PyTorch is an open-source machine learning (ML) library widely used to develop neural networks and ML models. Those models are usually trained on multiple GPU instances to speed up training, resulting in expensive training time and model sizes up to a few gigabytes. After they’re trained, these models are deployed in production to produce inferences. They can be synchronous, asynchronous, or batch-based workloads. Those endpoints must be highly scalable and resilient in order to process from zero to millions of requests. This is where AWS Lambda can be a compelling compute service for scalable, cost-effective, and reliable synchronous and asynchronous ML inferencing. Lambda offers benefits such as automatic scaling, reduced operational overhead, and pay-per-inference billing.
This post shows you how to use any PyTorch model with Lambda for scalable inferences in production with up to 10 GB of memory. This allows us to use ML models in Lambda functions up to a few gigabytes. For the PyTorch example, we use the Huggingface Transformers, open-source library to build a question-answering endpoint.
Overview of solution
Lambda is a serverless compute service that lets you run code without provisioning or managing servers. Lambda automatically scales your application by running code in response to every event, allowing event-driven architectures and solutions. The code runs in parallel and processes each event individually, scaling with the size of the workload, from a few requests per day to hundreds of thousands of workloads. The following diagram illustrates the architecture of our solution.

You can package your code and dependencies as a container image using tools such as the Docker CLI. The maximum container size is 10 GB. After the model for inference is Dockerized, you can upload the image to Amazon Elastic Container Registry (Amazon ECR). You can then create the Lambda function from the container image stored in Amazon ECR.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- The AWS Command Line Interface (AWS CLI) installed and configured to interact with AWS services locally
- The AWS Serverless Application Model (AWS SAM) CLI installed
- The Docker CLI
Implementing the solution
We use a pre-trained language model (DistilBERT) from Huggingface. Huggingface provides a variety of pre-trained language models; the model we’re using is 250 MB large and can be used to build a question-answering endpoint.
We use the AWS SAM CLI to create the serverless endpoint with an Amazon API Gateway. The following diagram illustrates our architecture.
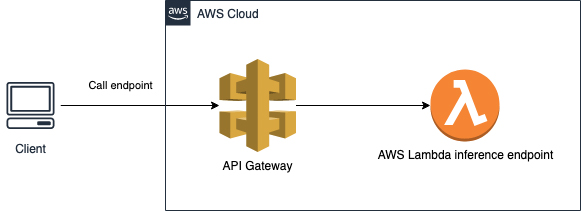
To implement the solution, complete the following steps:
- On your local machine, run
sam init. - Enter
1for the template source (AWS Quick Start Templates) - As a package type, enter
2for image. - For the base image, enter
3 - amazon/python3.8-base. - As a project name, enter
lambda-pytorch-example. - Change your
workdirtolambda-pytorch-exampleand copy the following code snippets into thehello_worldfolder.
The following code is an example of a requirements.txt file to run PyTorch code in Lambda. Huggingface has as a dependency PyTorch so we don’t need to add it here separately. Add the requirements to the empty requirements.txt in the folder hello_world.
# List all python libraries for the lambda
transformers[torch]==4.1.1
The following is the code for the app.py file:
import json
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
import torch
tokenizer = AutoTokenizer.from_pretrained("model/")
model = AutoModelForQuestionAnswering.from_pretrained("model/")
def lambda_handler(event, context):
body = json.loads(event['body'])
question = body['question']
context = body['context']
inputs = tokenizer.encode_plus(question, context,add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
output = model(**inputs)
answer_start_scores = output.start_logits
answer_end_scores = output.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
print('Question: {0}, Answer: {1}'.format(question, answer))
return {
'statusCode': 200,
'body': json.dumps({
'Question': question,
'Answer': answer
})
}
The following Dockerfile is an example for Python 3.8, which downloads and uses the DistilBERT language model fine-tuned for the question-answering task. For more information, see DistilBERT base uncased distilled SQuAD. You can use your custom models by copying them to the model folder and referencing it in the app.py.
# Pull the base image with python 3.8 as a runtime for your Lambda
FROM public.ecr.aws/lambda/python:3.8
# Copy the earlier created requirements.txt file to the container
COPY requirements.txt ./
# Install the python requirements from requirements.txt
RUN python3.8 -m pip install -r requirements.txt
# Copy the earlier created app.py file to the container
COPY app.py ./
# Load the BERT model from Huggingface and store it in the model directory
RUN mkdir model
RUN curl -L https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/pytorch_model.bin -o ./model/pytorch_model.bin
RUN curl https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/config.json -o ./model/config.json
RUN curl https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/tokenizer.json -o ./model/tokenizer.json
RUN curl https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/tokenizer_config.json -o ./model/tokenizer_config.json
# Set the CMD to your handler
CMD ["app.lambda_handler"]
Change your working directory back to lambda-pytorch-example and copy the following content into the template.yaml file:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
python3.8
Sample SAM Template for lambda-pytorch-example
Resources:
pytorchEndpoint:
Type: AWS::Serverless::Function
Properties:
PackageType: Image
MemorySize: 5000
Timeout: 300
Events:
ApiEndpoint:
Type: HttpApi
Properties:
Path: /inference
Method: post
TimeoutInMillis: 29000
Metadata:
Dockerfile: Dockerfile
DockerContext: ./hello_world
DockerTag: python3.8-v1
Outputs:
InferenceApi:
Description: "API Gateway endpoint URL for Prod stage for inference function"
Value: !Sub "https://${ServerlessHttpApi}.execute-api.${AWS::Region}.amazonaws.com/inference"
Now we need to create an Amazon ECR repository in AWS and register the local Docker to it. The repositoryUri is displayed in the output; save it for later.
# Create an ECR repository
aws ecr create-repository --repository-name lambda-pytorch-example --image-scanning-configuration scanOnPush=true --region <REGION>
# Register docker to ECR
aws ecr get-login-password --region <REGION> | docker login --username AWS --password-stdin <AWS_ACCOUNT_ID>.dkr.ecr.<REGION>.amazonaws.com
Deploying the application
The following steps deploy the application to your AWS account:
- Run
sam build && sam deploy –-guided. - For Stack Name, enter
pytorch-lambda-example. - Choose the same Region that you created the Amazon ECR repository in.
- Enter the image repository for the function (enter the earlier saved
repositoryUriof the Amazon ECR repository). - For Confirm changes before deploy and Allow SAM CLI IAM role creation, keep the defaults.
- For pytorchEndpoint may not have authorization defined, Is this okay?, select y.
- Keep the defaults for the remaining prompts.
AWS SAM uploads the container images to the Amazon ECR repository and deploys the application. During this process, you see a change set along with the status of the deployment. For a more detailed description about AWS SAM and container images for Lambda, see Using container image support for AWS Lambda with AWS SAM.
When the deployment is complete, the stack output is displayed. Use the InferenceApi endpoint to test your deployed application. The endpoint URL is displayed as an output during the deployment of the stack.
Overcoming a Lambda function cold start
Because the plain language model is already around 250 MB, the initial function run can take up to 25 seconds and may even exceed the maximum API timeout of 29 seconds. That time can also be reached when the function wasn’t called for some time and therefore is in a cold start mode. When the Lambda function is in a hot state, one inference run takes about 150 milliseconds.
There are multiple ways to mitigate the runtime of Lambda functions in a cold state. Lambda supports provisioned concurrency to keep the functions initialized. Another way is to create an Amazon CloudWatch event that periodically calls the function to keep it warm.
Make sure to change <API_GATEWAY_URL> to the URL of your API Gateway endpoint. In the following example code, the text is copied from the Wikipedia page on cars. You can change the question and context as you like and check the model’s answers.
curl --header "Content-Type: application/json" --request POST --data '{"question": "When was the car invented?","context": "Cars came into global use during the 20th century, and developed economies depend on them. The year 1886 is regarded as the birth year of the modern car when German inventor Karl Benz patented his Benz Patent-Motorwagen. Cars became widely available in the early 20th century. One of the first cars accessible to the masses was the 1908 Model T, an American car manufactured by the Ford Motor Company. Cars were rapidly adopted in the US, where they replaced animal-drawn carriages and carts, but took much longer to be accepted in Western Europe and other parts of the world."}' <API_GATEWAY_URL>The response shows the correct answer to the question:
{"Question": "When was the car invented?", "Answer": "1886"}Conclusion
Container image support for Lambda allows you to customize your function even more, opening up many new use cases for serverless ML. You can bring your custom models and deploy them on Lambda using up to 10 GB for the container image size. For smaller models that don’t need much computing power, you can perform online training and inference purely in Lambda. When the model size increases, cold start issues become more and more important and need to be mitigated. There is also no restriction on the framework or language with container images; other ML frameworks such as TensorFlow, Apache MXNet, XGBoost, or Scikit-learn can be used as well!
If you do require GPU for your inference, you can consider using containers services such as Amazon Elastic Container Service (Amazon ECS), Kubernetes, or deploy the model to an Amazon SageMaker endpoint
About the Author
 Jan Bauer is a Cloud Application Developer at AWS Professional Services. His interests are serverless computing, machine learning, and everything that involves cloud computing.
Jan Bauer is a Cloud Application Developer at AWS Professional Services. His interests are serverless computing, machine learning, and everything that involves cloud computing.