![]()
The Conference on Computer Vision and Pattern Recognition (CVPR) 2020 is being hosted virtually from June 14th – June 19th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Action Genome: Actions as Compositions of Spatio-temporal Scene Graphs
Authors: Jingwei Ji, Ranjay Krishna, Li Fei-Fei, Juan Carlos Niebles
Contact: jingweij@cs.stanford.edu
Links: Paper
Keywords: action recognition, scene graph, video understanding, relationships, composition, action, activity, video

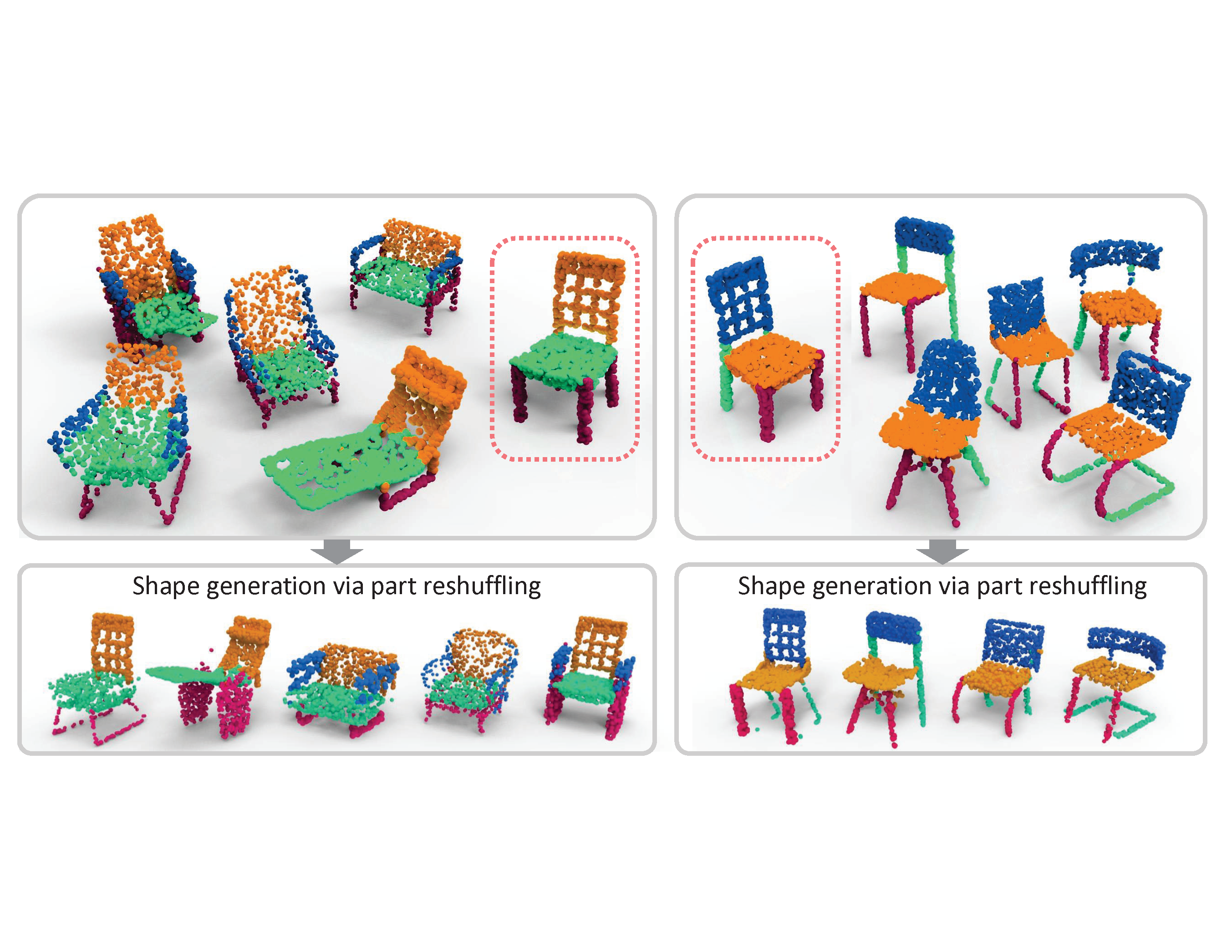
AdaCoSeg: Adaptive Shape Co-Segmentation with Group Consistency Loss
Authors: Chenyang Zhu, Kai Xu, Siddhartha Chaudhuri, Li Yi, Leonidas J. Guibas, Hao Zhang
Contact: guibas@cs.stanford.edu
Links: Paper
Keywords: shape segmentation, consistency
Adversarial Texture Optimization from RGB-D Scans
Authors: Jingwei Huang, Justus Thies, Angela Dai, Abhijit Kundu, Chiyu Jiang, Leonidas Guibas, Matthias Nießner, Thomas Funkhouser
Contact: jingweih@stanford,edu
Links: Paper | Video
Keywords: texture; adversarial;

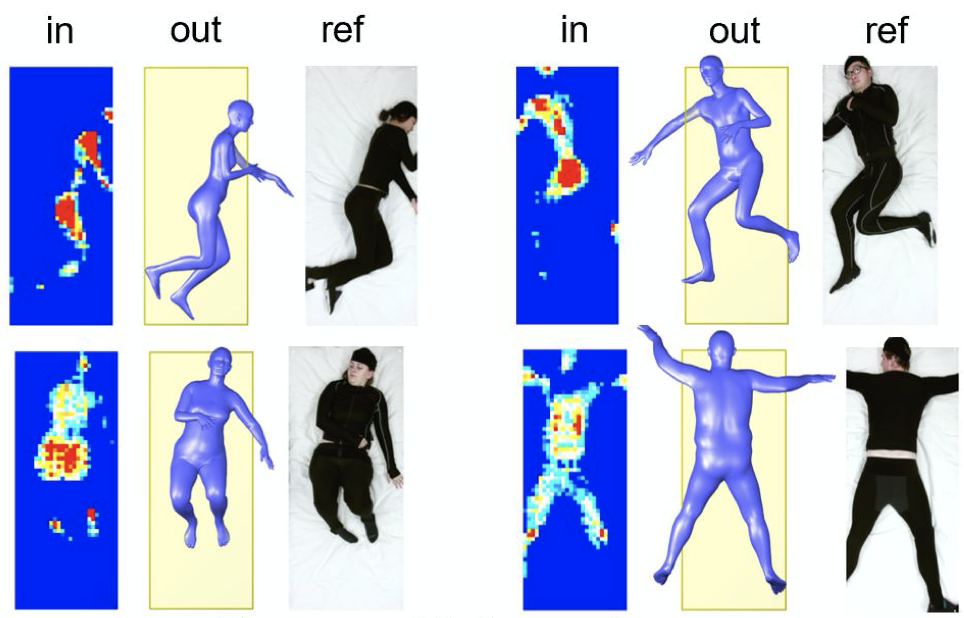
Bodies at Rest: 3D Human Pose and Shape Estimation from a Pressure Image using Synthetic Data
Authors: Henry M. Clever, Zackory Erickson, Ari Kapusta, Greg Turk, C.Karen Liu, and Charlie C. Kemp
Contact: karenliu@cs.stanford.edu
Links: Paper | Video
Keywords: human pose estimation;
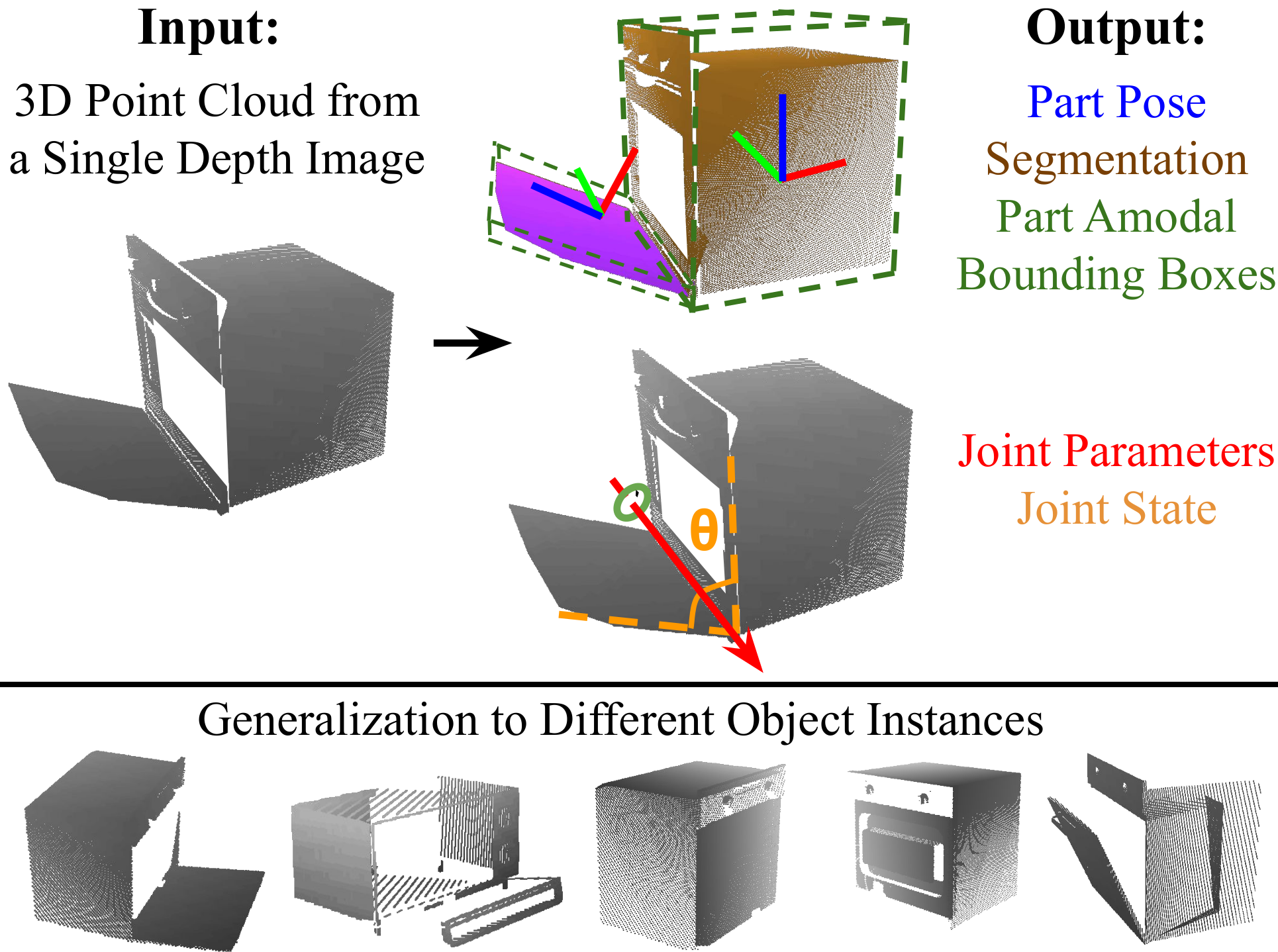
Category-Level Articulated Object Pose Estimation
Authors: Xiaolong Li, He Wang, Li Yi, Leonidas Guibas, A. Lynn Abbott, Shuran Song
Contact: hewang@stanford.edu
Award nominations: Oral presentation
Links: Paper | Video
Keywords: category level pose estimation, articulated object, 3d vision, point cloud, object part, object joint, segmentation, kinematic constraints
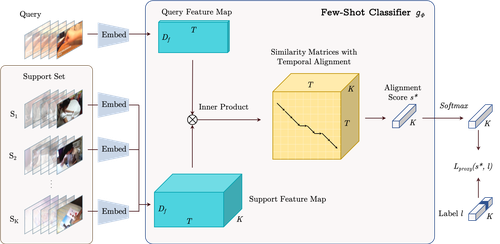
Few-Shot Video Classification via Temporal Alignment
Authors: Kaidi Cao, Jingwei Ji, Zhangjie Cao, Chien-Yi Chang, Juan Carlos Niebles
Contact: kaidicao@cs.stanford.edu
Links: Paper | Video
Keywords: video classification, few-shot learning, action recognition, temporal alignment
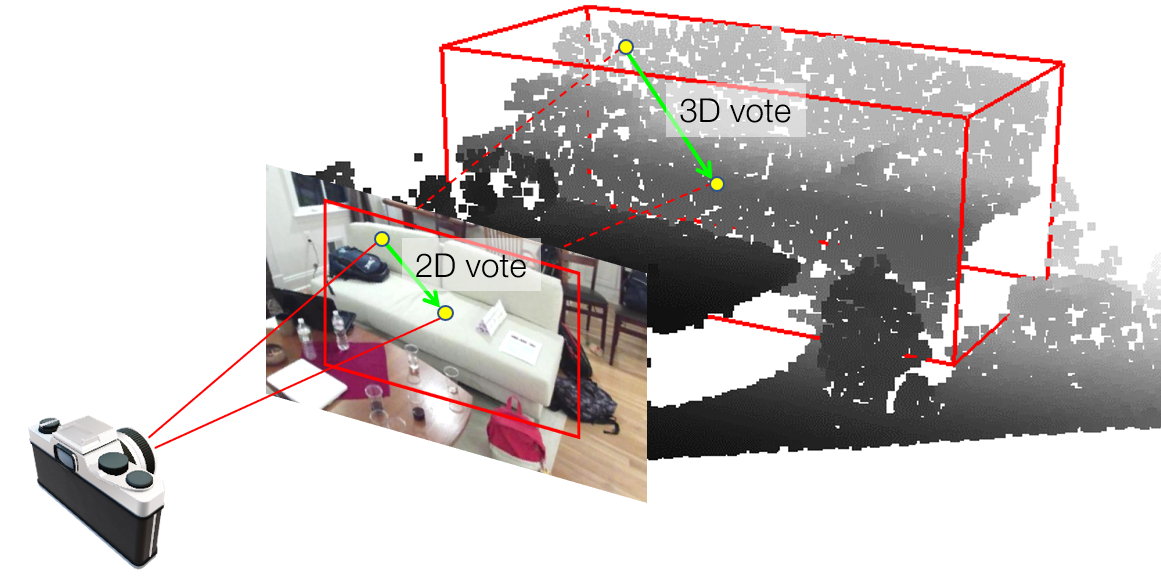
ImVoteNet: Boosting 3D Object Detection in Point Clouds With Image Votes
Authors: Charles R. Qi, Xinlei Chen, Or Litany, Leonidas J. Guibas
Contact: or.litany@gmail.com
Links: Paper
Keywords: 3d object detection, rgb-d, voting, point clouds, multi-modality, fusion, deep learning, object recognition.
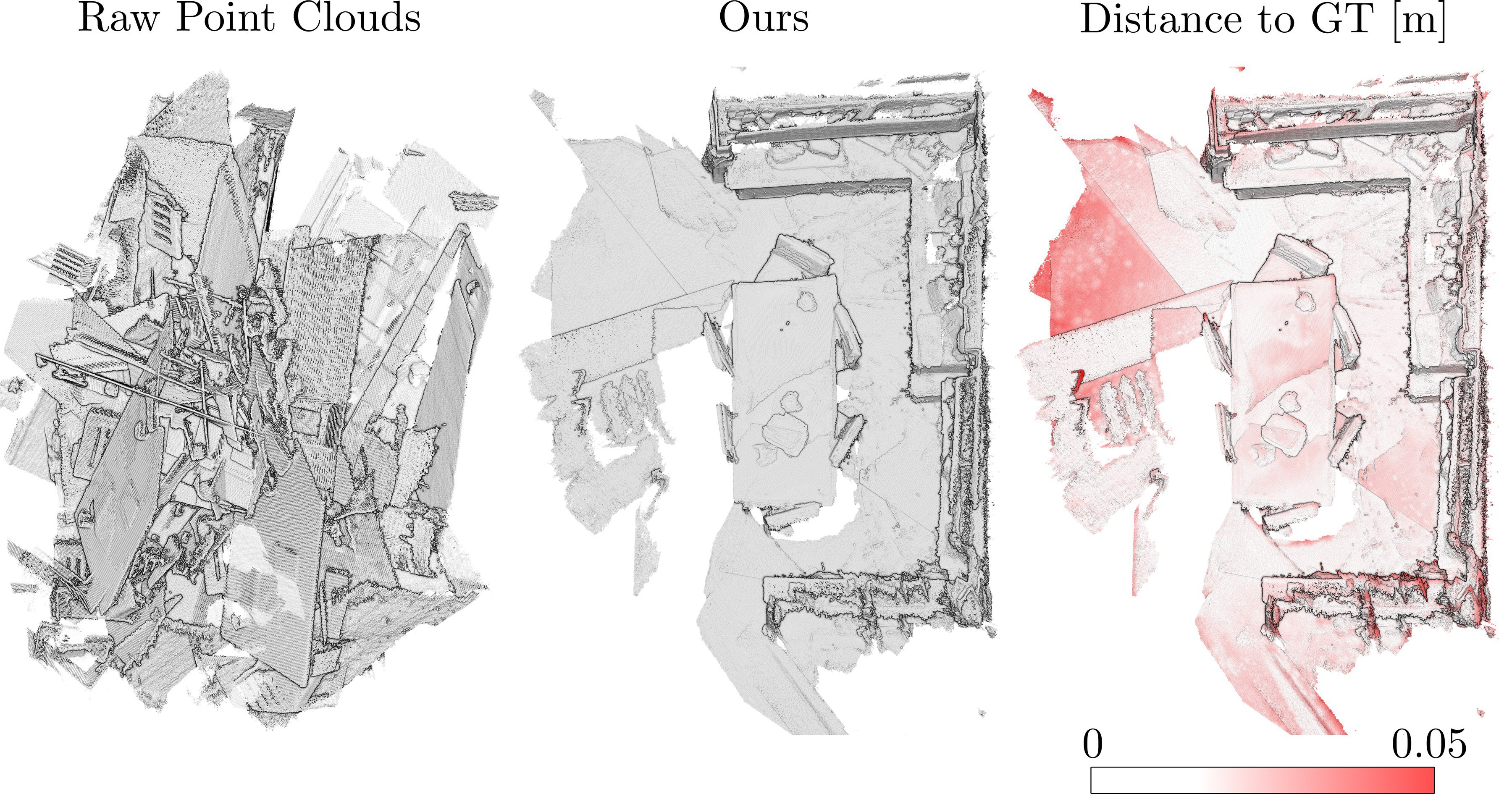
Learning multiview 3D point cloud registration
Authors: Zan Gojcic, Caifa Zhou, Jan D. Wegner, Leonidas J. Guibas, Tolga Birdal
Contact: tbirdal@stanford.edu
Links: Paper | Video
Keywords: registration, multiview, 3d reconstruction, point clouds, global alignment, synchronization, 3d, local features, end to end, 3d matching
Robust Learning Through Cross-Task Consistency
Authors: Amir R. Zamir, Alexander Sax, Nikhil Cheerla, Rohan Suri, Zhangjie Cao, Jitendra Malik, Leonidas J. Guibas;
Contact: guibas@cs.stanford.edu
Links: Paper | Video
Keywords: multi-task learning, transfer learning, cycle consistency

SAPIEN: A SimulAted Part-based Interactive ENvironment
Authors: Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X.Chang, Leonidas J. Guibas, Hao Su
Contact: kaichunm@stanford.edu
Award nominations: Oral presentation
Links: Paper | Video
Keywords: robotic simulator, 3d shape parts, robotic manipulation, 3d vision and robotics

Spatio-Temporal Graph for Video Captioning with Knowledge Distillation
Authors: Boxiao Pan, Haoye Cai, De-An Huang, Kuan-Hui Lee, Adrien Gaidon, Ehsan Adeli, Juan Carlos Niebles
Contact: bxpan@stanford.edu
Links: Paper | Video
Keywords: video captioning, spatio-temporal graph, knowledge distillation, video understanding, vision and language.
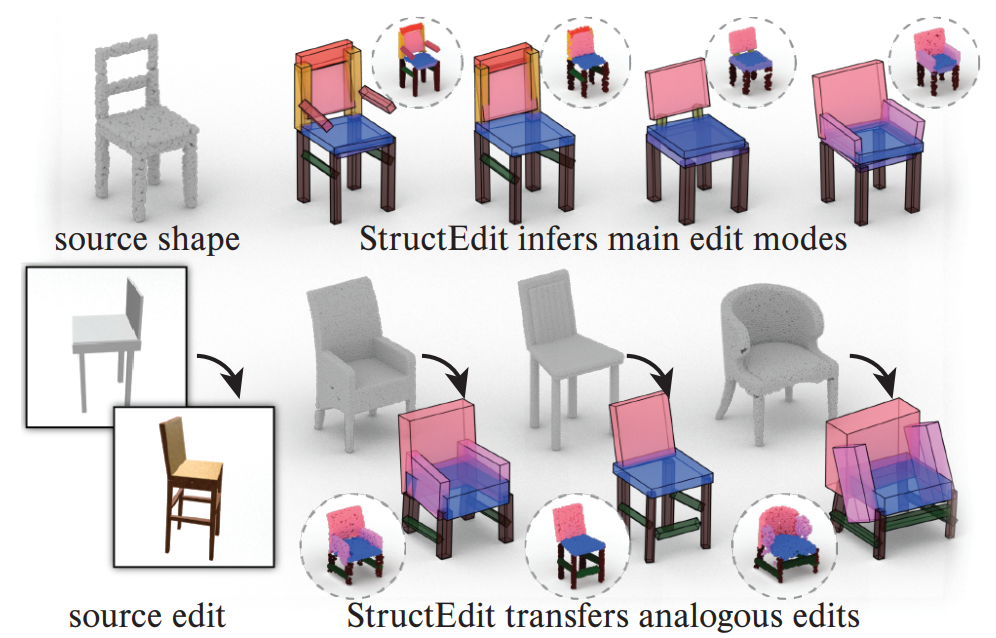
StructEdit: Learning Structural Shape Variations
Authors: Kaichun Mo, Paul Guerrero, Li Yi, Hao Su, Peter Wonka, Niloy Mitra, Leonidas J. Guibas
Contact: kaichunm@stanford.edu
Links: Paper
Keywords: shape editing; shape structure; 3d vision and graphics
Synchronizing Probability Measures on Rotations via Optimal Transport
Authors: Tolga Birdal, Michael Arbel, Umut Şimşekli, Leonidas Guibas
Contact: tbirdal@stanford.edu
Links: Paper | Video
Keywords: synchronization, optimal transport, rotation averaging, slam, sfm, probability measure, riemannian, gradient descent, pose estimation
Unsupervised Learning From Video With Deep Neural Embeddings
Authors: Chengxu Zhuang, Tianwei She, Alex Andonian, Max Sobol Mark, Daniel Yamins
Contact: chengxuz@stanford.edu
Links: Paper
Keywords: unsupervised learning, self-supervised learning, video learning, contrastive learning, deep neural networks, action recognition, object recognition, two-pathway models
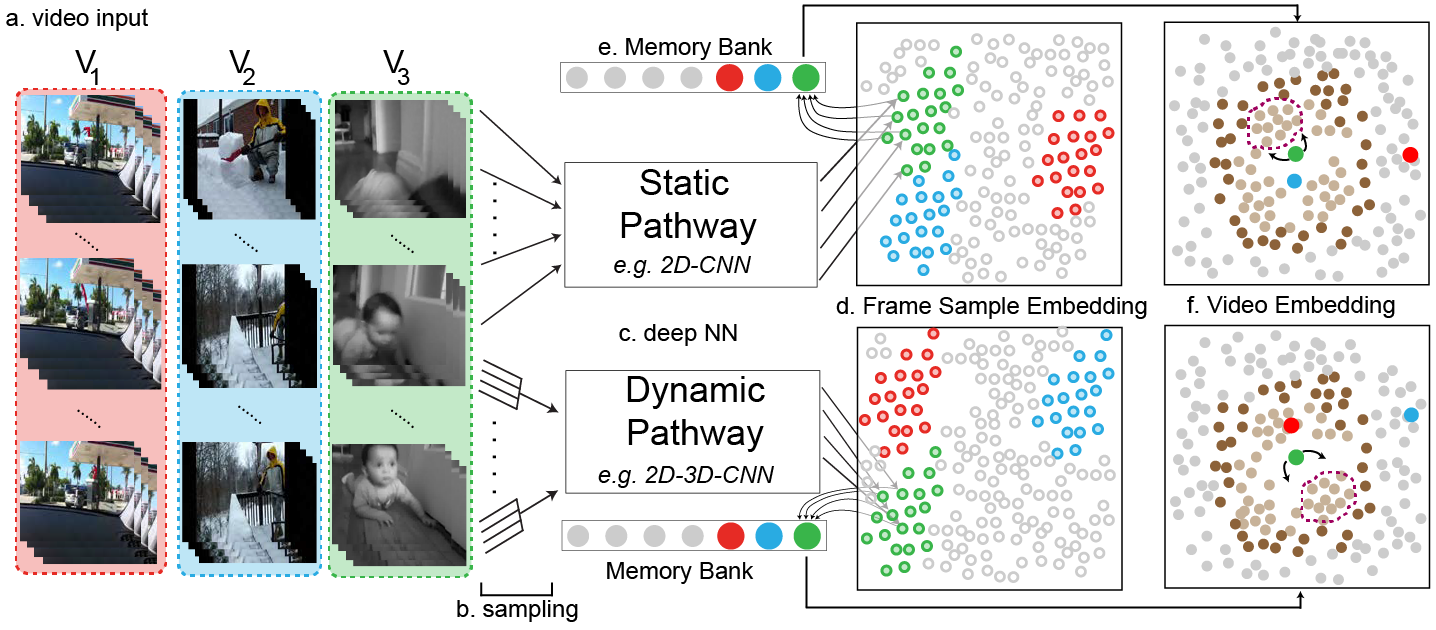
We look forward to seeing you at CVPR!