
This post is authored by Jae-Won Chung, a PhD student at the University of Michigan and the lead of the ML.ENERGY Initiative.
Deep learning consumes quite a bit of energy. For instance, training a single 200B LLM on AWS p4d instances consumed around 11.9 GWh (source: CIDR 2024 keynote), which is an amount that can single-handedly power more than a thousand average US households for a year.
Zeus is an open-source toolbox for measuring and optimizing the energy consumption of deep learning workloads. Our goal is to make energy optimization based on accurate measurements as easy as possible for diverse deep learning workloads and setups by offering composable tools with minimal assumptions.
Zeus largely provides two types of tools:
- Programmatic and command line GPU energy measurement tools
- Several energy optimization tools that find the best ML and/or GPU configurations
Zeus can benefit those who would like to
- measure and optimize their electricity cost
- reduce heat dissipation from their GPUs (by lowering power draw)
- report energy usage from research and development
- reduce carbon footprint from electricity usage
Part 1: Measuring Energy
Just like performance optimization, accurate measurement is the basis of effective energy optimization. Popular proxies for estimating power consumption like the maximum power draw of the hardware can sometimes be vastly off compared to actual measurement.
To make energy measurement as easy and transparent as possible, the core utility Zeus offers is the ZeusMonitor class. Let’s take a look at the actual snippet:
from zeus.monitor import ZeusMonitor
# All four GPUs are measured simultaneously.
monitor = ZeusMonitor(gpu_indices=[0,1,2,3])
# Measure total time and energy within the window.
monitor.begin_window("training")
for e in range(100):
# Measurement windows can arbitrarily be overlapped.
monitor.begin_window("epoch")
for x, y in train_dataloader:
y_hat = model(x)
loss = criterion(y, y_hat)
loss.backward()
optim.step()
measurement = monitor.end_window("epoch")
print(f"Epoch {e}: {measurement.time} s, {measurement.total_energy} J")
measurement = monitor.end_window("training")
print(f"Entire training: {measurement.time} s, {measurement.total_energy} J")
<script src=”https://gist.github.com/jaywonchung/f580b782ff0513374c6fa507d5e072a8.js”></script>
What you see above is a typical PyTorch training loop which uses four GPUs for data parallel training. Inside, we created an instance of ZeusMonitor and passed in a list of GPU indices to monitor. Then, using the monitor, we can measure the time and energy consumption of arbitrary execution windows within the training script by pairing calls to begin_window and end_window. Multiple windows can overlap and nest in arbitrary ways without affecting the measurement of each, as long as their names are different.
ZeusMonitor adds very little overhead – typically single digit milliseconds – around the window. This allows ZeusMonitor to be used in various applications. For instance:
- The ML.ENERGY Leaderboard: The first open-source benchmark on how much energy LLM text generation consumes.
- The ML.ENERGY Colosseum: An online service that lets users compare LLM responses side-by-side based on response quality and energy consumption.
See our blog post for a deeper technical dive into accurate GPU energy measurement.
Part 2: Optimizing Energy
Let me introduce you to two of the energy optimizers provided by Zeus.
GlobalPowerLimitOptimizer
GPUs allow users to configure its maximum power draw, called power limit. Typically, as you lower the GPU’s power limit from the default maximum, computation may get slightly slower, but you’ll save disproportionately more energy. The GlobalPowerLimitOptimizer in Zeus automatically finds the optimal GPU power limit globally across all GPUs.
from zeus.monitor import ZeusMonitor
from zeus.optimizer.power_limit import GlobalPowerLimitOptimizer
# The optimizer measures time and energy through the ZeusMonitor.
monitor = ZeusMonitor(gpu_indices=[0,1,2,3])
plo = GlobalPowerLimitOptimizer(monitor)
for e in range(100):
plo.on_epoch_begin()
for x, y in train_dataloader:
plo.on_step_begin()
y_hat = model(x)
loss = criterion(y, y_hat)
loss.backward()
optim.step()
plo.on_step_end()
plo.on_epoch_end()
<script src=”https://gist.github.com/jaywonchung/1922ddd56b15f8764f2bdacc4a441109.js”></script>
In our familiar PyTorch training loop, we have instantiated GlobalPowerLimitOptimizer and passed it an instance of the ZeusMonitor, through which the optimizer sees the GPUs. Then, we just need to let the optimizer know about training progress (step and epoch boundaries), and the optimizer will transparently do all the necessary profiling and converge to the optimal power limit.
If you’re using the HuggingFace Trainer or SFTTrainer, integration is even easier:
from zeus.monitor import ZeusMonitor
from zeus.optimizer.power_limit import HFGlobalPowerLimitOptimizer
# ZeusMonitor actually auto-detects CUDA_VISIBLE_DEVICES.
monitor = ZeusMonitor()
pl_optimizer = HFGlobalPowerLimitOptimizer(monitor)
# Pass in the optimizer as a Trainer callback. Also works for SFTTrainer.
trainer = Trainer(
model=model,
train_dataset=train_dataset,
...,
callbacks=[pl_optimizer],
)
<script src=”https://gist.github.com/jaywonchung/69aa379dd9633a6a486cede1887cec2c.js”></script>
The HFGlobalPowerLimitOptimizer wraps GlobalPowerLimitOptimizer so that it automatically detects step and epoch boundaries. We have example integrations here, including running Gemma 7B supervised fine-tuning with QLoRA.
Now, we know how to integrate the optimizer, but what is the optimal power limit? We know different users can have different preferences regarding trading off time and energy, so we allow users to specify an OptimumSelector (basically the Strategy Pattern) to express their needs.
# Built-in strategies for selecting the optimal power limit.
from zeus.optimizer.power_limit import (
GlobalPowerLimitOptimizer,
Time,
Energy,
MaxSlowdownConstraint,
)
# Minimize energy while tolerating at most 10% slowdown.
plo = GlobalPowerLimitOptimizer(
monitor,
MaxSlowdownConstraint(factor=1.1),
)
<script src=”https://gist.github.com/jaywonchung/1077b14bc7440b849be1f8320d4bf791.js”></script>
Some of the built-in strategies include “Minimize time” (Time, this might still reduce the power limit from the default since some workloads exhibit almost no slowdown even on lower power limits), “Minimize energy” (Energy), “Somewhere in between” (ZeusCost), and “Minimize energy given maximum slowdown” (MaxSlowdownConstraint). Users can also create their own optimum selectors as needed.
PipelineFrequencyOptimizer
The pipeline frequency optimizer, based on our research paper Perseus, is our latest work on energy optimization for large model training, like GPT-3. Perseus can reduce the energy consumption of large model training with no or negligible training throughput degradation. We’ll briefly talk about how.
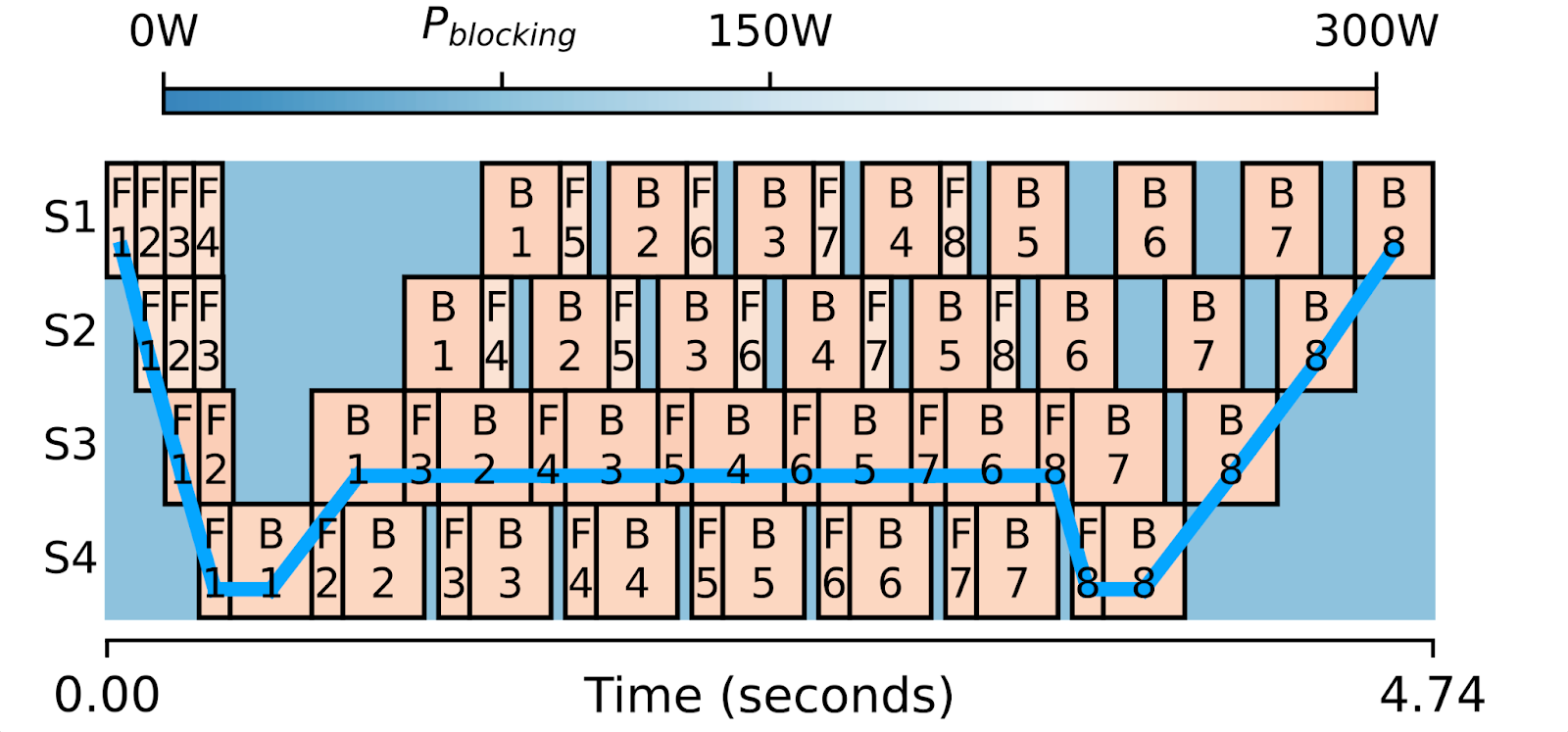
The above is a visualization of one iteration of training with four stage pipeline parallelism running with the 1F1B schedule. Each box is either a forward or a backward computation, and is colored with its power consumption.
The key observation here is that when models are partitioned into pipeline stages, it’s very difficult to slice them in perfectly equal sizes. This leads to forward/backward boxes of varying widths and therefore computation idle time between boxes. You would notice that those smaller boxes can run slightly slower than wider boxes and the overall critical path (blue line) will not change at all.
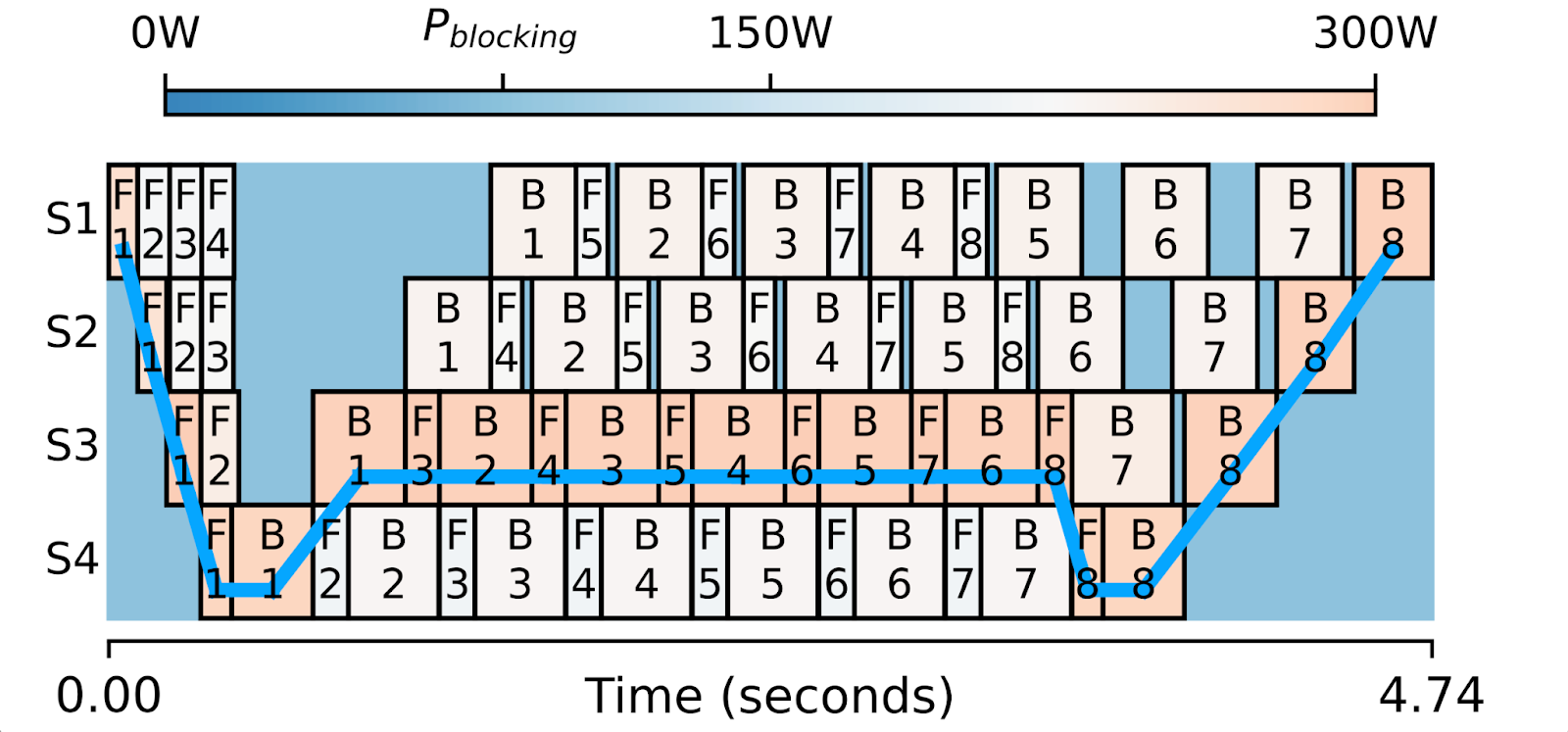
That’s what Perseus automatically does. Based on profiling, it identifies computation boxes that are not on the critical path and figures out the precise amount of slowdown for each box that minimizes energy consumption. When done correctly, computations we slowed down will consume less power & energy, but the overall iteration time of the pipeline does not change.
See our guide to get started with Perseus!
Final Words
For users who run their own on-premise compute, energy consumption and the resulting electricity bill is not something that can be easily overlooked. On a larger scale, energy consumption is not just about electricity bills, but also about data center power delivery. With thousands of GPUs running in clusters, finding stable, affordable, and sustainable electricity sources to power data centers is becoming increasingly challenging. Finding ways to reduce energy disproportionately more than slowdown leads to lower average power consumption, which can help with the power delivery challenge.
With Zeus, we hope to take the first step towards deep learning energy measurement and optimization.
Wondering where to go from here? Here are a couple helpful links:
- Zeus homepage/documentation
- Zeus GitHub repository
- Zeus usage and integration examples
- ML.ENERGY Initiative (i.e., the people building Zeus)