A research paper released today describes ways generative AI can assist one of the most complex engineering efforts: designing semiconductors.
The work demonstrates how companies in highly specialized fields can train large language models (LLMs) on their internal data to build assistants that increase productivity.
Few pursuits are as challenging as semiconductor design. Under a microscope, a state-of-the-art chip like an NVIDIA H100 Tensor Core GPU (above) looks like a well-planned metropolis, built with tens of billions of transistors, connected on streets 10,000x thinner than a human hair.
Multiple engineering teams coordinate for as long as two years to construct one of these digital megacities.
Some groups define the chip’s overall architecture, some craft and place a variety of ultra-small circuits, and others test their work. Each job requires specialized methods, software programs and computer languages.
A Broad Vision for LLMs
“I believe over time large language models will help all the processes, across the board,” said Mark Ren, an NVIDIA Research director and lead author on the paper.
Bill Dally, NVIDIA’s chief scientist, announced the paper today in a keynote at the International Conference on Computer-Aided Design, an annual gathering of hundreds of engineers working in the field called electronic design automation, or EDA.
“This effort marks an important first step in applying LLMs to the complex work of designing semiconductors,” said Dally at the event in San Francisco. “It shows how even highly specialized fields can use their internal data to train useful generative AI models.”
ChipNeMo Surfaces
The paper details how NVIDIA engineers created for their internal use a custom LLM, called ChipNeMo, trained on the company’s internal data to generate and optimize software and assist human designers.
Long term, engineers hope to apply generative AI to each stage of chip design, potentially reaping significant gains in overall productivity, said Ren, whose career spans more than 20 years in EDA.
After surveying NVIDIA engineers for possible use cases, the research team chose three to start: a chatbot, a code generator and an analysis tool.
Initial Use Cases
The latter — a tool that automates the time-consuming tasks of maintaining updated descriptions of known bugs — has been the most well-received so far.
A prototype chatbot that responds to questions about GPU architecture and design helped many engineers quickly find technical documents in early tests.
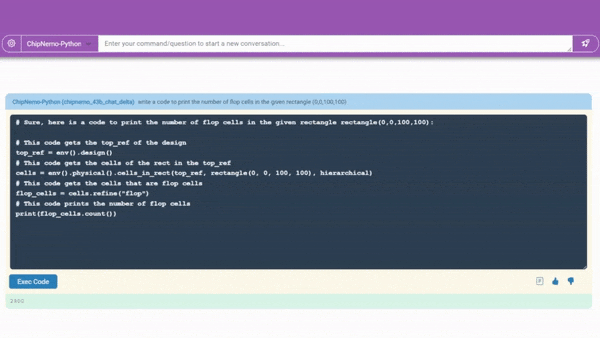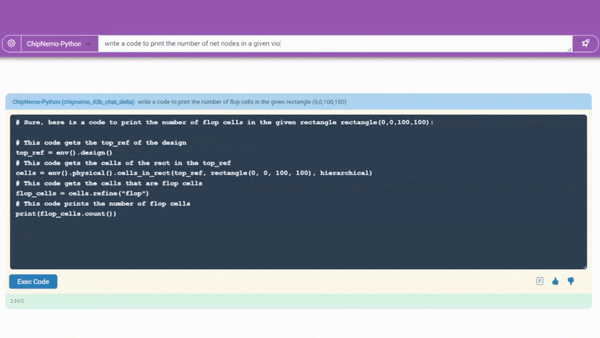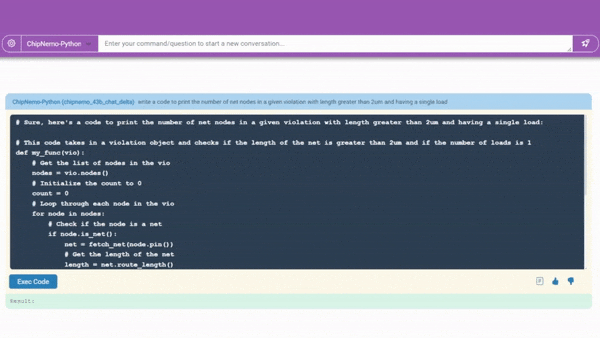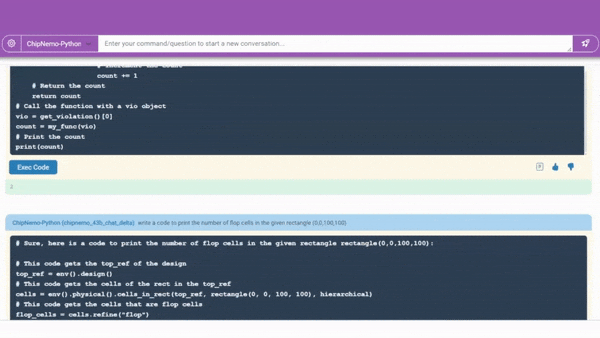
A code generator in development (demonstrated above) already creates snippets of about 10-20 lines of software in two specialized languages chip designers use. It will be integrated with existing tools, so engineers have a handy assistant for designs in progress.
Customizing AI Models With NVIDIA NeMo
The paper mainly focuses on the team’s work gathering its design data and using it to create a specialized generative AI model, a process portable to any industry.
As its starting point, the team chose a foundation model and customized it with NVIDIA NeMo, a framework for building, customizing and deploying generative AI models that’s included in the NVIDIA AI Enterprise software platform. The selected NeMo model sports 43 billion parameters, a measure of its capability to understand patterns. It was trained using more than a trillion tokens, the words and symbols in text and software.
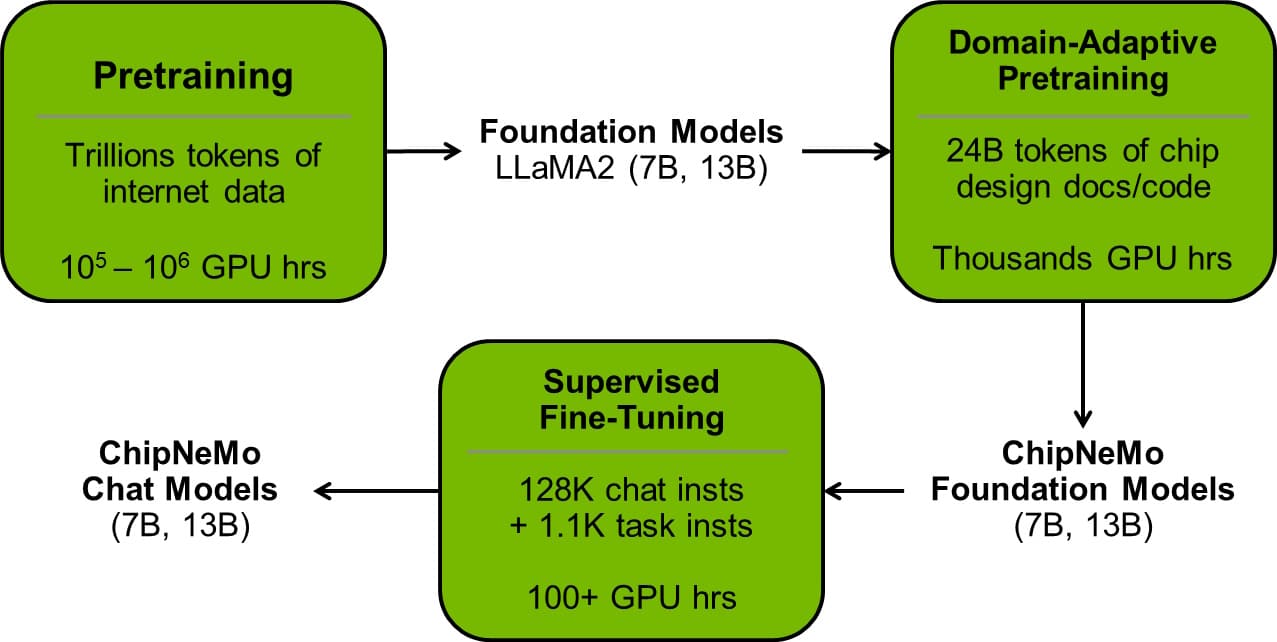
The team then refined the model in two training rounds, the first using about 24 billion tokens worth of its internal design data and the second on a mix of about 130,000 conversation and design examples.
The work is among several examples of research and proofs of concept of generative AI in the semiconductor industry, just beginning to emerge from the lab.
Sharing Lessons Learned
One of the most important lessons Ren’s team learned is the value of customizing an LLM.
On chip-design tasks, custom ChipNeMo models with as few as 13 billion parameters match or exceed performance of even much larger general-purpose LLMs like LLaMA2 with 70 billion parameters. In some use cases, ChipNeMo models were dramatically better.
Along the way, users need to exercise care in what data they collect and how they clean it for use in training, he added.
Finally, Ren advises users to stay abreast of the latest tools that can speed and simplify the work.
NVIDIA Research has hundreds of scientists and engineers worldwide focused on topics such as AI, computer graphics, computer vision, self-driving cars and robotics. Other recent projects in semiconductors include using AI to design smaller, faster circuits and to optimize placement of large blocks.
Enterprises looking to build their own custom LLMs can get started today using NeMo framework available from GitHub and NVIDIA NGC catalog.