This paper delves into the challenging task of Active Speaker Detection (ASD), where the system needs to determine in real-time whether a person is speaking or not in a series of video frames. While previous works have made significant strides in improving network architectures and learning effective representations for ASD, a critical gap exists in the exploration of real-time system deployment. Existing models often suffer from high latency and memory usage, rendering them impractical for immediate applications. To bridge this gap, we present two scenarios that address the key challenges…Apple Machine Learning Research

Transforming financial analysis with CreditAI on Amazon Bedrock: Octus’s journey with AWS
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes. Financial institutions need a solution that can not only aggregate and process large volumes of data but also deliver actionable intelligence in a conversational, user-friendly format. The intersection of AI and financial analysis presents a compelling opportunity to transform how investment professionals access and use credit intelligence, leading to more efficient decision-making processes and better risk management outcomes.
Founded in 2013, Octus, formerly Reorg, is the essential credit intelligence and data provider for the world’s leading buy side firms, investment banks, law firms and advisory firms. By surrounding unparalleled human expertise with proven technology, data and AI tools, Octus unlocks powerful truths that fuel decisive action across financial markets. Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. Follow Octus on LinkedIn and X.
Using advanced GenAI, CreditAI by Octus is a flagship conversational chatbot that supports natural language queries and real-time data access with source attribution, significantly reducing analysis time and streamlining research workflows. It gives instant access to insights on over 10,000 companies from hundreds of thousands of proprietary intel articles, helping financial institutions make informed credit decisions while effectively managing risk. Key features include chat history management, being able to ask questions that are targeted to a specific company or more broadly to a sector, and getting suggestions on follow-up questions.
is a flagship conversational chatbot that supports natural language queries and real-time data access with source attribution, significantly reducing analysis time and streamlining research workflows. It gives instant access to insights on over 10,000 companies from hundreds of thousands of proprietary intel articles, helping financial institutions make informed credit decisions while effectively managing risk. Key features include chat history management, being able to ask questions that are targeted to a specific company or more broadly to a sector, and getting suggestions on follow-up questions.
In this post, we demonstrate how Octus migrated its flagship product, CreditAI, to Amazon Bedrock, transforming how investment professionals access and analyze credit intelligence. We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate, and Amazon OpenSearch Service. We share detailed insights into the architecture decisions, implementation strategies, security best practices, and key learnings that enabled Octus to maintain zero downtime while significantly improving the application’s performance and scalability.
Opportunities for innovation
CreditAI by Octus version 1.x uses Retrieval Augmented Generation (RAG). It was built using a combination of in-house and external cloud services on Microsoft Azure for large language models (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Based on our operational experience, and as we started scaling up, we realized that there were several operational inefficiencies and opportunities for improvement:
- Our in-house services for embeddings (deployed on EC2 instances) were not as scalable and reliable as needed. They also required more time on operational maintenance than our team could spare.
- The overall solution was incurring high operational costs, especially due to the use of on-demand GPU instances. The real-time nature of our application meant that Spot Instances were not an option. Additionally, our investigation of lower-cost CPU-based instances revealed that they couldn’t meet our latency requirements.
- The use of multiple external cloud providers complicated DevOps, support, and budgeting.
These operational inefficiencies meant that we had to revisit our solution architecture. It became apparent that a cost-effective solution for our generative AI needs was required. Enter Amazon Bedrock Knowledge Bases. With its support for knowledge bases that simplify RAG operations, vectorized search as part of its integration with OpenSearch Service, availability of multi-tenant embeddings, as well as Anthropic’s Claude suite of LLMs, it was a compelling choice for Octus to migrate its solution architecture. Along the way, it also simplified operations as Octus is an AWS shop more generally. However, we were still curious about how we would go about this migration, and whether there would be any downtime through the transition.
Strategic requirements
To help us move forward systematically, Octus identified the following key requirements to guide the migration to Amazon Bedrock:
- Scalability – A crucial requirement was the need to scale operations from handling hundreds of thousands of documents to millions of documents. A significant challenge in the previous system was the slow (and relatively unreliable) process of embedding new documents into vector databases, which created bottlenecks in scaling operations.
- Cost-efficiency and infrastructure optimization – CreditAI 1.x, though performant, was incurring high infrastructure costs due to the use of GPU-based, single-tenant services for embeddings and reranking. We needed multi-tenant alternatives that were much cheaper while enabling elasticity and scale.
- Response performance and latency – The success of generative AI-based applications depends on the response quality and speed. Given our user base, it’s important that our responses are accurate while valuing users’ time (low latency). This is a challenge when the data size and complexity grow. We want to balance spatial and temporal retrieval in order to give responses that have the best answer and context relevance, especially when we get large quantities of data updated every day.
- Zero downtime – CreditAI is in production and we could not afford any downtime during this migration.
- Technological agility and innovation – In the rapidly evolving AI landscape, Octus recognized the importance of maintaining technological competitiveness. We wanted to move away from in-house development and feature maintenance such as embeddings services, rerankers, guardrails, and RAG evaluators. This would allow Octus to focus on product innovation and faster feature deployment.
- Operational consolidation and reliability – Octus’s goal is to consolidate cloud providers, and to reduce support overheads and operational complexity.
Migration to Amazon Bedrock and addressing our requirements
Migrating to Amazon Bedrock addressed our aforementioned requirements in the following ways:
- Scalability – The architecture of Amazon Bedrock, combined with AWS Fargate for Amazon ECS, Amazon Textract, and AWS Lambda, provided the elastic and scalable infrastructure necessary for this expansion while maintaining performance, data integrity, compliance, and security standards. The solution’s efficient document processing and embedding capabilities addressed the previous system’s limitations, enabling faster and more efficient knowledge base updates.
- Cost-efficiency and infrastructure optimization – By migrating to Amazon Bedrock multi-tenant embedding, Octus achieved significant cost reduction while maintaining performance standards through Anthropic’s Claude Sonnet and improved embedding capabilities. This move alleviated the need for GPU-instance-based services in favor of more cost-effective and serverless Amazon ECS and Fargate solutions.
- Response performance and latency – Octus verified the quality and latency of responses from Anthropic’s Claude Sonnet to confirm that response accuracy and latency are not maintained (or even exceeded) as part of this migration. With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before.
- Zero downtime – We were able to achieve zero downtime migration to Amazon Bedrock for our application using our in-house centralized infrastructure frameworks. Our frameworks comprise infrastructure as code (IaC) through Terraform, continuous integration and delivery (CI/CD), SOC2 security, monitoring, observability, and alerting for our infrastructure and applications.
- Technological agility and innovation – Amazon Bedrock emerged as an ideal partner, offering solutions specifically designed for AI application development. Amazon Bedrock built-in features, such as embeddings services, reranking, guardrails, and the upcoming RAG evaluator, alleviated the need for in-house development of these components, allowing Octus to focus on product innovation and faster feature deployment.
- Operational consolidation and reliability – The comprehensive suite of AWS services offers a streamlined framework that simplifies operations while providing high availability and reliability. This consolidation minimizes the complexity of managing multiple cloud providers and creates a more cohesive technological ecosystem. It also enables economies of scale with development velocity given that over 75 engineers at Octus already use AWS services for application development.
In addition, the Amazon Bedrock Knowledge Bases team worked closely with us to address several critical elements, including expanding embedding limits, managing the metadata limit (250 characters), testing different chunking methods, and syncing throughput to the knowledge base.
In the following sections, we explore our solution and how we addressed the details around the migration to Amazon Bedrock and Fargate.
Solution overview
The following figure illustrates our system architecture for CreditAI on AWS, with two key paths: the document ingestion and content extraction workflow, and the Q&A workflow for live user query response.
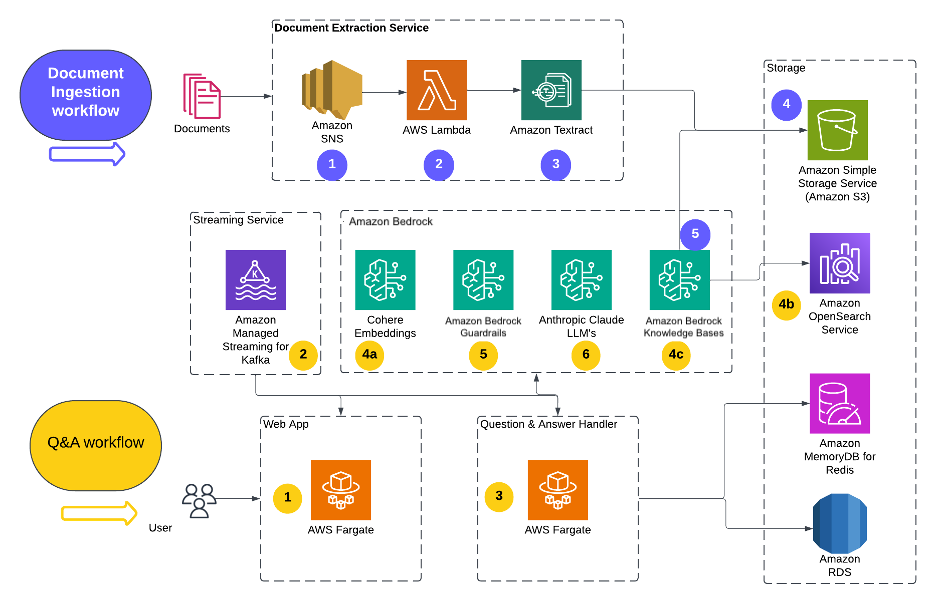
In the following sections, we dive into crucial details within key components in our solution. In each case, we connect them to the requirements discussed earlier for readability.
The document ingestion workflow (numbered in blue in the preceding diagram) processes content through five distinct stages:
- Documents uploaded to Amazon Simple Storage Service (Amazon S3) automatically invoke Lambda functions through S3 Event Notifications. This event-driven architecture provides immediate processing of new documents.
- Lambda functions process the event payload containing document location, perform format validation, and prepare content for extraction. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract.
- Amazon Textract processes the documents to extract both text and structural information. This service handles various formats, including PDFs, images, and forms, while preserving document layout and relationships between content elements.
- The extracted content is stored in a dedicated S3 prefix, separate from the source documents, maintaining clear data lineage. Each processed document maintains references to its source file, extraction timestamp, and processing metadata.
- The extracted content flows into Amazon Bedrock Knowledge Bases, where our semantic chunking strategy is implemented to divide content into optimal segments. The system then generates embeddings for each chunk and stores these vectors in OpenSearch Service for efficient retrieval. Throughout this process, the system maintains comprehensive metadata to support downstream filtering and source attribution requirements.
The Q&A workflow (numbered in yellow in the preceding diagram) processes user interactions through six integrated stages:
- The web application, hosted on AWS Fargate, handles user interactions and query inputs, managing initial request validation before routing queries to appropriate processing services.
- Amazon Managed Streaming for Kafka (Amazon MSK) serves as the streaming service, providing reliable inter-service communication while maintaining message ordering and high-throughput processing for query handling.
- The Q&A handler, running on AWS Fargate, orchestrates the complete query response cycle by coordinating between services and processing responses through the LLM pipeline.
- The pipeline integrates with Amazon Bedrock foundation models through these components:
- Cohere Embeddings model performs vector transformations of the input.
- Amazon OpenSearch Service manages vector embeddings and performs similarity searches.
- Amazon Bedrock Knowledge Bases provides efficient access to the document repository.
- Amazon Bedrock Guardrails implements content filtering and safety checks as part of the query processing pipeline.
- Anthropic Claude LLM performs the natural language processing, generating responses that are then returned to the web application.
This integrated workflow provides efficient query processing while maintaining response quality and system reliability.
For scalability: Using OpenSearch Service as our vector database
Amazon OpenSearch Serverless emerged as the optimal solution for CreditAI’s evolving requirements, offering advanced capabilities while maintaining seamless integration within the AWS ecosystem:
- Vector search capabilities – OpenSearch Serverless provides robust built-in vector search capabilities essential for our needs. The service supports hybrid search, allowing us to combine vector embeddings with raw text search without modifying our embedding model. This capability proved crucial for enabling broader question support in CreditAI 2.x, enhancing its overall usability and flexibility.
- Serverless architecture benefits – The serverless design alleviates the need to provision, configure, or tune infrastructure, significantly reducing operational complexities. This shift allows our team to focus more time and resources on feature development and application improvements rather than managing underlying infrastructure.
- AWS integration advantages – The tight integration with other AWS services, particularly Amazon S3 and Amazon Bedrock, streamlines our content ingestion process. This built-in compatibility provides a cohesive and scalable landscape for future enhancements while maintaining optimal performance.
OpenSearch Serverless enabled us to scale our vector search capabilities efficiently while minimizing operational overhead and maintaining high performance standards.
For scalability and security: Splitting data across multiple vector databases with in-house support for intricate permissions
To enhance scalability and security, we implemented isolated knowledge bases (corresponding to vector databases) for each client data. Although this approach slightly increases costs, it delivers multiple significant benefits. Primarily, it maintains complete isolation of client data, providing enhanced privacy and security. Thanks to Amazon Bedrock Knowledge Bases, this solution doesn’t compromise on performance. Amazon Bedrock Knowledge Bases enables concurrent embedding and synchronization across multiple knowledge bases, allowing us to maintain real-time updates without delays—something previously unattainable with our previous GPU based architectures.
Additionally, we introduced two in-house services within Octus to strengthen this system:
- AuthZ access management service – This service enforces granular access control, making sure users and applications can only interact with the data they are authorized to access. We had to migrate our AuthZ backend from Airbyte to native SQL replication so that it can support access management in near real time at scale.
- Global identifiers service – This service provides a unified framework to link identifiers across multiple domains, enabling seamless integration and cross-referencing of identifiers across multiple datasets.
Together, these enhancements create a robust, secure, and highly efficient environment for managing and accessing client data.
For cost efficiency: Adopting a multi-tenant embedding service
In our migration to Amazon Bedrock Knowledge Bases, Octus made a strategic shift from using an open-source embedding service on EC2 instances to using the managed embedding capabilities of Amazon Bedrock through Cohere’s multilingual model. This transition was carefully evaluated based on several key factors.
Our selection of Cohere’s multilingual model was driven by two primary advantages. First, it demonstrated superior retrieval performance in our comparative testing. Second, it offered robust multilingual support capabilities that were essential for our global operations.
The technical benefits of this migration manifested in two distinct areas: document embedding and message embedding. In document embedding, we transitioned from a CPU-based system to Amazon Bedrock Knowledge Bases, which enabled faster and higher throughput document processing through its multi-tenant architecture. For message embedding, we alleviated our dependency on dedicated GPU instances while maintaining optimal performance with 20–30 millisecond embedding times. The Amazon Bedrock Knowledge Bases API also simplified our operations by combining embedding and retrieval functionality into a single API call.
The migration to Amazon Bedrock Knowledge Bases managed embedding delivered two significant advantages: it eliminated the operational overhead of maintaining our own open-source solution while providing access to industry-leading embedding capabilities through Cohere’s model. This helped us achieve both our cost-efficiency and performance objectives without compromises.
For cost-efficiency and response performance: Choice of chunking strategy
Our primary goal was to improve three critical aspects of CreditAI’s responses: quality (accuracy of information), groundedness (ability to trace responses back to source documents), and relevance (providing information that directly answers user queries). To achieve this, we tested three different approaches to breaking down documents into smaller pieces (chunks):
- Fixed chunking – Breaking text into fixed-length pieces
- Semantic chunking – Breaking text based on natural semantic boundaries like paragraphs, sections, or complete thoughts
- Hierarchical chunking – Creating a two-level structure with smaller child chunks for precise matching and larger parent chunks for contextual understanding
Our testing showed that both semantic and hierarchical chunking performed significantly better than fixed chunking in retrieving relevant information. However, each approach came with its own technical considerations.
Hierarchical chunking requires a larger chunk size to maintain comprehensive context during retrieval. This approach creates a two-level structure: smaller child chunks for precise matching and larger parent chunks for contextual understanding. During retrieval, the system first identifies relevant child chunks and then automatically includes their parent chunks to provide broader context. Although this method optimizes both search precision and context preservation, we couldn’t implement it with our preferred Cohere embeddings because they only support chunks up to 512 tokens, which is insufficient for the parent chunks needed to maintain effective hierarchical relationships.
Semantic chunking uses LLMs to intelligently divide text by analyzing both semantic similarity and natural language structures. Instead of arbitrary splits, the system identifies logical break points by calculating embedding-based similarity scores between sentences and paragraphs, making sure semantically related content stays together. The resulting chunks maintain context integrity by considering both linguistic features (like sentence and paragraph boundaries) and semantic coherence, though this precision comes at the cost of additional computational resources for LLM analysis and embedding calculations.
After evaluating our options, we chose semantic chunking despite two trade-offs:
- It requires additional processing by our LLMs, which increases costs
- It has a limit of 1,000,000 tokens per document processing batch
We made this choice because semantic chunking offered the best balance between implementation simplicity and retrieval performance. Although hierarchical chunking showed promise, it would have been more complex to implement and harder to scale. This decision helped us maintain high-quality, grounded, and relevant responses while keeping our system manageable and efficient.
For response performance and technical agility: Adopting Amazon Bedrock Guardrails with Amazon Bedrock Knowledge Bases
Our implementation of Amazon Bedrock Guardrails focused on three key objectives: enhancing response security, optimizing performance, and simplifying guardrail management. This service plays a crucial role in making sure our responses are both safe and efficient.
Amazon Bedrock Guardrails provides a comprehensive framework for content filtering and response moderation. The system works by evaluating content against predefined rules before the LLM processes it, helping prevent inappropriate content and maintaining response quality. Through the Amazon Bedrock Guardrails integration with Amazon Bedrock Knowledge Bases, we can configure, test, and iterate on our guardrails without writing complex code.
We achieved significant technical improvements in three areas:
- Simplified moderation framework – Instead of managing multiple separate denied topics, we consolidated our content filtering into a unified guardrail service. This approach allows us to maintain a single source of truth for content moderation rules, with support for customizable sample phrases that help fine-tune our filtering accuracy.
- Performance optimization – We improved system performance by integrating guardrail checks directly into our main prompts, rather than running them as separate operations. This optimization reduced our token usage and minimized unnecessary API calls, resulting in lower latency for each query.
- Enhanced content control – The service provides configurable thresholds for filtering potentially harmful content and includes built-in capabilities for detecting hallucinations and assessing response relevance. This alleviated our dependency on external services like TruLens while maintaining robust content quality controls.
These improvements have helped us maintain high response quality while reducing both operational complexity and processing overhead. The integration with Amazon Bedrock has given us a more streamlined and efficient approach to content moderation.
To achieve zero downtime: Infrastructure migration
Our migration to Amazon Bedrock required careful planning to provide uninterrupted service for CreditAI while significantly reducing infrastructure costs. We achieved this through our comprehensive infrastructure framework that addresses deployment, security, and monitoring needs:
- IaC implementation – We used reusable Terraform modules to manage our infrastructure consistently across environments. These modules enabled us to share configurations efficiently between services and projects. Our approach supports multi-Region deployments with minimal configuration changes while maintaining infrastructure version control alongside application code.
- Automated deployment strategy – Our GitOps-embedded framework streamlines the deployment process by implementing a clear branching strategy for different environments. This automation handles CreditAI component deployments through CI/CD pipelines, reducing human error through automated validation and testing. The system also enables rapid rollback capabilities if needed.
- Security and compliance – To maintain SOC2 compliance and robust security, our framework incorporates comprehensive access management controls and data encryption at rest and in transit. We follow network security best practices, conduct regular security audits and monitoring, and run automated compliance checks in the deployment pipeline.
We maintained zero downtime during the entire migration process while reducing infrastructure costs by 70% by eliminating GPU instances. The successful transition from Amazon ECS on Amazon EC2 to Amazon ECS with Fargate has simplified our infrastructure management and monitoring.
Achieving excellence
CreditAI’s migration to Amazon Bedrock has yielded remarkable results for Octus:
- Scalability – We have almost doubled the number of documents available for Q&A across three environments in days instead of weeks. Our use of Amazon ECS with Fargate with auto scaling rules and controls gives us elastic scalability for our services during peak usage hours.
- Cost-efficiency and infrastructure optimization – By moving away from GPU-based clusters to Fargate, our monthly infrastructure costs are now 78.47% lower, and our per-question costs have reduced by 87.6%.
- Response performance and latency – There has been no drop in latency, and have seen a 27% increase in questions answered successfully. We have also seen a 250% boost in user engagement. Users especially love our support for broad, industry-wide questions enabled by Anthropic’s Claude Sonnet.
- Zero downtime – We experienced zero downtime during migration and 99% uptime overall for the whole application.
- Technological agility and innovation – We have been able to add new document sources in a quarter of the time it took pre-migration. In addition, we adopted enhanced guardrails support for free and no longer have to retrieve documents from the knowledge base and pass the chunks to Anthropic’s Claude Sonnet to trigger a guardrail.
- Operational consolidation and reliability – Post-migration, our DevOps and SRE teams see 20% less maintenance burden and overheads. Supporting SOC2 compliance is also straightforward now that we’re using only one cloud provider.
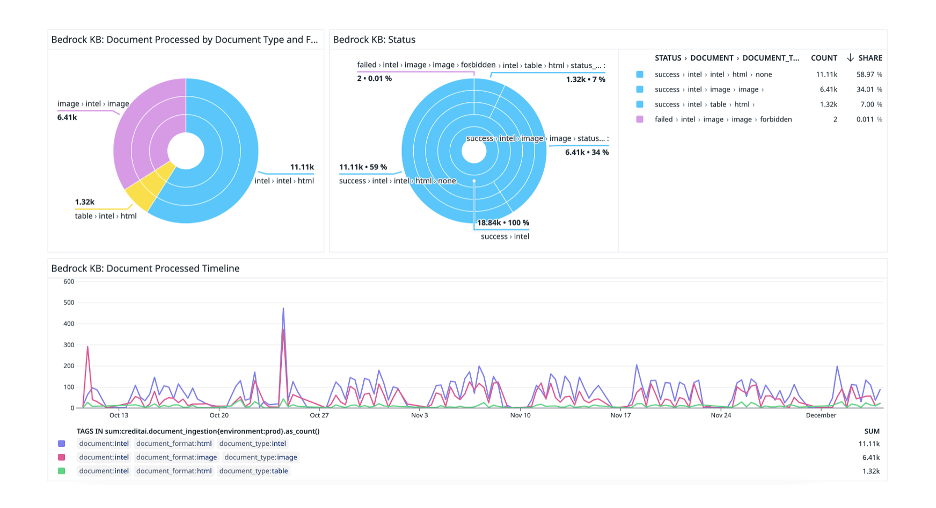
Operational monitoring
We use Datadog to monitor both LLM latency and our document ingestion pipeline, providing real-time visibility into system performance. The following screenshot showcases how we use custom Datadog dashboards to provide a live view of the document ingestion pipeline. This visualization offers both a high-level overview and detailed insights into the ingestion process, helping us understand the volume, format, and status of the documents processed. The bottom half of the dashboard presents a time-series view of document processing volumes. The timeline tracks fluctuations in processing rates, identifies peak activity periods, and provides actionable insights to optimize throughput. This detailed monitoring system enables us to maintain efficiency, minimize failures, and provide scalability.
Roadmap
Looking ahead, Octus plans to continue enhancing CreditAI by taking advantage of new capabilities released by Amazon Bedrock that continue to meet and exceed our requirements. Future developments will include:
- Enhance retrieval by testing and integrating with reranking techniques, allowing the system to prioritize the most relevant search results for better user experience and accuracy.
- Explore the Amazon Bedrock RAG evaluator to capture detailed metrics on CreditAI’s performance. This will add to the existing mechanisms at Octus to track performance that include tracking unanswered questions.
- Expand to ingest large-scale structured data, making it capable of handling complex financial datasets. The integration of text-to-SQL will enable users to query structured databases using natural language, simplifying data access.
- Explore replacing our in-house content extraction service (ADE) with the Amazon Bedrock advanced parsing solution to potentially further reduce document ingestion costs.
- Improve CreditAI’s disaster recovery and redundancy mechanisms, making sure that our services and infrastructure are more fault tolerant and can recover from outages faster.
These upgrades aim to boost the precision, reliability, and scalability of CreditAI.
Vishal Saxena, CTO at Octus, shares: “CreditAI is a first-of-its-kind generative AI application that focuses on the entire credit lifecycle. It is truly ’AI embedded’ software that combines cutting-edge AI technologies with an enterprise data architecture and a unified cloud strategy.”
Conclusion
CreditAI by Octus is the company’s flagship conversational chatbot that supports natural language queries and gives instant access to insights on over 10,000 companies from hundreds of thousands of proprietary intel articles. In this post, we described in detail our motivation, process, and results on Octus’s migration to Amazon Bedrock. Through this migration, Octus achieved remarkable results that included an over 75% reduction in operating costs as well as a 250% boost in engagement. Future steps include adopting new features such as reranking, RAG evaluator, and advanced parsing to further reduce costs and improve performance. We believe that the collaboration between Octus and AWS will continue to revolutionize financial analysis and research workflows.
To learn more about Amazon Bedrock, refer to the Amazon Bedrock User Guide.
About the Authors
 Vaibhav Sabharwal is a Senior Solutions Architect with Amazon Web Services based out of New York. He is passionate about learning new cloud technologies and assisting customers in building cloud adoption strategies, designing innovative solutions, and driving operational excellence. As a member of the Financial Services Technical Field Community at AWS, he actively contributes to the collaborative efforts within the industry.
Vaibhav Sabharwal is a Senior Solutions Architect with Amazon Web Services based out of New York. He is passionate about learning new cloud technologies and assisting customers in building cloud adoption strategies, designing innovative solutions, and driving operational excellence. As a member of the Financial Services Technical Field Community at AWS, he actively contributes to the collaborative efforts within the industry.
 Yihnew Eshetu is a Senior Director of AI Engineering at Octus, leading the development of AI solutions at scale to address complex business problems. With seven years of experience in AI/ML, his expertise spans GenAI and NLP, specializing in designing and deploying agentic AI systems. He has played a key role in Octus’s AI initiatives, including leading AI Engineering for its flagship GenAI chatbot, CreditAI.
Yihnew Eshetu is a Senior Director of AI Engineering at Octus, leading the development of AI solutions at scale to address complex business problems. With seven years of experience in AI/ML, his expertise spans GenAI and NLP, specializing in designing and deploying agentic AI systems. He has played a key role in Octus’s AI initiatives, including leading AI Engineering for its flagship GenAI chatbot, CreditAI.
 Harmandeep Sethi is a Senior Director of SRE Engineering and Infrastructure Frameworks at Octus, with nearly 10 years of experience leading high-performing teams in the design, implementation, and optimization of large-scale, highly available, and reliable systems. He has played a pivotal role in transforming and modernizing Credit AI infrastructure and services by driving best practices in observability, resilience engineering, and the automation of operational processes through Infrastructure Frameworks.
Harmandeep Sethi is a Senior Director of SRE Engineering and Infrastructure Frameworks at Octus, with nearly 10 years of experience leading high-performing teams in the design, implementation, and optimization of large-scale, highly available, and reliable systems. He has played a pivotal role in transforming and modernizing Credit AI infrastructure and services by driving best practices in observability, resilience engineering, and the automation of operational processes through Infrastructure Frameworks.
 Rohan Acharya is an AI Engineer at Octus, specializing in building and optimizing AI-driven solutions at scale. With expertise in GenAI and NLP, he focuses on designing and deploying intelligent systems that enhance automation and decision-making. His work involves developing robust AI architectures and advancing Octus’s AI initiatives, including the evolution of CreditAI.
Rohan Acharya is an AI Engineer at Octus, specializing in building and optimizing AI-driven solutions at scale. With expertise in GenAI and NLP, he focuses on designing and deploying intelligent systems that enhance automation and decision-making. His work involves developing robust AI architectures and advancing Octus’s AI initiatives, including the evolution of CreditAI.
 Hasan Hasibul is a Principal Architect at Octus leading the DevOps team, with nearly 12 years of experience in building scalable, complex architectures while following software development best practices. A true advocate of clean code, he thrives on solving complex problems and automating infrastructure. Passionate about DevOps, infrastructure automation, and the latest advancements in AI, he has architected Octus initial CreditAI, pushing the boundaries of innovation.
Hasan Hasibul is a Principal Architect at Octus leading the DevOps team, with nearly 12 years of experience in building scalable, complex architectures while following software development best practices. A true advocate of clean code, he thrives on solving complex problems and automating infrastructure. Passionate about DevOps, infrastructure automation, and the latest advancements in AI, he has architected Octus initial CreditAI, pushing the boundaries of innovation.
 Philipe Gutemberg is a Principal Software Engineer and AI Application Development Team Lead at Octus, passionate about leveraging technology for impactful solutions. An AWS Certified Solutions Architect – Associate (SAA), he has expertise in software architecture, cloud computing, and leadership. Philipe led both backend and frontend application development for CreditAI, ensuring a scalable system that integrates AI-driven insights into financial applications. A problem-solver at heart, he thrives in fast-paced environments, delivering innovative solutions for financial institutions while fostering mentorship, team development, and continuous learning.
Philipe Gutemberg is a Principal Software Engineer and AI Application Development Team Lead at Octus, passionate about leveraging technology for impactful solutions. An AWS Certified Solutions Architect – Associate (SAA), he has expertise in software architecture, cloud computing, and leadership. Philipe led both backend and frontend application development for CreditAI, ensuring a scalable system that integrates AI-driven insights into financial applications. A problem-solver at heart, he thrives in fast-paced environments, delivering innovative solutions for financial institutions while fostering mentorship, team development, and continuous learning.
 Kishore Iyer is the VP of AI Application Development and Engineering at Octus. He leads teams that build, maintain and support Octus’s customer-facing GenAI applications, including CreditAI, our flagship AI offering. Prior to Octus, Kishore has 15+ years of experience in engineering leadership roles across large corporations, startups, research labs, and academia. He holds a Ph.D. in computer engineering from Rutgers University.
Kishore Iyer is the VP of AI Application Development and Engineering at Octus. He leads teams that build, maintain and support Octus’s customer-facing GenAI applications, including CreditAI, our flagship AI offering. Prior to Octus, Kishore has 15+ years of experience in engineering leadership roles across large corporations, startups, research labs, and academia. He holds a Ph.D. in computer engineering from Rutgers University.
 Kshitiz Agarwal is an Engineering Leader at Amazon Web Services (AWS), where he leads the development of Amazon Bedrock Knowledge Bases. With a decade of experience at Amazon, having joined in 2012, Kshitiz has gained deep insights into the cloud computing landscape. His passion lies in engaging with customers and understanding the innovative ways they leverage AWS to drive their business success. Through his work, Kshitiz aims to contribute to the continuous improvement of AWS services, enabling customers to unlock the full potential of the cloud.
Kshitiz Agarwal is an Engineering Leader at Amazon Web Services (AWS), where he leads the development of Amazon Bedrock Knowledge Bases. With a decade of experience at Amazon, having joined in 2012, Kshitiz has gained deep insights into the cloud computing landscape. His passion lies in engaging with customers and understanding the innovative ways they leverage AWS to drive their business success. Through his work, Kshitiz aims to contribute to the continuous improvement of AWS services, enabling customers to unlock the full potential of the cloud.
 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
 Tim Ramos is a Senior Account Manager at AWS. He has 12 years of sales experience and 10 years of experience in cloud services, IT infrastructure, and SaaS. Tim is dedicated to helping customers develop and implement digital innovation strategies. His focus areas include business transformation, financial and operational optimization, and security. Tim holds a BA from Gonzaga University and is based in New York City.
Tim Ramos is a Senior Account Manager at AWS. He has 12 years of sales experience and 10 years of experience in cloud services, IT infrastructure, and SaaS. Tim is dedicated to helping customers develop and implement digital innovation strategies. His focus areas include business transformation, financial and operational optimization, and security. Tim holds a BA from Gonzaga University and is based in New York City.
Optimize reasoning models like DeepSeek with prompt optimization on Amazon Bedrock
DeepSeek-R1 models, now available on Amazon Bedrock Marketplace, Amazon SageMaker JumpStart, as well as a serverless model on Amazon Bedrock, were recently popularized by their long and elaborate thinking style, which, according to DeepSeek’s published results, lead to impressive performance on highly challenging math benchmarks like AIME-2024 and MATH-500, as well as competitive performance compared to then state-of-the-art models like Anthropic’s Claude Sonnet 3.5, GPT 4o, and OpenAI O1 (more details in this paper).
During training, researchers showed how DeepSeek-R1-Zero naturally learns to solve tasks with more thinking time, which leads to a boost in performance. However, what often gets ignored is the number of thinking tokens required at inference time, and the time and cost of generating these tokens before answering the original question.
In this post, we demonstrate how to optimize reasoning models like DeepSeek-R1 using prompt optimization on Amazon Bedrock.
Long reasoning chains and challenges with maximum token limits
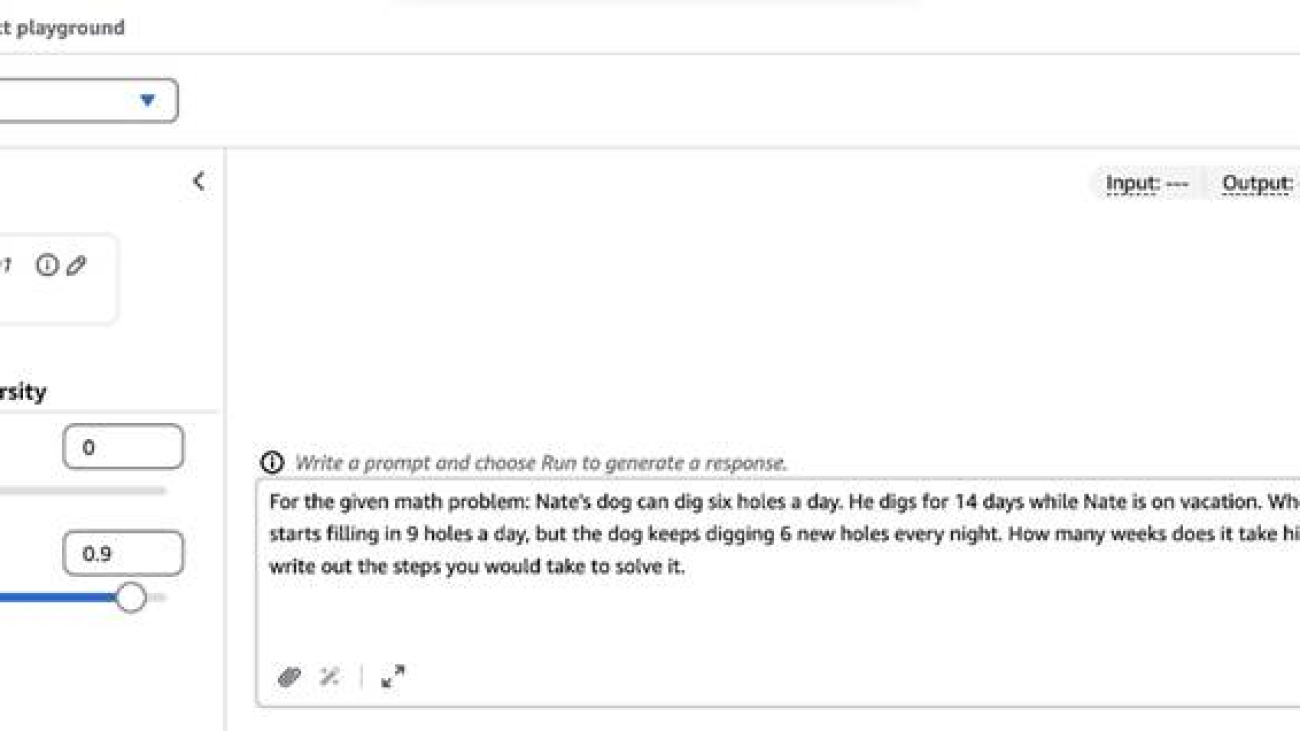
Let’s try out a straightforward question on DeepSeek-R1:
For the given math problem: Nate’s dog can dig six holes a day. He digs for 14 days while Nate is on vacation. When Nate gets home, he starts filling in 9 holes a day, but the dog keeps digging 6 new holes every night. How many weeks does it take him to fill in all the holes?, write out the steps you would take to solve it.
On the Amazon Bedrock Chat/Text Playground, you can follow along by choosing the new DeepSeek-R1 model, as shown in the following screenshot.

You might see that sometimes, based on the question, reasoning models don’t finish thinking within the overall maximum token budget.

Increasing the output token budget allows the model to think for longer. With the maximum tokens increased from 2,048 to 4,096, you should see the model reasoning for a while before printing the final answer.

The appendix at the end of this post provides the complete response. You can also collapse the reasoning steps to view just the final answer.

As we can see in the case with the 2,048-token budget, the thinking process didn’t end. This not only cost us 2,048 tokens’ worth of time and money, but we also didn’t get the final answer! This observation of high token counts for thinking usually leads to a few follow-up questions, such as:
- Is it possible to reduce the thinking tokens and still get a correct answer?
- Can the thinking be restricted to a maximum number of thinking tokens, or a thinking budget?
- At a high level, should thinking-intensive models like DeepSeek be used in real-time applications at all?
In this post, we show you how you can optimize thinking models like DeepSeek-R1 using prompt optimization on Amazon Bedrock, resulting in more succinct thinking traces without sacrificing accuracy.
Optimize DeepSeek-R1 prompts
To get started with prompt optimization, select DeepSeek-R1 on the model playground on Amazon Bedrock, enter your prompt, and choose the magic wand icon, or use the Amazon Bedrock optimize_prompt() API. You may also use prompt optimization on the console, add variables if required, set your model to Deepseek-R1 and model parameters, and click “Optimize”:

To demonstrate how prompt optimization on Amazon Bedrock can help with reasoning models, we first need a challenging dataset. Humanity’s Last Exam (HLE), a benchmark of extremely challenging questions from dozens of subject areas, is designed to be the “final” closed-ended benchmark of broad academic capabilities. HLE is multi-modal, featuring questions that are either text-only or accompanied by an image reference, and includes both multiple-choice and exact-match questions for automated answer verification. The questions require deep domain knowledge in various verticals; they are unambiguous and resistant to simple internet lookups or database retrieval. For context, several state-of-the-art models (including thinking models) perform poorly on the benchmark (see the results table in this full paper).
Let’s look at an example question from this dataset:
In an alternate universe where the mass of the electron was 1% heavier and the charges of the electron and proton were both 1% smaller, but all other fundamental constants stayed the same, approximately how would the speed of sound in diamond change? Answer Choices: A. Decrease by 2% B. Decrease by 1.5% C. Decrease by 1% D. Decrease by 0.5% E. Stay approximately the same F. Increase by 0.5% G. Increase by 1% H. Increase by 1.5% I. Increase by 2%
The question requires a deep understanding of physics, which most large language models (LLMs) today will fail at. Our goal with prompt optimization on Amazon Bedrock for reasoning models is to reduce the number of thinking tokens but not sacrifice accuracy. After using prompt optimization, the optimized prompt is as follows:
## Question <extracted_question_1>In an alternate universe where the mass of the electron was 1% heavier and the charges of the electron and proton were both 1% smaller, but all other fundamental constants stayed the same, approximately how would the speed of sound in diamond change? Answer Choices: A. Decrease by 2% B. Decrease by 1.5% C. Decrease by 1% D. Decrease by 0.5% E. Stay approximately the same F. Increase by 0.5% G. Increase by 1% H. Increase by 1.5% I. Increase by 2%</extracted_question_1> ## Instruction Read the question above carefully and provide the most accurate answer possible. If multiple choice options are provided within the question, respond with the entire text of the correct answer option, not just the letter or number. Do not include any additional explanations or preamble in your response. Remember, your goal is to answer as precisely and accurately as possible!
The following figure shows how, for this specific case, the number of thinking tokens reduced by 35%, while still getting the final answer correct (B. Decrease by 1.5%). Here, the number of thinking tokens reduced from 5,000 to 3,300. We also notice that in this and other examples with the original prompts, part of the reasoning is summarized or repeated before the final answer. As we can see in this example, the optimized prompt gives clear instructions, separates different prompt sections, and provides additional guidance based on the type of question and how to answer. This leads to both shorter, clearer reasoning traces and a directly extractable final answer.

Optimized prompts can also lead to correct answers as opposed to wrong ones after long-form thinking, because thinking doesn’t guarantee a correct final answer. In this case, we see that the number of thinking tokens reduced from 5,000 to 1,555, and the answer is obtained directly, rather than after another long, post-thinking explanation. The following figure shows an example.

The preceding two examples demonstrate ways in which prompt optimization can improve results while shortening output tokens for models like DeepSeek R1. Prompt optimization was also applied to 400 questions from HLE. The following table summarizes the results.
| Experiment | Overall Accuracy | Average Number of Prompt Tokens | Average Number of Tokens Completion (Thinking + Response) |
Average Number of Tokens (Response Only) |
Average Number of Tokens (Thinking Only) | Percentage of Thinking Completed (6,000 Maximum output Token) |
| Baseline DeepSeek | 8.75 | 288 | 3334 | 271 | 3063 | 80.0% |
| Prompt Optimized DeepSeek | 11 | 326 | 1925 | 27 | 1898 | 90.3% |
As we can see, the overall accuracy jumps to 11% on this subset of the HLE dataset, the number of thinking and output tokens are reduced (therefore reducing the time to last token and cost), and the rate of completing thinking increased to 90% overall. From our experiments, we see that although there is no explicit reference to reducing the thinking tokens, the clearer, more detailed instructions about the task at hand after prompt optimization might reduce the additional effort involved for models like DeepSeek-R1 to do self-clarification or deeper problem understanding. Prompt optimization for reasoning models makes sure that the quality of thinking and overall flow, which is self-adaptive and dependent on the question, is largely unaffected, leading to better final answers.
Conclusion
In this post, we demonstrated how prompt optimization on Amazon Bedrock can effectively enhance the performance of thinking-intensive models like DeepSeek-R1. Through our experiments with the HLE dataset, we showed that optimized prompts not only reduced the number of thinking tokens by a significant margin, but also improved overall accuracy from 8.75% to 11%. The optimization resulted in more efficient reasoning paths without sacrificing the quality of answers, leading to faster response times and lower costs. This improvement in both efficiency and effectiveness suggests that prompt optimization can be a valuable tool for deploying reasoning-heavy models in production environments where both accuracy and computational resources need to be carefully balanced. As the field of AI continues to evolve with more sophisticated thinking models, techniques like prompt optimization will become increasingly important for practical applications.
To get started with prompt optimization on Amazon Bedrock, refer to Optimize a prompt and Improve the performance of your Generative AI applications with Prompt Optimization on Amazon Bedrock.
Appendix
The following is the full response for the question about Nate’s dog:
About the authors
 Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.
 Zhengyuan Shen is an Applied Scientist at Amazon Bedrock, specializing in foundational models and ML modeling for complex tasks including natural language and structured data understanding. He is passionate about leveraging innovative ML solutions to enhance products or services, thereby simplifying the lives of customers through a seamless blend of science and engineering. Outside work, he enjoys sports and cooking.
Zhengyuan Shen is an Applied Scientist at Amazon Bedrock, specializing in foundational models and ML modeling for complex tasks including natural language and structured data understanding. He is passionate about leveraging innovative ML solutions to enhance products or services, thereby simplifying the lives of customers through a seamless blend of science and engineering. Outside work, he enjoys sports and cooking.
 Xuan Qi is an Applied Scientist at Amazon Bedrock, where she applies her background in physics to tackle complex challenges in machine learning and artificial intelligence. Xuan is passionate about translating scientific concepts into practical applications that drive tangible improvements in technology. Her work focuses on creating more intuitive and efficient AI systems that can better understand and interact with the world. Outside of her professional pursuits, Xuan finds balance and creativity through her love for dancing and playing the violin, bringing the precision and harmony of these arts into her scientific endeavors.
Xuan Qi is an Applied Scientist at Amazon Bedrock, where she applies her background in physics to tackle complex challenges in machine learning and artificial intelligence. Xuan is passionate about translating scientific concepts into practical applications that drive tangible improvements in technology. Her work focuses on creating more intuitive and efficient AI systems that can better understand and interact with the world. Outside of her professional pursuits, Xuan finds balance and creativity through her love for dancing and playing the violin, bringing the precision and harmony of these arts into her scientific endeavors.
 Shuai Wang is a Senior Applied Scientist and Manager at Amazon Bedrock, specializing in natural language proceeding, machine learning, large language modeling, and other related AI areas.
Shuai Wang is a Senior Applied Scientist and Manager at Amazon Bedrock, specializing in natural language proceeding, machine learning, large language modeling, and other related AI areas.

Amazon Bedrock announces general availability of multi-agent collaboration
Today, we’re announcing the general availability (GA) of multi-agent collaboration on Amazon Bedrock. This capability allows developers to build, deploy, and manage networks of AI agents that work together to execute complex, multi-step workflows efficiently.
Since its preview launch at re:Invent 2024, organizations across industries—including financial services, healthcare, supply chain and logistics, manufacturing, and customer support—have used multi-agent collaboration to orchestrate specialized agents, driving efficiency, accuracy, and automation. With this GA release, we’ve introduced enhancements based on customer feedback, further improving scalability, observability, and flexibility—making AI-driven workflows easier to manage and optimize.
What is multi-agent collaboration?
Generative AI is no longer just about models generating responses, it’s about automation. The next wave of innovation is driven by agents that can reason, plan, and act autonomously across company systems. Generative AI applications are no longer just generating content; they also take action, solve problems, and execute complex workflows. The shift is clear: businesses need AI that doesn’t just respond to prompts but orchestrates entire workflows, automating processes end to end.
Agents enable generative AI applications to perform tasks across company systems and data sources, and Amazon Bedrock already simplifies building them. With Amazon Bedrock, customers can quickly create agents that handle sales orders, compile financial reports, analyze customer retention, and much more. However, as applications become more capable, the tasks customers want them to perform can exceed what a single agent can manage—either because the tasks require specialized expertise, involve multiple steps, or demand continuous execution over time.
Coordinating potentially hundreds of agents at scale is also challenging, because managing dependencies, ensuring efficient task distribution, and maintaining performance across a large network of specialized agents requires sophisticated orchestration. Without the right tools, businesses can face inefficiencies, increased latency, and difficulties in monitoring and optimizing performance. For customers looking to advance their agents and tackle more intricate, multi-step workflows, Amazon Bedrock supports multi-agent collaboration, enabling developers to easily build, deploy, and manage multiple specialized agents working together seamlessly.
Multi-agent collaboration enables developers to create networks of specialized agents that communicate and coordinate under the guidance of a supervisor agent. Each agent contributes its expertise to the larger workflow by focusing on a specific task. This approach breaks down complex processes into manageable sub-tasks processed in parallel. By facilitating seamless interaction among agents, Amazon Bedrock enhances operational efficiency and accuracy, ensuring workflows run more effectively at scale. Because each agent only accesses the data required for its role, this approach minimizes exposure of sensitive information while reinforcing security and governance. This allows businesses to scale their AI-driven workflows without the need for manual intervention in coordinating agents. As more agents are added, the supervisor ensures smooth collaboration between them all.
By using multi-agent collaboration on Amazon Bedrock, organizations can:
- Streamline AI-driven workflows by distributing workloads across specialized agents.
- Improve execution efficiency by parallelizing tasks where possible.
- Enhance security and governance by restricting agent access to only necessary data.
- Reduce operational complexity by eliminating manual intervention in agent coordination.
A key challenge in building effective multi-agent collaboration systems is managing the complexity and overhead of coordinating multiple specialized agents at scale. Amazon Bedrock simplifies the process of building, deploying, and orchestrating effective multi-agent collaboration systems while addressing efficiency challenges through several key features and optimizations:
- Quick setup – Create, deploy, and manage AI agents working together in minutes without the need for complex coding.
- Composability – Integrate your existing agents as subagents within a larger agent system, allowing them to seamlessly work together to tackle complex workflows.
- Efficient inter-agent communication – The supervisor agent can interact with subagents using a consistent interface, supporting parallel communication for more efficient task completion.
- Optimized collaboration modes – Choose between supervisor mode and supervisor with routing mode. With routing mode, the supervisor agent will route simple requests directly to specialized subagents, bypassing full orchestration. For complex queries or when no clear intention is detected, it automatically falls back to the full supervisor mode, where the supervisor agent analyzes, breaks down problems, and coordinates multiple subagents as needed.
- Integrated trace and debug console – Visualize and analyze multi-agent interactions behind the scenes using the integrated trace and debug console.
What’s new in general availability?
The GA release introduces several key enhancements based on customer feedback, making multi-agent collaboration more scalable, flexible, and efficient:
- Inline agent support – Enables the creation of supervisor agents dynamically at runtime, allowing for more flexible agent management without predefined structures.
- AWS CloudFormation and AWS Cloud Development Kit (AWS CDK) support – Enables customers to deploy agent networks as code, enabling scalable, reusable agent templates across AWS accounts.
- Enhanced traceability and debugging – Provides structured execution logs, sub-step tracking, and Amazon CloudWatch integration to improve monitoring and troubleshooting.
- Increased collaborator and step count limits – Expands self-service limits for agent collaborators and execution steps, supporting larger-scale workflows.
- Payload referencing – Reduces latency and costs by allowing the supervisor agent to reference external data sources without embedding them in the agent request.
- Improved citation handling – Enhances accuracy and attribution when agents pull external data sources into their responses.
These features collectively improve coordination capabilities, communication speed, and overall effectiveness of the multi-agent collaboration framework in tackling complex, real-world problems.
Multi-agent collaboration across industries
Multi-agent collaboration is already transforming AI automation across sectors:
- Investment advisory – A financial firm uses multiple agents to analyze market trends, risk factors, and investment opportunities to deliver personalized client recommendations.
- Retail operations – A retailer deploys agents for demand forecasting, inventory tracking, pricing optimization, and order fulfillment to increase operational efficiency.
- Fraud detection – A banking institution assigns agents to monitor transactions, detect anomalies, validate customer behaviors, and flag potential fraud risks in real time.
- Customer support – An enterprise customer service platform uses agents for sentiment analysis, ticket classification, knowledge base retrieval, and automated responses to enhance resolution times.
- Healthcare diagnosis – A hospital system integrates agents for patient record analysis, symptom recognition, medical imaging review, and treatment plan recommendations to assist clinicians.
Deep dive: Syngenta’s use of multi-agent collaboration
Syngenta, a global leader in agricultural innovation, has integrated cutting-edge generative AI into its Cropwise service, resulting in the development of Cropwise AI. This advanced system is designed to enhance the efficiency of agronomic advisors and growers by providing tailored recommendations for crop management practices.
Business challenge
The agricultural sector faces the complex task of optimizing crop yields while ensuring sustainability and profitability. Farmers and agronomic advisors must consider a multitude of factors, including weather patterns, soil conditions, crop growth stages, and potential pest and disease threats. In the past, analyzing these variables required extensive manual effort and expertise. Syngenta recognized the need for a more efficient, data-driven approach to support decision-making in crop management.
Solution: Cropwise AI
To address these challenges, Syngenta collaborated with AWS to develop Cropwise AI, using Amazon Bedrock Agents to create a multi-agent system that integrates various data sources and AI capabilities. This system offers several key features:
- Advanced seed recommendation and placement – Uses predictive machine learning algorithms to deliver personalized seed recommendations tailored to each grower’s unique environment.
- Sophisticated predictive modeling – Employs state-of-the-art machine learning algorithms to forecast crop growth patterns, yield potential, and potential risk factors by integrating real-time data with comprehensive historical information.
- Precision agriculture optimization – Provides hyper-localized, site-specific recommendations for input application, minimizing waste and maximizing resource efficiency.
Agent architecture
Cropwise AI is built on AWS architecture and designed for scalability, maintainability, and security. The system uses Amazon Bedrock Agents to orchestrate multiple AI agents, each specializing in distinct tasks:
- Data aggregation agent – Collects and integrates extensive datasets, including over 20 years of weather history, soil conditions, and more than 80,000 observations on crop growth stages.
- Recommendation agent – Analyzes the aggregated data to provide tailored recommendations for precise input applications, product placement, and strategies for pest and disease control.
- Conversational AI agent – Uses a multilingual conversational large language model (LLM) to interact with users in natural language, delivering insights in a clear format.
This multi-agent collaboration enables Cropwise AI to process complex agricultural data efficiently, offering actionable insights and personalized recommendations to enhance crop yields, sustainability, and profitability.
Results
By implementing Cropwise AI, Syngenta has achieved significant improvements in agricultural practices:
- Enhanced decision-making: Agronomic advisors and growers receive data-driven recommendations, leading to optimized crop management strategies.
- Increased yields: Utilizing Syngenta’s seed recommendation models, Cropwise AI helps growers increase yields by up to 5%.
- Sustainable practices: The system promotes precision agriculture, reducing waste and minimizing environmental impact through optimized input applications.
Highlighting the significance of this advancement, Feroz Sheikh, Chief Information and Digital Officer at Syngenta Group, stated:
“Agricultural innovation leader Syngenta is using Amazon Bedrock Agents as part of its Cropwise AI solution, which gives growers deep insights to help them optimize crop yields, improve sustainability, and drive profitability. With multi-agent collaboration, Syngenta will be able to use multiple agents to further improve their recommendations to growers, transforming how their end-users make decisions and delivering even greater value to the farming community.”
This collaboration between Syngenta and AWS exemplifies the transformative potential of generative AI and multi-agent systems in agriculture, driving innovation and supporting sustainable farming practices.
How multi-agent collaboration works
Amazon Bedrock automates agent collaboration, including task delegation, execution tracking, and data orchestration. Developers can configure their system in one of two collaboration modes:
- Supervisor mode
- The supervisor agent receives an input, breaks down complex requests, and assigns tasks to specialized sub-agents.
- Sub-agents execute tasks in parallel or sequentially, returning responses to the supervisor, which consolidates the results.
- Supervisor with routing mode
- Simple queries are routed directly to a relevant sub-agent.
- Complex or ambiguous requests trigger the supervisor to coordinate multiple agents to complete the task.
Watch the Amazon Bedrock multi-agent collaboration video to learn how to get started.
Conclusion
By enabling seamless multi-agent collaboration, Amazon Bedrock empowers businesses to scale their generative AI applications with greater efficiency, accuracy, and flexibility. As organizations continue to push the boundaries of AI-driven automation, having the right tools to orchestrate complex workflows will be essential. With Amazon Bedrock, companies can confidently build AI systems that don’t just generate responses but drive real impact—automating processes, solving problems, and unlocking new possibilities across industries.
Amazon Bedrock multi-agent collaboration is now generally available.
- Learn more: Automate tasks in your application using AI agents
- Code samples: Amazon Bedrock agent samples on GitHub
- Try it out today in the AWS Management Console for Amazon Bedrock.
Multi-agent collaboration opens new possibilities for AI-driven automation. Whether in finance, healthcare, retail, or agriculture, Amazon Bedrock helps organizations scale AI workflows with efficiency and precision.
Start building today—and let us know what you create!
About the authors
 Sri Koneru has spent the last 13.5 years honing her skills in both cutting-edge product development and large-scale infrastructure. At Salesforce for 7.5 years, she had the incredible opportunity to build and launch brand new products from the ground up, reaching over 100,000 external customers. This experience was instrumental in her professional growth. Then, at Google for 6 years, she transitioned to managing critical infrastructure, overseeing capacity, efficiency, fungibility, job scheduling, data platforms, and spatial flexibility for all of Alphabet. Most recently, Sri joined Amazon Web Services leveraging her diverse skillset to make a significant impact on AI/ML services and infrastructure at AWS. Personally, Sri & her husband recently became empty nesters, relocating to Seattle from the Bay Area. They’re a basketball-loving family who even catch pre-season Warriors games but are looking forward to cheering on the Seattle Storm this year. Beyond basketball, Sri enjoys cooking, recipe creation, reading, and her newfound hobby of hiking. While she’s a sun-seeker at heart, she is looking forward to experiencing the unique character of Seattle weather.
Sri Koneru has spent the last 13.5 years honing her skills in both cutting-edge product development and large-scale infrastructure. At Salesforce for 7.5 years, she had the incredible opportunity to build and launch brand new products from the ground up, reaching over 100,000 external customers. This experience was instrumental in her professional growth. Then, at Google for 6 years, she transitioned to managing critical infrastructure, overseeing capacity, efficiency, fungibility, job scheduling, data platforms, and spatial flexibility for all of Alphabet. Most recently, Sri joined Amazon Web Services leveraging her diverse skillset to make a significant impact on AI/ML services and infrastructure at AWS. Personally, Sri & her husband recently became empty nesters, relocating to Seattle from the Bay Area. They’re a basketball-loving family who even catch pre-season Warriors games but are looking forward to cheering on the Seattle Storm this year. Beyond basketball, Sri enjoys cooking, recipe creation, reading, and her newfound hobby of hiking. While she’s a sun-seeker at heart, she is looking forward to experiencing the unique character of Seattle weather.

Utah to Advance AI Education, Training
A new AI education initiative in the State of Utah, developed in collaboration with NVIDIA, is set to advance the state’s commitment to workforce training and economic growth.
The public-private partnership aims to equip universities, community colleges and adult education programs across Utah with the resources to develop skills in generative AI.
“AI will continue to grow in importance, affecting every sector of Utah’s economy,” said Spencer Cox, governor of Utah. “We need to prepare our students and faculty for this revolution. Working with NVIDIA is an ideal path to help ensure that Utah is positioned for AI growth in the near and long term.”
As part of the new initiative, Utah’s educators can gain certification through the NVIDIA Deep Learning Institute University Ambassador Program. The program offers high-quality teaching kits, extensive workshop content and access to NVIDIA GPU-accelerated workstations in the cloud.
By empowering educators with the latest AI skills and technologies, the initiative seeks to create a competitive advantage for Utah’s entire higher education system.
“We believe that AI education is more than a pathway to innovation — it’s a foundation for solving some of the world’s most pressing challenges,” said Manish Parashar, director of the University of Utah Scientific Computing and Imaging (SCI) Institute, which leads the One-U Responsible AI Initiative. “By equipping students and researchers with the tools to explore, understand and create with AI, we empower them to be able to drive advancements in medicine, engineering and beyond.”
The initiative will begin with the Utah System of Higher Education (USHE) and several other universities in the state, including the University of Utah, Utah State University, Utah Valley University, Weber State University, Utah Tech University, Southern Utah University, Snow College and Salt Lake Community College.
Setting Up Students and Professionals for Success
The Utah AI education initiative will benefit students entering the job market and working professionals by helping them expand their skill sets beyond community college or adult education courses.
Utah state agencies are exploring how internship and apprenticeship programs can offer students hands-on experience with AI skills, helping bridge the gap between education and industry needs. This initiative aligns with Utah’s broader goals of fostering a tech-savvy workforce and positioning the state as a leader in AI innovation and application.
As AI continues to evolve and gain prevalence across industries, Utah’s proactive approach to equipping educators and students with resources and training will help prepare its workforce for the future of technology, sharpening its competitive edge.
Semantic Telemetry: Understanding how users interact with AI systems
AI tools are proving useful across a range of applications, from helping to drive the new era of business transformation to helping artists craft songs. But which applications are providing the most value to users? We’ll dig into that question in a series of blog posts that introduce the Semantic Telemetry project at Microsoft Research. In this initial post, we will introduce a new data science approach that we will use to analyze topics and task complexity of Copilot in Bing usage.
Human-AI interactions can be iterative and complex, requiring a new data science approach to understand user behavior to build and support increasingly high value use cases. Imagine the following chat:

Here we see that chats can be complex and span multiple topics, such as event planning, team building, and logistics. Generative AI has ushered in a two-fold paradigm shift. First, LLMs give us a new thing to measure, that is, how people interact with AI systems. Second, they give us a new way to measure those interactions, that is, they give us the capability to understand and make inferences on these interactions, at scale. The Semantic Telemetry project has created new measures to classify human-AI interactions and understand user behavior, contributing to efforts in developing new approaches for measuring generative AI (opens in new tab) across various use cases.
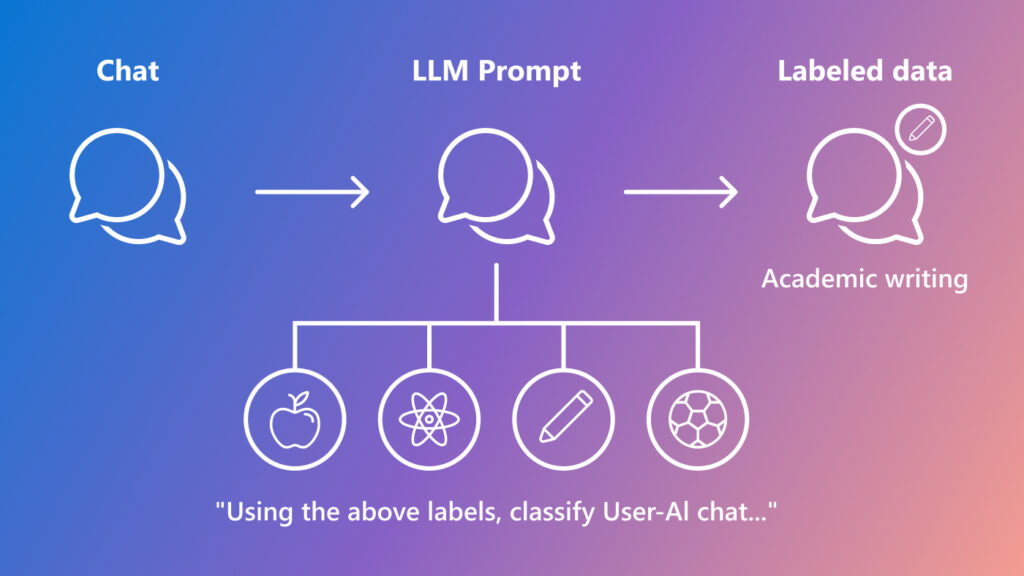
Semantic Telemetry is a rethink of traditional telemetry–in which data is collected for understanding systems–designed for analyzing chat-based AI. We employ an innovative data science methodology that uses a large language model (LLM) to generate meaningful categorical labels, enabling us to gain insights into chat log data.
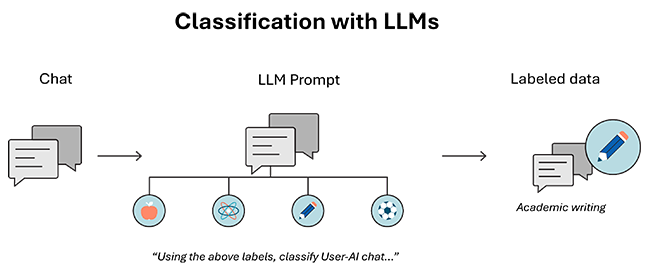
This process begins with developing a set of classifications and definitions. We create these classifications by instructing an LLM to generate a short summary of the conversation, and then iteratively prompting the LLM to generate, update, and review classification labels on a batched set of summaries. This process is outlined in the paper: TnT-LLM: Text Mining at Scale with Large Language Models. We then prompt an LLM with these generated classifiers to label new unstructured (and unlabeled) chat log data.
With this approach, we have analyzed how people interact with Copilot in Bing. In this blog, we examine insights into how people are using Copilot in Bing, including how that differs from traditional search engines. Note that all analyses were conducted on anonymous Copilot interactions containing no personal information.
Topics
To get a clear picture of how people are using Copilot in Bing, we need to first classify sessions into topical categories. To do this, we developed a topic classifier. We used the LLM classification approach described above to label the primary topic (domain) for the entire content of the chat. Although a single chat can cover multiple topics, for this analysis, we generated a single label for the primary topic of the conversation. We sampled five million anonymized Copilot in Bing chats during August and September 2024, and found that globally, 21% of all chats were about technology, with a high concentration of these chats in programming and scripting and computers and electronics.
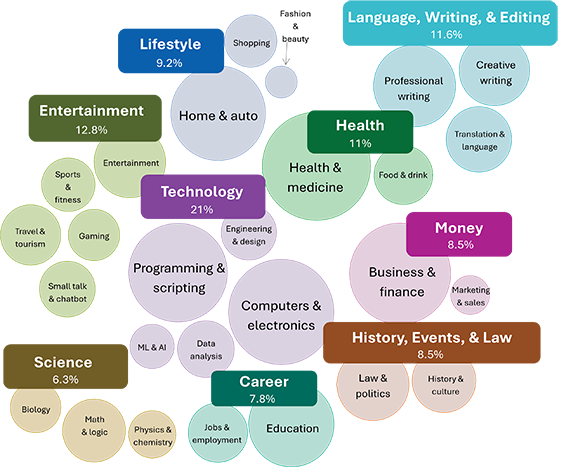
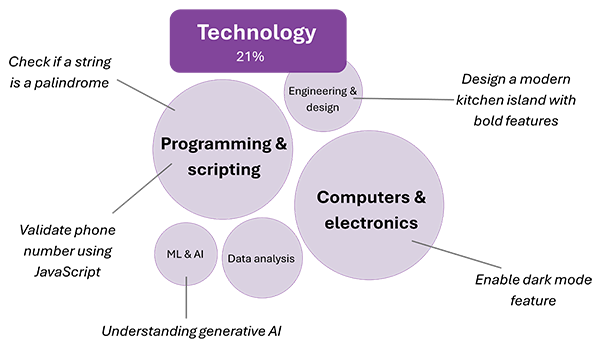
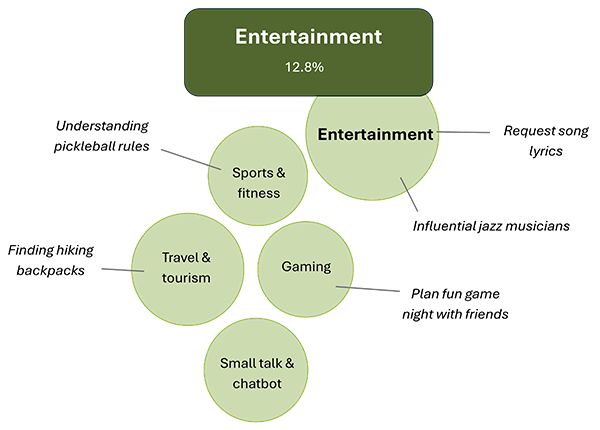
Diving into the technology category, we find a lot of professional tasks in programming and scripting, where users request problem-specific assistance such as fixing a SQL query syntax error. In computers and electronics, we observe users getting help with tasks like adjusting screen brightness and troubleshooting internet connectivity issues. We can compare this with our second most common topic, entertainment, in which we see users seeking information related to personal activities like hiking and game nights.
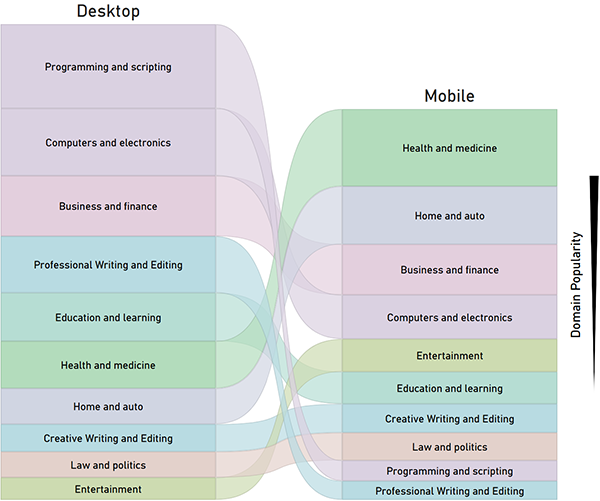
We also note that top topics differ by platform. The figure below depicts topic popularity based on mobile and desktop usage. Mobile device users tend to use the chat for more personal-related tasks such as helping to plant a garden or understanding medical symptoms whereas desktop users conduct more professional tasks like revising an email.
Microsoft research blog

PromptWizard: The future of prompt optimization through feedback-driven self-evolving prompts
PromptWizard from Microsoft Research is now open source. It is designed to automate and simplify AI prompt optimization, combining iterative LLM feedback with efficient exploration and refinement techniques to create highly effective prompts in minutes.
Search versus Copilot
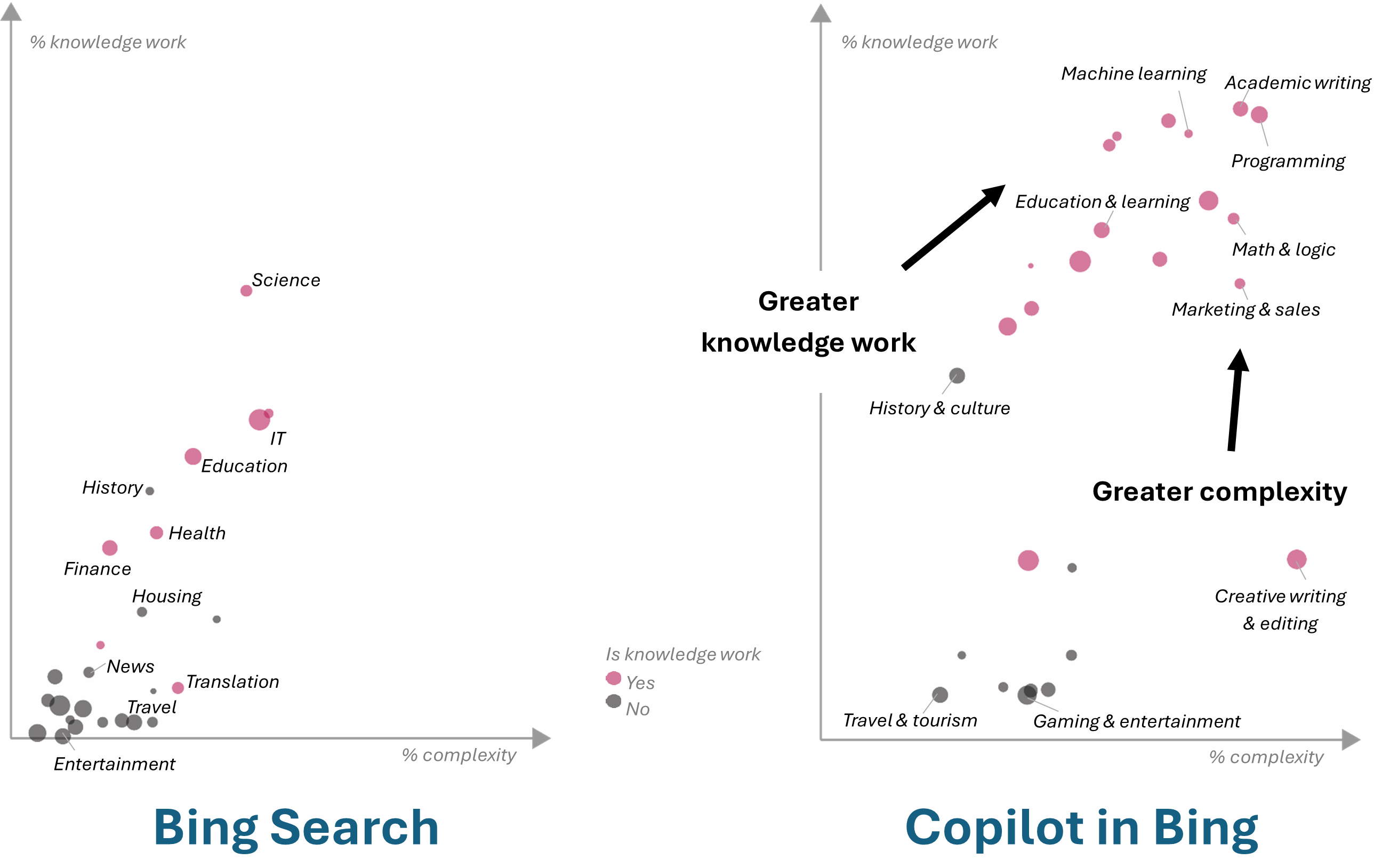
Beyond analyzing topics, we compared Copilot in Bing usage to that of traditional search. Chat extends beyond traditional online search by enabling users to summarize, generate, compare, and analyze information. Human-AI interactions are conversational and more complex than traditional search (Figure 6).
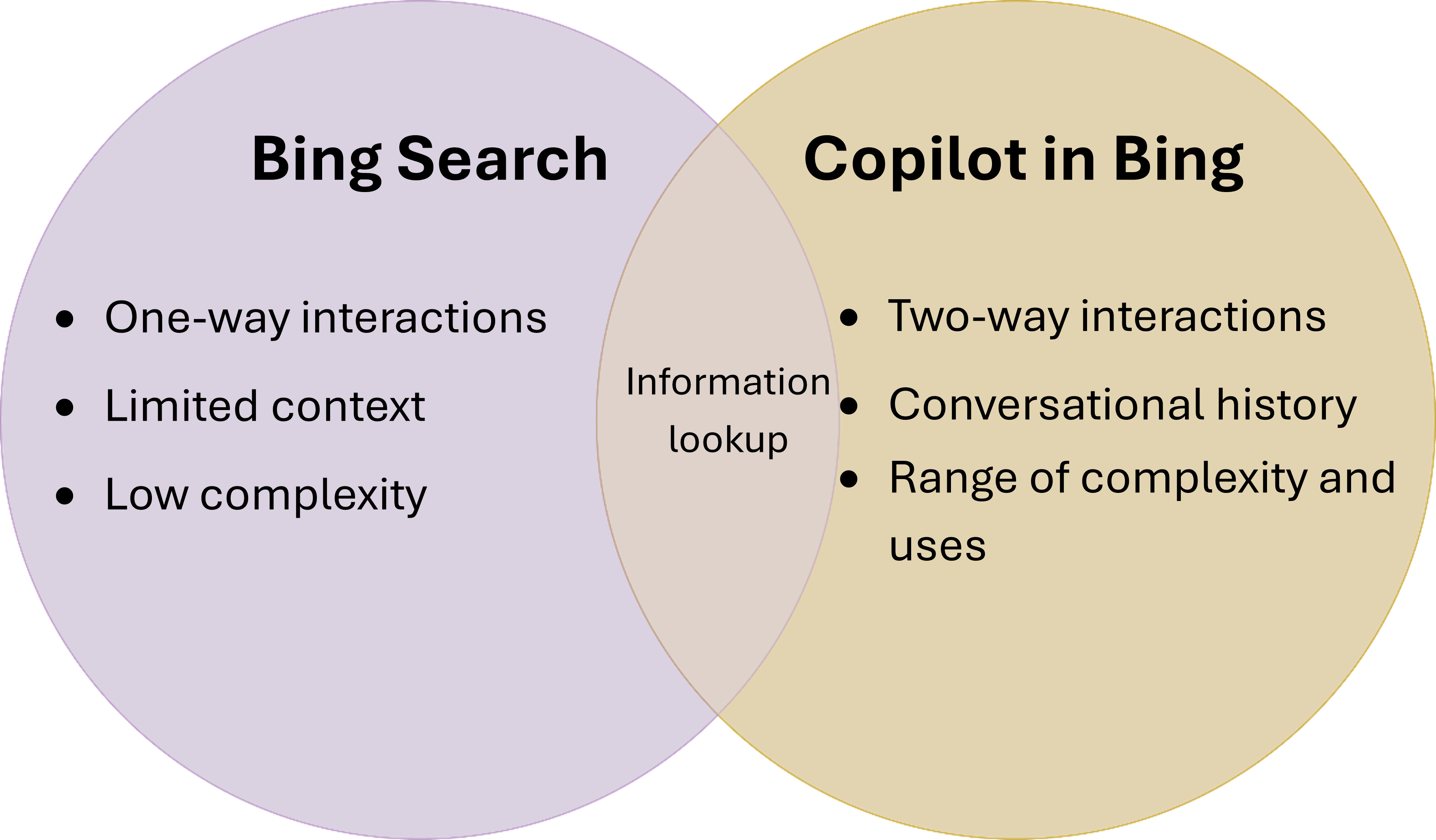
A major differentiation between search and chat is the ability to ask more complex questions, but how can we measure this? We think of complexity as a scale ranging from simply asking chat to look up information to evaluating several ideas. We aim to understand the difficulty of a task if performed by a human without the assistance of AI. To achieve this, we developed the task complexity classifier, which assesses task difficulty using Anderson and Krathwohl’s Taxonomy of Learning Objectives (opens in new tab). For our analysis, we have grouped the learning objectives into two categories: low complexity and high complexity. Any task more complicated than information lookup is classified as high complexity. Note that this would be very challenging to classify using traditional data science techniques.
Comparing low versus high complexity tasks, most chat interactions were categorized as high complexity (78.9%), meaning that they were more complex than looking up information. Programming and scripting, marketing and sales, and creative and professional writing are topics in which users engage in higher complexity tasks (Figure 7) such as learning a skill, troubleshooting a problem, or writing an article.
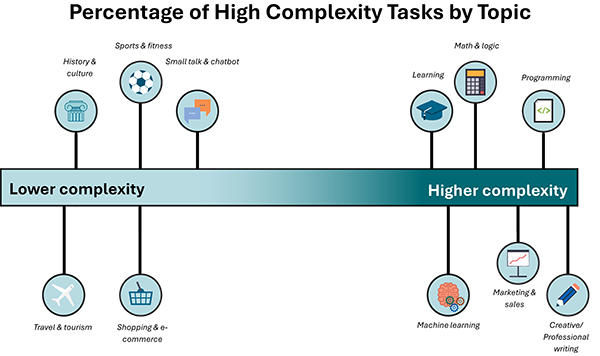
Travel and tourism and history and culture scored lowest in complexity, with users looking up information like flights time and latest news updates.
When should you use chat instead of search? A 2024 Microsoft Research study: The Use of Generative Search Engines for Knowledge Work and Complex Tasks, suggests that people are seeing value in technical, complex tasks such as web development and data analysis. Bing Search contained more queries with lower complexity focused on non-professional areas, like gaming and entertainment, travel and tourism, and fashion and beauty, while chat had a greater distribution of complex technical tasks. (Figure 8).
Conclusion
LLMs have enabled a new era of high-quality human-AI interaction, and with it, the capability to analyze those same interactions with high fidelity, at scale, and near real-time. We are now able to obtain actionable insight from complex data that is not possible with traditional data science pattern-matching methods. LLM-generated classifications are pushing research into new directions that will ultimately improve user experience and satisfaction when using chat and other user-AI interactions tools.
This analysis indicates that Copilot in Bing is enabling users to do more complex work, specifically in areas such as technology. In our next post, we will explore how Copilot in Bing is supporting professional knowledge work and how we can use these measures as indicators for retention and engagement.
FOOTNOTE: This research was conducted at the time the feature Copilot in Bing was available as part of the Bing service; since October 2024 Copilot in Bing has been deprecated in favor of the standalone Microsoft Copilot service.
References:
- Krathwohl, D. R. (2002). A Revision of Bloom’s Taxonomy: An Overview. Theory Into Practice, 41(4), 212–218. https://doi.org/10.1207/s15430421tip4104_2 (opens in new tab)
The post Semantic Telemetry: Understanding how users interact with AI systems appeared first on Microsoft Research.
Amazon Nova AI Challenge accelerating the field of generative AI
Inaugural global university competition focused on advancing secure, trusted AI-assisted software development.Read More
When Does a Predictor Know Its Own Loss?
Given a predictor and a loss function, how well can we predict the loss that the predictor will incur on an input? This is the problem of loss prediction, a key computational task associated with uncertainty estimation for a predictor. In a classification setting, a predictor will typically predict a distribution over labels and hence have its own estimate of the loss that it will incur, given by the entropy of the predicted distribution. Should we trust this estimate? In other words, when does the predictor know what it knows and what it does not know?
In this work we study the theoretical…Apple Machine Learning Research
Accelerating insurance policy reviews with generative AI: Verisk’s Mozart companion
This post is co-authored with Sundeep Sardana, Malolan Raman, Joseph Lam, Maitri Shah and Vaibhav Singh from Verisk.
Verisk (Nasdaq: VRSK) is a leading strategic data analytics and technology partner to the global insurance industry, empowering clients to strengthen operating efficiency, improve underwriting and claims outcomes, combat fraud, and make informed decisions about global risks. Through advanced data analytics, software, scientific research, and deep industry knowledge, Verisk helps build global resilience across individuals, communities, and businesses. At the forefront of using generative AI in the insurance industry, Verisk’s generative AI-powered solutions, like Mozart, remain rooted in ethical and responsible AI use. Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
The generative AI-powered Mozart companion uses sophisticated AI to compare legal policy documents and provides essential distinctions between them in a digestible and structured format. The new Mozart companion is built using Amazon Bedrock. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. The Mozart application rapidly compares policy documents and presents comprehensive change details, such as descriptions, locations, excerpts, in a tracked change format.
The following screenshot shows an example of the output of the Mozart companion displaying the summary of changes between two legal documents, the excerpt from the original document version, the updated excerpt in the new document version, and the tracked changes represented with redlines.

In this post, we describe the development journey of the generative AI companion for Mozart, the data, the architecture, and the evaluation of the pipeline.
Data: Policy forms
Mozart is designed to author policy forms like coverage and endorsements. These documents provide information about policy coverage and exclusions (as shown in the following screenshot) and help in determining the risk and premium associated with an insurance policy.

Solution overview
The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage. An AWS Batch job reads these documents, chunks them into smaller slices, then creates embeddings of the text chunks using the Amazon Titan Text Embeddings model through Amazon Bedrock and stores them in an Amazon OpenSearch Service vector database. Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. This process has been implemented as a periodic job to keep the vector database updated with new documents. During the solution design process, Verisk also considered using Amazon Bedrock Knowledge Bases because it’s purpose built for creating and storing embeddings within Amazon OpenSearch Serverless. In the future, Verisk intends to use the Amazon Titan Embeddings V2 model.
The user can pick the two documents that they want to compare. This action invokes an AWS Lambda function to retrieve the document embeddings from the OpenSearch Service database and present them to Anthropic’s Claude 3 Sonnet FM, which is accessed through Amazon Bedrock. The results are stored in a JSON structure and provided using the API service to the UI for consumption by the end-user.
The following diagram illustrates the solution architecture.

Security and governance
Generative AI is very new technology and brings with it new challenges related to security and compliance. Verisk has a governance council that reviews generative AI solutions to make sure that they meet Verisk’s standards of security, compliance, and data use. Verisk also has a legal review for IP protection and compliance within their contracts. It’s important that Verisk makes sure the data that is shared by the FM is transmitted securely and the FM doesn’t retain any of their data or use it for its own training. The quality of the solution, speed, cost, and ease of use were the key factors that led Verisk to pick Amazon Bedrock and Anthropic’s Claude Sonnet within their generative AI solution.
Evaluation criteria
To assess the quality of the results produced by generative AI, Verisk evaluated based on the following criteria:
- Accuracy
- Consistency
- Adherence to context
- Speed and cost
To assess the generative AI results’ accuracy and consistency, Verisk designed human evaluation metrics with the help of in-house insurance domain experts. Verisk conducted multiple rounds of human evaluation of the generated results. During these tests, in-house domain experts would grade accuracy, consistency, and adherence to context on a manual grading scale of 1–10. The Verisk team measured how long it took to generate the results by tracking latency. Feedback from each round of tests was incorporated in subsequent tests.
The initial results that Verisk got from the model were good but not close to the desired level of accuracy and consistency. The development process underwent iterative improvements that included redesign, making multiple calls to the FM, and testing various FMs. The primary metric used to evaluate the success of FM and non-FM solutions was a manual grading system where business experts would grade results and compare them. FM solutions are improving rapidly, but to achieve the desired level of accuracy, Verisk’s generative AI software solution needed to contain more components than just FMs. To achieve the desired accuracy, consistency, and efficiency, Verisk employed various techniques beyond just using FMs, including prompt engineering, retrieval augmented generation, and system design optimizations.
Prompt optimization
The change summary is different than showing differences in text between the two documents. The Mozart application needs to be able to describe the material changes and ignore the noise from non-meaningful changes. Verisk created prompts using the knowledge of their in-house domain experts to achieve these objectives. With each round of testing, Verisk added detailed instructions to the prompts to capture the pertinent information and reduce possible noise and hallucinations. The added instructions would be focused on reducing any issues identified by the business experts reviewing the end results. To get the best results, Verisk needed to adjust the prompts based on the FM used—there are differences in how each FM responds to prompts, and using the prompts specific to the given FM provides better results. Through this process, Verisk instructed the model on the role it is playing along with the definition of common terms and exclusions. In addition to optimizing prompts for the FMs, Verisk also explored techniques for effectively splitting and processing the document text itself.
Splitting document pages
Verisk tested multiple strategies for document splitting. For this use case, a recursive character text splitter with a chunk size of 500 characters with 15% overlap provided the best results. This splitter is part of the LangChain framework; it’s a semantic splitter that considers semantic similarities in the text. Verisk also considered the NLTK splitter. With an effective approach for splitting the document text into processable chunks, Verisk then focused on enhancing the quality and relevance of the summarized output.
Quality of summary
The quality assessment starts with confirming that the correct documents are picked for comparison. Verisk enhanced the quality of the solution by using document metadata to narrow the search results by specifying which documents to include or exclude from a query, resulting in more relevant responses generated by the FM. For the generative AI description of change, Verisk wanted to capture the essence of the change instead of merely highlighting the differences. The results were reviewed by their in-house policy authoring experts and their feedback was used to determine the prompts, document splitting strategy, and FM. With techniques in place to enhance output quality and relevance, Verisk also prioritized optimizing the performance and cost-efficiency of their generative AI solution. These techniques were specific to prompt engineering; some examples are few-shot prompting, chain of thought prompting, and the needle in a haystack approach.
Price-performance
To achieve lower cost, Verisk regularly evaluated various FM options and changed them as new options with lower cost and better performance were released. During the development process, Verisk redesigned the solution to reduce the number of calls to the FM and wherever possible used non-FM based options.
As mentioned earlier, the overall solution consists of a few different components:
- Location of the change
- Excerpts of the changes
- Change summary
- Changes shown in the tracked change format
Verisk reduced the FM load and improved accuracy by identifying the sections that contained differences and then passing these sections to the FM to generate the change summary. For constructing the tracked difference format, containing redlines, Verisk used a non-FM based solution. In addition to optimizing performance and cost, Verisk also focused on developing a modular, reusable architecture for their generative AI solution.
Reusability
Good software development practices apply to the development of generative AI solutions too. You can create a decoupled architecture with reusable components. The Mozart generative AI companion is provided as an API, which decouples it from the frontend development and allows for reusability of this capability. Similarly, the API consists of many reusable components like common prompts, common definitions, retrieval service, embedding creation, and persistence service. Through their modular, reusable design approach and iterative optimization process, Verisk was able to achieve highly satisfactory results with their generative AI solution.
Results
Based on Verisk’s evaluation template questions and rounds of testing, they concluded that the results generated over 90% good or acceptable summaries. Testing was done by providing results of the solution to business experts, and having these experts grade the results using a grading scale.
Business impact
Verisk’s customers spend significant time regularly to review changes to the policy forms. The generative AI-powered Mozart companion can simplify the review process by ingesting these complex and unstructured policy documents and providing a summary of changes in minutes. This enables Verisk’s customers to cut the change adoption time from days to minutes. The improved adoption speed not only increases productivity, but also enable timely implementation of changes.
Conclusion
Verisk’s generative AI-powered Mozart companion uses advanced natural language processing and prompt engineering techniques to provide rapid and accurate summaries of changes between insurance policy documents. By harnessing the power of large language models like Anthropic’s Claude 3 Sonnet while incorporating domain expertise, Verisk has developed a solution that significantly accelerates the policy review process for their customers, reducing change adoption time from days or weeks to just minutes. This innovative application of generative AI delivers tangible productivity gains and operational efficiencies to the insurance industry. With a strong governance framework promoting responsible AI use, Verisk is at the forefront of unlocking generative AI’s potential to transform workflows and drive resilience across the global risk landscape.
For more information, see the following resources:
- Explore generative AI on AWS
- Learn about unlocking the business value of generative AI
- Learn more about Anthropic’s Claude 3 models on Amazon Bedrock
- Learn about Amazon Bedrock and how to build and scale generative AI applications with FMs
- Explore other use cases for generative AI with Amazon Bedrock
About the Authors
 Sundeep Sardana is the Vice President of Software Engineering at Verisk Analytics, based in New Jersey. He leads the Reimagine program for the company’s Rating business, driving modernization across core services such as forms, rules, and loss costs. A dynamic change-maker and technologist, Sundeep specializes in building high-performing teams, fostering a culture of innovation, and leveraging emerging technologies to deliver scalable, enterprise-grade solutions. His expertise spans cloud computing, Generative AI, software architecture, and agile development, ensuring organizations stay ahead in an evolving digital landscape. Connect with him on LinkedIn.
Sundeep Sardana is the Vice President of Software Engineering at Verisk Analytics, based in New Jersey. He leads the Reimagine program for the company’s Rating business, driving modernization across core services such as forms, rules, and loss costs. A dynamic change-maker and technologist, Sundeep specializes in building high-performing teams, fostering a culture of innovation, and leveraging emerging technologies to deliver scalable, enterprise-grade solutions. His expertise spans cloud computing, Generative AI, software architecture, and agile development, ensuring organizations stay ahead in an evolving digital landscape. Connect with him on LinkedIn.
 Malolan Raman is a Principal Engineer at Verisk, based out of New Jersey specializing in the development of Generative AI (GenAI) applications. With extensive experience in cloud computing and artificial intelligence, He has been at the forefront of integrating cutting-edge AI technologies into scalable, secure, and efficient cloud solutions.
Malolan Raman is a Principal Engineer at Verisk, based out of New Jersey specializing in the development of Generative AI (GenAI) applications. With extensive experience in cloud computing and artificial intelligence, He has been at the forefront of integrating cutting-edge AI technologies into scalable, secure, and efficient cloud solutions.
 Joseph Lam is the senior director of commercial multi-lines that include general liability, umbrella/excess, commercial property, businessowners, capital assets, crime and inland marine. He leads a team responsible for research, development, and support of commercial casualty products, which mostly consist of forms and rules. The team is also tasked with supporting new and innovative solutions for the emerging marketplace.
Joseph Lam is the senior director of commercial multi-lines that include general liability, umbrella/excess, commercial property, businessowners, capital assets, crime and inland marine. He leads a team responsible for research, development, and support of commercial casualty products, which mostly consist of forms and rules. The team is also tasked with supporting new and innovative solutions for the emerging marketplace.
 Maitri Shah is a Software Development Engineer at Verisk with over two years of experience specializing in developing innovative solutions in Generative AI (GenAI) on Amazon Web Services (AWS). With a strong foundation in machine learning, cloud computing, and software engineering, Maitri has successfully implemented scalable AI models that drive business value and enhance user experiences.
Maitri Shah is a Software Development Engineer at Verisk with over two years of experience specializing in developing innovative solutions in Generative AI (GenAI) on Amazon Web Services (AWS). With a strong foundation in machine learning, cloud computing, and software engineering, Maitri has successfully implemented scalable AI models that drive business value and enhance user experiences.
 Vaibhav Singh is a Product Innovation Analyst at Verisk, based out of New Jersey. With a background in Data Science, engineering, and management, he works as a pivotal liaison between technology and business, enabling both sides to build transformative products & solutions that tackle some of the current most significant challenges in the insurance domain. He is driven by his passion for leveraging data and technology to build innovative products that not only address the current obstacles but also pave the way for future advancements in that domain.
Vaibhav Singh is a Product Innovation Analyst at Verisk, based out of New Jersey. With a background in Data Science, engineering, and management, he works as a pivotal liaison between technology and business, enabling both sides to build transformative products & solutions that tackle some of the current most significant challenges in the insurance domain. He is driven by his passion for leveraging data and technology to build innovative products that not only address the current obstacles but also pave the way for future advancements in that domain.
 Ryan Doty is a Solutions Architect Manager at AWS, based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
Ryan Doty is a Solutions Architect Manager at AWS, based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
 Tarik Makota is a Sr. Principal Solutions Architect with Amazon Web Services. He provides technical guidance, design advice, and thought leadership to AWS’ customers across the US Northeast. He holds an M.S. in Software Development and Management from Rochester Institute of Technology.
Tarik Makota is a Sr. Principal Solutions Architect with Amazon Web Services. He provides technical guidance, design advice, and thought leadership to AWS’ customers across the US Northeast. He holds an M.S. in Software Development and Management from Rochester Institute of Technology.
 Alex Oppenheim is a Senior Sales Leader at Amazon Web Services, supporting consulting and services customers. With extensive experience in the cloud and technology industry, Alex is passionate about helping enterprises unlock the power of AWS to drive innovation and digital transformation.
Alex Oppenheim is a Senior Sales Leader at Amazon Web Services, supporting consulting and services customers. With extensive experience in the cloud and technology industry, Alex is passionate about helping enterprises unlock the power of AWS to drive innovation and digital transformation.
Announcing general availability of Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics
Today, Amazon Web Services (AWS) announced the general availability of Amazon Bedrock Knowledge Bases GraphRAG (GraphRAG), a capability in Amazon Bedrock Knowledge Bases that enhances Retrieval-Augmented Generation (RAG) with graph data in Amazon Neptune Analytics. This capability enhances responses from generative AI applications by automatically creating embeddings for semantic search and generating a graph of the entities and relationships extracted from ingested documents. The graph, stored in Amazon Neptune Analytics, provides enriched context during the retrieval phase to deliver more comprehensive, relevant, and explainable responses tailored to customer needs. Developers can enable GraphRAG with just a few clicks on the Amazon Bedrock console to boost the accuracy of generative AI applications without any graph modeling expertise.
In this post, we discuss the benefits of GraphRAG and how to get started with it in Amazon Bedrock Knowledge Bases.
Enhance RAG with graphs for more comprehensive and explainable GenAI applications
Generative AI is transforming how humans interact with technology by having natural conversations that provide helpful, nuanced, and insightful responses. However, a key challenge facing current generative AI systems is providing responses that are comprehensive, relevant, and explainable because data is stored across multiple documents. Without effectively mapping shared context across input data sources, responses risk being incomplete and inaccurate.
To address this, AWS announced a public preview of GraphRAG at re:Invent 2024, and is now announcing its general availability. This new capability integrates the power of graph data modeling with advanced natural language processing (NLP). GraphRAG automatically creates graphs which capture connections between related entities and sections across documents. More specifically, the graph created will connect chunks to documents, and entities to chunks.
During response generation, GraphRAG first does semantic search to find the top k most relevant chunks, and then traverses the surrounding neighborhood of those chunks to retrieve the most relevant content. By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. Whether answering complex questions across topics or summarizing key details from lengthy reports, GraphRAG delivers the comprehensive and explainable responses needed to enable more helpful, reliable AI conversations.
GraphRAG boosts relevance and accuracy when relevant information is dispersed across multiple sources or documents, which can be seen in the following three use cases.
Streamlining market research to accelerate business decisions
A leading global financial institution sought to enhance insight extraction from its proprietary research. With a vast repository of economic and market research reports, the institution wanted to explore how GraphRAG could improve information retrieval and reasoning for complex financial queries. To evaluate this, they added their proprietary research papers, focusing on critical market trends and economic forecasts.
To evaluate the effectiveness of GraphRAG, the institution partnered with AWS to build a proof-of-concept using Amazon Bedrock Knowledge Bases and Amazon Neptune Analytics. The goal was to determine if GraphRAG could more effectively surface insights compared to traditional retrieval methods. GraphRAG structures knowledge into interconnected entities and relationships, enabling multi-hop reasoning across documents. This capability is crucial for answering intricate questions such as “What are some headwinds and tailwinds to capex growth in the next few years?” or “What is the impact of the ILA strike on international trade?”. Rather than relying solely on keyword matching, GraphRAG allows the model to trace relationships between economic indicators, policy changes, and industry impacts, ensuring responses are contextually rich and data-driven.
When comparing the quality of responses from GraphRAG and other retrieval methods, notable differences emerged in their comprehensiveness, clarity, and relevance. While other retrieval methods delivered straightforward responses, they often lacked deeper insights and broader context. GraphRAG instead provided more nuanced answers by incorporating related factors and offering additional relevant information, which made the responses more comprehensive than the other retrieval methods.
Improving data-driven decision-making in automotive manufacturing
An international auto company manages a large dataset, supporting thousands of use cases across engineering, manufacturing, and customer service. With thousands of users querying different datasets daily, making sure insights are accurate and connected across sources has been a persistent challenge.
To address this, the company worked with AWS to prototype a graph that maps relationships between key data points, such as vehicle performance, supply chain logistics, and customer feedback. This structure allows for more precise results across datasets, rather than relying on disconnected query results.
With Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics automatically constructing a graph from ingested documents, the company can surface relevant insights more efficiently in their RAG applications. This approach helps teams identify patterns in manufacturing quality, predict maintenance needs, and improve supply chain resilience, making data analysis more effective and scalable across the organization.
Enhancing cybersecurity incident analysis
A cybersecurity company is using GraphRAG to improve how its AI-powered assistant analyzes security incidents. Traditional detection methods rely on isolated alerts, often missing the broader context of an attack.
By using a graph, the company connects disparate security signals, such as login anomalies, malware signatures, and network traffic patterns, into a structured representation of threat activity. This allows for faster root cause analysis and more comprehensive security reporting.
Amazon Bedrock Knowledge Bases and Neptune Analytics enable this system to scale while maintaining strict security controls, providing resource isolation. With this approach, the company’s security teams can quickly interpret threats, prioritize responses, and reduce false positives, leading to more efficient incident handling.
Solution overview
In this post, we provide a walkthrough to build Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics, using files in an Amazon Simple Storage Service (Amazon S3) bucket. Running this example will incur costs in Amazon Neptune Analytics, Amazon S3, and Amazon Bedrock. Amazon Neptune Analytics costs for this example will be approximately $0.48 per hour. Amazon S3 costs will vary depending on how large your dataset is, and more details on Amazon S3 pricing can be found here. Amazon Bedrock costs will vary depending on the embeddings model and chunking strategy you select, and more details on Bedrock pricing can be found here.
Prerequisites
To follow along with this post, you need an AWS account with the necessary permissions to access Amazon Bedrock, and an Amazon S3 bucket containing data to serve as your knowledge base. Also ensure that you have enabled model access to Claude 3 Haiku (anthropic.claude-3-haiku-20240307-v1:0) and any other models that you wish to use as your embeddings model. For more details on how to enable model access, refer to the documentation here.
Build Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics
To get started, complete the following steps:
- On the Amazon Bedrock console, choose Knowledge Bases under Builder tools in the navigation pane.
- In the Knowledge Bases section, choose Create and Knowledge Base with vector store.

- For Knowledge Base details, enter a name and an optional description.
- For IAM permissions, select Create and use a new service role to create a new AWS Identity and Access Management (IAM) role.

- For Data source details, select Amazon S3 as your data source.
- Choose Next.
- For S3 URI, choose Browse S3 and choose the appropriate S3 bucket.
- For Parsing strategy, select Amazon Bedrock default parser.
- For Chunking strategy, choose Default chunking (recommended for GraphRAG) or any other strategy as you wish.
- Choose Next.

- For Embeddings model, choose an embeddings model, such as Amazon Titan Text Embeddings v2.
- For Vector database, select Quick create a new vector store and then select Amazon Neptune Analytics (GraphRAG).
- Choose Next.

- Review the configuration details and choose Create Knowledge Base.
Sync the data source
- Once the knowledge base is created, click Sync under the Data source section. The data sync can take a few minutes to a few hours, depending on how many source documents you have and how big each one is.

Test the knowledge base
Once the data sync is complete:
- Choose the expansion icon to expand the full view of the testing area.

- Configure your knowledge base by adding filters or guardrails.
- We encourage you to enable reranking (For information about pricing for reranking models, see Amazon Bedrock Pricing) to fully take advantage of the capabilities of GraphRAG. Reranking allows GraphRAG to refine and optimize search results.
- You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. You can apply filters to your retrievals, instructing the vector store to pre-filter based on document metadata and then search for relevant documents. This way, you have control over the retrieved documents, especially if your queries are ambiguous. Note that the
listtype is not supported.
- Use the chat area in the right pane to ask questions about the documents from your Amazon S3 bucket.
The responses will use GraphRAG and provide references to chunks and documents in their response.

Now that you’ve enabled GraphRAG, test it out by querying your generative AI application and observe how the responses have improved compared to baseline RAG approaches. You can monitor the Amazon CloudWatch logs for performance metrics on indexing, query latency, and accuracy.
Clean up
When you’re done exploring the solution, make sure to clean up by deleting any resources you created. Resources to clean up include the Amazon Bedrock knowledge base, the associated AWS IAM role that the Amazon Bedrock knowledge base uses, and the Amazon S3 bucket that was used for the source documents.
You will also need to separately delete the Amazon Neptune Analytics graph that was created on your behalf, by Amazon Bedrock Knowledge Bases.
Conclusion
In this post, we discussed how to get started with Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune. For further experimentation, check out the Amazon Bedrock Knowledge Bases Retrieval APIs to use the power of GraphRAG in your own applications. Refer to our documentation for code samples and best practices.
About the authors
 Denise Gosnell is a Principal Product Manager for Amazon Neptune, focusing on generative AI infrastructure and graph data applications that enable scalable, cutting-edge solutions across industry verticals.
Denise Gosnell is a Principal Product Manager for Amazon Neptune, focusing on generative AI infrastructure and graph data applications that enable scalable, cutting-edge solutions across industry verticals.
 Melissa Kwok is a Senior Neptune Specialist Solutions Architect at AWS, where she helps customers of all sizes and verticals build cloud solutions according to best practices. When she’s not at her desk you can find her in the kitchen experimenting with new recipes or reading a cookbook.
Melissa Kwok is a Senior Neptune Specialist Solutions Architect at AWS, where she helps customers of all sizes and verticals build cloud solutions according to best practices. When she’s not at her desk you can find her in the kitchen experimenting with new recipes or reading a cookbook.
 Ozan Eken is a Product Manager at AWS, passionate about building cutting-edge Generative AI and Graph Analytics products. With a focus on simplifying complex data challenges, Ozan helps customers unlock deeper insights and accelerate innovation. Outside of work, he enjoys trying new foods, exploring different countries, and watching soccer.
Ozan Eken is a Product Manager at AWS, passionate about building cutting-edge Generative AI and Graph Analytics products. With a focus on simplifying complex data challenges, Ozan helps customers unlock deeper insights and accelerate innovation. Outside of work, he enjoys trying new foods, exploring different countries, and watching soccer.
 Harsh Singh is a Principal Product Manager Technical at AWS AI. Harsh enjoys building products that bring AI to software developers and everyday users to improve their productivity.
Harsh Singh is a Principal Product Manager Technical at AWS AI. Harsh enjoys building products that bring AI to software developers and everyday users to improve their productivity.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.