Posted by Joel Shor, Software Engineer, Google Research and Sercan Arik, Research Scientist, Google Research, Cloud AI Team
Over the past 20 months, the COVID-19 pandemic has had a profound impact on daily life, presented logistical challenges for businesses planning for supply and demand, and created difficulties for governments and organizations working to support communities with timely public health responses. While there have been well-studied epidemiology models that can help predict COVID-19 cases and deaths to help with these challenges, this pandemic has generated an unprecedented amount of real-time publicly-available data, which makes it possible to use more advanced machine learning techniques in order to improve results.
In “A prospective evaluation of AI-augmented epidemiology to forecast COVID-19 in the USA and Japan“, accepted to npj Digital Medicine, we continued our previous work [1, 2, 3, 4] and proposed a framework designed to simulate the effect of certain policy changes on COVID-19 deaths and cases, such as school closings or a state-of-emergency at a US-state, US-county, and Japan-prefecture level, using only publicly-available data. We conducted a 2-month prospective assessment of our public forecasts, during which our US model tied or outperformed all other 33 models on COVID19 Forecast Hub. We also released a fairness analysis of the performance on protected sub-groups in the US and Japan. Like other Google initiatives to help with COVID-19 [1, 2, 3], we are releasing daily forecasts based on this work to the public for free, on the web [us, ja] and through BigQuery.
 |
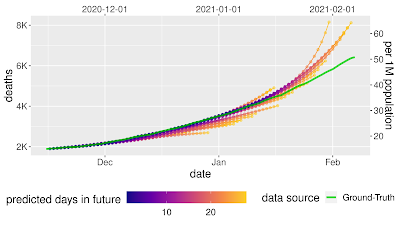 |
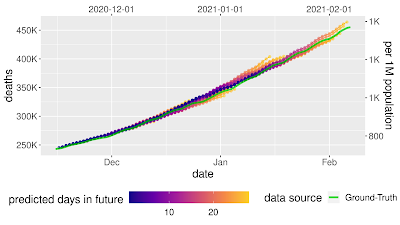
| Prospective forecasts for the USA and Japan models. Ground truth cumulative deaths counts (green lines) are shown alongside the forecasts for each day. Each daily forecast contains a predicted increase in deaths for each day during the prediction window of 4 weeks (shown as colored dots, where shading shifting to yellow indicates days further from the date of prediction in the forecasting horizon, up to 4 weeks). Predictions of deaths are shown for the USA (above) and Japan (below). |
The Model
Models for infectious diseases have been studied by epidemiologists for decades. Compartmental models are the most common, as they are simple, interpretable, and can fit different disease phases effectively. In compartmental models, individuals are separated into mutually exclusive groups, or compartments, based on their disease status (such as susceptible, exposed, or recovered), and the rates of change between these compartments are modeled to fit the past data. A population is assigned to compartments representing disease states, with people flowing between states as their disease status changes.
In this work, we propose a few extensions to the Susceptible-Exposed-Infectious-Removed (SEIR) type compartmental model. For example, susceptible people becoming exposed causes the susceptible compartment to decrease and the exposed compartment to increase, with a rate that depends on disease spreading characteristics. Observed data for COVID-19 associated outcomes, such as confirmed cases, hospitalizations and deaths, are used for training of compartmental models.
 |
| Visual explanation of “compartmental” models in epidemiology. People “flow” between compartments. Real-world events, like policy changes and more ICU beds, change the rate of flow between compartments. |
Our framework proposes a number of novel technical innovations:
- Learned transition rates: Instead of using static rates for transitions between compartments across all locations and times, we use machine-learned rates to map them. This allows us to take advantage of the vast amount of available data with informative signals, such as Google’s COVID-19 Community Mobility Reports, healthcare supply, demographics, and econometrics features.
- Explainability: Our framework provides explainability for decision makers, offering insights on disease propagation trends via its compartmental structure, and suggesting which factors may be most important for driving compartmental transitions.
- Expanded compartments: We add hospitalization, ICU, ventilator, and vaccine compartments and demonstrate efficient training despite data sparsity.
- Information sharing across locations: As opposed to fitting to an individual location, we have a single model for all locations in a country (e.g., >3000 US counties) with distinct dynamics and characteristics, and we show the benefit of transferring information across locations.
- Seq2seq modeling: We use a sequence-to-sequence model with a novel partial teacher forcing approach that minimizes amplified growth of errors into the future.
Forecast Accuracy
Each day, we train models to predict COVID-19 associated outcomes (primarily deaths and cases) 28 days into the future. We report the mean absolute percentage error (MAPE) for both a country-wide score and a location-level score, with both cumulative values and weekly incremental values for COVID-19 associated outcomes.
We compare our framework with alternatives for the US from the COVID19 Forecast Hub. In MAPE, our models outperform all other 33 models except one — the ensemble forecast that also includes our model’s predictions, where the difference is not statistically significant.
We also used prediction uncertainty to estimate whether a forecast is likely to be accurate. If we reject forecasts that the model considers uncertain, we can improve the accuracy of the forecasts that we do release. This is possible because our model has well-calibrated uncertainty.
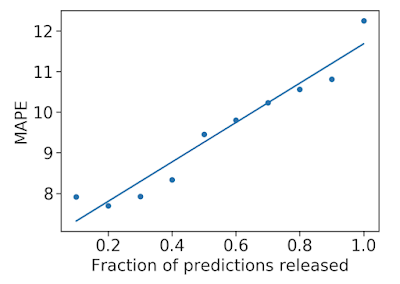 |
| Mean average percentage error (MAPE, the lower the better) decreases as we remove uncertain forecasts, increasing accuracy. |
What-If Tool to Simulate Pandemic Management Policies and Strategies
In addition to understanding the most probable scenario given past data, decision makers are interested in how different decisions could affect future outcomes, for example, understanding the impact of school closures, mobility restrictions and different vaccination strategies. Our framework allows counterfactual analysis by replacing the forecasted values for selected variables with their counterfactual counterparts. The results of our simulations reinforce the risk of prematurely relaxing non-pharmaceutical interventions (NPIs) until the rapid disease spreading is reduced. Similarly, the Japan simulations show that maintaining the State of Emergency while having a high vaccination rate greatly reduces infection rates.
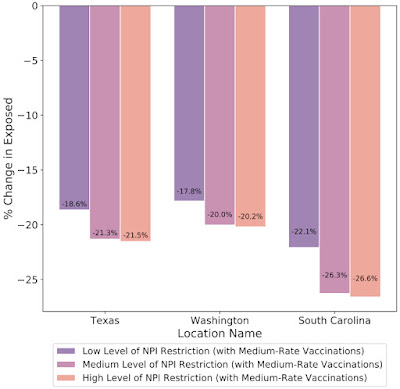 |
| What-if simulations on the percent change of predicted exposed individuals assuming different non-pharmaceutical interventions (NPIs) for the prediction date of March 1, 2021 in Texas, Washington and South Carolina. Increased NPI restrictions are associated with a larger % reduction in the number of exposed people. |
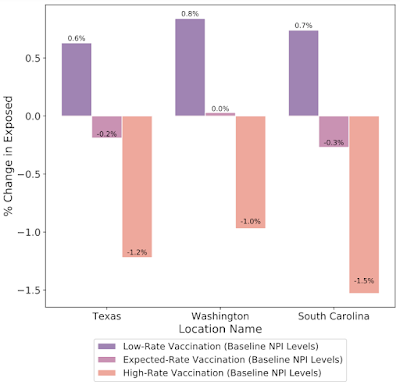 |
| What-if simulations on the percent change of predicted exposed individuals assuming different vaccination rates for the prediction date of March 1, 2021 in Texas, Washington and South Carolina. Increased vaccination rate also plays a key role to reduce exposed count in these cases. |
Fairness Analysis
To ensure that our models do not create or reinforce unfairly biased decision making, in alignment with our AI Principles, we performed a fairness analysis separately for forecasts in the US and Japan by quantifying whether the model’s accuracy was worse on protected sub-groups. These categories include age, gender, income, and ethnicity in the US, and age, gender, income, and country of origin in Japan. In all cases, we demonstrated no consistent pattern of errors among these groups once we controlled for the number of COVID-19 deaths and cases that occur in each subgroup.
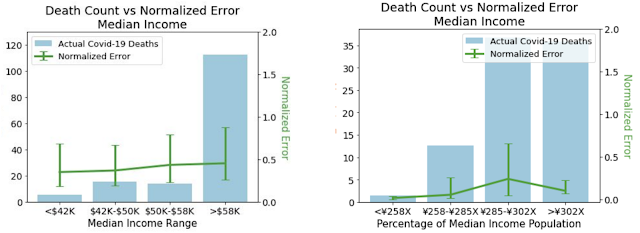 |
| Normalized errors by median income. The comparison between the two shows that patterns of errors don’t persist once errors are normalized by cases. Left: Normalized errors by median income for the US. Right: Normalized errors by median income for Japan. |
Real-World Use Cases
In addition to quantitative analyses to measure the performance of our models, we conducted a structured survey in the US and Japan to understand how organisations were using our model forecasts. In total, seven organisations responded with the following results on the applicability of the model.
- Organization type: Academia (3), Government (2), Private industry (2)
- Main user job role: Analyst/Scientist (3), Healthcare professional (1), Statistician (2), Managerial (1)
- Location: USA (4), Japan (3)
- Predictions used: Confirmed cases (7), Death (4), Hospitalizations (4), ICU (3), Ventilator (2), Infected (2)
- Model use case: Resource allocation (2), Business planning (2), scenario planning (1), General understanding of COVID spread (1), Confirm existing forecasts (1)
- Frequency of use: Daily (1), Weekly (1), Monthly (1)
- Was the model helpful?: Yes (7)
To share a few examples, in the US, the Harvard Global Health Institute and Brown School of Public Health used the forecasts to help create COVID-19 testing targets that were used by the media to help inform the public. The US Department of Defense used the forecasts to help determine where to allocate resources, and to help take specific events into account. In Japan, the model was used to make business decisions. One large, multi-prefecture company with stores in more than 20 prefectures used the forecasts to better plan their sales forecasting, and to adjust store hours.
Limitations and next steps
Our approach has a few limitations. First, it is limited by available data, and we are only able to release daily forecasts as long as there is reliable, high-quality public data. For instance, public transportation usage could be very useful but that information is not publicly available. Second, there are limitations due to the model capacity of compartmental models as they cannot model very complex dynamics of Covid-19 disease propagation. Third, the distribution of case counts and deaths are very different between the US and Japan. For example, most of Japan’s COVID-19 cases and deaths have been concentrated in a few of its 47 prefectures, with the others experiencing low values. This means that our per-prefecture models, which are trained to perform well across all Japanese prefectures, often have to strike a delicate balance between avoiding overfitting to noise while getting supervision from these relatively COVID-19-free prefectures.
We have updated our models to take into account large changes in disease dynamics, such as the increasing number of vaccinations. We are also expanding to new engagements with city governments, hospitals, and private organizations. We hope that our public releases continue to help public and policy-makers address the challenges of the ongoing pandemic, and we hope that our method will be useful to epidemiologists and public health officials in this and future health crises.
Acknowledgements
This paper was the result of hard work from a variety of teams within Google and collaborators around the globe. We’d especially like to thank our paper co-authors from the School of Medicine at Keio University, Graduate School of Public Health at St Luke’s International University, and Graduate School of Medicine at The University of Tokyo.
