AI is transforming many industries through advanced capabilities such as understanding and generating language, answering questions, and delivering accurate recommendations. These capabilities are fueled by ever-increasing size and complexity of AI models, which require vast amounts of computing power to train.
To meet the growing demands of AI training at scale, last year we introduced Fully Sharded Data Parallel (FSDP) in PyTorch/XLA. FSDP is a model parallelism architecture that unlocks the ability to easily and efficiently scale AI models into hundreds of billions of parameters. With PyTorch/XLA FSDP, during distributed training, each device can store a specific model shard, and all-gather the full model weights when it is time to perform the forward pass. Nested FSDP further optimizes performance by only using a given layer’s full parameters during its forward pass.
We are excited to announce that PyTorch/XLA FSDP has landed in Hugging Face Transformers. Now, Hugging Face users can train PyTorch models with up to 20 times more parameters using the same amount of computing power as before.
We built PyTorch/XLA FSDP support directly into the Hugging Face Trainer class, so that any model using Trainer can leverage FSDP. And with the addition of automatic wrapping to PyTorch/XLA FSDP, nested FSDP wrapping is both flexible and simple to apply. These new features make it easy to train a wide range of Hugging Face models at large scales. In this guide, we demonstrate training GPT-2 models with up to 128B parameters on Google Cloud TPUs. PyTorch/XLA FSDP training on TPUs is highly efficient, achieving up to 45.1% model FLOPS utilization (MFU) for GPT-2:
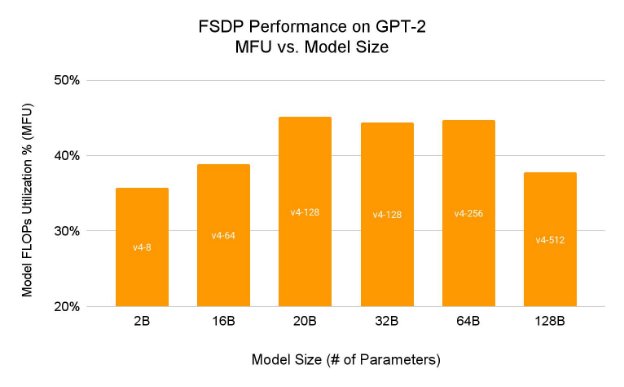
Figure 1: Model FLOPS utilization for Hugging Face GPT-2 on Google Cloud TPU v4
Configuring PyTorch/XLA FSDP in the Hugging Face Trainer
First, follow your preferred method to create your TPU(s) and install PyTorch and PyTorch/XLA. You need versions >= 2.0 for PyTorch and PyTorch/XLA.
Unset
pip3 install https://storage.googleapis.com/tpu-pytorch/wheels/tpuvm/torc h-2.0-cp38-cp38-linux_x86_64.whl --user
pip3 install https://storage.googleapis.com/tpu-pytorch/wheels/tpuvm/torc h_xla-2.0-cp38-cp38-linux_x86_64.whl
Next, clone and install the Hugging Face Transformers repo. Install all necessary dependencies (e.g., datasets, evaluate, scikit-learn, accelerate).
Unset
cd $HOME
git clone https://github.com/huggingface/transformers.git cd transformers
git checkout v4.31-release
pip3 install -e .
pip3 install datasets evaluate scikit-learn
pip3 install accelerate==0.21.0
In $HOME/transformers, create any model-specific configuration files you might need. Here is an example of a configuration file for a GPT-2 model with 2B parameters, which we later refer to as gpt2_config.json:
Unset
{
"activation_function": "gelu_new", "architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256, "embd_pdrop": 0.1, "eos_token_id": 50256, "initializer_range": 0.02, "layer_norm_epsilon": 1e-05, "model_type": "gpt2",
"n_embd": 3072,
"n_head": 24,
"n_layer": 18,
"n_positions": 1024, "resid_pdrop": 0.1, "summary_activation": null, "summary_first_dropout": 0.1, "summary_proj_to_labels": true, "summary_type": "cls_index", "summary_use_proj": true,
"task_specific_params": { "text-generation":![ref1] { "do_sample": true, "max_length": 50
}
},
"vocab_size": 50257
}
With PyTorch/XLA FSDP, it is possible to train model sizes much bigger than this on large accelerator slices. We have trained GPT-2 models as large as 128B parameters with these techniques; for expert tips on how to replicate this scale, see the appendix.
In $HOME/transformers, create your FSDP configuration file, a JSON file containing all of the configurable aspects of your XLA FSDP wrapping stored as a dictionary. Following the official Hugging Face Transformers XLA FSDP documentation, the following arguments are available to set:
xla (bool, *optional*, defaults toFalse): This is a boolean which determines whether or not you use XLA FSDP. Make sure to set this totrue.xla_fsdp_settings (dict, *optional*): This is a dictionary which stores all of the XLA FSDP wrapping parameters you want to set; note that you do not have to specify settings for parameters where you are using the default value. For a complete list of settings, see here.
For compute_dtype and buffer_dtype, enter these as strings which contain the corresponding torch data type, e.g. bfloat16.
fsdp_min_num_params (int, *optional*, defaults to0): An integer which sets the minimum number of parameters for size-based auto wrapping. Every module with at least as many parameters asfsdp_min_num_paramswill be XLA FSDP wrapped.fsdp_transformer_layer_cls_to_wrap (List[str], *optional*): A list of (case-sensitive) transformer layer class names to wrap. Note that this is mutually exclusive withfsdp_min_num_params. Example:["GPT2Block", "GPT2MLP"].xla_fsdp_grad_ckpt (bool, *optional*, defaults toFalse): This is a boolean which determines whether to use gradient checkpointing over each nested XLA FSDP wrapped layer. This setting can only be used when thexlaflag is set to true, and an auto wrapping policy is specified throughfsdp_min_num_paramsorfsdp_transformer_layer_cls_to_wrap.
Note: For transformer-based models, use fsdp_transformer_layer_cls_to_wrap instead of fsdp_min_num_params when performing automatic nested FSDP wrapping. Layers which share weights should not belong to separate FSDP wrapped units, and the input and output embedding layers in transformer-based models share weights.
For this GPT-2 example, here is what the corresponding fsdp_config.json file looks like:
Unset
{
"fsdp_transformer_layer_cls_to_wrap": [
"GPT2Block"
],
"xla": true,
"xla_fsdp_settings": {
"compute_dtype": "bfloat16",
"shard_param_on_dim_0": true,
"pin_layout_in_collective_ops": true
},
"xla_fsdp_grad_ckpt": true
}
| Now, it’s time to train your model! First, ensure that you have your PyTorch/XLA runtime set up appropriately by setting |
Unset
export PJRT_DEVICE=TPU
When running training, the key flags to pass are:
a) --fsdp "full_shard"
b) --fsdp_config fsdp_config.json
where you should replace fsdp_config.json with whatever you named your FSDP configuration file. Here is a sample command to train our example 2B GPT-2 model, where training is started by xla_spawn.py, a launcher script for distributed TPU training.
Unset
python3 -u examples/pytorch/xla_spawn.py --num_cores 4 examples/pytorch/language-modeling/run_clm.py --num_train_epochs 1
--dataset_name wikitext
--dataset_config_name wikitext-2-raw-v1 --per_device_train_batch_size 32 --per_device_eval_batch_size 32
--do_train
--do_eval
--output_dir /tmp/test-clm
--overwrite_output_dir
--config_name gpt2_config.json
--cache_dir /tmp
--tokenizer_name gpt2
--block_size 1024
--optim adafactor
--adafactor true
--save_strategy no
--logging_strategy no
--fsdp "full_shard"
--fsdp_config fsdp_config.json
Measuring Model FLOPS Utilization (MFU) for GPT-2
Model FLOPS are the floating point operations required to perform a single forward and backward pass. Model FLOPS are hardware- and implementation- independent, and only depend on the underlying model. In each step, the number of FLOPS is computed via the following formulas:
Unset
tokens_per_batch = global_batch_size * seq_len
FLOPS_per_step = 6 * tokens_per_batch * num_params
where seq_len is the sequence length and num_params is the number of parameters in the model. We note that this estimation assumes that d_model » sequence length. If this assumption is violated the self-attention FLOPs start to be significant enough and this expression.
Based on the step time and the hardware details (numbers of chips and the peak FLOPS per chip), we can compute Model FLOPS Utilization (MFU), which measures how effectively our implementation is using the underlying hardware. Achieving 100% MFU means that the hardware is being used perfectly by that model. We calculate MFU using the following formula:
Unset
model_FLOPS_utilization = FLOPS_per_step / step_time(s) / chip_count / FLOPS_per_chip
When training a GPT-2 model with 2B parameters with the XLA FSDP configuration file above on a Cloud TPU v4-8, we measure a step time of 4.191s. Using the above formula, we calculate 35.7% MFU on a v4-8. For further details on calculating MFU, refer to the PaLM paper.
The table below presents MFU for GPT-2 models with sizes between 2B and 128B, with a sequence length of 1024.
| TPU NumCores | v4-8 | v4-64 | v4-128 | v4-128 | v4-256 | v4-512 |
|---|---|---|---|---|---|---|
| # of Tokens / Batch | 131,072 | 524,288 | 524,288 | 524,288 | 1,048,576 | 1,048,576 |
| # of Parameters | 2B | 16B | 20B | 32B | 64B | 128B |
| Step Time (ms) | 4,191 | 14,592 | 7,824 | 12,970 | 25,653 | 30,460 |
| PFLOPS / Step | 1.65 | 50 | 62 | 101 | 404 | 809 |
| MFU | 35.7% | 38.8% | 45.1% | 44.4% | 44.7% | 37.7% |
Table 1: GPT-2 model FLOPS utilization calculation details
Among these configurations, MFU peaks at 45.1% for the 20B parameter model on v4-128. This result compares favorably to, for example, 41.5% MFU for a 22B Megatron-like model.
There are two actionable insights from these experiments:
First, simply increasing the number of chips without increasing the batch size generally means lower FLOPS utilization, because more time is spent on sharing the model shards. FSDP uses all-reduce communication collectives which are not asynchronous, which means that chip-to-chip communication cannot be overlapped with computation. As the number of chips increases, the number of model shards that must be communicated increases, and so we should expect the portion of the step time spent on communication to increase with the number of chips.
Second, increasing the batch size generally means better FLOPS utilization. As the number of chips increases, the memory footprint of the model decreases, which often frees up high bandwidth memory (HBM) to scale up the global batch size. With a larger global batch size, the number of tokens processed in each step increases, and thus, so does the FLOPS per step. As long as the step time does not increase proportionally, we expect a larger global batch size to improve MFU.
Therefore, to maximize the MFU, we recommend training with the largest global batch size possible that can fit in the HBM of the TPU slice, using FSDP to reduce memory required for the model parameters.
Training Very Large Models (tested to 128B parameters)
When using PyTorch/XLA, tensors must be initialized on the CPU before being moved to the XLA device. This means one may encounter host-side out-of-memory errors if the model is sufficiently large, even though the model can fit in the device HBM after sharding. To avoid this, we must defer each submodule’s initialization until it is FSDP wrapped, which ensures that submodules are sharded as soon as their values are populated, avoiding host-side limitations.
Below, we explain how to modify a local copy of the Hugging Face transformers repository to train a GPT-2 model with up to 128B parameters using this technique.
First, using the commands below, install torchdistX, which is a library containing experimental PyTorch Distributed features. This is the engine behind deferred initialization, and allows you to create tensors that don’t require immediate storage and can be materialized later. You also need to install a specific PyTorch/XLA 2.0 version that takes advantage of this package; note that you must uninstall PyTorch and PyTorch/XLA first, if you installed them earlier.
Unset
pip3 install torch==2.0 --index-url [https://download.pytorch.org/whl/test/cpu --user](https://download.pytorch.org/whl/test/cpu)
pip3 install torch_xla[torchdistx] -f https://storage.googleapis.com/tpu-pytorch/wheels/tpuvm/experimen tal/torch_xla-2.0-cp38-cp38-linux_x86_64.whl
Next, apply the following changes to your local copy of Hugging Face Transformers:
In src/transformers/trainer.py, add the following function in _wrap_model on the line immediately prior to PyTorch/XLA FSDP wrapping:
Python
from torchdistx import deferred_init
def _init_with_torchdistX(module):
def check_fn(k):
return not isinstance(k, FSDP) deferred_init.materialize_module(module, check_fn=check_fn)
The function materialize_module will initialize the model tensors if check_fn returns True. In this case, check_fn checks whether the module has been FSDP wrapped.
Within _wrap_model, modify your FSDP wrapping to accept the additional argument param_init_fn=_init_with_torchdistX:
Python
self.model = model = FSDP(
model,
auto_wrap_policy=auto_wrap_policy, auto_wrapper_callable=auto_wrapper_callable, param_init_fn=_init_with_torchdistX, **fsdp_kwargs,
)
In examples/pytorch/language-modeling/run_clm.py, add the following import statement at the beginning of the file:
Python
from torchdistx import deferred_init
Edit the model initialization so that the model is wrapped with deferred_init.deferred_init by replacing the line
Python
model = AutoModelForCausalLM.from_config(config)
with
Python
model = deferred_init.deferred_init(AutoModelForCausalLM.from_config, config)
Note that this assumes you are supplying your own model configuration file. Otherwise, you should modify your model initialization statement accordingly.
You should also comment out these two lines which immediately follow the line above:
Python
n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values()) logger.info(f"Training new model from scratch - Total size={n_params/2**20:.2f}M params")
They will cause an error if left unmodified, since the model tensors do not actually have storage when these lines are executed.
With these changes, you can now run GPT-2 models with as many as 128B parameters, provided the accelerator size is suitably large.
Next Steps & Acknowledgements
To learn more, the docs can be found here. We’d love to hear from you if you run into any issues with FSDP in PyTorch/XLA, or just want to tell us about how you are using it.
We are ecstatic about what’s ahead for PyTorch/XLA and invite the community to join us. PyTorch/XLA is developed fully in open source. So, please file issues, submit pull requests, and send RFCs to GitHub so that we can openly collaborate.
We’d like to thank Ronghang Hu and Ross Girshick at Meta AI and Lysandre Debut, Sourab Mangrulkar, Sylvain Gugger and Arthur Zucker for all the support and collaboration. We’d also like to thank Jiewen Tan, Liyang Lu, Will Cromar, Vaibhav Singh, and Chandra Devarakonda for their assistance in preparing this post.
Cheers!
The PyTorch/XLA Team at Google