Posted by Amir Yazdanbakhsh, Research Scientist, Google Research
One of the key contributors to recent machine learning (ML) advancements is the development of custom accelerators, such as Google TPUs and Edge TPUs, which significantly increase available compute power unlocking various capabilities such as AlphaGo, RankBrain, WaveNets, and Conversational Agents. This increase can lead to improved performance in neural network training and inference, enabling new possibilities in a broad range of applications, such as vision, language, understanding, and self-driving cars.
To sustain these advances, the hardware accelerator ecosystem must continue to innovate in architecture design and acclimate to rapidly evolving ML models and applications. This requires the evaluation of many different accelerator design points, each of which may not only improve the compute power, but also unravel a new capability. These design points are generally parameterized by a variety of hardware and software factors (e.g., memory capacity, number of compute units at different levels, parallelism, interconnection networks, pipelining, software mapping, etc.). This is a daunting optimization task, due to the fact that the search space is exponentially large1 while the objective function (e.g., lower latency and/or higher energy efficiency) is computationally expensive to evaluate through simulations or synthesis, making identification of feasible accelerator configurations challenging .
In “Apollo: Transferable Architecture Exploration”, we present the progress of our research on ML-driven design of custom accelerators. While recent work has demonstrated promising results in leveraging ML to improve the low-level floorplanning process (in which the hardware components are spatially laid out and connected in silicon), in this work we focus on blending ML into the high-level system specification and architectural design stage, a pivotal contributing factor to the overall performance of the chip in which the design elements that control the high-level functionality are established. Our research shows how ML algorithms can facilitate architecture exploration and suggest high-performing architectures across a range of deep neural networks, with domains spanning image classification, object detection, OCR and semantic segmentation.
Architecture Search Space and Workloads
The objective in architecture exploration is to discover a set of feasible accelerator parameters for a set of workloads, such that a desired objective function (e.g., the weighted average of runtime) is minimized under an optional set of user-defined constraints. However, the manifold of architecture search generally contains many points for which there is no feasible mapping from software to hardware. Some of these design points are known a priori and can be bypassed by formulating them as optimization constraints by the user (e.g., in the case of an area budget2 constraint, the total memory size must not pass over a predefined limit). However, due to the interplay of the architecture and compiler and the complexity of the search space, some of the constraints may not be properly formulated into the optimization, and so the compiler may not find a feasible software mapping for the target hardware. These infeasible points are not easy to formulate in the optimization problem, and are generally unknown until the whole compiler pass is performed. As such, one of main challenges for architecture exploration is to effectively sidestep the infeasible points for efficient exploration of the search space with a minimum number of cycle-accurate architecture simulations.
The following figure shows the overall architecture search space of a target ML accelerator. The accelerator contains a 2D array of processing elements (PE), each of which performs a set of arithmetic computations in a single instruction multiple data (SIMD) manner. The main architectural components of each PE are processing cores that include multiple compute lanes for SIMD operations. Each PE has shared memory (PE Memory) across all their compute cores, which is mainly used to store model activations, partial results, and outputs, while individual cores feature memory that is mainly used for storing model parameters. Each core has multiple compute lanes with multi-way multiply-accumulate (MAC) units. The results of model computations at each cycle are either stored back in the PE memory for further computation or are offloaded back into the DRAM.
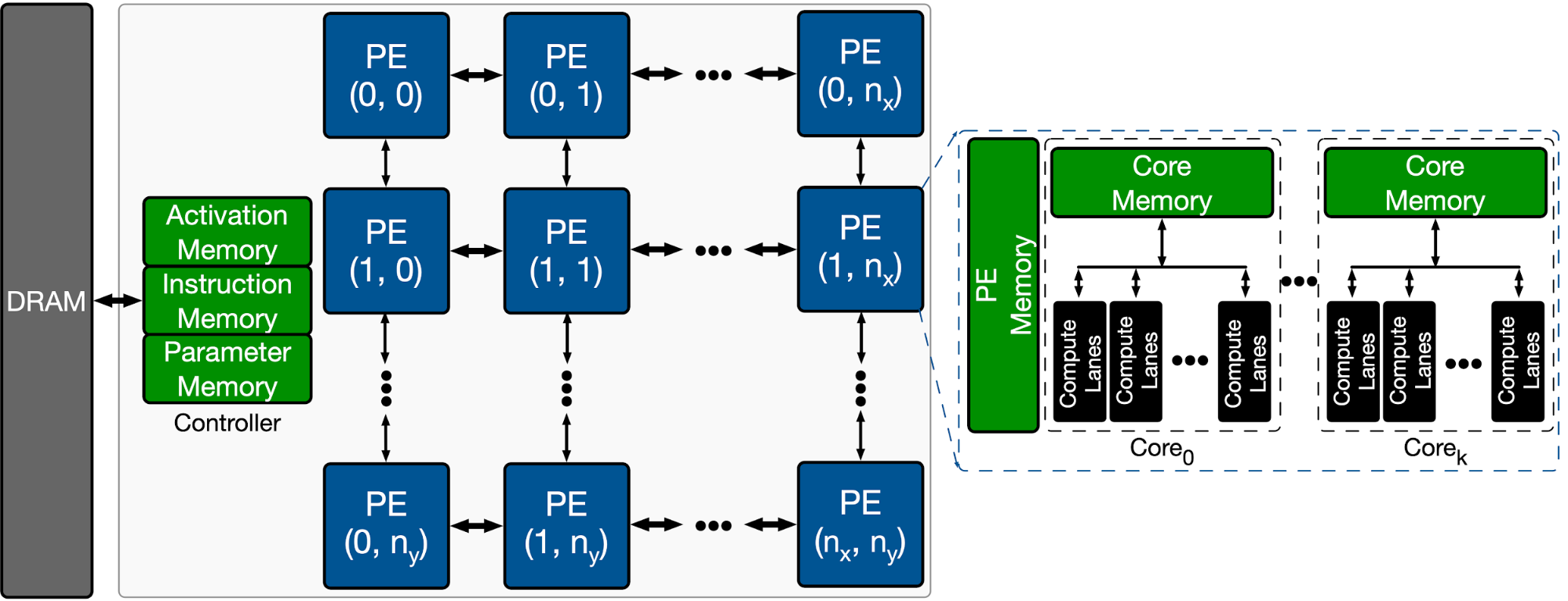 |
| Overview of the template-based ML accelerator used for architecture exploration. |
Optimization Strategies
In this study, we explored four optimization strategies in the context of architecture exploration:
- Random: Samples the architecture search space uniformly at random.
- Vizier: Uses Bayesian optimization for the exploration in the search space in which the evaluation of the objective function is expensive (e.g. hardware simulation which can take hours to complete). Using a collection of sampled points from the search space, the Bayesian optimization forms a surrogate function, usually represented by a Gaussian process, that approximates the manifold of the search space. Guided by the value of the surrogate function, the Bayesian optimization algorithm decides, in an exploration and exploitation trade-off, whether to sample more from the promising regions in the manifold (exploitation) or sample more from the unseen regions in the search space (exploration). Then, the optimization algorithm uses these newly sampled points and further updates the surrogate function to better model the target search space. Vizier uses expected improvement as its core acquisition function.
- Evolutionary: Performs evolutionary search using a population of k individuals, where the genome of each individual corresponds to a sequence of discretized accelerator configurations. New individuals are generated by selecting for each individual two parents from the population using tournament selecting, recombining their genomes with some crossover rate, and mutating the recombined genome with some probability.
- Population-based black-box optimization (P3BO): Uses an ensemble of optimization methods, including evolutionary and model-based, which has been shown to increase sample-efficiency and robustness. The sampled data are exchanged between optimization methods in the ensemble, and optimizers are weighted by their performance history to generate new configurations. In our study, we use a variant of P3BO in which the hyper-parameters of the optimizers are dynamically updated using evolutionary search.
Accelerator Search Space Embeddings
To better visualize the effectiveness of each optimization strategy in navigating the accelerator search space, we use t-distributed stochastic neighbor embedding (t-SNE) to map the explored configurations into a two-dimensional space across the optimization horizon. The objective (reward) for all the experiments is defined as the throughput (inference/second) per accelerator area. In the figures below, the x and y axes indicate the t-SNE components (embedding 1 and embedding 2) of the embedding space. The star and circular markers show the infeasible (zero reward) and feasible design points, respectively, with the size of the feasible points corresponding to their reward.
As expected, the random strategy searches the space in a uniformly distributed way and eventually finds very few feasible points in the design space.
 |
| Visualization presenting the t-SNE of the explored design points (~4K) by random optimization strategy (max reward = 0.96). The maximum reward points (red cross markers) are highlighted at the last frame of the animation. |
Compared to the random sampling approach, the Vizier default optimization strategy strikes a good balance between exploring the search space and finding the design points with higher rewards (1.14 vs. 0.96). However, this approach tends to get stuck in infeasible regions and, while it does find a few points with the maximum reward (indicated by the red cross markers), it finds few feasible points during the last iterations of exploration.
 |
| As above, with the Vizier (default) optimization strategy (max reward = 1.14). The maximum reward points (red cross markers) are highlighted at the last frame of the animation. |
The evolutionary optimization strategy, on the other hand, finds feasible solutions very early in the optimization and assemble clusters of feasible points around them. As such, this approach mostly navigates the feasible regions (the green circles) and efficiently sidesteps the infeasible points. In addition, the evolutionary search is able to find more design options with maximum reward (the red crosses). This diversity in the solutions with high reward provides flexibility to the designer in exploring various architectures with different design trade-offs.
 |
| As above, with the evolutionary optimization strategy (max reward = 1.10). The maximum reward points (red cross markers) are highlighted at the last frame of the animation. |
Finally, the population-based optimization method (P3BO) explores the design space in a more targeted way (regions with high reward points) in order to find optimal solutions. The P3BO strategy finds design points with the highest reward in search spaces with tighter constraints (e.g., a larger number of infeasible points), showing its effectiveness in navigating search spaces with large numbers of infeasible points.
 |
| As above, with the P3BO optimization strategy (max reward = 1.13). The maximum reward points (red cross markers) are highlighted at the last frame of the animation. |
Architecture Exploration under Different Design Constraints
We also studied the benefits of each optimization strategy under different area budget constraints, 6.8 mm2, 5.8 mm2 and 4.8 mm2. The following violin plots show the full distribution of the maximum achievable reward at the end of optimization (after ten runs each with 4K trials) across the studied optimization strategies. The wider sections represent a higher probability of observing feasible architecture configurations at a particular given reward. This implies that we favor the optimization algorithm that yields increased width at the points with higher reward (higher performance).
The two top-performing optimization strategies for architecture exploration are evolutionary and P3BO, both in terms of delivering solutions with high reward and robustness across multiple runs. Looking into different design constraints, we observe that as one tightens the area budget constraint, the P3BO optimization strategy yields more high performing solutions. For example, when the area budget constraint is set to 5.8 mm2, P3BO finds design points with a reward (throughput / accelerator area) of 1.25 outperforming all the other optimization strategies. The same trend is observed when the area budget constraint is set to 4.8 mm2, a slightly better reward is found with more robustness (less variability) across multiple runs.
 |
| Violin plot showing the full distribution of the maximum achievable reward in ten runs across the optimization strategies after 4K trial evaluations under an area budget of 6.8 mm2. The P3BO and Evolutionary algorithm yield larger numbers of high-performing designs (wider sections). The x and y axes indicate the studied optimization algorithms and the geometric mean of speedup (reward) over the baseline accelerator, respectively. |
 |
| As above, under an area budget of 5.8 mm2. |
 |
| As above, under an area budget of 4.8 mm2. |
Conclusion
While Apollo presents the first step towards better understanding of accelerator design space and building more efficient hardware, inventing accelerators with new capabilities is still an uncharted territory and a new frontier. We believe that this research is an exciting path forward to further explore ML-driven techniques for architecture design and co-optimization (e.g., compiler, mapping, and scheduling) across the computing stack to invent efficient accelerators with new capabilities for the next generation of applications.
Acknowledgments
This work was performed by Amir Yazdanbakhsh, Christof Angermueller, and Berkin Akin . We would like to also thank Milad Hashemi, Kevin Swersky, James Laudon, Herman Schmit, Cliff Young, Yanqi Zhou, Albin Jones, Satrajit Chatterjee, Ravi Narayanaswami, Ray (I-Jui) Sung, Suyog Gupta, Kiran Seshadri, Suvinay Subramanian, Matthew Denton, and the Vizier team for their help and support.
1 In our target accelerator, the total number of design points is around 5 x 108. ↩
2 The chip area is approximately the sum of total hardware components on the chip, including on-chip storage, processing engines, controllers, I/O pins, and etc. ↩
