 James Manyika and Kent Walker share three scientific imperatives for the AI era.Read More
James Manyika and Kent Walker share three scientific imperatives for the AI era.Read More

James Manyika and Kent Walker share three scientific imperatives for the AI era.Read More

 The best of Google AI is now included in Workspace with significant nonprofit discounts.Read More
The best of Google AI is now included in Workspace with significant nonprofit discounts.Read More

 Starting this week, Google Photos will begin using SynthID (a technology that embeds an imperceptible, digital watermark directly into AI-generated images, audio, text o…Read More
Starting this week, Google Photos will begin using SynthID (a technology that embeds an imperceptible, digital watermark directly into AI-generated images, audio, text o…Read More
Novel training procedure and decoding mechanism enable model to outperform much larger foundation model prompted to perform the same task.Read More

AI built for speech is now decoding the language of earthquakes.
A team of researchers from the Earth and environmental sciences division at Los Alamos National Laboratory repurposed Meta’s Wav2Vec-2.0, an AI model designed for speech recognition, to analyze seismic signals from Hawaii’s 2018 Kīlauea volcano collapse.
Their findings, published in Nature Communications, suggest that faults emit distinct signals as they shift — patterns that AI can now track in real time. While this doesn’t mean AI can predict earthquakes, the study marks an important step toward understanding how faults behave before a slip event.
“Seismic records are acoustic measurements of waves passing through the solid Earth,” said Christopher Johnson, one of the study’s lead researchers. “From a signal processing perspective, many similar techniques are applied for both audio and seismic waveform analysis.”

Big earthquakes don’t just shake the ground — they upend economies. In the past five years, quakes in Japan, Turkey and California have caused tens of billions of dollars in damage and displaced millions of people.
That’s where AI comes in. Led by Johnson, along with Kun Wang and Paul Johnson, the Los Alamos team tested whether speech-recognition AI could make sense of fault movements — deciphering the tremors like words in a sentence.
To test their approach, the team used data from the dramatic 2018 collapse of Hawaii’s Kīlauea caldera, which triggered a series of earthquakes over three months.
The AI analyzed seismic waveforms and mapped them to real-time ground movement, revealing that faults might “speak” in patterns resembling human speech.
Speech recognition models like Wav2Vec-2.0 are well-suited for this task because they excel at identifying complex, time-series data patterns — whether involving human speech or the Earth’s tremors.
The AI model outperformed traditional methods, such as gradient-boosted trees, which struggle with the unpredictable nature of seismic signals. Gradient-boosted trees build multiple decision trees in sequence, refining predictions by correcting previous errors at each step.
However, these models struggle with highly variable, continuous signals like seismic waveforms. In contrast, deep learning models like Wav2Vec-2.0 excel at identifying underlying patterns.
Unlike previous machine learning models that required manually labeled training data, the researchers used a self-supervised learning approach to train Wav2Vec-2.0. The model was pretrained on continuous seismic waveforms and then fine-tuned using real-world data from Kīlauea’s collapse sequence.
NVIDIA accelerated computing played a crucial role in processing vast amounts of seismic waveform data in parallel. High-performance NVIDIA GPUs accelerated training, enabling the AI to efficiently extract meaningful patterns from continuous seismic signals.
What’s Still Missing: Can AI Predict Earthquakes?
While the AI showed promise in tracking real-time fault shifts, it was less effective at forecasting future displacement. Attempts to train the model for near-future predictions — essentially, asking it to anticipate a slip event before it happens — yielded inconclusive results.
“We need to expand the training data to include continuous data from other seismic networks that contain more variations in naturally occurring and anthropogenic signals,” he explained.
Despite the challenges in forecasting, the results mark an intriguing advancement in earthquake research. This study suggests that AI models designed for speech recognition may be uniquely suited to interpreting the intricate, shifting signals faults generate over time.
“This research, as applied to tectonic fault systems, is still in its infancy,” Johnson. “The study is more analogous to data from laboratory experiments than large earthquake fault zones, which have much longer recurrence intervals. Extending these efforts to real-world forecasting will require further model development with physics-based constraints.”
So, no, speech-based AI models aren’t predicting earthquakes yet. But this research suggests they could one day — if scientists can teach it to listen more carefully.
Read the full paper, “Automatic Speech Recognition Predicts Contemporaneous Earthquake Fault Displacement,” to dive deeper into the science behind this groundbreaking research.
GeForce NOW celebrates its fifth anniversary this February with a lineup of five major releases. The month kicks off with Kingdom Come: Deliverance II. Prepare for a journey back in time — Warhorse Studios’ newest medieval role-playing game (RPG) comes to GeForce NOW on its launch day, bringing 15th-century Bohemia to devices everywhere.
Experience the highly anticipated sequel’s stunning open world at GeForce RTX quality in the cloud, available to stream across devices at launch. It leads seven games joining the GeForce NOW library of over 2,000 titles, along with MARVEL vs. CAPCOM Fighting Collection: Arcade Classics.

Kingdom Come: Deliverance II continues the epic, open-world RPG saga set in the brutal and realistic medieval world of Bohemia. Continue the story of Henry, a blacksmith’s son turned warrior, as he navigates political intrigue and warfare. Explore a world twice the size of the original, whether in the bustling streets of Kuttenberg or the picturesque Bohemian Paradise.
The game builds on its predecessor’s realistic combat system by introducing crossbows, early firearms and a host of new weapons, while refining its already sophisticated melee combat mechanics. Navigate a complex narrative full of difficult decisions, forge alliances with powerful figures, engage in tactical large-scale battles and face moral dilemmas that impact both the journey and fate of the kingdom — all while experiencing a historically rich environment faithful to the period.
The game also features enhanced graphics powered by GeForce RTX, making it ideal to stream on GeForce NOW even without a game-ready rig. Experience all the medieval action at up to 4K and 120 frames per second with eight-hour sessions using an Ultimate membership, or 1440p and 120 fps with six-hour sessions using a Performance membership. Enjoy seamless gameplay, stunning visuals and smooth performance throughout the vast, immersive world of Bohemia.

Experience every aspect of a paramedic’s life in Ambulance Life: A Paramedic Simulator from Nacon Games. Quickly reach the accident site, take care of the injured and apply first aid. Each accident is different. It’s up to players to adapt and make the right choices while being fast and efficient. Explore three different Districts containing a variety of environments. At each accident site, analyze the situation to precisely determine the right treatment for each patient. Build a reputation, unlock new tools and get assigned to new districts with thrilling new situations.
Look for the following games available to stream in the cloud this week:
What are you planning to play this weekend? Let us know on X or in the comments below.
Ultimate medieval game weapon – go!
—
NVIDIA GeForce NOW (@NVIDIAGFN) February 5, 2025
 Here are Google’s latest AI updates from January.Read More
Here are Google’s latest AI updates from January.Read More
This post is co-written with Martin Holste from Trellix.
Security teams are dealing with an evolving universe of cybersecurity threats. These threats are expanding in form factor, sophistication, and the attack surface they target. Constrained by talent and budget limitations, teams are often forced to prioritize the events pursued for investigation, limiting the ability to detect and identify new threats. Trellix Wise is an AI-powered technology enabling security teams to automate threat investigation and add risk scores to events. With Trellix Wise, security teams can now complete what used to take multiple analysts hours of work to investigate in seconds, enabling them to expand the security events they are able to cover.
Trellix, a leading company delivering cybersecurity’s broadest AI-powered platform to over 53,000 customers worldwide, emerged in 2022 from the merger of McAfee Enterprise and FireEye. The company’s comprehensive, open, and native AI-powered security platform helps organizations build operational resilience against advanced threats. Trellix Wise is available to customers as part of the Trellix Security Platform. This post discusses the adoption and evaluation of Amazon Nova foundation models (FMs) by Trellix.
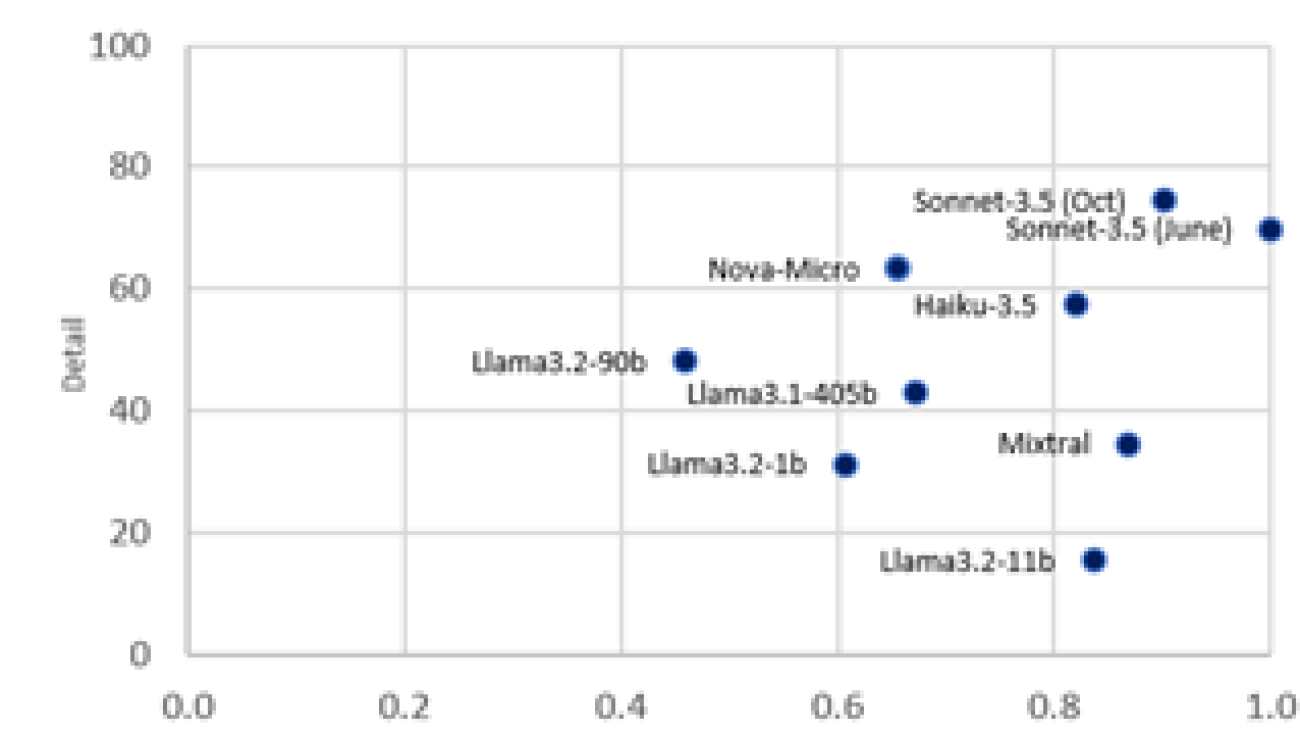
With growing adoption and use, the Trellix team has been exploring ways to optimize the cost structure of Trellix Wise investigations. Smaller, cost-effective FMs seemed promising and Amazon Nova Micro stood out as an option because of its quality and cost. In early evaluations, the Trellix team observed that Amazon Nova Micro delivered inferences three times faster and at nearly 100-fold lower cost.
The following figures are the results of tests by Trellix comparing Amazon Nova Micro to other models on Amazon Bedrock.


The Trellix team identified areas where Amazon Nova Micro can complement their use of Anthropic’s Claude Sonnet, delivering lower costs and higher overall speeds. Additionally, the professional services team at Trellix found Amazon Nova Lite to be a strong model for code generation and code understanding and is now using Amazon Nova Lite to speed up their custom solution delivery workflows.
Trellix Wise is built on Amazon Bedrock and uses Anthropic’s Claude Sonnet as its primary model. The platform uses the Amazon OpenSearch Service stores billions of security events collected from the environments monitored. OpenSearch Service comes with a built-in vector database capability, making it straightforward to use data stored in OpenSearch Service as context data in a Retrieval Augmented Generation (RAG) architecture with Amazon Bedrock Knowledge Bases. Using OpenSearch Service and Amazon Bedrock, Trellix Wise carries out its automated, proprietary threat investigation steps on each event. This includes retrieval of required data for analysis, analysis of the data using insights from other custom-built machine learning (ML) models, and risk scoring. This sophisticated approach enables the service to interpret complex security data patterns and make intelligent decisions about each event. The Trellix Wise investigation gives each event a risk score and allows analysts to dive deeper into the results of the analysis, to determine whether human follow-up is necessary.
The following screenshot shows an example of an event on the Trellix Wise dashboard.

With growing scale of adoption, Trellix has been evaluating ways to improve cost and speed. The Trellix team has determined not all stages in the investigation need the accuracy of Claude Sonnet, and that some stages can benefit from faster, lower cost models that nevertheless are highly accurate for the target task. This is where Amazon Nova Micro has helped improve the cost structure of investigations.
The threat investigation workflow consists of multiple steps, from data collection, to analysis, to assigning of a risk score for the event. The collections stage retrieves event-related information for analysis. This is implemented through one or more inference calls to a model in Amazon Bedrock. The priority in this stage is to maximize completeness of the retrieval data and minimize inaccuracy (hallucinations). The Trellix team identified this stage as the optimal stage in the workflow to optimize for speed and cost.
The Trellix team concluded, based on their testing, Amazon Nova Micro offered two key advantages. Its speed allows it to process 3-5 inferences in the same time as a single Claude Sonnet inference and it’s cost per inference is almost 100 times lower. The Trellix team determined that by running multiple inferences, you can maximize the coverage of required data and still lower costs by a factor of 30. Although the model responses had a higher variability than the larger models, running multiple passes enables getting to a more exhaustive response-set. The response limitations enforced through proprietary prompt engineering and reference data constrain the response space, limiting hallucinations and inaccuracies in the response.
Before implementing the approach, the Trellix team carried out detailed testing to review the response completeness, cost, and speed. The team realized early in their generative AI journey that standardized benchmarks are not sufficient when evaluating models for a specific use case. A test harness replicating the information gathering workflows was set up and detailed evaluations of multiple models were carried out, to validate the benefits of this approach before moving ahead. The speed and cost benefits observed by Trellix helped validate the benefits before moving the new approach into production. The approach is now deployed in a limited pilot environment. Detailed evaluations are being carried out as part of a phased roll-out into production.
In this post, we shared how Trellix adopted and evaluated Amazon Nova models, resulting in significant inference speedup and lower costs. Reflecting on the project, the Trellix team recognizes the following as key enablers allowing them to achieve these results:
“Amazon Bedrock makes it easy to evaluate new models and approaches as they become available. Using Amazon Nova Micro alongside Anthropic’s Claude Sonnet allows us to deliver the best coverage to our customers, fast, and at the best operating cost.“ says Martin Holste, Senior Director, Engineering, Trellix. “We’re really happy with the flexibility that Amazon Bedrock allows us as we continue to evaluate and improve Trellix Wise and the Trellix Security Platform.”
Get started with Amazon Nova on the Amazon Bedrock console. Learn more at the Amazon Nova product page.
Martin Holste is the CTO for Cloud and GenAI at Trellix.
Firat Elbey is a Principal Product Manager at Amazon AGI.
Deepak Mohan is a Principal Product Marketing Manager at AWS.

This post is co-written with Andrés Vélez Echeveri and Sean Azlin from OfferUp.

OfferUp is an online, mobile-first marketplace designed to facilitate local transactions and discovery. Known for its user-friendly app and trust-building features, including user ratings and in-app chat, OfferUp enables users to buy and sell items and explore a broad range of jobs and local services. As part of its ongoing mission to enhance user experience and drive business growth, OfferUp constantly seeks to improve its search capabilities, making it faster and more intuitive for users to discover, transact, and connect in their local communities.
In this two-part blog post series, we explore the key opportunities OfferUp embraced on their journey to boost and transform their existing search solution from traditional lexical search to modern multimodal search powered by Amazon Bedrock and Amazon OpenSearch Service. OfferUp found that multimodal search improved relevance recall by 27%, reduced geographic spread (which means more local results) by 54%, and grew search depth by 6.5%. This series delves into strategies, architecture patterns, business benefits and technical steps to modernize your own search solution
OfferUp hosts millions of active listings, with millions more added monthly by its users. Previously, OfferUp’s search engine was built with Elasticsearch (v7.10) on Amazon Elastic Compute Cloud (Amazon EC2), using a keyword search algorithm to find relevant listings. The following diagram illustrates the data pipeline for indexing and query in the foundational search architecture.

The data indexing workflow consists of the following steps:
This flow makes sure that new or updated listings are indexed and made available for search queries in Elasticsearch.
The data query workflow consists of the following steps:
OfferUp continuously strives to enhance user experience, focusing specifically on improving search relevance, which directly impacts Engagement with Seller Response (EWSR) and drives ad impressions. Although the foundational search architecture effectively surfaces a broad and diverse inventory, OfferUp encountered several limitations that prevent it from achieving optimal outcomes. These challenges include:
Keyword search, which uses BM25 as a ranking algorithm, lacks the ability to understand semantic relationships between words, often missing semantically relevant results if they don’t contain exact keywords.
To improve search quality, OfferUp explored various software and hardware solutions focused on boosting search relevance while maintaining cost-efficiency. Ultimately, OfferUp selected Amazon Titan Multimodal Embeddings and Amazon OpenSearch Service for their fully managed services, which support a robust multimodal search solution capable of delivering high accuracy and fast responses across search and recommendation use cases. This choice also simplifies the deployment and operation of large-scale search capabilities on the OfferUp app, meeting the high throughput and latency requirements.
This model is pre-trained on large datasets, so you can use it as-is or customize this model by fine-tuning with your own data for a particular task. This model is used for use cases like searching images by text, by image, or by a combination of text and image for similarity and personalization. It translates the input image or text into an embedding that contains the semantic meaning of both the image and text in the same semantic space. By comparing embeddings, the model produces more relevant and contextual responses than keyword matching alone.
The Amazon Titan Multimodal Embeddings G1 offers the following configurations:
Vector databases enable the storage and indexing of vectors alongside metadata, facilitating low-latency queries to discover assets based on similarity. These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems. Beyond basic k-NN functionality, vector databases offer a robust foundation for applications that require data management, fault tolerance, resource access controls, and an efficient query engine.
OpenSearch is a powerful, open-source suite that provides scalable and flexible tools for search, analytics, security monitoring, and observability—all under the Apache 2.0 license. With Amazon OpenSearch Service, you get a fully managed solution that makes it simple to deploy, scale, and operate OpenSearch in the AWS Cloud. By using Amazon OpenSearch Service as a vector database, you can combine traditional search, analytics, and vector search into one comprehensive solution. OpenSearch’s vector capabilities help accelerate AI application development, making it easier for teams to operationalize, manage, and integrate AI-driven assets.
To further boost these capabilities, OpenSearch offers advanced features, such as:
The following diagram below illustrates the data pipeline for indexing and query in the transformed multimodal search architecture:
![]()
The data indexing workflow consists of the following steps:
The data query workflow consists of the following steps:
After extensive A/B testing with various k values, OfferUp found that a k value of 128 delivers the best search results while optimizing compute resources.
OfferUp adopted a three-step process to implement multimodal search functionality into their foundational search architecture.
In this section, we discuss the benefits of multimodal search
OfferUp evaluated the impact of multimodal search through A/B testing to manage traffic control and user experiment variations. In this experiment, the control group used the existing keyword-based search, and the variant group experienced the new multimodal search functionality. The test included a substantial user base, allowing for a robust comparison.
OfferUp conducted additional experiments to assess technical metrics, utilizing 6 months of production system data to examine relevance recall with a focus on the top k=10 most relevant results within high-density and low-density DMAs. By segmenting these locations, OfferUp gained insights into how variations in user distribution across different market densities affect system performance, allowing for a deeper understanding of relevance recall efficiency in diverse markets.
relevance recall (RR)= sum(listing relevance score) / number of retrieved listingsListing relevance is labeled as (1, 0) and is based on query correlations with the listing retrieved.

In this post, we demonstrated how OfferUp transformed its foundational search architecture using Amazon Titan Multimodal Embeddings and OpenSearch Service, significantly increasing user engagement, improving search quality and offering users the ability to search with both text and images. OfferUp selected Amazon Titan Multimodal Embeddings and Amazon OpenSearch Service for their fully managed capabilities, enabling the development of a robust multimodal search solution with high accuracy and a faster time to market for search and recommendation use cases.
We are excited to share these insights with the broader community and support organizations embarking on their own multimodal search journeys or seeking to improve search precision. Based on our experience, we highly recommend using Amazon Bedrock and Amazon OpenSearch services to achieve similar outcomes.
In the next part of the series, we discuss how to build multimodal search solution with an Amazon SageMaker Jupyter notebook, Amazon Titan Multimodal Embeddings model and OpenSearch Service.
 Purna Sanyal is GenAI Specialist Solution Architect at AWS, helping customers to solve their business problems with successful adoption of cloud native architecture and digital transformation. He has specialization in data strategy, machine learning and Generative AI. He is passionate about building large-scale ML systems that can serve global users with optimal performance.
Purna Sanyal is GenAI Specialist Solution Architect at AWS, helping customers to solve their business problems with successful adoption of cloud native architecture and digital transformation. He has specialization in data strategy, machine learning and Generative AI. He is passionate about building large-scale ML systems that can serve global users with optimal performance.
 Andrés Vélez Echeveri is a Staff Data Scientist and Machine Learning Engineer at OfferUp, focused on enhancing the search experience by optimizing retrieval and ranking components within a recommendation system. He has a specialization in machine learning and generative AI. He is passionate about creating scalable AI systems that drive innovation and user impact.
Andrés Vélez Echeveri is a Staff Data Scientist and Machine Learning Engineer at OfferUp, focused on enhancing the search experience by optimizing retrieval and ranking components within a recommendation system. He has a specialization in machine learning and generative AI. He is passionate about creating scalable AI systems that drive innovation and user impact.
 Sean Azlin is a Principal Software Development Engineer at OfferUp, focused on leveraging technology to accelerate innovation, decrease time-to-market, and empower others to succeed and thrive. He is highly experienced in building cloud-native distributed systems at any scale. He is particularly passionate about GenAI and its many potential applications.
Sean Azlin is a Principal Software Development Engineer at OfferUp, focused on leveraging technology to accelerate innovation, decrease time-to-market, and empower others to succeed and thrive. He is highly experienced in building cloud-native distributed systems at any scale. He is particularly passionate about GenAI and its many potential applications.
As large language models (LLMs) become increasingly integrated into customer-facing applications, organizations are exploring ways to leverage their natural language processing capabilities. Many businesses are investigating how AI can enhance customer engagement and service delivery, and facing challenges in making sure LLMs driven engagements are on topic and follow the desired instructions.
In this blog post, we explore a real-world scenario where a fictional retail store, AnyCompany Pet Supplies, leverages LLMs to enhance their customer experience. Specifically, this post will cover:
Through this practical example, we’ll illustrate how startups can harness the power of LLMs to enhance customer experiences and the simplicity of Nemo Guardrails to guide the LLMs driven conversation toward the desired outcomes.
Note: For any considerations of adopting this architecture in a production setting, it is imperative to consult with your company specific security policies and requirements. Each production environment demands a uniquely tailored security architecture that comprehensively addresses its particular risks and regulatory standards. Some links for security best practices are shared below but we strongly recommend reaching out to your account team for detailed guidance and to discuss the appropriate security architecture needed for a secure and compliant deployment.
First, let’s try to understand what guardrails are and why we need them. Guardrails (or “rails” for short) in LLM applications function much like the rails on a hiking trail — they guide you through the terrain, keeping you on the intended path. These mechanisms help ensure that the LLM’s responses stay within the desired boundaries and produces answers from a set of pre-approved statements.
NeMo Guardrails, developed by NVIDIA, is an open-source solution for building conversational AI products. It allows developers to define and constrain the topics the AI agent will engage with, the possible responses it can provide, and how the agent interacts with various tools at its disposal.
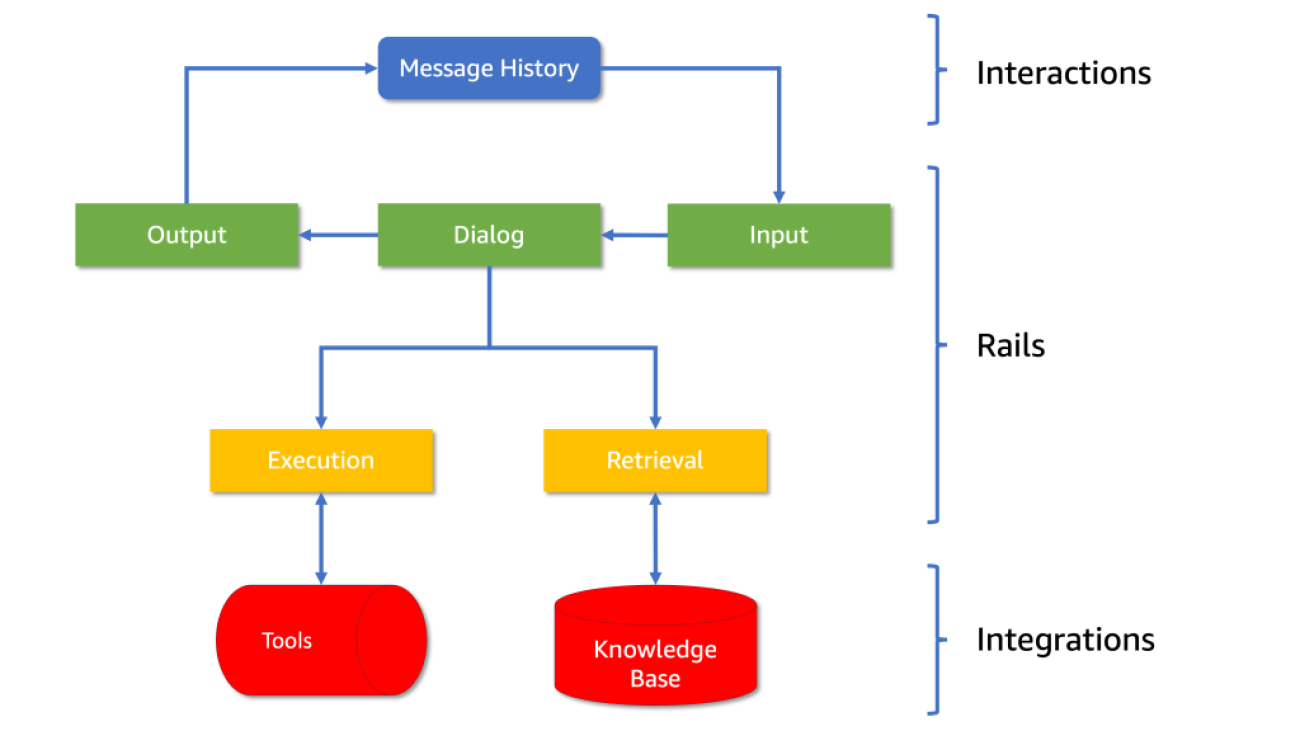
The architecture consists of five processing steps, each with its own set of controls, referred to as “rails” in the framework. Each rail defines the allowed outcomes (see Diagram 1):
For a retail chatbot like AnyCompany Pet Supplies’ AI assistant, guardrails help make sure that the AI collects the information needed to serve the customer, provides accurate product information, maintains a consistent brand voice, and integrates with the surrounding services supporting to perform actions on behalf of the user.
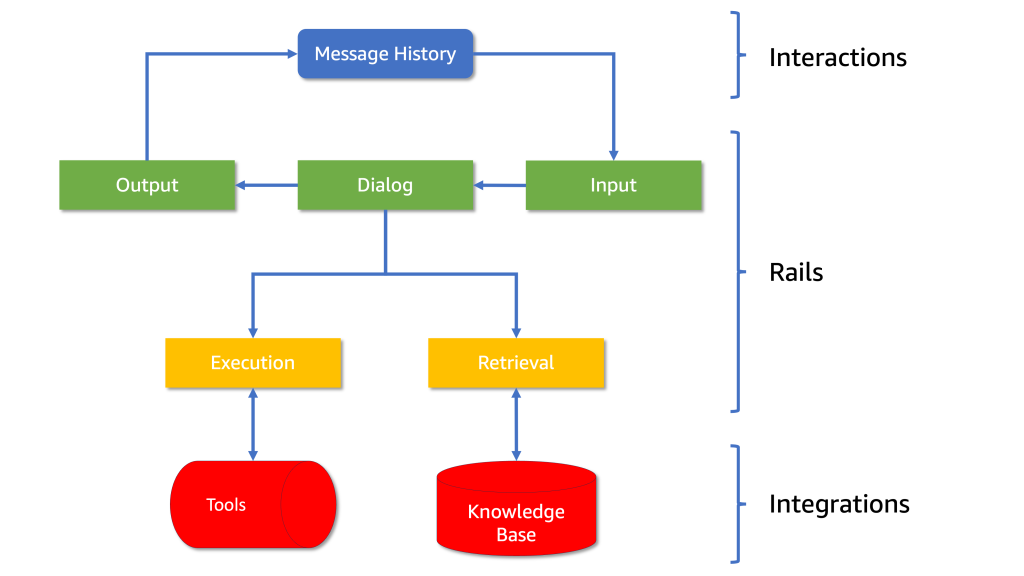
Diagram 1: The architecture of NeMo Guardrails, showing how interactions, rails and integrations are structured.
Within each rail, NeMo can understand user intent, invoke integrations when necessary, select the most appropriate response based on the intent and conversation history and generate a constrained message as a reply (see Diagram 2).
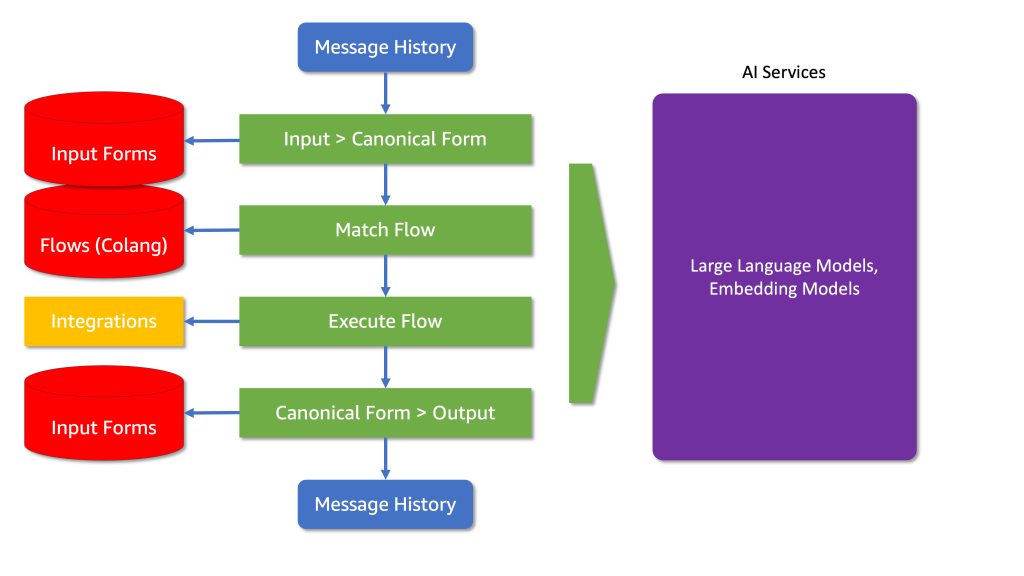
Diagram 2: The flow from input forms to the final output, including how integrations and AI services are utilized.
Creating a conversational AI that’s smart, engaging and operates with your use case goals in mind can be challenging. This is where NeMo Guardrails comes in. NeMo Guardrails is a toolset designed to create robust conversational agents, utilizing Colang — a modelling language specifically tailored for defining dialogue flows and guardrails. Let’s delve into how NeMo Guardrails own language can enhance your AI’s performance and provide a guided and seamless user experience.
Colang is purpose-built for simplicity and flexibility, featuring fewer constructs than typical programming languages, yet offering remarkable versatility. It leverages natural language constructs to describe dialogue interactions, making it intuitive for developers and simple to maintain.
Let’s delve into a basic Colang script to see how it works:
In this script, we see the three fundamental types of blocks in Colang:
In the example above, we defined a simple dialogue flow where a user expresses gratitude, and the bot responds with a welcoming message. This straightforward approach allows developers to construct intricate conversational pathways that uses the examples given to route the conversation toward the desired responses.
For this post, we’ll use Llama 3.1 8B instruct model from Meta, a recent model that strikes excellent balance between size, inference cost and conversational capabilities. We will launch it via Amazon SageMaker JumpStart, which provides access to numerous foundation models from providers such as Meta, Cohere, Hugging Face, Anthropic and more.
By leveraging SageMaker JumpStart, you can quickly evaluate and select suitable foundation models based on quality, alignment and reasoning metrics. The selected models can then be further fine-tuned on your data to better match your specific use case needs. On top of ample model choice, the additional benefit is that it enables your data to remain within your Amazon VPC during both inference and fine-tuning.
When integrating models from SageMaker JumpStart with NeMo Guardrails, the direct interaction with the SageMaker inference API requires some customization, which we will explore below.
Creating an Adapter for NeMo Guardrails
To verify compatibility, we need to create an adapter to make sure that requests and responses match the format expected by NeMo Guardrails. Although NeMo Guardrails provides a SagemakerEndpoint wrapper class, it requires some customization to handle the Llama 3.1 model API exposed by SageMaker JumpStart properly.
Below, you will find an implementation of a NeMo-compatible class that arranges the parameters required to call our SageMaker endpoint:
The Llama 3.1 model from Meta requires prompts to follow a specific structure, including special tokens like </s> and {role} to define parts of the conversation. When invoking the model through NeMo Guardrails, you must make sure that the prompts are formatted correctly.
To achieve seamless integration, you can modify the prompt.yaml file. Here’s an example:
For more details on formatting input text for Llama models, you can explore these resources:
In our task to create an intelligent and responsible AI assistant for AnyCompany Pet Supplies, we’re leveraging NeMo Guardrails to build a conversational AI chatbot that can understand customer needs, provide product recommendations, and guide users through the purchase process. Here’s how we implement this.
At the heart of NeMo Guardrails are two key concepts: flows and intents. These work together to create a structured, responsive, and context-aware conversational AI.
Flows define the conversation structure and guide the AI’s responses. They are sequences of actions that the AI should follow in specific scenarios. For example:
These flows outline how the AI should respond in different situations. When a user asks about pets, the chatbot will provide an answer. When faced with an unrelated question, it will politely refuse to answer.
The process of choosing which flow to follow begins with capturing the user intent. NeMo Guardrails uses a multi-faceted approach to understand user intent:
prompts.yml file to narrow down the intent:
This prompt is designed to guide the chatbot in determining the user’s intent. Let’s break it down:
{{ general_instructions }} variable contains overall guidelines for the chatbot’s behavior, as defined in our config.yml.{{ sample_conversation }} provides a model of how interactions should flow, giving the chatbot context for understanding user intents.{{ history | user_assistant_sequence }} variable includes the actual conversation history, allowing the chatbot to consider the context of the current interaction.{{ potential_user_intents }}. This constrains the chatbot to a set of known intents, ensuring consistency and predictability in intent recognition.{{ potential_user_intents }}“. This provides a clear, unambiguous intent selection.In Practice:
Here’s how this process works in practice (see Diagram 3):
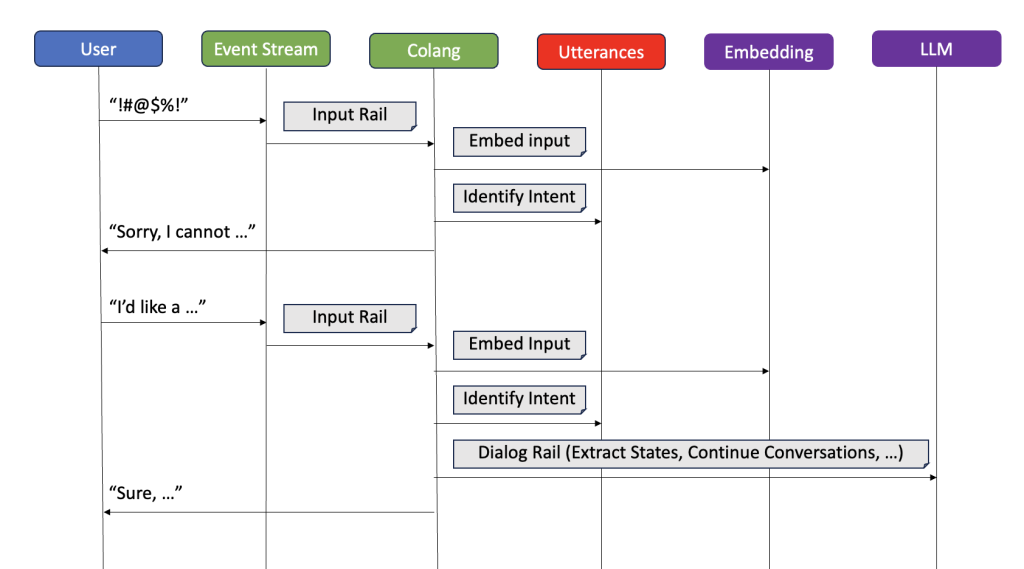
Diagram 3: Two example conversation flows, one denied by the input rails, one allowed to the dialog rail where the LLM picks up the conversation.
For example, if a user asks, “What’s the best food for a kitten?”, the chatbot might classify this as a “product_inquiry” intent. This intent would then activate a flow designed to recommend pet food products.
While this structured approach to intent recognition makes sure that the chatbot’s responses are focused and relevant to the user’s needs, it may introduce latency due to the need to process and analyze conversation history and intent in real-time. Each step, from intent recognition to flow selection, involves computational processing, which can impact the response time, especially in more complex interactions. Finding the right balance between flexibility, control, and real-time processing is crucial for creating an effective and reliable conversational AI system.
In our earlier discussion about Colang, we examined its core structure and its role in crafting conversational flows. Now, we will delve into one of Colang’s standout features: the ability to utilize variables to capture and process user input. This functionality enables us to construct conversational agents that are not only more dynamic but also highly responsive, tailoring their interactions based on precise user data.
Continuing with our practical example of developing a pet store assistant chatbot:
In the provided example above, we encounter the line:
$pet_type = ...
The ellipsis (...) serves as a placeholder in Colang, signaling where data extraction or inference is to be performed. This notation does not represent executable code but rather suggests that some form of logic or natural language processing should be applied at this stage.
More specifically, the use of an ellipsis here implies that the system is expected to:
The comment accompanying this line sheds more light on the intended data extraction process:
#extract the specific pet type at very high level if available, like dog, cat, bird. Make sure you still class things like puppy as "dog", kitty as "cat", etc. if available or "not available" if none apply
This directive indicates that the extraction should:
Returning to our initial code snippet, we use the $pet_type variable to customize responses, enabling the bot to offer specific advice based on whether the user has a dog, bird, or cat.
Next, we will expand on this example to integrate a Retrieval Augmented Generation (RAG) workflow, enhancing our assistant’s capabilities to recommend specific products tailored to the user’s inputs.
Incorporating advanced AI capabilities using a model like the Llama 3.1 8B instruct model requires more than just managing the tone and flow of conversations; it necessitates controlling the data the model accesses to respond to user queries. A common technique to achieve this is Retrieval Augmented Generation (RAG). This method involves searching a semantic database for content relevant to a user’s request and incorporating those findings into the model’s response context.
The typical approach uses an embedding model, which converts a sentence into a semantic numeric representation—referred to as a vector. These vectors are then stored in a vector database designed to efficiently search and retrieve closely related semantic information. For more information on this topic, please refer to Getting started with Amazon Titan Text Embeddings in Amazon Bedrock.
NeMo Guardrails simplifies this process: developers can store relevant content in a designated ‘kb’ folder. NeMo automatically reads this data, applies its internal embedding model and stores the vectors in an “Annoy” index, which functions as an in-memory vector database. However, this method might not scale well for extensive data sets typical in e-commerce environments. To address scalability, here are two solutions:
EmbeddingsIndex base class. This allows you to customize storage, search and data embedding processes according to your specific requirements, whether local or remote. This integration makes sure that that relevant information remains in the conversational context throughout the user interaction, though it does not allow for precise control over when or how the information is used. For example:
In the conversation rail’s flow, use variables and function calls to precisely manage searches and the integration of results:
These methods offer different levels of flexibility and control, making them suitable for various applications depending on the complexity of your system. In the next section, we will see how these techniques are applied in a more complex scenario to further enhance the capabilities of our AI assistant.
Let’s explore a complex implementation scenario with NeMo Guardrails interacting with multiple tools to drive specific business outcomes. We’ll keep the focus on the pet store e-commerce site that is being upgraded with a conversational sales agent. This agent is integrated directly into the search field at the top of the page. For instance, when a user searches for “double coat shampoo,” the results page displays several products and a chat window automatically engages the user by processing the search terms.
As the user interaction begins, the AI processes the input from the search field:
Output: "Would you be able to share the type of your dog breed?"
This initiates the engine’s recognition of the user’s intent to inquire about pet products. Here, the chatbot uses variables to try and extract the type and breed of the pet. If the breed isn’t immediately available from the input, the bot requests further clarification.
If the user responds with the breed (e.g., “It’s a Labradoodle”), the chatbot proceeds to tailor its search for relevant products:
Output: We found several shampoos for Labradoodles: [Product List]. Would you like to add any of these to your cart?
The chatbot uses the extracted variables to refine product search criteria, then retrieves relevant items using an embedded retrieval function. It formats this information into a user-friendly message, listing available products and offering further actions.
If the user expresses a desire to purchase a product (“I’d like to buy the second option from the list”), the chatbot transitions to processing the order:
Output: "Great choice! To finalize your order, could you please provide your full shipping address?"
At this point, we wouldn’t have the shipping information so the bot ask for it. However, if this was a known customer, the data could be injected into the conversation from other sources. For example, if the user is authenticated and has made previous orders, their shipping address can be retrieved from the user profile database and automatically populated within the conversation flow. Then the model would just have asked for confirmation about the purchase, skipping the part about asking for shipping information.
Once our variables are filled and we have enough information to process the order, we can transition the conversation naturally into a sales motion and have the bot finalize the order:
Output: "Success"
In this example, we’ve implemented a mock function called add_order to simulate a backend service call. This function verifies the address and places the chosen product into the user’s session cart. You can capture the return string from this function on the client side and take further action, for instance, if it indicates ‘Success,’ you can then run some JavaScript to display the filled cart to the user. This will show the cart with the item, pre-entered shipping details and a ready checkout button within the user interface, closing the sales loop experience for the user and tying together the conversational interface with the shopping cart and purchasing flow.
During this interaction, the NeMo Guardrails framework maintains the conversation within the boundaries set by the Colang configuration. For example, if the user deviates with a question such as ‘What’s the weather like today?’, NeMo Guardrails will classify this as part of a refusal flow and outside the relevant topics of ordering pet supplies. It will then tactfully declines to address the unrelated query and steers the discussion back towards selecting and ordering products, replying with a standard response like, ‘I’m afraid I can’t help with weather information, but let’s continue with your pet supplies order.’ as defined in Colang.
When using Amazon SageMaker JumpStart you’re deploying the selected models using on-demand GPU instances managed by Amazon SageMaker. These instances are billed per second and it’s important to optimize your costs by turning off the endpoint when not needed.
To clean up your resources, please ensure that you run the clean up cells in the three notebooks that you used. Make sure you delete the appropriate model and endpoints by executing similar cells:
Please note that in the third notebook, you additionally need to delete the embedding endpoints:
Additionally, you can make sure that you have deleted the appropriate resources manually by completing the following steps:
llm-model and embedding-model artifacts.llm-model and embedding-model endpoint configuration.llm-model and embedding-model endpoints running.When integrating NeMo Guardrails with SageMaker JumpStart, it’s important to consider AI governance frameworks and security best practices to ensure responsible AI deployment. While this blog focuses on showcasing the core functionality and capabilities of NeMo Guardrails, security aspects are beyond its scope.
For further guidance, please explore:
Integrating NeMo Guardrails with Large Language Models (LLMs) is a powerful step forward in deploying AI in customer-facing applications. The example of AnyCompany Pet Supplies illustrates how these technologies can enhance customer interactions while handling refusal and guiding the conversation toward the implemented outcomes. Looking forward, maintaining this balance of innovation and responsibility will be key to realizing the full potential of AI in various industries. This journey towards ethical AI deployment is crucial for building sustainable, trust-based relationships with customers and shaping a future where technology aligns seamlessly with human values.
You can find the examples used within this article via this link.
We encourage you to explore and implement NeMo Guardrails to enhance your own conversational AI solutions. By leveraging the guardrails and techniques demonstrated in this post, you can quickly constraint LLMs to drive tailored and effective results for your use case.
 Georgi Botsihhin is a Startup Solutions Architect at Amazon Web Services (AWS), based in the United Kingdom. He helps customers design and optimize applications on AWS, with a strong interest in AI/ML technology. Georgi is part of the Machine Learning Technical Field Community (TFC) at AWS. In his free time, he enjoys staying active through sports and taking long walks with his dog.
Georgi Botsihhin is a Startup Solutions Architect at Amazon Web Services (AWS), based in the United Kingdom. He helps customers design and optimize applications on AWS, with a strong interest in AI/ML technology. Georgi is part of the Machine Learning Technical Field Community (TFC) at AWS. In his free time, he enjoys staying active through sports and taking long walks with his dog.
 Lorenzo Boccaccia is a Startup Solutions Architect at Amazon Web Services (AWS), based in Spain. He helps startups in creating cost-effective, scalable solutions for their workloads running on AWS, with a focus on containers and EKS. Lorenzo is passionate about Generative AI and is is a certified AWS Solutions Architect Professional, Machine Learning Specialist and part of the Containers TFC. In his free time, he can be found online taking part sim racing leagues.
Lorenzo Boccaccia is a Startup Solutions Architect at Amazon Web Services (AWS), based in Spain. He helps startups in creating cost-effective, scalable solutions for their workloads running on AWS, with a focus on containers and EKS. Lorenzo is passionate about Generative AI and is is a certified AWS Solutions Architect Professional, Machine Learning Specialist and part of the Containers TFC. In his free time, he can be found online taking part sim racing leagues.

