Introduction
Text-to-image/video models like Midjourney, Imagen3, Stable Diffusion, and Sora can generate aesthetic, photo-realistic visuals from natural language prompts, for example, given “Several giant woolly mammoths approach, treading through a snowy meadow…”, Sora generates:
But how do we know if these models generate what we desire? For example, if the prompt is “The brown dog chases the black dog around a tree”, how can we tell if the model shows the dogs “chasing around a tree” rather than “playing in a backyard”? More generally, how should we evaluate these generative models? While humans can easily judge whether a generated image aligns with a prompt, large-scale human evaluation is costly. To address this, we introduce a new evaluation metric (VQAScore) and benchmark dataset (GenAI-Bench) [Lin et al., ECCV 2024] for automated evaluation of text-to-visual generative models. Our evaluation framework was recently employed by Google Deepmind to evaluate their Imagen3 model!

Background
While state-of-the-art text-to-visual models perform well on simple prompts, they struggle with complex prompts which involve multiple objects and require higher-order reasoning like negation. Recent models like DALL-E 3 [Betker et al., OpenAI 2023] and Stable Diffusion [Esser et al., Stability AI 2024] address this by training on higher-quality image-text pairs (often using language models such as GPT-4 to rewrite captions) or using strong language encoders like T5 [Raffel et al., JMLR 2020].
As text-to-visual models advance, evaluating them has become a challenging task. To measure similarity between two images, perceptual metrics like Learned Perceptual Image Patch Similarity (LPIPS) [Zhang et al., CVPR 2018] uses a pre-trained image encoder to embed and compare image features, with higher similarity indicating the images look alike. For measuring similarity between a text prompt and an image (image-text alignment), the common practice is to rely on OpenAI’s pre-trained CLIP model [Radford et al., OpenAI 2021]. CLIP includes both an image encoder and a text encoder, trained on millions of image-text pairs, to embed images and texts into the same feature space, where higher similarity suggests stronger image-text alignment. This approach is commonly referred to as CLIPScore [Hessel et al., EMNLP 2021].

However, CLIPScore suffers from a notorious “bag-of-words” issue. This means that when embedding texts, CLIP can ignore word order, leading to mistakes like confusing “The moon is over the cow” with “The cow is over the moon”.

Why is CLIPScore limited? Our prior work [Lin et al., ICML 2024], along with others [Yuksekgonul et al., ICLR 2023], suggests its bottleneck lies in its discriminative training approach. The structure of CLIP’s loss function causes it to maximize similarity between an image and its caption and minimize similarity between an image and a small set of unrelated captions. However, this structure allows for shortcut — CLIP often minimizes similarity to negatives by simply recognizing main objects, ignoring finer details. In contrast, we suspect that generative vision-language models trained for image-to-text generation (e.g., image captioning) are more robust because they cannot rely on shortcuts—generating the correct text sequence requires a precise understanding of word order.
VQAScore: A Strong and Simple Text-to-Visual Metric
Based on generative vision-language models trained for visual-question-answering (VQA) tasks that generate an answer from an image and a question, we propose a simple metric, VQAScore. Given an image and a text prompt, we define their alignment as the probability of the model responding “Yes” to the question, “Does this image show ‘{text}’? Please answer yes or no.” For example, given an image and the text prompt “the cow over the moon”, we would compute the following probability:
(P(“Yes” | image, “Does this figure show ‘the cow over the moon’? Please answer yes or no.”) )

Our paper [Lin et al., ECCV 2024] shows that VQAScore outperforms CLIPScore and all other evaluation metrics across benchmarks measuring correlation with human judgements on image-text alignment, including Winoground [Thrush et al., CVPR 2022], TIFA160 [Hu et al., ICCV 2023], Pick-a-pic [Kirstain et al., NeurIPS 2023]. VQAScore even outperforms metrics that use additional fine-tuning data or proprietary models like GPT-4 (Vision). These metrics can be grouped into three types:
(1) Human-feedback approaches, like ImageReward, PickScore, and Human Preference Score, fine-tune CLIP using human ratings of generated images.
(2) LLM-as-a-judge approaches, like VIEScore, use LLMs such as GPT-4 (Vision) to directly output image-text alignment scores, e.g., asking the model to output a score between 0 to 100.
(3) Divide-and-conquer approaches like TIFA, Davidsonian, and Gecko decompose text prompts into simpler question-answer pairs (often using LLMs like GPT-4) and then use VQA models to assess alignment based on answer accuracy.
Compared to these metrics, VQAScore offers several key advantages:
(1) No fine-tuning: VQAScore performs well using off-the-shelf VQA models without the need for fine-tuning on human feedback.
(2) Token probability is more precise than text generation: LLM-as-a-judge methods often assign similar and random scores (like 90) to most image-text pairs, regardless of alignment.
(3) No prompt decomposition: While divide-and-conquer approaches may seem promising, prompt decomposition is error-prone. For example, with the prompt “someone talks on the phone happily while another person sits angrily,” the state-of-the-art method Davidsonian wrongly asks irrelevant questions such as, “Is there another person?”
In addition, our paper also demonstrates VQAScore’s preliminary success in evaluating text-to-video and 3D generation. We are encouraged by recent work like Generative Verifier, which supports a similar approach for evaluating language models. Finally, DeepMind’s Imagen3 suggests that stronger models like Gemini could further enhance VQAScore, indicating that it scales well with future image-to-text models.
GenAI-Bench: A Compositional Text-to-Visual Generation Benchmark
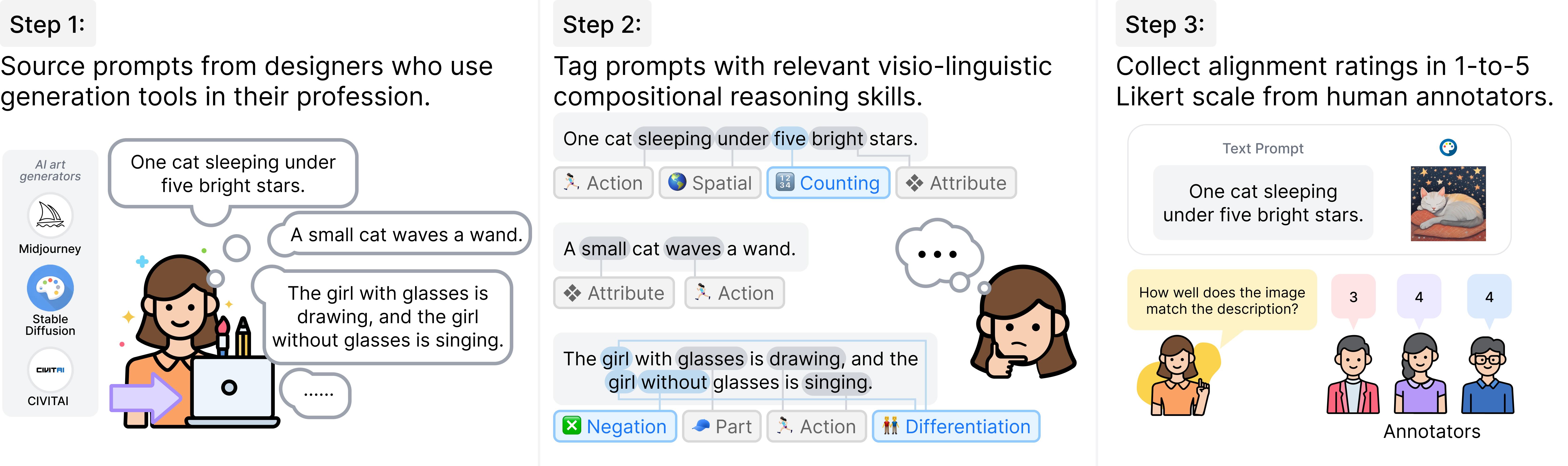
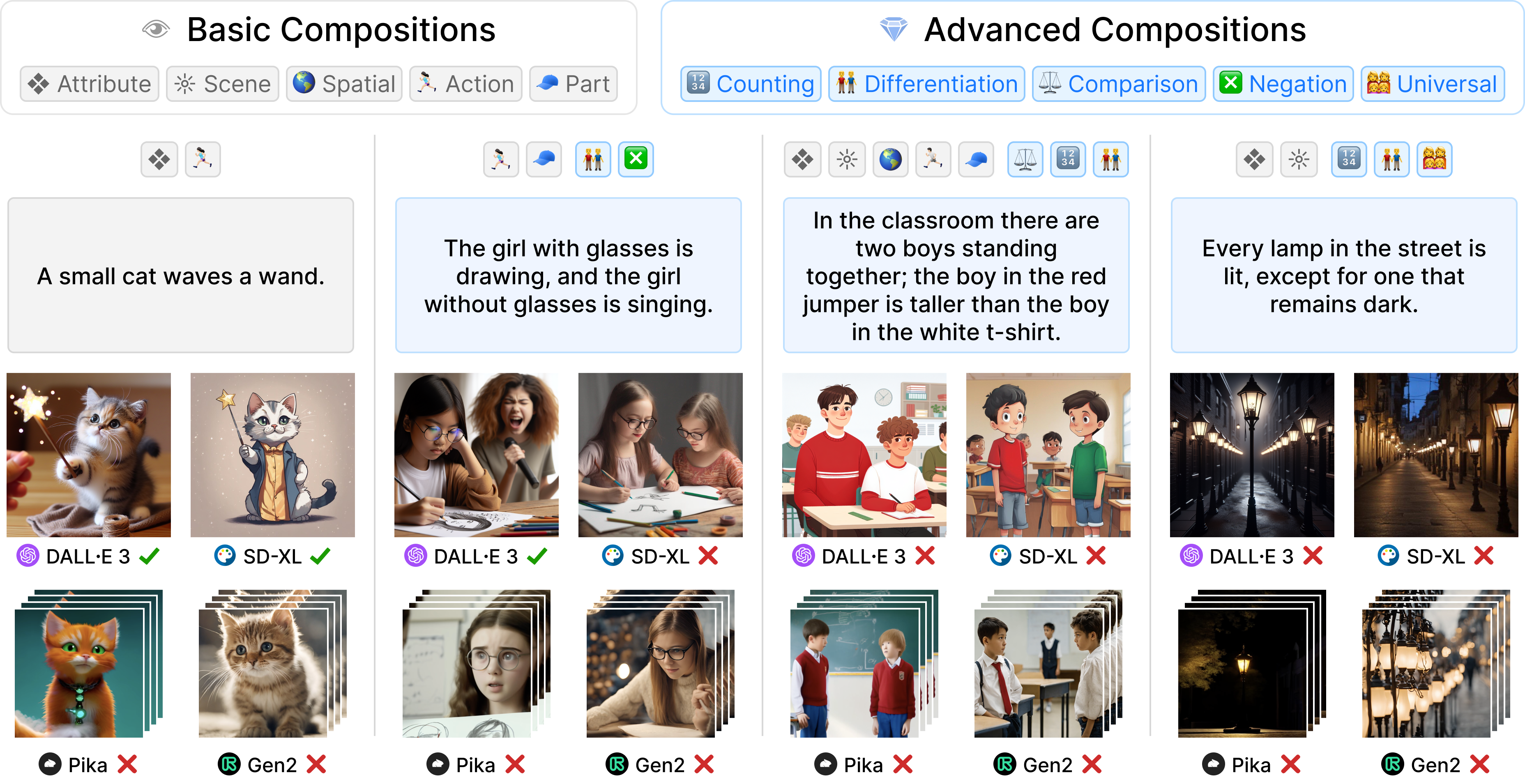
During our studies, we found that previous text-to-visual benchmarks like COCO and PartiPrompt lacked sufficiently challenging prompts. To address this, we collected 1,600 real prompts from graphic designers using tools like Midjourney. This results in GenAI-Bench [Li et al., CVPR 2024], which covers a broader range of compositional reasoning and presents a tougher challenge to text-to-visual models.

After gathering these diverse, real-world prompts, we collected 1-to-5 Likert-scale ratings on the generated images from state-of-the-art models like Midjourney and Stable Diffusion, with three annotators evaluating each image-text pair. We also discuss in the paper how these human ratings can be used to better evaluate future automated metrics.
Importantly, we found that most models still struggle with GenAI-Bench prompts, indicating significant room for improvement:
Improving Text-to-Image Generation with VQAScore
Lastly, we demonstrate how VQAScore can improve text-to-image generation in a black-box manner [Liu et al., CVPR 2024] by selecting the highest-VQAScore images from as few as three generated candidates:
Conclusion
Metrics and benchmarks play a crucial role in the evolution of science. We hope that VQAScore and GenAI-Bench provide new insights into the evaluation of text-to-visual models and offer a robust, reproducible alternative to costly human evaluations.
References:
- Lin et al., Evaluating Text-to-Visual Generation with Image-to-Text Generation. ECCV 2024.
- Li et al., GenAI-Bench: Evaluating and Improving Compositional Text-to-Visual Generation. CVPR SynData 2024 Workshop, Best Short Paper.
- Lin et al., Revisiting the Role of Language Priors in Vision-Language Models. ICML 2024.
- Liu et al., Language Models as Black-Box Optimizers for Vision-Language Models. CVPR 2024.
- Parashar et al., The Neglected Tails in Vision-Language Models. CVPR 2024.
- Hessel et al., A Reference-free Evaluation Metric for Image Captioning. EMNLP 2021.
- Heusel et al., GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. NeurIPS 2017.
- Betker et al., Improving Image Generation with Better Captions (DALL-E 3). OpenAI 2023.
- Esser et al., Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. Stability AI 2024.
- Zhang et al., The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. CVPR 2018.
- Thrush et al., Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality. CVPR 2022.
- Yuksekgonul et al., When and why vision-language models behave like bags-of-words, and what to do about it? ICLR 2023.