Posted by Artsiom Ablavatski and Marat Dukhan, Software Engineers, Google Research 
On-device inference of neural networks enables a variety of real-time applications, like pose estimation and background blur, in a low-latency and privacy-conscious way. Using ML inference frameworks like TensorFlow Lite with XNNPACK ML acceleration library, engineers optimize their models to run on a variety of devices by finding a sweet spot between model size, inference speed and the quality of the predictions.
One way to optimize a model is through use of sparse neural networks [1, 2, 3], which have a significant fraction of their weights set to zero. In general, this is a desirable quality as it not only reduces the model size via compression, but also makes it possible to skip a significant fraction of multiply-add operations, thereby speeding up inference. Further, it is possible to increase the number of parameters in a model and then sparsify it to match the quality of the original model, while still benefiting from the accelerated inference. However, the use of this technique remains limited in production largely due to a lack of tools to sparsify popular convolutional architectures as well as insufficient support for running these operations on-device.
Today we announce the release of a set of new features for the XNNPACK acceleration library and TensorFlow Lite that enable efficient inference of sparse networks, along with guidelines on how to sparsify neural networks, with the goal of helping researchers develop their own sparse on-device models. Developed in collaboration with DeepMind, these tools power a new generation of live perception experiences, including hand tracking in MediaPipe and background features in Google Meet, accelerating inference speed from 1.2 to 2.4 times, while reducing the model size by half. In this post, we provide a technical overview of sparse neural networks — from inducing sparsity during training to on-device deployment — and offer some ideas on how researchers might create their own sparse models.
 |
| Comparison of the processing time for the dense (left) and sparse (right) models of the same quality for Google Meet background features. For readability, the processing time shown is the moving average across 100 frames. |
Sparsifying a Neural Network
Many modern deep learning architectures, like MobileNet and EfficientNetLite, are primarily composed of depthwise convolutions with a small spatial kernel and 1×1 convolutions that linearly combine features from the input image. While such architectures have a number of potential targets for sparsification, including the full 2D convolutions that frequently occur at the beginning of many networks or the depthwise convolutions, it is the 1×1 convolutions that are the most expensive operators as measured by inference time. Because they account for over 65% of the total compute, they are an optimal target for sparsification.
| Architecture | Inference Time |
| MobileNet | 85% |
| MobileNetV2 | 71% |
| MobileNetV3 | 71% |
| EfficientNet-Lite | 66% |
| Comparison of inference time dedicated to 1×1 convolutions in % for modern mobile architectures. |
In modern on-device inference engines, like XNNPACK, the implementation of 1×1 convolutions as well as other operations in the deep learning models rely on the HWC tensor layout, in which the tensor dimensions correspond to the height, width, and channel (e.g., red, green or blue) of the input image. This tensor configuration allows the inference engine to process the channels corresponding to each spatial location (i.e., each pixel of an image) in parallel. However, this ordering of the tensor is not a good fit for sparse inference because it sets the channel as the innermost dimension of the tensor and makes it more computationally expensive to access.
Our updates to XNNPACK enable it to detect if a model is sparse. If so, it switches from its standard dense inference mode to sparse inference mode, in which it employs a CHW (channel, height, width) tensor layout. This reordering of the tensor allows for an accelerated implementation of the sparse 1×1 convolution kernel for two reasons: 1) entire spatial slices of the tensor can be skipped when the corresponding channel weight is zero following a single condition check, instead of a per-pixel test; and 2) when the channel weight is non-zero, the computation can be made more efficient by loading neighbouring pixels into the same memory unit. This enables us to process multiple pixels simultaneously, while also performing each operation in parallel across several threads. Together these changes result in a speed-up of 1.8x to 2.3x when at least 80% of the weights are zero.
In order to avoid converting back and forth between the CHW tensor layout that is optimal for sparse inference and the standard HWC tensor layout after each operation, XNNPACK provides efficient implementations of several CNN operators in CHW layout.
Guidelines for Training Sparse Neural Networks
To create a sparse neural network, the guidelines included in this release suggest one start with a dense version and then gradually set a fraction of its weights to zero during training. This process is called pruning. Of the many available techniques for pruning, we recommend using magnitude pruning (available in the TF Model Optimization Toolkit) or the recently introduced RigL method. With a modest increase in training time, both of these can successfully sparsify deep learning models without degrading their quality. The resulting sparse models can be stored efficiently in a compressed format that reduces the size by a factor of two compared to their dense equivalent.
The quality of sparse networks is influenced by several hyperparameters, including training time, learning rate and schedules for pruning. The TF Pruning API provides an excellent example of how to select these, as well as some tips for training such models. We recommend running hyperparameter searches to find the sweet spot for your application.
Applications
We demonstrate that it is possible to sparsify classification tasks, dense segmentation (e.g., Meet background blur) and regression problems (MediaPipe Hands), which provides tangible benefits to users. For example, in the case of Google Meet, sparsification lowered the inference time of the model by 30%, which provided access to higher quality models for more users.
 |
| Model size comparisons for the dense and sparse models in Mb. The models have been stored in 16- and 32-bit floating-point formats. |
The approach to sparsity described here works best with architectures based on inverted residual blocks, such as MobileNetV2, MobileNetV3 and EfficientNetLite. The degree of sparsity in a network influences both inference speed and quality. Starting from a dense network of a fixed capacity, we found modest performance gains even at 30% sparsity. With increased sparsity, the quality of the model remains relatively close to the dense baseline until reaching 70% sparsity, beyond which there is a more pronounced drop in accuracy. However, one can compensate for the reduced accuracy at 70% sparsity by increasing the size of the base network by 20%, which results in faster inference times without degrading the quality of the model. No further changes are required to run the sparsified models, because XNNPACK can recognize and automatically enable sparse inference.
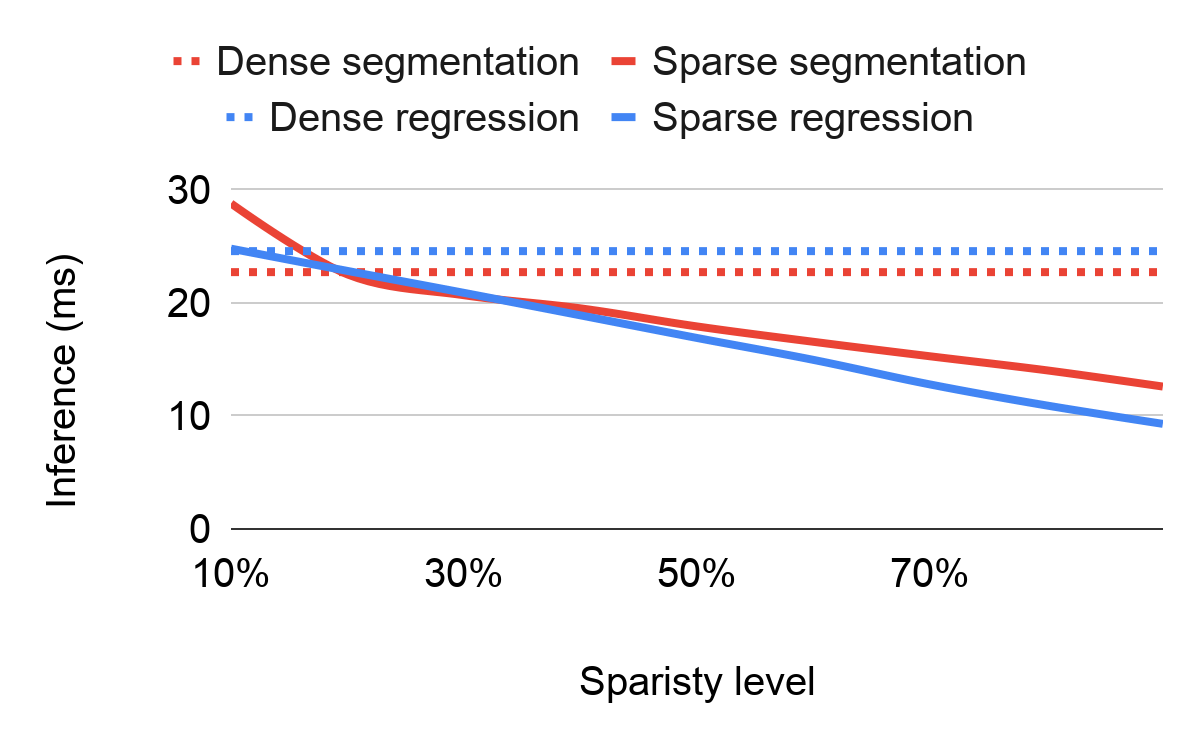 |
 |
| Ablation studies of different sparsity levels with respect to inference time (the smaller the better) and the quality measured by the Intersection over Union (IoU) for predicted segmentation mask. |
Sparsity as Automatic Alternative to Distillation
Background blur in Google Meet uses a segmentation model based on a modified MobileNetV3 backbone with attention blocks. We were able to speed up the model by 30% by applying a 70% sparsification, while preserving the quality of the foreground mask. We examined the predictions of the sparse and dense models on images from 17 geographic subregions, finding no significant difference, and released the details in the associated model card.
Similarly, MediaPipe Hands predicts hand landmarks in real-time on mobile and the web using a model based on the EfficientNetLite backbone. This backbone model was manually distilled from the large dense model, which is a computationally expensive, iterative process. Using the sparse version of the dense model instead of distilled one, we were able to maintain the same inference speed but without the labor intensive process of distilling from a dense model. Compared with the dense model the sparse model improved the inference by a factor of two, achieving the identical landmark quality as the distilled model. In a sense, sparsification can be thought of as an automatic approach to unstructured model distillation, which can improve model performance without extensive manual effort. We evaluated the sparse model on the geodiverse dataset and made the model card publicly available.
 |
| Comparison of execution time for the dense (left), distilled (middle) and sparse (right) models of the same quality. Processing time of the dense model is 2x larger than sparse or distilled models. The distilled model is taken from the official MediPipe solution. The dense and sparse web demos are publicly available. |
Future work
We find sparsification to be a simple yet powerful technique for improving CPU inference of neural networks. Sparse inference allows engineers to run larger models without incurring a significant performance or size overhead and offers a promising new direction for research. We are continuing to extend XNNPACK with wider support for operations in CHW layout and are exploring how it might be combined with other optimization techniques like quantization. We are excited to see what you might build with this technology!
Acknowledgments
Special thanks to all who worked on this project: Karthik Raveendran, Erich Elsen, Tingbo Hou, Trevor Gale, Siargey Pisarchyk, Yury Kartynnik, Yunlu Li, Utku Evci, Matsvei Zhdanovich, Sebastian Jansson, Stéphane Hulaud, Michael Hays, Juhyun Lee, Fan Zhang, Chuo-Ling Chang, Gregory Karpiak, Tyler Mullen, Jiuqiang Tang, Ming Guang Yong, Igor Kibalchich, and Matthias Grundmann.
