This is a guest blog post by Danny Brock, Rajeev Govindan and Krishnaram Kenthapadi at Fiddler AI.
Your Amazon SageMaker models are live. They’re handling millions of inferences each day and driving better business outcomes for your company. They’re performing exactly as well as the day they were launched.
Er, wait. Are they? Maybe. Maybe not.
Without enterprise-class model monitoring, your models may be decaying in silence. Your machine learning (ML) teams may never know that these models have actually morphed from miracles of revenue generation to liabilities making incorrect decisions that cost your company time and money.
Don’t fret. The solution is closer than you think.
Fiddler, an enterprise-class Model Performance Management solution available on the AWS Marketplace, offers model monitoring and explainable AI to help ML teams inspect and address a comprehensive range of model issues. Through model monitoring, model explainability, analytics, and bias detection, Fiddler provides your company with an easy-to-use single pane of glass to ensure your models are behaving as they should. And if they’re not, Fiddler also provides features that allow you to inspect your models to find the underlying root causes of performance decay.
This post shows how your MLOps team can improve data scientist productivity and reduce time to detect issues for your models deployed in SageMaker by integrating with the Fiddler Model Performance Management Platform in a few simple steps.
Solution overview
The following reference architecture highlights the primary points of integration. Fiddler exists as a “sidecar” to your existing SageMaker ML workflow.
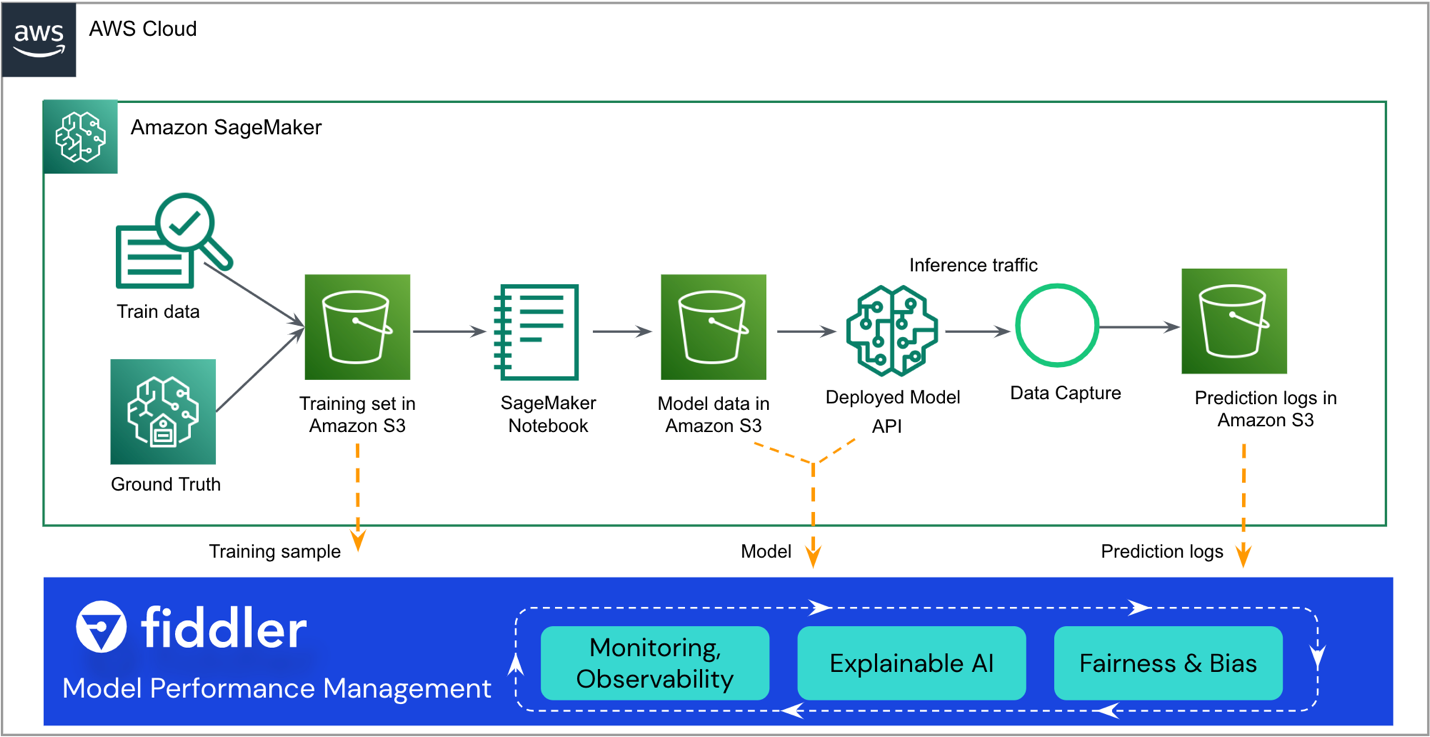
The remainder of this post walks you through the steps to integrate your SageMaker model with Fiddler’s Model Performance Management Platform:
- Ensure your model has data capture enabled.
- Create a Fiddler trial environment.
- Register information about your model in your Fiddler environment.
- Create an AWS Lambda function to publish SageMaker inferences to Fiddler.
- Explore Fiddler’s monitoring capabilities in your Fiddler trial environment.
Prerequisites
This post assumes that you have set up SageMaker and deployed a model endpoint. To learn how to configure SageMaker for model serving, refer to Deploy Models for Inference. Some examples are also available on the GitHub repo.
Ensure your model has data capture enabled
On the SageMaker console, navigate to your model’s serving endpoint and ensure you have enabled data capture into an Amazon Simple Storage Service (Amazon S3) bucket. This stores the inferences (requests and responses) your model makes each day as JSON lines files (.jsonl) in Amazon S3.

Create a Fiddler trial environment
From the fiddler.ai website, you can request a free trial. After filling out a quick form, Fiddler will contact you to understand the specifics of your model performance management needs and will have a trial environment ready for you in a few hours. You can expect a dedicated environment like https://yourcompany.try.fiddler.ai.

Register information about your model in your Fiddler environment
Before you can begin publishing events from your SageMaker hosted model into Fiddler, you need to create a project within your Fiddler trial environment and provide Fiddler details about your model through a step called model registration. If you want to use a preconfigured notebook from within Amazon SageMaker Studio rather than copy and paste the following code snippets, you can reference the Fiddler quickstart notebook on GitHub. Studio provides a single web-based visual interface where you can perform all ML development steps.
First, you must install the Fiddler Python client in your SageMaker notebook and instantiate the Fiddler client. You can get the AUTH_TOKEN from the Settings page in your Fiddler trial environment.
Next, create a project within your Fiddler trial environment:
Now upload your training dataset. The notebook also provides a sample dataset to run Fiddler’s explainability algorithms and as a baseline for monitoring metrics. The dataset is also used to generate the schema for this model in Fiddler.
Lastly, before you can start publishing inferences to Fiddler for monitoring, root cause analysis, and explanations, you need to register your model. Let’s first create a model_info object that contains the metadata about your model:
Then you can register the model using your new model_info object:
Great! Now you can publish some events to Fiddler in order to observe the model’s performance.
Create a Lambda function to publish SageMaker inferences to Fiddler
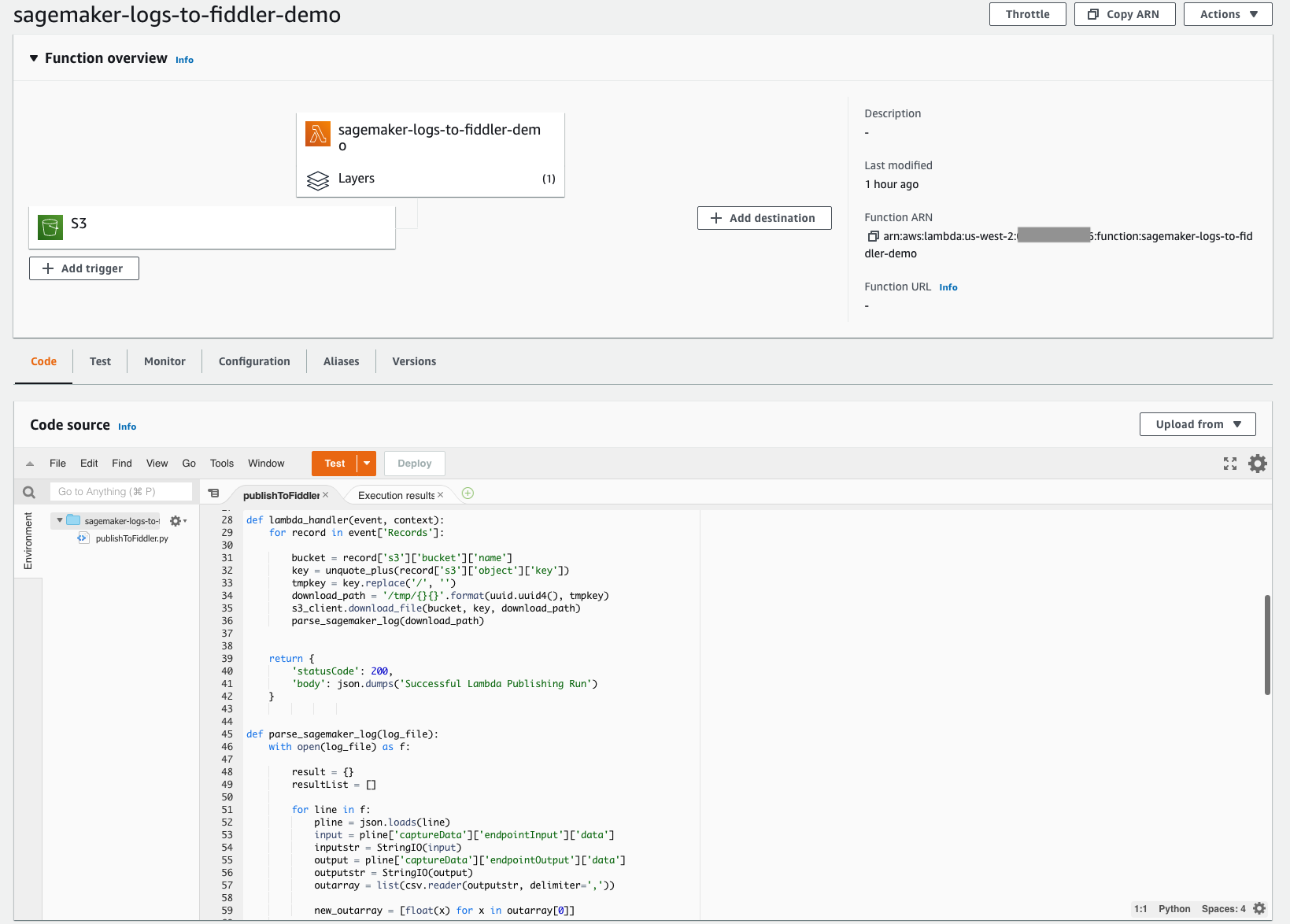
With the simple-to-deploy serverless architecture of Lambda, you can quickly build the mechanism required to move your inferences from the S3 bucket you set up earlier into your newly provisioned Fiddler trial environment. This Lambda function is responsible for opening any new JSONL event log files in your model’s S3 bucket, parsing and formatting the JSONL content into a dataframe, and then publishing that dataframe of events to your Fiddler trial environment. The following screenshot shows the code details of our function.
The Lambda function needs to be configured to trigger off of newly created files in your S3 bucket. The following tutorial guides you through creating an Amazon EventBridge trigger that invokes the Lambda function whenever a file is uploaded to Amazon S3. The following screenshot shows our function’s trigger configuration. This makes it simple to ensure that any time your model makes new inferences, those events stored in Amazon S3 are loaded into Fiddler to drive the model observability your company needs.
To simplify this further, the code for this Lambda function is publicly available from Fiddler’s documentation site. This code example currently works for binary classification models with structured inputs. If you have model types with different features or tasks, please contact Fiddler for assistance with minor changes to the code.
The Lambda function needs to make reference to the Fiddler Python client. Fiddler has created a publicly available Lambda layer that you can reference to ensure that the import fiddler as fdl step works seamlessly. You can reference this layer via an ARN in the us-west-2 Region: arn:aws:lambda:us-west-2:079310353266:layer:fiddler-client-0814:1, as shown in the following screenshot.

You also need to specify Lambda environment variables so the Lambda function knows how to connect to your Fiddler trial environment, and what the inputs and outputs are within the .jsonl files being captured by your model. The following screenshot shows a list of the required environment variables, which are also on Fiddler’s documentation site. Update the values for the environment variables to match your model and dataset.

Explore Fiddler’s monitoring capabilities in your Fiddler trial environment
You’ve done it! With your baseline data, model, and traffic connected, you can now explain data drift, outliers, model bias, data issues, and performance blips, and share dashboards with others. Complete your journey by watching a demo about the model performance management capabilities you have introduced to your company.
The example screenshots below provide a glimpse of model insights like drift, outlier detection, local point explanations, and model analytics that will be found in your Fiddler trial environment.

Conclusion
This post highlighted the need for enterprise-class model monitoring and showed how you can integrate your models deployed in SageMaker with the Fiddler Model Performance Management Platform in just a few steps. Fiddler offers functionality for model monitoring, explainable AI, bias detection, and root cause analysis, and is available on the AWS Marketplace. By providing your MLOps team with an easy-to-use single pane of glass to ensure your models are behaving as expected and to identify the underlying root causes of performance degradation, Fiddler can help improve data scientist productivity and reduce time to detect and resolve issues.
If you would like to learn more about Fiddler please visit fiddler.ai or if you would prefer to set up a personalized demo and technical discussion email sales@fiddler.ai.
About the Authors
 Danny Brock is a Sr Solutions Engineer at Fiddler AI. Danny is long tenured in the analytics and ML space, running presales and post-sales teams for startups like Endeca and Incorta. He founded his own big data analytics consulting company, Branchbird, in 2012.
Danny Brock is a Sr Solutions Engineer at Fiddler AI. Danny is long tenured in the analytics and ML space, running presales and post-sales teams for startups like Endeca and Incorta. He founded his own big data analytics consulting company, Branchbird, in 2012.
 Rajeev Govindan is a Sr Solutions Engineer at Fiddler AI. Rajeev has extensive experience in sales engineering and software development at several enterprise companies, including AppDynamics.
Rajeev Govindan is a Sr Solutions Engineer at Fiddler AI. Rajeev has extensive experience in sales engineering and software development at several enterprise companies, including AppDynamics.
 Krishnaram Kenthapadi is the Chief Scientist of Fiddler AI. Previously, he was a Principal Scientist at Amazon AWS AI, where he led the fairness, explainability, privacy, and model understanding initiatives in the Amazon AI platform, and prior to that, he held roles at LinkedIn AI and Microsoft Research. Krishnaram received his PhD in Computer Science from Stanford University in 2006.
Krishnaram Kenthapadi is the Chief Scientist of Fiddler AI. Previously, he was a Principal Scientist at Amazon AWS AI, where he led the fairness, explainability, privacy, and model understanding initiatives in the Amazon AI platform, and prior to that, he held roles at LinkedIn AI and Microsoft Research. Krishnaram received his PhD in Computer Science from Stanford University in 2006.