The recently released DeepSeek-R1 model family has brought a new wave of excitement to the AI community, allowing enthusiasts and developers to run state-of-the-art reasoning models with problem-solving, math and code capabilities, all from the privacy of local PCs.
With up to 3,352 trillion operations per second of AI horsepower, NVIDIA GeForce RTX 50 Series GPUs can run the DeepSeek family of distilled models faster than anything on the PC market.
A New Class of Models That Reason
Reasoning models are a new class of large language models (LLMs) that spend more time on “thinking” and “reflecting” to work through complex problems, while describing the steps required to solve a task.
The fundamental principle is that any problem can be solved with deep thought, reasoning and time, just like how humans tackle problems. By spending more time — and thus compute — on a problem, the LLM can yield better results. This phenomenon is known as test-time scaling, where a model dynamically allocates compute resources during inference to reason through problems.
Reasoning models can enhance user experiences on PCs by deeply understanding a user’s needs, taking actions on their behalf and allowing them to provide feedback on the model’s thought process — unlocking agentic workflows for solving complex, multi-step tasks such as analyzing market research, performing complicated math problems, debugging code and more.
The DeepSeek Difference
The DeepSeek-R1 family of distilled models is based on a large 671-billion-parameter mixture-of-experts (MoE) model. MoE models consist of multiple smaller expert models for solving complex problems. DeepSeek models further divide the work and assign subtasks to smaller sets of experts.
DeepSeek employed a technique called distillation to build a family of six smaller student models — ranging from 1.5-70 billion parameters — from the large DeepSeek 671-billion-parameter model. The reasoning capabilities of the larger DeepSeek-R1 671-billion-parameter model were taught to the smaller Llama and Qwen student models, resulting in powerful, smaller reasoning models that run locally on RTX AI PCs with fast performance.
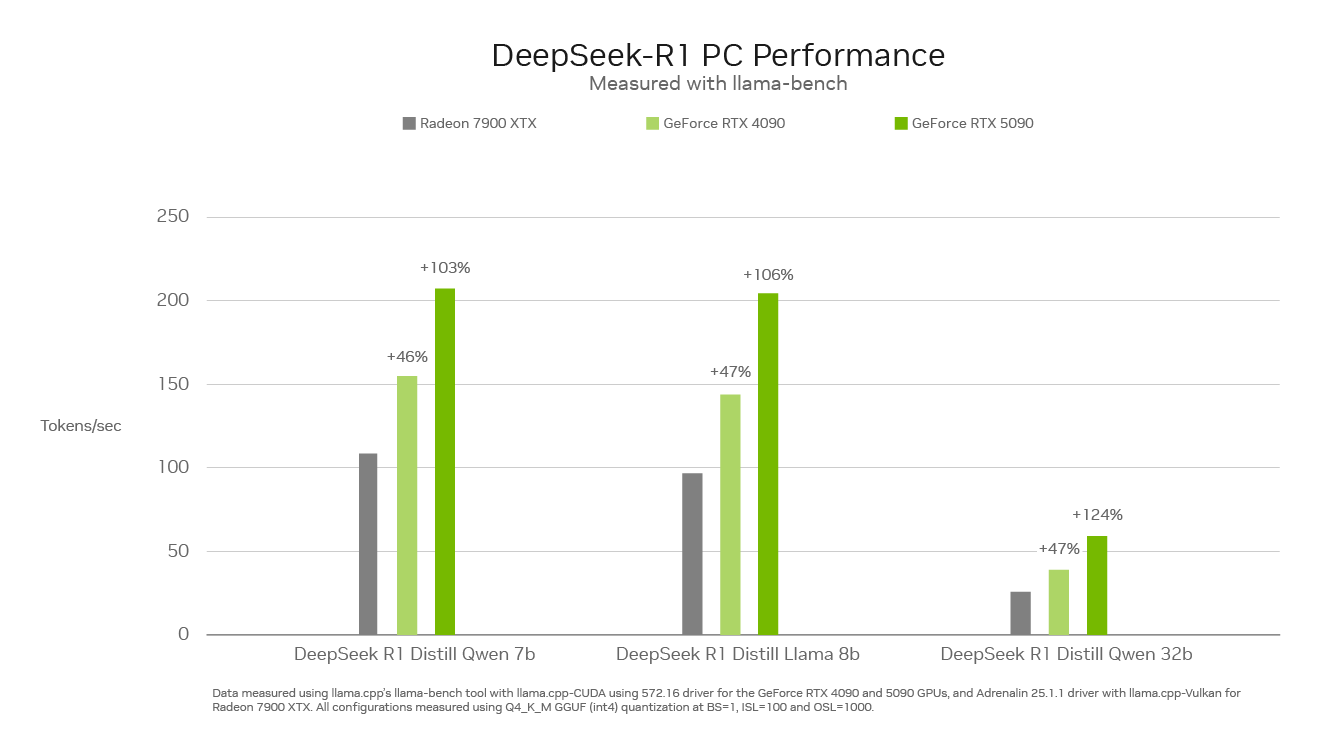
Peak Performance on RTX
Inference speed is critical for this new class of reasoning models. GeForce RTX 50 Series GPUs, built with dedicated fifth-generation Tensor Cores, are based on the same NVIDIA Blackwell GPU architecture that fuels world-leading AI innovation in the data center. RTX fully accelerates DeepSeek, offering maximum inference performance on PCs.
Experience DeepSeek on RTX in Popular Tools
NVIDIA’s RTX AI platform offers the broadest selection of AI tools, software development kits and models, opening access to the capabilities of DeepSeek-R1 on over 100 million NVIDIA RTX AI PCs worldwide, including those powered by GeForce RTX 50 Series GPUs.
High-performance RTX GPUs make AI capabilities always available — even without an internet connection — and offer low latency and increased privacy because users don’t have to upload sensitive materials or expose their queries to an online service.
Experience the power of DeepSeek-R1 and RTX AI PCs through a vast ecosystem of software, including Llama.cpp, Ollama, LM Studio, AnythingLLM, Jan.AI, GPT4All and OpenWebUI, for inference. Plus, use Unsloth to fine-tune the models with custom data.