In this post, we talk about how to split a machine learning (ML) dataset into train, test, and validation datasets with Amazon SageMaker Data Wrangler so you can easily split your datasets with minimal to no code.
Data used for ML is typically split into the following datasets:
- Training – Used to train an algorithm or ML model. The model iteratively uses the data and learns to provide the desired result.
- Validation – Introduces new data to the trained model. You can use a validation set to periodically measure model performance as training is happening, and also tune any hyperparameters of the model. However, validation datasets are optional.
- Test – Used on the final trained model to assess its performance on unseen data. This helps determine how well the model generalizes.
Data Wrangler is a capability of Amazon SageMaker that helps data scientists and data engineers quickly and easily prepare data for ML applications using a visual interface. It contains over 300 built-in data transformations so you can quickly normalize, transform, and combine features without having to write any code.
Today, we’re excited to announce a new data transformation to split datasets for ML use cases within Data Wrangler. This transformation splits your dataset into training, test, and optionally validation datasets without having to write any code.
Overview of the split data transformation
The split data transformation includes four commonly used techniques to split the data for training the model, validating the model, and testing the model:
- Random split – Splits data randomly into train, test, and, optionally validation datasets using the percentage specified for each dataset. It ensures that the distribution of the data is similar in all datasets. Choose this option when you don’t need to preserve the order of your input data. For example, consider a movie dataset where the dataset is sorted by genre and you’re predicting the genre of the movie. A random split on this dataset ensures that the distribution of the data includes all genres in all three datasets.
- Ordered split – Splits data in order, using the percentage specified for each dataset. An ordered split ensures that the data in each split is non-overlapping while preserving the order of the data. When training, we want to avoid past or future information leaking across datasets. The ordered split option prevents data leakage. For example, consider a scenario where you have customer engagement data for the first few months and you want to use this historical data to predict customer engagement in the next month. You can perform this split by providing an optional input column (numeric column). This operation uses the values of a numeric column to ensure that the data in each split doesn’t overlap while preserving the order. This helps avoid data leakage across splits. If no input column is provided, the order of the rows is used, so the data in each split still comes before the data in the next split. This is useful where the rows of the dataset are already ordered (for example, by date) and the model may need to be fit to earlier data and tested on later data.
- Stratified split – Splits the dataset so that each split is similar with respect to a column specifying different categories for your data, for example, size or country. This split ensures that the train, test, and validation datasets have the same proportions for each category as the input dataset. This is useful with classification problems where we’re trying to ensure that the train and test sets have approximately the same percentage of samples of each target class. Choose this option if you have imbalanced data across different categories and you need to have it balanced across split datasets.
- Split by key – Takes one or more columns as input (the key) and ensures that no combination of values across the input columns occurs in more than one of the splits (split by key). This is useful to avoid data leakage for unordered data. Choose this option if your data for key columns needs to be in the same split. For example, consider customer transactions split by customer ID; the split ensures that customer IDs don’t overlap across split datasets.
Solution overview
For this post, we demonstrate how to split data into train, test, and validation datasets using the four new split options in Data Wrangler. We use a hotel booking dataset available publicly on Kaggle, which has the year, month, and date that bookings were made, along with reservation statuses, cancellations, repeat customers, and other features.
Prerequisites
Before getting started, upload the dataset to an Amazon Simple Storage Service (S3) bucket, then import it into Data Wrangler. For instructions, refer to Import data from Amazon S3.
Random split
After we import the data into Data Wrangler, we start the transformation. We first demonstrate a random split.
- On the Data Wrangler console, choose the plus sign and choose Add transform.

- To add the split data transformation, choose Add step.

You’re redirected to the page where all transformations are displayed. - Scroll down the list and choose Split data.

The split data transformation has a drop-down menu that lists the available transformations to split your data, which include random, ordered, stratified, and split by key. By default, Randomized split is displayed. - Choose the default value Randomized split.
- In the Splits section, enter the name
Trainwith an 0.8 split percentage, andTestwith a 0.2 percentage. - Choose the plus sign to add an additional split.
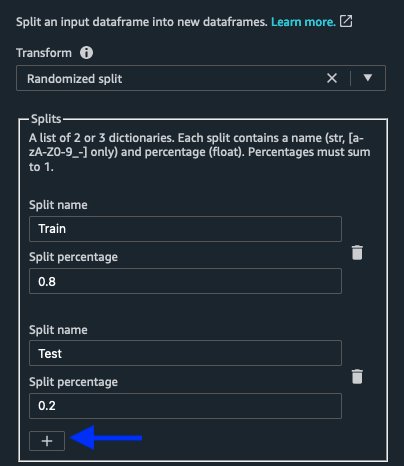
- Add the
Validationsplit with 0.2, and adjustTrainto 0.7 andTestto 0.1.
The split percentage can be any value you want, provided all three splits sum to 1 (100%).We can also specify optional fields like Error threshold and Random seed. We can achieve an exact split by setting the error threshold to 0. A smaller error threshold can lead to more processing time for splitting the data. This allows you to control the trade-off between time and accuracy on the operation. The Random seed option is for reproducibility. If not specified, Data Wrangler uses a default random seed value. We leave it blank for the purpose of this post. - To preview your data split, choose Preview.

The preview page displays the data split. You can choose Train, Test, or Validation on the drop-down menu to review the details of each split.
- When you’re satisfied with your data split, choose Add to add the transformation to your Data Wrangler flow.
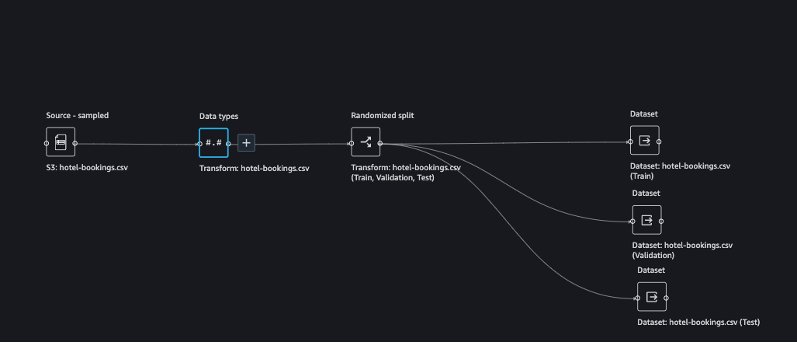
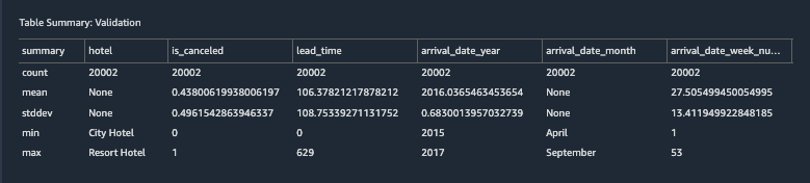
To analyze the train dataset, choose Add analysis.

You can perform a similar analysis on the validation and test datasets.

Ordered split
We now use the hotel bookings dataset to demonstrate an ordered split transformation. The hotel dataset contains rows ordered by date.
- Repeat the steps to add a split, and choose Ordered split on the drop-down menu.
- Specify your three splits and desired percentages.

- Preview your data and choose Add to add the transformation to the Data Wrangler flow.
- Use the Add analysis option to verify the splits.
Stratified split
In the hotel booking dataset, we have an is_cancelled column, which indicates whether the booking was cancelled or not. We want to use this column to split the data. A stratified split ensures that the train, test, and validation datasets have same percentage of samples of is_cancelled.
- Repeat the steps to add a transformation, and choose Stratified split.
- Specify your three splits and desired percentages.
- For Input column, choose is_canceled.

- Preview your data and choose Add to add the transformation to the Data Wrangler flow.
- Use the Add analysis option to verify the splits.
Split by key
The split by key transformation splits the data by the key or multiple keys we specify. This split is useful to avoid having the same data in the split datasets created during transformation and to avoid data leakage.
- Repeat the steps to add a transformation, and choose Split by key.
- Specify your three splits and desired percentages.
- For Key column, we can specify the columns to form the key. For this post, choose the following columns:
is_cancelledarrival_date_yeararrival_date_montharrival_date_week_number-
reservation_status

- Preview your data and choose Add to add the transformation to the Data Wrangler flow.
- Use the Add analysis option to verify the splits.

Considerations
The node labeled as Data types cannot be deleted. Deleting a split node deletes all its datasets and downstream datasets and its nodes.
Conclusion
In this post, we demonstrated how to split an input dataset into train, test, and validation datasets with Data Wrangler using the split techniques random, ordered, stratified, and split by key.
To learn more about using data flows with Data Wrangler, refer to Create and Use a Data Wrangler Flow. To get started with Data Wrangler, see Prepare ML Data with Amazon SageMaker Data Wrangler.
About the Authors
 Gopi Mudiyala is a Senior Technical Account Manager at AWS. He helps customers in the Financial Services Industry with their operations in AWS. As a machine learning specialist, Gopi works to support customers succeed in their ML journey.
Gopi Mudiyala is a Senior Technical Account Manager at AWS. He helps customers in the Financial Services Industry with their operations in AWS. As a machine learning specialist, Gopi works to support customers succeed in their ML journey.
 Patrick Lin is a Software Development Engineer with Amazon SageMaker Data Wrangler. He is committed to making Amazon SageMaker Data Wrangler the number one data preparation tool for productionized ML workflows. Outside of work, you can find him reading, listening to music, having conversations with friends, and serving at his church.
Patrick Lin is a Software Development Engineer with Amazon SageMaker Data Wrangler. He is committed to making Amazon SageMaker Data Wrangler the number one data preparation tool for productionized ML workflows. Outside of work, you can find him reading, listening to music, having conversations with friends, and serving at his church.
 Xiyi Li is a Front End Engineer at Amazon SageMaker Data Wrangler. She helps support Amazon SageMaker Data Wrangler and is passionate about building products that provide a great user experience. Outside of work, she enjoys hiking and listening to classical music.
Xiyi Li is a Front End Engineer at Amazon SageMaker Data Wrangler. She helps support Amazon SageMaker Data Wrangler and is passionate about building products that provide a great user experience. Outside of work, she enjoys hiking and listening to classical music.
 Vishaal Kapoor is a Senior Applied Scientist with AWS AI. He is passionate about helping customers understand their data in Data Wrangler. In his spare time, he mountain bikes, snowboards, and spends time with his family.
Vishaal Kapoor is a Senior Applied Scientist with AWS AI. He is passionate about helping customers understand their data in Data Wrangler. In his spare time, he mountain bikes, snowboards, and spends time with his family.