 Posted by Wei Wei, Developer Advocate
Posted by Wei Wei, Developer Advocate

Large language models (LLMs) are taking the world by storm, thanks to their powerful ability to generate text, translate languages, and answer questions in a coherent and informative way. At Google I/O 2023, we released the PaLM API as ‘public preview’ so that many developers can start building apps with it. While PaLM API already has excellent documentation on its extensive usage and best practices, in this blog we are going to take a more focused approach to explore how to leverage LLMs to augment your ML systems in a practical application: recommendation systems.
As a refresher, modern recommendation systems often follow a retrieval-ranking architecture, which enables them to effectively and efficiently filter and rank relevant items to maximize the utility in production. You can go through this codelab to learn about building a fullstack movie recommendation system using TensorFlow and Flutter.
 |
We will discuss how LLMs can be incorporated into this retrieval-ranking pipeline.
Conversational recommendations
If you already have access to Bard, you can ask it to create recommendations for you interactively in a dialogue. Here is an example of asking Bard for movie recommendations:
 |
As a developer, you can build a similar functionality in your own applications, using the PaLM API Chat service with minimal effort:
prompt = """You are a movie recommender and your job is to recommend new movies based on user input. |
The PaLM API also allows you to help your user continue the exploration and interactively refine the recommendations (e.g., asking to swap The Florida Project for another one) in a dialogue, which is what Chat service is designed for. This kind of conversational recommendation interface (think having a knowledgeable chatbot that guides a customer along the way in your shopping app) provides a fluid and personalized experience for the users, and can sometimes be a very appealing addition to your existing recommendation surfaces.
Sequential recommendations
Recommendations would be much more useful if your system knows what your users may like. One way to find out your users’ interest is looking at their historical activities and then extrapolating. This is often called ‘sequential recommendation’ because the recommender looks at the sequence of items that have been interacted with and infers what to recommend. Usually you need to use a ML library (i.e., TensorFlow Recommenders) to achieve this. But now with the power of LLMs, you can also do this with the PaLM API Text service:
prompt = """You are a movie recommender and your job is to recommend new movies based on the sequence of movies that a user has watched. You pay special attention to the order of movies because it matters.
|
This example prompts the Text service with 4 movies that have been watched and asks the PaLM API to generate new recommendations based on the sequence of past movies.
Rating predictions
In the ranking phase of modern recommendation engines, a list of candidates needs to be sorted based on certain criteria. This is usually done by using a learning-to-rank library (such as, TensorFlow Ranking) to predict the ordering. Now you can do this with the PaLM API. Here is an example of predicting movie ratings:
prompt = """You are a movie recommender and your job is to predict a user's rating (ranging from 1 to 5, with 5 being the highest) on a movie, based on that user's previous ratings.
|
The PaLM API predicted a high score for The Matrix. You can ask the PaLM API to predict a rating for a list of candidate movies one by one and then sort them in order before making final recommendations; this process is called ‘pointwise ranking’. You can even leverage the PaLM API to do pairwise ranking or listwise ranking, if you adjust the prompt accordingly.
For a more comprehensive study on rating prediction with LLMs, you can refer to this paper from Google.
Text embedding-based recommendations
At this point you may be asking: all the use cases so far involve well known movies that the LLM is already aware of, so maybe there is a requirement that candidate items need to be captured in LLMs in advance (in the training phase)? What if I have private items not known to LLMs beforehand? How could I use the PaLM API then?
Not to worry. The PaLM API for Embeddings can help you out in this case. The basic idea is to embed text associated with your items (for example, product description, movie plot) into vectors and use nearest neighbor search techniques (i.e., using the tf.math.top_k op from TensorFlow for brute force search or Google ScaNN/Chroma for approximate search) to identify similar items to recommend, based on a user query. Let’s walk through a simple example.
Suppose you are building a news app and at the bottom of each news article you want to recommend similar news to your users. First you can embed all news articles by calling the PaLM API Embedding service like below:
embedding = palm.generate_embeddings(model='embedding-gecko-001', text='example news article text')['embedding'] |
For simplicity, let’s assume you store all the news texts and their embeddings in a simple Pandas DataFrame with 2 columns: news_text and embedding. Then you can recommend interestings news to your users using the following:
def recommend_news(query_text, df, topk=5): |
The recommend_news function computes the query embedding’s dot product similarity with all news articles using the pre-computed embeddings, and then identifies 5 news articles most similar to what your user is reading.
This approach is often a quick and effective way to generate candidates and create recommendations based on item similarities. It may be sufficient for many use cases and can be particularly useful in the item cold start situation.
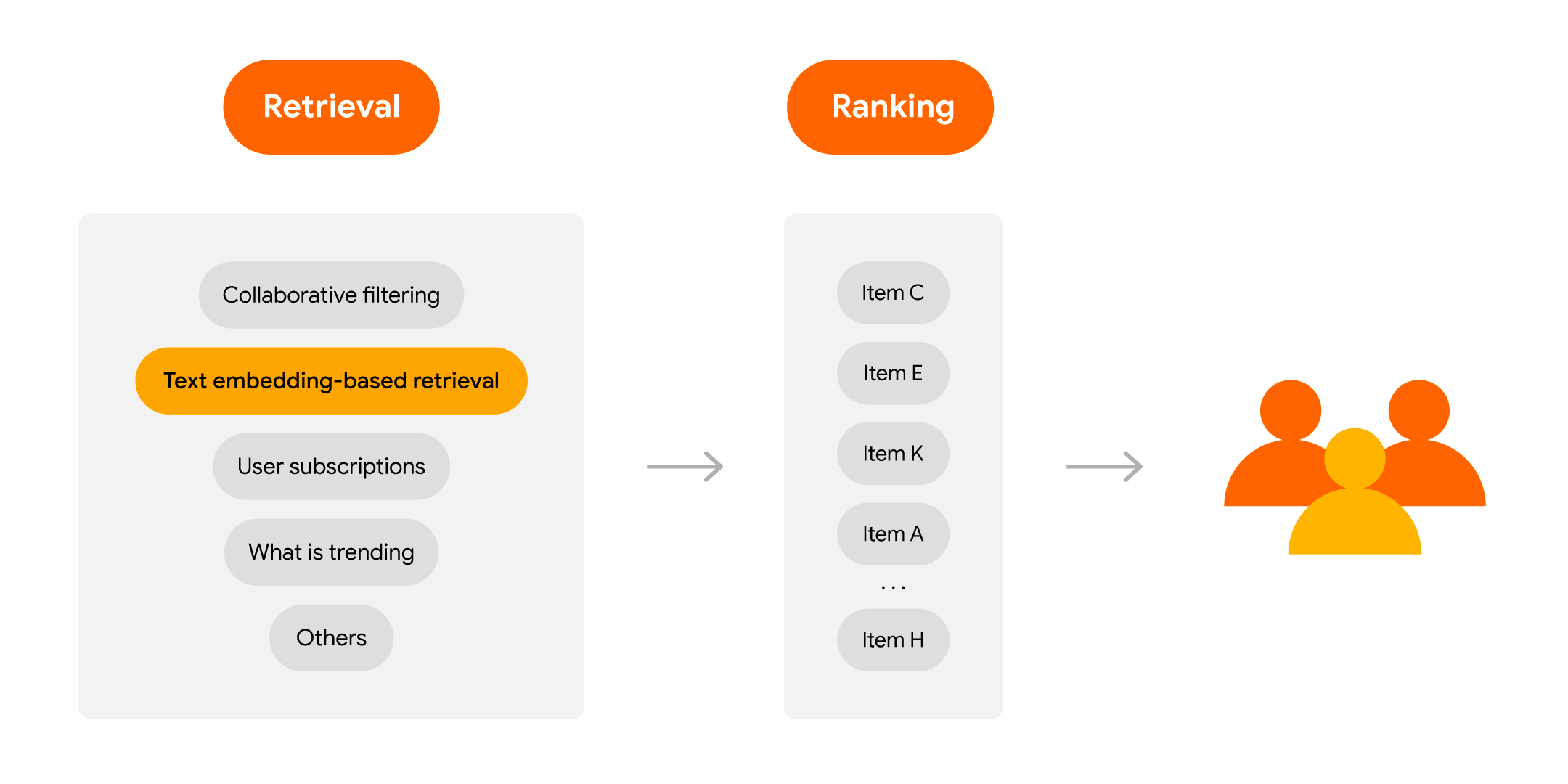
In practice, the candidate generation phase of modern large scale recommenders often consists of multiple sources. For example, you can use a mixer of text embedding-based retrieval, collaborative filtering, users’ subscriptions (i.e., new uploads from followed accounts on YouTube), real time trending items (i.e., breaking news) and etc. Thus, leveraging the PaLM API Embedding service could be a helpful augment for the retrieval stage in your existing recommendation system.
 |
Text embeddings as side features
In addition, you could also use the text embeddings as side features in a recommendation model. The text embeddings capture the semantic information of the candidate items via the description text and can potentially help improve the model accuracy. For example, in this TensorFlow Recommenders feature preprocessing tutorial, if you have pre-computed text embeddings for movie plot using LLMs, it’s fairly easy to inject them into the model as side features, when concatenating all the embeddings:
class MovieModel(tf.keras.Model):
|
The default PaLM Embedding service returns a vector of 768 floating numbers for any text, which may be too much. You can reduce the dimensions by initializing a tf.keras.layers.Embedding layer with the movie plot embedding matrix and then stacking a fully connected layer on top of it to project it down to fewer dimensions.
Conclusion
We have shared several ideas on leveraging LLMs to augment recommenders. Obviously, this is just scratching the surface as there are more not covered here. Also note that there may still be a long way before they can make it into production (i.e., latency and cost issues). But we hope this blog inspires you to start thinking about how you can improve your own recommendation systems with LLMs.
Lastly, we are holding an online Developer Summit on Recommendation Systems on June 9, 2023. If you want to learn more about Google products related to building recommendation systems, feel free to sign up here to attend.