In this blog, we present a case study on distilling a Llama 3.1 8B model into Llama 3.2 1B using torchtune’s knowledge distillation recipe. We demonstrate how knowledge distillation (KD) can be used in post-training to improve instruction-following task performance and showcase how users can leverage the recipe.
What is Knowledge Distillation?
Knowledge Distillation is a widely used compression technique that transfers knowledge from a larger (teacher) model to a smaller (student) model. Larger models have more parameters and capacity for knowledge, however, this larger capacity is also more computationally expensive to deploy. Knowledge distillation can be used to compress the knowledge of a larger model into a smaller model. The idea is that performance of smaller models can be improved by learning from larger model’s outputs.
How does Knowledge Distillation work?
Knowledge is transferred from the teacher to student model by training on a transfer set where the student is trained to imitate the token-level probability distributions of the teacher. The assumption is that the teacher model distribution is similar to the transfer dataset. The diagram below is a simplified representation of how KD works.
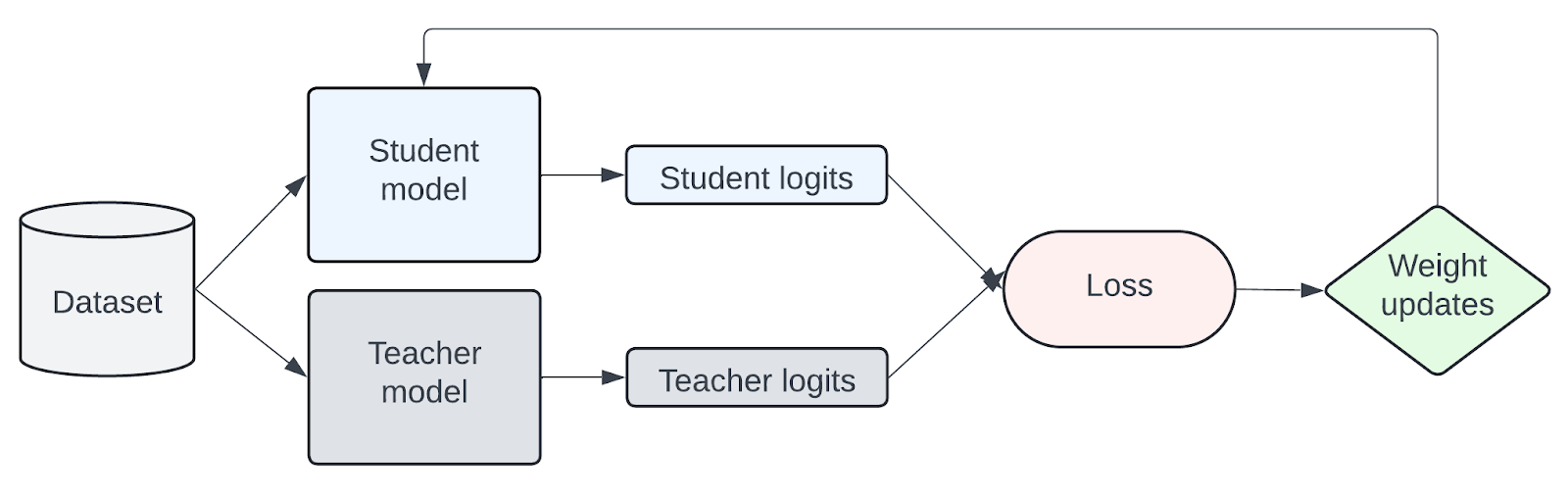
Figure 1: Simplified representation of knowledge transfer from teacher to student model
As knowledge distillation for LLMs is an active area of research, there are papers, such as MiniLLM, DistiLLM, AKL, and Generalized KD, investigating different loss approaches. In this case study, we focus on the standard cross-entropy (CE) loss with the forward Kullback-Leibler (KL) divergence loss as the baseline. Forward KL divergence aims to minimize the difference by forcing the student’s distribution to align with all of the teacher’s distributions.
Why is Knowledge Distillation useful?
The idea of knowledge distillation is that a smaller model can achieve better performance using a teacher model’s outputs as an additional signal than it could training from scratch or with supervised fine-tuning. For instance, Llama 3.2 lightweight 1B and 3B text models incorporated logits from Llama 3.1 8B and 70B to recover performance after pruning. In addition, for fine-tuning on instruction-following tasks, research in LLM distillation demonstrates that knowledge distillation methods can outperform supervised fine-tuning (SFT) alone.
| Model | Method | DollyEval | Self-Inst | S-NI |
| GPT-4 Eval | GPT-4 Eval | Rouge-L | ||
| Llama 7B | SFT | 73.0 | 69.2 | 32.4 |
| KD | 73.7 | 70.5 | 33.7 | |
| MiniLLM | 76.4 | 73.1 | 35.5 | |
| Llama 1.1B | SFT | 22.1 | – | 27.8 |
| KD | 22.2 | – | 28.1 | |
| AKL | 24.4 | – | 31.4 | |
| OpenLlama 3B | SFT | 47.3 | 41.7 | 29.3 |
| KD | 44.9 | 42.1 | 27.9 | |
| SeqKD | 48.1 | 46.0 | 29.1 | |
| DistiLLM | 59.9 | 53.3 | 37.6 |
Table 1: Comparison of knowledge distillation approaches to supervised fine-tuning
Below is a simplified example of how knowledge distillation differs from supervised fine-tuning.
| Supervised fine-tuning | Knowledge distillation |
|---|---|
|
|
KD recipe in torchtune
With torchtune, we can easily apply knowledge distillation to Llama3, as well as other LLM model families, using torchtune’s KD recipe. The objective for this recipe is to fine-tune Llama3.2-1B on the Alpaca instruction-following dataset by distilling from Llama3.1-8B. This recipe focuses on post-training and assumes the teacher and student models have already been pre-trained.
First, we have to download the model weights. To be consistent with other torchtune fine-tuning configs, we will use the instruction tuned models of Llama3.1-8B as teacher and Llama3.2-1B as student.
tune download meta-llama/Meta-Llama-3.1-8B-Instruct --output-dir /tmp/Meta-Llama-3.1-8B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
tune download meta-llama/Llama-3.2-1B-Instruct --output-dir /tmp/Llama-3.2-1B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
In order for the teacher model distribution to be similar to the Alpaca dataset, we will fine-tune the teacher model using LoRA. Based on our experiments, shown in the next section, we’ve found that KD performs better when the teacher model is already fine-tuned on the target dataset.
tune run lora_finetune_single_device --config llama3_1/8B_lora_single_device
Finally, we can run the following command to distill the fine-tuned 8B model into the 1B model on a single GPU. For this case study, we used a single A100 80GB GPU. We also have a distributed recipe for running on multiple devices.
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_device
Ablation studies
In this section, we demonstrate how changing configurations and hyperparameters can affect performance. By default, our configuration uses the LoRA fine-tuned 8B teacher model, downloaded 1B student model, learning rate of 3e-4 and KD loss ratio of 0.5. For this case study, we fine-tuned on the alpaca_cleaned_dataset and evaluated the models on truthfulqa_mc2, hellaswag and commonsense_qa tasks through the EleutherAI LM evaluation harness. Let’s take a look at the effects of:
- Using a fine-tuned teacher model
- Using a fine-tuned student model
- Hyperparameter tuning of KD loss ratio and learning rate
Using a fine-tuned teacher model
The default settings in the config uses the fine-tuned teacher model. Now, let’s take a look at the effects of not fine-tuning the teacher model first.
Taking a loss at the losses, using the baseline 8B as teacher results in a higher loss than using the fine-tuned teacher model. The KD loss also remains relatively constant, suggesting that the teacher model should have the same distributions as the transfer dataset.
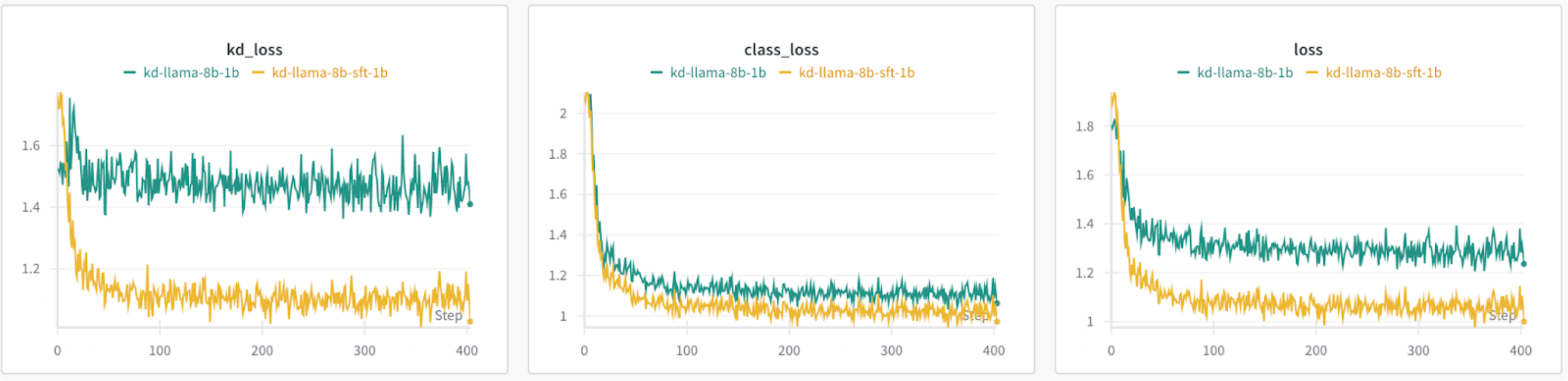
Figure 2: (left to right) KD loss from forward KL divergence, class loss from cross entropy, total loss: even combination of KD and class loss.
In our benchmarks, we can see that supervised fine-tuning of the 1B model achieves better accuracy than the baseline 1B model. By using the fine-tuned 8B teacher model, we see comparable results for truthfulqa and improvement for hellaswag and commonsense. When using the baseline 8B as a teacher, we see improvement across all metrics, but lower than the other configurations.
| Model | TruthfulQA | hellaswag | commonsense | |
| mc2 | acc | acc_norm | acc | |
| Baseline Llama 3.1 8B | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| Fine-tuned Llama 3.1 8B using LoRA | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| Baseline Llama 3.2 1B | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| Fine-tuned Llama 3.2 1B using LoRA | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| KD using baseline 8B as teacher | 0.444 | 0.4576 | 0.6123 | 0.5561 |
| KD using fine-tuned 8B as teacher | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
Table 2: Comparison between using baseline and fine-tuned 8B as teacher model
Using a fine-tuned student model
For these experiments, we look at the effects of KD when the student model is already fine-tuned. We analyze the effects using different combinations of baseline and fine-tuned 8B and 1B models.
Based on the loss graphs, using a fine-tuned teacher model results in a lower loss irrespective of whether the student model is fine-tuned or not. It’s also interesting to note that the class loss starts to increase when using a fine-tuned student model.
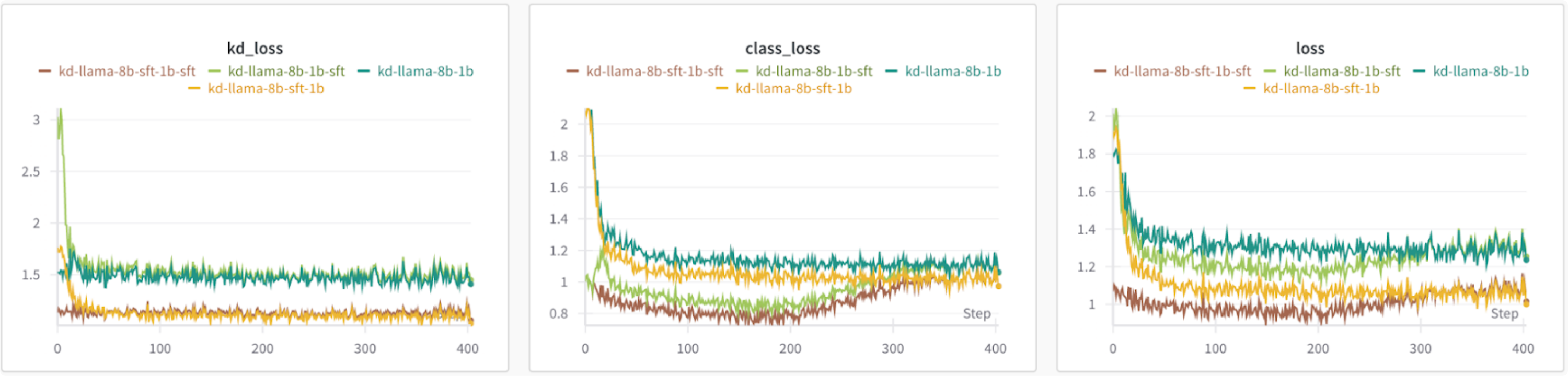
Figure 3: Comparing losses of different teacher and student model initializations
Using the fine-tuned student model boosts accuracy even further for truthfulqa, but the accuracy drops for hellaswag and commonsense. Using a fine-tuned teacher model and baseline student model achieved the best results on hellaswag and commonsense dataset. Based on these findings, the best configuration will change depending on which evaluation dataset and metric you are optimizing for.
| Model | TruthfulQA | hellaswag | commonsense | |
| mc2 | acc | acc_norm | acc | |
| Baseline Llama 3.1 8B | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| Fine-tuned Llama 3.1 8B using LoRA | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| Baseline Llama 3.2 1B | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| Fine-tuned Llama 3.2 1B using LoRA | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| KD using baseline 8B and baseline 1B | 0.444 | 0.4576 | 0.6123 | 0.5561 |
| KD using baseline 8B and fine-tuned 1B | 0.4508 | 0.448 | 0.6004 | 0.5274 |
| KD using fine-tuned 8B and baseline 1B | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
| KD using fine-tuned 8B and fine-tuned 1B | 0.4713 | 0.4512 | 0.599 | 0.5233 |
Table 3: Comparison using baseline and fine-tuned teacher and student models
Hyperparameter tuning: learning rate
By default, the recipe has a learning rate of 3e-4. For these experiments, we changed the learning rate from as high as 1e-3 to as low as 1e-5.
Based on the loss graphs, all learning rates result in similar losses except for 1e-5, which has a higher KD and class loss.
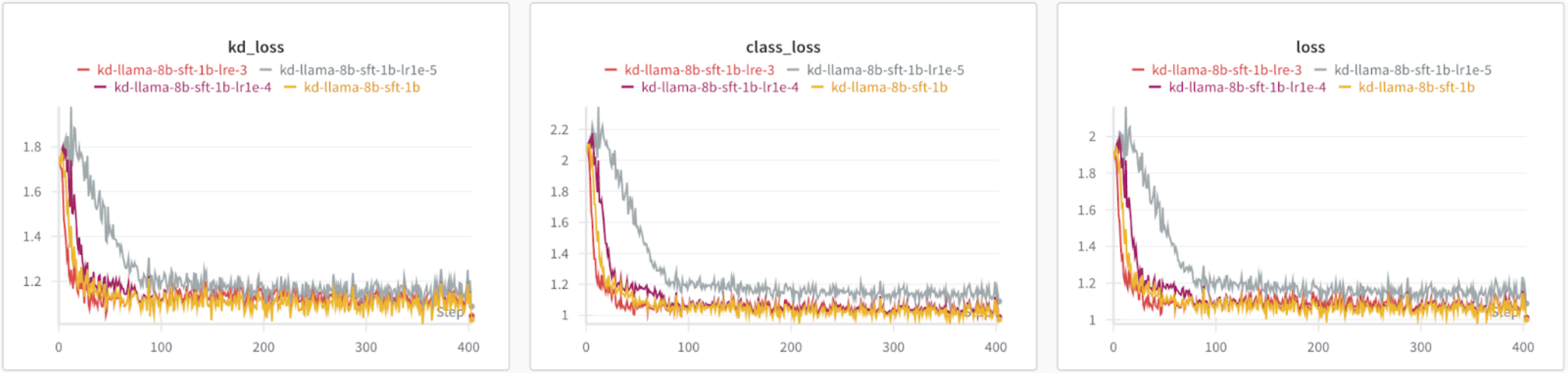
Figure 4: Comparing losses of different learning rates
Based on our benchmarks, the optimal learning rate changes depending on which metric and tasks you are optimizing for.
| Model | learning rate | TruthfulQA | hellaswag | commonsense | |
| mc2 | acc | acc_norm | acc | ||
| Baseline Llama 3.1 8B | – | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| Fine-tuned Llama 3.1 8B using LoRA | – | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| Baseline Llama 3.2 1B | – | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| Fine-tuned Llama 3.2 1B using LoRA | – | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| KD using fine-tuned 8B and baseline 1B | 3e-4 | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
| KD using fine-tuned 8B and baseline 1B | 1e-3 | 0.4453 | 0.4535 | 0.6071 | 0.5258 |
| KD using fine-tuned 8B and baseline 1B | 1e-4 | 0.4489 | 0.4606 | 0.6156 | 0.5586 |
| KD using fine-tuned 8B and baseline 1B | 1e-5 | 0.4547 | 0.4548 | 0.6114 | 0.5487 |
Table 4: Effects of tuning learning rate
Hyperparameter tuning: KD ratio
By default, the KD ratio is set to 0.5, which gives even weighting to both the class and KD loss. In these experiments, we look at the effects of different KD ratios, where 0 only uses the class loss and 1 only uses the KD loss.
Overall, the benchmark results show that for these tasks and metrics, higher KD ratios perform slightly better.
| Model | kd_ratio (lr=3e-4) | TruthfulQA | hellaswag | commonsense | |
| mc2 | acc | acc_norm | acc | ||
| Baseline Llama 3.1 8B | – | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| Fine-tuned Llama 3.1 8B using LoRA | – | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| Baseline Llama 3.2 1B | – | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| Fine-tuned Llama 3.2 1B using LoRA | – | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| KD using fine-tuned 8B and baseline 1B | 0.25 | 0.4485 | 0.4595 | 0.6155 | 0.5602 |
| KD using fine-tuned 8B and baseline 1B | 0.5 | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
| KD using fine-tuned 8B and baseline 1B | 0.75 | 0.4543 | 0.463 | 0.6189 | 0.5643 |
| KD using fine-tuned 8B and baseline 1B | 1.0 | 0.4537 | 0.4641 | 0.6177 | 0.5717 |
Table 5: Effects of tuning KD ratio
Looking Ahead
In this blog, we presented a study on how to distill LLMs through torchtune using the forward KL divergence loss on Llama 3.1 8B and Llama 3.2 1B logits. There are many directions for future exploration to further improve performance and offer more flexibility in distillation methods.
- Expand KD loss offerings. The KD recipe uses the forward KL divergence loss. However, aligning the student distribution to the whole teacher distribution may not be effective, as mentioned above. There are multiple papers, such as MiniLLM, DistiLLM, and Generalized KD, that introduce new KD losses and policies to address the limitation and have shown to outperform the standard use of cross entropy with forward KL divergence loss. For instance, MiniLLM uses reverse KL divergence to prevent the student from over-estimating low-probability regions of the teacher. DistiLLM introduces a skewed KL loss and an adaptive training policy.
- Enable cross-tokenizer distillation. The current recipe requires the teacher and student model to use the same tokenizer, which limits the ability to distill across different LLM families. There has been research on cross-tokenizer approaches (e.g. Universal Logit Distillation) that we could explore.
- Expand distillation to multimodal LLMs and encoder models. A natural extension of the KD recipe is to expand to multimodal LLMs. Similar to deploying more efficient LLMs, there’s also a need to deploy smaller and more efficient multimodal LLMs. In addition, there has been work in demonstrating LLMs as encoder models (e.g. LLM2Vec). Distillation from LLMs as encoders to smaller encoder models may also be a promising direction to explore.