Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. Amazon Textract has a Tables feature within the AnalyzeDocument API that offers the ability to automatically extract tabular structures from any document. In this post, we discuss the improvements made to the Tables feature and how it makes it easier to extract information in tabular structures from a wide variety of documents.
Tabular structures in documents such as financial reports, paystubs, and certificate of analysis files are often formatted in a way that enables easy interpretation of information. They often also include information such as table title, table footer, section title, and summary rows within the tabular structure for better readability and organization. For a similar document prior to this enhancement, the Tables feature within AnalyzeDocument would have identified those elements as cells, and it didn’t extract titles and footers that are present outside the bounds of the table. In such cases, custom postprocessing logic to identify such information or extract it separately from the API’s JSON output was necessary. With this announcement of enhancements to the Table feature, the extraction of various aspects of tabular data becomes much simpler.
In April 2023, Amazon Textract introduced the ability to automatically detect titles, footers, section titles, and summary rows present in documents via the Tables feature. In this post, we discuss these enhancements and give examples to help you understand and use them in your document processing workflows. We walk through how to use these improvements through code examples to use the API and process the response with the Amazon Textract Textractor library.
Overview of solution
The following image shows that the updated model not only identifies the table in the document but all corresponding table headers and footers. This sample financial report document contains table title, footer, section title, and summary rows.
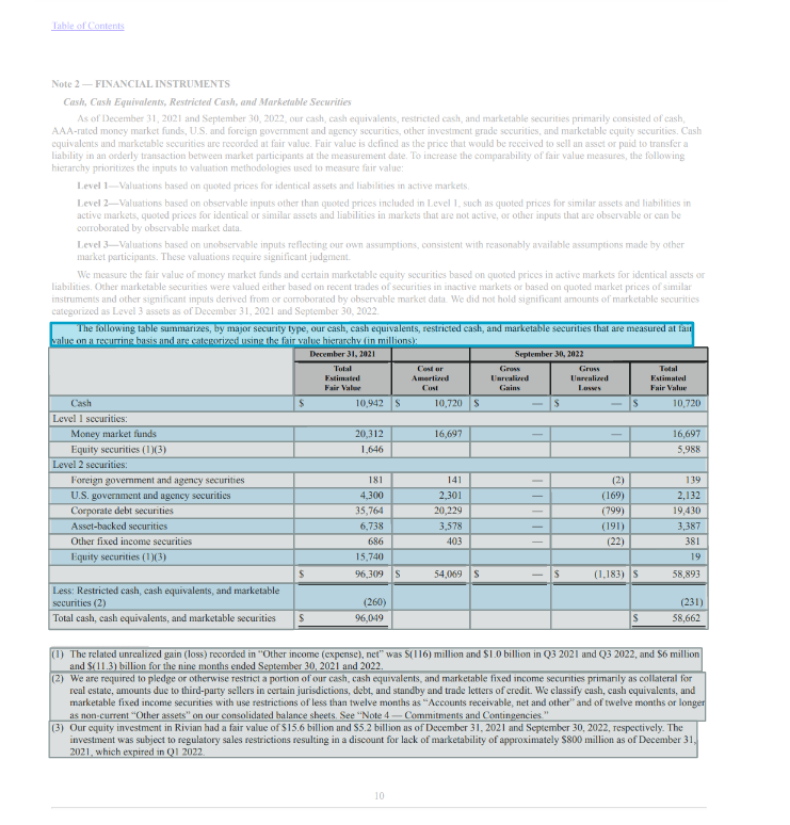
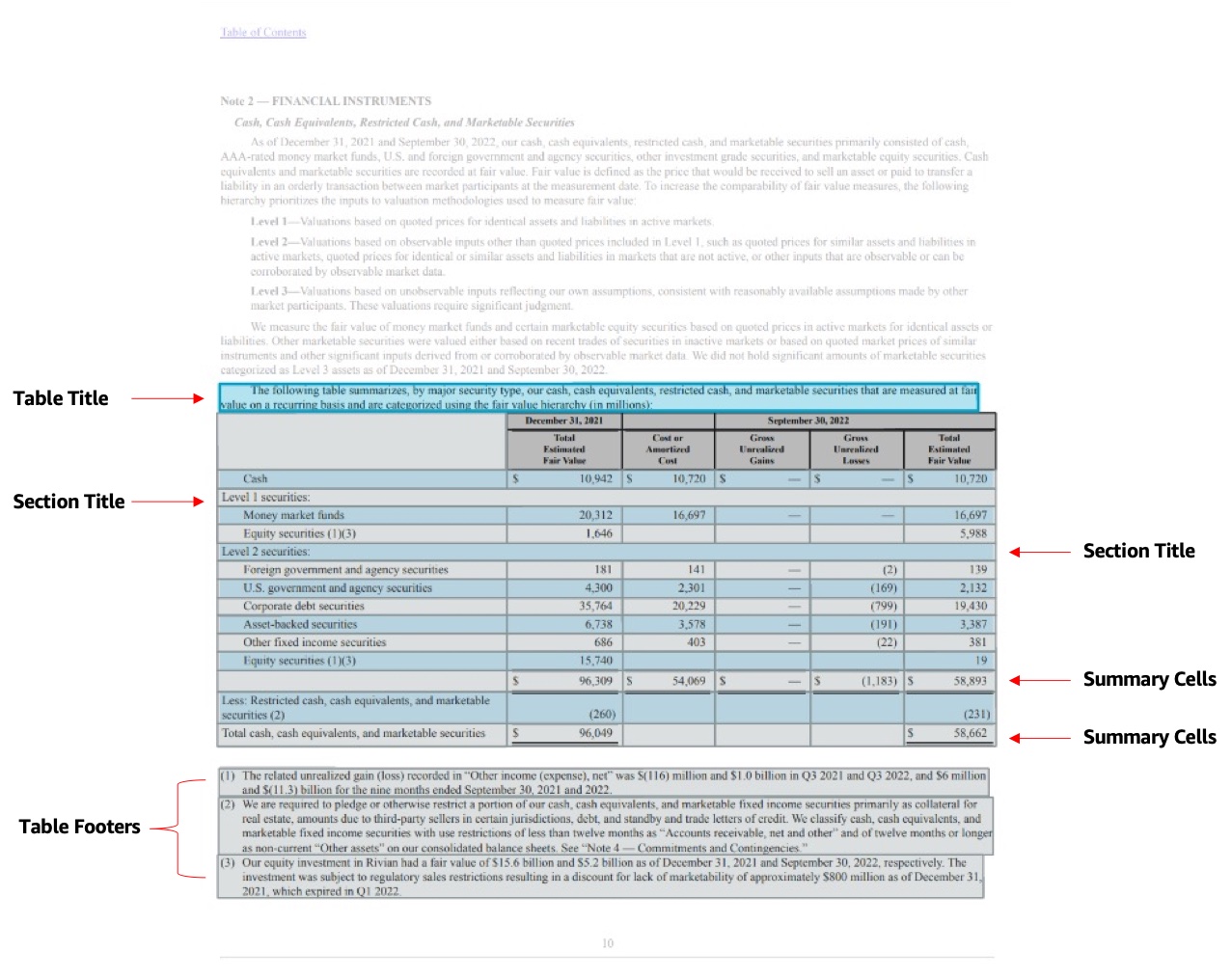
The Tables feature enhancement adds support for four new elements in the API response that allows you to extract each of these table elements with ease, and adds the ability to distinguish the type of table.
Table elements
Amazon Textract can identify several components of a table such as table cells and merged cells. These components, known as Blockobjects, encapsulate the details related to the component, such as the bounding geometry, relationships, and confidence score. A Block represents items that are recognized in a document within a group of pixels close to each other. The following are the new Table Blocks introduced in this enhancement:
- Table title – A new
Blocktype calledTABLE_TITLEthat enables you to identify the title of a given table. Titles can be one or more lines, which are typically above a table or embedded as a cell within the table. - Table footers – A new
Blocktype calledTABLE_FOOTERthat enables you to identify the footers associated with a given table. Footers can be one or more lines that are typically below the table or embedded as a cell within the table. - Section title – A new
Blocktype calledTABLE_SECTION_TITLEthat enables you to identify if the cell detected is a section title. - Summary cells – A new
Blocktype calledTABLE_SUMMARYthat enables you to identify if the cell is a summary cell, such as a cell for totals on a paystub.
Types of tables
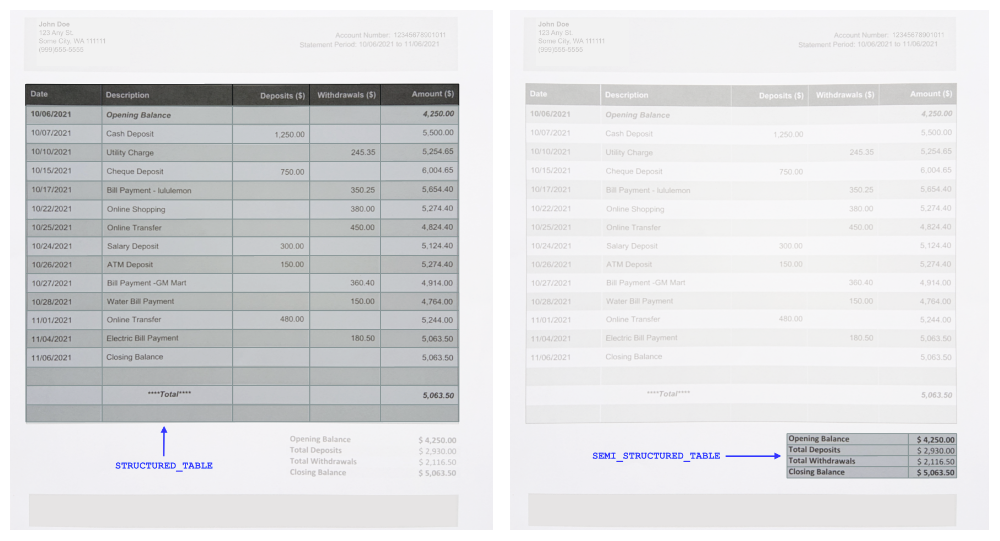
When Amazon Textract identifies a table in a document, it extracts all the details of the table into a top-level Block type of TABLE. Tables can come in various shapes and sizes. For example, documents often contain tables that may or may not have a discernible table header. To help distinguish these types of tables, we added two new entity types for a TABLE Block: SEMI_STRUCTURED_TABLE and STRUCTURED_TABLE. These entity types help you distinguish between a structured versus a semistructured table.
Structured tables are tables that have clearly defined column headers. But with semi-structured tables, data might not follow a strict structure. For example, data may appear in tabular structure that isn’t a table with defined headers. The new entity types offer the flexibility to choose which tables to keep or remove during post-processing. The following image shows an example of STRUCTURED_TABLE and SEMI_STRUCTURED_TABLE.
Analyzing the API output
In this section, we explore how you can use the Amazon Textract Textractor library to postprocess the API output of AnalyzeDocument with the Tables feature enhancements. This allows you to extract relevant information from tables.
Textractor is a library created to work seamlessly with Amazon Textract APIs and utilities to subsequently convert the JSON responses returned by the APIs into programmable objects. You can also use it to visualize entities on the document and export the data in formats such as comma-separated values (CSV) files. It’s intended to aid Amazon Textract customers in setting up their postprocessing pipelines.
In our examples, we use the following sample page from a 10-K SEC filing document.
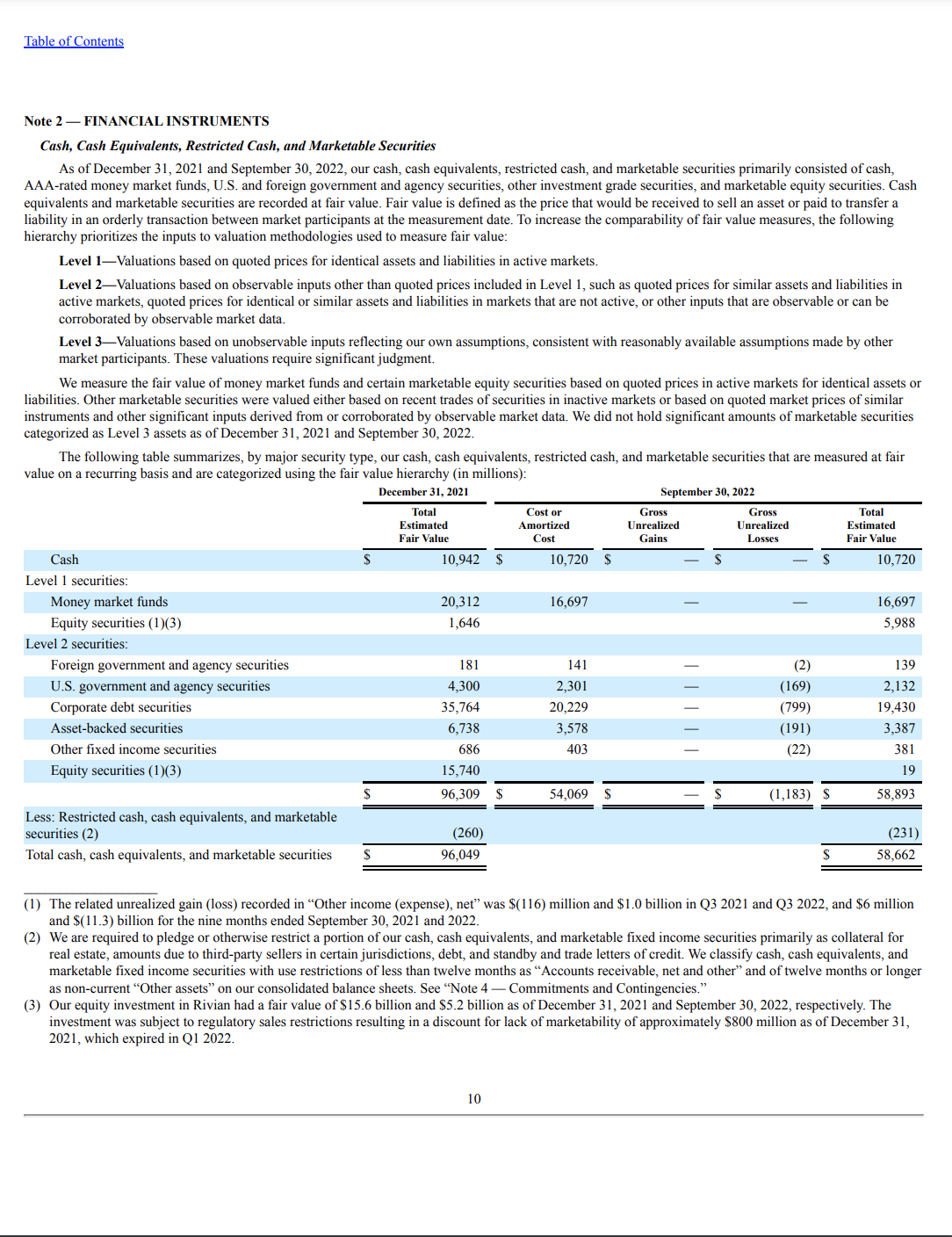
The following code can be found within our GitHub repository. To process this document, we make use of the Textractor library and import it for us to postprocess the API outputs and visualize the data:
The first step is to call Amazon Textract AnalyzeDocument with Tables feature, denoted by the features=[TextractFeatures.TABLES] parameter to extract the table information. Note that this method invokes the real-time (or synchronous) AnalyzeDocument API, which supports single-page documents. However, you can use the asynchronous StartDocumentAnalysis API to process multi-page documents (with up to 3,000 pages).
The document object contains metadata about the document that can be reviewed. Notice that it recognizes one table in the document along with other entities in the document:
Now that we have the API output containing the table information, we visualize the different elements of the table using the response structure discussed previously:
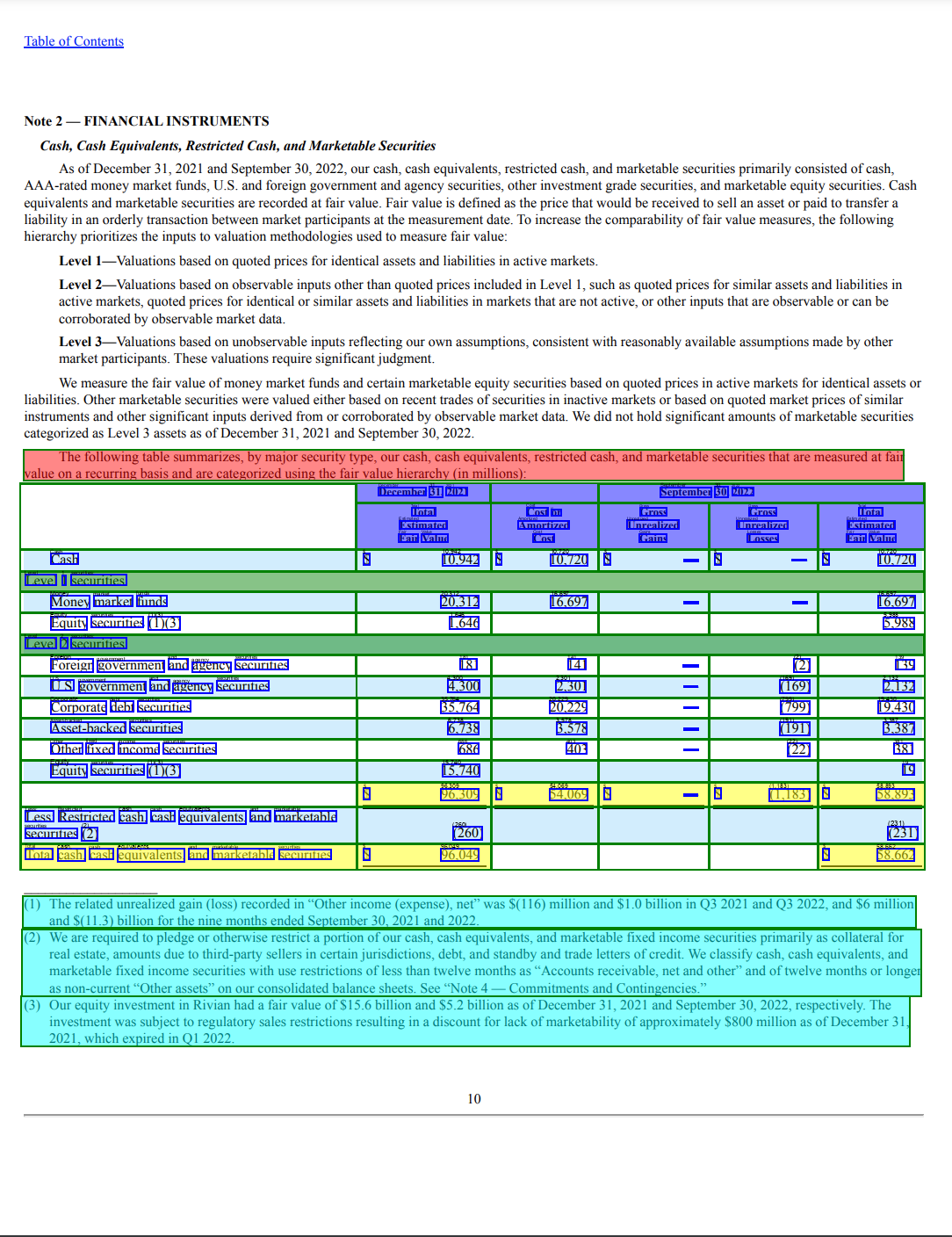
The Textractor library highlights the various entities within the detected table with a different color code for each table element. Let’s dive deeper into how we can extract each element. The following code snippet demonstrates extracting the title of the table:
Similarly, we can use the following code to extract the footers of the table. Notice that table_footers is a list, which means that there can be one or more footers associated with the table. We can iterate over this list to see all the footers present, and as shown in the following code snippet, the output displays three footers:
Generating data for downstream ingestion
The Textractor library also helps you simplify the ingestion of table data into downstream systems or other workflows. For example, you can export the extracted table data into a human readable Microsoft Excel file. At the time of this writing, this is the only format that supports merged tables.
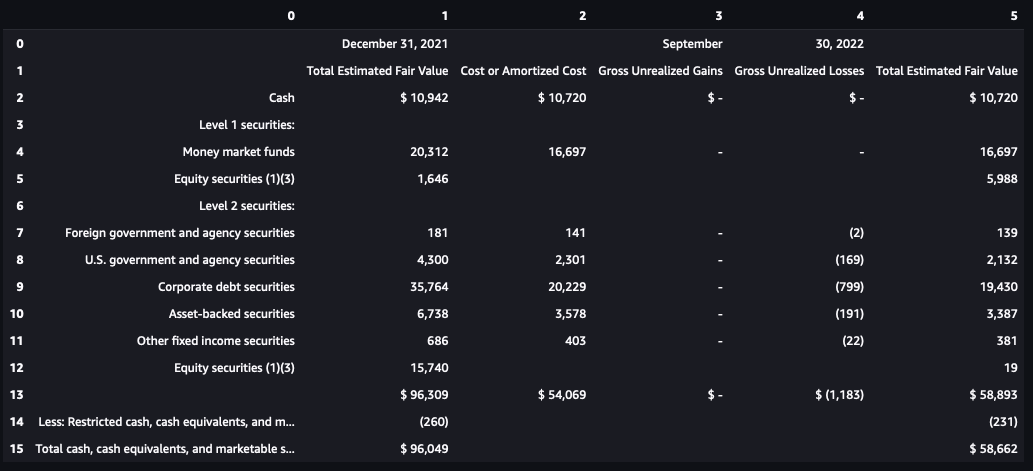
We can also convert it to a Pandas DataFrame. DataFrame is a popular choice for data manipulation, analysis, and visualization in programming languages such as Python and R.
In Python, DataFrame is a primary data structure in the Pandas library. It’s flexible and powerful, and is often the first choice for data analysis professionals for various data analysis and ML tasks. The following code snippet shows how to convert the extracted table information into a DataFrame with a single line of code:
Lastly, we can convert the table data into a CSV file. CSV files are often used to ingest data into relational databases or data warehouses. See the following code:
Conclusion
The introduction of these new block and entity types (TABLE_TITLE, TABLE_FOOTER, STRUCTURED_TABLE, SEMI_STRUCTURED_TABLE, TABLE_SECTION_TITLE, TABLE_FOOTER, and TABLE_SUMMARY) marks a significant advancement in extraction of tabular structures from documents with Amazon Textract.
These tools provide a more nuanced and flexible approach, catering to both structured and semistructured tables and making sure that no important data is overlooked, regardless of its location in a document.
This means we can now handle diverse data types and table structures with enhanced efficiency and accuracy. As we continue to embrace the power of automation in document processing workflows, these enhancements will no doubt pave the way for more streamlined workflows, higher productivity, and more insightful data analysis. For more information on AnalyzeDocument and the Tables feature, refer to AnalyzeDocument.
About the authors
 Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
 Anjan Biswas is a Senior AI Services Solutions Architect with focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand, and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations and is actively helping customers get started and scale on AWS AI services.
Anjan Biswas is a Senior AI Services Solutions Architect with focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand, and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations and is actively helping customers get started and scale on AWS AI services.
 Lalita Reddi is a Senior Technical Product Manager with the Amazon Textract team. She is focused on building machine learning-based services for AWS customers. In her spare time, Lalita likes to play board games, and go on hikes.
Lalita Reddi is a Senior Technical Product Manager with the Amazon Textract team. She is focused on building machine learning-based services for AWS customers. In her spare time, Lalita likes to play board games, and go on hikes.