When most people think of using machine learning (ML) with audio data, the use case that usually comes to mind is transcription, also known as speech-to-text. However, there are other useful applications, including using ML to detect sounds.
Using software to detect a sound is called audio event detection, and it has a number of applications. For example, suppose you want to monitor the sounds from a noisy factory floor, listening for an alarm bell that indicates a problem with a machine. In a healthcare environment, you can use audio event detection to passively listen for sounds from a patient that indicate an acute health problem. Media workloads are a good fit for this technique, for example to detect when a referee’s whistle is blown in a sports video. And of course, you can use this technique in a variety of surveillance workloads, like listening for a gunshot or the sound of a car crash from a microphone mounted above a city street.
This post describes how to detect sounds in an audio file even if there are significant background sounds happening at the same time. What’s more, perhaps surprisingly, we use computer vision-based techniques to do the detection, using Amazon Rekognition.
Using audio data with machine learning
The first step in detecting audio events is understanding how audio data is represented. For the purposes of this post, we deal only with recorded audio, although these techniques work with streaming audio.
Recorded audio is typically stored as a sequence of sound samples, which measure the intensity of the sound waves that struck the microphone during recording, over time. There are a wide variety of formats with which to store these samples, but a common approach is to store 10,000, 20,000, or even 40,000 samples per second, with each sample being an integer from 0–65535 (two bytes). Because each sample measures only the intensity of sound waves at a particular moment, the sound data generally isn’t helpful for ML processes because it doesn’t have any useful features in its raw state.
To make that data useful, the sound sample is converted into an image called a spectrogram, which is a representation of the audio data that shows the intensity of different frequency bands over time. The following image shows an example.

The X axis of this image represents time, meaning that the left edge of the image is the very start of the sound, and the right edge of the image is the end. Each column of data within the image represents different frequency bands (indicated by the scale on the left side of the image), and the color at each point represents the intensity of that frequency at that moment in time.
Vertical scaling for spectrograms can be changed to other representations. For example, linear scaling means that the Y axis is evenly divided over frequencies, logarithmic scaling uses a log scale, and so forth. The problem with using these representations is that the frequencies in a sound file are usually not evenly distributed, so most of the information we might be interested in ends up being clustered near the bottom of the image (the lower frequencies).
To solve that problem, our sample image is an example of a Mel spectrogram, which is scaled to closely approximate how human beings perceive sound. Notice the frequency indicators along the left side of the image—they give an idea of how they are distributed vertically, and it’s clear that it’s a non-linear scale.
Additionally, we can modify the measurement of intensity by frequency by time to enhance various features of the audio being measured. As with the Y axis scaling that is implemented by a Mel spectrogram, others emphasize features such as the intensity of the 12 distinctive pitch classes that are used to study music (chroma). Another class emphasizes horizonal (harmonic) features or vertical (percussive) features. The type of sound that is being detected should drive the type of spectrogram used for the detection system.
The earlier example spectrogram represents a music clip that is just over 2 minutes long. Zooming in reveals more detail, as is shown in the following image.

The numbers along the top of the image show the number of seconds from the start of the audio file. You can clearly see a sequence of sounds that seems to repeat more than four times per second, indicated by the bright colors near the bottom of the image.
As you can see, this is one of the benefits of converting audio to a spectrogram—distinct sounds are often easily visible with the naked eye, and even if they aren’t, they can frequently be detected using computer vision object detection algorithms. In fact, this is exactly the process we follow in order to detect sounds.
Looking for discrete sounds in a spectrogram
Depending on the length of the audio file that we’re searching, finding a discrete sound that lasts just a second or two is a challenge. Refer to the first spectrogram we shared—because we’re viewing an entire 3:30 minutes of data, details that last only a second or so aren’t visible. We zoomed in a great deal in order to see the rhythm that is shown in the second image. Clearly, with larger sound files (and therefore much larger spectrograms), we quickly run into problems unless we use a different approach. That approach is called windowing.
Windowing refers to using a sliding window that moves across the entire spectrogram, isolating a few seconds (or less) at a time. By repeatedly isolating portions of the overall image, we get smaller images that are searchable for the presence of the sound to be detected. Because each window could result in only part of the image we’re looking for (as in the case of searching for a sound that doesn’t start exactly at the start of a window), windowing is often performed with succeeding windows being overlapped. For example, the first window starts at 0:00 and extends 2 seconds, then the second window starts at 0:01 and extends 2 seconds, and the third window starts at 0:02 and extends 2 seconds, and so on.
Windowing splits a spectrogram image horizontally. We can improve the effectiveness of the detection process by isolating certain frequency bands by cropping or searching only certain vertical parts of the image. For example, if you know that the alarm bell you want to detect creates sounds that range from one specific frequency to another, you can modify the current window to only consider those frequency ranges. That vastly reduces the amount of data to be manipulated, and results in a much faster search. It also improves accuracy, because it’s eliminating possible false positives matches occurring in frequency bands outside of the desired range. The following images compare a full Y axis (left) with a limited Y axis (right).

Full Y Axis |
Limited Y Axis |
Now that we know how to iterate over a spectrogram with a windowing approach and filter to certain frequency bands, the next step is to do the actual search for the sound. For that, we use Amazon Rekognition Custom Labels. The Rekognition Custom Labels feature builds off of the existing capabilities of Amazon Rekognition, which is already trained on tens of millions of images across many categories. Instead of thousands of images, you simply need to upload a small set of training images (typically a few hundred images, but optimal training dataset size should be arrived at experimentally based on the specific use case to avoid under- or over-training the model) that are specific to your use case via the Rekognition Custom Labels console.
If your images are already labeled, Amazon Rekognition training is accessible with just a few clicks. Alternatively, you can label the images directly within the Amazon Rekognition labeling interface, or use Amazon SageMaker Ground Truth to label them for you. When Amazon Rekognition begins training from your image set, it produces a custom image analysis model for you in just a few hours. Behind the scenes, Rekognition Custom Labels automatically loads and inspects the training data, selects the right ML algorithms, trains a model, and provides model performance metrics. You can then use your custom model via the Rekognition Custom Labels API and integrate it into your applications.
Assembling training data and training a Rekognition Custom Labels model
In the GitHub repo associated with this post, you’ll find code that shows how to listen for the sound of a smoke alarm going off, regardless of background noise. In this case, our Rekognition Custom Labels model is a binary classification model, meaning that the results are either “smoke alarm sound was detected” or “smoke alarm sound was not detected.”
To create a custom model, we need training data. That training data is comprised of two main types: environmental sounds, and the sounds you wish to detect (like a smoke alarm going off).
The environmental data should represent a wide variety of soundscapes that are typical for the environment you want to detect the sound in. For example, if you want to detect a smoke alarm sound in a factory environment, start with sounds recorded in that factory environment under a variety of situations (without the smoke alarm sounding, of course).
The sounds you want to detect should be isolated if possible, meaning the recordings should just be the sound itself without any environmental background sounds. For our example, that’s a sound of a smoke alarm going off.
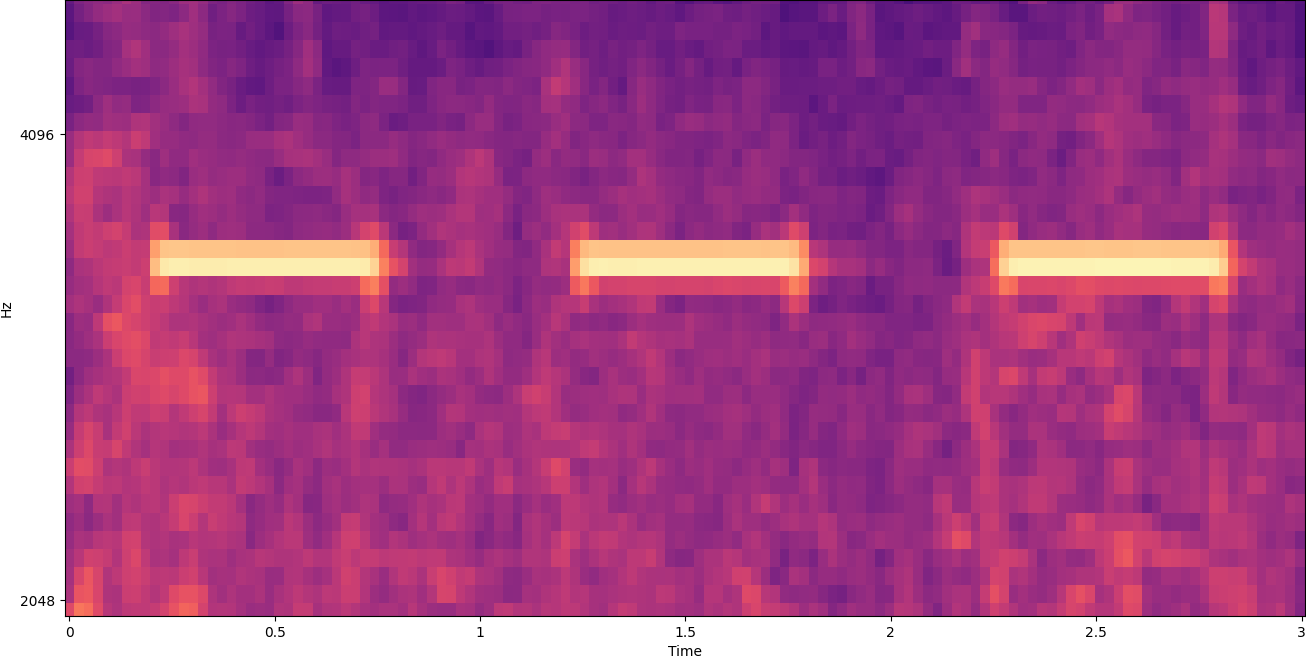
After you’ve collected these sounds, the code in the GitHub repo shows how to combine the environmental sounds with the smoke alarm sounds in various ways (and then convert them to spectrograms) in order to create a number of images that represent the environmental sounds with and without the smoke alarm sounds overlaid on them. The following image is an example of some environmental sounds with a smoke alarm sound (the bright horizontal bars) overlaid on top of it.

The training and test data is stored in an Amazon Simple Storage Service (Amazon S3) bucket. The following directory structure is a good starting point to organize data within the bucket.

The sample code in the GitHub repo allows you to choose how many training images to create. Rekognition Custom Labels doesn’t require a large number of training images. A training set of 200–500 images should be sufficient.
Creating a Rekognition Custom Labels project requires that you specify the URIs of the S3 folder that contains the training data, and (optionally) test data. When specifying the data sources for the training job, one of the options is Automatic labeling, as shown in the following screenshot.

Using this option means that Amazon Rekognition uses the names of the folders as the label names. For our smoke alarm detection use case, the folder structure inside of the train and test folders looks like the following screenshot.

The training data images go into those folders, with spectrograms containing the sound of the smoke alarm going in the alarm folder, and spectrograms that don’t contain the smoke alarm sound in the no_alarm folder. Amazon Rekognition uses those names as the output class names for the custom labels model.
Training a custom label model usually takes 30–90 minutes. At the end of that training, you must start the trained model so it becomes available for use.
End-to-end architecture for sound detection
After we create our model, the next step is to set up an inference pipeline, so we can use the model to detect if a smoke alarm sound is present in an audio file. To do this, the input sound must be turned into a spectrogram and then windowed and filtered by frequency, as was done for the training process. Each window of the spectrogram is given to the model, which returns a classification that indicates if the smoke alarm sounded or not.
The following diagram shows an example architecture that implements this inference pipeline.

This architecture waits for an audio file to be placed into an S3 bucket, which then causes an AWS Lambda function to be invoked. Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. You can trigger a Lambda function from over 200 AWS services and software as a service (SaaS) applications, and only pay for what you use.
The Lambda function receives the name of the bucket and the name of the key (or file name) of the audio file. The file is downloaded from Amazon S3 to the function’s memory, which then converts it into a spectrogram and performs windowing and frequency filtering. Each windowed portion of the spectrogram is then sent to Amazon Rekognition, which uses the previously-trained Amazon Custom Labels model to detect the sound. If that sound is found, the Lambda function signals that by using an Amazon Simple Notification Service (Amazon SNS) notification. Amazon SNS offers a pub/sub approach where notifications can be sent to Amazon Simple Queue Service (Amazon SQS) queues, Lambda functions, HTTPS endpoints, email addresses, mobile push, and more.
Conclusion
You can use machine learning with audio data to determine when certain sounds occur, even when other sounds are occurring at the same time. Doing so requires converting the sound into a spectrogram image, and then homing in on different parts of that spectrogram by windowing and filtering by frequency band. Rekognition Custom Labels makes it easy to train a custom model for sound detection.
You can use the GitHub repo containing the example code for this post as a starting point for your own experiments. For more information about audio event detection, refer to Sound Event Detection: A Tutorial.
About the authors
 Greg Sommerville is a Senior Prototyping Architect on the AWS Prototyping and Cloud Engineering team, where he helps AWS customers implement innovative solutions to challenging problems with machine learning, IoT and serverless technologies. He lives in Ann Arbor, Michigan and enjoys practicing yoga, catering to his dogs, and playing poker.
Greg Sommerville is a Senior Prototyping Architect on the AWS Prototyping and Cloud Engineering team, where he helps AWS customers implement innovative solutions to challenging problems with machine learning, IoT and serverless technologies. He lives in Ann Arbor, Michigan and enjoys practicing yoga, catering to his dogs, and playing poker.
 Jeff Harman is a Senior Prototyping Architect on the AWS Prototyping and Cloud Engineering team, where he helps AWS customers implement innovative solutions to challenging problems. He lives in Unionville, Connecticut and enjoys woodworking, blacksmithing, and Minecraft.
Jeff Harman is a Senior Prototyping Architect on the AWS Prototyping and Cloud Engineering team, where he helps AWS customers implement innovative solutions to challenging problems. He lives in Unionville, Connecticut and enjoys woodworking, blacksmithing, and Minecraft.