Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. Amazon Bedrock Knowledge Bases offers fully managed, end-to-end Retrieval Augmented Generation (RAG) workflows to create highly accurate, low-latency, secure, and custom generative AI applications by incorporating contextual information from your company’s data sources.
Organizations need to control access to their data across different business units, including companies, departments, or even individuals, while maintaining scalability. When organizations try to separate data sources manually, they often create unnecessary complexity and hit service limitations. This post demonstrates how Amazon Bedrock Knowledge Bases can help you scale your data management effectively while maintaining proper access controls on different management levels.
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities.
Organizing S3 folder structures for scalable knowledge bases
Organizations working with multiple customers need a secure and scalable way to keep each customer’s data separate while maintaining efficient access controls. Without proper data segregation, companies risk exposing sensitive information between customers or creating complex, hard-to-maintain systems. For this post, we focus on maintaining access controls across multiple business units within the same management level.
A key strategy involves using S3 folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segregation within a single knowledge base. Instead of creating separate knowledge bases for each customer, you can use a consolidated knowledge base with a well-structured S3 folder hierarchy. For example, imagine a consulting firm that manages documentation for multiple healthcare providers—each customer’s sensitive patient records and operational documents must remain strictly separated. The Amazon S3 structure might look as follows:
s3://amzn-s3-demo-my-knowledge-base-bucket/customer-data/
s3://amzn-s3-demo-my-knowledge-base-bucket/customer-data/customerA/
s3://amzn-s3-demo-my-knowledge-base-bucket/customer-data/customerA/policies/
s3://amzn-s3-demo-my-knowledge-base-bucket/customer-data/customerA/procedures/
s3://amzn-s3-demo-my-knowledge-base-bucket/customer-data/customerB/
s3://amzn-s3-demo-my-knowledge-base-bucket/customer-data/customerB/policies/
s3://amzn-s3-demo-my-knowledge-base-bucket/customer-data/customerB/procedures/
This structure makes sure that Customer A’s healthcare documentation remains completely separate from Customer B’s data. When combined with Amazon Bedrock Knowledge Bases metadata filtering, you can verify that users associated with Customer A can only access their organization’s documents, and Customer B’s users can only see their own data—maintaining strict data boundaries while using a single, efficient knowledge base infrastructure.
The Amazon Bedrock Knowledge Bases metadata filtering capability enhances this segregation by allowing you to tag documents with customer-specific identifiers and other relevant attributes. These metadata filters provide an additional layer of security and organization, making sure that queries only return results from the appropriate customer’s dataset.
Solution overview
The following diagram provides a high-level overview of AWS services and features through a sample use case. Although the example uses Customer A and Customer B for illustration, these can represent distinct business units (such as departments, companies, or teams) with different compliance requirements, rather than only individual customers.

The workflow consists of the following steps:
- Customer data is uploaded along with metadata indicating data ownership and other properties to specific folders in an S3 bucket.
- The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source. Amazon Bedrock Knowledge Bases ingests the data, along with the metadata, from the source repository and a knowledge base sync is performed.
- A customer initiates a query using a frontend application with metadata filters against the Amazon Bedrock knowledge base. An access control metadata filter must be in place to make sure that the customer only accesses data they own; the customer can apply additional filters to further refine query results. This combined query and filter is passed to the
RetrieveAndGenerate API.
- The
RetrieveAndGenerate API handles the core RAG workflow. It consists of several sub-steps:
- The user query is converted into a vector representation (embedding).
- Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base.
- The original query is augmented with the retrieved documents, providing context for the large language model (LLM).
- The LLM generates a response based on the augmented query and retrieved context.
- Finally, the generated response is sent back to the user.
When implementing Amazon Bedrock Knowledge Bases in scenarios involving sensitive information or requiring access controls, developers must implement proper metadata filtering in their application code. Failure to enforce appropriate metadata-based filtering could result in unauthorized access to sensitive documents within the knowledge base. Metadata filtering serves as a critical security boundary and should be consistently applied across all queries. For comprehensive guidance on implementing secure metadata filtering practices, refer to the Amazon Bedrock Knowledge Base Security documentation.
Implement metadata filtering
For this use case, two specific example customers, Customer A and Customer B, are aligned to different proprietary compliance documents. The number of customers and folders can scale to N depending on the size of the customer base. We will use the following public documents, which will reside in the respective customer’s S3 folder. Customer A requires the Architecting for HIPAA Security and Compliance on AWS document. Customer B requires access to the Using AWS in the Context of NHS Cloud Security Guidance document.
- Create a JSON file representing the corresponding metadata for both Customer A and Customer B:
The following is the JSON metadata for Customer A’s data:
{ "metadataAttributes": { "customer": "CustomerA", "documentType": "HIPAA Compliance Guide", "focus": "HIPAA Compliance", "publicationYear": 2022, "region": "North America" }}
The following is the JSON metadata for Customer B’s data:
{ "metadataAttributes": { "customer": "CustomerB", "documentType": "NHS Compliance Guidance", "focus": "UK Healthcare Compliance", "publicationYear": 2023, "region": "Europe" }}
- Save these files separately with the naming convention <filename>.pdf.metadata.JSON and store them in the same S3 folder or prefix that stores the source document. For Customer A, name the metadata file architecting-hipaa-compliance-on-aws.pdf.metadata.json and upload it to the folder corresponding to Customer A’s documents. Repeat these steps for Customer B.

- Create an Amazon Bedrock knowledge base. For instructions, see Create a knowledge base by connecting to a data source in Amazon Bedrock Knowledge Bases
- After you create your knowledge base, you can sync the data source. For more details, see Sync your data with your Amazon Bedrock knowledge base.
Test metadata filtering
After you sync the data source, you can test the metadata filtering.
The following is an example for setting the customer = CustomerA metadata filter to show Customer A only has access to the HIPAA compliance document and not the NHS Compliance Guidance that relates to Customer B.
To use the metadata filtering options on the Amazon Bedrock console, complete the following steps:
- On the Amazon Bedrock console, choose Knowledge Bases in the navigation pane.
- Choose the knowledge base you created.
- Choose Test knowledge base.
- Choose the Configurations icon, then expand Filters.
- Enter a condition using the format: key = value (for this example,
customer = CustomerA) and press Enter.
- When finished, enter your query in the message box, then choose Run.
We enter two queries, “summarize NHS Compliance Guidance” and “summarize HIPAA Compliance Guide.” The following figure shows the two queries: one attempting to query data related to NHS compliance guidance, which fails because it is outside of the Customer A segment, and another successfully querying data on HIPAA compliance, which has been tagged for Customer A.

Implement field-specific chunking
Amazon Bedrock Knowledge Bases supports several document types for Amazon S3 metadata filtering. The supported file formats include:
- Plain text (.txt)
- Markdown (.md)
- HTML (.html)
- Microsoft Word documents (.doc and.docx)
- CSV files (.csv)
- Microsoft Excel spreadsheets (.xls and .xlsx)
When working with CSV data, customers often want to chunk on a specific field in their CSV documents to gain granular control over data retrieval and enhance the efficiency and accuracy of queries. By creating logical divisions based on fields, users can quickly access relevant subsets of data without needing to process the entire dataset.
Additionally, field-specific chunking aids in organizing and maintaining large datasets, facilitating updating or modifying specific portions without affecting the whole. This granularity supports better version control and data lineage tracking, which are crucial for data integrity and compliance. Focusing on relevant chunks can improve the performance of LLMs, ultimately leading to more accurate insights and better decision-making processes within organizations. For more information, see Amazon Bedrock Knowledge Bases now supports advanced parsing, chunking, and query reformulation giving greater control of accuracy in RAG based applications.
To demonstrate field-specific chunking, we use two sample datasets with the following schemas:
- Schema 1 – Customer A uses the following synthetic dataset for recording medical case reports (
case_reports.csv)
| CaseID |
DoctorID |
PatientID |
Diagnosis |
TreatmentPlan |
Content |
| C001 |
D001 |
P001 |
Hypertension |
Lifestyle changes, Medication (Lisinopril) |
“Patient diagnosed with hypertension, advised lifestyle changes, and started on Lisinopril.” |
| C002 |
D002 |
P002 |
Diabetes Type 2 |
Medication (Metformin), Diet adjustment |
“Diabetes Type 2 confirmed, prescribed Metformin, and discussed a low-carb diet plan.” |
| C003 |
D003 |
P003 |
Asthma |
Inhaler (Albuterol) |
“Patient reports difficulty breathing; prescribed Albuterol inhaler for asthma management.” |
| C004 |
D004 |
P004 |
Coronary Artery Disease |
Medication (Atorvastatin), Surgery Consultation |
“Coronary artery disease diagnosed, started on Atorvastatin, surgery consultation recommended.” |
| … |
… |
… |
… |
… |
… |
- Schema 2 – Customer B uses the following dataset for recording genetic testing results (
genetic_testings.csv)
| SampleID |
PatientID |
TestType |
Result |
| S001 |
P001 |
Genome Sequencing |
Positive |
| S002 |
P002 |
Exome Sequencing |
Negative |
| S003 |
P003 |
Targeted Gene Panel |
Positive |
| S004 |
P004 |
Whole Genome Sequencing |
Negative |
| … |
… |
… |
… |
Complete the following steps:
- Create a JSON file representing the corresponding metadata for both Customer A and Customer B:
The following is the JSON metadata for Customer A’s data (note that recordBasedStructureMetadata supports exactly one content field):
{
"metadataAttributes": {
"customer": "CustomerA"
},
"documentStructureConfiguration": {
"type": "RECORD_BASED_STRUCTURE_METADATA",
"recordBasedStructureMetadata": {
"contentFields": [
{
"fieldName": "Content"
}
],
"metadataFieldsSpecification": {
"fieldsToInclude": [
{
"fieldName": "CaseID"
},
{
"fieldName": "DoctorID"
},
{
"fieldName": "PatientID"
},
{
"fieldName": "Diagnosis"
},
{
"fieldName": "TreatmentPlan"
}
]
}
}
}
}
The following is the JSON metadata for Customer B’s data:
{
"metadataAttributes": {
"customer": "CustomerB"
},
"documentStructureConfiguration": {
"type": "RECORD_BASED_STRUCTURE_METADATA",
"recordBasedStructureMetadata": {
"contentFields": [
{
"fieldName": "TestType"
}
],
"metadataFieldsSpecification": {
"fieldsToInclude": [
{
"fieldName": "SampleID"
},
{
"fieldName": "PatientID"
},
{
"fieldName": "Result"
}
]
}
}
}
}
- Save your files with the naming convention <filename>.csv.metadata.json and store the new JSON file in the same S3 prefix of the bucket where you stored the dataset. For Customer A, name the metadata file case_reports.csv.metadata.JSON and upload the file to the same folder corresponding to Customer A’s datasets.

Repeat the process for Customer B. You have now created metadata from the source CSV itself, as well as an additional metadata field customer that doesn’t exist in the original dataset. The following image highlights the metadata.
- Create an Amazon Bedrock knowledge base.
- Sync your data with your Amazon Bedrock knowledge base.
Test field-specific chunking
The following is an example of setting the customer = CustomerA metadata filter demonstrating that Customer A only has access to the medical case reports dataset and not the genetic testing dataset that relates to Customer B. We enter a query requesting information about a patient with PatientID as P003.
To test, complete the following steps:
- On the Amazon Bedrock console, choose Knowledge Bases in the navigation pane.
- Choose the knowledge base you created.
- Choose Test knowledge base.
- Choose the Configurations icon, then expand Filters.
- Enter a condition using the format: key = value (for this example,
customer = CustomerA) and press Enter.
- When finished, enter your query in the message box, then choose Run.
The knowledge base returns, “Patient reports difficulty breathing; prescribed Albuterol inhaler for asthma management,” which is the Result column entry from Customer A’s medical case reports dataset for that PatientID. Although there is a record with the same PatientID in Customer B’s genetic testing dataset, Customer A has access only to the medical case reports data due to the metadata filtering.
Apply metadata filtering for the Amazon Bedrock API
You can call the Amazon Bedrock API RetrieveAndGenerate to query a knowledge base and generate responses based on the retrieved results using the specified FM or inference profile. The response only cites sources that are relevant to the query.
The following Python Boto3 example API call applies the metadata filtering for retrieving Customer B data and generates responses based on the retrieved results using the specified FM (Anthropic’s Claude 3 Sonnet) in RetrieveAndGenerate:
response = bedrock_client.retrieve_and_generate(
input={
"text": "Summarize NHS compliance guidance."
},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
'knowledgeBaseId': 'example_knowledge_base_id’,
"modelArn": "arn:aws:bedrock:{}::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0".format(region),
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": 5,
"filter": {
"equals": {
"key": "customer",
"value": ‘CustomerB’
}
}
}
}
}
})
The following GitHub repository provides a notebook that you can follow to deploy an Amazon Bedrock knowledge base with access control implemented using metadata filtering in your own AWS account.
Integrate existing vector databases with Amazon Bedrock Knowledge Bases and validate metadata
There are multiple ways to create vector databases from AWS services and partner offerings to build scalable solutions. If a vector database doesn’t exist, you can use Amazon Bedrock Knowledge Bases to create one using Amazon OpenSearch Serverless Service, Amazon Aurora PostgreSQL Serverless, or Amazon Neptune Analytics to store embeddings, or you can specify an existing vector database supported by Redis Enterprise Cloud, Amazon Aurora PostgreSQL with the pgvector extension, MongoDB Atlas, or Pinecone. After you create your knowledge base and either ingest or sync your data, the metadata attached to the data will be ingested and automatically populated to the vector database.
In this section, we review how to incorporate and validate metadata filtering with existing vector databases using OpenSearch Serverless, Aurora PostgreSQL with the pgvector extension, and Pinecone. To learn how to set up each individual vector databases, follow the instructions in Prerequisites for your own vector store for a knowledge base.
OpenSearch Serverless as a knowledge base vector store
With OpenSearch Serverless vector database capabilities, you can implement semantic search, RAG with LLMs, and recommendation engines. To address data segregation between business segments within each Amazon Bedrock knowledge base with an OpenSearch Serverless vector database, use metadata filtering. Metadata filtering allows you to segment data inside of an OpenSearch Serverless vector database. This can be useful when you want to add descriptive data to your documents for more control and granularity in searches.
Each OpenSearch Serverless dashboard has a URL that can be used to add documents and query your database; the structure of the URL is domain-endpoint/_dashboard.
After creating a vector database index, you can use metadata filtering to selectively retrieve items by using JSON query options in the request body. For example, to return records owned by Customer A, you can use the following request:
GET <index_name>/_search
{
"query": {
"match": {
"customer": "CustomerA"
}
}
}
This query will return a JSON response containing the document index with the document labeled as belonging to Customer A.
Aurora PostgreSQL with the pgvector extension as a knowledge base vector store
Pgvector is an extension of PostgreSQL that allows you to extend your relational database into a high-dimensional vector database. It stores each document’s vector in a separate row of a database table. For details on creating an Aurora PostgreSQL table to be used as the vector store for a knowledge base, see Using Aurora PostgreSQL as a Knowledge Base for Amazon Bedrock.
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting data ingestion.
Continuing with the Customer A example, the customer requires the Architecting for HIPAA Security and Compliance on AWS document.
The following is the JSON metadata for Customer A’s data:
{ "metadataAttributes": { "customer": "CustomerA", "documentType": "HIPAA Compliance Guide", "focus": "HIPAA Compliance", "publicationYear": 2022, "region": "North America" }}
The schema of the PostgreSQL table you create must contain four essential columns for ID, text content, vector values, and service managed metadata; it must also include additional metadata columns (customer, documentType, focus, publicationYear, region) for each metadata property in the corresponding metadata file. This allows pgvector to perform efficient vector searches and similarity comparisons by running queries directly on the database table. The following table summarizes the columns.
| Column Name |
Data Type |
Description |
| id |
UUID primary key |
Contains unique identifiers for each record |
| chunks |
Text |
Contains the chunks of raw text from your data sources |
| embedding |
Vector |
Contains the vector embeddings of the data sources |
| metadata |
JSON |
Contains Amazon Bedrock managed metadata required to carry out source attribution and to enable data ingestion and querying. |
| customer |
Text |
Contains the customer ID |
| documentType |
Text |
Contains the type of document |
| focus |
Text |
Contains the document focus |
| publicationYear |
Int |
Contains the year document was published |
| region |
Text |
Contains the document’s related AWS Region |
During Amazon Bedrock knowledge base data ingestion, these columns will be populated with the corresponding attribute values. Chunking can break down a single document into multiple separate records (each associated with a different ID).
This PostgreSQL table structure allows for efficient storage and retrieval of document vectors, using PostgreSQL’s robustness and pgvector’s specialized vector handling capabilities for applications like recommendation systems, search engines, or other systems requiring similarity searches in high-dimensional space.
Using this approach, you can implement access control at the table level by creating database tables for each segment. Additional metadata columns can also be included in the table for properties such as the specific document owner (user_id), tags, and so on to further enable and enforce fine-grained (row-level) access control and result filtering if you restrict each user to only query the rows that contain their user ID (document owner).
After creating a vector database table, you can use metadata filtering to selectively retrieve items by using a PostgreSQL query. For example, to return table records owned by Customer A, you can use the following query:
SELECT *
FROM bedrock_integration.bedrock_kb
WHERE customer = 'CustomerA';
This query will return a response containing the database records with the document labeled as belonging to Customer A.
Pinecone as a knowledge base vector store
Pinecone, a fully managed vector database, enables semantic search, high-performance search, and similarity matching. Pinecone databases can be integrated into your AWS environment in the form of Amazon Bedrock knowledge bases, but are first created through the Pinecone console. For detailed documentation about setting up a vector store in Pinecone, see Pinecone as a Knowledge Base for Amazon Bedrock. Then, you can integrate the databases using the Amazon Bedrock console. For more information about Pinecone integration with Amazon Bedrock, see Bring reliable GenAI applications to market with Amazon Bedrock and Pinecone.
You can segment a Pinecone database by adding descriptive metadata to each index and using that metadata to inform query results. Pinecone supports strings and lists of strings to filter vector searches on customer names, customer industry, and so on. Pinecone also supports numbers and booleans.
Use metadata query language to filter output ($eq, $ne, $in, $nin, $and, and $or). The following example shows a snippet of metadata and queries that will return that index. The example queries in Python demonstrate how you can retrieve a list of records associated with Customer A from the Pinecone database.
pc = Pinecone(api_key="xxxxxxxxxxx")
index = pc.Index(<index_name>)
index.query(
namespace="",
vector=[0.17,0.96, …, 0.44],
filter={
"customer": {"$eq": "CustomerA"}
},
top_k=10,
include_metadata=True # Include metadata in the response.
)
This query will return a response containing the database records labeled as belonging to Customer A.
Enhanced scaling with multiple data sources
Amazon Bedrock Knowledge Bases now supports multiple data sources across AWS accounts. Amazon Bedrock Knowledge Bases can ingest data from up to five data sources, enhancing the comprehensiveness and relevancy of a knowledge base. This feature allows customers with complex IT systems to incorporate data into generative AI applications without restructuring or migrating data sources. It also provides flexibility for you to scale your Amazon Bedrock knowledge bases when data resides in different AWS accounts.
The features includes cross-account data access, enabling the configuration of S3 buckets as data sources across different accounts and efficient data management options for retaining or deleting data when a source is removed. These enhancements alleviate the need for creating multiple knowledge bases or redundant data copies.
Clean up
After completing the steps in this blog post, make sure to clean up your resources to avoid incurring unnecessary charges. Delete the Amazon Bedrock Knowledge Base by navigating to the Amazon Bedrock console, selecting your knowledge base, and choosing “Delete” from the “Actions” dropdown menu. If you created vector databases for testing, remember to delete OpenSearch Serverless collections, stop or delete Aurora PostgreSQL instances, and remove Pinecone index created. Additionally, consider deleting test documents uploaded to S3 buckets specifically for this blog example to avoid storage charges. Review and clean up any IAM roles or policies created for this demonstration if they’re no longer needed.
While Amazon Bedrock Knowledge Bases include charges for data indexing and queries, the underlying storage in S3 and vector databases will continue to incur charges until those resources are removed. For specific pricing details, refer to the Amazon Bedrock pricing page.
Conclusion
In this post, we covered several key strategies for building scalable, secure, and segmented Amazon Bedrock knowledge bases. These include using S3 folder structure, metadata to organize data sources, and data segmentation within a single knowledge base. Using metadata filtering to create custom queries that target specific data segments helps provide retrieval accuracy and maintain data privacy. We also explored integrating and validating metadata for vector databases including OpenSearch Serverless, Aurora PostgreSQL with the pgvector extension, and Pinecone.
By consolidating multiple business segments or customer data within a single Amazon Bedrock knowledge base, organizations can achieve cost optimization compared to creating and managing them separately. The improved data segmentation and access control measures help make sure each team or customer can only access the information relevant to their domain. The enhanced scalability helps meet the diverse needs of organizations, while maintaining the necessary data segregation and access control.
Try out metadata filtering with Amazon Bedrock Knowledge Bases, and share your thoughts and questions with the authors or in the comments.
About the Authors
 Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing 1P and 3P model adoption. Breanne is also on the Women at Amazon board as co-director of Allyship with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor of Science in Computer Engineering from University of Illinois at Urbana Champaign.
Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing 1P and 3P model adoption. Breanne is also on the Women at Amazon board as co-director of Allyship with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor of Science in Computer Engineering from University of Illinois at Urbana Champaign.
 Justin Lin is a Small & Medium Business Solutions Architect at Amazon Web Services. He studied computer science at UW Seattle. Dedicated to designing and developing innovative solutions that empower customers, Justin has been dedicating his time to experimenting with applications in generative AI, natural language processing, and forecasting.
Justin Lin is a Small & Medium Business Solutions Architect at Amazon Web Services. He studied computer science at UW Seattle. Dedicated to designing and developing innovative solutions that empower customers, Justin has been dedicating his time to experimenting with applications in generative AI, natural language processing, and forecasting.
 Chloe Gorgen is an Enterprise Solutions Architect at Amazon Web Services, advising AWS customers in various topics including security, analytics, data management, and automation. Chloe is passionate about youth engagement in technology, and supports several AWS initiatives to foster youth interest in cloud-based technology. Chloe holds a Bachelor of Science in Statistics and Analytics from the University of North Carolina at Chapel Hill.
Chloe Gorgen is an Enterprise Solutions Architect at Amazon Web Services, advising AWS customers in various topics including security, analytics, data management, and automation. Chloe is passionate about youth engagement in technology, and supports several AWS initiatives to foster youth interest in cloud-based technology. Chloe holds a Bachelor of Science in Statistics and Analytics from the University of North Carolina at Chapel Hill.
Read More




 Learn how Google DeepMind and Google Cloud are helping to bring a cinema classic to larger-than-life in Las Vegas.
Learn how Google DeepMind and Google Cloud are helping to bring a cinema classic to larger-than-life in Las Vegas.









 Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine learning and generative AI hub. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.
Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine learning and generative AI hub. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.


 John Liu has 14 years of experience as a product executive and 10 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 and Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols and fintech companies, and also spent 9 years as a portfolio manager at various hedge funds.
John Liu has 14 years of experience as a product executive and 10 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 and Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols and fintech companies, and also spent 9 years as a portfolio manager at various hedge funds.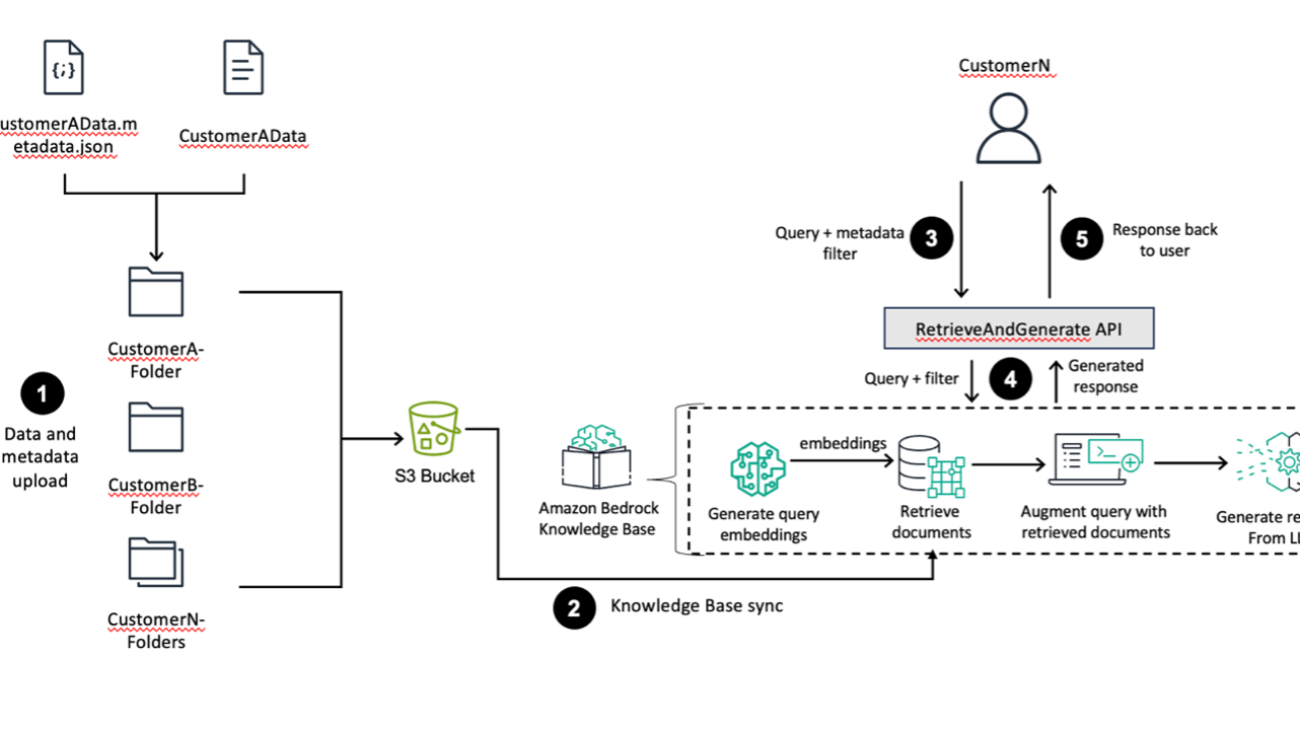











 Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks. Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Amazon Bedrock at Amazon Web Services, specializing in Amazon Bedrock security. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies and security principles allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value while maintaining robust security postures.
Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Amazon Bedrock at Amazon Web Services, specializing in Amazon Bedrock security. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies and security principles allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value while maintaining robust security postures. Kosta Belz is a Senior Applied Scientist in the AWS Generative AI Innovation Center, where he helps customers design and build generative AI solutions to solve key business problems.
Kosta Belz is a Senior Applied Scientist in the AWS Generative AI Innovation Center, where he helps customers design and build generative AI solutions to solve key business problems. Sean Eichenberger is a Sr Product Manager at AWS.
Sean Eichenberger is a Sr Product Manager at AWS.