 Dolphin researchers are using Gemma and Google Pixel phones to try to decipher how dolphins talk to one another.Read More
Dolphin researchers are using Gemma and Google Pixel phones to try to decipher how dolphins talk to one another.Read More

Dolphin researchers are using Gemma and Google Pixel phones to try to decipher how dolphins talk to one another.Read More

NVIDIA is working with its manufacturing partners to design and build factories that, for the first time, will produce NVIDIA AI supercomputers entirely in the U.S.
Together with leading manufacturing partners, the company has commissioned more than a million square feet of manufacturing space to build and test NVIDIA Blackwell chips in Arizona and AI supercomputers in Texas.
NVIDIA Blackwell chips have started production at TSMC’s chip plants in Phoenix, Arizona. NVIDIA is building supercomputer manufacturing plants in Texas, with Foxconn in Houston and with Wistron in Dallas. Mass production at both plants is expected to ramp up in the next 12-15 months.
The AI chip and supercomputer supply chain is complex and demands the most advanced manufacturing, packaging, assembly and test technologies. NVIDIA is partnering with Amkor and SPIL for packaging and testing operations in Arizona.
Within the next four years, NVIDIA plans to produce up to half a trillion dollars of AI infrastructure in the United States through partnerships with TSMC, Foxconn, Wistron, Amkor and SPIL. These world-leading companies are deepening their partnership with NVIDIA, growing their businesses while expanding their global footprint and hardening supply chain resilience.
NVIDIA AI supercomputers are the engines of a new type of data center created for the sole purpose of processing artificial intelligence — AI factories that are the infrastructure powering a new AI industry. Tens of “gigawatt AI factories” are expected to be built in the coming years. Manufacturing NVIDIA AI chips and supercomputers for American AI factories is expected to create hundreds of thousands of jobs and drive trillions of dollars in economic security over the coming decades.
“The engines of the world’s AI infrastructure are being built in the United States for the first time,” said Jensen Huang, founder and CEO of NVIDIA. “Adding American manufacturing helps us better meet the incredible and growing demand for AI chips and supercomputers, strengthens our supply chain and boosts our resiliency.”
The company will utilize its advanced AI, robotics and digital twin technologies to design and operate the facilities, including NVIDIA Omniverse to create digital twins of factories and NVIDIA Isaac GR00T to build robots to automate manufacturing.
This paper was accepted at the Workshop on Foundation Models in the Wild at ICLR 2025.
Visual understanding is inherently contextual – what we focus on in an image depends on the task at hand. For instance, given an image of a person holding a bouquet of flowers, we may focus on either the person such as their clothing, or the type of flowers, depending on the context of interest. Yet, most existing image encoding paradigms represent an image as a fixed, generic feature vector, overlooking the potential needs of prioritizing varying visual information for different downstream use cases. In…Apple Machine Learning Research
At Apple, we believe privacy is a fundamental human right. And we believe in giving our users a great experience while protecting their privacy. For years, we’ve used techniques like differential privacy as part of our opt-in device analytics program. This lets us gain insights into how our products are used, so we can improve them, while protecting user privacy by preventing Apple from seeing individual-level data from those users.
This same need to understand usage while protecting privacy is also present in Apple Intelligence. One of our principles is that Apple does not use our users’…Apple Machine Learning Research

 At Google Cloud Next 25, L’Oréal, Reddit, Deutsche Bank and more share how generative AI is creating exciting opportunities across industries.Read More
At Google Cloud Next 25, L’Oréal, Reddit, Deutsche Bank and more share how generative AI is creating exciting opportunities across industries.Read More
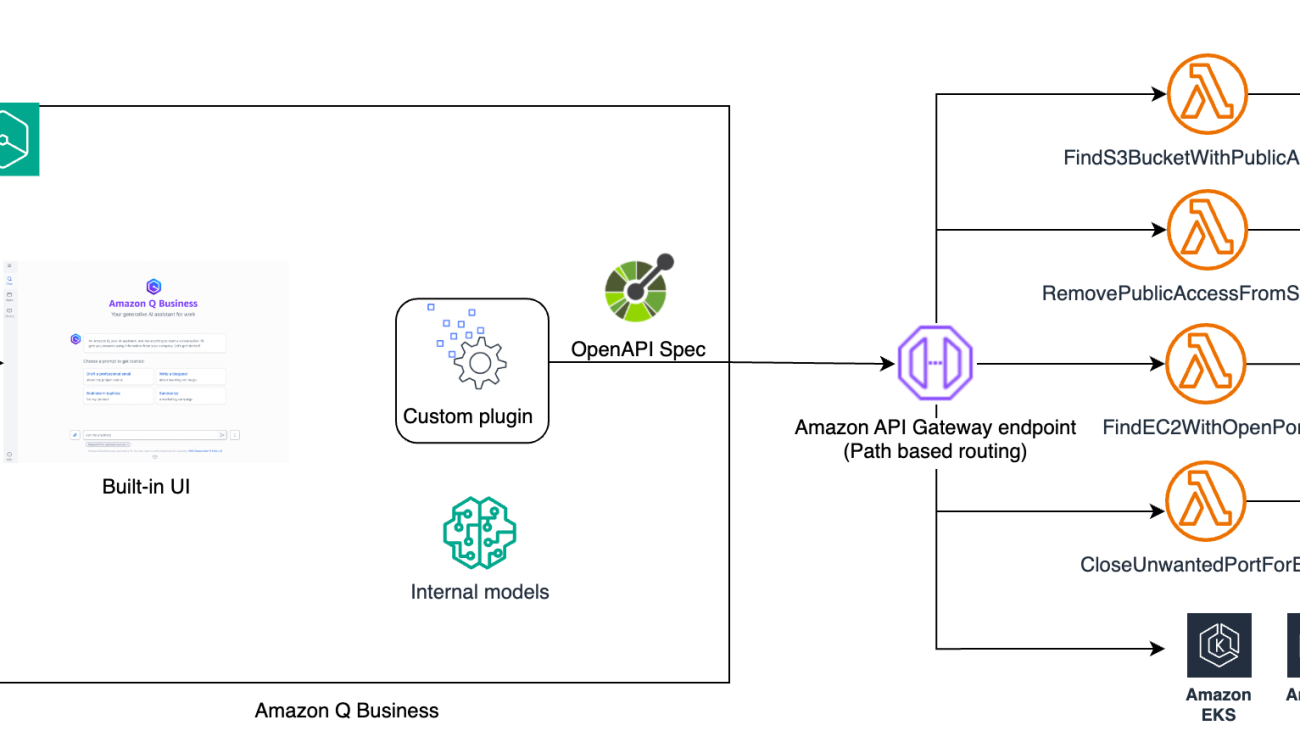
Many organizations rely on multiple third-party applications and services for different aspects of their operations, such as scheduling, HR management, financial data, customer relationship management (CRM) systems, and more. However, these systems often exist in silos, requiring users to manually navigate different interfaces, switch between environments, and perform repetitive tasks, which can be time-consuming and inefficient.
Moreover, while many enterprise systems are equipped with APIs for integration, users often lack the technical expertise to interact with these APIs directly. As a result, organizations need an intuitive and seamless way to query data and perform actions across these applications using natural language, without requiring specialized knowledge of each system or its APIs.
To address the challenge of integrating multiple third-party applications into a unified, natural language-driven interface, users can use plugins for Amazon Q Business. Plugins provide a way to bridge the gap between complex, siloed enterprise applications in a user-friendly interfacing empowering users to take action across systems with easy. Amazon Q Business supports multiple enterprise systems with pre-built plugins, as well as custom plugins, that users can use to integrate a variety of enterprise systems with Amazon Q Business applications.
In this post, we demonstrate how you can use custom plugins for Amazon Q Business to build a chatbot that can interact with multiple APIs using natural language prompts. We showcase how to build an AIOps chatbot that enables users to interact with their AWS infrastructure through natural language queries and commands. The chatbot is capable of handling tasks such as querying the data about Amazon Elastic Compute Cloud (Amazon EC2) ports and Amazon Simple Storage Service (Amazon S3) buckets access settings. For example, users can ask the chatbot questions like “Which EC2 instances have port 3389 open?” or request actions such as “Please close public access for S3 buckets.”
By integrating other AWS services with Amazon Q using OpenAPI schemas, the chatbot can not only retrieve real-time information (such as checking which S3 buckets have public access), but also take corrective actions (such as closing open ports or public access) in response to user commands. This solution reduces manual intervention and simplifies complex cloud operations by enabling IT teams to manage infrastructure through natural language interactions. The chatbot will streamline operational tasks, reduce the need for switching between different tools, and improve the efficiency of IT and operations teams by allowing them to interact with complex systems using simple, intuitive language.
To implement the solution, you will build the following architecture.

Users sign in the AIOps Chatbot using the credentials configured in AWS IAM Identity Center. You will use finding and removing public access from S3 buckets along with finding and closing specific open ports on Amazon EC2 instances as the use cases to demonstrate the capability of this AIOps chatbot using Amazon Q Business custom plugins. However, you can extend the architecture to support other operations use cases through API based integration.
You deploy the required infrastructure using the AWS Serverless Application Model (AWS SAM).
The following is a summary of the functionality of the architecture:
The resources in this demonstration will be provisioned in the US East (N. Virginia) AWS Region (us-east-1). You walk through the following phases to implement the model customization workflow:
See the GitHub repository for the latest instructions. Run the following steps to deploy the AWS Step Functions workflow using the AWS SAM template.
2. Change directory to the solution directory:
3. Run the following command to deploy the resources using SAM.
4. When prompted, enter the following parameter values:
5. Note the outputs from the AWS SAM deployment process. This contains the Amazon Q Business web experience (chatbot) URL. Before you can sign in to the chatbot application, you must set up a user.
Use the following steps to configure a user for the AIOps chatbot application.

2. Choose Manage access and subscription.

3. Choose Add groups and users.

4. Select either Add and assign new users or Assign existing users and groups depending on if you pre-created the user as mentioned in the prerequisites and choose Next.

5. If you have an existing user that you want to provide access to your AIOps application, search for and select the username and choose Assign.

6. On the review page, select the current subscription and choose Confirm.

Use the following steps to log into the chatbot and test it. Responses from large language models are non-deterministic. Hence, you may not get the exact same response every time.
QBusinessWebExperienceURL from the sam deploy output using the user credential configured in the previous step.
3. Enable public access on an Amazon S3 bucket. This is done for testing purposes only, so check your organization policies before performing this test. For this demo we used a bucket named aiops-chatbot-demo.
4. Return to the AIOps Chatbot and enter a question such as: Do I have any S3 bucket with public access? and choose Submit. Provide the bucket prefix to narrow down the search.

5. The AIOps chatbot identifies the buckets that have public access:

6. Ask a follow up question such as: Please block the public access. The chat bot blocks public access. Validate the change from the S3 console.

7. Open a port, such as 1234, for an Amazon EC2 instance using security group inbound rules.

8. Return to the chat bot and enter a question such as: Do I have any EC2 instance with port 1234 open?
9. After the chat bot identifies the EC2 instance with the open port, confirm that you want to close the port.
10. The chat bot closes the open port and confirms.

Properly decommissioning provisioned AWS resources is an important best practice to optimize costs and enhance security posture after concluding proofs of concept and demonstrations. To delete the resources deployed to your AWS account through AWS SAM, run the following command:
After the custom plugin is deployed, Amazon Q Business will process a user’s prompt and use the OpenAPI schema to dynamically determine the appropriate APIs to call to accomplish the user’s goal. Therefore, the OpenAPI schema definition has a big impact on API selection accuracy. Follow the best practices for OpenAPI schema definition for ideal results. This AIOps chatbot demonstrated four operations supported by the following API operations:
find-s3-bucket-with-public-access – This API finds S3 buckets that have the specified prefix and are configured for public access.remove-public-access-from-s3-bucket – This API removes public access from a specific S3 bucket.find-ec2-with-specific-open-port – This API finds EC2 instances that have a specified port open for inbound access.close-unwanted-port-for-ec2 – This API removes a specified port from a given EC2 instance.The API operations are implemented using API Gateway and Lambda functions.
The following are some troubleshooting steps if you encounter errors while using the AIOps chatbot.
Do I have any EC2 instance with port 1234 open? instead of Do I have any EC2 exposed to internet?In this post, you learned an end-to-end process for creating an AIOps chatbot using Amazon Q Business custom plugins, demonstrating how users can use natural language processing to interact with AWS resources and streamline cloud operations. By integrating other AWS services with Amazon Q Business, the chatbot can query infrastructure for security and compliance status while automating key actions such as closing open ports or restricting public access to S3 buckets. This solution enhances operational efficiency, reduces manual intervention, and enabled teams to manage complex environments more effectively through intuitive, conversational interfaces. With custom plugins and OpenAPI schemas, users can build a powerful, flexible chatbot solution tailored to their specific operational needs, transforming the way they manage IT operations and respond to business challenges.
For more information on Amazon Q Business and custom plugins:
About the authors
 Upendra V is a Sr. Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprise customers design and deploy production-ready Generative AI workloads, implement Large Language Models (LLMs) and Agentic AI systems, and optimize cloud deployments. With expertise in cloud adoption and machine learning, he enables organizations to build and scale AI-driven applications efficiently.
Upendra V is a Sr. Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprise customers design and deploy production-ready Generative AI workloads, implement Large Language Models (LLMs) and Agentic AI systems, and optimize cloud deployments. With expertise in cloud adoption and machine learning, he enables organizations to build and scale AI-driven applications efficiently.
 Biswanath Mukherjee is a Senior Solutions Architect at Amazon Web Services. He works with large strategic customers of AWS by providing them technical guidance to migrate and modernize their applications on AWS Cloud. With his extensive experience in cloud architecture and migration, he partners with customers to develop innovative solutions that leverage the scalability, reliability, and agility of AWS to meet their business needs. His expertise spans diverse industries and use cases, enabling customers to unlock the full potential of the AWS Cloud.
Biswanath Mukherjee is a Senior Solutions Architect at Amazon Web Services. He works with large strategic customers of AWS by providing them technical guidance to migrate and modernize their applications on AWS Cloud. With his extensive experience in cloud architecture and migration, he partners with customers to develop innovative solutions that leverage the scalability, reliability, and agility of AWS to meet their business needs. His expertise spans diverse industries and use cases, enabling customers to unlock the full potential of the AWS Cloud.
This post is co-written with Keith Brazil, Julien Didier, and Bryan Rand from TransPerfect.
TransPerfect, a global leader in language and technology solutions, serves a diverse array of industries. Founded in 1992, TransPerfect has grown into an enterprise with over 10,000 employees in more than 140 cities on six continents. The company offers a broad spectrum of services, including translation, localization, interpretation, multicultural marketing, website globalization, subtitling, voiceovers, and legal support services. TransPerfect also uses cutting-edge technology to offer AI-driven language solutions, such as its proprietary translation management system, GlobalLink.
This post describes how the AWS Customer Channel Technology – Localization Team worked with TransPerfect to integrate Amazon Bedrock into the GlobalLink translation management system, a cloud-based solution designed to help organizations manage their multilingual content and translation workflows. Organizations use TransPerfect’s solution to rapidly create and deploy content at scale in multiple languages using AI.
Amazon Bedrock is a fully managed service that simplifies the deployment and management of generative AI models. It offers access to a variety of foundation models (FMs), enabling developers to build and scale AI applications efficiently. Amazon Bedrock is designed to be highly scalable, secure, and straightforward to integrate with other AWS services, making it suitable for a broad array of use cases, including language translation.
The AWS Customer Channel Technology – Localization Team is a long-standing TransPerfect customer. The team manages the end-to-end localization process of digital content at AWS, including webpages, technical documentation, ebooks, banners, videos, and more. The AWS team handles billions of words in multiple languages across digital assets. Given the growing demand for multilingual content by internationally minded businesses and new local cloud adoption journeys, the AWS team needs to support an ever-increasing load and a wider set of languages. To do so, the team relies on the GlobalLink technology suite to optimize and automate translation processes.
The AWS team and TransPerfect created streamlined custom workflows and toolsets that enable the translation and delivery of billions of words each year. Content localization is a multi-step process consisting minimally of asset handoff, asset preprocessing, machine translation, post-editing, quality review cycles, and asset handback. These steps are often manual, costly, and time-consuming. AWS and TransPerfect are continually striving to optimize this workflow to enable the processing of more content at a lower cost and to decrease those assets’ time to market—providing valuable, salient content faster for non-English-speaking customers. Additionally, transcreation of creative content posed a unique challenge, because it traditionally required highly skilled human linguists and was resistant to automation, resulting in higher costs and longer turnaround times. To address these issues, TransPerfect worked with AWS to evaluate generative AI-powered initiatives for transcreation and automatic post-editing within TransPerfect’s GlobalLink architecture.
Amazon Bedrock helps make sure data is neither shared with FM providers nor used to improve base models. Amazon Bedrock adheres to major compliance standards like ISO and SOC and is also a FedRAMP-authorized service, making it suitable for government contracts. The extensive monitoring and logging capabilities of Amazon Bedrock allow TransPerfect to align with stringent auditability requirements.
Although data safety is a key requirement, there are many other factors to take into account, such as responsible AI. Amazon Bedrock Guardrails enabled TransPerfect to build and customize truthfulness protections for the automatic post-edit offering. Large language models (LLMs) can generate incorrect information due to hallucinations. Amazon Bedrock supports contextual grounding checks to detect and filter hallucinations if the responses are factually incorrect or inconsistent. This is a critical feature for a translation solution that requires perfect accuracy.
To translate at scale, Amazon Translate powered machine translation is used in AWS team workflows. Segments whose translations can’t be recycled from translation memories (databases of previous high-quality human translations) are routed to machine translation workflows. Depending on the language or content, Amazon either uses a machine translation-only workflow where content is translated and published with no human touch, or machine translation post-edit workflows. Post-editing is when a linguist finesses the machine-translated output of a given segment to make sure it correctly conveys the meaning of the original sentence and is in line with AWS style guides and agreed glossaries. Because this process can add days to the translation timeline, automating some or all of the process would have a major impact on cost and turnaround times.
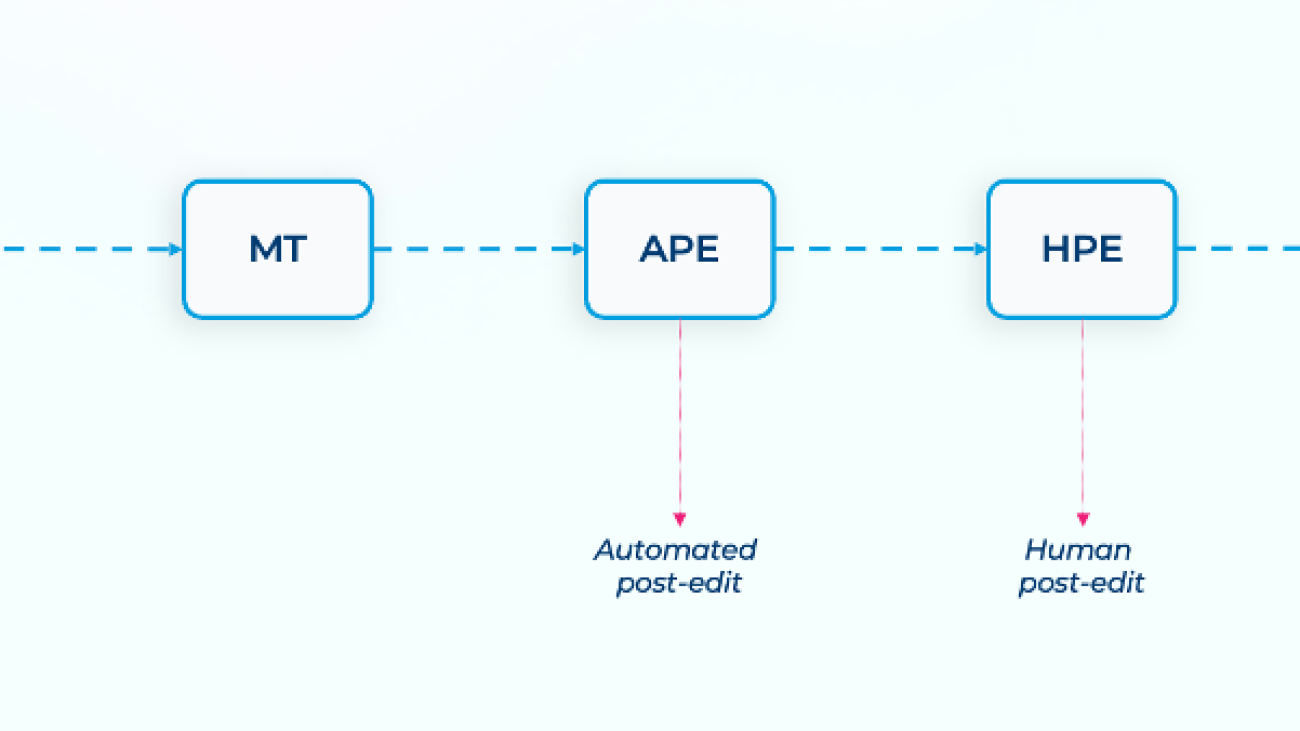
The following diagram illustrates the machine translation workflow.

The workflow consists of the following components:
The following example follows the path through the preceding workflow for one source segment.
| Source | To choose user name attributes, don’t select User name as a sign-in option when you create your user pool. |
| MT | Pour choisir des attributs de nom d’utilisateur, évitez de sélectionner User name (Nom d’utilisateur) comme option de connexion au moment de créer votre groupe d’utilisateurs. |
| APE | Pour choisir des attributs de nom d’utilisateur, évitez de sélectionner User name (Nom d’utilisateur) comme option de connexion lorsque vous créez votre groupe d’utilisateurs. |
| HPE | Pour choisir les attributs de nom d’utilisateur, évitez de sélectionner User name (Nom d’utilisateur) comme option de connexion lorsque vous créez votre groupe d’utilisateurs. |
TransPerfect began working with generative AI and LLMs several years ago with the foresight that AI was on track to disrupt the translation industry. As expected, localization workflows have mostly shifted to “expert in the loop”, and are striving toward “no human touch” models. In pursuit of this, TransPerfect chose to use Amazon Bedrock within its GlobalLink Enterprise solution to further automate and optimize these workflows. Amazon Bedrock, by design, provides data ownership and security. This is a critical feature for TransPerfect clients, especially those in sensitive industries such as life sciences or banking.
With Amazon Bedrock and GlobalLink, machine-translated content is now routed through one of the LLMs available in Amazon Bedrock for automatic post-editing. By using style guides, relevant examples of approved translations, and examples of errors to avoid, the LLM is prompted to improve existing machine translations. This post-edited content is either handed off to a linguist for a lighter post-edit (a less difficult task) or is applied in “no human touch workflows” to greatly improve the output. The result is enhanced quality across the board and the ability for post-editors to focus on higher-value edits.
For post-editing, over 95% of all edits suggested by Amazon Bedrock LLMs showed markedly improved translation quality, leading to up to 50% overall cost savings for translations for Transperfect and freeing human linguists for higher-level tasks.
Although machine translation shows great strength in technical, formal, and instructional content, it hasn’t historically performed as well with creative content that leans into nuance, subtlety, humor, descriptiveness, and cultural references. Creative content can sound stiff or unnatural when machine translated. Because of this, TransPerfect has traditionally relied on human linguists to manually transcreate this type of content.
Transcreation is the process of adapting a message from one language to another while maintaining its intent, style, tone, and context. In German, for example, Nike’s “Just do it” tagline is transcreated to “Du tust es nie nur für dich,” which actually means “you never do it just for yourself.”
A successfully transcreated message evokes the same emotions and carries the same implications in the target language as it does in the source language. The AWS team uses transcreation for highly creative marketing assets to maximize their impact in a given industry. However, transcreation historically hasn’t benefitted from the automation solutions used in other types of localization workflows due to the highly customized and creative nature of the process. This means there has been a lot of interest in using generative AI to potentially decrease the costs and time associated with transcreation.
TransPerfect sought to use LLMs to cut down on time and costs typically associated with transcreation. Rather than an all-human or fully automated process, translations are produced through Anthropic’s Claude or Amazon Nova Pro on Amazon Bedrock, with the prompt to create multiple candidate translations with some variations. Within the translation editor, the human linguist chooses the most suitable adapted translation instead of composing it from scratch.
The following screenshot shows an LLM-powered transcreation within the GlobalLink Translate online editor.

Using GlobalLink powered by Amazon Bedrock for transcreation, users are seeing linguist productivity gains of up to 60%.
Thanks to LLM-powered transcreation and post-editing, customers in industries ranging from life sciences to finance to manufacturing have seen cost savings of up to 40% within their translation workflows and up to an 80% reduction in project turnaround times. In addition, the automatic post-edit step added to machine translation-only workflows provides a major quality boost to the no human touch output.
Amazon Bedrock safeguards data by not allowing sharing with FM providers and excluding it from model improvements. Beyond data security, responsible AI is essential. Amazon Bedrock Guardrails allows TransPerfect to customize truthfulness protections for post-editing. To address AI hallucinations, it offers contextual grounding checks to identify and filter inaccuracies—critical for producing precise translations.
Try out LLM-powered transcreation and post-editing with Amazon Bedrock for your own use case, and share your feedback and questions in the comments.
 Peter Chung is a Senior Solutions Architect at AWS, based in New York. Peter helps software and internet companies across multiple industries scale, modernize, and optimize. Peter is the author of “AWS FinOps Simplified”, and is an active member of the FinOps community.
Peter Chung is a Senior Solutions Architect at AWS, based in New York. Peter helps software and internet companies across multiple industries scale, modernize, and optimize. Peter is the author of “AWS FinOps Simplified”, and is an active member of the FinOps community.
 Franziska Willnow is a Senior Program Manager (Tech) at AWS. A seasoned localization professional, Franziska Willnow brings over 15 years of expertise from various localization roles at Amazon and other companies. Franziska focuses on localization efficiency improvements through automation, machine learning, and AI/LLM. Franziska is passionate about building innovative products to support AWS’ global customers.
Franziska Willnow is a Senior Program Manager (Tech) at AWS. A seasoned localization professional, Franziska Willnow brings over 15 years of expertise from various localization roles at Amazon and other companies. Franziska focuses on localization efficiency improvements through automation, machine learning, and AI/LLM. Franziska is passionate about building innovative products to support AWS’ global customers.
 Ajit Manuel is a product leader at AWS, based in Seattle. Ajit heads the content technology product practice, which powers the AWS global content supply chain from creation to intelligence with practical enterprise AI. Ajit is passionate about enterprise digital transformation and applied AI product development. He has pioneered solutions that transformed InsurTech, MediaTech, and global MarTech.
Ajit Manuel is a product leader at AWS, based in Seattle. Ajit heads the content technology product practice, which powers the AWS global content supply chain from creation to intelligence with practical enterprise AI. Ajit is passionate about enterprise digital transformation and applied AI product development. He has pioneered solutions that transformed InsurTech, MediaTech, and global MarTech.
 Keith Brazil is Senior Vice President of Technology at TransPerfect, with specialization in Translation Management technologies as well as AI/ML data collection and annotation platforms. A native of Dublin, Ireland, Keith has been based in New York city for the last 23 years.
Keith Brazil is Senior Vice President of Technology at TransPerfect, with specialization in Translation Management technologies as well as AI/ML data collection and annotation platforms. A native of Dublin, Ireland, Keith has been based in New York city for the last 23 years.
 Julien Didier is Vice-President of Technology for translations.com and is responsible for the implementation of AI for both internal workflows and client-facing products. Julien manages a worldwide team of engineers, developers and architects who ensure successful deployments in addition to providing feedback for feature requests.
Julien Didier is Vice-President of Technology for translations.com and is responsible for the implementation of AI for both internal workflows and client-facing products. Julien manages a worldwide team of engineers, developers and architects who ensure successful deployments in addition to providing feedback for feature requests.
 Bryan Rand is Senior Vice President of Global Solutions at TransPerfect, specializing in enterprise software, AI-driven digital marketing, and content management strategies. With over 20 years of experience leading business units and implementing customer experience innovations, Bryan has played a key role in driving successful global transformations for Fortune 1000 companies. He holds a BA in Economics from the University of Texas.
Bryan Rand is Senior Vice President of Global Solutions at TransPerfect, specializing in enterprise software, AI-driven digital marketing, and content management strategies. With over 20 years of experience leading business units and implementing customer experience innovations, Bryan has played a key role in driving successful global transformations for Fortune 1000 companies. He holds a BA in Economics from the University of Texas.
The AWS DeepRacer League is the world’s first autonomous racing league, open to anyone. Announced at re:Invent 2018, it puts machine learning in the hands of every developer through the fun and excitement of developing and racing self-driving remote control cars. Through the past 7 years, over 560 thousand developers of all skill levels have competed in the league at thousands of Amazon and customer events globally. While the final championships concluded at re:Invent 2024, that same event played host to a brand new AI competition, ushering in a new era of gamified learning in the age of generative AI.
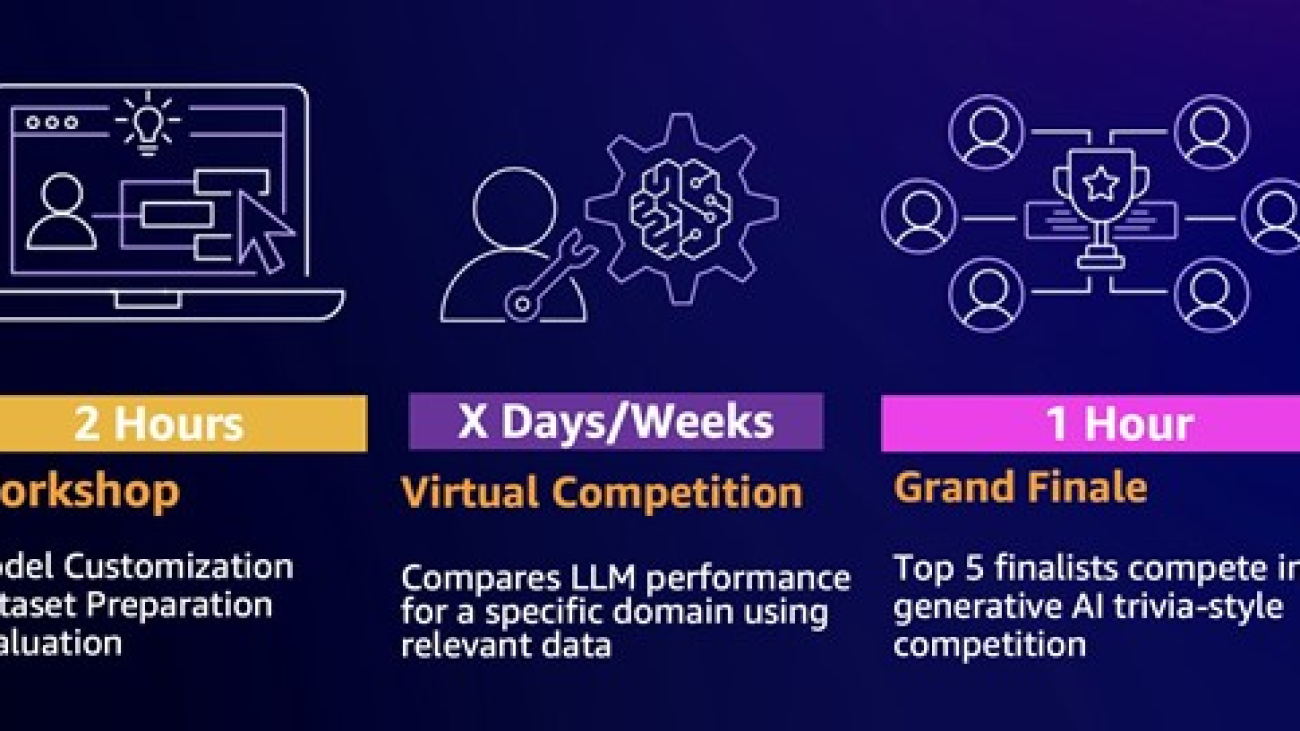
In December 2024, AWS launched the AWS Large Language Model League (AWS LLM League) during re:Invent 2024. This inaugural event marked a significant milestone in democratizing machine learning, bringing together over 200 enthusiastic attendees from diverse backgrounds to engage in hands-on technical workshops and a competitive foundation model fine-tuning challenge. Using learnings from DeepRacer, the primary objective of the event was to simplify model customization learning while fostering a collaborative community around generative AI innovation through a gamified competition format.
The AWS LLM League was designed to lower the barriers to entry in generative AI model customization by providing an experience where participants, regardless of their prior data science experience, could engage in fine-tuning LLMs. Using Amazon SageMaker JumpStart, attendees were guided through the process of customizing LLMs to address real business challenges adaptable to their domain.

As shown in the preceding figure, the challenge began with a workshop, where participants embarked on a competitive journey to develop highly effective fine-tuned LLMs. Competitors were tasked with customizing Meta’s Llama 3.2 3B base model for a specific domain, applying the tools and techniques they learned. The submitted model would be compared against a bigger 90B reference model with the quality of the responses decided using an LLM-as-a-Judge approach. Participants score a win for each question where the LLM judge deemed the fine-tuned model’s response to be more accurate and comprehensive than that of the larger model.

In the preliminary rounds, participants submitted hundreds of unique fine-tuned models to the competition leaderboard, each striving to outperform the baseline model. These submissions were evaluated based on accuracy, coherence, and domain-specific adaptability. After rigorous assessments, the top five finalists were shortlisted, with the best models achieving win rates above 55% against the large reference models (as shown in the preceding figure). Demonstrating that a smaller model can achieve competitive performance highlights significant benefits in compute efficiency at scale. Using a 3B model instead of a 90B model reduces operational costs, enables faster inference, and makes advanced AI more accessible across various industries and use cases.
The competition culminates in the Grand Finale, where finalists showcase their models in a final round of evaluation to determine the ultimate winner.
This journey was carefully designed to guide participants through each critical stage of fine-tuning a large language model—from dataset creation to model evaluation—using a suite of no-code AWS tools. Whether they were newcomers or experienced builders, participants gained hands-on experience in customizing a foundation model through a structured, accessible process. Let’s take a closer look at how the challenge unfolded, starting with how participants prepared their datasets.
During the workshop, participants learned how to generate synthetic data using an Amazon PartyRock playground (as shown in the following figure). PartyRock offers access to a variety of top foundation models through Amazon Bedrock at no additional cost. This enabled participants to use a no-code AI generated app for creating synthetic training data that were used for fine-tuning.

Participants began by defining the target domain for their fine-tuning task, such as finance, healthcare, or legal compliance. Using PartyRock’s intuitive interface, they generated instruction-response pairs that mimicked real-world interactions. To enhance dataset quality, they used PartyRock’s ability to refine responses iteratively, making sure that the generated data was both contextually relevant and aligned with the competition’s objectives.
This phase was crucial because the quality of synthetic data directly impacted the model’s ability to outperform a larger baseline model. Some participants further enhanced their datasets by employing external validation methods, such as human-in-the-loop review or reinforcement learning-based filtering.
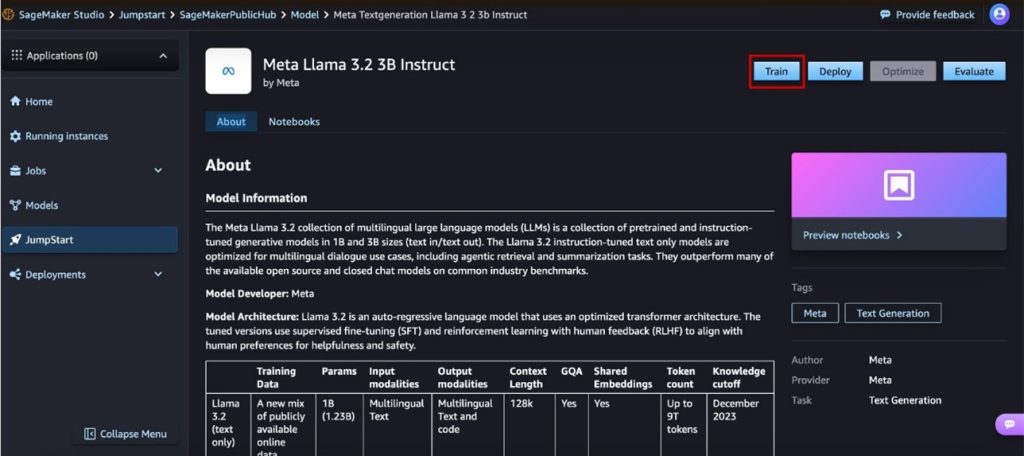
After the datasets were prepared, participants moved to SageMaker JumpStart, a fully managed machine learning hub that simplifies the fine-tuning process. Using a pre-trained Meta Llama 3.2 3B model as the base, they customized it with their curated datasets, adjusting hyperparameters (shown in the following figure) such as:

One of the key advantages of SageMaker JumpStart is that it provides a no-code UI, shown in the following figure, allowing participants to fine-tune models without needing to write code. This accessibility enabled even those with minimal machine learning experience to engage in model customization effectively.
By using the distributed training capabilities of SageMaker, participants were able to run multiple experiments in parallel, optimizing their models for accuracy and response quality. The iterative fine-tuning process allowed them to explore different configurations to maximize performance.
To make sure that their models were not only accurate but also unbiased, participants had the option to use Amazon SageMaker Clarify for evaluation, shown in the following figure.

This phase included:
While not mandatory, the integration of SageMaker Clarify provided an additional layer of assurance for participants who wanted to validate their models further, verifying that their outputs were reliable and performant.
After fine-tuned models were ready, they were submitted to the competition leaderboard for evaluation using the Amazon Bedrock Evaluations LLM-as-a-Judge approach. This automated evaluation system compares the fine-tuned models against the reference 90B model using predefined benchmarks, as shown in the following figure.

Each response was scored based on:
Participants’ models earned a score each time their response outperformed the 90B model in a head-to-head comparison. The leaderboard dynamically updated as new submissions were evaluated, fostering a competitive yet collaborative learning environment.
The Grand Finale of the AWS LLM League was an electrifying showdown, where the top five finalists, handpicked from hundreds of submissions, competed in a high-stakes live event. Among them was Ray, a determined contender whose fine-tuned model had consistently delivered strong results throughout the competition. Each finalist had to prove not just the technical superiority of their fine-tuned models, but also their ability to adapt and refine responses in real-time.

The competition was intense from the outset, with each participant bringing unique strategies to the table. Ray’s ability to tweak prompts dynamically set him apart early on, providing optimal responses to a range of domain-specific questions. The energy in the room was palpable as finalists’ AI-generated answers were judged by a hybrid evaluation system—40% by an LLM, 40% by expert panelists from Meta AI and AWS, and 20% by an enthusiastic live audience against the following rubric:
One of the most gripping moments came when contestants encountered the infamous Strawberry Problem, a deceptively simple letter-counting challenge that exposed an inherent weakness in LLMs. Ray’s model delivered the correct answer, but the AI judge misclassified it, sparking a debate among the human judges and audience. This pivotal moment underscored the importance of human-in-the-loop evaluation, highlighting how AI and human judgment must complement each other for fair and accurate assessments.
As the final round concluded, Ray’s model consistently outperformed expectations, securing him the title of AWS LLM League Champion. The Grand Finale was not just a test of AI—it was a showcase of innovation, strategy, and the evolving synergy between artificial intelligence and human ingenuity.

The inaugural AWS LLM League competition successfully demonstrated how large language model fine-tuning can be gamified to drive innovation and engagement. By providing hands-on experience with cutting-edge AWS AI and machine learning (ML) services, the competition not only demystified the fine-tuning process, but also inspired a new wave of AI enthusiasts to experiment and innovate in this space.
As the AWS LLM League moves forward, future iterations will expand on these learnings, incorporating more advanced challenges, larger datasets, and deeper model customization opportunities. Whether you’re a seasoned AI practitioner or a newcomer to machine learning, the AWS LLM League offers an exciting and accessible way to develop real-world AI expertise.
Stay tuned for upcoming AWS LLM League events and get ready to put your fine-tuning skills to the test!
 Vincent Oh is the Senior Specialist Solutions Architect in AWS for AI & Innovation. He works with public sector customers across ASEAN, owning technical engagements and helping them design scalable cloud solutions across various innovation projects. He created the LLM League in the midst of helping customers harness the power of AI in their use cases through gamified learning. He also serves as an Adjunct Professor in Singapore Management University (SMU), teaching computer science modules under School of Computer & Information Systems (SCIS). Prior to joining Amazon, he worked as Senior Principal Digital Architect at Accenture and Cloud Engineering Practice Lead at UST.
Vincent Oh is the Senior Specialist Solutions Architect in AWS for AI & Innovation. He works with public sector customers across ASEAN, owning technical engagements and helping them design scalable cloud solutions across various innovation projects. He created the LLM League in the midst of helping customers harness the power of AI in their use cases through gamified learning. He also serves as an Adjunct Professor in Singapore Management University (SMU), teaching computer science modules under School of Computer & Information Systems (SCIS). Prior to joining Amazon, he worked as Senior Principal Digital Architect at Accenture and Cloud Engineering Practice Lead at UST.
 Natasya K. Idries is the Product Marketing Manager for AWS AI/ML Gamified Learning Programs. She is passionate about democratizing AI/ML skills through engaging and hands-on educational initiatives that bridge the gap between advanced technology and practical business implementation. Her expertise in building learning communities and driving digital innovation continues to shape her approach to creating impactful AI education programs. Outside of work, Natasya enjoys traveling, cooking Southeast Asian cuisines and exploring nature trails.
Natasya K. Idries is the Product Marketing Manager for AWS AI/ML Gamified Learning Programs. She is passionate about democratizing AI/ML skills through engaging and hands-on educational initiatives that bridge the gap between advanced technology and practical business implementation. Her expertise in building learning communities and driving digital innovation continues to shape her approach to creating impactful AI education programs. Outside of work, Natasya enjoys traveling, cooking Southeast Asian cuisines and exploring nature trails.

As a teenager, Bradley Rothenberg was obsessed with CAD: computer-aided design software.
Before he turned 30, Rothenberg channeled that interest into building a startup, nTop, which today offers product developers — across vastly different industries — fast, highly iterative tools that help them model and create innovative, often deeply unorthodox designs.
One of Rothenberg’s key insights has been how closely iteration at scale and innovation correlate — especially in the design space.
He also realized that by creating engineering software for GPUs, rather than CPUs — which powered (and still power) virtually every CAD tool — nTop could tap into parallel processing algorithms and AI to offer designers fast, virtually unlimited iteration for any design project. The result: almost limitless opportunities for innovation.
Product designers of all stripes took note.
A decade after its founding, nTop — a member of the NVIDIA Inception program for cutting-edge startups — now employs more than 100 people, primarily in New York City, where it’s headquartered, as well as in Germany, France and the U.K. — with plans to grow another 10% by year’s end.
Its computation design tools autonomously iterate alongside designers, spitballing different virtual shapes and potential materials to arrive at products, or parts of a product, that are highly performant. It’s design trial and error at scale.
“As a designer, you frequently have all these competing goals and questions: If I make this change, will my design be too heavy? Will it be too thick?” Rothenberg said. “When making a change to the design, you want to see how that impacts performance, and nTop helps evaluate those performance changes in real time.”

U.K.-based supermarket chain Ocado, which builds and deploys autonomous robots, is one of nTop’s biggest customers.
Ocado differentiates itself from other large European grocery chains through its deep integration of autonomous robots and grocery picking. Its office-chair-sized robots speed around massive warehouses — approaching the size of eight American football fields — at around 20 mph, passing within a millimeter of one another as they pick and sort groceries in hive-like structures.
In early designs, Ocado’s robots often broke down or even caught fire. Their weight also meant Ocado had to build more robust — and more expensive — warehouses.
Using nTop’s software, Ocado’s robotics team quickly redesigned 16 critical parts in its robots, cutting the robot’s overall weight by two-thirds. Critically, the redesign took around a week. Earlier redesigns that didn’t use nTop’s tools took about four months.

“Ocado created a more robust version of its robot that was an order of magnitude cheaper and faster,” Rothenberg said. “Its designers went through these rapid design cycles where they could press a button and the entire robot’s structure would be redesigned overnight using nTop, prepping it for testing the next day.”
The Ocado use case is typical of how designers use nTop’s tools.
nTop software runs hundreds of simulations analyzing how different conditions might impact a design’s performance. Insights from those simulations are then fed back into the design algorithm, and the entire process restarts. Designers can easily tweak their designs based on the results, until the iterations land on an optimal result.
nTop has begun integrating AI models into its simulation workloads, along with an nTop customer’s bespoke design data into its iteration process. nTop uses the NVIDIA Modulus framework, NVIDIA Omniverse platform and NVIDIA CUDA-X libraries to train and infer its accelerated computing workloads and AI models.
“We have neural networks that can be trained on the geometry and physics of a company’s data,” Rothenberg said. “If a company has a specific way of engineering the structure of a car, it can construct that car in nTop, train up an AI in nTop and very quickly iterate through different versions of the car’s structure or any future car designs by accessing all the data the model is already trained on.”
nTop’s tools have wide applicability across industries.
A Formula 1 design team used nTop to virtually model countless versions of heat sinks before choosing an unorthodox but highly performant sink for its car.
Traditionally, heat sinks are made of small, uniform pieces of metal aligned side by side to maximize metal-air interaction and, therefore, heat exchange and cooling.

The engineers iterated with nTop on an undulating multilevel sink that maximized air-metal interaction even as it optimized aerodynamics, which is crucial for racing.
The new heat sink achieved 3x the surface area for heat transfer than earlier models, while cutting weight by 25%, delivering superior cooling performance and enhanced efficiency.
Going forward, nTop anticipates its implicit modeling tools will drive greater adoption from product designers who want to work with an iterative “partner” trained on their company’s proprietary data.
“We work with many different partners who develop designs, run a bunch of simulations using models and then optimize for the best results,” said Rothenberg. “The advances they’re making really speak for themselves.”
Learn more about nTop’s product design workflow and work with partners.
Novel three-pronged approach combines claim-level evaluations, chain-of-thought reasoning, and classification of hallucination error types.Read More