On November 30, 2021, we announced the general availability of Amazon SageMaker Canvas, a visual point-and-click interface that enables business analysts to generate highly accurate machine learning (ML) predictions without having to write a single line of code. With Canvas, you can take ML mainstream throughout your organization so business analysts without data science or ML experience can use accurate ML predictions to make data-driven decisions.
ML is becoming ubiquitous in organizations across industries to gather valuable business insights using predictions from existing data quickly and accurately. The key to scaling the use of ML is making it more accessible. This means empowering business analysts to use ML on their own, without depending on data science teams. Canvas helps business analysts apply ML to common business problems without having to know the details such as algorithm types, training parameters, or ensemble logic. Today, customers are using Canvas to address a wide range of use cases across verticals including churn detection, sales conversion, and time series forecasting.
In this post, we discuss key Canvas capabilities.
Get started with Canvas
Canvas offers an interactive tour to help you navigate through the visual interface, starting with importing data from the cloud or on-premises sources. Getting started with Canvas is quick; we offer sample datasets for multiple use cases, including predicting customer churn, estimating loan default probabilities, forecasting demand, and predicting supply chain delivery times. These datasets cover all the use cases currently supported by Canvas, including binary classification, multi-class classification, regression, and time series forecasting. To learn more about navigating Canvas and using the sample datasets, see Amazon SageMaker Canvas accelerates onboarding with new interactive product tours and sample datasets.
Exploratory data analysis
After you import your data, Canvas allows you to explore and analyze it, before building predictive models. You can preview your imported data and visualize the distribution of different features. You can then choose to transform your data to make it suitable to address your problem. For example, you may choose to drop columns, extract date and time, impute missing values, or replace outliers with standard or custom values. These activities are recorded in a model recipe, which is a series of steps towards data preparation. This recipe is maintained throughout the lifecycle of a particular ML model from data preparation to generating predictions. See Amazon SageMaker Canvas expands capabilities to better prepare and analyze data for machine learning to learn more about preparing and analyzing data within Canvas.

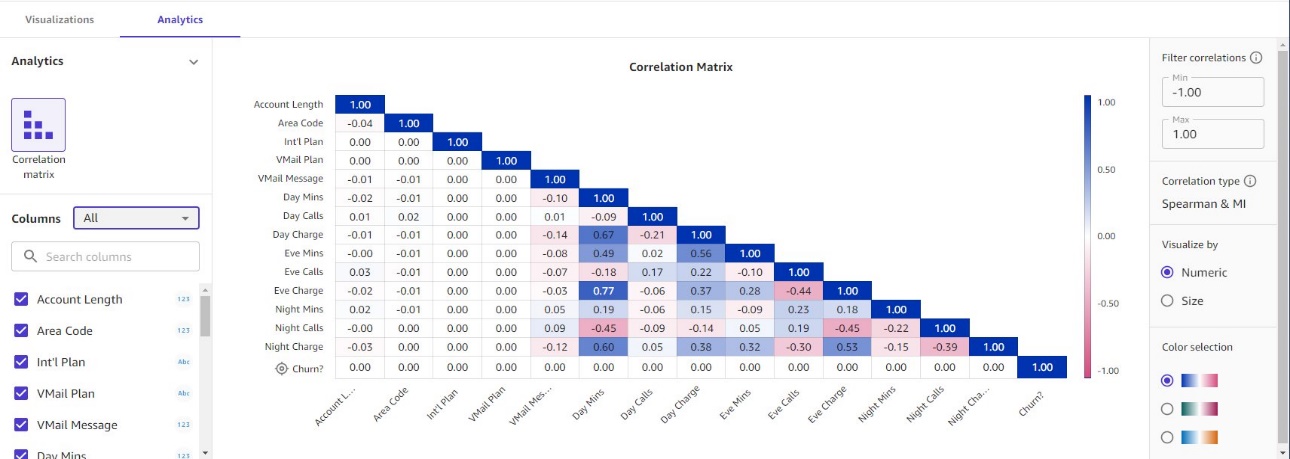
Visualize your data
Canvas also offers the ability to define and create new features in your data through mathematical operators and logical functions. You can visualize and explore your data through box plots, bar graphs, and scatterplots by dragging and dropping features directly on charts. In addition, Canvas provides correlation matrices for numerical and categorical variables to understand the relationships between features in your data. This information can be used to refine your input data and drive more accurate models. For more details on data analysis capabilities in Canvas, see Use Amazon SageMaker Canvas for exploratory data analysis. To learn more about mathematical functions and operators in Canvas, see Amazon SageMaker Canvas supports mathematical functions and operators for richer data exploration.
After you prepare and explore your data, Canvas gives you an option to validate your datasets so you can proactively check for data quality issues. Canvas validates the data on your behalf and surfaces issues such as missing values in any row or column and too many unique labels in the target column compared to the number of rows. In addition, Canvas provides you with options to fix these issues before you build your ML model. For a deeper dive into data validation capabilities, refer to Identifying and avoiding common data issues while building no code ML models with Amazon SageMaker Canvas.
Build ML models
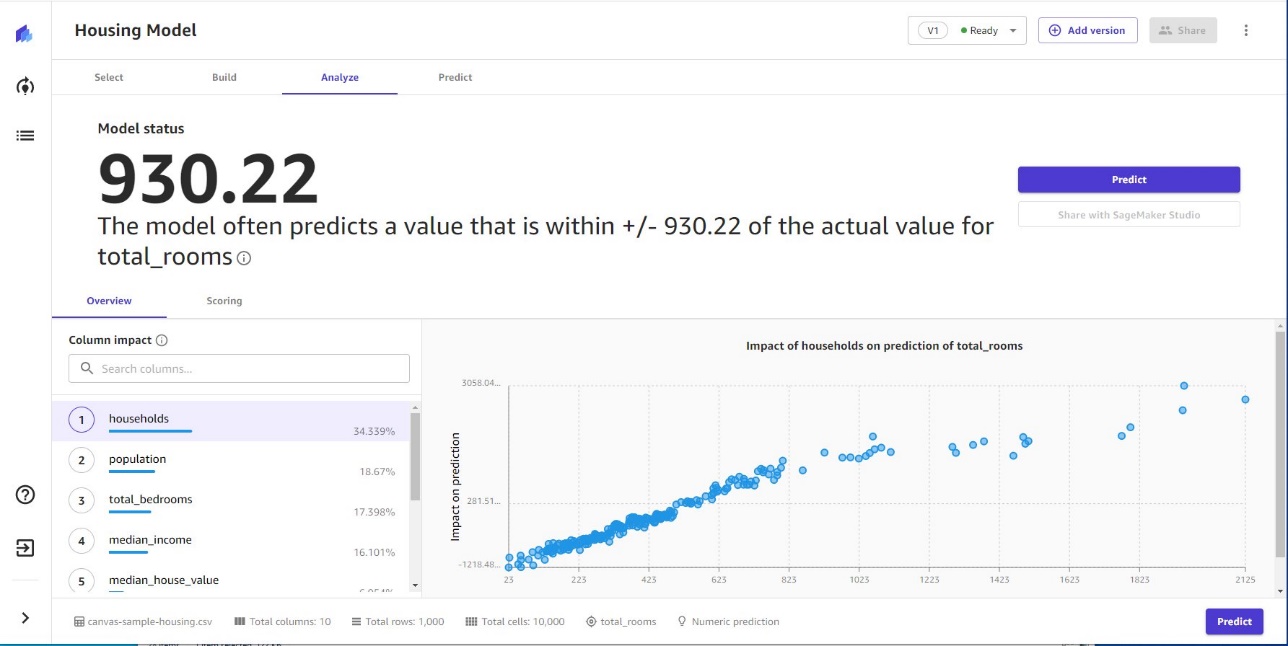
The first step towards building ML models in Canvas is to define the target column for the problem. For example, you could choose the total number of rooms as the target column to determine home prices in a housing model. Alternatively, you could use churn as the target column to determine the probability of losing customers under different conditions. After you select the target column, Canvas automatically determines the type of problem for the model to be built.
Prior to building an ML model, you can get directional insights into the model’s estimated accuracy and how each feature influenced results by running a preview analysis. Based on these insights, you can further prepare, analyze, or explore your data to get the desired accuracy for model predictions.
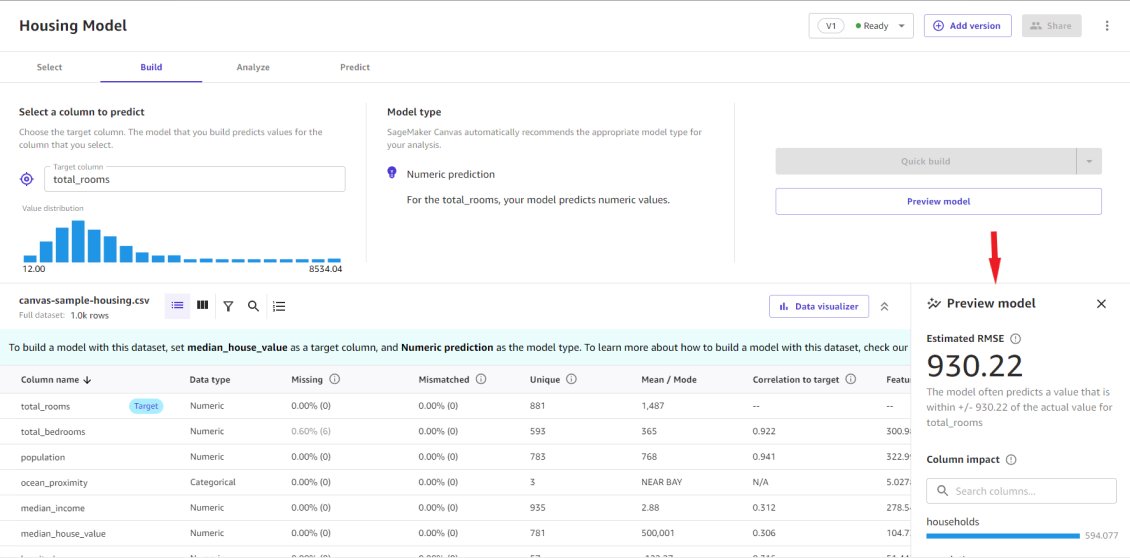
Canvas offers two methods to train ML models: Quick build and Standard build. Both methods deliver a fully trained ML model with complete transparency to understand the importance of each feature towards the model outcome. Quick build focuses on speed and experimentation, whereas standard build focuses on the highest levels of accuracy by going through multiple iterations of data preprocessing, choosing the right algorithm, exploring the hyperparameter space, and generating multiple candidate models before selecting the best performing model. This process is done behind the scenes by Canvas without the need to write code.
New performance improvements deliver up to three times faster ML model training time, enabling rapid prototyping and faster time-to-value for business outcomes. To learn more, see Amazon SageMaker Canvas announces up to 3x faster ML model training time.
Model analysis
After you build the model, Canvas provides detailed model accuracy metrics and feature explainability.
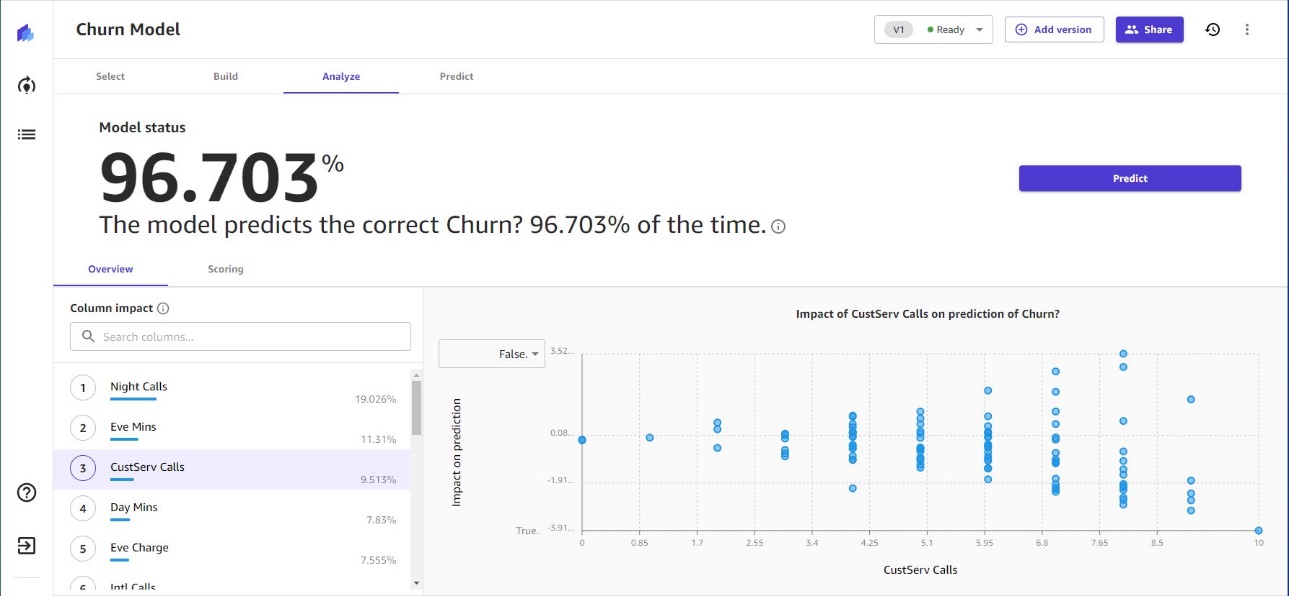
Canvas also presents a Sankey chart depicting the flow of the data from one value into the other, including false positives and false negatives.
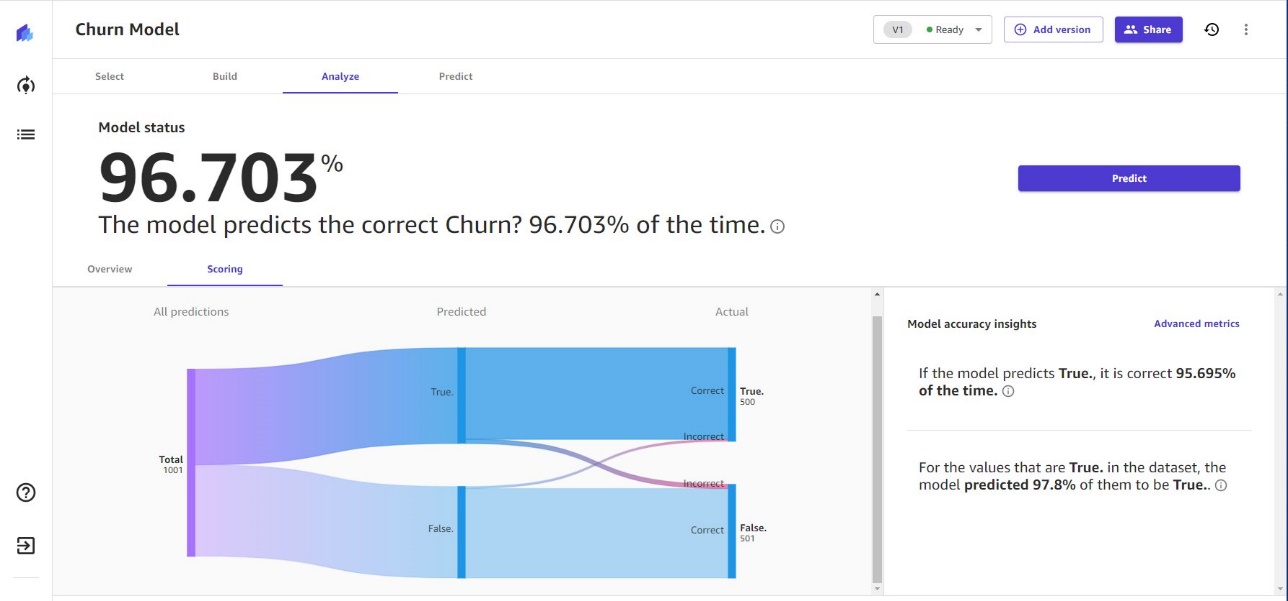
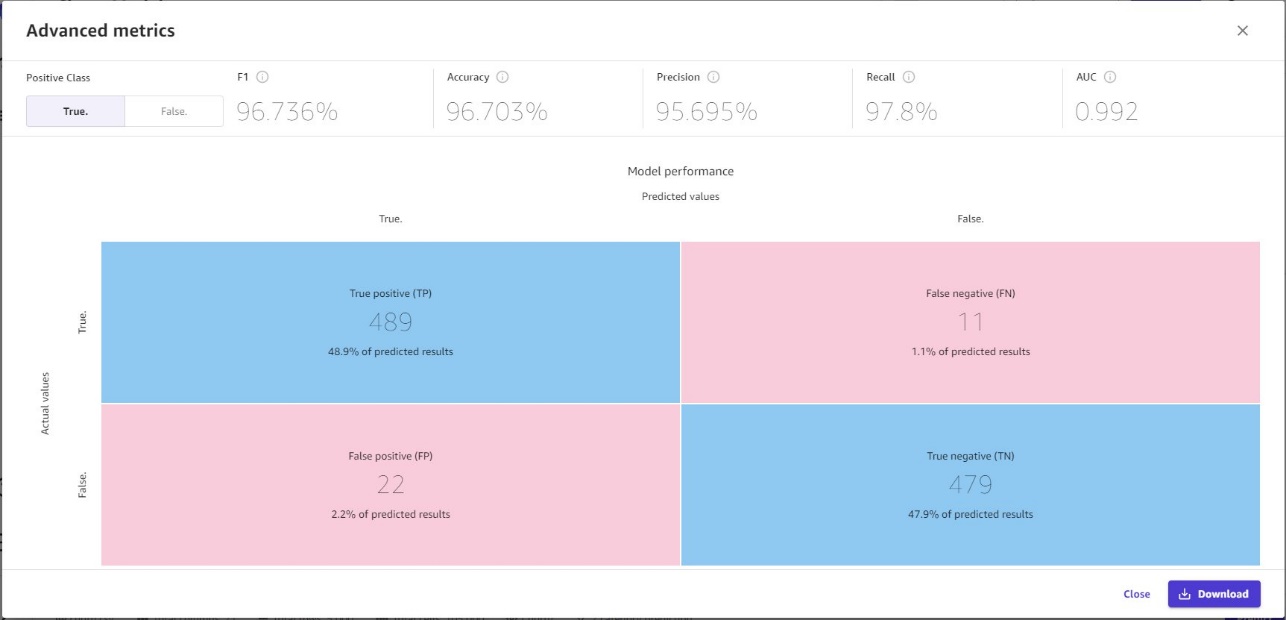
For users interested in analyzing more advanced metrics, Canvas provides F1 scores that combine precision and recall, an accuracy metric quantifying how many times the model made a correct prediction across the entire dataset, and the Area Under the Curve (AUC), which measures how well the model separates the categories in the dataset.
Model predictions
With Canvas, you can run real-time predictions on the trained model with interactive what-if analyses by analyzing the impact of different feature values on the model accuracy.
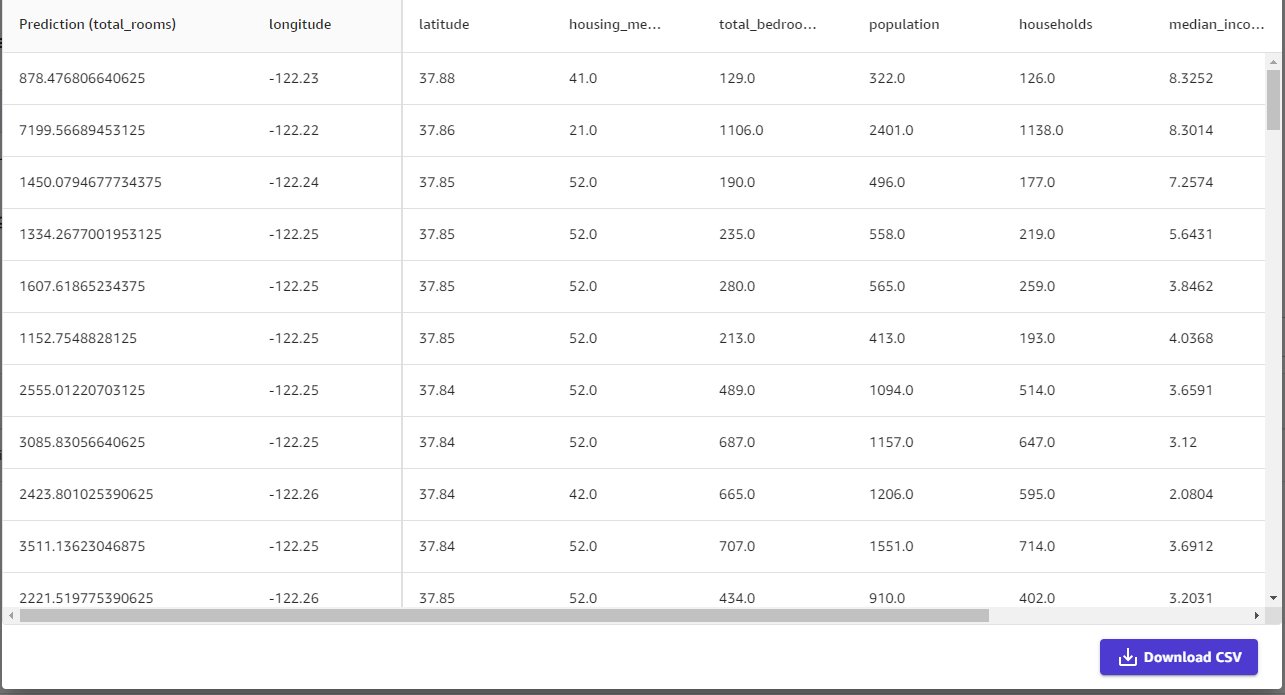
Furthermore, you can run batch predictions on any validation dataset as a whole. These predictions can be previewed and downloaded for use with downstream applications.
Sharing and collaboration
Canvas allows you to continue the ML journey by sharing your models with your data science teams for review, feedback, and updates. You can share your models with other users using Amazon SageMaker Studio, a fully integrated development environment (IDE) for ML. Studio users can review the model and, if needed, update data transformations, retrain the model, and share back the updated version of the model with Canvas users who can then use it to generate predictions.
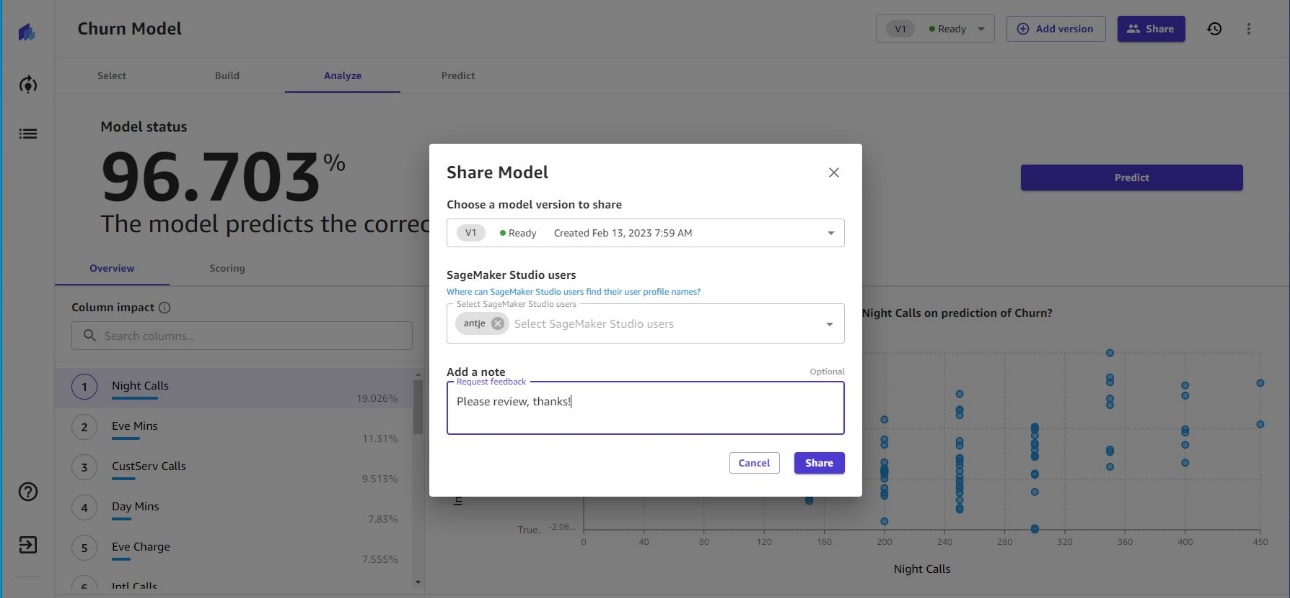
In addition, data scientists can share models built outside of Amazon SageMaker with Canvas users, removing the heavy lifting to build a separate tool or user interface to share models between different teams. With the bring your own model (BYOM) approach, you can now use ML models built by your data science teams in other environments and generate predictions within minutes directly in Canvas. This seamless collaboration between business and technical teams helps democratize ML across the organization by bringing transparency to ML models and accelerating ML deployments. To learn more about sharing and collaboration between business and technical teams using Canvas, see New – Bring ML Models Built Anywhere into Amazon SageMaker Canvas and Generate Predictions.
Conclusion
Get started today with Canvas and take advantage of ML to achieve your business outcomes without writing a line of code. Learn more from the interactive tutorial or MOOC course on Coursera. Happy innovating!
About the author
 Shyam Srinivasan is on the AWS low-code/no-code ML product team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends.
Shyam Srinivasan is on the AWS low-code/no-code ML product team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends.