The vLLM engine is currently one of the top-performing ways to execute large language models (LLM). It provides the vllm serve command as an easy option to deploy a model on a single machine. While this is convenient, to serve these LLMs in production and at scale some advanced features are necessary.
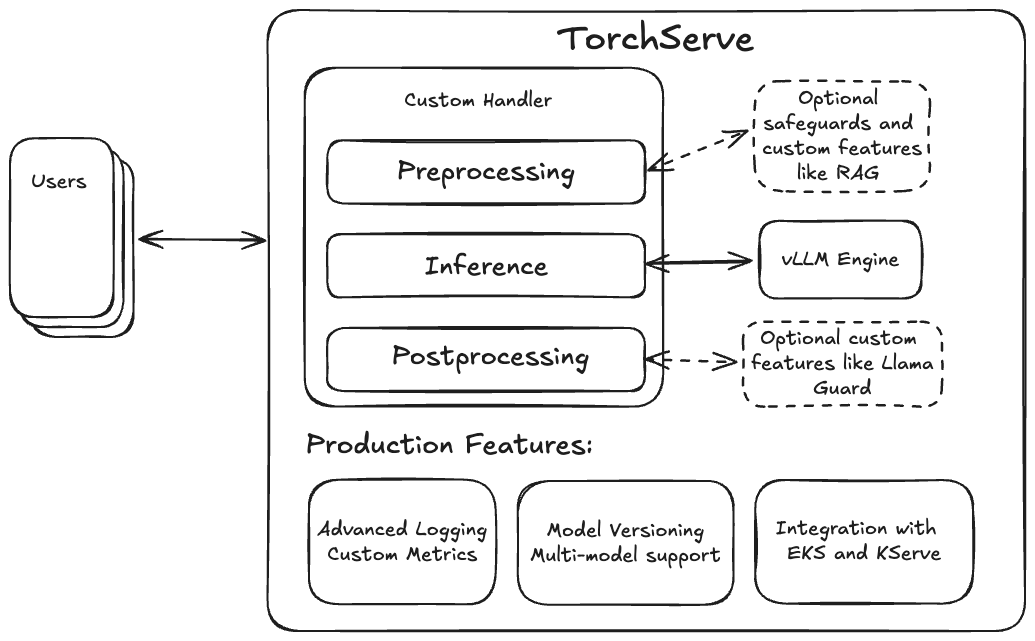
TorchServe offers these essential production features (like custom metrics and model versioning) and through its flexible custom handler design, makes it very easy to integrate features such as retrieval-augmented generation (RAG) or safeguards like Llama Guard. It is therefore natural to pair the vLLM engine with TorchServe to create a full-fledged LLM serving solution for production.
Before going into the specifics of the integration, we will demonstrate the deployment of a Llama-3.1-70B-Instruct model using TorchServe’s vLLM docker image.
Quickly getting started with Llama 3.1 on TorchServe + vLLM
To get started we need to build the new TS LLM Docker container image by checking out the TorchServe repository and execute the following command from the main folder:
docker build --pull . -f docker/Dockerfile.vllm -t ts/vllm
The container uses our new LLM launcher script ts.llm_launcher which takes a Hugging Face model URI or local folder and spins up a local TorchServe instance with the vLLM engine running in the backend. To serve a model locally, you can create an instance of the container with the following command:
#export token=<HUGGINGFACE_HUB_TOKEN>
docker run --rm -ti --shm-size 10g --gpus all -e HUGGING_FACE_HUB_TOKEN=$token -p
8080:8080 -v data:/data ts/vllm --model_id meta-llama/Meta-Llama-3.1-70B-Instruct --disable_token_auth
You can test the endpoint locally with this curl command:
curl -X POST -d '{"model":"meta-llama/Meta-Llama-3.1-70B-Instruct", "prompt":"Hello, my name is", "max_tokens": 200}' --header "Content-Type: application/json" "http://localhost:8080/predictions/model/1.0/v1/completions"
The docker stores the model weights in the local folder “data” which gets mounted as /data inside the container. To serve your custom local weights simply copy them into data and point the model_id to /data/<your weights>.
Internally, the container uses our new ts.llm_launcher script to launch TorchServe and deploy the model. The launcher simplifies the deployment of an LLM with TorchServe into a single command line and can also be used outside the container as an efficient tool for experimentation and testing. To use the launcher outside the docker, follow the TorchServe installation steps and then execute the following command to spin up a 8B Llama model:
# after installing TorchServe and vLLM run
python -m ts.llm_launcher --model_id meta-llama/Meta-Llama-3.1-8B-Instruct --disable_token_auth
If multiple GPUs are available the launcher will automatically claim all visible devices and apply tensor parallelism (see CUDA_VISIBLE_DEVICES to specify which GPUs to use).
While this is very convenient, it’s important to note that it does not encompass all the functionalities provided by TorchServe. For those looking to leverage more advanced features, a model archive needs to be created. While this process is a bit more involved than issuing a single command, it bears the advantage of custom handlers and versioning. While the former allows to implement RAG inside the preprocessing step, the latter lets you test different versions of a handler and model before deploying on a larger scale.
Before we provide the detailed steps to create and deploy a model archive, let’s dive into the details of the vLLM engine integration.
TorchServe’s vLLM Engine Integration
As a state-of-the-art serving framework, vLLM offers a plethora of advanced features, including PagedAttention, continuous batching, rapid model execution through CUDA graphs, and support for various quantization methods such as GPTQ, AWQ, INT4, INT8, and FP8. It also provides integration for important parameter-efficient adapter methods like LoRA and access to a wide range of model architectures including Llama and Mistral. vLLM is maintained by the vLLM team and a thriving open-source community.
To facilitate quick deployment, it offers a serving mode based on FastAPI to serve LLMs over HTTP. For a tighter, more flexible integration the project also provides the vllm.LLMEngine which offers interfaces to process requests on a continuous basis. We leveraged the asynchronous variant for the integration into TorchServe.
TorchServe is an easy-to-use, open-source solution for serving PyTorch models in production. As a production-tested serving solution, TorchServe offers numerous benefits and features beneficial for deploying PyTorch models at scale. By combining it with the inference performance of the vLLM engine these benefits can now also be used to deploy LLMs at scale.
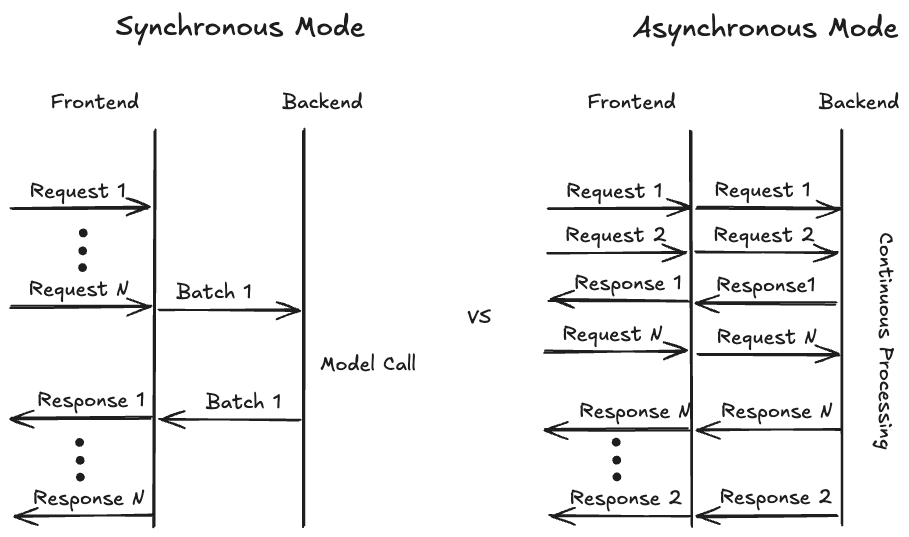
To maximize hardware utilization it is generally a good practice to batch requests from multiple users together. Historically, TorchServe only offered a synchronized mode to collect requests from various users. In this mode, TorchServe waits for a predefined amount of time (e.g., batch_delay=200ms) or until enough requests (e.g., batch_size=8) have arrived. When one of these events is triggered, the batched data gets forwarded to the backend where the model is applied to the batch, and the model output is returned to the users through the frontend. This works especially well for traditional vision models where outputs for each request usually finish at the same time.
For generative use cases, particularly text generation, the assumption that requests are ready simultaneously is no longer valid, as responses will have varying lengths. Although TorchServe supports continuous batching (the ability to add and remove requests dynamically), this mode only accommodates a static maximum batch size. With the introduction of PagedAttention, even this assumption of a maximum batch size becomes more flexible, as vLLM can combine requests of different lengths in a highly adaptable manner to optimize memory utilization.
To achieve optimal memory utilization, i.e., to fill unused gaps in memory (think Tetris), vLLM requires complete control over the decision of which requests to process at any given time. To provide this flexibility, we had to reevaluate how TorchServe handles user requests. Instead of the previous synchronous processing mode, we introduced an asynchronous mode (see diagram below) where incoming requests are directly forwarded to the backend, making them available for vLLM. The backend feeds the vllm.AsyncEngine, which can now select from all available requests. If streaming mode is enabled and the first token of a request is available, the backend will send out the result immediately and continue sending tokens until the final token is generated.
Our implementation of the VLLMHandler enables users to quickly deploy any model compatible with vLLM using a configuration file, while still offering the same level of flexibility and customizability through a custom handler. Users are free to add e.g. custom preprocessing or post-processing steps by inheriting from VLLMHandler and overriding the respective class methods.
We also support single-node, multi-GPU distributed inference, where we configure vLLM to use tensor parallel sharding of the model to either increase capacity for smaller models or enable larger models that do not fit on a single GPU, such as the 70B Llama variants. Previously, TorchServe only supported distributed inference using torchrun, where multiple backend worker processes were spun up to shard the model. vLLM manages the creation of these processes internally, so we introduced the new “custom” parallelType to TorchServe which launches a single backend worker process and provides the list of assigned GPUs. The backend process can then launch its own subprocesses if necessary.
To facilitate integration of TorchServe + vLLM into docker-based deployments, we provide a separate Dockerfile based on TorchServe’s GPU docker image, with vLLM added as a dependency. We chose to keep the two separate to avoid increasing the docker image size for non-LLM deployments.
Next, we will demonstrate the steps required to deploy a Llama 3.1 70B model using TorchServe + vLLM on a machine with four GPUs.
Step-by-Step Guide
For this step-by-step guide we assume the installation of TorchServe has finished successfully. Currently, vLLM is not a hard-dependency for TorchServe so let’s install the package using pip:
$ pip install -U vllm==0.6.1.post2
In the following steps, we will (optionally) download the model weights, explain the configuration, create a model archive, deploy and test it:
1. (Optional) Download Model Weights
This step is optional, as vLLM can also handle downloading the weights when the model server is started. However, pre-downloading the model weights and sharing the cached files between TorchServe instances can be beneficial in terms of storage usage and startup time of the model worker. If you choose to download the weights, use the huggingface-cli and execute:
# make sure you have logged into huggingface with huggingface-cli login before
# and have your access request for the Llama 3.1 model weights approved
huggingface-cli download meta-llama/Meta-Llama-3.1-70B-Instruct --exclude original/*
This will download the files under $HF_HOME, and you can alter the variable if you want to place the files elsewhere. Please ensure that you update the variable wherever you run TorchServe and make sure it has access to that folder.
2. Configure the Model
Next, we create a YAML configuration file that contains all the necessary parameters for our model deployment. The first part of the config file specifies how the frontend should launch the backend worker, which will ultimately run the model in a handler. The second part includes parameters for the backend handler, such as the model to load, followed by various parameters for vLLM itself. For more information on possible configurations for the vLLM engine, please refer to this link.
echo '
# TorchServe frontend parameters
minWorkers: 1
maxWorkers: 1 # Set the number of worker to create a single model instance
startupTimeout: 1200 # (in seconds) Give the worker time to load the model weights
deviceType: "gpu"
asyncCommunication: true # This ensures we can cummunicate asynchronously with the worker
parallelType: "custom" # This lets TS create a single backend prosses assigning 4 GPUs
parallelLevel: 4
# Handler parameters
handler:
# model_path can be a model identifier for Hugging Face hub or a local path
model_path: "meta-llama/Meta-Llama-3.1-70B-Instruct"
vllm_engine_config: # vLLM configuration which gets fed into AsyncVLLMEngine
max_num_seqs: 16
max_model_len: 512
tensor_parallel_size: 4
served_model_name:
- "meta-llama/Meta-Llama-3.1-70B-Instruct"
- "llama3"
'> model_config.yaml
3. Create the Model Folder
After creating the model configuration file (model_config.yaml), we will now create a model archive that includes the configuration and additional metadata, such as versioning information. Since the model weights are large, we will not include them inside the archive. Instead, the handler will access the weights by following the model_path specified in the model configuration. Note that in this example, we have chosen to use the “no-archive” format, which creates a model folder containing all necessary files. This allows us to easily modify the config files for experimentation without any friction. Later, we can also select the mar or tgz format to create a more easily transportable artifact.
mkdir model_store
torch-model-archiver --model-name vllm --version 1.0 --handler vllm_handler --config-file model_config.yaml --archive-format no-archive --export-path model_store/
4. Deploy the Model
The next step is to start a TorchServe instance and load the model. Please note that we have disabled token authentication for local testing purposes. It is highly recommended to implement some form of authentication when publicly deploying any model.
To start the TorchServe instance and load the model, run the following command:
torchserve --start --ncs --model-store model_store --models vllm --disable-token-auth
You can monitor the progress of the model loading through the log statements. Once the model has finished loading, you can proceed to test the deployment.
5. Test the Deployment
The vLLM integration uses an OpenAI API compatible format so we can either use a specialized tool for this purpose or curl. The JSON data we are using here includes the model identifier as well as the prompt text. Other options and their default values can be found in the vLLMEngine docs.
echo '{
"model": "llama3",
"prompt": "A robot may not injure a human being",
"stream": 0
}' | curl --header "Content-Type: application/json" --request POST --data-binary @- http://localhost:8080/predictions/vllm/1.0/v1/completions
The output of the request looks like this:
{
"id": "cmpl-cd29f1d8aa0b48aebcbff4b559a0c783",
"object": "text_completion",
"created": 1727211972,
"model": "meta-llama/Meta-Llama-3.1-70B-Instruct",
"choices": [
{
"index": 0,
"text": " or, through inaction, allow a human being to come to harm.nA",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 26,
"completion_tokens": 16
}
When streaming is False TorchServe will collect the full answer and send it in one go after the last token was created. If we flip the stream parameter we will receive piecewise data containing a single token in each message.
Conclusion
In this blog post, we explored the new, native integration of the vLLM inference engine into TorchServe. We demonstrated how to locally deploy a Llama 3.1 70B model using the ts.llm_launcher script and how to create a model archive for deployment on any TorchServe instance. Additionally, we discussed how to build and run the solution in a Docker container for deployment on Kubernetes or EKS. In future works, we plan to enable multi-node inference with vLLM and TorchServe, as well as offer a pre-built Docker image to simplify the deployment process.
We would like to express our gratitude to Mark Saroufim and the vLLM team for their invaluable support in the lead-up to this blog post.