Generative AI is rapidly transforming the modern workplace, offering unprecedented capabilities that augment how we interact with text and data. At Amazon Web Services (AWS), we recognize that many of our customers rely on the familiar Microsoft Office suite of applications, including Word, Excel, and Outlook, as the backbone of their daily workflows. In this blog post, we showcase a powerful solution that seamlessly integrates AWS generative AI capabilities in the form of large language models (LLMs) based on Amazon Bedrock into the Office experience. By harnessing the latest advancements in generative AI, we empower employees to unlock new levels of efficiency and creativity within the tools they already use every day. Whether it’s drafting compelling text, analyzing complex datasets, or gaining more in-depth insights from information, integrating generative AI with Office suite transforms the way teams approach their essential work. Join us as we explore how your organization can leverage this transformative technology to drive innovation and boost employee productivity.
Solution overview

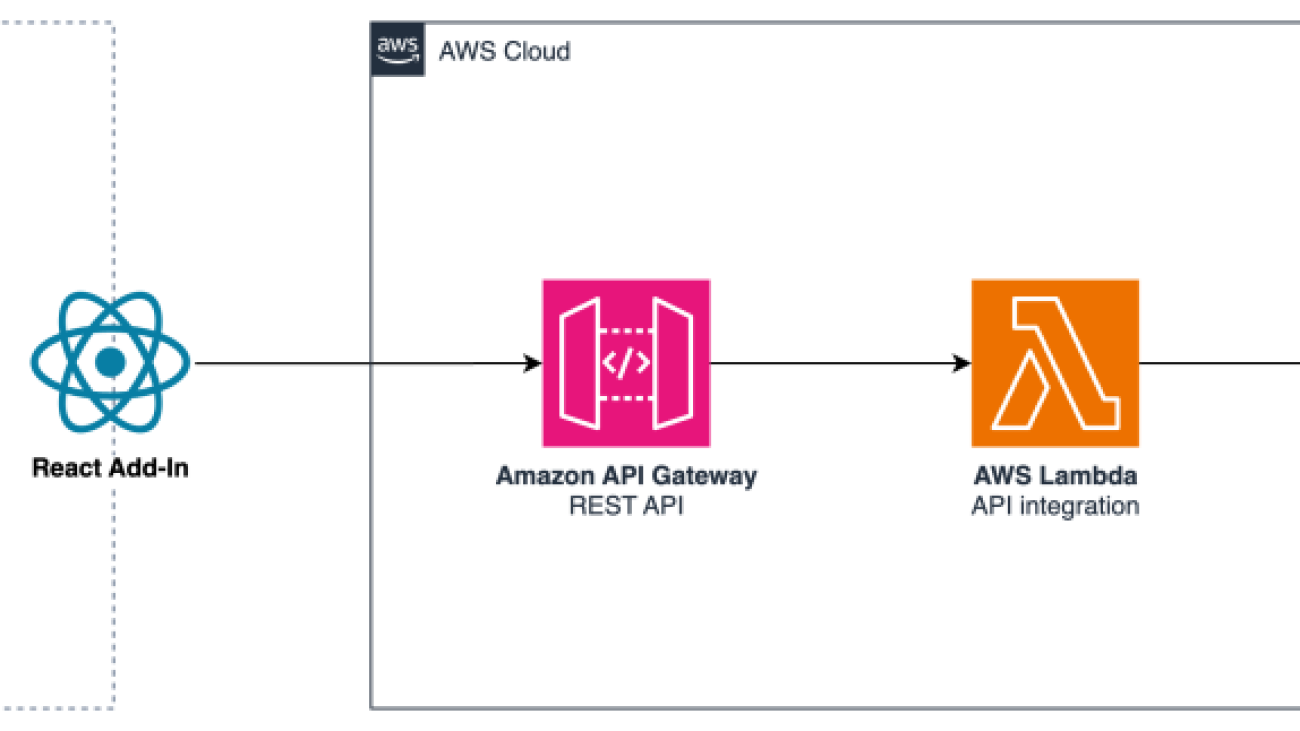
Figure 1: Solution architecture overview
The solution architecture in Figure 1 shows how Office applications interact with a serverless backend hosted on the AWS Cloud through an Add-In. This architecture allows users to leverage Amazon Bedrock’s generative AI capabilities directly from within the Office suite, enabling enhanced productivity and insights within their existing workflows.
Components deep-dive
Office Add-ins
Office Add-ins allow extending Office products with custom extensions built on standard web technologies. Using AWS, organizations can host and serve Office Add-ins for users worldwide with minimal infrastructure overhead.
An Office Add-in is composed of two elements:
- Manifest: A domain-specific XML file that specifies how the Office Add-in integrates with the application. The manifest must be loaded within the Office installation. Refer to the recommended publishing methods. For testing, one can sideload an Office Add-in.
- User Interface: A custom web application that gets integrated into the MS Office experience. One can quickly host such application on the AWS Cloud without managing the underlying infrastructure, for example, with Amazon Simple Storage Service (S3) and Amazon CloudFront.
The code snippet below demonstrates part of a function that could run whenever a user invokes the plugin, performing the following actions:
- Initiate a request to the generative AI backend, providing the user prompt and available context in the request body
- Integrate the results from the backend response into the Word document using Microsoft’s Office JavaScript APIs. Note that these APIs use objects as namespaces, alleviating the need for explicit imports. Instead, we use the globally available namespaces, such as
Word, to directly access relevant APIs, as shown in following example snippet.
Generative AI backend infrastructure
The AWS Cloud backend consists of three components:
- Amazon API Gateway acts as an entry point, receiving requests from the Office applications’ Add-in. API Gateway supports multiple mechanisms for controlling and managing access to an API.
- AWS Lambda handles the REST API integration, processing the requests and invoking the appropriate AWS services.
- Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available via an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. With Bedrock’s serverless experience, you can get started quickly, privately customize FMs with your own data, and quickly integrate and deploy them into your applications using the AWS tools without having to manage infrastructure.
LLM prompting
Amazon Bedrock allows you to choose from a wide selection of foundation models for prompting. Here, we use Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock for completions. The system prompt we used in this example is as follows:
You are an office assistant helping humans to write text for their documents.
[When preparing the answer, take into account the following text: <text>{context}</text>]
Before answering the question, think through it step-by-step within the <thinking></thinking> tags.
Then, detect the user's language from their question and store it in the form of an ISO 639-1 code within the <user_language></user_language> tags.
Then, develop your answer in the user’s language within the <response></response> tags.
In the prompt, we first give the LLM a persona, indicating that it is an office assistant helping humans. The second, optional line contains text that has been selected by the user in the document and is provided as context to the LLM. We specifically instruct the LLM to first mimic a step-by-step thought process for arriving at the answer (chain-of-thought reasoning), an effective measure of prompt-engineering to improve the output quality. Next, we instruct it to detect the user’s language from their question so we can later refer to it. Finally, we instruct the LLM to develop its answer using the previously detected user language within response tags, which are used as the final response. While here, we use the default configuration for inference parameters such as temperature, that can quickly be configured with every LLM prompt. The user input is then added as a user message to the prompt and sent via the Amazon Bedrock Messages API to the LLM.
Implementation details and demo setup in an AWS account
As a prerequisite, we need to make sure that we are working in an AWS Region with Amazon Bedrock support for the foundation model (here, we use Anthropic’s Claude 3.5 Sonnet). Also, access to the required relevant Amazon Bedrock foundation models needs to be added. For this demo setup, we describe the manual steps taken in the AWS console. If required, this setup can also be defined in Infrastructure as Code.
To set up the integration, follow these steps:
- Create an AWS Lambda function with Python runtime and below code to be the backend for the API. Make sure that we have Powertools for AWS Lambda (Python) available in our runtime, for example, by attaching aLambda layer to our function. Make sure that the Lambda function’s IAM role provides access to the required FM, for example:
The following code block shows a sample implementation for the REST API Lambda integration based on a Powertools for AWS Lambda (Python) REST API event handler:
- Create an API Gateway REST API with a Lambda proxy integration to expose the Lambda function via a REST API. You can follow this tutorial for creating a REST API for the Lambda function by using the API Gateway console. By creating a Lambda proxy integration with a proxy resource, we can route requests to the resources to the Lambda function. Follow the tutorial to deploy the API and take note of the API’s invoke URL. Make sure to configure adequate access control for the REST API.
We can now invoke and test our function via the API’s invoke URL. The following example uses curl to send a request (make sure to replace all placeholders in curly braces as required), and the response generated by the LLM:
If required, the created resources can be cleaned up by 1) deleting the API Gateway REST API, and 2) deleting the REST API Lambda function and associated IAM role.
Example use cases
To create an interactive experience, the Office Add-in integrates with the cloud back-end that implements conversational capabilities with support for additional context retrieved from the Office JavaScript API.
Next, we demonstrate two different use cases supported by the proposed solution, text generation and text refinement.
Text generation

Figure 2: Text generation use-case demo
In the demo in Figure 2, we show how the plug-in is prompting the LLM to produce a text from scratch. The user enters their query with some context into the Add-In text input area. Upon sending, the backend will prompt the LLM to generate respective text, and return it back to the frontend. From the Add-in, it is inserted into the Word document at the cursor position using the Office JavaScript API.
Text refinement
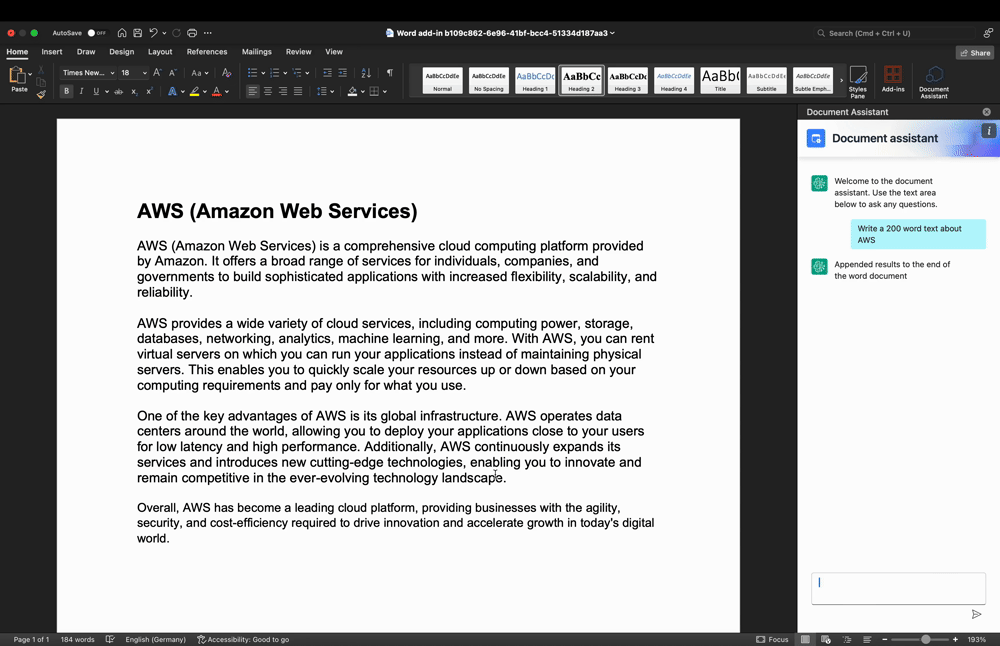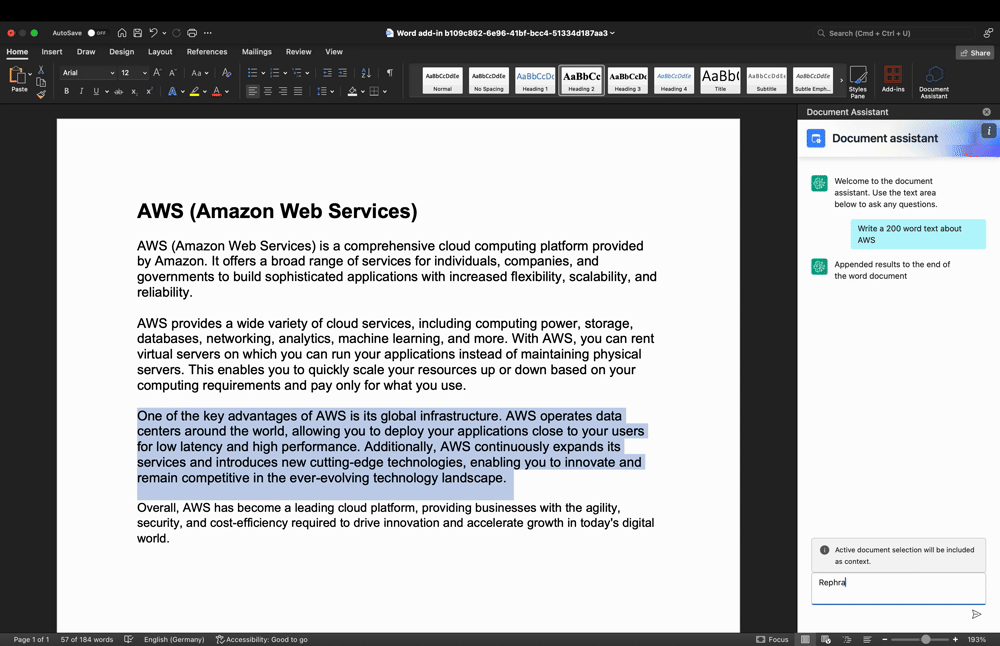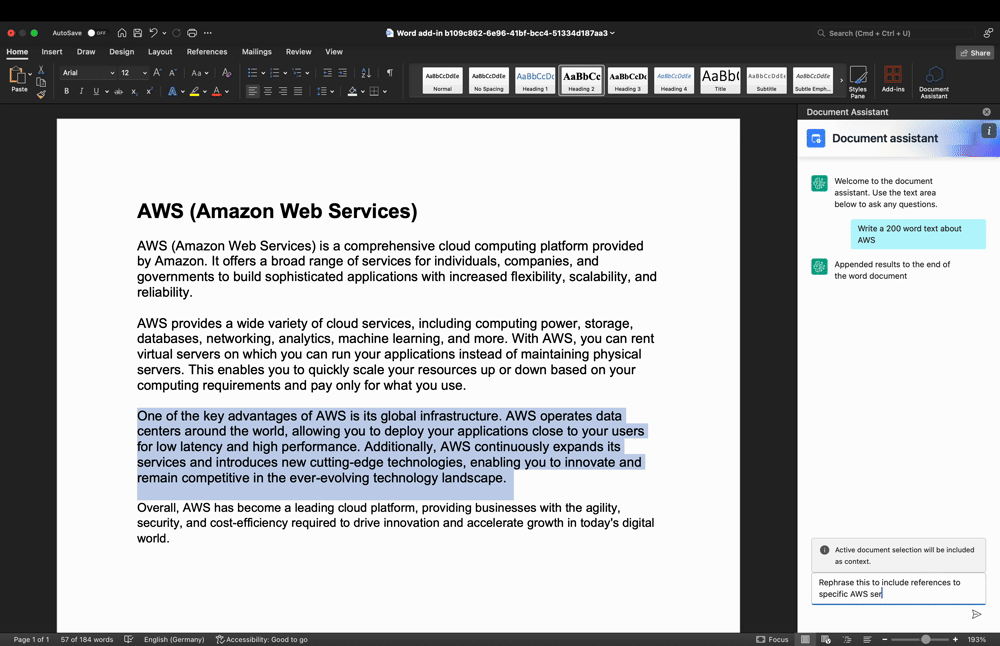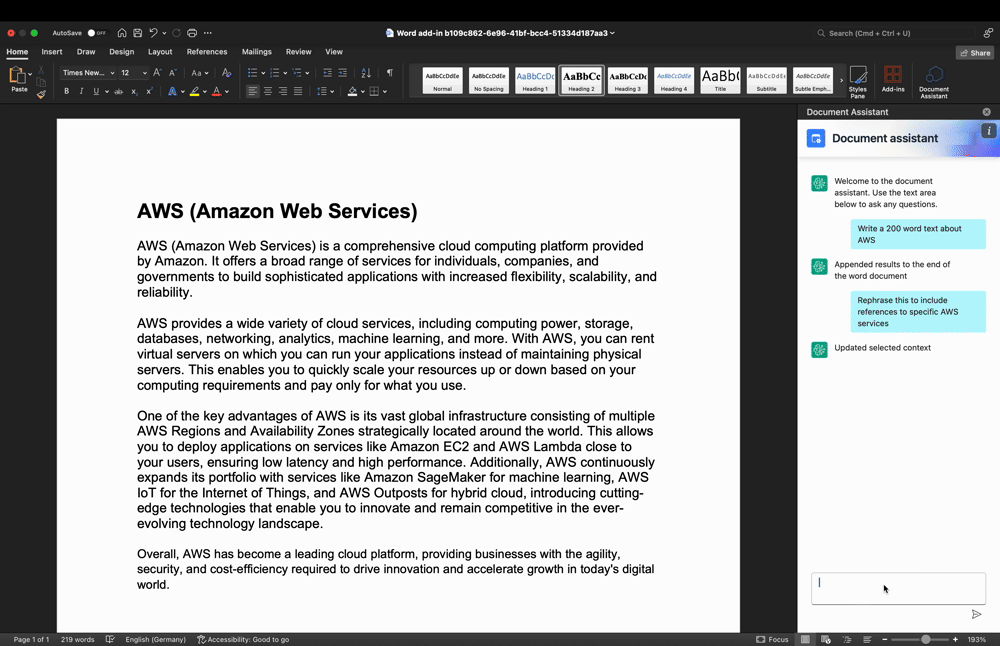
Figure 3: Text refinement use-case demo
In Figure 3, the user highlighted a text segment in the work area and entered a prompt into the Add-In text input area to rephrase the text segment. Again, the user input and highlighted text are processed by the backend and returned to the Add-In, thereby replacing the previously highlighted text.
Conclusion
This blog post showcases how the transformative power of generative AI can be incorporated into Office processes. We described an end-to-end sample of integrating Office products with an Add-in for text generation and manipulation with the power of LLMs. In our example, we used managed LLMs on Amazon Bedrock for text generation. The backend is hosted as a fully serverless application on the AWS cloud.
Text generation with LLMs in Office supports employees by streamlining their writing process and boosting productivity. Employees can leverage the power of generative AI to generate and edit high-quality content quickly, freeing up time for other tasks. Additionally, the integration with a familiar tool like Word provides a seamless user experience, minimizing disruptions to existing workflows.
To learn more about boosting productivity, building differentiated experiences, and innovating faster with AWS visit the Generative AI on AWS page.
About the Authors
 Martin Maritsch is a Generative AI Architect at AWS ProServe focusing on Generative AI and MLOps. He helps enterprise customers to achieve business outcomes by unlocking the full potential of AI/ML services on the AWS Cloud.
Martin Maritsch is a Generative AI Architect at AWS ProServe focusing on Generative AI and MLOps. He helps enterprise customers to achieve business outcomes by unlocking the full potential of AI/ML services on the AWS Cloud.
 Miguel Pestana is a Cloud Application Architect in the AWS Professional Services team with over 4 years of experience in the automotive industry delivering cloud native solutions. Outside of work Miguel enjoys spending its days at the beach or with a padel racket in one hand and a glass of sangria on the other.
Miguel Pestana is a Cloud Application Architect in the AWS Professional Services team with over 4 years of experience in the automotive industry delivering cloud native solutions. Outside of work Miguel enjoys spending its days at the beach or with a padel racket in one hand and a glass of sangria on the other.
 Carlos Antonio Perea Gomez is a Builder with AWS Professional Services. He enables customers to become AWSome during their journey to the cloud. When not up in the cloud he enjoys scuba diving deep in the waters.
Carlos Antonio Perea Gomez is a Builder with AWS Professional Services. He enables customers to become AWSome during their journey to the cloud. When not up in the cloud he enjoys scuba diving deep in the waters.
 Rahul Pathak is Vice President Data and AI GTM at AWS, where he leads the global go-to-market and specialist teams who are helping customers create differentiated value with AWS’s AI and capabilities such as Amazon Bedrock, Amazon Q, Amazon SageMaker, and Amazon EC2 and Data Services such as Amaqzon S3, AWS Glue and Amazon Redshift. Rahul believes that generative AI will transform virtually every single customer experience and that data is a key differentiator for customers as they build AI applications. Prior to his current role, he was Vice President, Relational Database Engines where he led Amazon Aurora, Redshift, and DSQL . During his 13+ years at AWS, Rahul has been focused on launching, building, and growing managed database and analytics services, all aimed at making it easy for customers to get value from their data. Rahul has over twenty years of experience in technology and has co-founded two companies, one focused on analytics and the other on IP-geolocation. He holds a degree in Computer Science from MIT and an Executive MBA from the University of Washington.
Rahul Pathak is Vice President Data and AI GTM at AWS, where he leads the global go-to-market and specialist teams who are helping customers create differentiated value with AWS’s AI and capabilities such as Amazon Bedrock, Amazon Q, Amazon SageMaker, and Amazon EC2 and Data Services such as Amaqzon S3, AWS Glue and Amazon Redshift. Rahul believes that generative AI will transform virtually every single customer experience and that data is a key differentiator for customers as they build AI applications. Prior to his current role, he was Vice President, Relational Database Engines where he led Amazon Aurora, Redshift, and DSQL . During his 13+ years at AWS, Rahul has been focused on launching, building, and growing managed database and analytics services, all aimed at making it easy for customers to get value from their data. Rahul has over twenty years of experience in technology and has co-founded two companies, one focused on analytics and the other on IP-geolocation. He holds a degree in Computer Science from MIT and an Executive MBA from the University of Washington.










 Jose Navarro is an AI/ML Specialist Solutions Architect at AWS, based in Spain. Jose helps AWS customers—from small startups to large enterprises—architect and take their end-to-end machine learning use cases to production.
Jose Navarro is an AI/ML Specialist Solutions Architect at AWS, based in Spain. Jose helps AWS customers—from small startups to large enterprises—architect and take their end-to-end machine learning use cases to production. Morgan Dutton is a Senior Technical Program Manager at AWS, Amazon Q Business based in Seattle.
Morgan Dutton is a Senior Technical Program Manager at AWS, Amazon Q Business based in Seattle. Eva Pagneux is a Principal Product Manager at AWS, Amazon Q Business, based in San Francisco.
Eva Pagneux is a Principal Product Manager at AWS, Amazon Q Business, based in San Francisco. Wesleigh Roeca is a Senior Worldwide Gen AI/ML Specialist at AWS, Amazon Q Business, based in Santa Monica.
Wesleigh Roeca is a Senior Worldwide Gen AI/ML Specialist at AWS, Amazon Q Business, based in Santa Monica.













 Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open-source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open-source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions. Greeshma Nallapareddy is a Sr. Business Development Manager at AWS working with NVIDIA on go-to-market strategy to accelerate AI solutions for customers at scale. Her experience includes leading solutions architecture teams focused on working with startups.
Greeshma Nallapareddy is a Sr. Business Development Manager at AWS working with NVIDIA on go-to-market strategy to accelerate AI solutions for customers at scale. Her experience includes leading solutions architecture teams focused on working with startups. Akshit Arora is a senior data scientist at NVIDIA, where he works on deploying conversational AI models on GPUs at scale. He’s a graduate of University of Colorado at Boulder, where he applied deep learning to improve knowledge tracking on a K-12 online tutoring service. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning.
Akshit Arora is a senior data scientist at NVIDIA, where he works on deploying conversational AI models on GPUs at scale. He’s a graduate of University of Colorado at Boulder, where he applied deep learning to improve knowledge tracking on a K-12 online tutoring service. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning. Ankur Srivastava is a Sr. Solutions Architect in the ML Frameworks Team. He focuses on helping customers with self-managed distributed training and inference at scale on AWS. His experience includes industrial predictive maintenance, digital twins, probabilistic design optimization and has completed his doctoral studies from Mechanical Engineering at Rice University and post-doctoral research from Massachusetts Institute of Technology.
Ankur Srivastava is a Sr. Solutions Architect in the ML Frameworks Team. He focuses on helping customers with self-managed distributed training and inference at scale on AWS. His experience includes industrial predictive maintenance, digital twins, probabilistic design optimization and has completed his doctoral studies from Mechanical Engineering at Rice University and post-doctoral research from Massachusetts Institute of Technology. Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon AI MLOps, DevOps, Scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon AI MLOps, DevOps, Scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.