Amazon SageMaker Autopilot makes it possible for organizations to quickly build and deploy an end-to-end machine learning (ML) model and inference pipeline with just a few lines of code or even without any code at all with Amazon SageMaker Studio. Autopilot offloads the heavy lifting of configuring infrastructure and the time it takes to build an entire pipeline, including feature engineering, model selection, and hyperparameter tuning.
In this post, we show how to go from raw data to a robust and fully deployed inference pipeline with Autopilot.
Solution overview
We use Lyft’s public dataset on bikesharing for this simulation to predict whether or not a user participates in the Bike Share for All program. This is a simple binary classification problem.
We want to showcase how easy it is to build an automated and real-time inference pipeline to classify users based on their participation in the Bike Share for All program. To this end, we simulate an end-to-end data ingestion and inference pipeline for an imaginary bikeshare company operating in the San Francisco Bay Area.
The architecture is broken down into two parts: the ingestion pipeline and the inference pipeline.
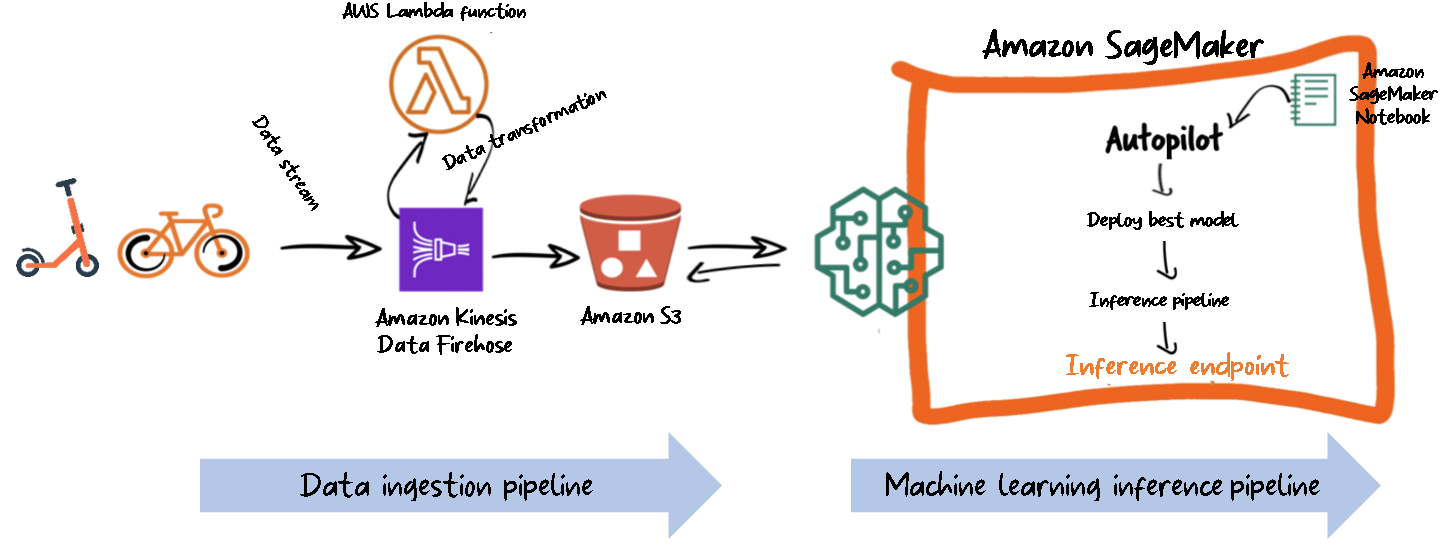
We primarily focus on the ML pipeline in the first section of this post, and review the data ingestion pipeline in the second part.
Prerequisites
To follow along with this example, complete the following prerequisites:
- Create a new SageMaker notebook instance.
- Create an Amazon Kinesis Data Firehose delivery stream with an AWS Lambda transform function. For instructions, see Amazon Kinesis Firehose Data Transformation with AWS Lambda. This step is optional and only needed to simulate data streaming.
Data exploration
Let’s download and visualize the dataset, which is located in a public Amazon Simple Storage Service (Amazon S3) bucket and static website:
The following screenshot shows a subset of the data before transformation.
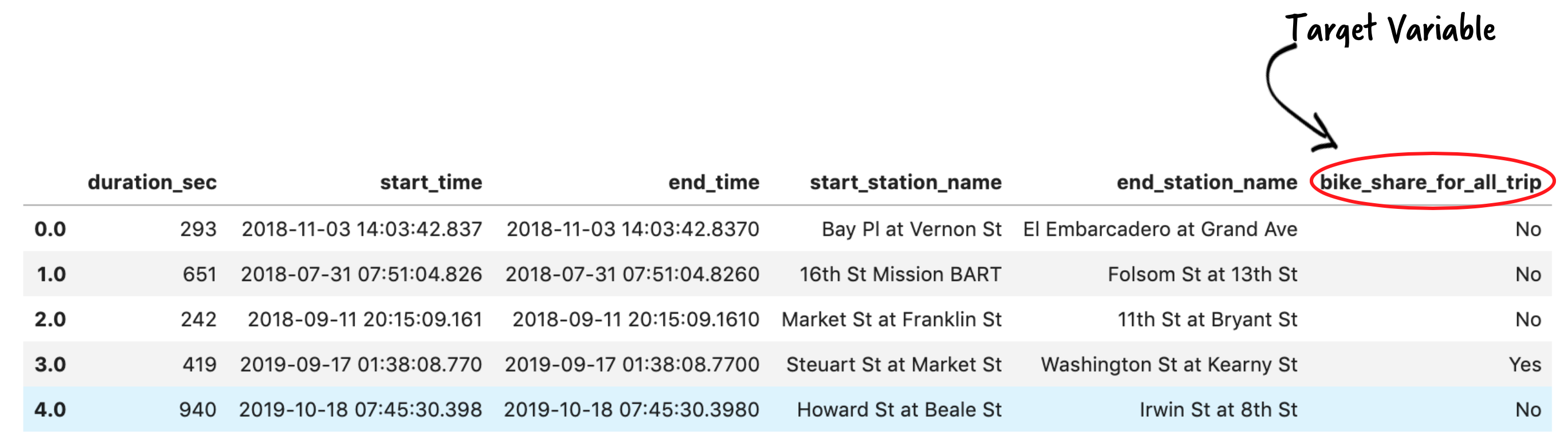
The last column of the data contains the target we want to predict, which is a binary variable taking either a Yes or No value, indicating whether the user participates in the Bike Share for All program.
Let’s take a look at the distribution of our target variable for any data imbalance.
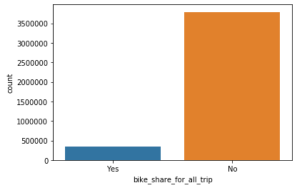
As shown in the graph above, the data is imbalanced, with fewer people participating in the program.
We need to balance the data to prevent an over-representation bias. This step is optional because Autopilot also offers an internal approach to handle class imbalance automatically, which defaults to a F1 score validation metric. Additionally, if you choose to balance the data yourself, you can use more advanced techniques for handling class imbalance, such as SMOTE or GAN.
For this post, we downsample the majority class (No) as a data balancing technique:
The following code enriches the data and under-samples the overrepresented class:
We deliberately left our categorical features not encoded, including our binary target value. This is because Autopilot takes care of encoding and decoding the data for us as part of the automatic feature engineering and pipeline deployment, as we see in the next section.
The following screenshot shows a sample of our data.

The data in the following graphs looks otherwise normal, with a bimodal distribution representing the two peaks for the morning hours and the afternoon rush hours, as you would expect. We also observe low activities on weekends and at night.
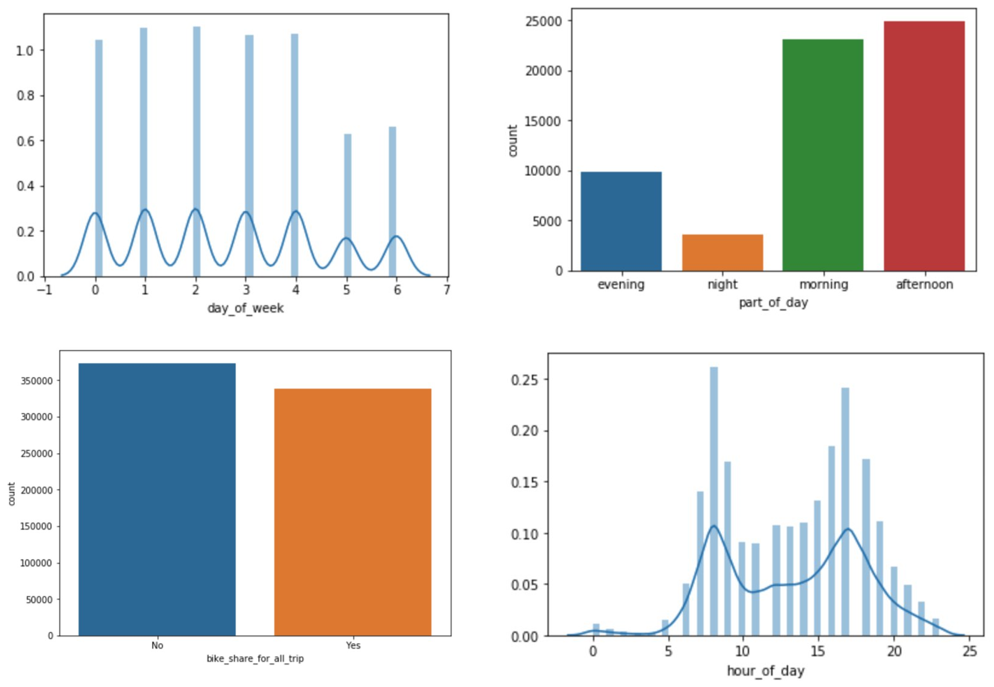
In the next section, we feed the data to Autopilot so that it can run an experiment for us.
Build a binary classification model
Autopilot requires that we specify the input and output destination buckets. It uses the input bucket to load the data and the output bucket to save the artifacts, such as feature engineering and the generated Jupyter notebooks. We retain 5% of the dataset to evaluate and validate the model’s performance after the training is complete and upload 95% of the dataset to the S3 input bucket. See the following code:
After we upload the data to the input destination, it’s time to start Autopilot:
All we need to start experimenting is to call the fit() method. Autopilot needs the input and output S3 location and the target attribute column as the required parameters. After feature processing, Autopilot calls SageMaker automatic model tuning to find the best version of a model by running many training jobs on your dataset. We added the optional max_candidates parameter to limit the number of candidates to 30, which is the number of training jobs that Autopilot launches with different combinations of algorithms and hyperparameters in order to find the best model. If you don’t specify this parameter, it defaults to 250.
We can observe the progress of Autopilot with the following code:
The training takes some time to complete. While it’s running, let’s look at the Autopilot workflow.
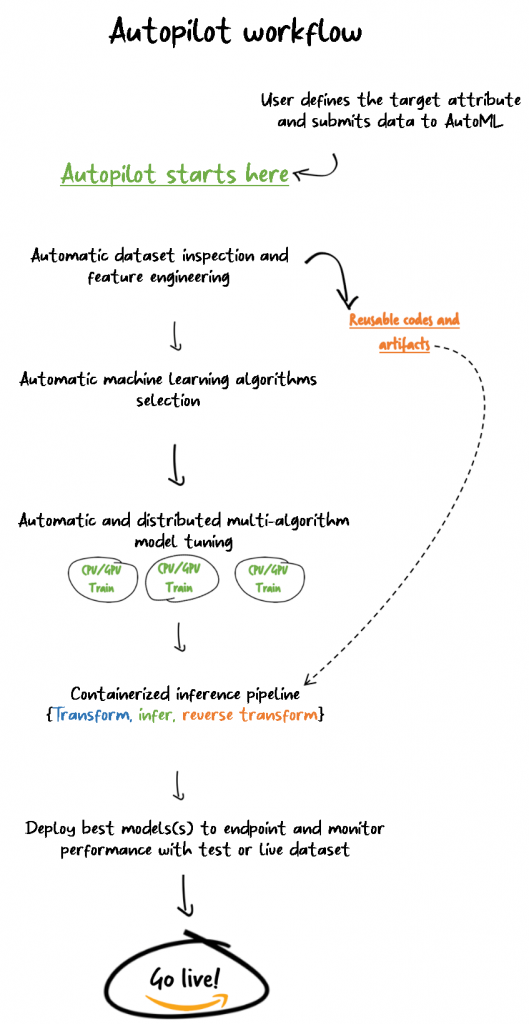
To find the best candidate, use the following code:
The following screenshot shows our output.

Our model achieved a validation accuracy of 96%, so we’re going to deploy it. We could add a condition such that we only use the model if the accuracy is above a certain level.
Inference pipeline
Before we deploy our model, let’s examine our best candidate and what’s happening in our pipeline. See the following code:
The following diagram shows our output.
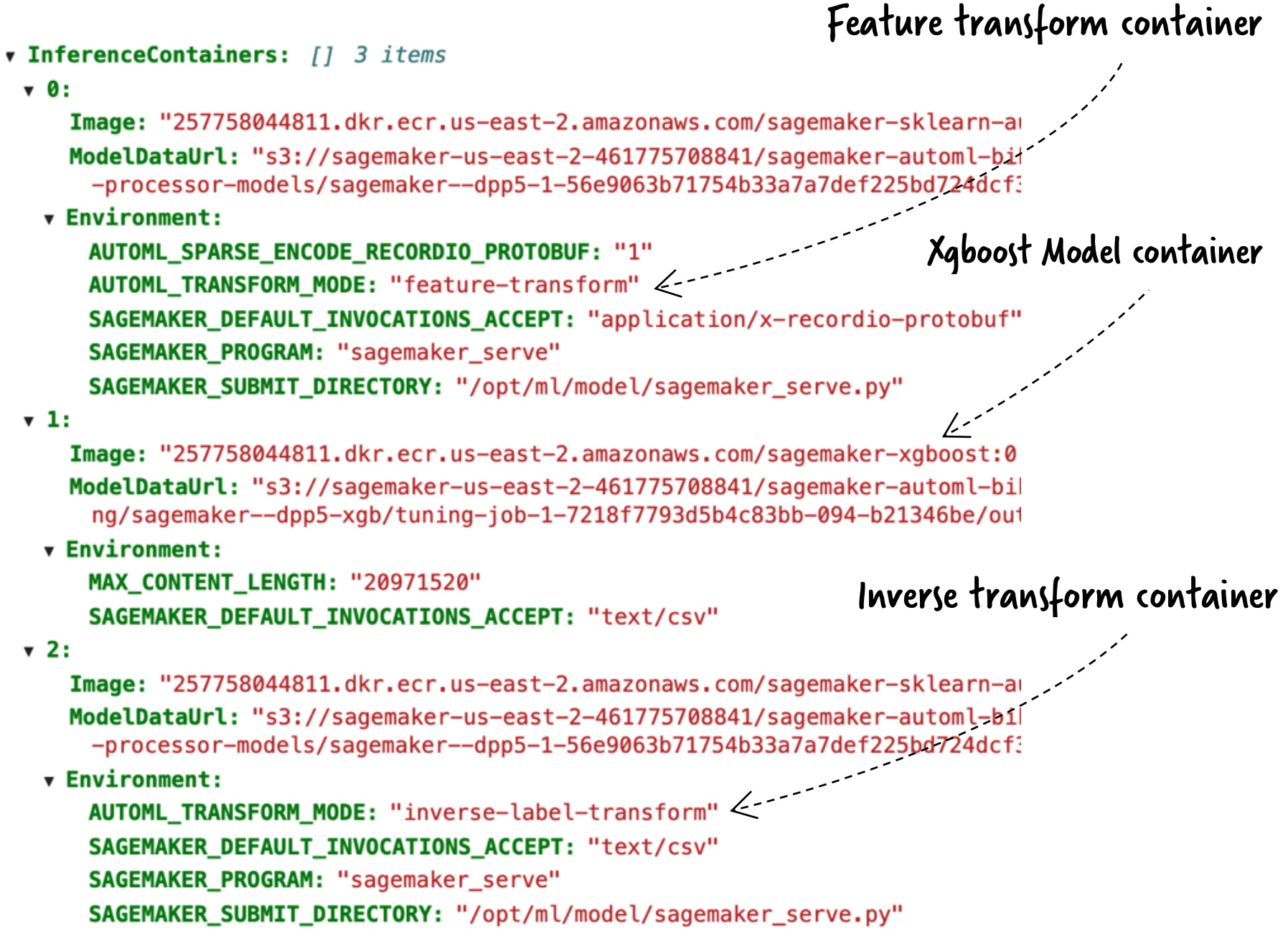
Autopilot has built the model and has packaged it in three different containers, each sequentially running a specific task: transform, predict, and reverse-transform. This multi-step inference is possible with a SageMaker inference pipeline.
A multi-step inference can also chain multiple inference models. For instance, one container can perform principal component analysis before passing the data to the XGBoost container.
Deploy the inference pipeline to an endpoint
The deployment process involves just a few lines of code:
Let’s configure our endpoint for prediction with a predictor:
Now that we have our endpoint and predictor ready, it’s time to use the testing data we set aside and test the accuracy of our model. We start by defining a utility function that sends the data one line at a time to our inference endpoint and gets a prediction in return. Because we have an XGBoost model, we drop the target variable before sending the CSV line to the endpoint. Additionally, we removed the header from the testing CSV before looping through the file, which is also another requirement for XGBoost on SageMaker. See the following code:
The following screenshot shows our output.
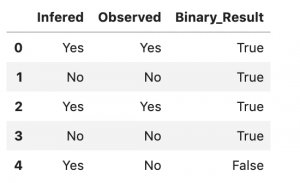
Now let’s calculate the accuracy of our model.
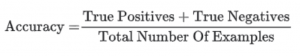
See the following code:
We get an accuracy of 92%. This is slightly lower than the 96% obtained during the validation step, but it’s still high enough. We don’t expect the accuracy to be exactly the same because the test is performed with a new dataset.
Data ingestion
We downloaded the data directly and configured it for training. In real life, you may have to send the data directly from the edge device into the data lake and have SageMaker load it directly from the data lake into the notebook.
Kinesis Data Firehose is a good option and the most straightforward way to reliably load streaming data into data lakes, data stores, and analytics tools. It can capture, transform, and load streaming data into Amazon S3 and other AWS data stores.
For our use case, we create a Kinesis Data Firehose delivery stream with a Lambda transformation function to do some lightweight data cleaning as it traverses the stream. See the following code:
This Lambda function performs light transformation of the data streamed from the devices onto the data lake. It expects a CSV formatted data file.
For the ingestion step, we download the data and simulate a data stream to Kinesis Data Firehose with a Lambda transform function and into our S3 data lake.
Let’s simulate streaming a few lines:
Clean up
It’s important to delete all the resources used in this exercise to minimize cost. The following code deletes the SageMaker inference endpoint we created as well the training and testing data we uploaded:
Conclusion
ML engineers, data scientists, and software developers can use Autopilot to build and deploy an inference pipeline with little to no ML programming experience. Autopilot saves time and resources, using data science and ML best practices. Large organizations can now shift engineering resources away from infrastructure configuration towards improving models and solving business use cases. Startups and smaller organizations can get started on machine learning with little to no ML expertise.
We recommend learning more about other important features SageMaker has to offer, such as the Amazon SageMaker Feature Store, which integrates with Amazon SageMaker Pipelines to create, add feature search and discovery, and reuse automated ML workflows. You can run multiple Autopilot simulations with different feature or target variants in your dataset. You could also approach this as a dynamic vehicle allocation problem in which your model tries to predict vehicle demand based on time (such as time of day or day of the week) or location, or a combination of both.
About the Authors
 Doug Mbaya is a Senior Solution architect with a focus in data and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solution in the cloud. Doug’s prior experience includes supporting AWS customers in the ride sharing and food delivery segment.
Doug Mbaya is a Senior Solution architect with a focus in data and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solution in the cloud. Doug’s prior experience includes supporting AWS customers in the ride sharing and food delivery segment.
 Valerio Perrone is an Applied Science Manager working on Amazon SageMaker Automatic Model Tuning and Autopilot.
Valerio Perrone is an Applied Science Manager working on Amazon SageMaker Automatic Model Tuning and Autopilot.