’s Claude 3 models (Haiku and Sonnet), have significantly improved accuracy.
Industrial adoption
The aim of this solution is to help customers make an informed decision while purchasing vehicles and empowering OEM managers to analyze factors contributing to sales fluctuations and formulate corresponding targeted sales boosting strategies, all based on data-driven insights. The solution can also be adopted in other sectors, as shown in the following table.
| Industry | Solution adoption |
| Retail and ecommerce | By closely monitoring customer reviews, comments, and sentiments expressed on social media channels, the solution can assist customers in making informed decisions when purchasing electronic devices. |
| Hospitality and tourism | The solution can assist hotels, restaurants, and travel companies to understand customer sentiments, feedback, and preferences and offer personalized services. |
| Entertainment and media | It can assist television, movie studios, and music companies to analyze and gauge audience reactions and plan content strategies for the future. |
Conclusion
The solution discussed in this post demonstrates the power of generative AI on AWS by empowering customers to use natural language conversations to obtain personalized, data-driven insights to make informed decisions during the purchase of their vehicle. It also supports OEMs in enhancing customer satisfaction, improving features, and driving sales growth in a competitive market.
Although the focus of this post has been on the automotive domain, the presented approach holds potential for adoption in other industries to provide a more streamlined and fulfilling purchasing experience.
Overall, the solution demonstrates the power of generative AI to provide accurate information based on various structured and unstructured data sources governed by guardrails to help avoid unauthorized conversations. For more information, see the HCLTech GenAI Automotive Companion in AWS Marketplace.
About the Authors
 Bhajan Deep Singh leads the AWS Gen AI/AIML Center of Excellence at HCL Technologies. He plays an instrumental role in developing proof-of-concept projects and use cases utilizing AWS’s generative AI offerings. He has successfully led numerous client engagements to deliver data analytics and AI/machine learning solutions. He holds AWS’s AI/ML Specialty, AI Practitioner certification and authors technical blogs on AI/ML services and solutions. With his expertise and leadership, he enables clients to maximize the value of AWS generative AI.
Bhajan Deep Singh leads the AWS Gen AI/AIML Center of Excellence at HCL Technologies. He plays an instrumental role in developing proof-of-concept projects and use cases utilizing AWS’s generative AI offerings. He has successfully led numerous client engagements to deliver data analytics and AI/machine learning solutions. He holds AWS’s AI/ML Specialty, AI Practitioner certification and authors technical blogs on AI/ML services and solutions. With his expertise and leadership, he enables clients to maximize the value of AWS generative AI.
 Mihir Bhambri works as AWS Senior Solutions Architect at HCL Technologies. He specializes in tailored Generative AI solutions, driving industry-wide innovation in sectors such as Financial Services, Life Sciences, Manufacturing, and Automotive. Leveraging AWS cloud services and diverse Large Language Models (LLMs) to develop multiple proof-of-concepts to support business improvements. He also holds AWS Solutions Architect Certification and has contributed to the research community by co-authoring papers and winning multiple AWS generative AI hackathons.
Mihir Bhambri works as AWS Senior Solutions Architect at HCL Technologies. He specializes in tailored Generative AI solutions, driving industry-wide innovation in sectors such as Financial Services, Life Sciences, Manufacturing, and Automotive. Leveraging AWS cloud services and diverse Large Language Models (LLMs) to develop multiple proof-of-concepts to support business improvements. He also holds AWS Solutions Architect Certification and has contributed to the research community by co-authoring papers and winning multiple AWS generative AI hackathons.
 Yajuvender Singh is an AWS Senior Solution Architect at HCLTech, specializing in AWS Cloud and Generative AI technologies. As an AWS-certified professional, he has delivered innovative solutions across insurance, automotive, life science and manufacturing industries and also won multiple AWS GenAI hackathons in India and London. His expertise in developing robust cloud architectures and GenAI solutions, combined with his contributions to the AWS technical community through co-authored blogs, showcases his technical leadership.
Yajuvender Singh is an AWS Senior Solution Architect at HCLTech, specializing in AWS Cloud and Generative AI technologies. As an AWS-certified professional, he has delivered innovative solutions across insurance, automotive, life science and manufacturing industries and also won multiple AWS GenAI hackathons in India and London. His expertise in developing robust cloud architectures and GenAI solutions, combined with his contributions to the AWS technical community through co-authored blogs, showcases his technical leadership.
 Sara van de Moosdijk, simply known as Moose, is an AI/ML Specialist Solution Architect at AWS. She helps AWS partners build and scale AI/ML solutions through technical enablement, support, and architectural guidance. Moose spends her free time figuring out how to fit more books in her overflowing bookcase.
Sara van de Moosdijk, simply known as Moose, is an AI/ML Specialist Solution Architect at AWS. She helps AWS partners build and scale AI/ML solutions through technical enablement, support, and architectural guidance. Moose spends her free time figuring out how to fit more books in her overflowing bookcase.
 Jerry Li, is a Senior Partner Solution Architect at AWS Australia, collaborating closely with HCLTech in APAC for over four years. He also works with HCLTech Data & AI Center of Excellence team, focusing on AWS data analytics and generative AI skills development, solution building, and go-to-market (GTM) strategy.
Jerry Li, is a Senior Partner Solution Architect at AWS Australia, collaborating closely with HCLTech in APAC for over four years. He also works with HCLTech Data & AI Center of Excellence team, focusing on AWS data analytics and generative AI skills development, solution building, and go-to-market (GTM) strategy.
About HCLTech
HCLTech is at the vanguard of generative AI technology, using the robust AWS Generative AI tech stack. The company offers cutting-edge generative AI solutions that are poised to revolutionize the way businesses and individuals approach content creation, problem-solving, and decision-making. HCLTech has developed a suite of readily deployable generative AI assets and solutions, encompassing the domains of customer experience, software development life cycle (SDLC) integration, and industrial processes.


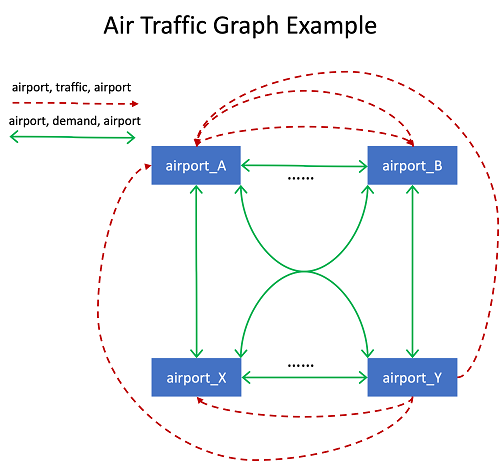
 Jian Zhang is a Senior Applied Scientist who has been using machine learning techniques to help customers solve various problems, such as fraud detection, decoration image generation, and more. He has successfully developed graph-based machine learning, particularly graph neural network, solutions for customers in China, the US, and Singapore. As an enlightener of AWS graph capabilities, Zhang has given many public presentations about GraphStorm, the GNN, the Deep Graph Library (DGL), Amazon Neptune, and other AWS services.
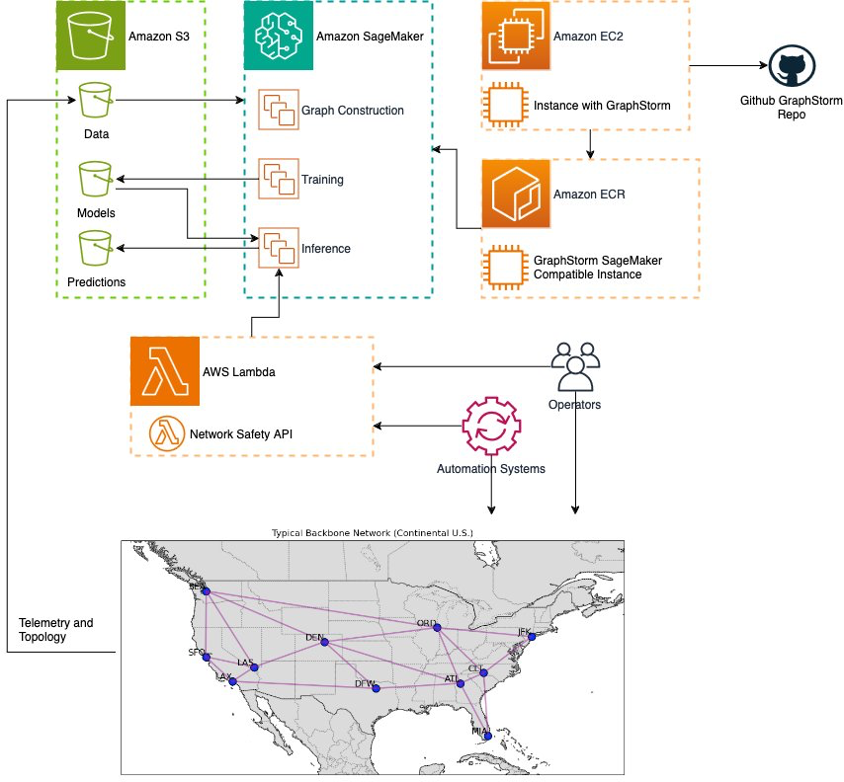
Jian Zhang is a Senior Applied Scientist who has been using machine learning techniques to help customers solve various problems, such as fraud detection, decoration image generation, and more. He has successfully developed graph-based machine learning, particularly graph neural network, solutions for customers in China, the US, and Singapore. As an enlightener of AWS graph capabilities, Zhang has given many public presentations about GraphStorm, the GNN, the Deep Graph Library (DGL), Amazon Neptune, and other AWS services. Fabien Chraim is a Principal Research Scientist in AWS networking. Since 2017, he’s been researching all aspects of network automation, from telemetry and anomaly detection to root causing and actuation. Before Amazon, he co-founded and led research and development at Civil Maps (acquired by Luminar). He holds a PhD in electrical engineering and computer sciences from UC Berkeley.
Fabien Chraim is a Principal Research Scientist in AWS networking. Since 2017, he’s been researching all aspects of network automation, from telemetry and anomaly detection to root causing and actuation. Before Amazon, he co-founded and led research and development at Civil Maps (acquired by Luminar). He holds a PhD in electrical engineering and computer sciences from UC Berkeley. Patrick Taylor is a Senior Data Scientist in AWS networking. Since 2020, he has focused on impact reduction and risk management in networking software systems and operations research in networking operations teams. Previously, Patrick was a data scientist specializing in natural language processing and AI-driven insights at Hyper Anna (acquired by Alteryx) and holds a Bachelor’s degree from the University of Sydney.
Patrick Taylor is a Senior Data Scientist in AWS networking. Since 2020, he has focused on impact reduction and risk management in networking software systems and operations research in networking operations teams. Previously, Patrick was a data scientist specializing in natural language processing and AI-driven insights at Hyper Anna (acquired by Alteryx) and holds a Bachelor’s degree from the University of Sydney. Xiang Song is a Senior Applied Scientist at AWS AI Research and Education (AIRE), where he develops deep learning frameworks including GraphStorm, DGL, and DGL-KE. He led the development of Amazon Neptune ML, a new capability of Neptune that uses graph neural networks for graphs stored in graph database. He is now leading the development of GraphStorm, an open source graph machine learning framework for enterprise use cases. He received his PhD in computer systems and architecture at the Fudan University, Shanghai, in 2014.
Xiang Song is a Senior Applied Scientist at AWS AI Research and Education (AIRE), where he develops deep learning frameworks including GraphStorm, DGL, and DGL-KE. He led the development of Amazon Neptune ML, a new capability of Neptune that uses graph neural networks for graphs stored in graph database. He is now leading the development of GraphStorm, an open source graph machine learning framework for enterprise use cases. He received his PhD in computer systems and architecture at the Fudan University, Shanghai, in 2014. Florian Saupe is a Principal Technical Product Manager at AWS AI/ML research supporting science teams like the graph machine learning group, and ML Systems teams working on large scale distributed training, inference, and fault resilience. Before joining AWS, Florian lead technical product management for automated driving at Bosch, was a strategy consultant at McKinsey & Company, and worked as a control systems and robotics scientist—a field in which he holds a PhD.
Florian Saupe is a Principal Technical Product Manager at AWS AI/ML research supporting science teams like the graph machine learning group, and ML Systems teams working on large scale distributed training, inference, and fault resilience. Before joining AWS, Florian lead technical product management for automated driving at Bosch, was a strategy consultant at McKinsey & Company, and worked as a control systems and robotics scientist—a field in which he holds a PhD.
 Apply now for an opportunity to receive funding and to participate in the Google.org Accelerator: Generative AI, a $30 million global open call.
Apply now for an opportunity to receive funding and to participate in the Google.org Accelerator: Generative AI, a $30 million global open call.









 Robert Belson is a Developer Advocate in the AWS Worldwide Telecom Business Unit, specializing in AWS edge computing. He focuses on working with the developer community and large enterprise customers to solve their business challenges using automation, hybrid networking, and the edge cloud.
Robert Belson is a Developer Advocate in the AWS Worldwide Telecom Business Unit, specializing in AWS edge computing. He focuses on working with the developer community and large enterprise customers to solve their business challenges using automation, hybrid networking, and the edge cloud. Aditya Lolla is a Sr. Hybrid Edge Specialist Solutions architect at Amazon Web Services. He assists customers across the world with their migration and modernization journey from on-premises environments to the cloud and also build hybrid architectures on AWS Edge infrastructure. Aditya’s areas of interest include private networks, public and private cloud platforms, multi-access edge computing, hybrid and multi cloud strategies and computer vision applications.
Aditya Lolla is a Sr. Hybrid Edge Specialist Solutions architect at Amazon Web Services. He assists customers across the world with their migration and modernization journey from on-premises environments to the cloud and also build hybrid architectures on AWS Edge infrastructure. Aditya’s areas of interest include private networks, public and private cloud platforms, multi-access edge computing, hybrid and multi cloud strategies and computer vision applications.



 Raphael Shu is a Senior Applied Scientist at Amazon Bedrock. He received his PhD from the University of Tokyo in 2020, earning a Dean’s Award. His research primarily focuses on Natural Language Generation, Conversational AI, and AI Agents, with publications in conferences such as ICLR, ACL, EMNLP, and AAAI. His work on the attention mechanism and latent variable models received an Outstanding Paper Award at ACL 2017 and the Best Paper Award for JNLP in 2018 and 2019. At AWS, he led the Dialog2API project, which enables large language models to interact with the external environment through dialogue. In 2023, he has led a team aiming to develop the Agentic capability for Amazon Titan. Since 2024, Raphael worked on multi-agent collaboration with LLM-based agents.
Raphael Shu is a Senior Applied Scientist at Amazon Bedrock. He received his PhD from the University of Tokyo in 2020, earning a Dean’s Award. His research primarily focuses on Natural Language Generation, Conversational AI, and AI Agents, with publications in conferences such as ICLR, ACL, EMNLP, and AAAI. His work on the attention mechanism and latent variable models received an Outstanding Paper Award at ACL 2017 and the Best Paper Award for JNLP in 2018 and 2019. At AWS, he led the Dialog2API project, which enables large language models to interact with the external environment through dialogue. In 2023, he has led a team aiming to develop the Agentic capability for Amazon Titan. Since 2024, Raphael worked on multi-agent collaboration with LLM-based agents. Nilaksh Das is an Applied Scientist at AWS, where he works with the Bedrock Agents team to develop scalable, interactive and modular AI systems. His contributions at AWS have spanned multiple initiatives, including the development of foundational models for semantic speech understanding, integration of function calling capabilities for conversational LLMs and the implementation of communication protocols for multi-agent collaboration. Nilaksh completed his PhD in AI Security at Georgia Tech in 2022, where he was also conferred the Outstanding Dissertation Award.
Nilaksh Das is an Applied Scientist at AWS, where he works with the Bedrock Agents team to develop scalable, interactive and modular AI systems. His contributions at AWS have spanned multiple initiatives, including the development of foundational models for semantic speech understanding, integration of function calling capabilities for conversational LLMs and the implementation of communication protocols for multi-agent collaboration. Nilaksh completed his PhD in AI Security at Georgia Tech in 2022, where he was also conferred the Outstanding Dissertation Award. Michelle Yuan is an Applied Scientist on Amazon Bedrock Agents. Her work focuses on scaling customer needs through Generative and Agentic AI services. She has industry experience, multiple first-author publications in top ML/NLP conferences, and strong foundation in mathematics and algorithms. She obtained her Ph.D. in Computer Science at University of Maryland before joining Amazon in 2022.
Michelle Yuan is an Applied Scientist on Amazon Bedrock Agents. Her work focuses on scaling customer needs through Generative and Agentic AI services. She has industry experience, multiple first-author publications in top ML/NLP conferences, and strong foundation in mathematics and algorithms. She obtained her Ph.D. in Computer Science at University of Maryland before joining Amazon in 2022. Monica Sunkara is a Senior Applied Scientist at AWS, where she works on Amazon Bedrock Agents. With over 10 years of industry experience, including 6.5 years at AWS, Monica has contributed to various AI and ML initiatives such as Alexa Speech Recognition, Amazon Transcribe, and Amazon Lex ASR. Her work spans speech recognition, natural language processing, and large language models. Recently, she worked on adding function calling capabilities to Amazon Titan text models. Monica holds a degree from Cornell University, where she conducted research on object localization under the supervision of Prof. Andrew Gordon Wilson before joining Amazon in 2018.
Monica Sunkara is a Senior Applied Scientist at AWS, where she works on Amazon Bedrock Agents. With over 10 years of industry experience, including 6.5 years at AWS, Monica has contributed to various AI and ML initiatives such as Alexa Speech Recognition, Amazon Transcribe, and Amazon Lex ASR. Her work spans speech recognition, natural language processing, and large language models. Recently, she worked on adding function calling capabilities to Amazon Titan text models. Monica holds a degree from Cornell University, where she conducted research on object localization under the supervision of Prof. Andrew Gordon Wilson before joining Amazon in 2018. Dr. Yi Zhang is a Principal Applied Scientist at AWS, Bedrock. With 25 years of combined industrial and academic research experience, Yi’s research focuses on syntactic and semantic understanding of natural language in dialogues, and their application in the development of conversational and interactive systems with speech and text/chat. He has been technically leading the development of modeling solutions behind AWS services such as Bedrock Agents, AWS Lex, HealthScribe, etc.
Dr. Yi Zhang is a Principal Applied Scientist at AWS, Bedrock. With 25 years of combined industrial and academic research experience, Yi’s research focuses on syntactic and semantic understanding of natural language in dialogues, and their application in the development of conversational and interactive systems with speech and text/chat. He has been technically leading the development of modeling solutions behind AWS services such as Bedrock Agents, AWS Lex, HealthScribe, etc.