In recent years, language models (LMs) have become more prominent in natural language processing (NLP) research and are also becoming increasingly impactful in practice. Scaling up LMs has been shown to improve performance across a range of NLP tasks. For instance, scaling up language models can improve perplexity across seven orders of magnitude of model sizes, and new abilities such as multi-step reasoning have been observed to arise as a result of model scale. However, one of the challenges of continued scaling is that training new, larger models requires great amounts of computational resources. Moreover, new models are often trained from scratch and do not leverage the weights from previously existing models.
In this blog post, we explore two complementary methods for improving existing language models by a large margin without using massive computational resources. First, in “Transcending Scaling Laws with 0.1% Extra Compute”, we introduce UL2R, which is a lightweight second stage of pre-training that uses a mixture-of-denoisers objective. UL2R improves performance across a range of tasks and even unlocks emergent performance on tasks that previously had close to random performance. Second, in “Scaling Instruction-Finetuned Language Models”, we explore fine-tuning a language model on a collection of datasets phrased as instructions, a process we call “Flan”. This approach not only boosts performance, but also improves the usability of the language model to user inputs without engineering of prompts. Finally, we show that Flan and UL2R can be combined as complementary techniques in a model called Flan-U-PaLM 540B, which outperforms the unadapted PaLM 540B model by 10% across a suite of challenging evaluation benchmarks.
UL2R Training
Traditionally, most language models are pre-trained on either a causal language modeling objective that enables the model to predict the next word in a sequence (e.g., GPT-3 or PaLM) or a denoising objective, where the model learns to recover the original sentence from a corrupted sequence of words, (e.g., T5). Although there are some tradeoffs in language modeling objectives in that causal LMs are better at long-form generation and LMs trained on a denoising objective are better for fine-tuning, in prior work we demonstrated that a mixture-of-denoisers objective that includes both objectives results in better performance on both scenarios.
However, pre-training a large language model on a different objective from scratch can be computationally prohibitive. Hence, we propose UL2 Repair (UL2R), an additional stage of continued pre-training with the UL2 objective that only requires a relatively small amount of compute. We apply UL2R to PaLM and call the resulting new language model U-PaLM.
In empirical evaluations, we found that scaling curves improve substantially with only a small amount of UL2 training. For instance, we show that by using UL2R on the intermediate checkpoint of PaLM 540B, we reach the performance of the final PaLM 540B checkpoint while using 2x less compute (or a difference of 4.4 million TPUv4 hours). Naturally, applying UL2R to the final PaLM 540B checkpoint also leads to substantial improvements, as described in the paper.
 |
| Compute versus model performance of PaLM 540B and U-PaLM 540B on 26 NLP benchmarks (listed in Table 8 in the paper). U-PaLM 540B continues training PaLM for a very small amount of compute but provides a substantial gain in performance. |
Another benefit that we observed from using UL2R is that on some tasks, performance is much better than models trained purely on the causal language modeling objective. For instance, there are many BIG-Bench tasks that have been described as “emergent abilities”, i.e., abilities that can only be observed in sufficiently large language models. Although the way that emergent abilities are most commonly found is by scaling up the size of the LM, we found that UL2R can actually elicit emergent abilities without increasing the scale of the LM.
For instance, in the Navigate task from BIG-Bench, which measures the model’s ability to perform state tracking, all models except U-PaLM with less than 1023 training FLOPs achieve approximately random performance. U-PaLM performance is more than 10 points above that. Another example of this is the Snarks task from BIG-Bench, which measures the model’s ability to detect sarcasm. Again, whereas all models less than 1024 training FLOPs achieve approximately random performance, U-PaLM achieves well above even for the 8B and 62B models.
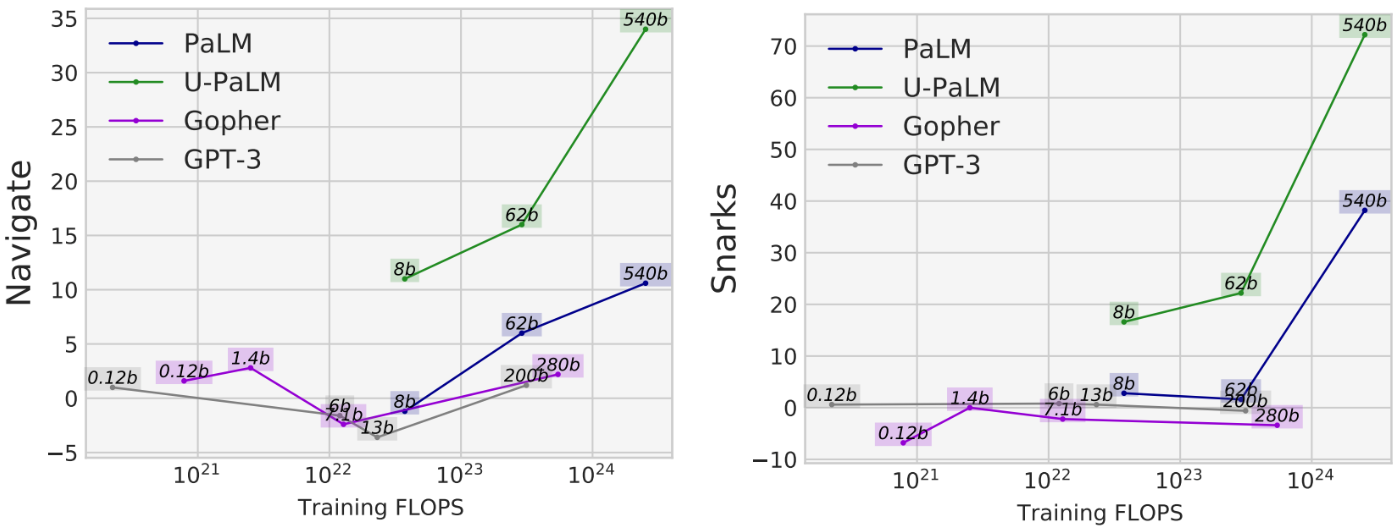 |
| For two abilities from BIG-Bench that demonstrate emergent task performance, U-PaLM achieves emergence at a smaller model size due to its use of the UL2R objective. |
Instruction Fine-Tuning
In our second paper, we explore instruction fine-tuning, which involves fine-tuning LMs on a collection of NLP datasets phrased as instructions. In prior work, we applied instruction fine-tuning to a 137B-parameter model on 62 NLP tasks, such as answering a trivia question, classifying the sentiment of a movie, or translating a sentence to Spanish.
In this work we fine-tune a 540B parameter language model on more than 1.8K tasks. Moreover, whereas previous efforts only fine-tuned a LM with few-shot exemplars (e.g., MetaICL) or zero-shot without exemplars (e.g., FLAN, T0), we fine-tune on a combination of both. We also include chain of thought fine-tuning data, which enables the model to perform multi-step reasoning. We call our improved methodology “Flan”, for fine-tuning language models. Notably, even with fine-tuning on 1.8K tasks, Flan only uses a small portion of compute compared to pre-training (e.g., for PaLM 540B, Flan only requires 0.2% of the pre-training compute).
 |
| We fine-tune language models on 1.8K tasks phrased as instructions, and evaluate them on unseen tasks, which are not included in fine-tuning. We fine-tune both with and without exemplars (i.e., zero-shot and few-shot) and with and without chain of thought, enabling generalization across a range of evaluation scenarios. |
In the paper, we instruction–fine-tune LMs of a range of sizes to investigate the joint effect of scaling both the size of the LM and the number of fine-tuning tasks. For instance, for the PaLM class of LMs, which includes models of 8B, 62B, and 540B parameters. We evaluate our models on four challenging benchmark evaluation suites (MMLU, BBH, TyDiQA, and MGSM), and find that both scaling the number of parameters and number of fine-tuning tasks improves performance on unseen tasks.
 |
| Both scaling up to a 540B parameter model and using 1.8K fine-tuning tasks improves the performance on unseen tasks. The y-axis is the normalized average over four evaluation suites (MMLU, BBH, TyDiQA, and MGSM). |
In addition to better performance, instruction fine-tuning a LM enables it to respond to user instructions at inference time, without few-shot exemplars or prompt engineering. This makes LMs more user-friendly across a range of inputs. For instance, LMs without instruction fine-tuning can sometimes repeat the input or fail to follow instructions, but instruction fine-tuning mitigates such errors.
 |
| Our instruction–fine-tuned language model, Flan-PaLM, responds better to instructions compared to the PaLM model without instruction fine-tuning. |
Putting Them Together
Finally, we show that UL2R and Flan can be combined to train the Flan-U-PaLM model. Since Flan uses new data from NLP tasks and enables zero-shot instruction following, we apply Flan as the second method after UL2R. We again evaluate on the four benchmark suites, and find that the Flan-U-PaLM model outperforms PaLM models with just UL2R (U-PaLM) or just Flan (Flan-PaLM). Further, Flan-U-PaLM achieves a new state-of-the-art on the MMLU benchmark with a score of 75.4% when combined with chain of thought and self-consistency.
 |
| Combining UL2R and Flan (Flan-U-PaLM) leads to the best performance compared to just using UL2R (U-PaLM) or just Flan (Flan-U-PaLM). Performance is the normalized average over four evaluation suites (MMLU, BBH, TyDiQA, and MGSM). |
<!–
| Average performance on four challenging evaluation suites | |
| PaLM | 49.1% |
| U-PaLM | 50.2% |
| Flan-PaLM | 58.4% |
| Flan-U-PaLM | 59.1% |
| Combining UL2R and Flan (Flan-U-PaLM) leads to the best performance compared to just using UL2R (U-PaLM) or just Flan (Flan-U-PaLM). Performance is the normalized average over four evaluation suites (MMLU, BBH, TyDiQA, and MGSM). |
–>
Overall, UL2R and Flan are two complementary methods for improving pre-trained language models. UL2R adapts the LM to a mixture-of-denoisers objective using the same data, whereas Flan leverages training data from over 1.8K NLP tasks to teach the model to follow instructions. As LMs become even larger, techniques such as UL2R and Flan that improve general performance without large amounts of compute may become increasingly attractive.
Acknowledgements
It was a privilege to collaborate on these two papers with Hyung Won Chung, Vinh Q. Tran, David R. So, Siamak Shakeri, Xavier Garcia, Huaixiu Steven Zheng, Jinfeng Rao, Aakanksha Chowdhery, Denny Zhou, Donald Metzler, Slav Petrov, Neil Houlsby, Quoc V. Le, Mostafa Dehghani, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Ed H. Chi, Jeff Dean, Jacob Devlin, and Adam Roberts.