
Over the past year, our work on AutoGen has highlighted the transformative potential of agentic AI and multi-agent applications. Today, we are excited to announce AutoGen v0.4, a significant milestone informed by insights from our community of users and developers. This update represents a complete redesign of the AutoGen library, developed to improve code quality, robustness, generality, and scalability in agentic workflows.
The initial release of AutoGen generated widespread interest in agentic technologies. At the same time, users struggled with architectural constraints, an inefficient API compounded by rapid growth, and limited debugging and intervention functionality. Feedback highlighted the need for stronger observability and control, more flexible multi-agent collaboration patterns, and reusable components. AutoGen v0.4 addresses these issues with its asynchronous, event-driven architecture.
This update makes AutoGen more robust and extensible, enabling a broader range of agentic scenarios. The new framework includes the following features, inspired by feedback from both within and outside Microsoft.
- Asynchronous messaging: Agents communicate through asynchronous messages, supporting both event-driven and request/response interaction patterns.
- Modular and extensible: Users can easily customize systems with pluggable components, including custom agents, tools, memory, and models. They can also build proactive and long-running agents using event-driven patterns.
- Observability and debugging: Built-in metric tracking, message tracing, and debugging tools provide monitoring and control over agent interactions and workflows, with support for OpenTelemetry for industry-standard observability.
- Scalable and distributed: Users can design complex, distributed agent networks that operate seamlessly across organizational boundaries.
- Built-in and community extensions: The extensions module enhances the framework’s functionality with advanced model clients, agents, multi-agent teams, and tools for agentic workflows. Community support allows open-source developers to manage their own extensions.
- Cross-language support: This update enables interoperability between agents built in different programming languages, with current support for Python and .NET and additional languages in development.
- Full type support: Interfaces enforce type checks at build time, improving robustness and maintaining code quality.
Microsoft research podcast

Collaborators: Silica in space with Richard Black and Dexter Greene
College freshman Dexter Greene and Microsoft research manager Richard Black discuss how technology that stores data in glass is supporting students as they expand earlier efforts to communicate what it means to be human to extraterrestrials.
New AutoGen framework
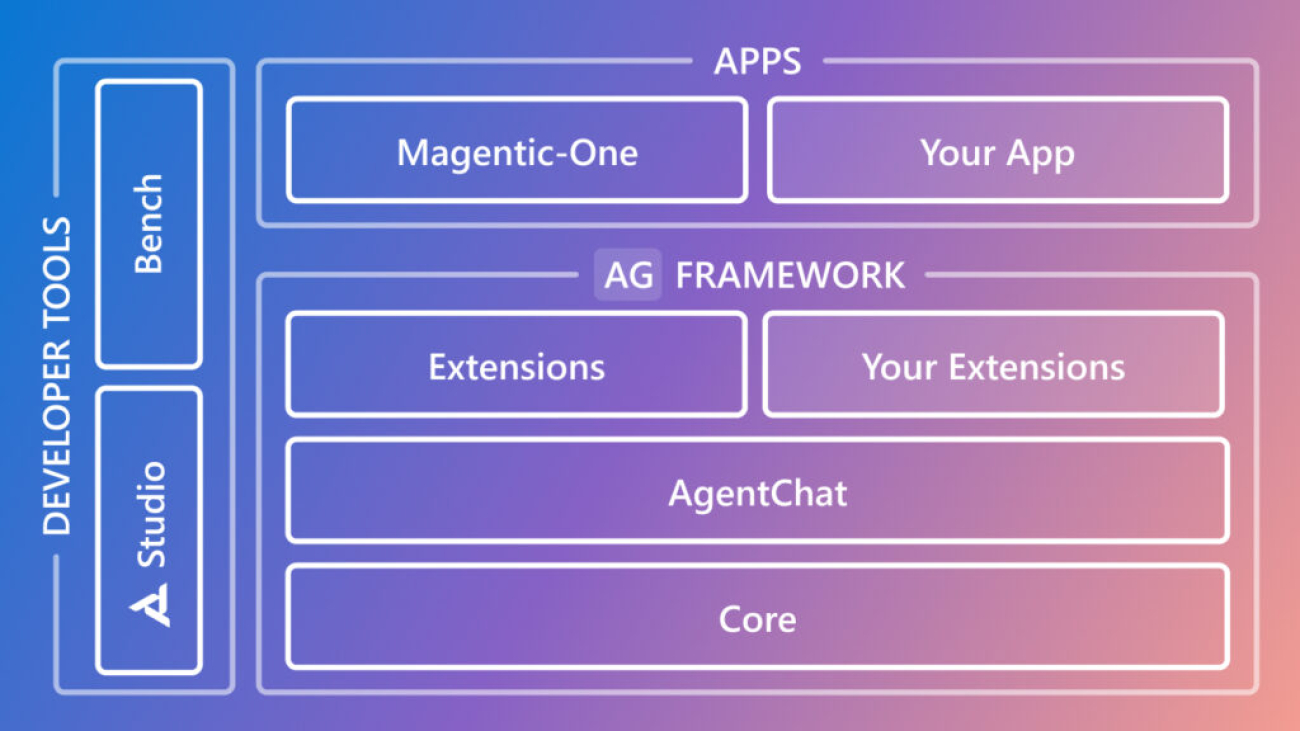
As shown in Figure 1, the AutoGen framework features a layered architecture with clearly defined responsibilities across the framework, developer tools, and applications. The framework comprises three layers: core, agent chat, and first-party extensions.
- Core: The foundational building blocks for an event-driven agentic system.
- AgentChat: A task-driven, high-level API built on the core layer, featuring group chat, code execution, pre-built agents, and more. This layer is most similar to AutoGen v0.2 (opens in new tab), making it the easiest API to migrate to.
- Extensions: Implementations of core interfaces and third-party integrations, such as the Azure code executor and OpenAI model client.

Developer tools
In addition to the framework, AutoGen 0.4 includes upgraded programming tools and applications, designed to support developers in building and experimenting with AutoGen.
AutoGen Bench: Enables developers to benchmark their agents by measuring and comparing performance across tasks and environments.
AutoGen Studio: Rebuilt on the v0.4 AgentChat API, this low-code interface enables rapid prototyping of AI agents. It introduces several new capabilities:
- Real-time agent updates: View agent action streams in real time with asynchronous, event-driven messages.
- Mid-execution control: Pause conversations, redirect agent actions, and adjust team composition. Then seamlessly resume tasks.
- Interactive feedback through the UI: Add a UserProxyAgent to enable user input and guidance during team runs in real time.
- Message flow visualization: Understand agent communication through an intuitive visual interface that maps message paths and dependencies.
- Drag-and-drop team builder: Design agent teams visually using an interface for dragging components into place and configuring their relationships and properties.
- Third-party component galleries: Import and use custom agents, tools, and workflows from external galleries to extend functionality.
Magentic-One: A new generalist multi-agent application to solve open-ended web and file-based tasks across various domains. This tool marks a significant step toward creating agents capable of completing tasks commonly encountered in both work and personal contexts.
Migrating to AutoGen v0.4
We implemented several measures to facilitate a smooth upgrade from the previous v0.2 API, addressing core differences in the underlying architecture.
First, the AgentChat API maintains the same level of abstraction as v0.2, making it easy to migrate existing code to v0.4. For example, AgentChat offers an AssistantAgent and UserProxy agent with similar behaviors to those in v0.2. It also provides a team interface with implementations like RoundRobinGroupChat and SelectorGroupChat, which cover all the capabilities of the GroupChat class in v0.2. Additionally, v0.4 introduces many new functionalities, such as streaming messages, improved observability, saving and restoring task progress, and resuming paused actions where they left off.
For detailed guidance, refer to the migration guide (opens in new tab).
Looking forward
This new release sets the stage for a robust ecosystem and strong foundation to drive advances in agentic AI application and research. Our roadmap includes releasing .NET support, introducing built-in, well-designed applications and extensions for challenging domains, and fostering a community-driven ecosystem. We remain committed to the responsible development of AutoGen and its evolving capabilities.
We encourage you to engage with us on AutoGen’s Discord server (opens in new tab) and share feedback on the official AutoGen repository (opens in new tab) via GitHub Issues. Stay up to date with frequent AutoGen updates via X.
Acknowledgments
We would like to thank the many individuals whose ideas and insights helped formalize the concepts introduced in this release, including Rajan Chari, Ece Kamar, John Langford, Ching-An Chen, Bob West, Paul Minero, Safoora Yousefi, Will Epperson, Grace Proebsting, Enhao Zhang, and Andrew Ng.
The post AutoGen v0.4: Reimagining the foundation of agentic AI for scale, extensibility, and robustness appeared first on Microsoft Research.

 The CMA has announced that it will assess whether Google Search has “Strategic Market Status” (SMS) under the new Digital Markets, Competition and Consumers regime, and …
The CMA has announced that it will assess whether Google Search has “Strategic Market Status” (SMS) under the new Digital Markets, Competition and Consumers regime, and …




 Maram AlSaegh is a Cloud Infrastructure Architect at Amazon Web Services (AWS), where she supports AWS customers in accelerating their journey to cloud. Currently, she is focused on developing innovative solutions that leverage generative AI and machine learning (ML) for public sector entities.
Maram AlSaegh is a Cloud Infrastructure Architect at Amazon Web Services (AWS), where she supports AWS customers in accelerating their journey to cloud. Currently, she is focused on developing innovative solutions that leverage generative AI and machine learning (ML) for public sector entities.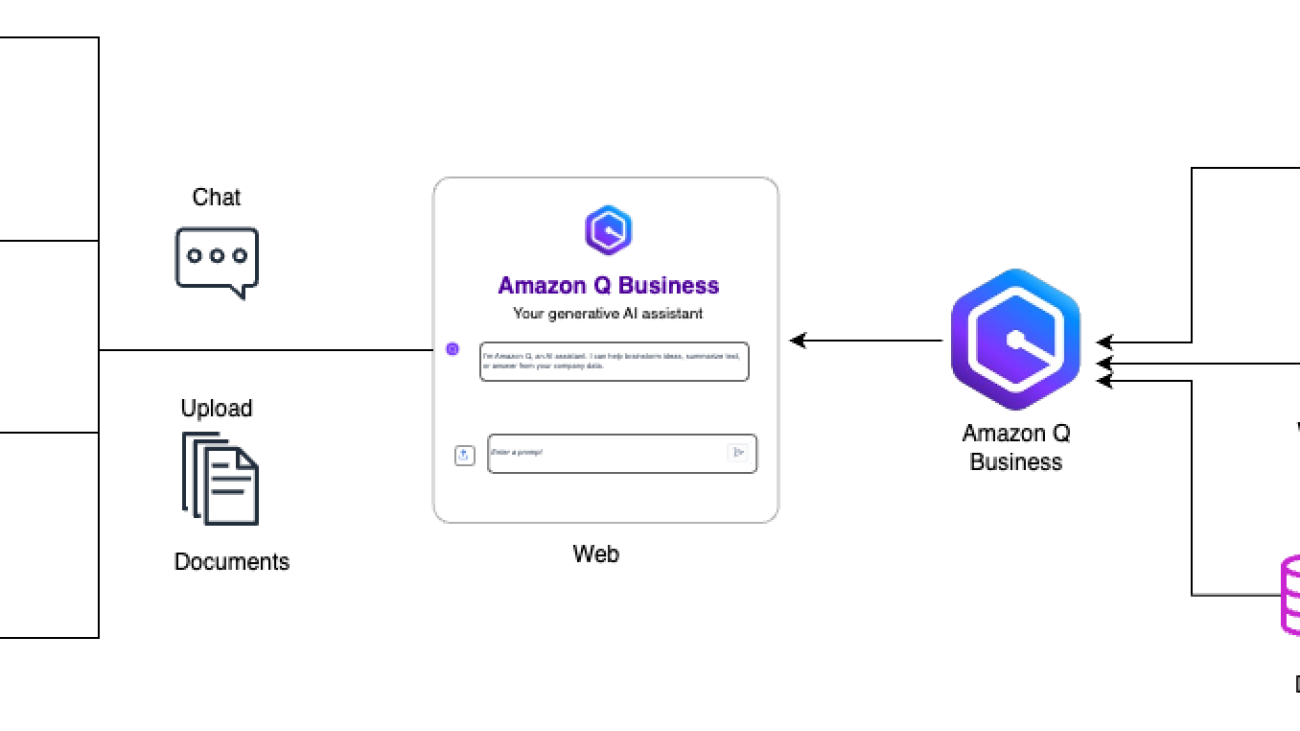

 Rueben Jimenez is an AWS Sr Solutions Architect who designs and implements complex data analytics, machine learning, generative AI, and cloud infrastructure solutions.
Rueben Jimenez is an AWS Sr Solutions Architect who designs and implements complex data analytics, machine learning, generative AI, and cloud infrastructure solutions. Sona Rajamani is a Sr. Manager Solutions Architect at AWS. She lives in the San Francisco Bay Area and helps customers architect and optimize applications on AWS. In her spare time, she enjoys traveling and hiking.
Sona Rajamani is a Sr. Manager Solutions Architect at AWS. She lives in the San Francisco Bay Area and helps customers architect and optimize applications on AWS. In her spare time, she enjoys traveling and hiking. Erick Joaquin is a Sr Customer Solutions Manager for Strategic Accounts at AWS. As a member of the account team, he is focused on evolving his customers’ maturity in the cloud to achieve operational efficiency at scale.
Erick Joaquin is a Sr Customer Solutions Manager for Strategic Accounts at AWS. As a member of the account team, he is focused on evolving his customers’ maturity in the cloud to achieve operational efficiency at scale.

 Today Google Cloud is unveiling Automotive AI Agent, a new way for automakers to create helpful generative AI experiences. Built using Gemini with Vertex AI, Automotive …
Today Google Cloud is unveiling Automotive AI Agent, a new way for automakers to create helpful generative AI experiences. Built using Gemini with Vertex AI, Automotive …