In many industries, it’s critical to extract custom entities from documents in a timely manner. This can be challenging. Insurance claims, for example, often contain dozens of important attributes (such as dates, names, locations, and reports) sprinkled across lengthy and dense documents. Manually scanning and extracting such information can be error-prone and time-consuming. Rule-based software can help, but ultimately is too rigid to adapt to the many varying document types and layouts.
To help automate and speed up this process, you can use Amazon Comprehend to detect custom entities quickly and accurately by using machine learning (ML). This approach is flexible and accurate, because the system can adapt to new documents by using what it has learned in the past. Until recently, however, this capability could only be applied to plain text documents, which meant that positional information was lost when converting the documents from their native format. To address this, it was recently announced that Amazon Comprehend can extract custom entities in PDFs, images, and Word file formats.
In this post, we walk through a concrete example from the insurance industry of how you can build a custom recognizer using PDF annotations.
Solution overview
We walk you through the following high-level steps:
- Create PDF annotations.
- Use the PDF annotations to train a custom model using the Python API.
- Obtain evaluation metrics from the trained model.
- Perform inference on an unseen document.
By the end of this post, we want to be able to send a raw PDF document to our trained model, and have it output a structured file with information about our labels of interest. In particular, we train our model to detect the following five entities that we chose because of their relevance to insurance claims: DateOfForm, DateOfLoss, NameOfInsured, LocationOfLoss, and InsuredMailingAddress. After reading the structured output, we can visualize the label information directly on the PDF document, as in the following image.

This post is accompanied by a Jupyter notebook that contains the same steps. Feel free to follow along while running the steps in that notebook. Note that you need to set up the Amazon SageMaker environment to allow Amazon Comprehend to read from Amazon Simple Storage Service (Amazon S3) as described at the top of the notebook.
Create PDF annotations
To create annotations for PDF documents, you can use Amazon SageMaker Ground Truth, a fully managed data labeling service that makes it easy to build highly accurate training datasets for ML.
For this tutorial, we have already annotated the PDFs in their native form (without converting to plain text) using Ground Truth. The Ground Truth job generates three paths we need for training our custom Amazon Comprehend model:
- Sources – The path to the input PDFs.
- Annotations – The path to the annotation JSON files containing the labeled entity information.
- Manifest – The file that points to the location of the annotations and source PDFs. This file is used to create an Amazon Comprehend custom entity recognition training job and train a custom model.
The following screenshot shows a sample annotation.
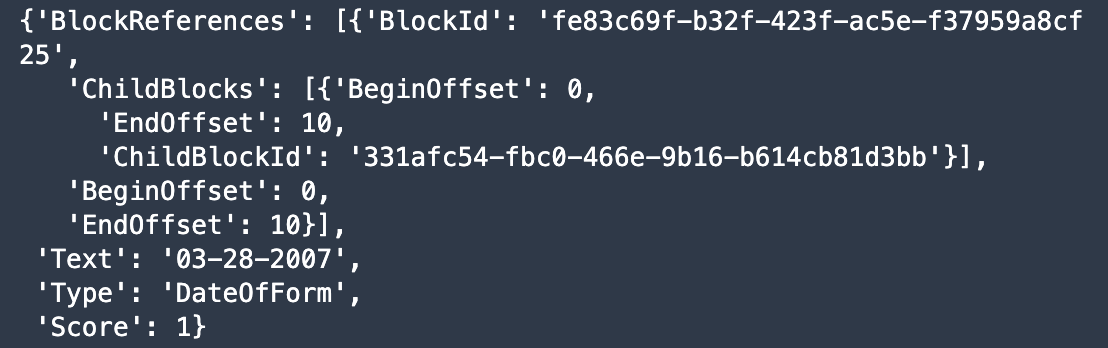
The custom Ground Truth job generates a PDF annotation that captures block-level information about the entity. Such block-level information provides the precise positional coordinates of the entity (with the child blocks representing each word within the entity block). This is distinct from a standard Ground Truth job in which the data in the PDF is flattened to textual format and only offset information—but not precise coordinate information—is captured during annotation. The rich positional information we obtain with this custom annotation paradigm allows us to train a more accurate model.
The manifest that’s generated from this type of job is called an augmented manifest, as opposed to a CSV that’s used for standard annotations. For more information, see Annotations.
Use the PDF annotations to train a custom model using the Python API
An augmented manifest file must be formatted in JSON Lines format. In JSON Lines format, each line in the file is a complete JSON object followed by a newline separator.
The following code is an entry within this augmented manifest file.

A few things to note:
- Five labeling types are associated with this job:
DateOfForm,DateOfLoss,NameOfInsured,LocationOfLoss, andInsuredMailingAddress. - The manifest file references both the source PDF location and the annotation location.
- Metadata about the annotation job (such as creation date) is captured.
-
Use-textract-onlyis set toFalse, meaning the annotation tool decides whether to use PDFPlumber (for a native PDF) or Amazon Textract (for a scanned PDF). If set totrue, Amazon Textract is used in either case (which is more costly but potentially more accurate).
Now we can train the recognizer, as shown in the following example code.
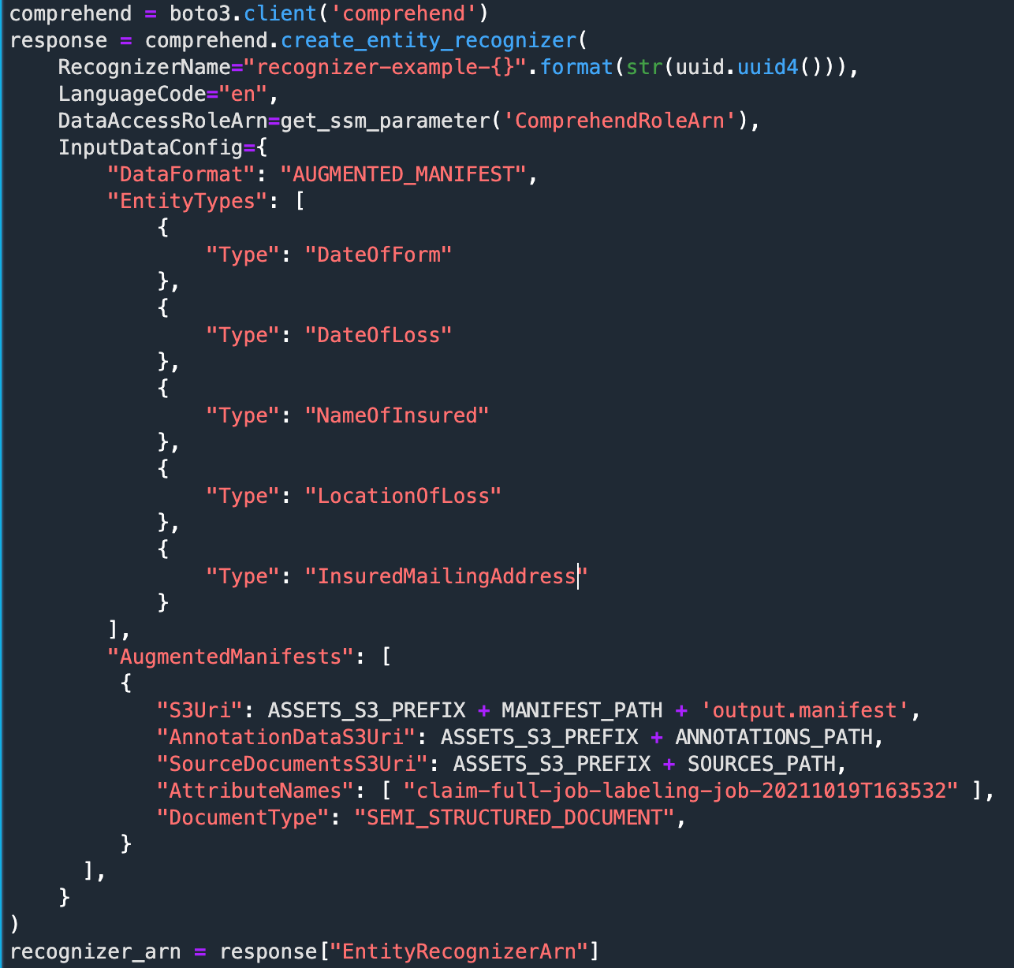
We create a recognizer to recognize all five types of entities. We could have used a subset of these entities if we preferred. You can use up to 25 entities.
For the details of each parameter, refer to create_entity_recognizer.
Depending on the size of the training set, training time can vary. For this dataset, training takes approximately 1 hour. To monitor the status of the training job, you can use the describe_entity_recognizer API.
Obtain evaluation metrics from the trained model
Amazon Comprehend provides model performance metrics for a trained model, which indicates how well the trained model is expected to make predictions using similar inputs. We can obtain both global precision and recall metrics as well as per-entity metrics. An accurate model has high precision and high recall. High precision means the model is usually correct when it indicates a particular label; high recall means that the model found most of the labels. F1 is a composite metric (harmonic mean) of these measures, and is therefore high when both components are high. For a detailed description of the metrics, see Custom Entity Recognizer Metrics.
When you provide the documents to the training job, Amazon Comprehend automatically separates them into a train and test set. When the model has reached TRAINED status, you can use the describe_entity_recognizer API again to obtain the evaluation metrics on the test set.
The following is an example of global metrics.
![]()
The following is an example of per-entity metrics.
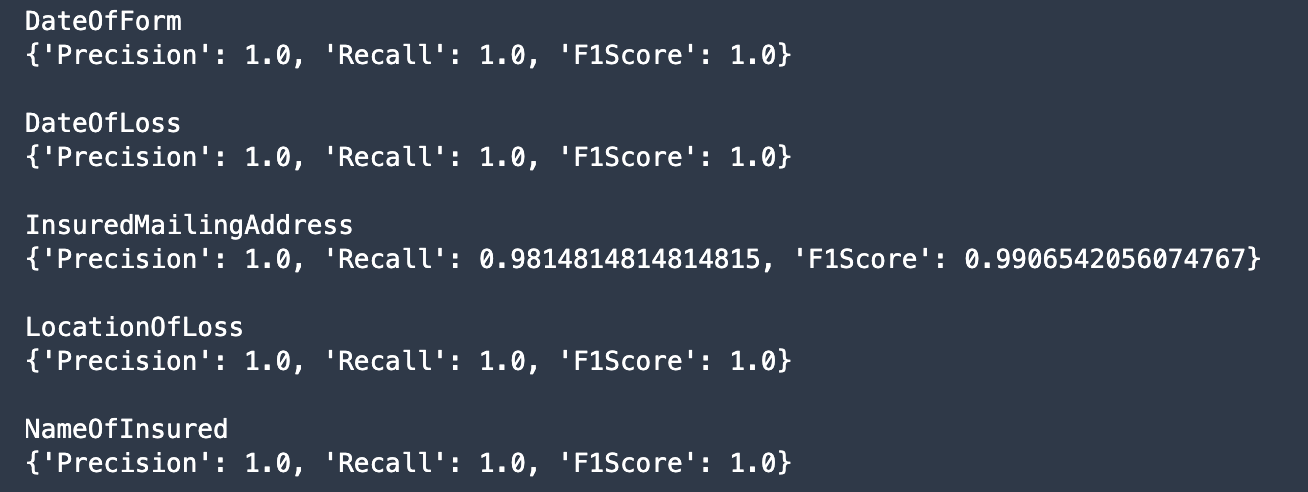
The high scores indicate that the model has learned well how to detect these entities.
Perform inference on an unseen document
Let’s run inference with our trained model on a document that was not part of the training procedure. We can use this asynchronous API for standard or custom NER. If using it for custom NER (as in this post), we must pass the ARN of the trained model.
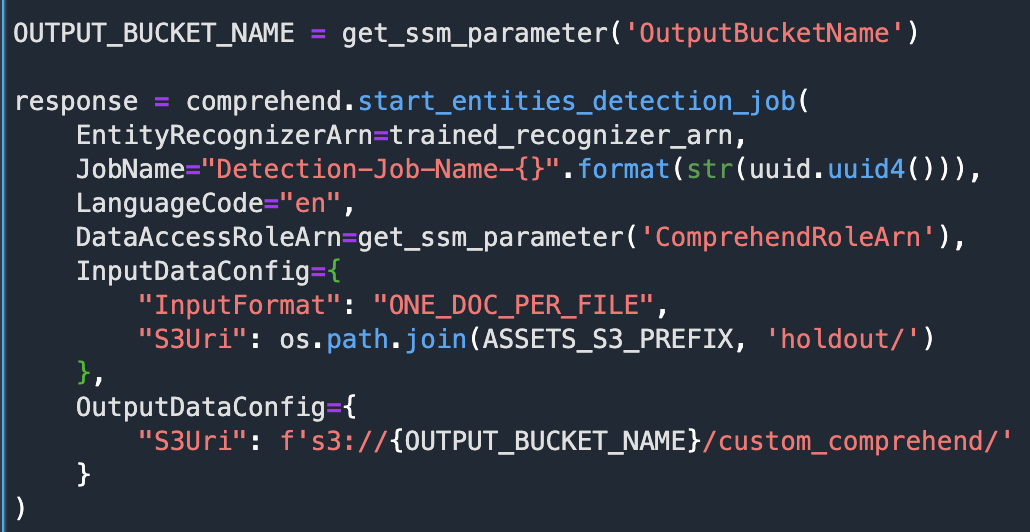
We can review the submitted job by printing the response.

We can format the output of the detection job with Pandas into a table. The Score value indicates the confidence level the model has about the entity.
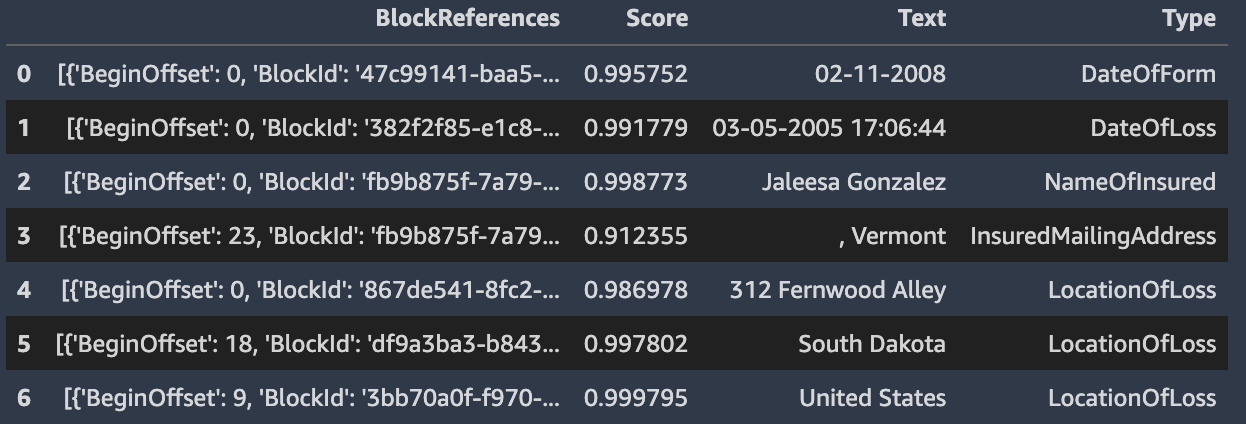
Finally, we can overlay the predictions on the unseen documents, which gives the result as shown at the top of this post.
Conclusion
In this post, you saw how to extract custom entities in their native PDF format using Amazon Comprehend. As next steps, consider diving deeper:
- Train your own recognizer using the accompanying notebook here. Remember to delete any resources when finished to avoid future charges.
- Set up your own custom annotation job to collect PDF annotations for your entities of interest. For more information, refer to Custom document annotation for extracting named entities in documents using Amazon Comprehend.
- Train a custom NER model on the Amazon Comprehend console. For more information, see Extract custom entities from documents in their native format with Amazon Comprehend.
About the Authors
 Joshua Levy is Senior Applied Scientist in the Amazon Machine Learning Solutions lab, where he helps customers design and build AI/ML solutions to solve key business problems.
Joshua Levy is Senior Applied Scientist in the Amazon Machine Learning Solutions lab, where he helps customers design and build AI/ML solutions to solve key business problems.
 Andrew Ang is a Machine Learning Engineer in the Amazon Machine Learning Solutions Lab, where he helps customers from a diverse spectrum of industries identify and build AI/ML solutions to solve their most pressing business problems. Outside of work he enjoys watching travel & food vlogs.
Andrew Ang is a Machine Learning Engineer in the Amazon Machine Learning Solutions Lab, where he helps customers from a diverse spectrum of industries identify and build AI/ML solutions to solve their most pressing business problems. Outside of work he enjoys watching travel & food vlogs.
 Alex Chirayath is a Software Engineer in the Amazon Machine Learning Solutions Lab focusing on building use case-based solutions that show customers how to unlock the power of AWS AI/ML services to solve real world business problems.
Alex Chirayath is a Software Engineer in the Amazon Machine Learning Solutions Lab focusing on building use case-based solutions that show customers how to unlock the power of AWS AI/ML services to solve real world business problems.
 Jennifer Zhu is an Applied Scientist from Amazon AI Machine Learning Solutions Lab. She works with AWS’s customers building AI/ML solutions for their high-priority business needs.
Jennifer Zhu is an Applied Scientist from Amazon AI Machine Learning Solutions Lab. She works with AWS’s customers building AI/ML solutions for their high-priority business needs.
 Niharika Jayanthi is a Front End Engineer in the Amazon Machine Learning Solutions Lab – Human in the Loop team. She helps create user experience solutions for Amazon SageMaker Ground Truth customers.
Niharika Jayanthi is a Front End Engineer in the Amazon Machine Learning Solutions Lab – Human in the Loop team. She helps create user experience solutions for Amazon SageMaker Ground Truth customers.
 Boris Aronchik is a Manager in Amazon AI Machine Learning Solutions Lab where he leads a team of ML Scientists and Engineers to help AWS customers realize business goals leveraging AI/ML solutions.
Boris Aronchik is a Manager in Amazon AI Machine Learning Solutions Lab where he leads a team of ML Scientists and Engineers to help AWS customers realize business goals leveraging AI/ML solutions.