This is blog post is co-written by Theresa Cabrera Menard, an Applied Scientist/Geographic Information Systems Specialist at The Nature Conservancy (TNC) in Hawaii.
In recent years, Amazon and AWS have developed a series of sustainability initiatives with the overall goal of helping preserve the natural environment. As part of these efforts, AWS Professional Services establishes partnerships with organizations such as The Nature Conservancy (TNC), offering financial support and consulting services towards environmental preservation efforts. The advent of big data technologies is rapidly scaling up ecological data collection, while machine learning (ML) techniques are increasingly utilized in ecological data analysis. AWS is in a unique position to help with data storage and ingestion as well as with data analysis.
Hawaiian forests are essential as a source of clean water and for preservation of traditional cultural practices. However, they face critical threats from deforestation, species extinction, and displacement of native species by invasive plants. The state of Hawaii spends about half a billion dollars yearly fighting invasive species. TNC is helping to address the invasive plant problem through initiatives such as the Hawaii Challenge, which allows anyone with a computer and internet access to participate in tagging invasive weeds across the landscape. AWS has partnered with TNC to build upon these efforts and develop a scalable, cloud-based solution that automates and expedites the detection and localization of invasive ferns.
Among the most aggressive species invading the Hawaiian forests is the Australian tree fern, originally introduced as an ornamental, but now rapidly spreading across several islands by producing numerous spores that are easily transported by the wind. The Australian tree fern is fast growing and outcompetes other plants, smothering the canopy and affecting several native species, resulting in a loss of biological diversity.
Currently, detection of the ferns is accomplished by capturing images from fixed wing aircraft surveying the forest canopy. The imagery is manually inspected by human labelers. This process takes significant effort and time, potentially delaying the mitigation efforts by ground crews by weeks or longer. One of the advantages of utilizing a computer vision (CV) algorithm is the potential time savings because the inference time is expected to take only a few hours.
Machine learning pipeline
The following diagram shows the overall ML workflow of this project. The first goal of the AWS-TNC partnership was to automate the detection of ferns from aerial imagery. A second goal was to evaluate the potential of CV algorithms to reliably classify ferns as either native or invasive. The CV model inference can then form the basis of a fully automated AWS Cloud-native solution that enhances the capacity of TNC to efficiently and in a timely manner detect invasive ferns and direct resources to highly affected areas. The following diagram illustrates this architecture.
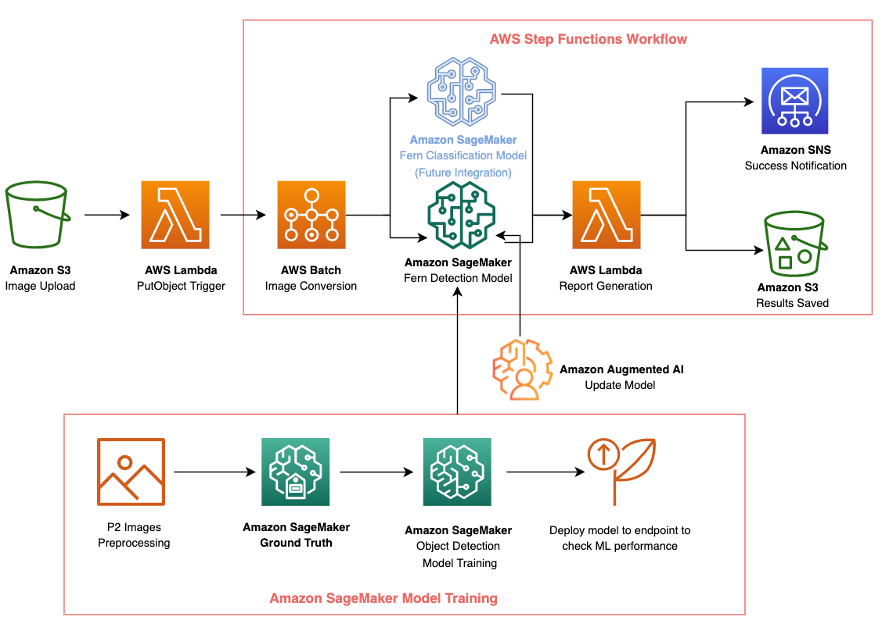
In the following sections, we cover the following topics:
- The data processing and analysis tools utilized.
- The fern detection model pipeline, including training and evaluation.
- How native and invasive ferns are classified.
- The benefits TNC experienced through this implementation.
Data processing and analysis
Aerial footage is acquired by TNC contractors by flying fixed winged aircraft above affected areas within the Hawaiian Islands. Heavy and persistent cloud cover prevents use of satellite imagery. The data available to TNC and AWS consists of raw images and metadata allowing the geographical localization of the inferred ferns.
Images and geographical coordinates
Images received from aerial surveys are in the range of 100,000 x 100,000 pixels and are stored in the JPEG2000 (JP2) format, which incorporates geolocation and other metadata. Each pixel can be associated to specific Universal Transverse Mercator (UTM) geospatial coordinates. The UTM coordinate system divides the world into north-south zones, each 6 degrees of longitude wide. The first UTM coordinate (northing) refers to the distance between a geographical position and the equator, measured with the north as the positive direction. The second coordinated (easting) measures the distance, in meters, towards east, starting from a central meridian that is uniquely assigned for each zone. By convention, the central meridian in each region has a value of 500,000, and a meter east of the region central meridian therefore has the value 500,001. To convert between pixel coordinates and UTM coordinates, we utilize the affine transform as outlined in the following equation, where x’, y’ are UTM coordinates and x, y are pixel coordinates. The parameters a, b, c, d, e, and f of the affine transform are provided as part of the JP2 file metadata.
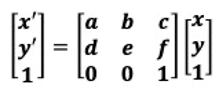
For the purposes of labeling, training and inference of the raw JP2 files are divided into non-overlapping 512 x 512-pixel JPG files. The extraction of smaller sub-images from the original JP2 necessitates the creation of an individual affine transform directly from each individual extracted JPG file. These operations were performed utilizing the rasterio and affine Python packages with AWS Batch and facilitated the reporting of the position of inferred ferns in UTM coordinates.
Data labeling
Visual identification of ferns in the aerial images is complicated by several factors. Most of the information is aggregated in the green channel, and there is a high density of foliage with frequent partial occlusion of ferns by both nearby ferns and other vegetation. The information of interest to TNC is the relative density of ferns per acre, therefore it’s important to count each individual fern even in the presence of occlusion. Given these goals and constraints, we chose to utilize an object detection CV framework.
To label the data, we set up an Amazon SageMaker Ground Truth labeling job. Each bounding box was intended to be centered in the center of the fern, and to cover most of the fern branches, while at the same time attempting to minimize the inclusion of other vegetation. The labeling was performed by the authors following consultation with TNC domain experts. The initial labeled dataset included 500 images, each typically containing several ferns, as shown in the following example images. In this initial labeled set we did not distinguish between native and invasive ferns.

Fern Object detection model training and update
In this section we discuss training the initial fern detection model, data labeling in Ground Truth and the model update through retraining. We also discuss using Amazon Augmented AI (Amazon A2I) for the model update, and using AWS Step Functions for the overall fern detection inference pipeline.
Initial fern detection model training
We utilized the Amazon SageMaker object detection algorithm because it provides state-of-the-art performance and can be easily integrated with other SageMaker services such as Ground Truth, endpoints, and Batch Transform jobs. We utilized the Single Shot MultiBox Detector (SSD) framework and base network vgg-16. This network comes pre-trained on millions of images and thousands of classes from the ImageNet dataset. We break all the given TNC JP2 images into 512 x 512-pixel tiles as the training dataset. There are about 5,000 small JPG images, and we randomly selected 4,500 images as the training dataset and 500 images as the validation dataset. After hyperparameter tuning, we chose the following hyperparameters for the model training: class=1, overlap_threshold=0.3, learning_rate=0.001, and epochs=50. The initial model’s mean average precision (mAP) computed on the validation set is 0.49. After checking the detection results and TNC labels, we discovered that many ferns that were detected as ferns by our object detection model were not labeled as ferns from TNC fern labels, as shown in the following images.

Therefore, we decided to use Ground Truth to relabel a subset of the fern dataset in the attempt to improve model performance and then compare ML inference results with this initial model to check which approach is better.
Data labeling in Ground Truth
To label the fern dataset, we set up a Ground Truth job of 500 randomly selected 512 x 512-pixel images. Each bounding box was intended to be centered in the center of the fern, and to cover most of the fern branches, while at the same time attempting to minimize the inclusion of other vegetation. The labeling was performed by AWS data scientists following consultation with TNC domain experts. In this labeled dataset, we didn’t distinguish between native and invasive ferns.
Retraining the fern detection model
The first model training iteration utilized a set of 500 labeled images, of which 400 were in the training set and 100 in the validation set. This model achieved a mAP (computed on the validation set) score of 0.46, which isn’t very high. We next used this initial model to produce predictions on a larger set of 3,888 JPG images extracted from the available JP2 data. With this larger image set for training, the model achieved a mAP score of 0.87. This marked improvement (as shown in the following example images) illustrates the value of automated labeling and model iteration.

Based on these findings we determined that Ground Truth labeling plus automated labeling and model iteration appear to significantly increase prediction performance. To further quantify the performance of the resulting model, a set of 300 images were randomly selected for an additional round of validation. We found that when utilizing a threshold of 0.3 for detection confidence, 84% of the images were deemed by the labeler to have the correct number of predicted ferns, with 6.3% being overcounts and 9.7% being undercounts. In most cases, the over/undercounting was off by only one or two ferns out of five or six present in an image, and is therefore not expected to significantly affect the overall estimation of fern density per acre.
Amazon A2I for fern detection model update
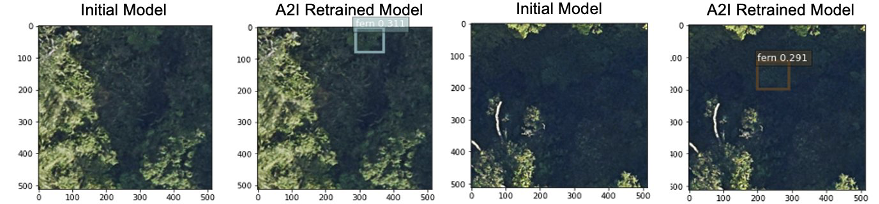
One challenge for this project is that the images coming in every year are taken from aircraft, so the altitude, angles, and light condition of the images may be different. The model trained on the previous dataset needs to be retrained to maintain good performance, but labeling ferns for a new dataset is labor-intensive. Therefore, we used Amazon A2I to integrate human review to ensure accuracy with new data. We used 360 images as a test dataset; 35 images were sent back to for review because these images didn’t have predictions with a confidence score over 0.3. We relabeled these 35 images and retrained the model using incremental learning in Amazon A2I. The retrained model showed significant improvement from the previous model on many aspects, such as detections under darker light conditions, as shown in the following images. These improvements made the new model perform fairly well on new dataset with very few human reviews and relabeling work.
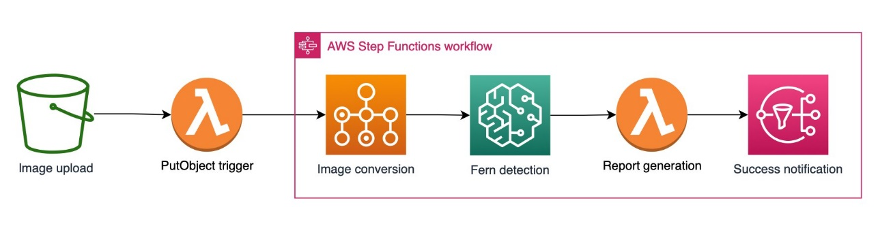
Fern detection inference pipeline
The overall goal of the TNC-AWS partnership is the creation of an automated pipeline that takes as input the JP2 files and produces as output UTM coordinates of the predicted ferns. There are three main tasks:
- The first is the ingestion of the large JP2 file and its division into smaller 512 x 512 JPG files. Each of these has an associated affine transform that can generate UTM coordinates from the pixel coordinates.
- The second task is the actual inference and detection of potential ferns and their locations.
- The final task assembles the inference results into a single CSV file that is delivered to TNC.
The orchestration of the pipeline was implemented using Step Functions. As is the case for the inference, this choice automates many of the aspects of provisioning and releasing computing resources on an as-needed basis. Additionally, the pipeline architecture can be visually inspected, which enhances dissemination to the customer. Finally, as updated models potentially become available in the future, they can be swapped in with little or no disruption to the workflow. The following diagram illustrates this workflow.
When the inference pipeline was used in batch mode on a source image of 10,000 x 10,000 pixels, and allocating an m4.large instance to SageMaker batch transform, the whole inference workflow ran within 25 minutes. Of these, 10 minutes was taken by the batch transform, and the rest by Step Functions steps and AWS Lambda functions. TNC expects sets up to 24 JP2 images at one time, about twice a year. By adjusting the size and number of instances to be used by the batch transform, we expect that the inference pipeline can be fully run within 24 hours.
Fern classification
In this section, we discuss how we applied the SageMaker Principal Component Analysis (PCA) algorithm to the bounding boxes and validated the classification results.
Application of PCA to fern bounding boxes
To determine whether it is possible to distinguish between the Australian tree fern and native ferns without the substantial effort of labeling a large set of images, we implemented an unsupervised image analysis procedure. For each predicted fern, we extracted the region inside the bounding box and saved it as a separate image. Next, these images were embedded in a high dimensional vector space by utilizing the img2vec approach. This procedure generated a 2048-long vector for each input image. These vectors were analyzed by utilizing Principal Component Analysis as implemented in the SageMaker PCA algorithm. We retained for further analysis the top three components, which together accounted for more than 85% of the variance in the vector data.
For each of the top three components, we extracted the associated images with the highest and lowest scores along the component. These images were visually inspected by AWS data scientists and TNC domain experts, with the goal of identifying whether the highest and lowest scores are associated with native or invasive ferns. We further quantified the classification power of each principal component by manually labeling a small set of 100 fern images as either invasive or native and utilizing the scikit-learn utility to obtain metrics such as area under the precision-recall curve for each of the three PCA components. When the PCA scores were used as inputs to a binary classifier (see the following graph), we found that PCA2 was the most discriminative, followed by PCA3, with PCA1 displaying only modest performance in distinguishing between native and invasive ferns.
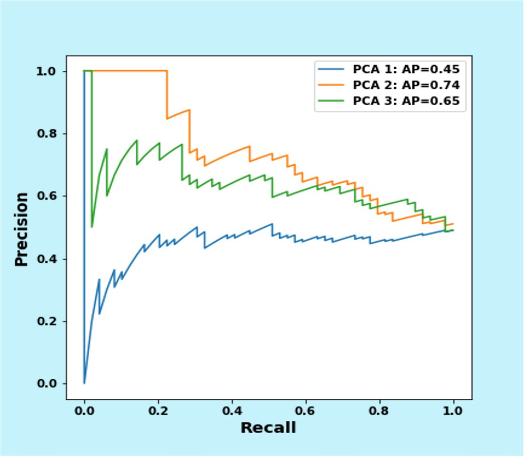
Validation of classification results
We then examined images with the biggest and smallest PCA2 values with TNC domain experts to check if the algorithm can differentiate native and invasive ferns effectively. After going over 100 sample fern images, TNC experts determined that the images with the smallest PCA2 values are very likely to be native ferns, and the images with the largest PCA2 values are very likely to be invasive ferns (see the following example images). We would like to further investigate this approach with TNC in the near future.

Conclusion
The major benefits to TNC from adopting the inference pipeline proposed in this post are twofold. First, substantial cost savings is achieved by replacing months-long efforts by human labelers with an automatic pipeline that incurs minimal inference costs. Although exact costs can depend on several factors, we estimate the cost reductions to be at least of an order of magnitude. The second benefit is the reduction of time from data collection to the initiation of mitigation efforts. Currently, manual labeling for a dozen large JP2 files take several weeks to complete, whereas the inference pipeline is expected to take a matter of hours, depending on the number and size of inference instances allocated. A faster turnaround time would impact the capacity of TNC to plan routes for the crews responsible for treating the invasive ferns in a timely manner, and potentially find appropriate treatment windows considering the seasonality and weather patterns on the islands.
To get started using Ground Truth, see Build a highly accurate training dataset with Amazon SageMaker Ground Truth. Also learn more about Amazon ML by going to the Amazon SageMaker product page, and explore visual workflows for modern applications by going to the AWS Step Functions product page.
About the Authors
 Dan Iancu is a data scientist with AWS. He has joined AWS three years ago and has worked with a variety of customers including in Health Care and Life Sciences, the space industry and the public sector. He believes in the importance of bringing value to the customer as well as contributing to environmental preservation by utilizing ML tools.
Dan Iancu is a data scientist with AWS. He has joined AWS three years ago and has worked with a variety of customers including in Health Care and Life Sciences, the space industry and the public sector. He believes in the importance of bringing value to the customer as well as contributing to environmental preservation by utilizing ML tools.
 Kara Yang is a Data Scientist in AWS Professional Services. She is passionate about helping customers achieve their business goals with AWS cloud services. She has helped organizations build ML solutions across multiple industries such as manufacturing, automotive, environmental sustainability and aerospace.
Kara Yang is a Data Scientist in AWS Professional Services. She is passionate about helping customers achieve their business goals with AWS cloud services. She has helped organizations build ML solutions across multiple industries such as manufacturing, automotive, environmental sustainability and aerospace.
 Arkajyoti Misra is a Data Scientist at Amazon LastMile Transportation. He is passionate about applying Computer Vision techniques to solve problems that helps the earth. He loves to work with non-profit organizations and is a founding member of ekipi.org.
Arkajyoti Misra is a Data Scientist at Amazon LastMile Transportation. He is passionate about applying Computer Vision techniques to solve problems that helps the earth. He loves to work with non-profit organizations and is a founding member of ekipi.org.
 Annalyn Ng is a Senior Solutions Architect based in Singapore, where she designs and builds cloud solutions for public sector agencies. Annalyn graduated from the University of Cambridge, and blogs about machine learning at algobeans.com. Her book, Numsense! Data Science for the Layman, has been translated into multiple languages and is used in top universities as reference text.
Annalyn Ng is a Senior Solutions Architect based in Singapore, where she designs and builds cloud solutions for public sector agencies. Annalyn graduated from the University of Cambridge, and blogs about machine learning at algobeans.com. Her book, Numsense! Data Science for the Layman, has been translated into multiple languages and is used in top universities as reference text.
 Theresa Cabrera Menard is an Applied Scientist/Geographic Information Systems Specialist at The Nature Conservancy (TNC) in Hawai`i, where she manages a large dataset of high-resolution imagery from across the Hawaiian Islands. She was previously involved with the Hawai`i Challenge that used armchair conservationists to tag imagery for weeds in the forests of Kaua`i.
Theresa Cabrera Menard is an Applied Scientist/Geographic Information Systems Specialist at The Nature Conservancy (TNC) in Hawai`i, where she manages a large dataset of high-resolution imagery from across the Hawaiian Islands. She was previously involved with the Hawai`i Challenge that used armchair conservationists to tag imagery for weeds in the forests of Kaua`i.
 Veronika Megler is a Principal Consultant, Big Data, Analytics & Data Science, for AWS Professional Services. She holds a PhD in Computer Science, with a focus on spatio-temporal data search. She specializes in technology adoption, helping customers use new technologies to solve new problems and to solve old problems more efficiently and effectively.
Veronika Megler is a Principal Consultant, Big Data, Analytics & Data Science, for AWS Professional Services. She holds a PhD in Computer Science, with a focus on spatio-temporal data search. She specializes in technology adoption, helping customers use new technologies to solve new problems and to solve old problems more efficiently and effectively.