 Learn more about Google Research’s FireSat project, built to detect small wildfires.Read More
Learn more about Google Research’s FireSat project, built to detect small wildfires.Read More

Learn more about Google Research’s FireSat project, built to detect small wildfires.Read More

 Learn how our AI Collaboratives for wildfires and food security are taking a new funding approach to help people around the world.Read More
Learn how our AI Collaboratives for wildfires and food security are taking a new funding approach to help people around the world.Read More

 The first satellite for the FireSat constellation officially made contact with Earth. This satellite is the first of more than 50 in a first-of-its-kind constellation de…Read More
The first satellite for the FireSat constellation officially made contact with Earth. This satellite is the first of more than 50 in a first-of-its-kind constellation de…Read More

Learn more about Google Research’s FireSat project, built to detect small wildfires.Read More

GTC is coming back to San Jose on March 17–21, 2025. Join PyTorch Foundation members Arm, AWS, Google Cloud, IBM, Lightning AI, Meta, Microsoft Azure, Snowflake, and thousands of developers as we celebrate PyTorch. Together learn how AI & accelerated computing are helping humanity solve our most complex challenges.
Join in person with discounted GTC registration for PyTorch Foundation or watch online with free registration.

Hear from PyTorch Foundation’s Executive Director Matt White & panelists from UC Berkeley, Meta, NVIDIA, & Sequoia Capital how open source is transforming AI development, bringing together experts from industry, academia, and venture capital to discuss the technical and business aspects of collaborative open source AI development They’ll examine how open source projects like PyTorch, vLLM, Ray, and NVIDIA’s NeMo are accelerating AI innovation while creating new opportunities for businesses and researchers. They’ll share real-world experiences from PyTorch’s development, Berkeley’s research initiatives, and successful AI startups. Take away valuable insights into the technical and business aspects of open source AI. – Monday, Mar 17 10:00 AM – 11:00 AM PDT
The Performance of CUDA with the Flexibility of PyTorch
Mark Saroufim, Software Engineer, Meta Platforms
This talk explores how PyTorch users are also becoming CUDA developers. We’ll start with motivating examples from eager, the launch of torch.compile and the more recent trend of kernel zoos. We will share details on how we went about integrating low bit matmuls in torchao and the torch.compile CUTLASS backend. We’ll also discuss details on how you can define, build and package your own custom ops in PyTorch so you get the raw performance of CUDA while maintaining the flexibility of PyTorch.
Make My PyTorch Model Fast, and Show Me How You Did It
Thomas Viehmann, Principal Research Engineer, Lightning AI
Luca Antiga, CTO, Lightning AI
PyTorch is popular in deep learning and LLMs for richness and ease of expressions. To make the most of compute resources, PyTorch models benefit from nontrivial optimizations, but this means losing some of their ease and understandability. Learn how with Thunder, a PyTorch-to-Python compiler focused on usability, understandability, and extensibility, you can optimize and transform (i.e., distribute across many machines) models while • leaving the PyTorch code unchanged • targeting a variety of models without needing to adapt to each of them • understanding each transformation step because the results are presented as simple Python code • accessing powerful extension code for your own optimizations with just one or a few lines of code We’ll show how the combination of Thunder transforms and the NVIDIA stack (NVFuser, cuDNN, Apex) delivers optimized performance in training and inference on a variety of models.
FlexAttention: The Flexibility of PyTorch With the Performance of FlashAttention
Driss Guessous, Machine Learning Engineer, Meta Platforms
Introducing FlexAttention: a novel PyTorch API that enables custom, user-defined attention mechanisms with performance comparable to state-of-the-art solutions. By leveraging the PyTorch compiler stack, FlexAttention supports dynamic modifications to attention scores within SDPA, achieving both runtime and memory efficiency through kernel fusion with the FlashAttention algorithm. Our benchmarks on A100 GPUs show FlexAttention achieves 90% of FlashAttention2’s performance in forward passes and 85% in backward passes. On H100 GPUs, FlexAttention’s forward performance averages 85% of FlashAttention3 and is ~25% faster than FlashAttention2, while backward performance averages 76% of FlashAttention3 and is ~3% faster than FlashAttention2. Explore how FlexAttention balances near-state-of-the-art performance with unparalleled flexibility, empowering researchers to rapidly iterate on attention mechanisms without sacrificing efficiency.
Keep Your GPUs Going Brrr : Crushing Whitespace in Model Training
Syed Ahmed, Senior Software Engineer, NVIDIA
Alban Desmaison, Research Engineer, Meta
Aidyn Aitzhan, Senior Software Engineer, NVIDIA
Substantial progress has recently been made on the compute-intensive portions of model training, such as high-performing attention variants. While invaluable, this progress exposes previously hidden bottlenecks in model training, such as redundant copies during collectives and data loading time. We’ll present recent improvements in PyTorch achieved through Meta/NVIDIA collaboration to tackle these newly exposed bottlenecks and how practitioners can leverage them.
Accelerated Python: The Community and Ecosystem
Andy Terrel, CUDA Python Product Lead, NVIDIA
Jeremy Tanner, Open Source Programs, NVIDIA
Anshuman Bhat, CUDA Product Management, NVIDIA
Python is everywhere. Simulation, data science, and Gen AI all depend on it. Unfortunately, the dizzying array of tools leaves a newcomer baffled at where to start. We’ll take you on a guided tour of the vibrant community and ecosystem surrounding accelerated Python programming. Explore a variety of tools, libraries, and frameworks that enable efficient computation and performance optimization in Python, including CUDA Python, RAPIDS, Warp, and Legate. We’ll also discuss integration points with PyData, PyTorch, and JAX communities. Learn about collaborative efforts within the community, including open source projects and contributions that drive innovation in accelerated computing. We’ll discuss best practices for leveraging these frameworks to enhance productivity in developing AI-driven applications and conducting large-scale data analyses.
Supercharge large scale AI with Google Cloud AI hypercomputer (Presented by Google Cloud)
Deepak Patil, Product Manager, Google Cloud
Rajesh Anantharaman, Product Management Lead, ML Software, Google Cloud
Unlock the potential of your large-scale AI workloads with Google Cloud AI Hypercomputer – a supercomputing architecture designed for maximum performance and efficiency. In this session, we will deep dive into PyTorch and JAX stacks on Google Cloud on NVIDIA GPUs, and showcase capabilities for high performance foundation model building on Google Cloud.
Peering Into the Future: What AI and Graph Networks Can Mean for the Future of Financial Analysis
Siddharth Samsi, Sr. Solutions Architect, NVIDIA
Sudeep Kesh, Chief Innovation Officer, S&P Global
Artificial Intelligence, agentic systems, and graph neural networks (GNNs) are providing the new frontier to assess, monitor, and estimate opportunities and risks across work portfolios within financial services. Although many of these technologies are still developing, organizations are eager to understand their potential. See how S&P Global and NVIDIA are working together to find practical ways to learn and integrate such capabilities, ranging from forecasting corporate debt issuance to understanding capital markets at a deeper level. We’ll show a graph representation of market data using the PyTorch-Geometric library and a dataset of issuances spanning three decades and across financial and non-financial industries. Technical developments include generation of a bipartite graph and link-prediction GNN forecasting. We’ll address data preprocessing, pipelines, model training, and how these technologies can broaden capabilities in an increasingly complex world.
Unlock Deep Learning Performance on Blackwell With cuDNN
Yang Xu (Enterprise Products), DL Software Engineering Manager, NVIDIA
Since its launch, cuDNN, a library for GPU-accelerating deep learning (DL) primitives, has been powering many AI applications in domains such as conversational AI, recommender systems, and speech recognition, among others. CuDNN remains a core library for DL primitives in popular frameworks such as PyTorch, JAX, Tensorflow, and many more while covering training, fine-tuning, and inference use cases. Even in the rapidly evolving space of Gen AI — be it Llama, Gemma, or mixture-of-experts variants requiring complex DL primitives such as flash attention variants — cuDNN is powering them all. Learn about new/updated APIs of cuDNN pertaining to Blackwell’s microscaling format, and how to program against those APIs. We’ll deep dive into leveraging its graph APIs to build some fusion patterns, such as matmul fusion patterns and fused flash attention from state-of-the-art models. Understand how new CUDA graph support in cuDNN, not to be mistaken with the cuDNN graph API, could be exploited to avoid rebuilding CUDA graphs, offering an alternative to CUDA graph capture with real-world framework usage.
Train and Serve AI Systems Fast With the Lightning AI Open-Source Stack (Presented by Lightning AI)
Luca Antiga, CTO, Lightning AI
See how the Lightning stack can cover the full life cycle, from data preparation to deployment, with practical examples and particular focus on distributed training and high-performance inference. We’ll show examples that focus on new features like support for multi-dimensional parallelism through DTensors, as well as quantization through torchao.
Meet the Experts From Deep Learning Framework Teams
Eddie Yan, Technical Lead of PyTorch, NVIDIA
Masaki Kozuki, Senior Software Engineer in PyTorch, NVIDIA
Patrick Wang (Enterprise Products), Software Engineer in PyTorch, NVIDIA
Mike Ruberry, Distinguished Engineer in Deep Learning Frameworks, NVIDIA
Rishi Puri, Sr. Deep Learning Engineer and Lead for PyTorch Geometric, NVIDIA
Kernel Optimization for AI and Beyond: Unlocking the Power of Nsight Compute
Felix Schmitt, Sr. System Software Engineer, NVIDIA
Peter Labus, Senior System Software Engineer, NVIDIA
Learn how to unlock the full potential of NVIDIA GPUs with the powerful profiling and analysis capabilities of Nsight Compute. AI workloads are rapidly increasing the demand for GPU computing, and ensuring that they efficiently utilize all available GPU resources is essential. Nsight Compute is the most powerful tool for understanding kernel execution behavior and performance. Learn how to configure and launch profiles customized for your needs, including advice on profiling accelerated Python applications, AI frameworks like PyTorch, and optimizing Tensor Core utilization essential to modern AI performance. Learn how to debug your kernel and use the expert system built into Nsight Compute, known as “Guided Analysis,” that automatically detects common issues and directs you to the most relevant performance data all the way down to the source code level.
Make Retrieval Better: Fine-Tuning an Embedding Model for Domain-Specific RAG
Gabriel Moreira, Sr. Research Scientist, NVIDIA
Ronay Ak, Sr. Data Scientist, NVIDIA
LLMs power AI applications like conversational chatbots and content generators, but are constrained by their training data. This might lead to hallucinations in content generation, which requires up-to-date or domain-specific information. Retrieval augmented generation (RAG) addresses this issue by enabling LLMs to access external context without modifying model parameters. Embedding or dense retrieval models are a key component of a RAG pipeline for retrieving relevant context to the LLM. However, an embedding model’s effectiveness to capture the unique characteristics of the custom data hinges on the quality and domain relevance of its training data. Fine-tuning embedding models is gaining interest to provide more accurate and relevant responses tailored to users’ specific domain.
In this lab, you’ll learn to generate a synthetic dataset with question-context pairs from a domain-specific corpus, and process the data for fine-tuning. Then, fine-tune a text embedding model using synthetic data and evaluate it.
Single-View X-Ray 3D Reconstruction Using Neural Back Projection and Frustum Resampling
Tran Minh Quan, Developer Technologist, NVIDIA
Enable Novel Applications in the New AI Area in Medicine: Accelerated Feature Computation for Pathology Slides
Nils Bruenggel, Principal Software Engineer, Roche Diagnostics Int. AG
Computer use is a breakthrough capability from Anthropic that allows foundation models (FMs) to visually perceive and interpret digital interfaces. This capability enables Anthropic’s Claude models to identify what’s on a screen, understand the context of UI elements, and recognize actions that should be performed such as clicking buttons, typing text, scrolling, and navigating between applications. However, the model itself doesn’t execute these actions—it requires an orchestration layer to safely implement the supported actions.
Today, we’re announcing computer use support within Amazon Bedrock Agents using Anthropic’s Claude 3.5 Sonnet V2 and Anthropic’s Claude Sonnet 3.7 models on Amazon Bedrock. This integration brings Anthropic’s visual perception capabilities as a managed tool within Amazon Bedrock Agents, providing you with a secure, traceable, and managed way to implement computer use automation in your workflows.
Organizations across industries struggle with automating repetitive tasks that span multiple applications and systems of record. Whether processing invoices, updating customer records, or managing human resource (HR) documents, these workflows often require employees to manually transfer information between different systems – a process that’s time-consuming, error-prone, and difficult to scale.
Traditional automation approaches require custom API integrations for each application, creating significant development overhead. Computer use capabilities change this paradigm by allowing machines to perceive existing interfaces just as humans.
In this post, we create a computer use agent demo that provides the critical orchestration layer that transforms computer use from a perception capability into actionable automation. Without this orchestration layer, computer use would only identify potential actions without executing them. The computer use agent demo powered by Amazon Bedrock Agents provides the following benefits:
This integration combines Anthropic’s perceptual understanding of digital interfaces with the orchestration capabilities of Amazon Bedrock Agents, creating a powerful agent for automating complex workflows across applications. Rather than build custom integrations for each system, developers can now create agents that perceive and interact with existing interfaces in a managed, secure way.
With computer use, Amazon Bedrock Agents can automate tasks through basic GUI actions and built-in Linux commands. For example, your agent could take screenshots, create and edit text files, and run built-in Linux commands. Using Amazon Bedrock Agents and compatible Anthropic’s Claude models, you can use the following action groups:
An example computer use workflow consists of the following steps:
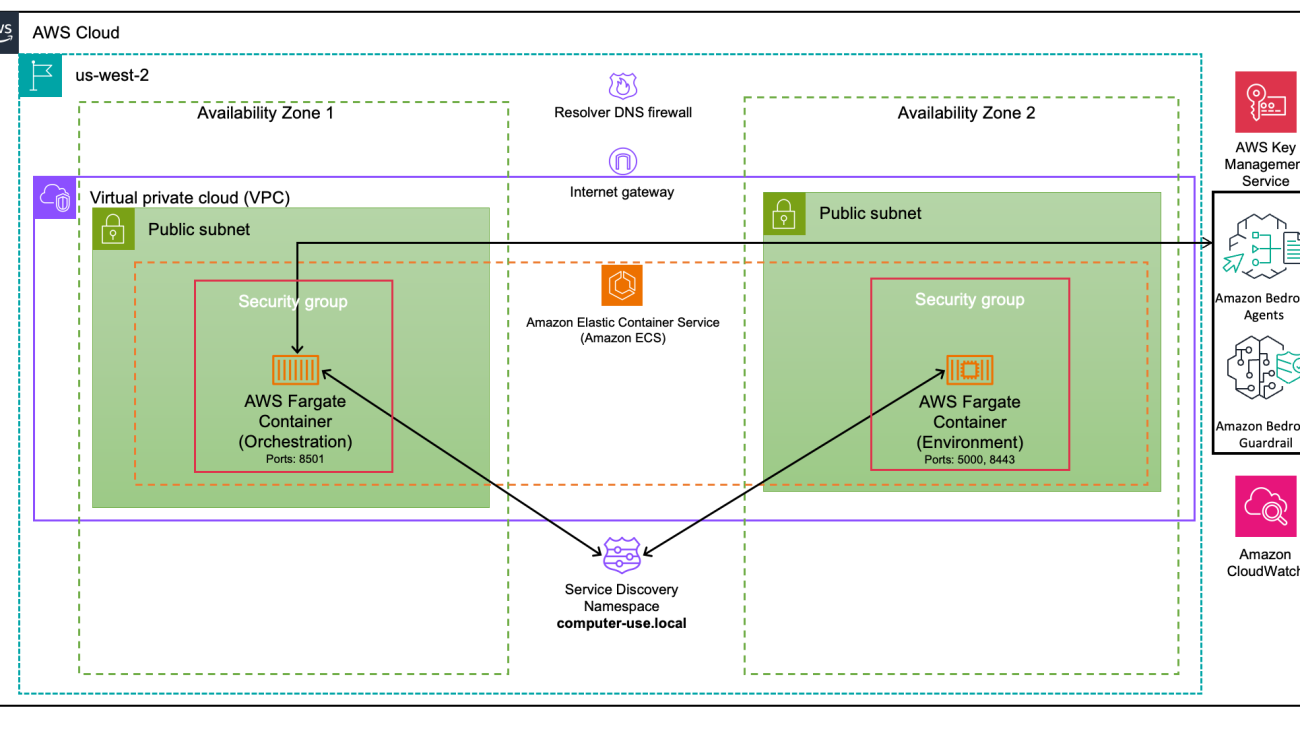
You can recreate this example in the us-west-2 AWS Region with the AWS Cloud Development Kit (AWS CDK) by following the instructions in the GitHub repository. This demo deploys a containerized application using AWS Fargate across two Availability Zones in the us-west-2 Region. The infrastructure operates within a virtual private cloud (VPC) containing public subnets in each Availability Zone, with an internet gateway providing external connectivity. The architecture is complemented by essential supporting services, including AWS Key Management Service (AWS KMS) for security and Amazon CloudWatch for monitoring, creating a resilient, serverless container environment that alleviates the need to manage underlying infrastructure while maintaining robust security and high availability.
The following diagram illustrates the solution architecture.

At the core of our solution are two Fargate containers managed through Amazon Elastic Container Service (Amazon ECS), each protected by its own security group. The first is our orchestration container, which not only handles the communication between Amazon Bedrock Agents and end users, but also orchestrates the workflow that enables tool execution. The second is our environment container, which serves as a secure sandbox where the Amazon Bedrock agent can safely run its computer use tools. The environment container has limited access to the rest of the ecosystem and the internet. We utilize service discovery to connect Amazon ECS services with DNS names.
The orchestration container includes the following components:
The environment container includes the following components:
The following diagram illustrates these components.

You can use the following code sample to create a simple Amazon Bedrock agent with computer, bash, and text editor action groups. It is crucial to provide a compatible action group signature when using Anthropic’s Claude 3.5 Sonnet V2 and Anthropic’s Claude 3.7 Sonnet as highlighted here.
| Model | Action Group Signature |
| Anthropic’s Claude 3.5 Sonnet V2 | computer_20241022 text_editor_20241022 bash_20241022 |
| Anthropic’s Claude 3.7 Sonnet | computer_20250124 text_editor_20250124 bash_20250124 |
In this post, we demonstrate an example where we use Amazon Bedrock Agents with the computer use capability to complete a web form. In the example, the computer use agent can also switch Firefox tabs to interact with a customer relationship management (CRM) agent to get the required information to complete the form. Although this example uses a sample CRM application as the system of record, the same approach works with Salesforce, SAP, Workday, or other systems of record with the appropriate authentication frameworks in place.
In the demonstrated use case, you can observe how well the Amazon Bedrock agent performed with computer use tools. Our implementation completed the customer ID, customer name, and email by visually examining the excel data. However, for the overview, it decided to select the cell and copy the data, because the information wasn’t completely visible on the screen. Finally, the CRM agent was used to get additional information on the customer.
The following are some ways you can improve the performance for your use case:
The computer use feature is made available to you as a beta service as defined in the AWS Service Terms. It is subject to your agreement with AWS and the AWS Service Terms, and the applicable model EULA. Computer use poses unique risks that are distinct from standard API features or chat interfaces. These risks are heightened when using the computer use feature to interact with the internet. To minimize risks, consider taking precautions such as:
Any content that you enable Anthropic’s Claude to see or access can potentially override instructions or cause the model to make mistakes or perform unintended actions. Taking proper precautions, such as isolating Anthropic’s Claude from sensitive surfaces, is essential – including to avoid risks related to prompt injection. Before enabling or requesting permissions necessary to enable computer use features in your own products, inform end users of any relevant risks, and obtain their consent as appropriate.
When you are done using this solution, make sure to clean up all the resources. Follow the instructions in the provided GitHub repository.
Organizations across industries face significant challenges with cross-application workflows that traditionally require manual data entry or complex custom integrations. The integration of Anthropic’s computer use capability with Amazon Bedrock Agents represents a transformative approach to these challenges.
By using Amazon Bedrock Agents as the orchestration layer, organizations can alleviate the need for custom API development for each application, benefit from comprehensive logging and tracing capabilities essential for enterprise deployment, and implement automation solutions quickly.
As you begin exploring computer use with Amazon Bedrock Agents, consider workflows in your organization that could benefit from this approach. From invoice processing to customer onboarding, HR documentation to compliance reporting, the potential applications are vast and transformative.
We’re excited to see how you will use Amazon Bedrock Agents with the computer use capability to securely streamline operations and reimagine business processes through AI-driven automation.
Resources
To learn more, refer to the following resources:
 Eashan Kaushik is a Specialist Solutions Architect AI/ML at Amazon Web Services. He is driven by creating cutting-edge generative AI solutions while prioritizing a customer-centric approach to his work. Before this role, he obtained an MS in Computer Science from NYU Tandon School of Engineering. Outside of work, he enjoys sports, lifting, and running marathons.
Eashan Kaushik is a Specialist Solutions Architect AI/ML at Amazon Web Services. He is driven by creating cutting-edge generative AI solutions while prioritizing a customer-centric approach to his work. Before this role, he obtained an MS in Computer Science from NYU Tandon School of Engineering. Outside of work, he enjoys sports, lifting, and running marathons.
 Maira Ladeira Tanke is a Tech Lead for Agentic workloads in Amazon Bedrock at AWS, where she enables customers on their journey to develop autonomous AI systems. With over 10 years of experience in AI/ML. At AWS, Maira partners with enterprise customers to accelerate the adoption of agentic applications using Amazon Bedrock, helping organizations harness the power of foundation models to drive innovation and business transformation. In her free time, Maira enjoys traveling, playing with her cat, and spending time with her family someplace warm.
Maira Ladeira Tanke is a Tech Lead for Agentic workloads in Amazon Bedrock at AWS, where she enables customers on their journey to develop autonomous AI systems. With over 10 years of experience in AI/ML. At AWS, Maira partners with enterprise customers to accelerate the adoption of agentic applications using Amazon Bedrock, helping organizations harness the power of foundation models to drive innovation and business transformation. In her free time, Maira enjoys traveling, playing with her cat, and spending time with her family someplace warm.
 Raj Pathak is a Principal Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Generative AI, Natural Language Processing, Intelligent Document Processing, and MLOps.
Raj Pathak is a Principal Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Generative AI, Natural Language Processing, Intelligent Document Processing, and MLOps.
 Adarsh Srikanth is a Software Development Engineer at Amazon Bedrock, where he develops AI agent services. He holds a master’s degree in computer science from USC and brings three years of industry experience to his role. He spends his free time exploring national parks, discovering new hiking trails, and playing various racquet sports.
Adarsh Srikanth is a Software Development Engineer at Amazon Bedrock, where he develops AI agent services. He holds a master’s degree in computer science from USC and brings three years of industry experience to his role. He spends his free time exploring national parks, discovering new hiking trails, and playing various racquet sports.
 Abishek Kumar is a Senior Software Engineer at Amazon, bringing over 6 years of valuable experience across both retail and AWS organizations. He has demonstrated expertise in developing generative AI and machine learning solutions, specifically contributing to key AWS services including SageMaker Autopilot, SageMaker Canvas, and AWS Bedrock Agents. Throughout his career, Abishek has shown passion for solving complex problems and architecting large-scale systems that serve millions of customers worldwide. When not immersed in technology, he enjoys exploring nature through hiking and traveling adventures with his wife.
Abishek Kumar is a Senior Software Engineer at Amazon, bringing over 6 years of valuable experience across both retail and AWS organizations. He has demonstrated expertise in developing generative AI and machine learning solutions, specifically contributing to key AWS services including SageMaker Autopilot, SageMaker Canvas, and AWS Bedrock Agents. Throughout his career, Abishek has shown passion for solving complex problems and architecting large-scale systems that serve millions of customers worldwide. When not immersed in technology, he enjoys exploring nature through hiking and traveling adventures with his wife.
 Krishna Gourishetti is a Senior Software Engineer for the Bedrock Agents team in AWS. He is passionate about building scalable software solutions that solve customer problems. In his free time, Krishna loves to go on hikes.
Krishna Gourishetti is a Senior Software Engineer for the Bedrock Agents team in AWS. He is passionate about building scalable software solutions that solve customer problems. In his free time, Krishna loves to go on hikes.
Organizations building and deploying AI applications, particularly those using large language models (LLMs) with Retrieval Augmented Generation (RAG) systems, face a significant challenge: how to evaluate AI outputs effectively throughout the application lifecycle. As these AI technologies become more sophisticated and widely adopted, maintaining consistent quality and performance becomes increasingly complex.
Traditional AI evaluation approaches have significant limitations. Human evaluation, although thorough, is time-consuming and expensive at scale. Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Furthermore, traditional automated evaluation metrics typically require ground truth data, which for many AI applications is difficult to obtain. Especially for those involving open-ended generation or retrieval augmented systems, defining a single “correct” answer is practically impossible. Finally, metrics such as ROUGE and F1 can be fooled by shallow linguistic similarities (word overlap) between the ground truth and the LLM response, even when the actual meaning is very different. These challenges make it difficult for organizations to maintain consistent quality standards across their AI applications, particularly for generative AI outputs.
Amazon Bedrock has recently launched two new capabilities to address these evaluation challenges: LLM-as-a-judge (LLMaaJ) under Amazon Bedrock Evaluations and a brand new RAG evaluation tool for Amazon Bedrock Knowledge Bases. Both features rely on the same LLM-as-a-judge technology under the hood, with slight differences depending on if a model or a RAG application built with Amazon Bedrock Knowledge Bases is being evaluated. These evaluation features combine the speed of automated methods with human-like nuanced understanding, enabling organizations to:
These capabilities integrate seamlessly into the AI development lifecycle, empowering organizations to improve model and application quality, promote responsible AI practices, and make data-driven decisions about model selection and application deployment.
This post focuses on RAG evaluation with Amazon Bedrock Knowledge Bases, provides a guide to set up the feature, discusses nuances to consider as you evaluate your prompts and responses, and finally discusses best practices. By the end of this post, you will understand how the latest Amazon Bedrock evaluation features can streamline your approach to AI quality assurance, enabling more efficient and confident development of RAG applications.
Before diving into the implementation details, we examine the key features that make the capabilities of RAG evaluation on Amazon Bedrock Knowledge Bases particularly powerful. The key features are:
These features enable organizations to comprehensively assess AI performance, promote responsible AI development, and make informed decisions about model selection and optimization throughout the AI application lifecycle. Now that we’ve explained the key features, we examine how these capabilities come together in a practical implementation.
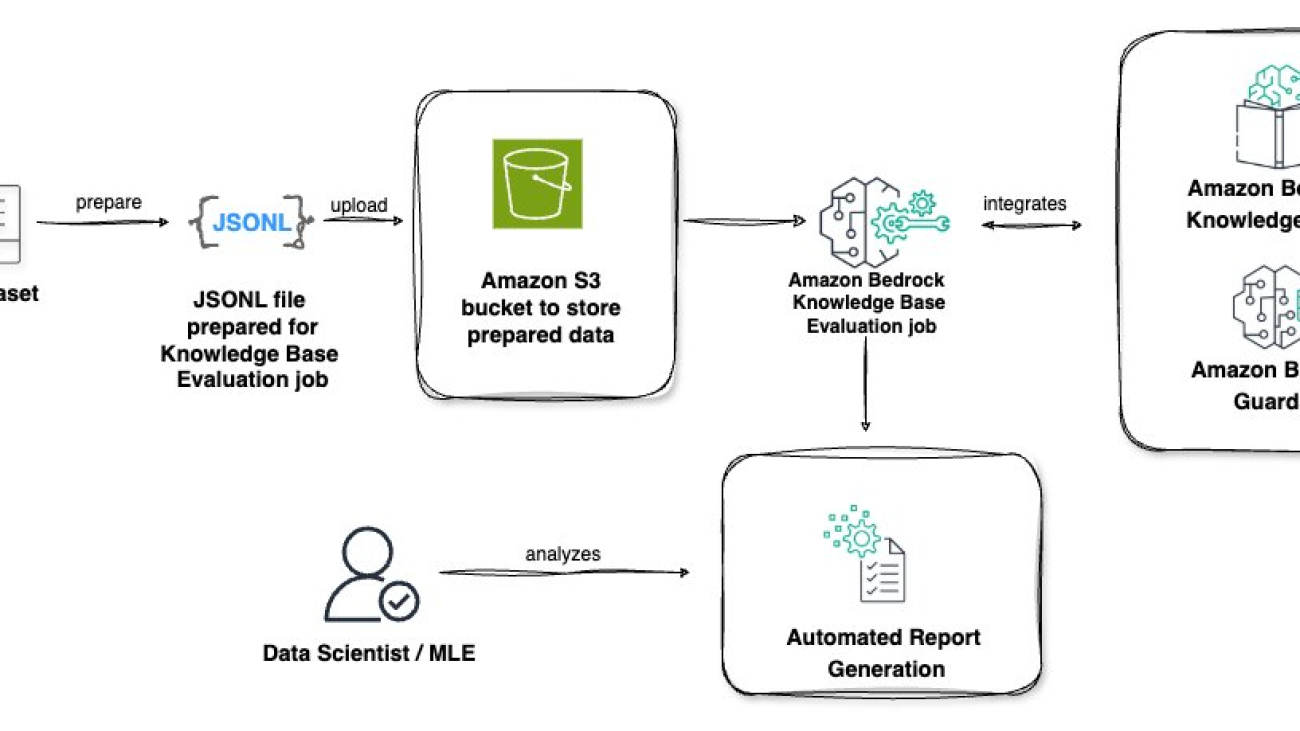
The Amazon Bedrock Knowledge Bases RAG evaluation feature provides a comprehensive, end-to-end solution for assessing and optimizing RAG applications. This automated process uses the power of LLMs to evaluate both retrieval and generation quality, offering insights that can significantly improve your AI applications.
The workflow is as follows, as shown moving from left to right in the following architecture diagram:

RAG system evaluation requires a balanced approach that considers three key aspects: cost, speed, and quality. Although Amazon Bedrock Evaluations primarily focuses on quality metrics, understanding all three components helps create a comprehensive evaluation strategy. The following diagram shows how these components interact and feed into a comprehensive evaluation strategy, and the next sections examine each component in detail.

The efficiency of RAG systems depends on model selection and usage patterns. Costs are primarily driven by data retrieval and token consumption during retrieval and generation, and speed depends on model size and complexity as well as prompt and context size. For applications requiring high performance content generation with lower latency and costs, model distillation can be an effective solution to use for creating a generator model, for example. As a result, you can create smaller, faster models that maintain quality of larger models for specific use cases.
Amazon Bedrock knowledge base evaluation provides comprehensive insights through various quality dimensions:
Begin your evaluation process by choosing default configurations in your knowledge base (vector or graph database), such as default chunking strategies, embedding models, and prompt templates. These are just some of the possible options. This approach establishes a baseline performance, helping you understand your RAG system’s current effectiveness across available evaluation metrics before optimization. Next, create a diverse evaluation dataset. Make sure this dataset contains a diverse set of queries and knowledge sources that accurately reflect your use case. The diversity of this dataset will provide a comprehensive view of your RAG application performance in production.
Understanding how different components affect these metrics enables informed decisions about:
Implement a systematic approach to ongoing evaluation:
To use the knowledge base evaluation feature, make sure that you have satisfied the following requirements:
To prepare your dataset for a knowledge base evaluation job, you need to follow two important steps:
conversationTurns key in the dataset format).jsonl extension)Special note: On March 20, 2025, the referenceContexts key will change to referenceResponses. The content of referenceResponses should be the expected ground truth answer that an end-to-end RAG system would have generated given the prompt, not the expected passages/chunks retrieved from the Knowledge Base.
Amazon Bedrock Evaluations provides you with an option to run an evaluation job through a guided user interface on the console. To start an evaluation job through the console, follow these steps:


 The following screenshot shows the Configurations screen.
The following screenshot shows the Configurations screen.






On the Evaluation details tab, examine score distributions through histograms for each evaluation metric, showing average scores and percentage differences. Hover over the histogram bars to check the number of conversations in each score range, helping identify patterns in performance, as shown in the following screenshots.


To use the Python SDK for creating a knowledge base evaluation job, follow these steps. First, set up the required configurations:
For retrieval-only evaluation, create a job that focuses on assessing the quality of retrieved contexts:
For a complete evaluation of both retrieval and generation, use this configuration:
To monitor the progress of your evaluation job, use this configuration:
After your evaluation jobs are completed, Amazon Bedrock RAG evaluation provides a detailed comparative dashboard across the evaluation dimensions.

The evaluation dashboard includes comprehensive metrics, but we focus on one example, the completeness histogram shown below. This visualization represents how well responses cover all aspects of the questions asked. In our example, we notice a strong right-skewed distribution with an average score of 0.921. The majority of responses (15) scored above 0.9, while a small number fell in the 0.5-0.8 range. This type of distribution helps quickly identify if your RAG system has consistent performance or if there are specific cases needing attention.


Selecting specific score ranges in the histogram reveals detailed conversation analyses. For each conversation, you can examine the input prompt, generated response, number of retrieved chunks, ground truth comparison, and most importantly, the detailed score explanation from the evaluator model.
Consider this example response that scored 0.75 for the question, “What are some risks associated with Amazon’s expansion?” Although the generated response provided a structured analysis of operational, competitive, and financial risks, the evaluator model identified missing elements around IP infringement and foreign exchange risks compared to the ground truth. This detailed explanation helps in understanding not just what’s missing, but why the response received its specific score.
This granular analysis is crucial for systematic improvement of your RAG pipeline. By understanding patterns in lower-performing responses and specific areas where context retrieval or generation needs improvement, you can make targeted optimizations to your system—whether that’s adjusting retrieval parameters, refining prompts, or modifying knowledge base configurations.
These best practices help build a solid foundation for your RAG evaluation strategy:
To help you dive deeper into the scientific validation of these practices, we’ll be publishing a technical deep-dive post that explores detailed case studies using public datasets and internal AWS validation studies. This upcoming post will examine how our evaluation framework performs across different scenarios and demonstrate its correlation with human judgments across various evaluation dimensions. Stay tuned as we explore the research and validation that powers Amazon Bedrock Evaluations.
Amazon Bedrock knowledge base RAG evaluation enables organizations to confidently deploy and maintain high-quality RAG applications by providing comprehensive, automated assessment of both retrieval and generation components. By combining the benefits of managed evaluation with the nuanced understanding of human assessment, this feature allows organizations to scale their AI quality assurance efficiently while maintaining high standards. Organizations can make data-driven decisions about their RAG implementations, optimize their knowledge bases, and follow responsible AI practices through seamless integration with Amazon Bedrock Guardrails.
Whether you’re building customer service solutions, technical documentation systems, or enterprise knowledge base RAG, Amazon Bedrock Evaluations provides the tools needed to deliver reliable, accurate, and trustworthy AI applications. To help you get started, we’ve prepared a Jupyter notebook with practical examples and code snippets. You can find it on our GitHub repository.
We encourage you to explore these capabilities in the Amazon Bedrock console and discover how systematic evaluation can enhance your RAG applications.
 Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
 Ayan Ray is a Senior Generative AI Partner Solutions Architect at AWS, where he collaborates with ISV partners to develop integrated Generative AI solutions that combine AWS services with AWS partner products. With over a decade of experience in Artificial Intelligence and Machine Learning, Ayan has previously held technology leadership roles at AI startups before joining AWS. Based in the San Francisco Bay Area, he enjoys playing tennis and gardening in his free time.
Ayan Ray is a Senior Generative AI Partner Solutions Architect at AWS, where he collaborates with ISV partners to develop integrated Generative AI solutions that combine AWS services with AWS partner products. With over a decade of experience in Artificial Intelligence and Machine Learning, Ayan has previously held technology leadership roles at AI startups before joining AWS. Based in the San Francisco Bay Area, he enjoys playing tennis and gardening in his free time.
 Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
 Evangelia Spiliopoulou is an Applied Scientist in the AWS Bedrock Evaluation group, where the goal is to develop novel methodologies and tools to assist automatic evaluation of LLMs. Her overall work focuses on Natural Language Processing (NLP) research and developing NLP applications for AWS customers, including LLM Evaluations, RAG, and improving reasoning for LLMs. Prior to Amazon, Evangelia completed her Ph.D. at Language Technologies Institute, Carnegie Mellon University.
Evangelia Spiliopoulou is an Applied Scientist in the AWS Bedrock Evaluation group, where the goal is to develop novel methodologies and tools to assist automatic evaluation of LLMs. Her overall work focuses on Natural Language Processing (NLP) research and developing NLP applications for AWS customers, including LLM Evaluations, RAG, and improving reasoning for LLMs. Prior to Amazon, Evangelia completed her Ph.D. at Language Technologies Institute, Carnegie Mellon University.
 Jesse Manders is a Senior Product Manager on Amazon Bedrock, the AWS Generative AI developer service. He works at the intersection of AI and human interaction with the goal of creating and improving generative AI products and services to meet our needs. Previously, Jesse held engineering team leadership roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the University of Florida, and an MBA from the University of California, Berkeley, Haas School of Business.
Jesse Manders is a Senior Product Manager on Amazon Bedrock, the AWS Generative AI developer service. He works at the intersection of AI and human interaction with the goal of creating and improving generative AI products and services to meet our needs. Previously, Jesse held engineering team leadership roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the University of Florida, and an MBA from the University of California, Berkeley, Haas School of Business.
Speech foundation models, such as HuBERT and its variants, are pre-trained on large amounts of unlabeled speech data and then used for a range of downstream tasks. These models use a masked prediction objective, where the model learns to predict information about masked input segments from the unmasked context. The choice of prediction targets in this framework impacts their performance on downstream tasks. For instance, models pre-trained with targets that capture prosody learn representations suited for speaker-related tasks, while those pre-trained with targets that capture phonetics learn…Apple Machine Learning Research
 Google shares policy recommendations in response to OSTP’s request for information for the U.S. AI Action Plan.Read More
Google shares policy recommendations in response to OSTP’s request for information for the U.S. AI Action Plan.Read More
This post was co-written with Vishal Singh, Data Engineering Leader at Data & Analytics team of GoDaddy
Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) in these solutions has become increasingly popular. However, inference of LLMs as single model invocations or API calls doesn’t scale well with many applications in production.
With batch inference, you can run multiple inference requests asynchronously to process a large number of requests efficiently. You can also use batch inference to improve the performance of model inference on large datasets.
This post provides an overview of a custom solution developed by the for GoDaddy, a domain registrar, registry, web hosting, and ecommerce company that seeks to make entrepreneurship more accessible by using generative AI to provide personalized business insights to over 21 million customers—insights that were previously only available to large corporations. In this collaboration, the Generative AI Innovation Center team created an accurate and cost-efficient generative AI–based solution using batch inference in Amazon Bedrock, helping GoDaddy improve their existing product categorization system.
GoDaddy wanted to enhance their product categorization system that assigns categories to products based on their names. For example:
GoDaddy used an out-of-the-box Meta Llama 2 model to generate the product categories for six million products where a product is identified by an SKU. The generated categories were often incomplete or mislabeled. Moreover, employing an LLM for individual product categorization proved to be a costly endeavor. Recognizing the need for a more precise and cost-effective solution, GoDaddy sought an alternative approach that was a more accurate and cost-efficient way for product categorization to improve their customer experience.
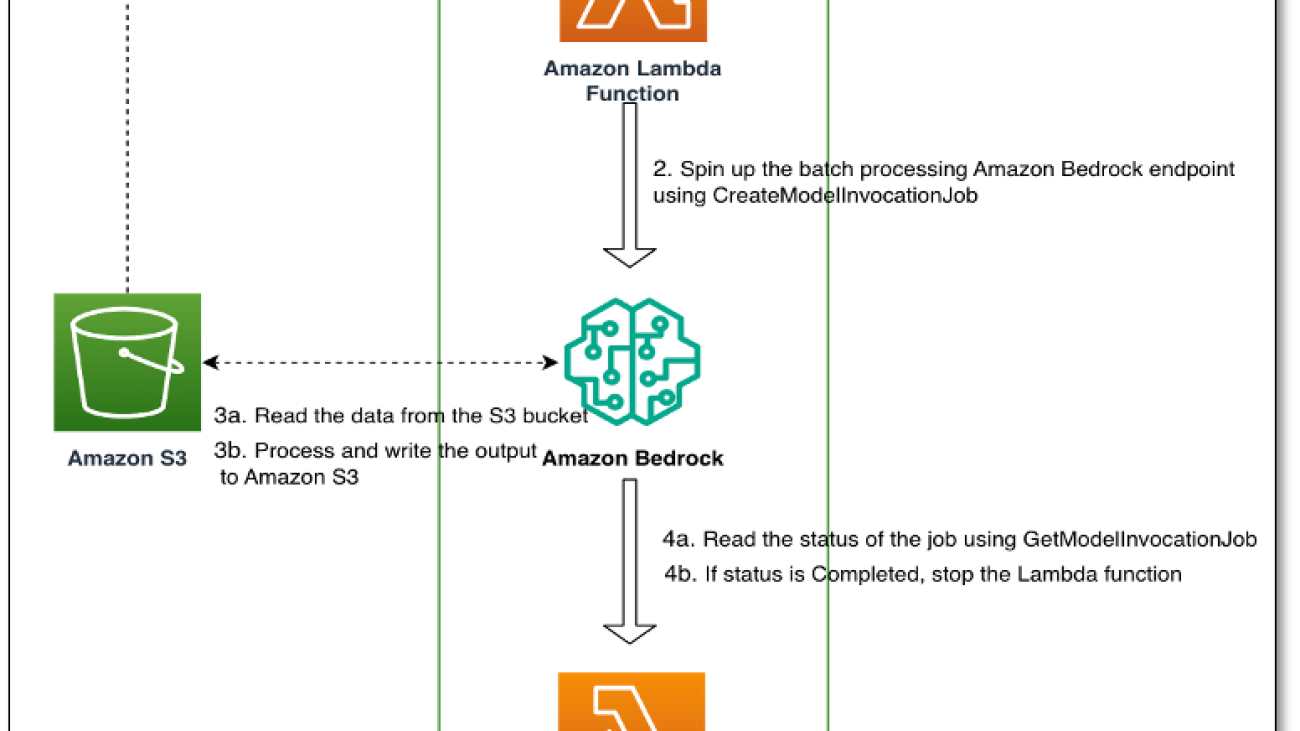
This solution uses the following components to categorize products more accurately and efficiently:
The key steps are illustrated in the following figure:
model_output value appended to each row, corresponding to the input data.The security measures are inherently integrated into the AWS services employed in this architecture. For detailed information, refer to the Security Best Practices section of this post.

We used a dataset that consisted of 30 labeled data points and 100,000 unlabeled test data points. The labeled data points were generated by llama2-7b and verified by a human subject matter expert (SME). As shown in the following screenshot of the sample ground truth, some fields have N/A or missing values, which isn’t ideal because GoDaddy wants a solution with high coverage for downstream predictive modeling. Higher coverage for each possible field can provide more business insights to their customers.

The distribution for the number of words or tokens per SKU shows mild outlier concern, suitable for bundling many products to be categorized in the prompts and potentially more efficient model response.

The solution delivers a comprehensive framework for generating insights within GoDaddy’s product categorization system. It’s designed to be compatible with a range of LLMs on Amazon Bedrock, features customizable prompt templates, and supports batch and real-time (online) inferences. Additionally, the framework includes evaluation metrics that can be extended to accommodate changes in accuracy requirements.
In the following sections, we look at the key components of the solution in more detail.
We used Amazon Bedrock for batch inference processing. Amazon Bedrock provides the CreateModelInvocationJob API to create a batch job with a unique job name. This API returns a response containing jobArn. Refer to the following code:
We can monitor the job status using GetModelInvocationJob with the jobArn returned on job creation. The following are valid statuses during the lifecycle of a job:
modelOutput. If it was a 4xx error, it’s written in the metadata of the Job.CreateModelInvocationJob in outputDataConfig.StopModelInvocationJob API is called on a job that is InProgress. A terminal state job (Succeeded or Failed) can’t be stopped using StopModelInvocationJob.The following is example code for the GetModelInvocationJob API:
When the job is complete, the S3 path specified in s3OutputDataConfig will contain a new folder with an alphanumeric name. The folder contains two files:
modelOutput contains a list of categories for a given product name in JSON format.
We then process the jsonl.out file in Amazon S3. This file is parsed using LangChain’s PydanticOutputParser to generate a .csv file. The PydanticOutputParser requires a schema to be able to parse the JSON generated by the LLM. We created a CCData class that contains the list of categories to be generated for each product as shown in the following code example. Because we enable n-packing, we wrap the schema with a List, as defined in List_of_CCData.
We also use OutputFixingParser to handle situations where the initial parsing attempt fails. The following screenshot shows a sample generated .csv file.

Prompt engineering involves the skillful crafting and refining of input prompts. This process entails choosing the right words, phrases, sentences, punctuation, and separator characters to efficiently use LLMs for diverse applications. Essentially, prompt engineering is about effectively interacting with an LLM. The most effective strategy for prompt engineering needs to vary based on the specific task and data, specifically, data card generation and GoDaddy SKUs.
Prompts consist of particular inputs from the user that direct LLMs to produce a suitable response or output based on a specified task or instruction. These prompts include several elements, such as the task or instruction itself, the surrounding context, full examples, and the input text that guides LLMs in crafting their responses. The composition of the prompt will vary based on factors like the specific use case, data availability, and the nature of the task at hand. For example, in a Retrieval Augmented Generation (RAG) use case, we provide additional context and add a user-supplied query in the prompt that asks the LLM to focus on contexts that can answer the query. In a metadata generation use case, we can provide the image and ask the LLM to generate a description and keywords describing the image in a specific format.
In this post, we briefly distribute the prompt engineering solutions into two steps: output generation and format parsing.
The following are best practices and considerations for output generation:
The following are best practices and considerations for format parsing:
You are a Product Information Manager, Taxonomist, and Categorization Expert who follows instruction well.
EVERY category information needs to be filled based on BOTH product name AND your best guess. If you forget to generate any category information, leave it as missing or N/A, then an innocent people will die.
Format your output in the JSON format (ensure to escape special character):
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
{“properties”: {“list_of_dict”: {“title”: “List Of Dict”, “type”: “array”, “items”: {“$ref”: “#/definitions/CCData”}}}, “required”: [“list_of_dict”], “definitions”: {“CCData”: {“title”: “CCData”, “type”: “object”, “properties”: {“product_name”: {“title”: “Product Name”, “description”: “product name, which will be given as input”, “type”: “string”}, “brand”: {“title”: “Brand”, “description”: “Brand of the product inferred from the product name”, “type”: “string”}, “color”: {“title”: “Color”, “description”: “Color of the product inferred from the product name”, “type”: “string”}, “material”: {“title”: “Material”, “description”: “Material of the product inferred from the product name”, “type”: “string”}, “price”: {“title”: “Price”, “description”: “Price of the product inferred from the product name”, “type”: “string”}, “category”: {“title”: “Category”, “description”: “Category of the product inferred from the product name”, “type”: “string”}, “sub_category”: {“title”: “Sub Category”, “description”: “Sub-category of the product inferred from the product name”, “type”: “string”}, “product_line”: {“title”: “Product Line”, “description”: “Product Line of the product inferred from the product name”, “type”: “string”}, “gender”: {“title”: “Gender”, “description”: “Gender of the product inferred from the product name”, “type”: “string”}, “year_of_first_sale”: {“title”: “Year Of First Sale”, “description”: “Year of first sale of the product inferred from the product name”, “type”: “string”}, “season”: {“title”: “Season”, “description”: “Season of the product inferred from the product name”, “type”: “string”}}}}}
We used the following prompting parameters:
For Llama 2, the model choices were meta.llama2-13b-chat-v1 or meta.llama2-70b-chat-v1. We used the following LLM parameters:
For Anthropic’s Claude, the model choices were anthropic.claude-instant-v1 and anthropic.claude-v2. We used the following LLM parameters:
The solution is straightforward to extend to other LLMs hosted on Amazon Bedrock, such as Amazon Titan (switch the model ID to amazon.titan-tg1-large, for example), Jurassic (model ID ai21.j2-ultra), and more.
The framework includes evaluation metrics that can be extended further to accommodate changes in accuracy requirements. Currently, it involves five different metrics:
The following are the approximate sample input and output lengths under some best performing settings:
The following table summarizes our consolidated quantitative results.
| Config | Latency | Accuracy | ||||||
| Batch process service | Model | Prompt | Batch process latency (5 packing) | Near-real-time process latency (1 packing) | Programmatic evaluation (coverage) | |||
| test set = 20 | test set = 5k | GoDaddy rqmt @ 5k | Recall on parsing exact match | Final content coverage | ||||
| Amazon Bedrock batch inference | Llama2-13b | zero-shot | n/a | n/a | 3600s | n/a | n/a | n/a |
| 5-shot (template12) | 65.4s | 1704s | 3600s | 72/20=3.6s | 92.60% | 53.90% | ||
| Llama2-70b | zero-shot | n/a | n/a | 3600s | n/a | n/a | n/a | |
| 5-shot (template13) | 139.6s | 5299s | 3600s | 156/20=7.8s | 98.30% | 61.50% | ||
| Claude-v1 (instant) | zero-shot (template6) | 29s | 723s | 3600s | 44.8/20=2.24s | 98.50% | 96.80% | |
| 5-shot (template12) | 30.3s | 644s | 3600s | 51/20=2.6s | 99% | 84.40% | ||
| Claude-v2 | zero-shot (template6) | 82.2s | 1706s | 3600s | 104/20=5.2s | 99% | 84.40% | |
| 5-shot (template14) | 49.1s | 1323s | 3600s | 104/20=5.2s | 99.40% | 90.10% | ||
The following tables summarize the scaling effect in batch inference.
| Batch process service | Model | Prompt | Batch process latency (5 packing) | Near-real-time process latency (1 packing) | |||
| test set = 20 | test set = 5k | GoDaddy rqmt @ 5k | test set = 100k | ||||
| Amazon Bedrock batch | Claude-v1 (instant) | zero-shot (template6) | 29s | 723s | 3600s | 5733s | 44.8/20=2.24s |
| Amazon Bedrock batch | Anthropic’s Claude-v2 | zero-shot (template6) | 82.2s | 1706s | 3600s | 7689s | 104/20=5.2s |
| Batch process service | Near-real-time process latency (1 packing) | Programmatic evaluation (coverage) | |||
| Parsing recall on product name (test set = 5k) | Parsing recall on product name (test set = 100k) | Final content coverage (test set = 5k) | Final content coverage (test set = 100k) | ||
| Amazon Bedrock batch | 44.8/20=2.24s | 98.50% | 98.40% | 96.80% | 96.50% |
| Amazon Bedrock batch | 104/20=5.2s | 99% | 98.80% | 84.40% | 97% |
The following table summarizes the effect of n-packing. Llama 2 has an output length limit of 2,048 and fits up to around 20 packing. Anthropic’s Claude has a higher limit. We tested on 20 ground truth samples for 1, 5, and 10 packing and selected results from all model and prompt templates. The scaling effect on latency was more obvious in the Anthropic’s Claude model family than Llama 2. Anthropic’s Claude had better generalizability than Llama 2 when extending the packing numbers in output.
We only tried a few shots with Llama 2 models, which showed improved accuracy over zero-shot.
| Batch process service | Model | Prompt | Latency (test set = 20) | Accuracy (final coverage) | ||||
| npack = 1 | npack= 5 | npack = 10 | npack = 1 | npack= 5 | npack = 10 | |||
| Amazon Bedrock batch inference | Llama2-13b | 5-shot (template12) | 72s | 65.4s | 65s | 95.90% | 93.20% | 88.90% |
| Llama2-70b | 5-shot (template13) | 156s | 139.6s | 150s | 85% | 97.70% | 100% | |
| Claude-v1 (instant) | zero-shot (template6) | 45s | 29s | 27s | 99.50% | 99.50% | 99.30% | |
| 5-shot (template12) | 51.3s | 30.3s | 27.4s | 99.50% | 99.50% | 100% | ||
| Claude-v2 | zero-shot (template6) | 104s | 82.2s | 67s | 85% | 97.70% | 94.50% | |
| 5-shot (template14) | 104s | 49.1s | 43.5s | 97.70% | 100% | 99.80% |
We noted the following qualitative results:
llama2-13b-chat-v1, or they should all be invoked to anthropic.claude-instant-v1. However, GoDaddy chose Llama 2 as the LLM for category generation. For this use case, we found that using Llama 2 in output generation only and using Anthropic’s Claude in format parsing was suitable due to Llama 2’s relative lower model capability.format_instruction() in zero-shot prompts.\“), which can incur significant parsing time and cost and also degrade accuracy.format_instruction(). It shortens the input length, and is therefore more cost-effective. It also shows Anthropic’s Claude’s better capability in following instructions.We had the following key business takeaways:
We had the following key technical takeaways:
The following are the recommendations that the GoDaddy team is considering as a part of future steps:
In this post, we shared how the Generative AI Innovation Center team worked with GoDaddy to create a more accurate and cost-efficient generative AI–based solution using batch inference in Amazon Bedrock, helping GoDaddy improve their existing product categorization system. We implemented n-packing techniques and used Anthropic’s Claude and Meta Llama 2 models to improve latency. We experimented with different prompts to improve the categorization with LLMs and found that Anthropic’s Claude model family gave the better accuracy and generalizability than the Llama 2 model family. GoDaddy team will test this solution on a larger dataset and evaluate the categories generated from the recommended approaches.
If you’re interested in working with the AWS Generative AI Innovation Center, please reach out.
 Vishal Singh is a Data Engineering leader at the Data and Analytics team of GoDaddy. His key focus area is towards building data products and generating insights from them by application of data engineering tools along with generative AI.
Vishal Singh is a Data Engineering leader at the Data and Analytics team of GoDaddy. His key focus area is towards building data products and generating insights from them by application of data engineering tools along with generative AI.
 Yun Zhou is an Applied Scientist at AWS where he helps with research and development to ensure the success of AWS customers. He works on pioneering solutions for various industries using statistical modeling and machine learning techniques. His interest includes generative models and sequential data modeling.
Yun Zhou is an Applied Scientist at AWS where he helps with research and development to ensure the success of AWS customers. He works on pioneering solutions for various industries using statistical modeling and machine learning techniques. His interest includes generative models and sequential data modeling.
 Meghana Ashok is a Machine Learning Engineer at the Generative AI Innovation Center. She collaborates closely with customers, guiding them in developing secure, cost-efficient, and resilient solutions and infrastructure tailored to their generative AI needs.
Meghana Ashok is a Machine Learning Engineer at the Generative AI Innovation Center. She collaborates closely with customers, guiding them in developing secure, cost-efficient, and resilient solutions and infrastructure tailored to their generative AI needs.
 Karan Sindwani is an Applied Scientist at AWS where he works with AWS customers across different verticals to accelerate their use of Gen AI and AWS Cloud services to solve their business challenges.
Karan Sindwani is an Applied Scientist at AWS where he works with AWS customers across different verticals to accelerate their use of Gen AI and AWS Cloud services to solve their business challenges.
 Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he uses his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he uses his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.