In the dynamic world of streaming on Amazon Music, every search for a song, podcast, or playlist holds a story, a mood, or a flood of emotions waiting to be unveiled. These searches serve as a gateway to new discoveries, cherished experiences, and lasting memories. The search bar is not just about finding a song; it’s about the millions of active users starting their personal journey into the rich and diverse world that Amazon Music has to offer.
Delivering a superior customer experience to instantly find the music that users search for requires a platform that is both smart and responsive. Amazon Music uses the power of AI to accomplish this. However, optimizing the customer experience while managing cost of training and inference of AI models that power the search bar’s capabilities, like real-time spellcheck and vector search, is difficult during peak traffic times.
Amazon SageMaker provides an end-to-end set of services that allow Amazon Music to build, train, and deploy on the AWS Cloud with minimal effort. By taking care of the undifferentiated heavy lifting, SageMaker allows you to focus on working on your machine learning (ML) models, and not worry about things such as infrastructure. As part of the shared responsibility model, SageMaker makes sure that the services they provide are reliable, performant, and scalable, while you make sure the application of the ML models makes the best use of the capabilities that SageMaker provides.
In this post, we walk through the journey Amazon Music took to optimize performance and cost using SageMaker and NVIDIA Triton Inference Server and TensorRT. We dive deep into showing how that seemingly simple, yet intricate, search bar works, ensuring an unbroken journey into the universe of Amazon Music with little-to-zero frustrating typo delays and relevant real-time search results.
Amazon SageMaker and NVIDIA: Delivering fast and accurate vector search and spellcheck capabilities
Amazon Music offers a vast library of over 100 million songs and millions of podcast episodes. However, finding the right song or podcast can be challenging, especially if you don’t know the exact title, artist, or album name, or the searched query is very broad, such as “news podcasts.”
Amazon Music has taken a two-pronged approach to improve the search and retrieval process. The first step is to introduce vector search (also known as embedding-based retrieval), an ML technique that can help users find the most relevant content they’re looking for by using semantics of the content. The second step involves introducing a Transformer-based Spell Correction model in the search stack. This can be especially helpful when searching for music, because users may not always know the exact spelling of a song title or artist name. Spell correction can help users find the music they’re looking for even if they make a spelling mistake in their search query.
Introducing Transformer models in a search and retrieval pipeline (in query embedding generation needed for vector search and the generative Seq2Seq Transformer model in Spell Correction) may lead to significant increase in overall latency, affecting customer experience negatively. Therefore, it became a top priority for us to optimize the real-time inference latency for vector search and spell correction models.
Amazon Music and NVIDIA have come together to bring the best possible customer experience to the search bar, using SageMaker to implement both fast and accurate spellcheck capabilities and real-time semantic search suggestions using vector search-based techniques. The solution includes using SageMaker hosting powered by G5 instances that uses NVIDIA A10G Tensor Core GPUs, SageMaker-supported NVIDIA Triton Inference Server Container, and the NVIDIA TensorRT model format. By reducing the inference latency of the spellcheck model to 25 milliseconds at peak traffic, and reducing search query embedding generation latency by 63% on average and cost by 73% compared to CPU based inference, Amazon Music has elevated the search bar’s performance.
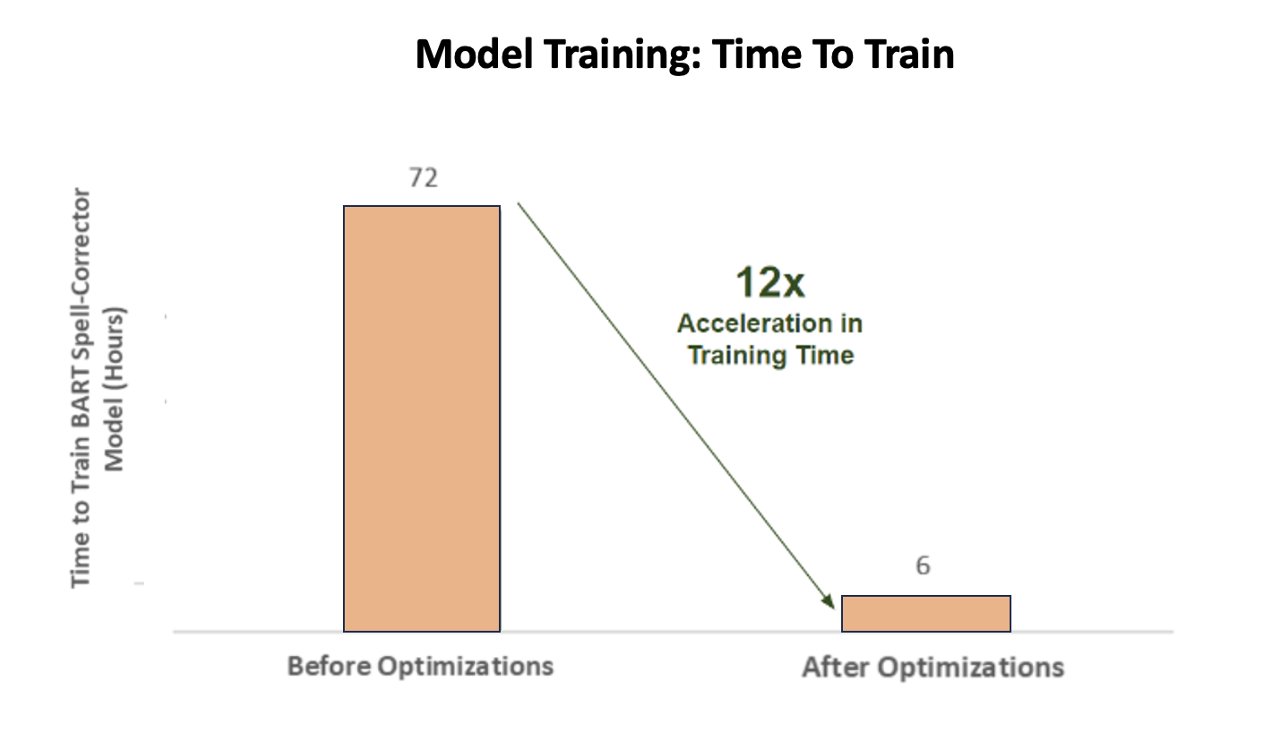
Additionally, when training the AI model to deliver accurate results, Amazon Music achieved a whopping 12 fold acceleration in training time for their BART sequence-to-sequence spell corrector transformer model, saving them both time and money, by optimizing their GPU utilization.
Amazon Music partnered with NVIDIA to prioritize the customer search experience and craft a search bar with well-optimized spellcheck and vector search functionalities. In the following sections, we share more about how these optimizations were orchestrated.
Optimizing training with NVIDIA Tensor Core GPUs
Gaining access to an NVIDIA Tensor Core GPU for large language model training is not enough to capture its true potential. There are key optimization steps that must happen during training in order to fully maximize the GPU’s utilization. However, an underutilized GPU will undoubtedly lead to inefficient use of resources, prolonged training durations, and increased operational costs.
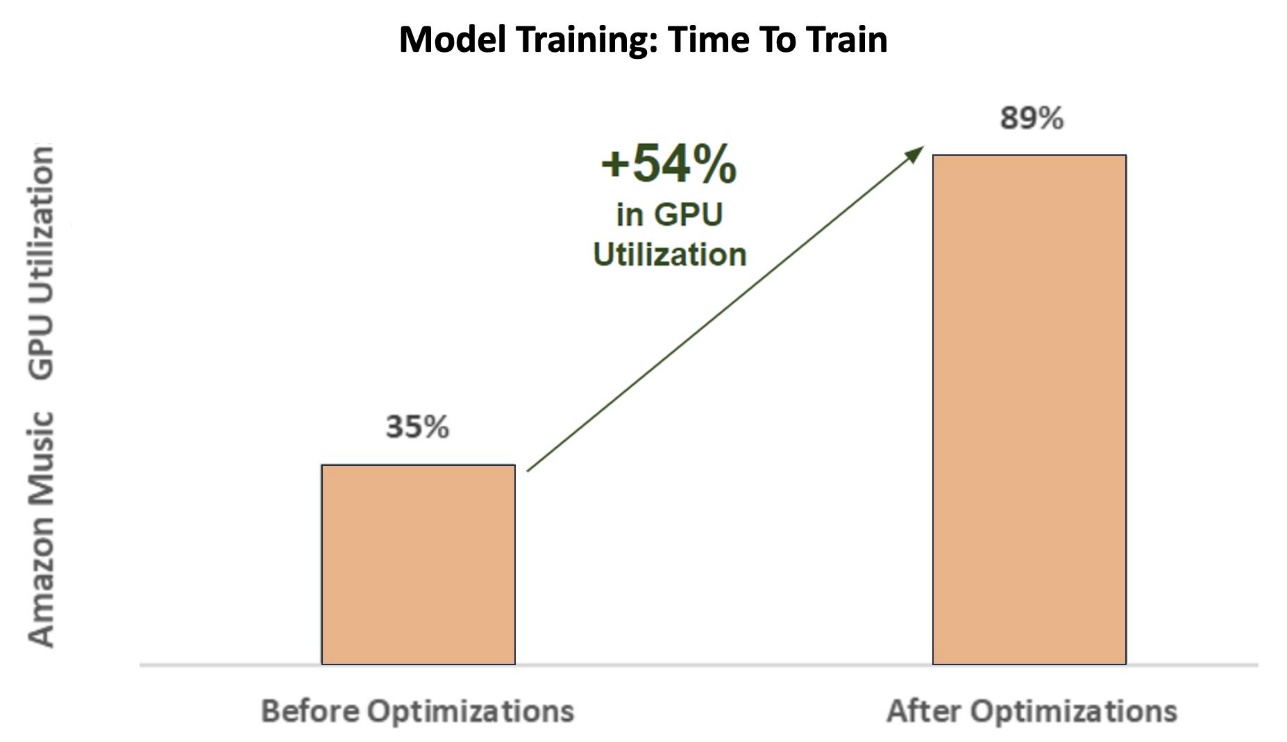
During the initial phases of training the spell corrector BART (bart-base) transformer model on a SageMaker ml.p3.24xlarge instance (8 NVIDIA V100 Tensor Core GPUs), Amazon Music’s GPU utilization was around 35%. To maximize the benefits of NVIDIA GPU-accelerated training, AWS and NVIDIA solution architects supported Amazon Music in identifying areas for optimizations, particularly around the batch size and precision parameters. These two crucial parameters influence the efficiency, speed, and accuracy of training deep learning models.
The resulting optimizations yielded a new and improved V100 GPU utilization, steady at around 89%, drastically reducing Amazon Music’s training time from 3 days to 5–6 hours. By switching the batch size from 32 to 256 and using optimization techniques like running automatic mixed precision training instead of only using FP32 precision, Amazon Music was able to save both time and money.
The following chart illustrates the 54% percentage point increase in GPU utilization after optimizations.
The following figure illustrates the acceleration in training time.
This increase in batch size enabled the NVIDIA GPU to process significantly more data concurrently across multiple Tensor Cores, resulting in accelerated training time. However, it’s important to maintain a delicate balance with memory, because larger batch sizes demand more memory. Both increasing batch size and employing mixed precision can be critical in unlocking the power of NVIDIA Tensor Core GPUs.
After the model was trained to convergence, it was time to optimize for inference deployment on Amazon Music’s search bar.
Spell Correction: BART model inferencing
With the help of SageMaker G5 instances and NVIDIA Triton Inference Server (an open source inference serving software), as well as NVIDIA TensorRT, an SDK for high-performance deep learning inference that includes an inference optimizer and runtime, Amazon Music limits their spellcheck BART (bart-base) model server inference latency to just 25 milliseconds at peak traffic. This includes overheads like load balancing, preprocessing, model inferencing, and postprocessing times.
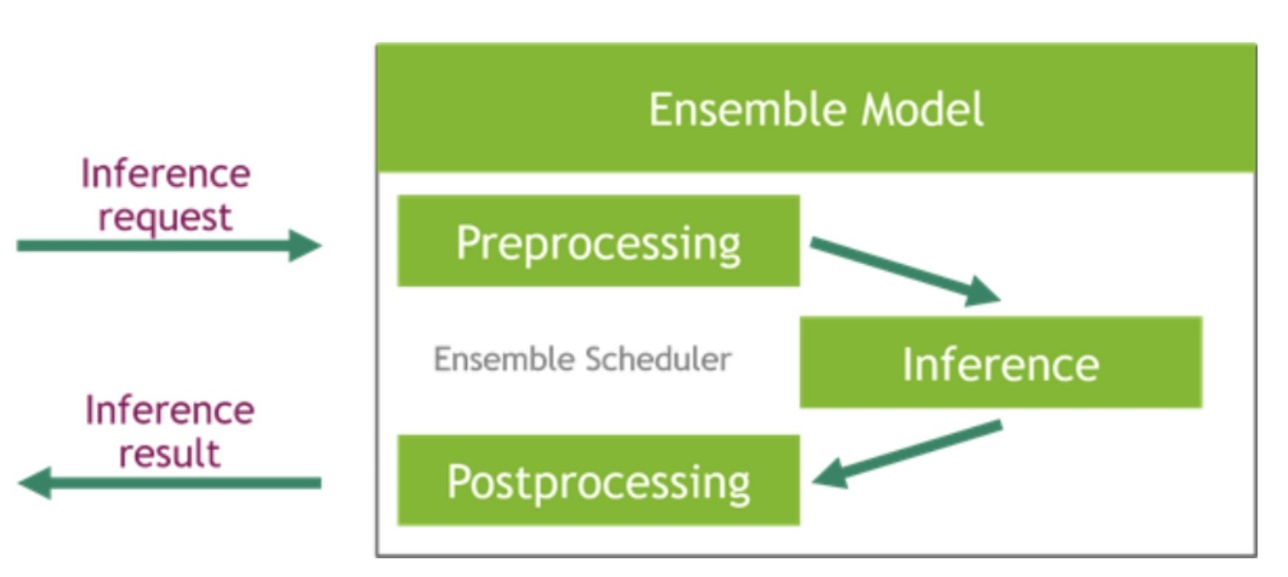
NVIDIA Triton Inference Server provides two different kind backends: one for hosting models on GPU, and a Python backend where you can bring your own custom code to be used in preprocessing and postprocessing steps. The following figure illustrates the model ensemble scheme.
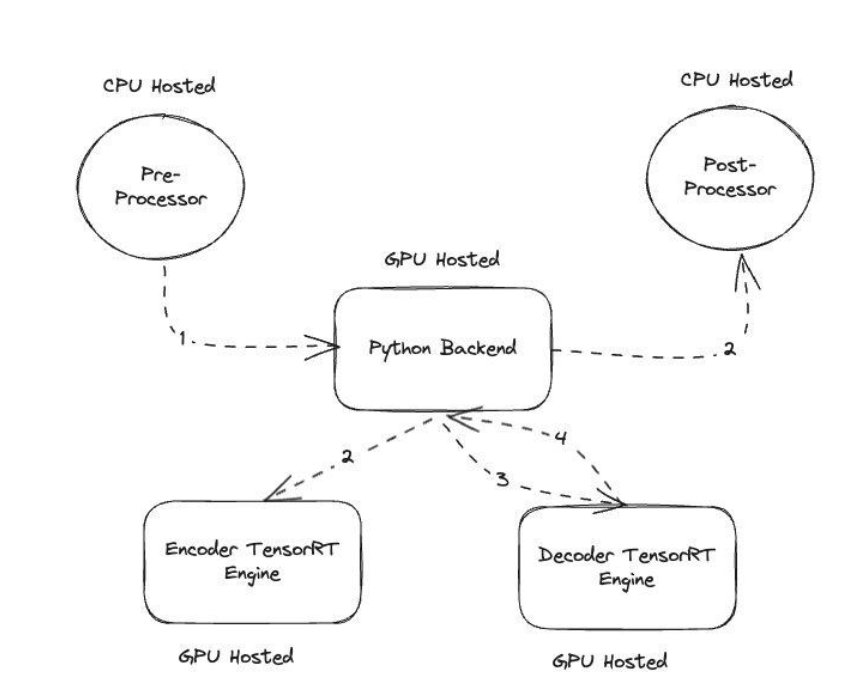
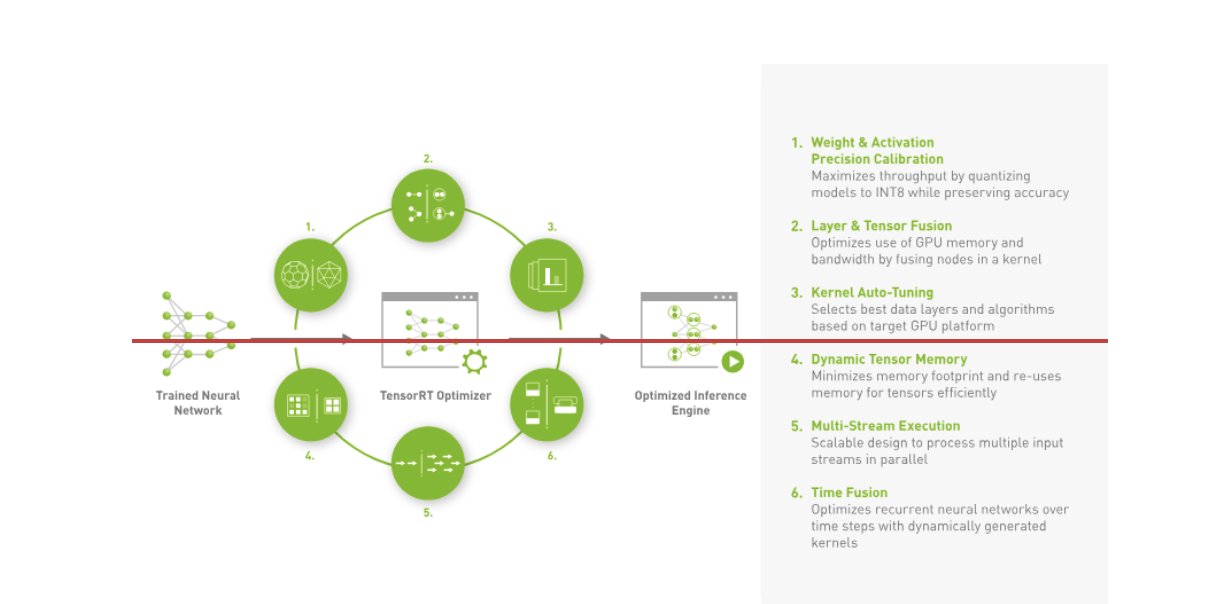
Amazon Music built its BART inference pipeline by running both preprocessing (text tokenization) and postprocessing (tokens to text) steps on CPUs, whereas the model execution step runs on NVIDIA A10G Tensor Core GPUs. A Python backend sits in the middle of the preprocessing and postprocessing steps, and is responsible for communicating with the TensorRT-converted BART models as well as the encoder/decoder networks. TensorRT boosts inference performance with precision calibration, layer and tensor fusion, kernel auto-tuning, dynamic tensor memory, multi-stream execution, and time fusion.
The following figure illustrates the high-level design of the key modules that make up the spell corrector BART model inferencing pipeline.
Vector search: Query embedding generation sentence BERT model inferencing
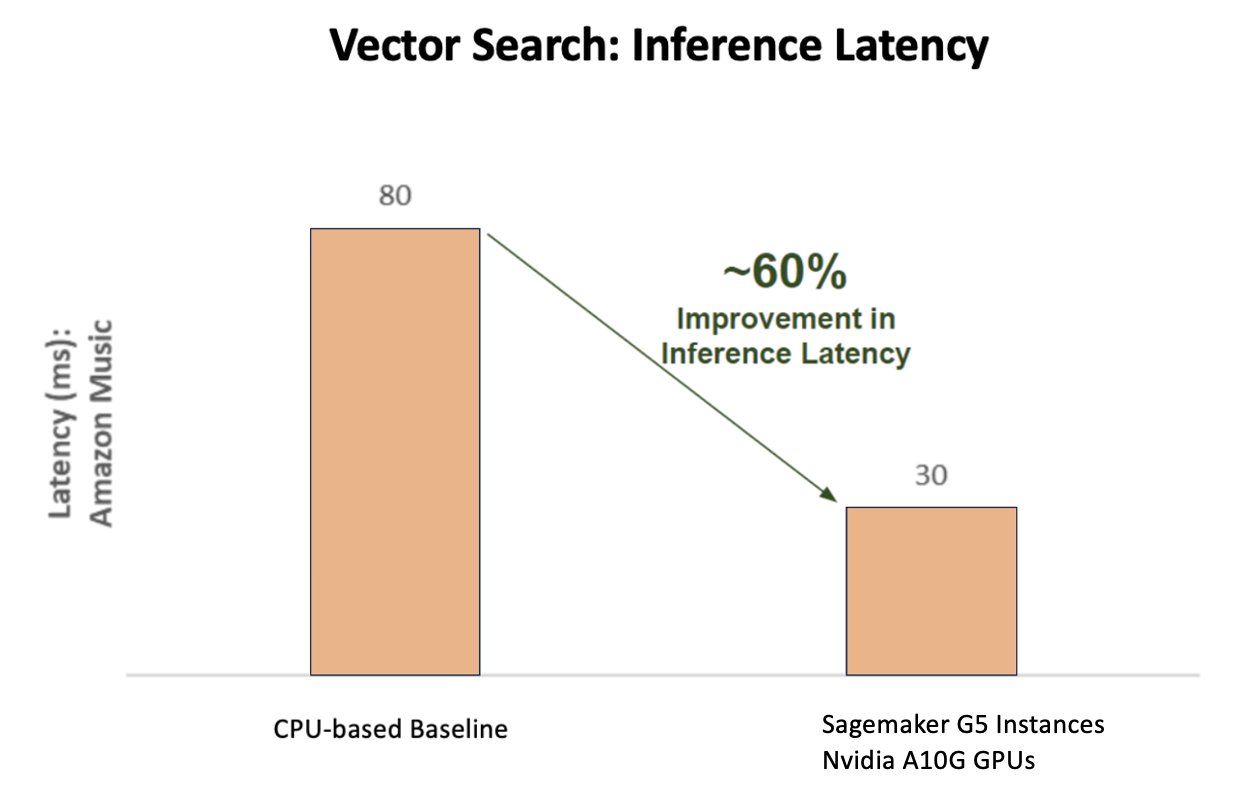
The following chart illustrates the 60% improvement in latency (serving p90 800–900 TPS) when using the NVIDIA AI Inference Platform compared to a CPU-based baseline.
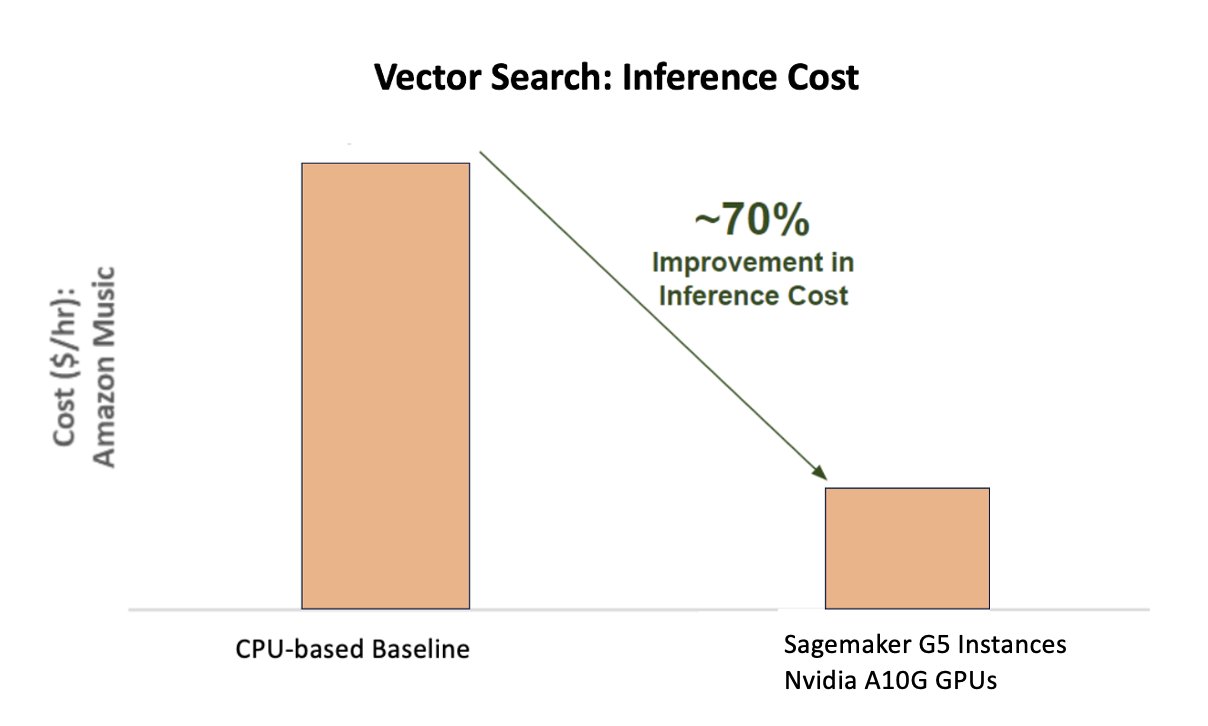
The following chart shows a 70% improvement in cost when using the NVIDIA AI Inference Platform compared to a CPU-based baseline.
The following figure illustrates an SDK for high-performance deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for inference applications.
To achieve these results, Amazon Music experimented with several different Triton deployment parameters using Triton Model Analyzer, a tool that helps find the best NVIDIA Triton model configuration to deploy efficient inference. To optimize model inference, Triton offers features like dynamic batching and concurrent model execution, and has framework support for other flexibility capabilities. The dynamic batching gathers inference requests, seamlessly grouping them together into cohorts in order to maximize throughput, all while ensuring real-time responses for Amazon Music users. The concurrent model execution capability further enhances inference performance by hosting multiple copies of the model on the same GPU. Finally, by utilizing Triton Model Analyzer, Amazon Music was able to carefully fine-tune the dynamic batching and model concurrency inference hosting parameters to find optimal settings that maximize inference performance using simulated traffic.
Conclusion
Optimizing configurations with Triton Inference Server and TensorRT on SageMaker allowed Amazon Music to achieve outstanding results for both training and inference pipelines. The SageMaker platform is the end-to-end open platform for production AI, providing quick time to value and the versatility to support all major AI use cases across both hardware and software. By optimizing V100 GPU utilization for training and switching from CPUs to G5 instances using NVIDIA A10G Tensor Core GPUs, as well as by using optimized NVIDIA software like Triton Inference Server and TensorRT, companies like Amazon Music can save time and money while boosting performance in both training and inference, directly translating to a better customer experience and lower operating costs.
SageMaker handles the undifferentiated heavy lifting for ML training and hosting, allowing Amazon Music to deliver reliable, scalable ML operations across both hardware and software.
We encourage you to check that your workloads are optimized using SageMaker by always evaluating your hardware and software choices to see if there are ways you can achieve better performance with decreased costs.
To learn more about NVIDIA AI in AWS, refer to the following:
- How Amazon Search achieves low-latency, high-throughput T5 inference with NVIDIA Triton on AWS
- Deploy fast and scalable AI with NVIDIA Triton Inference Server in Amazon SageMaker
- Achieve hyper-scale performance for model serving using NVIDIA Triton Inference Server on Amazon SageMaker
- NVIDIA H100 Tensor Core GPUs Now Available on AWS Cloud
About the authors
 Siddharth Sharma is a Machine Learning Tech Lead at Science & Modeling team at Amazon Music. He specializes in Search, Retrieval, Ranking and NLP related modeling problems. Siddharth has a rich back-ground working on large scale machine learning problems that are latency sensitive e.g. Ads Targeting, Multi Modal Retrieval, Search Query Understanding etc. Prior to working at Amazon Music, Siddharth was working at companies like Meta, Walmart Labs, Rakuten on E-Commerce centric ML Problems. Siddharth spent early part of his career working with bay area ad-tech startups.
Siddharth Sharma is a Machine Learning Tech Lead at Science & Modeling team at Amazon Music. He specializes in Search, Retrieval, Ranking and NLP related modeling problems. Siddharth has a rich back-ground working on large scale machine learning problems that are latency sensitive e.g. Ads Targeting, Multi Modal Retrieval, Search Query Understanding etc. Prior to working at Amazon Music, Siddharth was working at companies like Meta, Walmart Labs, Rakuten on E-Commerce centric ML Problems. Siddharth spent early part of his career working with bay area ad-tech startups.
 Tarun Sharma is a Software Development Manager leading Amazon Music Search Relevance. His team of scientists and ML engineers is responsible for providing contextually relevant and personalized search results to Amazon Music customers.
Tarun Sharma is a Software Development Manager leading Amazon Music Search Relevance. His team of scientists and ML engineers is responsible for providing contextually relevant and personalized search results to Amazon Music customers.
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on LinkedIn.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on LinkedIn.
 Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
 Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
 Tugrul Konuk is a Senior Solution Architect at NVIDIA, specializing at large-scale training, multimodal deep learning, and high-performance scientific computing. Prior to NVIDIA, he worked at the energy industry, focusing on developing algorithms for computational imaging. As part of his PhD, he worked on physics-based deep learning for numerical simulations at scale. In his leisure time, he enjoys reading, playing the guitar and the piano.
Tugrul Konuk is a Senior Solution Architect at NVIDIA, specializing at large-scale training, multimodal deep learning, and high-performance scientific computing. Prior to NVIDIA, he worked at the energy industry, focusing on developing algorithms for computational imaging. As part of his PhD, he worked on physics-based deep learning for numerical simulations at scale. In his leisure time, he enjoys reading, playing the guitar and the piano.
 Rohil Bhargava is a Product Marketing Manager at NVIDIA, focused on deploying NVIDIA application frameworks and SDKs on specific CSP platforms.
Rohil Bhargava is a Product Marketing Manager at NVIDIA, focused on deploying NVIDIA application frameworks and SDKs on specific CSP platforms.
 Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon’s AI MLOps, DevOps, Scientists and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing Generative AI Foundation models spanning from data curation, GPU training, model inference and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon’s AI MLOps, DevOps, Scientists and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing Generative AI Foundation models spanning from data curation, GPU training, model inference and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.