A guest post by Mohamed Nour Abouelseoud and Elena Zhelezina at Arm.
This blog post introduces collaborative techniques for machine learning model optimization for edge devices, proposed and contributed by Arm to the TensorFlow Model Optimization Toolkit, available starting from release v0.7.0.
The main idea of the collaborative optimization pipeline is to apply the different optimization techniques in the TensorFlow Model Optimization Toolkit one after another while maintaining the balance between compression and accuracy required for deployment. This leads to significant reduction in the model size and could improve inference speed given framework and hardware-specific support such as that offered by the Arm Ethos-N and Ethos-U NPUs.
This work is a part of the toolkit’s roadmap to support the development of smaller and faster ML models. You can see previous posts on post-training quantization, quantization-aware training, sparsity, and clustering for more background on the toolkit and what it can do.
What is Collaborative Optimization? And why?
The motivation behind collaborative optimization remains the same as that behind the Model Optimization Toolkit (TFMOT) in general, which is to enable model conditioning and compression for improving deployment to edge devices. The push towards edge computing and endpoint-oriented AI creates high demand for such tools and techniques. The Collaborative Optimization API stacks all of the available techniques for model optimization to take advantage of their cumulative effect and achieve the best model compression while maintaining required accuracy.
Given the following optimization techniques, various combinations for deployment are possible:
- Weight pruning
- Weight clustering
- Quantization
In other words, it is possible to apply one or both of pruning and clustering, followed by post-training quantization or QAT before deployment.
The challenge in combining these techniques is that the APIs don’t consider previous ones, with each optimization and fine-tuning process not preserving the results of the preceding technique. This spoils the overall benefit of simultaneously applying them; i.e., clustering doesn’t preserve the sparsity introduced by the pruning process and the fine-tuning process of QAT loses both the pruning and clustering benefits. To overcome these problems, we introduce the following collaborative optimization techniques:
- Sparsity preserving clustering: clustering API that ensures a zero cluster, preserving the sparsity of the model.
- Sparsity preserving quantization aware training (PQAT): QAT training API that preserves the sparsity of the model.
- Cluster preserving quantization aware training (CQAT): QAT training API that does re-clustering and preserves the same number of centroids.
- Sparsity and cluster preserving quantization aware training (PCQAT): QAT training API that preserves the sparsity and number of clusters of a model trained with sparsity-preserving clustering.
Considered together, along with the option of post-training quantization instead of QAT, these provide several paths for deployment, visualized in the following deployment tree, where the leaf nodes are deployment-ready models, meaning they are fully quantized and in TFLite format. The green fill indicates steps where retraining/fine-tuning is required and a dashed red border highlights the collaborative optimization steps. The technique used to obtain a model at a given node is indicated in the corresponding label.

The direct, quantization-only (post-training or QAT) deployment path is omitted in the figure above.
The idea is to reach the fully optimized model at the third level of the above deployment tree; however, any of the other levels of optimization could prove satisfactory and achieve the required inference latency, compression, and accuracy target, in which case no further optimization is needed. The recommended training process would be to iteratively go through the levels of the deployment tree applicable to the target deployment scenario and see if the model fulfils the optimization requirements and, if not, use the corresponding collaborative optimization technique to compress the model further and repeat until the model is fully optimized (pruned, clustered, and quantized), if needed.
To further unlock the improvements in memory usage and speed at inference time associated with collaborative optimization, specialized run-time or compiler software and dedicated machine learning hardware is required. Examples include the Arm ML Ethos-N driver stack for the Ethos-N processor and the Ethos-U Vela compiler for the Ethos-U processor. Both examples currently require quantizing and converting optimized Keras models to TensorFlow Lite first.
The figure below shows the density plots of a sample weight kernel going through the full collaborative optimization pipeline.
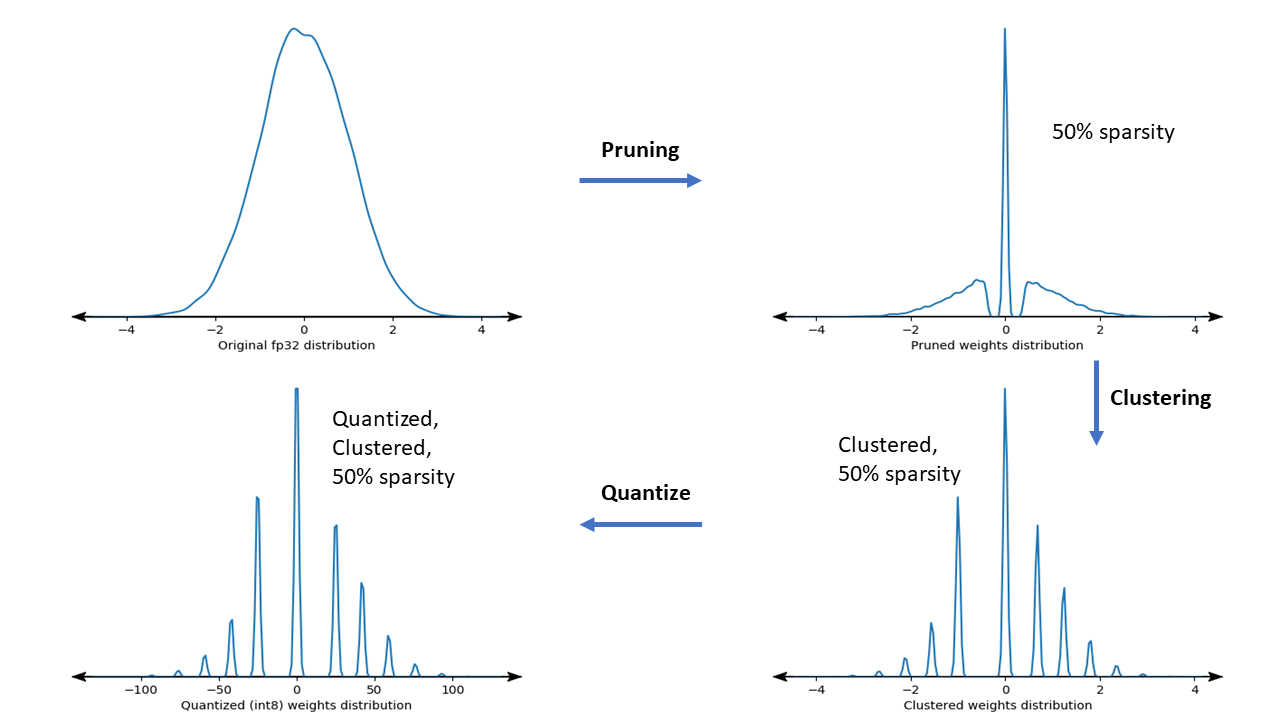
The result is a quantized deployment model with a reduced number of unique values as well as a significant number of sparse weights, depending on the target sparsity specified at training time. This results in substantial model compression advantages and significantly reduced inference latency on specialized hardware.
Compression and accuracy results
The tables below show the results of running several experiments on popular models, demonstrating the compression benefits vs. accuracy loss incurred by applying these techniques. More aggressive optimizations can be applied, but at the cost of accuracy. Though the table below includes measurements for TensorFlow Lite models, similar benefits are observed for other serialization formats.
Sparsity-preserving Quantization aware training (PQAT)
|
Model |
Metric |
Baseline |
Pruned Model (50% sparsity) |
QAT Model |
PQAT Model |
|
DS-CNN-L |
FP32 Top-1 Accuracy |
95.23% |
94.80% |
(Fake INT8) 94.721% |
(Fake INT8) 94.128% |
|
INT8 Top-1 Accuracy |
94.48% |
93.80% |
94.72% |
94.13% |
|
|
Compression |
528,128 → 434,879 (17.66%) |
528,128 → 334,154 (36.73%) |
512,224 → 403,261 (21.27%) |
512,032 → 303,997 (40.63%) |
|
|
MobileNet_v1 on ImageNet |
FP32 Top-1 Accuracy |
70.99% |
70.11% |
(Fake INT8) 70.67% |
(Fake INT8) 70.29% |
|
INT8 Top-1 Accuracy |
69.37% |
67.82% |
70.67% |
70.29% |
|
|
Compression |
4,665,520 → 3,880,331 (16.83%) |
4,665,520 → 2,939,734 (37.00%) |
4,569,416 → 3,808,781 (16.65%) |
4,569,416 → 2,869,600 (37.20%) |
Note: DS-CNN-L is a keyword spotting model designed for edge devices. More can be found in Arm’s ML Examples repository.
Cluster-preserving Quantization aware training (CQAT)
|
Model |
Metric |
Baseline |
Clustered Model |
QAT Model |
CQAT Model |
|
MobileNet_v1 on CIFAR-10 |
FP32 Top-1 Accuracy |
94.88% |
94.48% (16 clusters) |
(Fake INT8) 94.80% |
(Fake INT8) 94.60% |
|
INT8 Top-1 Accuracy |
94.65% |
94.41% (16 clusters) |
94.77% |
94.52% |
|
|
Size |
3,000,000 |
2,000,000 |
2,840,000 |
1,940,000 |
|
|
MobileNet_v1 on ImageNet |
FP32 Top-1 Accuracy |
71.07% |
65.30% (32 clusters) |
(Fake INT8) 70.39% |
(Fake INT8) 65.35% |
|
INT8 Top-1 Accuracy |
69.34% |
60.60% (32 clusters) |
70.35% |
65.42% |
|
|
Compression |
4,665,568 → 3,886,277 (16.7%) |
4,665,568 → 3,035,752 (34.9%) |
4,569,416 → 3,804,871 (16.7%) |
4,569,472 → 2,912,655 (36.25%) |
Sparsity and cluster preserving quantization aware training (PCQAT)
|
Model |
Metric |
Baseline |
Pruned Model (50% sparsity) |
QAT Model |
Pruned Clustered Model |
PCQAT Model |
|
DS-CNN-L |
FP32 Top-1 Accuracy |
95.06% |
94.07% |
(Fake INT8) 94.85% |
93.76% (8 clusters) |
(Fake INT8) 94.28% |
|
INT8 Top-1 Accuracy |
94.35% |
93.80% |
94.82% |
93.21% (8 clusters) |
94.06% |
|
|
Compression |
506,400 → 425,006 (16.07%) |
506,400 → 317,937 (37.22%) |
507,296 → 424,368 (16.35%) |
506,400 → 205,333 (59.45%) |
507,296 → 201,744 (60.23%) |
|
|
MobileNet_v1 on ImageNet |
FP32 Top-1 Accuracy |
70.98% |
70.49% |
(Fake INT8) 70.88% |
67.64% (16 clusters) |
(Fake INT8) 67.80% |
|
INT8 Top-1 Accuracy |
70.37% |
69.85% |
70.87% |
66.89% (16 clusters) |
68.63%
|
|
|
Compression |
4,665,552 → 3,886,236 (16.70%) |
4,665,552 → 2,909,148 (37.65%) |
4,569,416 → 3,808,781 (16.65%) |
4,665,552 → 2,013,010 (56.85%) |
4,569472 → 1,943,957 (57.46%) |
Applying PCQAT
To apply PCQAT, you will need to first use the pruning API to prune the model, then chain it with clustering using the sparsity-preserving clustering API. After that, the QAT API is used along with the custom collaborative optimization quantization scheme. An example is shown below.
import tensorflow_model_optimization as tfmot
model = build_your_model()
# prune model
model_for_pruning = tfmot.sparsity.keras.prune_low_magnitude(model, ...)
model_for_pruning.fit(...)
# pruning wrappers must be stripped before clustering
stripped_pruned_model = tfmot.sparsity.keras.strip_pruning(pruned_model)
After pruning the model, cluster and fit as below.
# Sparsity preserving clustering
from tensorflow_model_optimization.python.core.clustering.keras.experimental import (cluster)
# Specify your clustering parameters along
# with the `preserve_sparsity` flag
clustering_params = {
...,
'preserve_sparsity': True
}
# Cluster and fine-tune as usual
cluster_weights = cluster.cluster_weights
sparsity_clustered_model = cluster_weights(stripped_pruned_model_copy, **clustering_params)
sparsity_clustered_model.compile(...)
sparsity_clustered_model.fit(...)
# Strip clustering wrappers before the PCQAT step
stripped_sparsity_clustered_model = tfmot.clustering.keras.strip_clustering(sparsity_clustered_model)
Then apply PCQAT.
pcqat_annotate_model = quantize.quantize_annotate_model(stripped_sparsity_clustered_model )
pcqat_model = quantize.quantize_apply(quant_aware_annotate_model,scheme=default_8bit_cluster_preserve_quantize_scheme.Default8BitClusterPreserveQuantizeScheme(preserve_sparsity=True))
pcqat_model.compile(...)
pcqat_model.fit(...)The example above shows the training process to achieve a fully optimized PCQAT model, for the other techniques, please refer to the CQAT, PQAT, and sparsity-preserving clustering example notebooks. Note that the API used for PCQAT is the same as that of CQAT, the only difference being the use of the preserve_sparsity flag to ensure that the zero cluster is preserved during training. The PQAT API usage is similar but uses a different, sparsity preserving, quantization scheme.
Acknowledgments
The features and results presented in this post are the work of many people including the Arm ML Tooling team and our collaborators in Google’s TensorFlow Model Optimization Toolkit team.
From Arm – Anton Kachatkou, Aron Virginas-Tar, Ruomei Yan, Saoirse Stewart, Peng Sun, Elena Zhelezina, Gergely Nagy, Les Bell, Matteo Martincigh, Benjamin Klimczak, Thibaut Goetghebuer-Planchon, Tamás Nyíri, Johan Gras.
From Google – David Rim, Frederic Rechtenstein, Alan Chiao, Pulkit Bhuwalka