Posted by Elie Bursztein and Owen Vallis, Google
TensorFlow similarity now supports key self-supervised learning algorithms to help you boost your model’s accuracy when you don’t have a lot of labeled data.
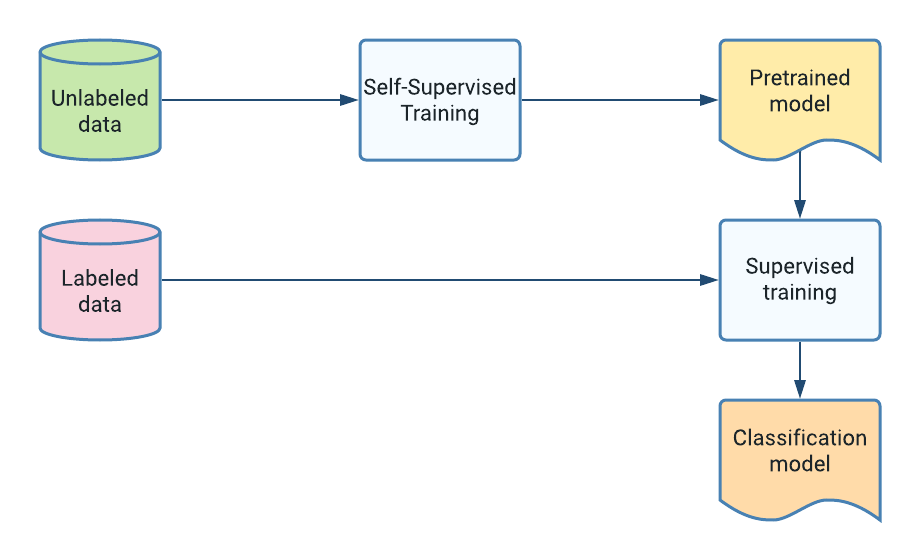
|
| Basic Self-Supervised Training. |
Often when training a new machine learning classifier, we have a lot more unlabeled data, such as photos, than labeled examples. Self-supervised learning techniques aim at leveraging those unlabeled data to learn useful data representations to boost classifier accuracy via a pre-training phase on those unlabeled examples. The ability to tap into abundant unlabeled data can significantly improve model accuracy in some cases.
Perhaps the most well known example of successful self-supervised training are transformer models, such as BERT, that learn meaningful language representations by pre-training on very large quantities of text, e.g., wikipedia or the web.
Self-supervised learning can be applied to any type of data and at various data scales. For example, if you have only a few hundred labeled images, using self-supervised learning can boost your model accuracy by pre-training on a medium sized dataset such as ImageNet. For example, SimCLR uses the ImageNet ILSVRC-2012 dataset for training the representations and then evaluates the transfer learning performance on 12 other image datasets such as CIFAR, Oxford-IIIT Pets, Food-101, and others. Self-supervised learning works at larger scales as well, where pre-training on billions of examples improves accuracy as well, including text transformer and vision transformer.
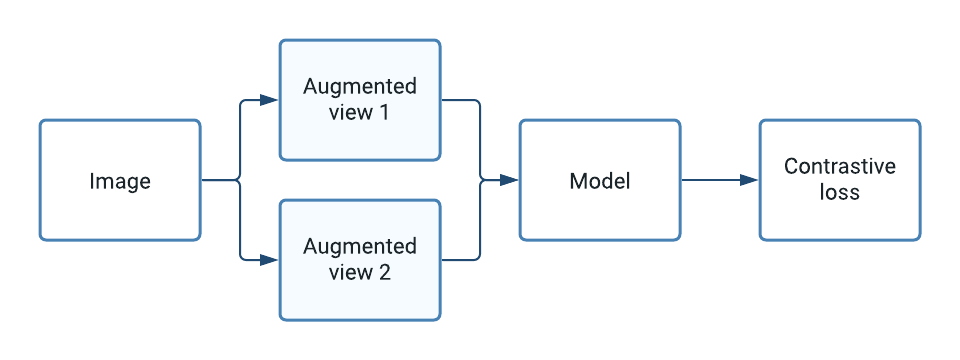 |
| High level overview of how self-supervised learning works for images. |
At its core, self-supervised learning works by contrasting two augmented “views” of the same example. The model objective is to maximize the similarity between these views to learn representations that are useful for down-stream tasks, such as training a supervised classifier. In practice, after pre-training on a large corpus of unlabeled images, training an image classifier is done by adding a single softmax dense layer with a on top of the frozen pre-trained representation and training as usual using a small number of labeled examples.
 |
| Examples of pairs of augmented views on CIFAR10 from the hello world notebook. |
TensorFlow Similarity currently provides three key approaches for learning self-supervised representations: SimCLR, SimSiam, Barlow Twins, that work out of the box. TensorFlow Similarity also provides all the necessary components to implement additional forms of unsupervised learning. These include, callbacks, metrics, and data samplers.
You can start to explore how to leverage a self-supervised learning hello world notebook that demonstrates how to double the accuracy on CIFAR10.