Organizations across various industries are using artificial intelligence (AI) and machine learning (ML) to solve business challenges specific to their industry. For example, in the financial services industry, you can use AI and ML to solve challenges around fraud detection, credit risk prediction, direct marketing, and many others.
Large enterprises sometimes set up a center of excellence (CoE) to tackle the needs of different lines of business (LoBs) with innovative analytics and ML projects.
To generate high-quality and performant ML models at scale, they need to do the following:
- Provide an easy way to access relevant data to their analytics and ML CoE
- Create accountability on data providers from individual LoBs to share curated data assets that are discoverable, understandable, interoperable, and trustworthy
This can reduce the long cycle time for converting ML use cases from experiment to production and generate business value across the organization.
A data mesh architecture strives to solve these technical and organizational challenges by introducing a decentralized socio-technical approach to share, access, and manage data in complex and large-scale environments—within or across organizations. The data mesh design pattern creates a responsible data-sharing model that aligns with the organizational growth to achieve the ultimate goal of increasing the return of business investments in the data teams, process, and technology.
In this two-part series, we provide guidance on how organizations can build a modern data architecture using a data mesh design pattern on AWS and enable an analytics and ML CoE to build and train ML models with data across multiple LoBs. We use an example of a financial service organization to set the context and the use case for this series.
Build and train ML models using a data mesh architecture on AWS:
|
In this first post, we show the procedures of setting up a data mesh architecture with multiple AWS data producer and consumer accounts. Then we focus on one data product, which is owned by one LoB within the financial organization, and how it can be shared into a data mesh environment to allow other LoBs to consume and use this data product. This is mainly targeting the data steward persona, who is responsible for streamlining and standardizing the process of sharing data between data producers and consumers and ensuring compliance with data governance rules.
In the second post, we show one example of how an analytics and ML CoE can consume the data product for a risk prediction use case. This is mainly targeting the data scientist persona, who is responsible for utilizing both organizational-wide and third-party data assets to build and train ML models that extract business insights to enhance the experience of financial services customers.
Data mesh overview
The founder of the data mesh pattern, Zhamak Dehghani in her book Data Mesh Delivering Data-Driven Value at Scale, defined four principles towards the objective of the data mesh:
- Distributed domain ownership – To pursue an organizational shift from centralized ownership of data by specialists who run the data platform technologies to a decentralized data ownership model, pushing ownership and accountability of the data back to the LoBs where data is produced (source-aligned domains) or consumed (consumption-aligned domains).
- Data as a product – To push upstream the accountability of sharing curated, high-quality, interoperable, and secure data assets. Therefore, data producers from different LoBs are responsible for making data in a consumable form right at the source.
- Self-service analytics – To streamline the experience of data users of analytics and ML so they can discover, access, and use data products with their preferred tools. Additionally, to streamline the experience of LoB data providers to build, deploy, and maintain data products via recipes and reusable components and templates.
- Federated computational governance – To federate and automate the decision-making involved in managing and controlling data access to be on the level of data owners from the different LoBs, which is still in line with the wider organization’s legal, compliance, and security policies that are ultimately enforced through the mesh.
AWS introduced its vision for building a data mesh on top of AWS in various posts:
- First, we focused on the organizational part associated with distributed domain ownership and data as a product principles. The authors described the vision of aligning multiple LOBs across the organization towards a data product strategy that provides the consumption-aligned domains with tools to find and obtain the data they need, while guaranteeing the necessary control around the use of that data by introducing accountability for the source-aligned domains to provide data products ready to be used right at the source. For more information, refer to How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform.
- Then we focused on the technical part associated with building data products, self-service analytics, and federated computational governance principles. The authors described the core AWS services that empower the source-aligned domains to build and share data products, a wide variety of services that can enable consumer-aligned domains to consume data products in different ways based on their preferred tools and the use cases they are working towards, and finally the AWS services that govern the data sharing procedure by enforcing data access polices. For more information, refer to Design a data mesh architecture using AWS Lake Formation and AWS Glue.
- We also showed a solution to automate data discovery and access control through a centralized data mesh UI. For more details, refer to Build a data sharing workflow with AWS Lake Formation for your data mesh.
Financial services use case
Typically, large financial services organizations have multiple LoBs, such as consumer banking, investment banking, and asset management, and also one or more analytics and ML CoE teams. Each LoB provides different services:
- The consumer banking LoB provides a variety of services to consumers and businesses, including credit and mortgage, cash management, payment solutions, deposit and investment products, and more
- The commercial or investment banking LoB offers comprehensive financial solutions, such as lending, bankruptcy risk, and wholesale payments to clients, including small businesses, mid-sized companies, and large corporations
- The asset management LoB provides retirement products and investment services across all asset classes
Each LoB defines their own data products, which are curated by people who understand the data and are best suited to specify who is authorized to use it, and how it can be used. In contrast, other LoBs and application domains such as the analytics and ML CoE are interested in discovering and consuming qualified data products, blending it together to generate insights, and making data-driven decisions.
The following illustration depicts some LoBs and examples of data products that they can share. It also shows the consumers of data products such as the analytics and ML CoE, who build ML models that can be deployed to customer-facing applications to further enhance the end-customer’s experience.
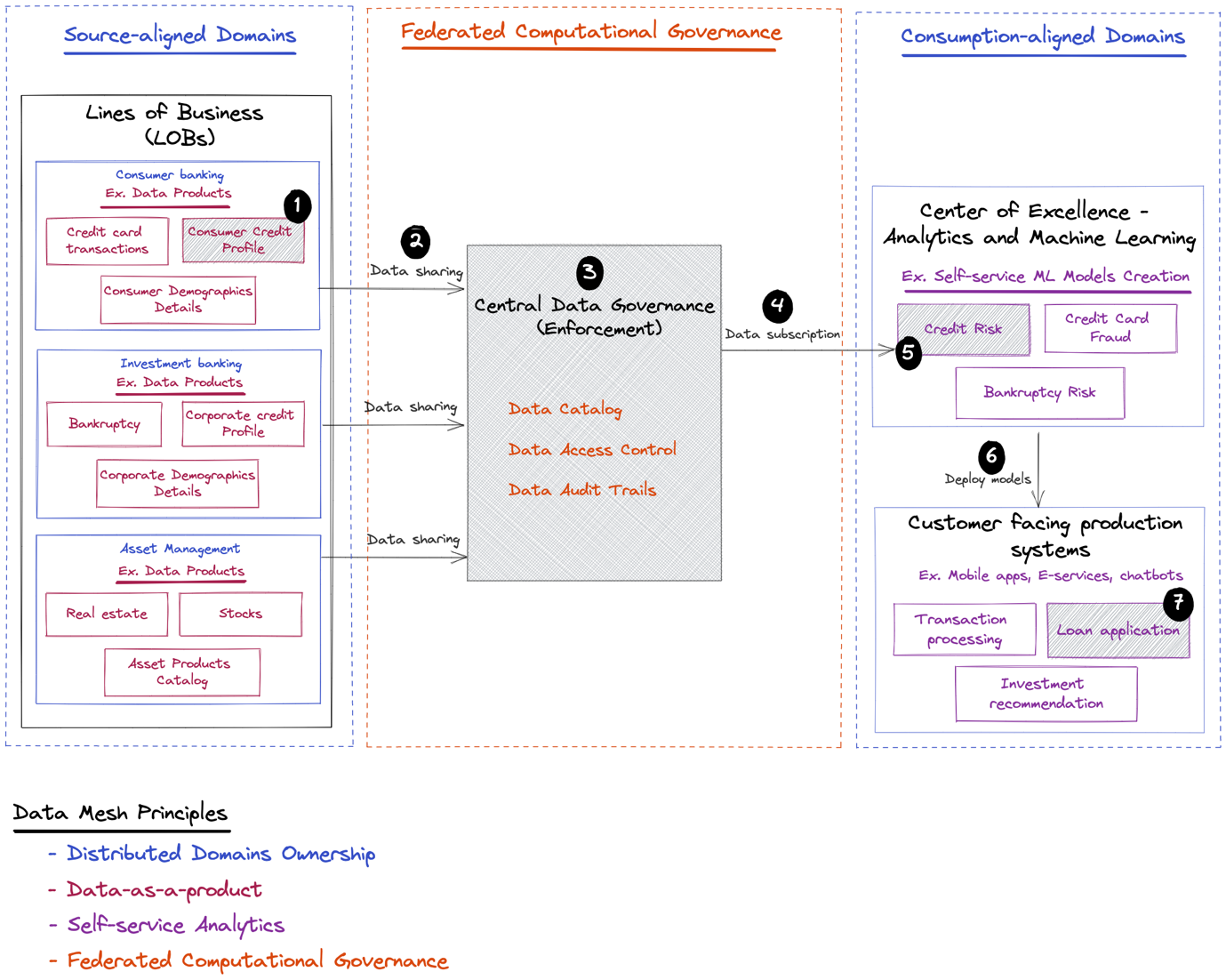
Following the data mesh socio-technical concept, we start with the social aspect with a set of organizational steps, such as the following:
- Utilizing domain experts to define boundaries for each domain, so each data product can be mapped to a specific domain
- Identifying owners for data products provided from each domain, so each data product has a strategy defined by their owner
- Identifying governance polices from global and local or federated incentives, so when data consumers access a specific data product, the access policy associated with the product can be automatically enforced through a central data governance layer
Then we move to the technical aspect, which includes the following end-to-end scenario defined in the previous diagram:
- Empower the consumer banking LoB with tools to build a ready-to-use consumer credit profile data product.
- Allow the consumer banking LoB to share data products into the central governance layer.
- Embed global and federated definitions of data access policies that should be enforced while accessing the consumer credit profile data product through the central data governance.
- Allow the analytics and ML CoE to discover and access the data product through the central governance layer.
- Empower the analytics and ML CoE with tools to utilize the data product for building and training a credit risk prediction model.We don’t cover the final steps (6 and 7 in the preceding diagram) in this series. However, to show the business value such an ML model can bring to the organization in an end-to-end scenario, we illustrate the following:
- This model could later be deployed back to customer-facing systems such as a consumer banking web portal or mobile application.
- It can be specifically used within the loan application to assess the risk profile of credit and mortgage requests.
Next, we describe the technical needs of each of the components.
Deep dive into technical needs
To make data products available for everyone, organizations need to make it easy to share data between different entities across the organization while maintaining appropriate control over it, or in other words, to balance agility with proper governance.
Data consumer: Analytics and ML CoE
The data consumers such as data scientists from the analytics and ML CoE need to be able to do the following:
- Discover and access relevant datasets for a given use case
- Be confident that datasets they want to access are already curated, up to date, and have robust descriptions
- Request access to datasets of interest to their business cases
- Use their preferred tools to query and process such datasets within their environment for ML without the need for replicating data from the original remote location or for worrying about engineering or infrastructure complexities associated with processing data physically stored in a remote site
- Get notified of any data updates made by the data owners
Data producer: Domain ownership
The data producers, such as domain teams from different LoBs in the financial services org, need to register and share curated datasets that contain the following:
- Technical and operational metadata, such as database and table names and sizes, column schemas, and keys
- Business metadata such as data description, classification, and sensitivity
- Tracking metadata such as schema evolution from the source to the target form and any intermediate forms
- Data quality metadata such as correctness and completeness ratios and data bias
- Access policies and procedures
These are needed to allow data consumers to discover and access data without relying on manual procedures or having to contact the data product’s domain experts to gain more knowledge about the meaning of the data and how it can be accessed.
Data governance: Discoverability, accessibility, and auditability
Organizations need to balance the agilities illustrated earlier with proper mitigation of the risks associated with data leaks. Particularly in regulated industries like financial services, there is a need to maintain central data governance to provide overall data access and audit control while reducing the storage footprint by avoiding multiple copies of the same data across different locations.
In traditional centralized data lake architectures, the data producers often publish raw data and pass on the responsibility of data curation, data quality management, and access control to data and infrastructure engineers in a centralized data platform team. However, these data platform teams may be less familiar with the various data domains, and still rely on support from the data producers to be able to properly curate and govern access to data according to the policies enforced at each data domain. In contrast, the data producers themselves are best positioned to provide curated, qualified data assets and are aware of the domain-specific access polices that need to be enforced while accessing data assets.
Solution overview
The following diagram shows the high-level architecture of the proposed solution.

We address data consumption by the analytics and ML CoE with Amazon Athena and Amazon SageMaker in part 2 of this series.
In this post, we focus on the data onboarding process into the data mesh and describe how an individual LoB such as the consumer banking domain data team can use AWS tools such as AWS Glue and AWS Glue DataBrew to prepare, curate, and enhance the quality of their data products, and then register those data products into the central data governance account through AWS Lake Formation.
Consumer banking LoB (data producer)
One of the core principles of data mesh is the concept of data as a product. It’s very important that the consumer banking domain data team work on preparing data products that are ready for use by data consumers. This can be done by using AWS extract, transform, and load (ETL) tools like AWS Glue to process raw data collected on Amazon Simple Storage Service (Amazon S3), or alternatively connect to the operational data stores where the data is produced. You can also use DataBrew, which is a no-code visual data preparation tool that makes it easy to clean and normalize data.
For example, while preparing the consumer credit profile data product, the consumer banking domain data team can make a simple curation to translate from German to English the attribute names of the raw data retrieved from the open-source dataset Statlog German credit data, which consists of 20 attributes and 1,000 rows.
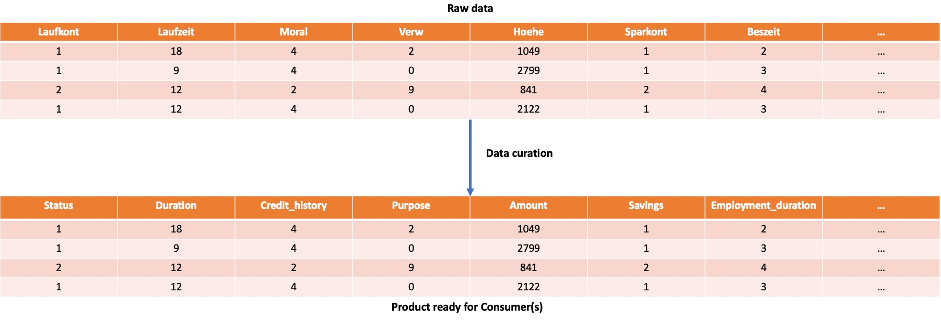
Data governance
The core AWS service for enabling data mesh governance is Lake Formation. Lake Formation offers the ability to enforce data governance within each data domain and across domains to ensure data is easily discoverable and secure. It provides a federated security model that can be administered centrally, with best practices for data discovery, security, and compliance, while allowing high agility within each domain.
Lake Formation offers an API to simplify how data is ingested, stored, and managed, together with row-level security to protect your data. It also provides functionality like granular access control, governed tables, and storage optimization.
In addition, Lake Formations offers a Data Sharing API that you can use to share data across different accounts. This allows the analytics and ML CoE consumer to run Athena queries that query and join tables across multiple accounts. For more information, refer to the AWS Lake Formation Developer Guide.
AWS Resource Access Manager (AWS RAM) provides a secure way to share resources via AWS Identity and Access Manager (IAM) roles and users across AWS accounts within an organization or organizational units (OUs) in AWS Organizations.
Lake Formation together with AWS RAM provides one way to manage data sharing and access across AWS accounts. We refer to this approach as RAM-based access control. For more details about this approach, refer to Build a data sharing workflow with AWS Lake Formation for your data mesh.
Lake Formation also offers another way to manage data sharing and access using Lake Formation tags. We refer to this approach as tag-based access control. For more details, refer to Build a modern data architecture and data mesh pattern at scale using AWS Lake Formation tag-based access control.
Throughout this post, we use the tag-based access control approach because it simplifies the creation of policies on a smaller number of logical tags that are commonly found in different LoBs instead of specifying policies on named resources at the infrastructure level.
Prerequisites
To set up a data mesh architecture, you need at least three AWS accounts: a producer account, a central account, and a consumer account.
Deploy the data mesh environment
To deploy a data mesh environment, you can use the following GitHub repository. This repository contains three AWS CloudFormation templates that deploy a data mesh environment that includes each of the accounts (producer, central, and consumer). Within each account, you can run its corresponding CloudFormation template.
Central account
In the central account, complete the following steps:
- Launch the CloudFormation stack:

- Create two IAM users:
DataMeshOwnerProducerSteward
- Grant
DataMeshOwneras the Lake Formation admin. - Create one IAM role:
LFRegisterLocationServiceRole
- Create two IAM policies:
ProducerStewardPolicyS3DataLakePolicy
- Create the database credit-card for
ProducerStewardat the producer account. - Share the data location permission to the producer account.
Producer account
In the producer account, complete the following steps:
- Launch the CloudFormation stack:
- Create the S3 bucket
credit-card, which holds the tablecredit_card. - Allow S3 bucket access for the central account Lake Formation service role.
- Create the AWS Glue crawler
creditCrawler-<ProducerAccountID>. - Create an AWS Glue crawler service role.
- Grant permissions on the S3 bucket location
credit-card-<ProducerAccountID>-<aws-region>to the AWS Glue crawler role. - Create a producer steward IAM user.
Consumer account
In the consumer account, complete the following steps:
- Launch the CloudFormation stack:
- Create the S3 bucket
<AWS Account ID>-<aws-region>-athena-logs. - Create the Athena workgroup
consumer-workgroup. - Create the IAM user
ConsumerAdmin.
Add a database and subscribe the consumer account to it
After you run the templates, you can go through the step-by-step guide to add a product in the data catalog and have the consumer subscribed to it. The guide starts by setting up a database where the producer can place its products and then explains how the consumer can subscribe to that database and access the data. All of this is performed while using LF-tags, which is the tag-based access control for Lake Formation.
Data product registration
The following architecture describes the detailed steps of how the consumer banking LoB team acting as data producers can register their data products in the central data governance account (onboard data products to the organization data mesh).
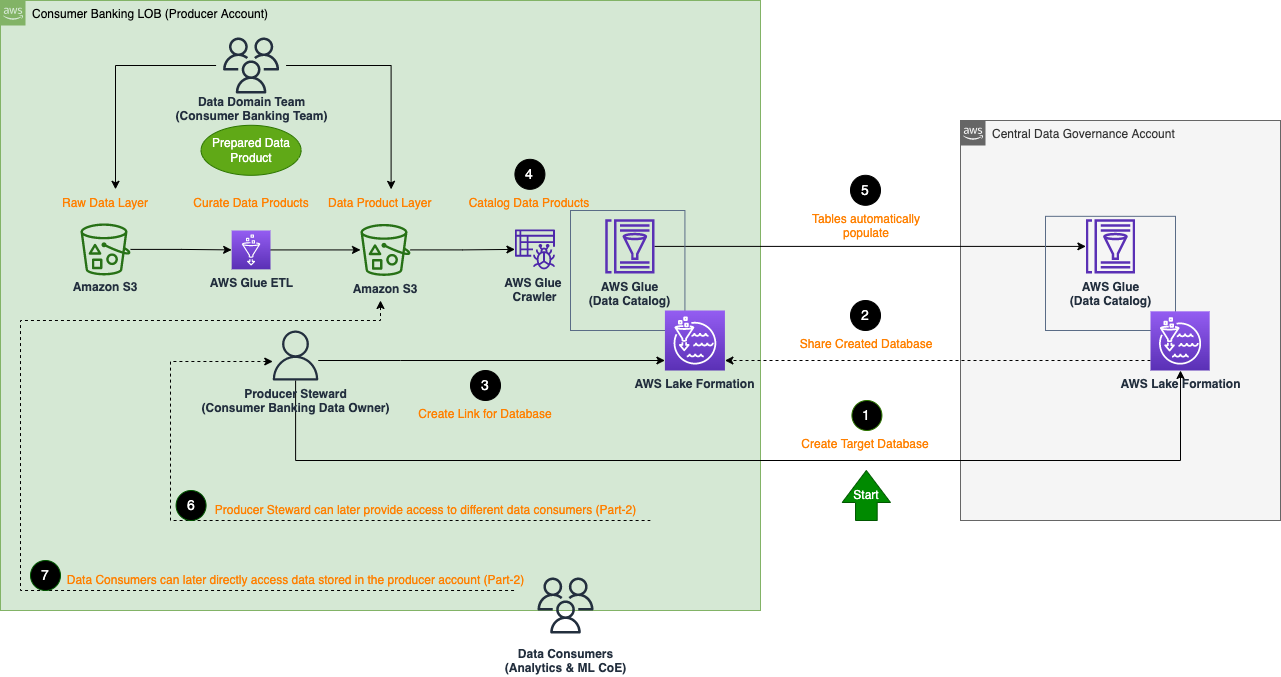
The general steps to register a data product are as follows:
- Create a target database for the data product in the central governance account. As an example, the CloudFormation template from the central account already creates the target database
credit-card. - Share the created target database with the origin in the producer account.
- Create a resource link of the shared database in the producer account. In the following screenshot, we see on the Lake Formation console in the producer account that
rl_credit-cardis the resource link of thecredit-carddatabase.

- Populate tables (with the data curated in the producer account) inside the resource link database (
rl_credit-card) using an AWS Glue crawler in the producer account.

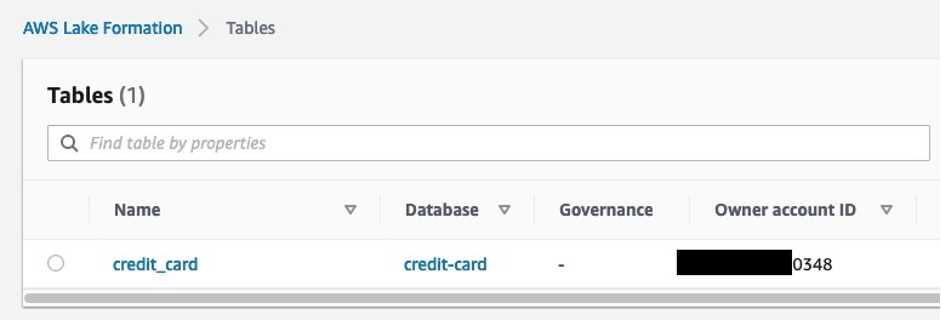
The created table automatically appears in the central governance account. The following screenshot shows an example of the table in Lake Formation in the central account. This is after performing the earlier steps to populate the resource link database rl_credit-card in the producer account.
Conclusion
In part 1 of this series, we discussed the goals of financial services organizations to achieve more agility for their analytics and ML teams and reduce the time from data to insights. We also focused on building a data mesh architecture on AWS, where we’ve introduced easy-to-use, scalable, and cost-effective AWS services such as AWS Glue, DataBrew, and Lake Formation. Data producing teams can use these services to build and share curated, high-quality, interoperable, and secure data products that are ready to use by different data consumers for analytical purposes.
In part 2, we focus on analytics and ML CoE teams who consume data products shared by the consumer banking LoB to build a credit risk prediction model using AWS services such as Athena and SageMaker.
About the authors
 Karim Hammouda is a Specialist Solutions Architect for Analytics at AWS with a passion for data integration, data analysis, and BI. He works with AWS customers to design and build analytics solutions that contribute to their business growth. In his free time, he likes to watch TV documentaries and play video games with his son.
Karim Hammouda is a Specialist Solutions Architect for Analytics at AWS with a passion for data integration, data analysis, and BI. He works with AWS customers to design and build analytics solutions that contribute to their business growth. In his free time, he likes to watch TV documentaries and play video games with his son.
 Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, Hasan helps customers design and deploy machine learning applications in production on AWS. He has over 12 years of work experience as a data scientist, machine learning practitioner, and software developer. In his spare time, Hasan loves to explore nature and spend time with friends and family.
Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, Hasan helps customers design and deploy machine learning applications in production on AWS. He has over 12 years of work experience as a data scientist, machine learning practitioner, and software developer. In his spare time, Hasan loves to explore nature and spend time with friends and family.
 Benoit de Patoul is an AI/ML Specialist Solutions Architect at AWS. He helps customers by providing guidance and technical assistance to build solutions related to AI/ML using AWS. In his free time, he likes to play piano and spend time with friends.
Benoit de Patoul is an AI/ML Specialist Solutions Architect at AWS. He helps customers by providing guidance and technical assistance to build solutions related to AI/ML using AWS. In his free time, he likes to play piano and spend time with friends.