
Tens of thousands of companies worldwide rely on Apache Spark to crunch massive datasets to support critical operations, as well as predict trends, customer behavior, business performance and more. The faster a company can process and understand its data, the more it stands to make and save.
That’s why companies with massive datasets — including the world’s largest retailers and banks — have adopted NVIDIA RAPIDS Accelerator for Apache Spark. The open-source software runs on top of the NVIDIA accelerated computing platform to significantly accelerate the processing of end-to-end data science and analytics pipelines — without any code changes.
To make it even easier for companies to get value out of NVIDIA-accelerated Spark, NVIDIA today unveiled Project Aether — a collection of tools and processes that automatically qualify, test, configure and optimize Spark workloads for GPU acceleration at scale.
Project Aether Completes a Year’s Worth of Work in Less Than a Week
Customers using Spark in production often manage tens of thousands of complex jobs, or more. Migrating from CPU-only to GPU-powered computing offers numerous and significant benefits, but can be a manual and time-consuming process.
Project Aether automates the myriad steps that companies previously have done manually, including analyzing all of their Spark jobs to identify the best candidates for GPU acceleration, as well as staging and performing test runs of each job. It uses AI to fine-tune the configuration of each job to obtain the maximum performance.
To understand the impact of Project Aether, consider an enterprise that has 100 Spark jobs to complete. With Project Aether, each of these jobs can be configured and optimized for NVIDIA GPU acceleration in as little as four days. The same process done manually by a single data engineer could take up to an entire year.
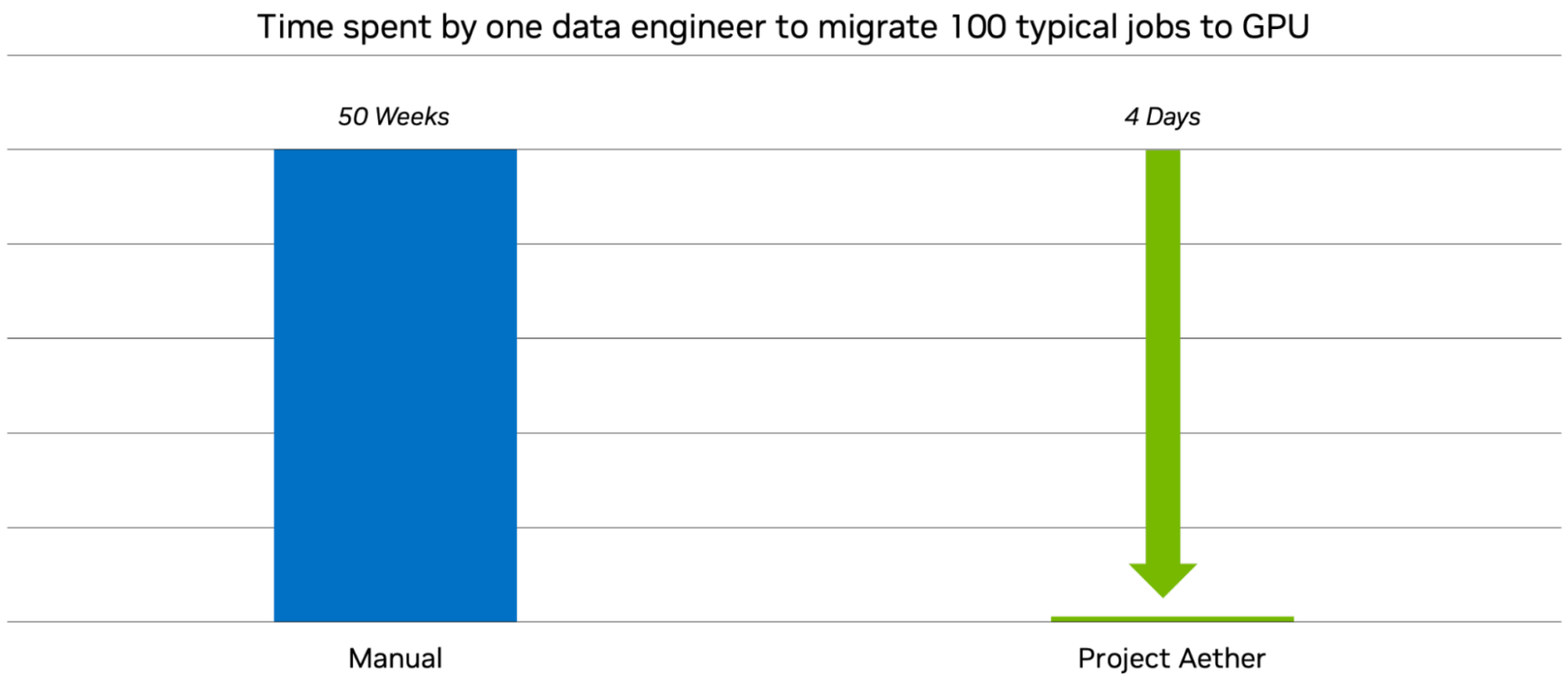
CBA Drives AI Transformation With NVIDIA-Accelerated Apache Spark
Running Apache Spark on NVIDIA accelerated computing helps enterprises around the world complete jobs faster and with less hardware compared with using CPUs only — saving time, space, power and cooling, as well as on-premises capital and operational costs in the cloud.
Australia’s largest financial institution, the Commonwealth Bank of Australia, is responsible for processing 60% of the continent’s financial transactions. CBA was experiencing challenges from the latency and costs associated with running its Spark workloads. Using CPU-only computing clusters, the bank estimates it faced nearly nine years of processing time for its training backlog — on top of handling already taxing daily data demands.
“With 40 million inferencing transactions a day, it was critical we were able to process these in a timely, reliable manner,” said Andrew McMullan, chief data and analytics officer at CBA.
Running RAPIDS Accelerator for Apache Spark on GPU-powered infrastructure provided CBA with a 640x performance boost, allowing the bank to process a training of 6.3 billion transactions in just five days. Additionally, on its daily volume of 40 million transactions, CBA is now able to conduct inference in 46 minutes and reduce costs by more than 80% compared with using a CPU-based solution.
McMullan says another value of NVIDIA-accelerated Apache Spark is how it offers his team the compute time efficiency needed to cost-effectively build models that can help CBA deliver better customer service, anticipate when customers may need assistance with home loans and more quickly detect fraudulent transactions.
CBA also plans to use NVIDIA-accelerated Apache Spark to better pinpoint where customers commonly end their digital journeys, enabling the bank to remediate when needed to reduce the rate of abandoned applications.
Global Ecosystem
RAPIDS Accelerator for Apache Spark is available through a global network of partners. It runs on Amazon Web Services, Cloudera, Databricks, Dataiku, Google Cloud, Microsoft Azure and Oracle Cloud Infrastructure.
Dell Technologies today also announced the integration of RAPIDS Accelerator for Apache Spark with Dell Data Lakehouse.
To get assistance through NVIDIA Project Aether with a large-scale migration of Apache Spark workloads, apply for access.
To learn more, register for NVIDIA GTC and attend these key sessions featuring Walmart, Capital One, CBA and other industry leaders:
- How Walmart Uses RAPIDS to Improve Efficiency, and What We Have Learned Along the Way
- Accelerate Distributed Apache Spark Applications on Kubernetes With RAPIDS
- Build Lightning-Fast Data Science Pipelines in Industry With Accelerated Computing
- Advancing Transaction Fraud Detection in Financial Services With NVIDIA RAPIDS on AWS
- Accelerating Data Intelligence With GPUs and RAPIDS on Databricks
- Scale Your Apache Spark Data Processing With State-of-the-Art NVIDIA Blackwell GPUs for Cost Savings and Performance
See notice regarding software product information.













 Shyam Srinivasan is on the Amazon Bedrock Guardrails product team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends.
Shyam Srinivasan is on the Amazon Bedrock Guardrails product team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends. Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at AWS. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at AWS. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends. Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Amazon Bedrock at Amazon Web Services. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value.
Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Amazon Bedrock at Amazon Web Services. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value.

