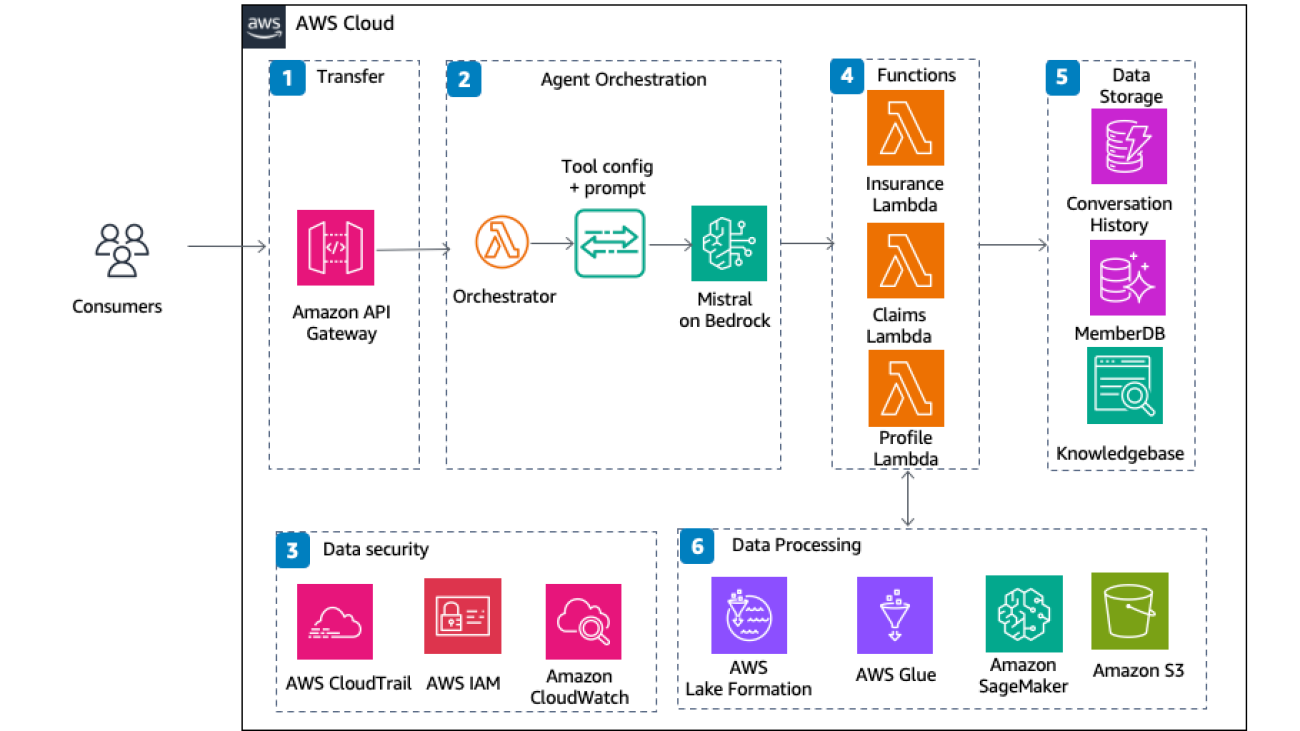
The rise of generative AI has significantly increased the complexity of building, training, and deploying machine learning (ML) models. It now demands deep expertise, access to vast datasets, and the management of extensive compute clusters. Customers also face the challenges of writing specialized code for distributed training, continuously optimizing models, addressing hardware issues, and keeping projects on track and within budget. To simplify this process, AWS introduced Amazon SageMaker HyperPod during AWS re:Invent 2023, and it has emerged as a pioneering solution, revolutionizing how companies approach AI development and deployment.
As Amazon CEO Andy Jassy recently shared, “One of the most exciting innovations we’ve introduced is SageMaker HyperPod. HyperPod accelerates the training of machine learning models by distributing and parallelizing workloads across numerous powerful processors like AWS’s Trainium chips or GPUs. HyperPod also constantly monitor your infrastructure for problems, automatically repairing them when detected. During repair, your work is automatically saved, ensuring seamless resumption. This innovation is widely adopted, with most SageMaker AI customers relying on HyperPod for their demanding training needs.”
In this post, we show how SageMaker HyperPod, and its new features introduced at AWS re:Invent 2024, is designed to meet the demands of modern AI workloads, offering a persistent and optimized cluster tailored for distributed training and accelerated inference at cloud scale and attractive price-performance.
Customers using SageMaker HyperPod
Leading startups like Writer, Luma AI, and Perplexity, as well as major enterprises such as Thomson Reuters and Salesforce, are accelerating model development with SageMaker HyperPod. Amazon itself used SageMaker HyperPod to train its new Amazon Nova models, significantly reducing training costs, enhancing infrastructure performance, and saving months of manual effort that would have otherwise been spent on cluster setup and end-to-end process management.

Today, more organizations are eager to fine-tune popular publicly available models or train their own specialized models to revolutionize their businesses and applications with generative AI. To support this demand, SageMaker HyperPod continues to evolve, introducing new innovations that make it straightforward, faster, and more cost-effective for customers to build, train, and deploy these models at scale.
Deep infrastructure control
SageMaker HyperPod offers persistent clusters with deep infrastructure control, enabling builders to securely connect using SSH to Amazon Elastic Compute Cloud (Amazon EC2) instances for advanced model training, infrastructure management, and debugging. To maximize availability, HyperPod maintains a pool of dedicated and spare instances (at no additional cost), minimizing downtime during critical node replacements.
You can use familiar orchestration tools such as Slurm or Amazon Elastic Kubernetes Service (Amazon EKS), along with the libraries built on these tools, to enable flexible job scheduling and compute sharing. Integrating SageMaker HyperPod clusters with Slurm also allows the use of NVIDIA’s Enroot and Pyxis for efficient container scheduling in performant, unprivileged sandboxes. The underlying operating system and software stack are based on the Deep Learning AMI, preconfigured with NVIDIA CUDA, NVIDIA cuDNN, and the latest versions of PyTorch and TensorFlow. SageMaker HyperPod also is integrated with Amazon SageMaker AI distributed training libraries, optimized for AWS infrastructure, enabling automatic workload distribution across thousands of accelerators for efficient parallel training.
Builders can use built-in ML tools within SageMaker HyperPod to enhance model performance. For example, Amazon SageMaker with TensorBoard helps visualize model architecture and address convergence issues, as shown in the following screenshot. Integration with observability tools like Amazon CloudWatch Container Insights, Amazon Managed Service for Prometheus, and Amazon Managed Grafana offers deeper insights into cluster performance, health, and utilization, streamlining development time.

SageMaker HyperPod allows you to implement custom libraries and frameworks, enabling the service to be tailored to specific AI project needs. This level of personalization is essential in the rapidly evolving AI landscape, where innovation often requires experimenting with cutting-edge techniques and technologies. The adaptability of SageMaker HyperPod means that businesses are not constrained by infrastructure limitations, fostering creativity and technological advancement.
Intelligent resource management
As organizations increasingly provision large amounts of accelerated compute capacity for model training, they face challenges in effectively governing resource usage. These compute resources are both expensive and finite, making it crucial to prioritize critical model development tasks and avoid waste or under utilization. Without proper controls over task prioritization and resource allocation, some projects stall due to insufficient resources, while others leave resources underused. This creates a significant burden for administrators, who must constantly reallocate resources, and for data scientists, who struggle to maintain progress. These inefficiencies delay AI innovation and drive up costs.
SageMaker HyperPod addresses these challenges with its task governance capabilities, enabling you to maximize accelerator utilization for model training, fine-tuning, and inference. With just a few clicks, you can define task priorities and set limits on compute resource usage for teams. Once configured, SageMaker HyperPod automatically manages the task queue, making sure the most critical work receives the necessary resources. This reduction in operational overhead allows organizations to reallocate valuable human resources toward more innovative and strategic initiatives. This reduces model development costs by up to 40%.
For instance, if an inference task powering a customer-facing service requires urgent compute capacity but all resources are currently in use, SageMaker HyperPod reallocates underutilized or non-urgent resources to prioritize the critical task. Non-urgent tasks are automatically paused, checkpoints are saved to preserve progress, and these tasks resume seamlessly when resources become available. This makes sure you maximize your compute investments without compromising ongoing work.
As a fast-growing generative AI startup, Articul8 AI constantly optimizes their compute environment to allocate accelerated compute resources as efficiently as possible. With automated task prioritization and resource allocation in SageMaker HyperPod, they have seen a dramatic improvement in GPU utilization, reducing idle time and accelerating their model development process by optimizing tasks ranging from training and fine-tuning to inference. The ability to automatically shift resources to high-priority tasks has increased their team’s productivity, allowing them to bring new generative AI innovations to market faster than ever before.
At its core, SageMaker HyperPod represents a paradigm shift in AI infrastructure, moving beyond the traditional emphasis on raw computational power to focus on intelligent and adaptive resource management. By prioritizing optimized resource allocation, SageMaker HyperPod minimizes waste, maximizes efficiency, and accelerates innovation—all while reducing costs. This makes AI development more accessible and scalable for organizations of all sizes.
Get started faster with SageMaker HyperPod recipes
Many customers want to customize popular publicly available models, like Meta’s Llama and Mistral, for their specific use cases using their organization’s data. However, optimizing training performance often requires weeks of iterative testing—experimenting with algorithms, fine-tuning parameters, monitoring training impact, debugging issues, and benchmarking performance.
To simplify this process, SageMaker HyperPod now offers over 30 curated model training recipes for some of today’s most popular models, including DeepSeek R1, DeepSeek R1 Distill Llama, DeepSeek R1 Distill Qwen, Llama, Mistral, and Mixtral. These recipes enable you to get started in minutes by automating key steps like loading training datasets, applying distributed training techniques, and configuring systems for checkpointing and recovery from infrastructure failures. This empowers users of all skill levels to achieve better price-performance for model training on AWS infrastructure from the outset, eliminating weeks of manual evaluation and testing.
You can browse the GitHub repo to explore available training recipes, customize parameters to fit your needs, and deploy in minutes. With a simple one-line change, you can seamlessly switch between GPU or AWS Trainium based instances to further optimize price-performance.
Researchers at Salesforce were looking for ways to quickly get started with foundation model (FM) training and fine-tuning, without having to worry about the infrastructure, or spend weeks optimizing their training stack for each new model. With SageMaker HyperPod recipes, researchers at Salesforce can conduct rapid prototyping when customizing FMs. Now, Salesforce’s AI Research teams are able to get started in minutes with a variety of pre-training and fine-tuning recipes, and can operationalize frontier models with high performance.
Integrating Kubernetes with SageMaker Hyperpod
Though the standalone capabilities of SageMaker HyperPod are impressive, its integration with Amazon EKS takes AI workloads to new levels of power and flexibility. Amazon EKS simplifies the deployment, scaling, and management of containerized applications, making it an ideal solution for orchestrating complex AI/ML infrastructure.
By running SageMaker HyperPod on Amazon EKS, organizations can use Kubernetes’s advanced scheduling and orchestration features to dynamically provision and manage compute resources for AI/ML workloads, providing optimal resource utilization and scalability.
“We were able to meet our large language model training requirements using Amazon SageMaker HyperPod,” says John Duprey, Distinguished Engineer, Thomson Reuters Labs. “Using Amazon EKS on SageMaker HyperPod, we were able to scale up capacity and easily run training jobs, enabling us to unlock benefits of LLMs in areas such as legal summarization and classification.”
This integration also enhances fault tolerance and high availability. With self-healing capabilities, HyperPod automatically replaces failed nodes, maintaining workload continuity. Automated GPU health monitoring and seamless node replacement provide reliable execution of AI/ML workloads with minimal downtime, even during hardware failures.
Additionally, running SageMaker HyperPod on Amazon EKS enables efficient resource isolation and sharing using Kubernetes namespaces and resource quotas. Organizations can isolate different AI/ML workloads or teams while maximizing resource utilization across the cluster.
Flexible training plans help meet timelines and budgets
Although infrastructure innovations help reduce costs and improve training efficiency, customers still face challenges in planning and managing the compute capacity needed to complete training tasks on time and within budget. To address this, AWS is introducing flexible training plans for SageMaker HyperPod.
With just a few clicks, you can specify your desired completion date and the maximum amount of compute resources needed. SageMaker HyperPod then helps acquire capacity and sets up clusters, saving teams weeks of preparation time. This eliminates much of the uncertainty customers encounter when acquiring large compute clusters for model development tasks.

SageMaker HyperPod training plans are now available in US East (N. Virginia), US East (Ohio), and US West (Oregon) AWS Regions and support ml.p4d.48xlarge, ml.p5.48xlarge, ml.p5e.48xlarge, ml.p5en.48xlarge, and ml.trn2.48xlarge instances. Trn2 and P5en instances are only in the US East (Ohio) Region. To learn more, visit the SageMaker HyperPod product page and SageMaker pricing page.
Hippocratic AI is an AI company that develops the first safety-focused large language model (LLM) for healthcare. To train its primary LLM and the supervisor models, Hippocratic AI required powerful compute resources, which were in high demand and difficult to obtain. SageMaker HyperPod flexible training plans made it straightforward for them to gain access to EC2 P5 instances.
Developers and data scientists at OpenBabylon, an AI company that customizes LLMs for underrepresented languages, has been using SageMaker HyperPod flexible training plans for a few months to streamline their access to GPU resources to run large-scale experiments. Using the multi-node SageMaker HyperPod distributed training capabilities, they conducted 100 large-scale model training experiments, achieving state-of-the-art results in English-to-Ukrainian translation. This breakthrough was achieved on time and cost-effectively, demonstrating the ability of SageMaker HyperPod to successfully deliver complex projects on time and at budget.
Integrating training and inference infrastructures
A key focus area is integrating next-generation AI accelerators like the anticipated AWS Trainium2 release. These advanced accelerators promise unparalleled computational performance, offering 30–40% better price-performance than the current generation of GPU-based EC2 instances, significantly boosting AI model training and deployment efficiency and speed. This will be crucial for real-time applications and processing vast datasets simultaneously. The seamless accelerator integration with SageMaker HyperPod enables businesses to harness cutting-edge hardware advancements, driving AI initiatives forward.
Another pivotal aspect is that SageMaker HyperPod, through its integration with Amazon EKS, enables scalable inference solutions. As real-time data processing and decision-making demands grow, the SageMaker HyperPod architecture efficiently handles these requirements. This capability is essential across sectors like healthcare, finance, and autonomous systems, where timely, accurate AI inferences are critical. Offering scalable inference enables deploying high-performance AI models under varying workloads, enhancing operational effectiveness.
Moreover, integrating training and inference infrastructures represents a significant advancement, streamlining the AI lifecycle from development to deployment and providing optimal resource utilization throughout. Bridging this gap facilitates a cohesive, efficient workflow, reducing transition complexities from development to real-world applications. This holistic integration supports continuous learning and adaptation, which is key for next-generation, self-evolving AI models (continuously learning models, which possess the ability to adapt and refine themselves in real time based on their interactions with the environment).
SageMaker HyperPod uses established open source technologies, including MLflow integration through SageMaker, container orchestration through Amazon EKS, and Slurm workload management, providing users with familiar and proven tools for their ML workflows. By engaging the global AI community and encouraging knowledge sharing, SageMaker HyperPod continuously evolves, incorporating the latest research advancements. This collaborative approach helps SageMaker HyperPod remain at the forefront of AI technology, providing the tools to drive transformative change.
Conclusion
SageMaker HyperPod represents a fundamental change in AI infrastructure, offering a future-fit solution that empowers organizations to unlock the full potential of AI technologies. With its intelligent resource management, versatility, scalability, and forward-thinking design, SageMaker HyperPod enables businesses to accelerate innovation, reduce operational costs, and stay ahead of the curve in the rapidly evolving AI landscape.
Whether it’s optimizing the training of LLMs, processing complex datasets for medical imaging inference, or exploring novel AI architectures, SageMaker HyperPod provides a robust and flexible foundation for organizations to push the boundaries of what is possible in AI.
As AI continues to reshape industries and redefine what is possible, SageMaker HyperPod stands at the forefront, enabling organizations to navigate the complexities of AI workloads with unparalleled agility, efficiency, and innovation. With its commitment to continuous improvement, strategic partnerships, and alignment with emerging technologies, SageMaker HyperPod is poised to play a pivotal role in shaping the future of AI, empowering organizations to unlock new realms of possibility and drive transformative change.
Take the first step towards revolutionizing your AI initiatives by scheduling a consultation with our experts. Let us guide you through the process of harnessing the power of SageMaker HyperPod and unlock a world of possibilities for your business.
About the authors
 Ilan Gleiser is a Principal GenAI Specialist at AWS WWSO Frameworks team focusing on developing scalable Artificial General Intelligence architectures and optimizing foundation model training and inference. With a rich background in AI and machine learning, Ilan has published over 20 blogs and delivered 100+ prototypes globally over the last 5 years. Ilan holds a Master’s degree in mathematical economics.
Ilan Gleiser is a Principal GenAI Specialist at AWS WWSO Frameworks team focusing on developing scalable Artificial General Intelligence architectures and optimizing foundation model training and inference. With a rich background in AI and machine learning, Ilan has published over 20 blogs and delivered 100+ prototypes globally over the last 5 years. Ilan holds a Master’s degree in mathematical economics.
 Trevor Harvey is a Principal Specialist in Generative AI at Amazon Web Services and an AWS Certified Solutions Architect – Professional. Trevor works with customers to design and implement machine learning solutions and leads go-to-market strategies for generative AI services.
Trevor Harvey is a Principal Specialist in Generative AI at Amazon Web Services and an AWS Certified Solutions Architect – Professional. Trevor works with customers to design and implement machine learning solutions and leads go-to-market strategies for generative AI services.
 Shubha Kumbadakone is a Sr. Mgr on the AWS WWSO Frameworks team focusing on Foundation Model Builders and self-managed machine learning with a focus on open-source software and tools. She has more than 19 years of experience in cloud infrastructure and machine learning and is helping customers build their distributed training and inference at scale for their ML models on AWS. She also holds a patent on a caching algorithm for rapid resume from hibernation for mobile systems.
Shubha Kumbadakone is a Sr. Mgr on the AWS WWSO Frameworks team focusing on Foundation Model Builders and self-managed machine learning with a focus on open-source software and tools. She has more than 19 years of experience in cloud infrastructure and machine learning and is helping customers build their distributed training and inference at scale for their ML models on AWS. She also holds a patent on a caching algorithm for rapid resume from hibernation for mobile systems.
 Matt Nightingale is a Solutions Architect Manager on the AWS WWSO Frameworks team focusing on Generative AI Training and Inference. Matt specializes in distributed training architectures with a focus on hardware performance and reliability. Matt holds a bachelors degree from University of Virginia and is based in Boston, Massachusetts.
Matt Nightingale is a Solutions Architect Manager on the AWS WWSO Frameworks team focusing on Generative AI Training and Inference. Matt specializes in distributed training architectures with a focus on hardware performance and reliability. Matt holds a bachelors degree from University of Virginia and is based in Boston, Massachusetts.
Read More

 Rajendra Choudhary is a Sr. Business Analyst at Amazon. With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, data modeling, and data engineering. He is passionate about supporting customers by leveraging generative AI–based solutions. Outside of work, Rajendra is an avid foodie and music enthusiast, and he enjoys swimming and hiking.
Rajendra Choudhary is a Sr. Business Analyst at Amazon. With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, data modeling, and data engineering. He is passionate about supporting customers by leveraging generative AI–based solutions. Outside of work, Rajendra is an avid foodie and music enthusiast, and he enjoys swimming and hiking.






 Vrinda Dabke leads AWS Professional Services North America Delivery. Prior to joining AWS, Vrinda held a variety of leadership roles in Fortune 100 companies like UnitedHealth Group, The Hartford, Aetna, and Pfizer. Her work has been focused on in the areas of business intelligence, analytics, and AI/ML. She is a motivational people leader with experience in leading and managing high-performing global teams in complex matrix organizations.
Vrinda Dabke leads AWS Professional Services North America Delivery. Prior to joining AWS, Vrinda held a variety of leadership roles in Fortune 100 companies like UnitedHealth Group, The Hartford, Aetna, and Pfizer. Her work has been focused on in the areas of business intelligence, analytics, and AI/ML. She is a motivational people leader with experience in leading and managing high-performing global teams in complex matrix organizations. Kannan Raman leads the North America Delivery for AWS Professional Services Healthcare and Life Sciences practice at AWS. He has over 24 years of healthcare and life sciences experience and provides thought leadership in digital transformation. He works with C level customer executives to help them with their digital transformation agenda.
Kannan Raman leads the North America Delivery for AWS Professional Services Healthcare and Life Sciences practice at AWS. He has over 24 years of healthcare and life sciences experience and provides thought leadership in digital transformation. He works with C level customer executives to help them with their digital transformation agenda. Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He helps customers implement big data, machine learning, and analytics solutions. Outside of work, he enjoys spending time with family, reading, running, and playing golf.
Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He helps customers implement big data, machine learning, and analytics solutions. Outside of work, he enjoys spending time with family, reading, running, and playing golf. Bruno Klein is a Senior Machine Learning Engineer with AWS Professional Services Analytics Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and trying new food.
Bruno Klein is a Senior Machine Learning Engineer with AWS Professional Services Analytics Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and trying new food.


 At The Check Up, we unveil how we’re using AI to reshape what’s possible in health and help people live healthier lives.
At The Check Up, we unveil how we’re using AI to reshape what’s possible in health and help people live healthier lives.
 Ubie, a health tech startup in Japan, is using Google AI to change patient — and healthcare worker — experiences for the better.
Ubie, a health tech startup in Japan, is using Google AI to change patient — and healthcare worker — experiences for the better.