Financial documents such as bank, loan, or mortgage statements are often formatted to be visually appealing and easy to read for the human eye. These same features can also make automated processing challenging at times. For instance, in the following sample statement, merging rows or columns in a table helps reduce information redundancy, but it can become difficult to write the code that identifies the repeating value and assign it to the corresponding elements.

In April 2022, Amazon Textract introduced a new capability of the table feature that automatically detects merged rows and columns as well as headers. Prior to this enhancement, for a similar document, the table’s output would have contained empty values for the Date column. Customers had to write custom code to detect the beginning of a new row and carry over the appropriate value.
This post walks you through a simple example of how to use the merged cells and headers features.
The new Amazon Textract table response structure
The response schema for the Amazon Textract API is now enhanced with two new structure types, as illustrated in the following diagram:
- A new block type called
MERGED_CELL - New cell entity types called
COLUMN_HEADERorROW_HEADER
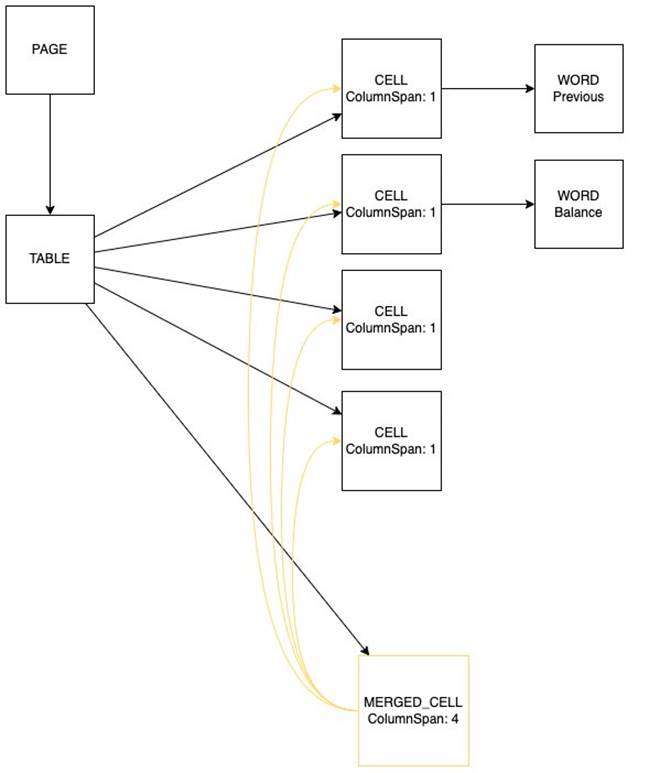
MERGED_CELL blocks are appended to the JSON document as any other CELL block. The MERGED_CELL blocks have a parent/child relationship with the CELL blocks they combine. This allows you to propagate the same cell value across multiple columns or rows even when not explicitly represented in the document. The MERGED_CELL block itself is then referenced from the TABLE block via a parent/child relationship.
Headers are flagged through a new entity type populated within the corresponding CELL block.
Using the new feature
Let’s try out the new feature on the sample statement presented earlier. The following code snippet calls Amazon Textract to extract tables out of the document, turn the output data into a Pandas DataFrame, and display its content.
We use the following modules in this example:
- amazon-textract-caller to invoke the Amazon Textract API on our behalf
- amazon-textract-response-parser to parse the response payload
- amazon-textract-prettyprinter to pretty-print tables
Let’s initialize the Boto3 session and invoke Amazon Textract with the sample statement as the input document:
Let’s pretty-print the response payload. As you can see, by default the date is not populated across all rows.
Then, we load the response into a document by using the Amazon Textract response parser module, and reorder the blocks by location:
Now let’s iterate through the tables’ content, and extract the data into a DataFrame:
The trp module has been improved to include two new capabilities, as highlighted in the preceding code’s comments:
- Fetch the header column names
- Expose merged cells’ repeated value
Displaying the DataFrame produces the following output.

We can now use multi-level indexing and reproduce the table’s initial structure:

For a complete version of the notebook presented in this post, visit the amazon-textract-code-samples GitHub repository.
Conclusion
Amazon Textract already helps you speed up document processing and reduce the number of manual tasks. The table’s new headers and merged cells features help you even further by reducing the need for custom or hard-coded logic. It can also help reduce postprocessing manual corrections.
For more information, please visit the Amazon Textract Response Objects documentation page. And if you are interested in learning more about another recently announced Textract feature, we highly recommend checking out Specify and extract information from documents using the new Queries feature in Amazon Textract.
About the Authors
 Narcisse Zekpa is a Solutions Architect based in Boston. He helps customers in the Northeast U.S. accelerate their adoption of the AWS Cloud, by providing architectural guidelines, design innovative, and scalable solutions. When Narcisse is not building, he enjoys spending time with his family, traveling, cooking, and playing basketball.
Narcisse Zekpa is a Solutions Architect based in Boston. He helps customers in the Northeast U.S. accelerate their adoption of the AWS Cloud, by providing architectural guidelines, design innovative, and scalable solutions. When Narcisse is not building, he enjoys spending time with his family, traveling, cooking, and playing basketball.
 Martin Schade is a Senior ML Product SA with the Amazon Textract team. He has over 20 years of experience with internet-related technologies, engineering, and architecting solutions. He joined AWS in 2014, first guiding some of the largest AWS customers on the most efficient and scalable use of AWS services, and later focused on AI/ML with a focus on computer vision. Currently, he’s obsessed with extracting information from documents.
Martin Schade is a Senior ML Product SA with the Amazon Textract team. He has over 20 years of experience with internet-related technologies, engineering, and architecting solutions. He joined AWS in 2014, first guiding some of the largest AWS customers on the most efficient and scalable use of AWS services, and later focused on AI/ML with a focus on computer vision. Currently, he’s obsessed with extracting information from documents.