Large language models (LLMs) excel at generating human-like text but face a critical challenge: hallucination—producing responses that sound convincing but are factually incorrect. While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. Retrieval Augmented Generation (RAG) techniques help address this by grounding LLMs in relevant data during inference, but these models can still generate non-deterministic outputs and occasionally fabricate information even when given accurate source material. For organizations deploying LLMs in production applications—particularly in critical domains such as healthcare, finance, or legal services—these residual hallucinations pose serious risks, potentially leading to misinformation, liability issues, and loss of user trust.
To address these challenges, we introduce a practical solution that combines the flexibility of LLMs with the reliability of drafted, curated, verified answers. Our solution uses two key Amazon Bedrock services: Amazon Bedrock Knowledge Bases, a fully managed service that you can use to store, search, and retrieve organization-specific information for use with LLMs; and Amazon Bedrock Agents, a fully managed service that you can use to build, test, and deploy AI assistants that can understand user requests, break them down into steps, and execute actions. Similar to how a customer service team maintains a bank of carefully crafted answers to frequently asked questions (FAQs), our solution first checks if a user’s question matches curated and verified responses before letting the LLM generate a new answer. This approach helps prevent hallucinations by using trusted information whenever possible, while still allowing the LLM to handle new or unique questions. By implementing this technique, organizations can improve response accuracy, reduce response times, and lower costs. Whether you’re new to AI development or an experienced practitioner, this post provides step-by-step guidance and code examples to help you build more reliable AI applications.
Solution overview
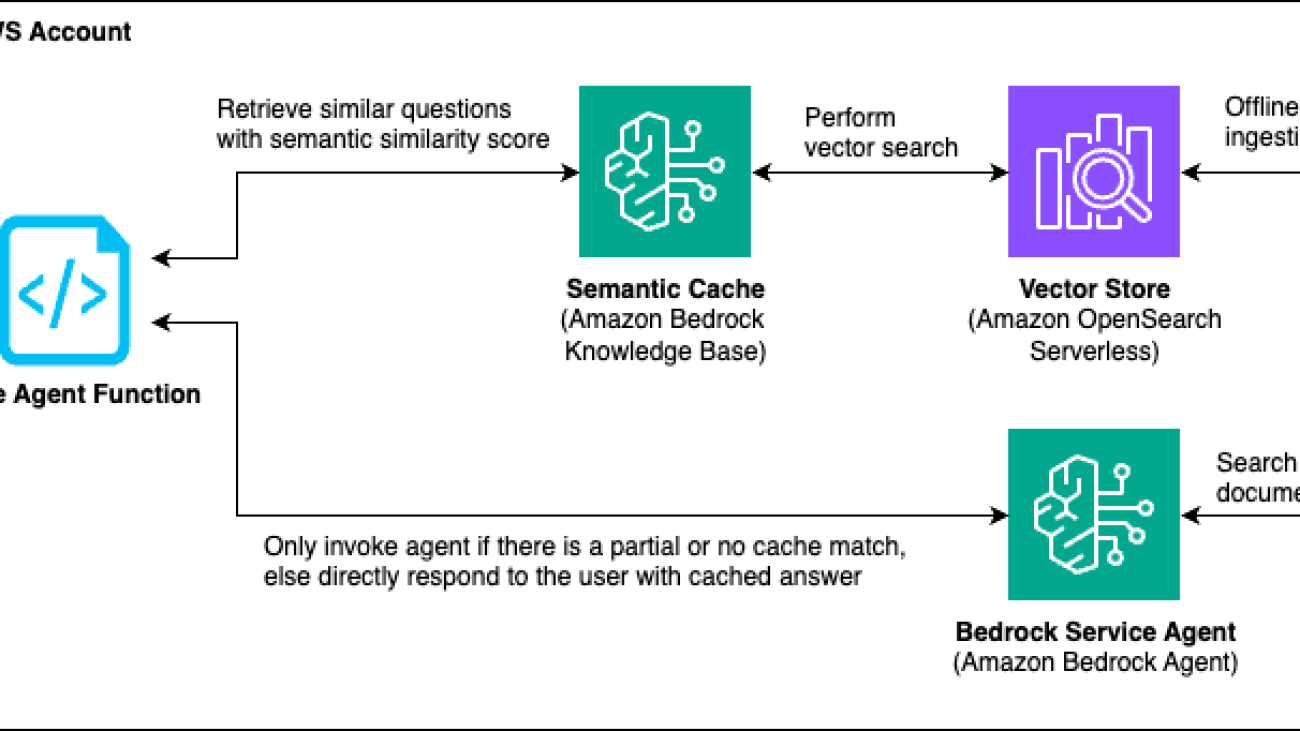
Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. This read-only semantic cache acts as an intelligent intermediary layer between the user and Amazon Bedrock Agents, storing curated and verified question-answer pairs.
When a user submits a query, the solution first evaluates its semantic similarity with existing verified questions in the knowledge base. For highly similar queries (greater than 80% match), the solution bypasses the LLM completely and returns the curated and verified answer directly. When partial matches (60–80% similarity) are found, the solution uses the verified answers as few-shot examples to guide the LLM’s response, significantly improving accuracy and consistency. For queries with low similarity (less than 60%) or no match, the solution falls back to standard LLM processing, making sure that user questions receive appropriate responses.
This approach offers several key benefits:
- Reduced costs: By minimizing unnecessary LLM invocations for frequently answered questions, the solution significantly reduces operational costs at scale
- Improved accuracy: Curated and verified answers minimize the possibility of hallucinations for known user queries, while few-shot prompting enhances accuracy for similar questions.
- Lower latency: Direct retrieval of cached answers provides near-instantaneous responses for known queries, improving the overall user experience.
The semantic cache serves as a growing repository of trusted responses, continuously improving the solution’s reliability while maintaining efficiency in handling user queries.
Solution architecture

The solution architecture in the preceding figure consists of the following components and workflow. Let’s assume that the question “What date will AWS re:invent 2024 occur?” is within the verified semantic cache. The corresponding answer is also input as “AWS re:Invent 2024 takes place on December 2–6, 2024.” Let’s walkthrough an example of how this solution would handle a user’s question.
1. Query processing:
a. User submits a question “When is re:Invent happening this year?”, which is received by the Invoke Agent function.
b. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
c. Amazon Bedrock Knowledge Bases performs a semantic search and finds a similar question with an 85% similarity score.
2. Response paths: (Based on the 85% similarity score in step 1.c, our solution follows the strong match path)
a. Strong match (similarity score greater than 80%):
i. Invoke Agent function returns exactly the verified answer “AWS re:Invent 2024 takes place on December 2–6, 2024” directly from the Amazon Bedrock knowledge base, providing a deterministic response.
ii. No LLM invocation needed, response in less than 1 second.
b. Partial match (similarity score 60–80%):
i. The Invoke Agent function invokes the Amazon Bedrock agent and provides the cached answer as a few-shot example for the agent through Amazon Bedrock Agents promptSessionAttributes.
ii. If the question was “What’s the schedule for AWS events in December?”, our solution would provide the verified re:Invent dates to guide the Amazon Bedrock agent’s response with additional context.
iii. Providing the Amazon Bedrock agent with a curated and verified example might help increase accuracy.
c. No match (similarity score less than 60%):
i. If the user’s question isn’t similar to any of the curated and verified questions in the cache, the Invoke Agent function invokes the Amazon Bedrock agent without providing it any additional context from cache.
ii. For example, if the question was “What hotels are near re:Invent?”, our solution would invoke the Amazon Bedrock agent directly, and the agent would use the tools at its disposal to formulate a response.
3. Offline knowledge management:
a. Verified question-answer pairs are stored in a verified Q&A Amazon S3 bucket (Amazon Simple Storage Service), and must be updated or reviewed periodically to make sure that the cache contains the most recent and accurate information.
b. The S3 bucket is periodically synchronized with the Amazon Bedrock knowledge base. This offline batch process makes sure that the semantic cache remains up-to-date without impacting real-time operations.
Solution walkthrough
You need to meet the following prerequisites for the walkthrough:
- An AWS account
- Model access to Anthropic’s Claude Sonnet V1 and Amazon Titan Text Embedding V2
- AWS Command Line Interface (AWS CLI) installed and configured with the appropriate credentials
Once you have the prerequisites in place, use the following steps to set up the solution in your AWS account.
Step 0: Set up the necessary infrastructure
Follow the “Getting started” instructions in the README of the Git repository to set up the infrastructure for this solution. All the following code samples are extracted from the Jupyter notebook in this repository.
Step 1: Set up two Amazon Bedrock knowledge bases
This step creates two Amazon Bedrock knowledge bases. The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
This establishes the foundation for your semantic caching solution, setting up the AWS resources to store the agent’s knowledge and verified cache entries.
Step 2: Populate the agent knowledge base and associate it with an Amazon Bedrock agent
For this walkthrough, you will create an LLM Amazon Bedrock agent specialized in answering questions about Amazon Bedrock. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset. After ingesting the data, you create an agent with specific instructions:
This setup enables the Amazon Bedrock agent to use the ingested knowledge to provide responses about Amazon Bedrock services. To test it, you can ask a question that isn’t present in the agent’s knowledge base, making the LLM either refuse to answer or hallucinate.
Step 3: Create a cache dataset with known question-answer pairs and populate the cache knowledge base
In this step, you create a raw dataset of verified question-answer pairs that aren’t present in the agent knowledge base. These curated and verified answers serve as our semantic cache to prevent hallucinations on known topics. Good candidates for inclusion in this cache are:
- Frequently asked questions (FAQs): Common queries that users often ask, which can be answered consistently and accurately.
- Critical questions requiring deterministic answers: Topics where precision is crucial, such as pricing information, service limits, or compliance details.
- Time-sensitive information: Recent updates, announcements, or temporary changes that might not be reflected in the main RAG knowledge base.
By carefully curating this cache with high-quality, verified answers to such questions, you can significantly improve the accuracy and reliability of your solution’s responses. For this walkthrough, use the following example pairs for the cache:
Q: 'What are the dates for reinvent 2024?'A: 'The AWS re:Invent conference was held from December 2-6 in 2024.'
Q: 'What was the biggest new feature announcement for Bedrock Agents during reinvent 2024?'A: 'During re:Invent 2024, one of the headline new feature announcements for Bedrock Agents was the custom orchestrator. This key feature allows users to implement their own orchestration strategies through AWS Lambda functions, providing granular control over task planning, completion, and verification while enabling real-time adjustments and reusability across multiple agents.'
You then format these pairs as individual text files with corresponding metadata JSON files, upload them to an S3 bucket, and ingest them into your cache knowledge base. This process makes sure that your semantic cache is populated with accurate, curated, and verified information that can be quickly retrieved to answer user queries or guide the agent’s responses.
Step 4: Implement the verified semantic cache logic
In this step, you implement the core logic of your verified semantic cache solution. You create a function that integrates the semantic cache with your Amazon Bedrock agent, enhancing its ability to provide accurate and consistent responses.
- Queries the cache knowledge base for similar entries to the user question.
- If a high similarity match is found (greater than 80%), it returns the cached answer directly.
- For partial matches (60–80%), it uses the cached answer as a few-shot example for the agent.
- For low similarity (less than 60%), it falls back to standard agent processing.
This simplified logic forms the core of the semantic caching solution, efficiently using curated and verified information to improve response accuracy and reduce unnecessary LLM invocations.
Step 5: Evaluate results and performance
This step demonstrates the effectiveness of the verified semantic cache solution by testing it with different scenarios and comparing the results and latency. You’ll use three test cases to showcase the solution’s behavior:
- Strong semantic match (greater than 80% similarity)
- Partial semantic match (60-80% similarity)
- No semantic match (less than 60% similarity)
Here are the results:
- Strong semantic match (greater than 80% similarity) provides the exact curated and verified answer in less than 1 second.
- Partial semantic match (60–80% similarity) passes the verified answer to the LLM during the invocation. The Amazon Bedrock agent answers the question correctly using the cached answer even though the information is not present in the agent knowledge base.
- No semantic match (less than 60% similarity) invokes the Amazon Bedrock agent as usual. For this query, the LLM will either refuse to provide the information because it’s not present in the agent’s knowledge base, or will hallucinate and provide a response that is plausible but incorrect.
These results demonstrate the effectiveness of the semantic caching solution:
- Strong matches provide near-instant, accurate, and deterministic responses without invoking an LLM.
- Partial matches guide the LLM agent to provide a more relevant or accurate answer.
- No matches fall back to standard LLM agent processing, maintaining flexibility.
The semantic cache significantly reduces latency for known questions and improves accuracy for similar queries, while still allowing the agent to handle unique questions when necessary.
Step 6: Resource clean up
Make sure that the Amazon Bedrock knowledge bases that you created, along with the underlying Amazon OpenSearch Serverless collections are deleted to avoid incurring unnecessary costs.
Production readiness considerations
Before deploying this solution in production, address these key considerations:
- Similarity threshold optimization: Experiment with different thresholds to balance cache hit rates and accuracy. This directly impacts the solution’s effectiveness in preventing hallucinations while maintaining relevance.
- Feedback loop implementation: Create a mechanism to continuously update the verified cache with new, accurate responses. This helps prevent cache staleness and maintains the solution’s integrity as a source of truth for the LLM.
- Cache management and update strategy: Regularly refresh the semantic cache with current, frequently asked questions to maintain relevance and improve hit rates. Implement a systematic process for reviewing, validating, and incorporating new entries to help ensure cache quality and alignment with evolving user needs.
- Ongoing tuning: Adjust similarity thresholds as your dataset evolves. Treat the semantic cache as a dynamic component, requiring continuous optimization for your specific use case.
Conclusion
This verified semantic cache approach offers a powerful solution to reduce hallucinations in LLM responses while improving latency and reducing costs. By using Amazon Bedrock Knowledge Bases, you can implement a solution that can efficiently serve curated and verified answers, guide LLM responses with few-shot examples, and gracefully fall back to full LLM processing when needed.
About the Authors
 Dheer Toprani is a System Development Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazon’s operations. Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
Dheer Toprani is a System Development Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazon’s operations. Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
 Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazon’s Worldwide Returns and ReCommerce organization. He specializes in building scalable machine learning infrastructure, distributed systems, and containerization technologies. His expertise lies in developing robust solutions that enhance monitoring, streamline inference processes, and strengthen audit capabilities to support and optimize Amazon’s global operations.
Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazon’s Worldwide Returns and ReCommerce organization. He specializes in building scalable machine learning infrastructure, distributed systems, and containerization technologies. His expertise lies in developing robust solutions that enhance monitoring, streamline inference processes, and strengthen audit capabilities to support and optimize Amazon’s global operations.
 Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions. At Amazon, he plays a key role in developing scalable data pipelines, improving data quality, and enabling actionable insights for reverse logistics and ReCommerce operations. He is deeply passionate about generative AI and consistently seeks opportunities to implement AI into solving complex customer challenges.
Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions. At Amazon, he plays a key role in developing scalable data pipelines, improving data quality, and enabling actionable insights for reverse logistics and ReCommerce operations. He is deeply passionate about generative AI and consistently seeks opportunities to implement AI into solving complex customer challenges.
 Karam Muppidi is a Senior Engineering Manager at Amazon Retail, where he leads data engineering, infrastructure and analytics for the Worldwide Returns and ReCommerce organization. He has extensive experience developing enterprise-scale data architectures and governance strategies using both proprietary and native AWS platforms, as well as third-party tools. Previously, Karam developed big-data analytics applications and SOX compliance solutions for Amazon’s Fintech and Merchant Technologies divisions.
Karam Muppidi is a Senior Engineering Manager at Amazon Retail, where he leads data engineering, infrastructure and analytics for the Worldwide Returns and ReCommerce organization. He has extensive experience developing enterprise-scale data architectures and governance strategies using both proprietary and native AWS platforms, as well as third-party tools. Previously, Karam developed big-data analytics applications and SOX compliance solutions for Amazon’s Fintech and Merchant Technologies divisions.






 Yunfei Bai is a Principal Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
Yunfei Bai is a Principal Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music. Shayan Ray is an Applied Scientist at Amazon Web Services. His area of research is all things natural language (like NLP, NLU, and NLG). His work has been focused on conversational AI, task-oriented dialogue systems, and LLM-based agents. His research publications are on natural language processing, personalization, and reinforcement learning.
Shayan Ray is an Applied Scientist at Amazon Web Services. His area of research is all things natural language (like NLP, NLU, and NLG). His work has been focused on conversational AI, task-oriented dialogue systems, and LLM-based agents. His research publications are on natural language processing, personalization, and reinforcement learning. Jose Cassio dos Santos Junior is a Senior Data Scientist member of the MLU team. He is responsible for Curriculum Development for Advanced Modules. As a previous Senior Data Scientist on the AWS LATAM Professional Services Data Science team, he has over 20 years of experience working as a software engineer and more than 10 years of teaching experience at colleges and as an instructor for Linux certification preparation and Microsoft Innovation Center bootcamps. As a business process management expert, he participated in BPO projects for more than 7 years. He holds a Master’s degree in Computer Engineering, a Bachelor’s degree in Physics, and a Bachelor’s degree in Business Administration, specialized in IT Quantitative Methods.
Jose Cassio dos Santos Junior is a Senior Data Scientist member of the MLU team. He is responsible for Curriculum Development for Advanced Modules. As a previous Senior Data Scientist on the AWS LATAM Professional Services Data Science team, he has over 20 years of experience working as a software engineer and more than 10 years of teaching experience at colleges and as an instructor for Linux certification preparation and Microsoft Innovation Center bootcamps. As a business process management expert, he participated in BPO projects for more than 7 years. He holds a Master’s degree in Computer Engineering, a Bachelor’s degree in Physics, and a Bachelor’s degree in Business Administration, specialized in IT Quantitative Methods.






















 Manjunath Arakere is a Senior Solutions Architect on the Worldwide Public Sector team at AWS, based in Atlanta, Georgia. He partners with AWS customers to design and scale well-architected solutions, supporting their cloud migrations and modernization initiatives. With extensive experience in the field, Manjunath specializes in migration strategies, application modernization, serverless, and Generative AI (GenAI). He is passionate about helping organizations leverage the full potential of cloud computing to drive innovation and operational efficiency. Outside of work, Manjunath enjoys outdoor runs, tennis, volleyball, and challenging his son in PlayStation soccer games.
Manjunath Arakere is a Senior Solutions Architect on the Worldwide Public Sector team at AWS, based in Atlanta, Georgia. He partners with AWS customers to design and scale well-architected solutions, supporting their cloud migrations and modernization initiatives. With extensive experience in the field, Manjunath specializes in migration strategies, application modernization, serverless, and Generative AI (GenAI). He is passionate about helping organizations leverage the full potential of cloud computing to drive innovation and operational efficiency. Outside of work, Manjunath enjoys outdoor runs, tennis, volleyball, and challenging his son in PlayStation soccer games. Imtranur Rahman is an experienced Sr. Solutions Architect in WWPS team with 14+ years of experience. Imtranur works with large AWS Global SI partners and helps them build their cloud strategy and broad adoption of Amazon’s cloud computing platform. Imtranur specializes in Containers, Dev/SecOps, GitOps, microservices based applications, hybrid application solutions, application modernization and loves innovating on behalf of his customers. He is highly customer obsessed and takes pride in providing the best solutions through his extensive expertise.
Imtranur Rahman is an experienced Sr. Solutions Architect in WWPS team with 14+ years of experience. Imtranur works with large AWS Global SI partners and helps them build their cloud strategy and broad adoption of Amazon’s cloud computing platform. Imtranur specializes in Containers, Dev/SecOps, GitOps, microservices based applications, hybrid application solutions, application modernization and loves innovating on behalf of his customers. He is highly customer obsessed and takes pride in providing the best solutions through his extensive expertise.






 Santosh Kulkarni is a Senior Moderation Architect with over 16 years of experience, specialized in developing serverless, container-based, and data architectures for clients across various domains. Santosh’s expertise extends to machine learning, as a certified AWS ML specialist. Currently, engaged in multiple initiatives leveraging AWS Bedrock and hosted Foundation models.
Santosh Kulkarni is a Senior Moderation Architect with over 16 years of experience, specialized in developing serverless, container-based, and data architectures for clients across various domains. Santosh’s expertise extends to machine learning, as a certified AWS ML specialist. Currently, engaged in multiple initiatives leveraging AWS Bedrock and hosted Foundation models. Joyanta Banerjee is a Senior Modernization Architect with AWS ProServe and specializes in building secure and scalable cloud native application for customers from different industry domains. He has developed an interest in the AI/ML space particularly leveraging Gen AI capabilities available on Amazon Bedrock.
Joyanta Banerjee is a Senior Modernization Architect with AWS ProServe and specializes in building secure and scalable cloud native application for customers from different industry domains. He has developed an interest in the AI/ML space particularly leveraging Gen AI capabilities available on Amazon Bedrock. Mallik Panchumarthy is a Senior Specialist Solutions Architect for generative AI and machine learning at AWS. Mallik works with customers to help them architect efficient, secure and scalable AI and machine learning applications. Mallik specializes in generative AI services Amazon Bedrock and Amazon SageMaker.
Mallik Panchumarthy is a Senior Specialist Solutions Architect for generative AI and machine learning at AWS. Mallik works with customers to help them architect efficient, secure and scalable AI and machine learning applications. Mallik specializes in generative AI services Amazon Bedrock and Amazon SageMaker.



 Sajin Jacob is the Director of Software Engineering at Verisk, where he leads the Premium Audit Advisory Service (PAAS) development team. In this role, Sajin plays a crucial part in designing the architecture and providing strategic guidance to eight development teams, optimizing their efficiency and ensuring the maintainability of all solutions. He holds an MS in Software Engineering from Periyar University, India.
Sajin Jacob is the Director of Software Engineering at Verisk, where he leads the Premium Audit Advisory Service (PAAS) development team. In this role, Sajin plays a crucial part in designing the architecture and providing strategic guidance to eight development teams, optimizing their efficiency and ensuring the maintainability of all solutions. He holds an MS in Software Engineering from Periyar University, India. Jerry Chen is a Lead Software Developer at Verisk, based in Jersey City. He leads the GenAi development team, working on solutions for projects within the Verisk Underwriting department to enhance application functionalities and accessibility. Within PAAS, he has worked on the implementation of the conversational RAG architecture with enhancements such as hybrid search, guardrails, and response evaluations. Jerry holds a degree in Computer Science from Stevens Institute of Technology.
Jerry Chen is a Lead Software Developer at Verisk, based in Jersey City. He leads the GenAi development team, working on solutions for projects within the Verisk Underwriting department to enhance application functionalities and accessibility. Within PAAS, he has worked on the implementation of the conversational RAG architecture with enhancements such as hybrid search, guardrails, and response evaluations. Jerry holds a degree in Computer Science from Stevens Institute of Technology. Sid Mohanram is the Senior Vice President of Core Lines Technology at Verisk. His area of expertise includes data strategy, analytics engineering, and digital transformation. Sid is head of the technology organization with global teams across five countries. He is also responsible for leading the technology transformation for the multi-year Core Lines Reimagine initiative. Sid holds an MS in Information Systems from Stevens Institute of Technology.
Sid Mohanram is the Senior Vice President of Core Lines Technology at Verisk. His area of expertise includes data strategy, analytics engineering, and digital transformation. Sid is head of the technology organization with global teams across five countries. He is also responsible for leading the technology transformation for the multi-year Core Lines Reimagine initiative. Sid holds an MS in Information Systems from Stevens Institute of Technology. Luis Barbier is the Chief Technology Officer (CTO) of Verisk Underwriting at Verisk. He provides guidance to the development teams’ architectures to maximize efficiency and maintainability for all underwriting solutions. Luis holds an MBA from Iona University.
Luis Barbier is the Chief Technology Officer (CTO) of Verisk Underwriting at Verisk. He provides guidance to the development teams’ architectures to maximize efficiency and maintainability for all underwriting solutions. Luis holds an MBA from Iona University. Kristen Chenowith, MSMSL, CPCU, WCP, APA, CIPA, AIS, is PAAS Product Manager at Verisk. She is currently the product owner for the Premium Audit Advisory Service (PAAS) product suite, including PAAS AI, a first to market generative AI chat tool for premium audit that accelerates research for many consultative questions by 98% compared to traditional methods. Kristen holds an MS in Management, Strategy and Leadership at Michigan State University and a BS in Business Administration at Valparaiso University. She has been in the commercial insurance industry and premium audit field since 2006.
Kristen Chenowith, MSMSL, CPCU, WCP, APA, CIPA, AIS, is PAAS Product Manager at Verisk. She is currently the product owner for the Premium Audit Advisory Service (PAAS) product suite, including PAAS AI, a first to market generative AI chat tool for premium audit that accelerates research for many consultative questions by 98% compared to traditional methods. Kristen holds an MS in Management, Strategy and Leadership at Michigan State University and a BS in Business Administration at Valparaiso University. She has been in the commercial insurance industry and premium audit field since 2006. Michelle Stahl, MBA, CPCU, AIM, API, AIS, is a Digital Product Manager with Verisk. She has over 20 years of experience building and transforming technology initiatives for the insurance industry. She has worked as a software developer, project manager, and product manager throughout her career.
Michelle Stahl, MBA, CPCU, AIM, API, AIS, is a Digital Product Manager with Verisk. She has over 20 years of experience building and transforming technology initiatives for the insurance industry. She has worked as a software developer, project manager, and product manager throughout her career. Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed, and uses the working backward process to build modern architectures to help customers solve their unique challenges. Connect with him on
Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed, and uses the working backward process to build modern architectures to help customers solve their unique challenges. Connect with him on  Ryan Doty is a Solutions Architect Manager at AWS, based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
Ryan Doty is a Solutions Architect Manager at AWS, based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him. Apoorva Kiran, PhD, is a Senior Solutions Architect at AWS, based out of New York. He is aligned with the financial service industry, and is responsible for providing architectural guidelines to design innovative and scalable fintech solutions. He specializes in developing and commercializing artificial intelligence and machine learning products. Connect with him on
Apoorva Kiran, PhD, is a Senior Solutions Architect at AWS, based out of New York. He is aligned with the financial service industry, and is responsible for providing architectural guidelines to design innovative and scalable fintech solutions. He specializes in developing and commercializing artificial intelligence and machine learning products. Connect with him on 










 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN)